Datasets for Aspect-Based Sentiment Analysis in Bangla and Its Baseline Evaluation

Institute of Information Technology, University of Dhaka, Dhaka 1000, Bangladesh
*
Authors to whom correspondence should be addressed.
Data 2018, 3(2), 15; https://doi.org/10.3390/data3020015
Submission received: 20 March 2018
/
Revised: 30 April 2018
/
Accepted: 2 May 2018
/
Published: 4 May 2018
Abstract
:With the extensive growth of user interactions through prominent advances of the Web, sentiment analysis has obtained more focus from an academic and a commercial point of view. Recently, sentiment analysis in the Bangla language is progressively being considered as an important task, for which previous approaches have attempted to detect the overall polarity of a Bangla document. To the best of our knowledge, there is no research on the aspect-based sentiment analysis (ABSA) of Bangla text. This can be described as being due to the lack of available datasets for ABSA. In this paper, we provide two publicly available datasets to perform the ABSA task in Bangla. One of the datasets consists of human-annotated user comments on cricket, and the other dataset consists of customer reviews of restaurants. We also describe a baseline approach for the subtask of aspect category extraction to evaluate our datasets.
Dataset License: CC0
1. Summary
People trust human opinion more so than traditional advertising. For example, consumers are used to seeking advice and recommendation from others before making decisions regarding important purchases. Word of mouth (WOM) has always been salient for consumers when making a decision. Such referrals have a strong impact on both customer decision-making and new customer acquisition for the purchasing of a company’s product or service [1]. On the other hand, organizations are eager to mine all the activities and interactions of people to understand what their weaknesses and strengths are. This understanding would help them to develop their organizational strategy in this competitive world.
Sentiment analysis (or opinion mining) is a process to determine the viewpoint of a person on a certain topic. It classifies the polarity of a document (i.e., review, tweet, blog, or news), that is, whether the communicated opinion is positive, negative, or neutral. There are three levels at which sentiment is analyzed [2]: the document level, sentence level, and aspect level. The document level considers that a document has an opinion on an entity, and the task is to classify whether an entire document expresses a positive or negative sentiment. The task at the sentence level regards sentences and determining whether each sentence expresses a positive, negative, or neutral opinion. Neither the document level nor the sentence level analysis discover exactly what people liked and did not like. The aspect level (or aspect-based sentiment analysis—ABSA) performs a finer-grained analysis that identifies the aspects of a given document or sentence and the sentiment expressed towards each aspect. This level of analysis is the most detailed version that is capable of discovering complex opinions from reviews.
There are two major tasks when performing ABSA. The first is to extract the specific areas or aspects mentioned in the opinioned review. The second is to identify the polarity (either positive, negative, or neutral) for every aspect. For example, the following review of a restaurant reveals two aspects: service and food. Both aspects have a positive polarity.
“The service was excellent and the food was delicious.”
As one can see, the name of the aspect categories are explicitly mentioned in this review. A review might also contain implicit categories; for example, “The staff makes you feel at home and the chicken is great.” Here, the same aspects, “service” and “food”, are contained without being directly mentioned.
Semantic Evaluation (SemEval), a reputed workshop in the NLP domain, introduced a complete dataset [3] in English for the ABSA task. Later this was expanded to the ABSA task by adding multi-lingual datasets in which eight languages over seven domains were incorporated. To perform ABSA, datasets of several languages, such as Arabic [4], Czech [5], and French [6], were created. There is no dataset for Bangla in the field of ABSA. Consequently, no work is being done to extract aspects and to identify corresponding polarities for Bangla reviews. We are currently working on a project to extract the aspects from a Bangla review or comments for a particular product of a company, as online shopping is very popular nowadays in Bangladesh and is growing rapidly. People like to buy products online after reading the comments of others.
In this paper, we have created two new datasets that serve as a benchmark for the ABSA domain in Bangla texts. We present two datasets named “Cricket” and “Restaurant”. The first dataset contains 2900 comments on cricket over 5 aspect categories, and the second dataset contains 2600 restaurant reviews.
Because there is no work in Bangla for the ABSA task, we have introduced ABSA by extracting aspect categories from Bangla texts in order to evaluate our datasets. We performed the task with different training approaches and found a satisfactory outcome compared to evaluations of other languages.
There are some related works from which we founded the idea of this topic. The restaurant review dataset, provided by Ganu et al. [7], was used to improve rating predictions. Their annotations included six aspect categories and overall sentence polarities. They had not prepared a complete ABSA dataset, as the aspect category was present but the corresponding polarity of that aspect was absent. The SemEval 2014 evaluation campaign [3] extended their dataset by adding three more fields with the aspect category. They published their dataset with four fields being contained for each review, that is, with the aspect term occurring in the sentences, the aspect term’s polarity, the aspect category, and the aspect category’s polarity. They also provided a laptop-review dataset and manually annotated with similar entities as for the restaurant dataset. These are the benchmark datasets that [8,9,10,11] researches have used for performing the ABSA task.
The task was repeated in SemEval 2015 [12], for which aspect categories were the combination of the entity type and an attribute type. Multilingual datasets were released in the SemEval 2016 workshop [13] on the seven domains (restaurant, laptop, mobile phone, digital camera, hotel, and museum) and in eight languages (English, Arabic, French, Chinese, Turkish, Spanish, Dutch, and Russian).
A book-review dataset in the Arabic language was provided by [4]. They annotated book reviews into 14 categories and 4 types of polarities, including “Conflict”. In [5], the author created an IT product-review dataset for the ABSA task, in which a total 2200 reviews were contained.
The contribution of this paper is as follows:
- We have collected and presented two Bangla datasets for ABSA and have made them publicly available.
- We performed statistical linguistic analysis on the datasets.
- We implemented state-of-the-art machine learning approaches for the collected datasets and found satisfactory accuracies.
2. Data Description
“Digital Bangladesh” is the integral part of the Bangladesh government’s Vision 2021. The Internet is growing very fast over the country, and people are using different online platforms in every aspect of their lives. This encouraged us to construct datasets to analyze the Bengali people’s opinions and to extract their sentiments in different aspects. In this paper, we have constructed two different datasets, namely, the Cricket dataset and Restaurant dataset, to evaluate the people’s opinions.
2.1. Cricket Dataset
The Cricket dataset consists of 2900 different comments from different online sources with five different aspect categories. Most of the comments are collected from Facebook pages (https://www.facebook.com/BBCBengaliService/; https://www.facebook.com/DailyProthomAlo/). Some comments are collected from two popular Bengali Websites, BBC Bangla (http://www.bbc.com/bengali), and the Daily Prothom Alo (http://www.prothomalo.com). This dataset was collected by the authors of this paper. The comments are of different lengths and each review contains approximately 3–100 Bangla words. The reasons behind choosing these Websites for collecting data are given below:
- BBC Bangla and the Daily Prothom Alo are very popular online news sites for the Bengali community all around the world. They are popular for publishing trustworthy and authentic news. Bengali people frequently read the news and sometimes make comments to share their opinion. Although people write their comments or opinions in both Bangla and English, most of the time, they choose Bangla. We studied different articles and found that in almost 90% of the cases, people expressed their opinion in Bangla.
- The Facebook page of Prothom Alo has over 13 million followers, and BBC Bangla has over 11 million. These two pages provide enormous text posts as well as a large number of comments.
- Cricket is one of the most popular games nowadays for Bengali people. We found that people are more interested in making comments on cricket-related news than on any other topic. Thus, we chose this category for our experiment.
Table 1 shows an example of comments collected from the Facebook pages.
People usually comment in Bangla about the news. We also found that 5–10% of the time, they commented in English and also wrote Bangla sentences written in the English alphabet. We did not consider these opinions in our dataset. In addition, some comments had only emoticons and no other text or words. We also omitted these for our dataset. All of the processes were done manually by the authors. The following section describes the annotation process of the collected corpus of cricket-related comments.
2.1.1. Annotation of Cricket Dataset
The Bangla text on cricket was annotated jointly by the authors, a group of second-year students of BSSE, and two employees from the Institute of Information Technology, University of Dhaka, Bangladesh. All participants agreed to categorize the whole dataset into five different aspect categories. These were bowling, batting, team, team management, and other. Given a comment, the task of the annotators was to recommend the aspect category and polarity labels for each. Three types of polarities were considered, that is, positive, negative, and neutral. Table 2 shows the information about the participants.
Each participant categorized every comment of the dataset. We applied the majority voting technique to make the final decision about the aspect category and the polarity of a sentence. As an example, we have taken the following comment:
“এই পিচে রান করা টাফ, বোলিং নিঃসন্দেহে ভালো হয়েছে ”
The voting result we found for the comment is given in Table 3.
From Table 3, we can see that the comments had three votes for Batting with a negative polarity, two votes for Other with a neutral polarity, and four votes for Bowling with a positive polarity. Thus, our method determined this comment as being in the Bowling category with a positive polarity. We also had ties for some comments. In this situation, we took both the categories with their polarity in our dataset. Table 4 shows an example for this scenario.
We can see from Table 4 that 50% of the evaluators voted for Batting, and 50% of the votes were for the Team category, both with a negative polarity. As they had tied, our algorithm took both of these categories in the labeled dataset with a negative polarity.
We also faced another kind of problem to construct the dataset. After calculating the category, we found dissimilarities for some comments among the participants regarding the polarity of the comment. For example, when we considered the following comment, we found the voting result given in Table 5.
From Table 5, we can see that, for the comment, both the Bowling and Team categories had four votes. Thus, we keep both of these categories in our annotated dataset. In polarity, there were three positive votes and one negative vote for bowling. Thus, we considered it as having a positive polarity and added it to our dataset. Table 6 shows a sample of the labeled Cricket dataset.
In Table 7, the summary of the complete Cricket dataset is presented. We can see that there are a total of 3034 different comments with five different categories, that is, Batting, Bowling, Team, Team Management, and Other. Each of the categories contains three different polarities: positive, negative, and neutral. For example, the Batting category contains a total of 583 comments, for which 138 are of positive, 389 are of negative, and 56 are of neutral polarity. The Bowling category contains 154 positive, 145 negative, and 33 neutral polarity comments. The Team, Team Management, and Other categories contain totals of 774, 332, and 1013 comments, respectively.
2.1.2. Analysis of Proposed Cricket Dataset
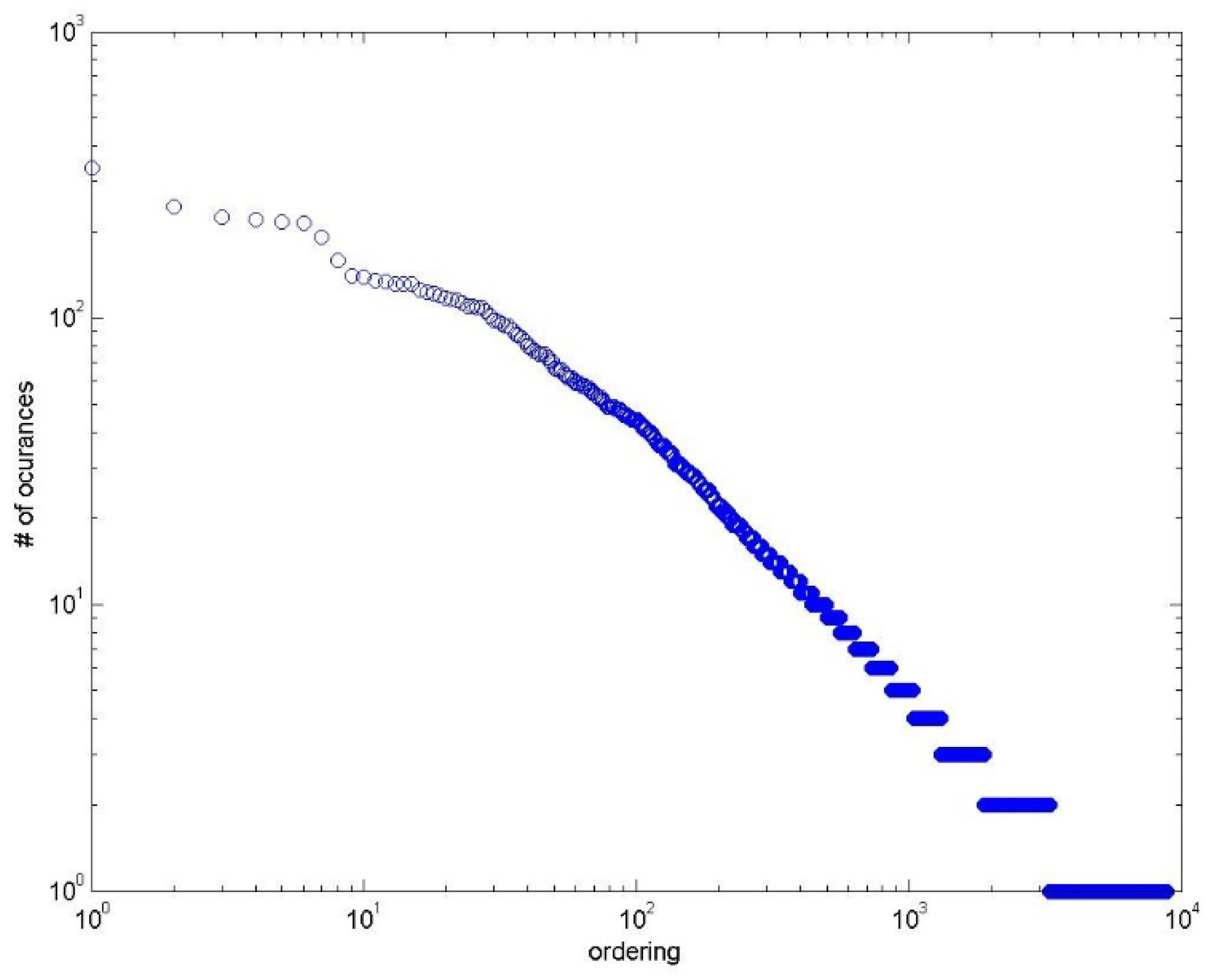
We used Zipf’s law [14] for our proposed Cricket dataset. Zipf’s law is a statement-based observation that states that in a collection of data, the frequency of a given word should be inversely proportional to its rank in the corpus. The word that is the most frequent and scores rank 1 in a dataset should occur approximately twice as the second most frequent word, three times as the third most frequent, and so on. Figure 1 shows the diagram in which we plotted the words of our Cricket dataset. The plot follows the trend of Zipf’s law. We also calculated the reliability of the annotation process. The value of the intraclass correlation (ICC) was 0.71.
2.2. Restaurant Dataset
To create the Bangla Restaurant dataset, we took help directly from the English benchmark’s Restaurant dataset [3]. All comments were abstractly translated into Bangla with their exact annotation. The original English dataset contains a total of 2800 different comments. Participants from the same group involved in the Cricket dataset’s creation were involved in the translation process of the Restaurant dataset, except participants P9 and P10. We divided the original dataset equally into eight parts and distributed these to the participants. They translated their assigned parts of the original English dataset abstractly. Finally, participants P1 and P2 merged the separate sections and performed an extensive proofread.
Annotation Schema for Restaurant
The Restaurant reviews [3] dataset used in this paper was abstractly translated into Bangla. There were five types of aspect categories, that is, Food, Price, Service, Ambiance, and Miscellaneous. As the objective was to identify the aspect category and corresponding polarity, the participants did not add aspect terms or their polarities. In terms of the polarity of an aspect category, we considered only three polarity labels, that is, positive, negative and neutral. The original dataset consisted of four different polarity labels: positive, negative, neutral, and conflict. In our translated Bangla dataset, we omitted the conflict category and assumed it to be the same as the neutral category. The annotators were asked to assign each translated Bangla restaurant review into their categories and their polarities for the original dataset. Table 8 shows a sample of the translated Restaurant dataset.
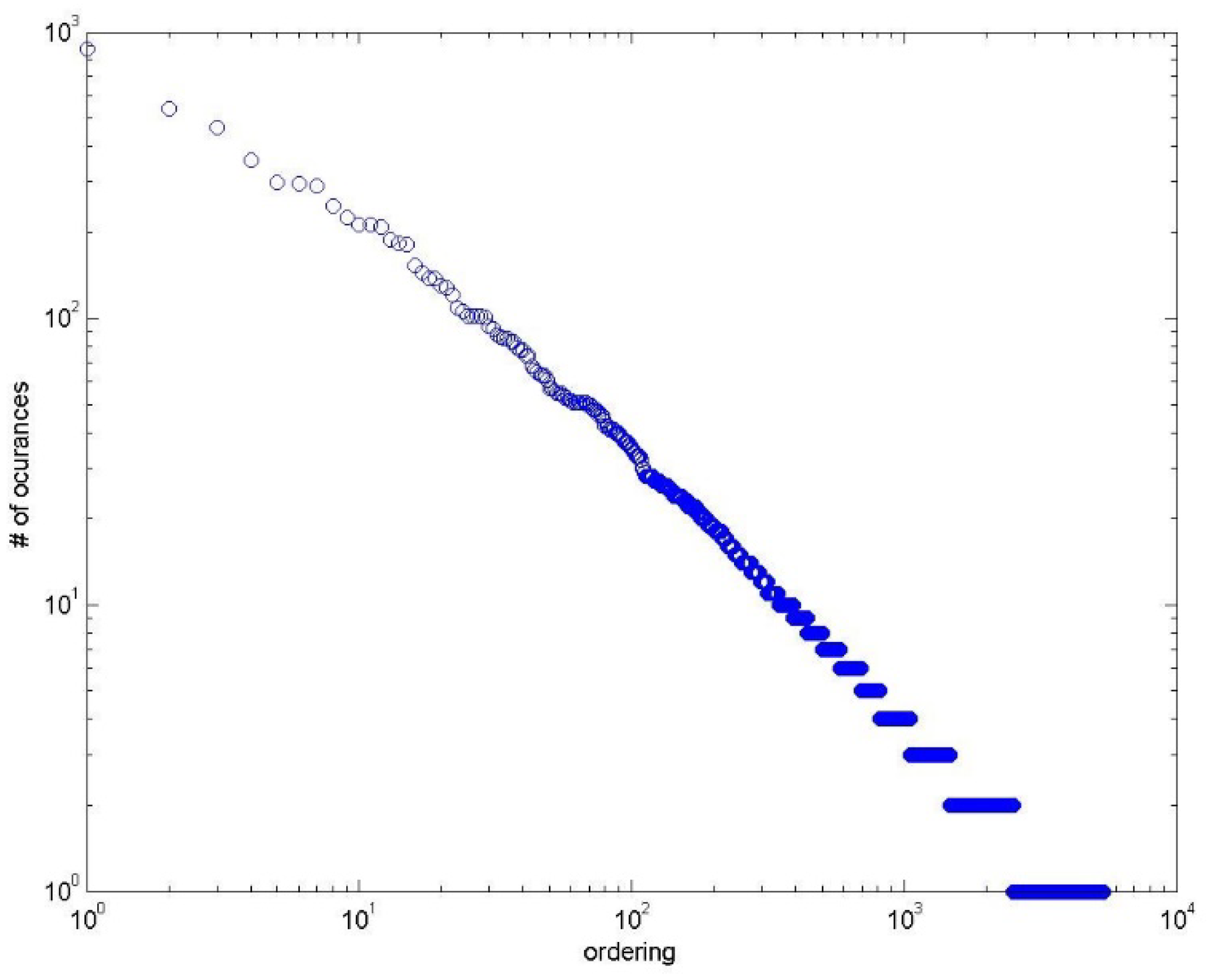
Table 9 shows the complete statistics of the Bangla Restaurant dataset. We can see from the table that five different categories, that is, Food, Price, Service, Ambiance, and Miscellaneous, contained 713, 178, 336, 234, and 613 reviews, respectively, with three different polarities. For example, the category Food contained 500 positive, 126 negative, and 87 neutral sentiment labels. The Service category contained 186 positive, 118 negative, and 32 neutral sentiments. We also found that this Restaurant dataset also followed Zipf’s law, which is shown in Figure 2.
3. Baseline Evaluation
Our objective is to provide benchmark datasets for Bangla ABSA. Our datasets are designed for two major tasks of ABSA. These are aspect category extraction and the identification of polarity for each aspect category. In this paper, we experimented with the first subtask, that is, the extraction of the aspect category. We applied three major steps to extract the aspect category. Firstly, preprocessing was performed on the dataset. After this, we extracted features from the data and finally performed classification using some popular classification models.
3.1. Preprocessing and Feature Extraction
In the preprocessing phase, each Bangla document was represented as a “bag of words”. We applied traditional preprocessing steps for the evaluation. Firstly, punctuations and stop words were removed from each of the comments. After this, we removed the digits from our dataset, because we found that digits were not necessary for the aspect category. Finally, we tokenized each Bangla word from our dataset.
Thus, a vocabulary of Bangla words was prepared after preprocessing. We created a feature matrix for which each review was represented by a vector of that vocabulary. Term frequency–inverse document frequency (TF–IDF) was used for calculating the features.
3.2. Results
In the training phase, extracted feature sets were trained by the popular supervised machine learning algorithms. Because this was a multi-label classification problem, we trained our models by setting up multi-label output. We used linear SVC in the support vector machine (SVM) implementation. The following machine learning algorithms were used:
- Support Vector Machine (SVM)
- Random forest (RF)
- K-nearest neighbor (KNN)
After the training was completed, our proposed Bangla test dataset was executed on the trained model. The result is shown in the following table and figure.
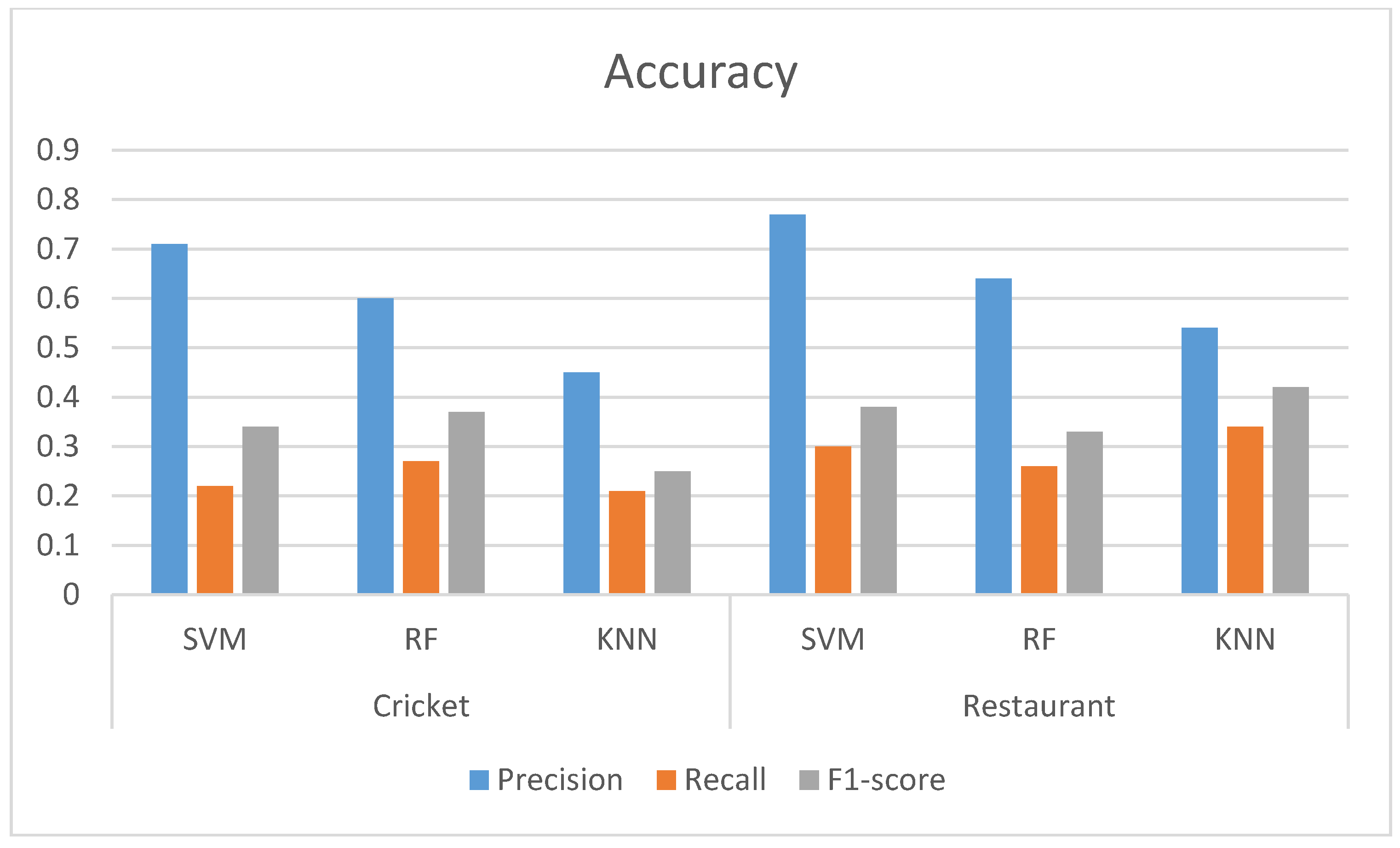
Table 10 shows the results for the task of aspect category extraction of the datasets we have presented in this paper. We can see that using the SVM, we obtained the highest precision rate for both of the datasets. Both datasets showed a low recall and F1-score. Figure 3 shows the overall accuracy of the models using our datasets. The inherent nature of the datasets is the reason behind the lower performance of the models for both datasets. People share their opinion with their individual judgment. Therefore, the variety of opinions in the datasets is much larger. On the other hand, aspect extraction is a multi-label classification problem. One’s opinion might have multiple aspect categories. Conventional classifiers miss some of these aspect categories.
These results can be improved if we process and train the datasets in a more sophisticated way. In this work, we have taken all of the vocabulary as features for the evaluation after removing punctuation, stop words, and digits. Some state-of-the-art techniques for information gain can be applied to the dataset before classification and after the preprocessing steps to attain better results.
4. Conclusions and Future Work
Two datasets are provided for the ABSA of Bangla text. These datasets have been designed to perform two tasks covering aspect category extraction and the identification of polarity for that aspect category. We also report baseline results to evaluate the task of aspect category extraction.
As future plans, we aim to enhance our work by including further domains such as cars, mobiles, and laptops. We are working on more advanced methods for the ABSA of Bangla text using our datasets to achieve better performance.
Author Contributions
All authors contributed equally to this work, and have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Trusov, M.; Bucklin, R.E.; Pauwels, K. Effects of word-of-mouth versus traditional marketing: Findings from an internet social networking site. J. Mark. 2009, 73, 90–102. [Google Scholar] [CrossRef]
- Jeyapriya, A.; Selvi, C.K. Extracting Aspects and Mining Opinions in Product Reviews Using Supervised Learning Algorithm. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. Available online: http://www.aclweb.org/anthology/S14-2004 (accessed on 3 May 2018).
- Al-Smadi, M.; Qawasmeh, O.; Talafha, B.; Quwaider, M. Human Annotated Arabic Dataset of Book Reviews for Aspect Based Sentiment Analysis. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud (FiCloud), Rome, Italy, 24–26 August 2015. [Google Scholar]
- Tamchyna, A.; Fiala, O.; Veselovská, K. Czech Aspect-Based Sentiment Analysis: A New Dataset and Preliminary Results. Available online: https://pdfs.semanticscholar.org/cbd8/7f4201c427db33783b1890bca65f5bf99d2c.pdf (accessed on 3 May 2018).
- Apidianaki, M.; Tannier, X.; Richart, C. Datasets for Aspect-Based Sentiment Analysis in French. Available online: http://www.lrec-conf.org/proceedings/lrec2016/pdf/61_Paper.pdf (accessed on 3 May 2018).
- Gayatree, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions Using Review Text Content. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.150.140&rep=rep1&type=pdf (accessed on 3 May 2018).
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. Available online: http://www.aclweb.org/anthology/S14-2076 (accessed on 3 May 2018).
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. Supervised and Unsupervised Aspect Category Detection for Sentiment Analysis with Co-cccurrence Data. In IEEE Transactions on Cybernetics; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Soujanya, P.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl.-Based Syst. 2016, 108, 42–49. [Google Scholar]
- Pengfei, L.; Joty, S.; Meng, H. Fine-Grained Opinion Mining with Recurrent Neural Networks and Word Embeddings. Available online: http://www.aclweb.org/anthology/D15-1168 (accessed on 3 May 2018).
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 Task 12: Aspect Based Sentiment Analysis. Available online: http://www.aclweb.org/anthology/S15-2082 (accessed on 3 May 2018).
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. Available online: http://www.aclweb.org/anthology/S16-1002 (accessed on 3 May 2018).
- Pak, A.; Paroubek, P. Twitter as A Corpus for Sentiment Analysis and Opinion Mining. Available online: http://crowdsourcing-class.org/assignments/downloads/pak-paroubek.pdf (accessed on 3 May 2018).
Figure 1.
Distribution of word frequencies of Cricket dataset using Zipf’s law.

Figure 2.
Word frequency of Bangla Restaurant dataset according to Zipf’s law.

Figure 3.
The result of three models of our datasets.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Example of cricket-related comments on Prothom Alo and BBC Bangla Facebook pages.
| Comments | Source |
|---|---|
| মাশরাফি এক জাদুকারী নাম । যে নামটা শুনলেই মন ভরে যায়। আমাদের জহির,জনসন,পোলক,ব্রেটলি নাই তবে এক জন মাশরাফি আছে | Prothom Alo Facebook page |
| বোলারদেরও দোষ নেই,দোষটা ১০০% ম্যানেজমেন্টের। পেস বোলারদের জন্য উইকেট তৈরি তো তারাই করে না।দোষটা ম্যানেজমেন্ট না মানলে আমি নেব। | Prothom Alo Facebook page |
| আশা করি তাসকিন অতি দ্রুত দলে ফিরবে আর নিয়মিত খেলবে এবং প্রচুর আউট করবে। | Prothom Alo Facebook page |
| এখন দর্শকদের কাছে জনপ্রিয় হচ্ছে 20---টেষ্ট/ওয়ানডে মানুষ এখন দেখতেই চায়না.. | Prothom Alo Facebook page |
| হারলেও বাংলাদেশ জিতলেও বাংলাদেশ।আগামীতে আবার আমরাই জিতবো। ইশ! আমাদের যদি বিরাট কোহলির মতো একটা ব্যাটস্ম্যান থাকতো | BBC Bangla Facebook page |
| আমার পরামর্শ হলো ক্রিকেটারদের কর্পোরেট জগত থেকে দুরে রাখতে হবে। | BBC Bangla Facebook page |
Table 2.
Information about the participants in data collection.
| Participant ID | Gender | Profession | Task |
|---|---|---|---|
| P1 | Male | MS student/author | Data collection (Cricket) and annotation |
| P2 | Male | Faculty/author | Data collection (Cricket) and annotation |
| P3 | Male | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P4 | Female | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P5 | Female | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P6 | Male | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P7 | Male | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P8 | Male | Graduate student | Annotation (Cricket) and translation (Restaurant) |
| P9 | Female | Accountant | Annotation |
| P10 | Male | Officer | Annotation |
Table 3.
Voting example to define the category and polarity.
| Comment: এই পিচে রান করা টাফ, বোলিং নিঃসন্দেহে ভালো হয়েছে | ||
|---|---|---|
| Participant | Voting for Category | Voting for Polarity |
| P1 | Bowling | Positive |
| P2 | Bowling | Positive |
| P3 | Batting | Negative |
| P4 | Batting | Negative |
| P5 | Other | Neutral |
| P6 | Bowling | Positive |
| P7 | Other | Neutral |
| P8 | Bowling | Positive |
| P9 | Bowling | Positive |
| P10 | Batting | Negative |
Table 4.
Voting category identification.
| Comment: ওরা ২০০ করেছে, তোমরা ১০০ করতে পারবে না? | ||
|---|---|---|
| Participant | Voting for Category | Voting for Polarity |
| P1 | Batting | Negative |
| P2 | Team | Negative |
| P3 | Batting | Negative |
| P4 | Batting | Negative |
| P5 | Batting | Negative |
| P6 | Team | Negative |
| P7 | Team | Negative |
| P8 | Batting | Negative |
| P9 | Team | Negative |
| P10 | Team | Negative |
Table 5.
Problem related to polarity determination.
| Comment: রাজ্জাক বুড়ো হয়ে গেছে, খেলা পারেনা। তাহলে আজ কিভাবে কি করলো? | ||
|---|---|---|
| Participant | Voting for Category | Voting for Polarity |
| P1 | Bowling | Positive |
| P2 | Bowling | Positive |
| P3 | Team | Negative |
| P4 | Bowling | Negative |
| P5 | Other | Positive |
| P6 | Team | Negative |
| P7 | Other | Negative |
| P8 | Team | Negative |
| P9 | Bowling | Positive |
| P10 | Team | Negative |
Table 6.
A part of the Cricket dataset in xlsx format.
| ব্যাপার না। এটা শুধুমাত্র দুর্ঘটনা ছাড়া কিছু না। | other | neutral |
| শুভকামনা টাইগারদের জন্য। | team | positive |
| বাংলাদেশ এখনো তামিমের যোগ্য ওপেনার পেলো না। | batting | negative |
| বাংলাদেশ হারবে আজ । | team | negative |
| সাতজন স্পিনার নিয়ে মাঠে বোতল টানানো যায় ম্যাচ জেতা যায় না। | bowling | negative |
| টার্নিং পিচ বানিয়ে ঔষধ খুজে লাভ কি বাউন্সি পিচ বানালেই হয়। | team management | negative |
| এটা পুরাদমে ফিক্সিং একটা খেলা হইসে। | team | negative |
| জয় শুধু সময়ের অপেক্ষা। | other | positive |
| যেই ড্র জয়ের সমান!! | other | neutral |
| বোলাররা যে পরিমানে শর্ট বল দিচ্ছে- তাতে রান কতবেশি হয় সেটাই দেখার বিষয়! | bowling | negative |
| তাকে টেস্ট আর ওডিআই দলে নিয়মিত চাই। | team | positive |
| বাংলাদেশ ক্রিকেট আরো এগিয়ে যাবে, ওপেনারদের একটু ভালো করতে হবে। | team | positive |
| বাংলাদেশ ক্রিকেট আরো এগিয়ে যাবে, ওপেনারদের একটু ভালো করতে হবে। | batting | negative |
| ফিরেই চমক দেখালেন রাজ্জাক | bowling | positive |
| নবীনদের সুযোগ দেয়া দরকার. | other | neutral |
| বোলিং পিচ তবে আমাদের ব্যাটসম্যানদের আউটগুলো আত্মহত্যা ছাড়া আর কিছুই নয়। | batting | negative |
| বোলিং পিচ তবে আমাদের ব্যাটসম্যানদের আউটগুলো আত্মহত্যা ছাড়া আর কিছুই নয়। | bowling | neutral |
| দায়িত্বজ্ঞান হীনতার অভাব? | other | negative |
Table 7.
The complete statistics of Cricket dataset.
| Category | Polarity | Total | ||
|---|---|---|---|---|
| Positive | Negative | Neutral | ||
| Batting | 138 | 389 | 56 | 583 |
| Bowling | 154 | 145 | 33 | 332 |
| Team | 166 | 502 | 66 | 774 |
| Team Management | 24 | 293 | 15 | 332 |
| Other | 89 | 828 | 96 | 1013 |
| Total Comments | 3034 | |||
Table 8.
A part of the Restaurant dataset in xlsx format.
| খুব সীমিত আসন আছে এবং খাদ্য পাওয়ার জন্য যথেষ্ট অপেক্ষা করতে হবে। | ambience | negative |
| খুব সীমিত আসন আছে এবং খাদ্য পাওয়ার জন্য যথেষ্ট অপেক্ষা করতে হবে। | service | negative |
| দাম তুলনামূলকভাবে কম। | price | positive |
| ফ্রাই ছিল মজাদার | food | positive |
| যদিও খাবারটি চমৎকার ছিল, এটি সস্তা ছিল না। | food | positive |
| যদিও খাবারটি চমৎকার ছিল, এটি সস্তা ছিল না। | price | negative |
| খুব ভাল! | miscellaneous | positive |
| আচারের সংযোজন খুব ভাল ছিল । | food | positive |
| শুধুমাত্র রান্নাই যে সেরা তা নয়, সেবা সবসময় মনোযোগী এবং ভাল হয়েছে। | food | positive |
| শুধুমাত্র রান্নাই যে সেরা তা নয়, সেবা সবসময় মনোযোগী এবং ভাল হয়েছে। | service | positive |
| সর্বদা একটি সুন্দর ভিড়, কিন্তু কোন কোলাহল নেই। | ambience | positive |
| সজ্জা অল্পস্বল্প এবং পরিষ্কার-বিভ্রান্ত বা প্রশংসা করা কিছুই নেই | ambience | neutral |
| আমি নিশ্চিত যে আমাকে বারবর ফিরে যেতে হবে, !!! | miscellaneous | positive |
| সম্ভাবত এটি একটি ছোট আরামদায়ক রেস্টুরেন্ট,ভাল সজ্জার সঙ্গে রোমান্টিক অনুভূতি। | ambience | positive |
| যদিও খাদ্য ভাল ছিল পরিবেষনা ছিল বিশ্রী। | food | positive |
| যদিও খাদ্য ভাল ছিল পরিবেষনা ছিল বিশ্রী। | service | negative |
| কর্মীরা মনোযোগী এবং বন্ধুত্বপূর্ণ। | service | positive |
| খাবার ভাল ছিল। | food | positive |
Table 9.
Complete statistics of Bangla Restaurant dataset.
| Category | Polarity | Total | ||
|---|---|---|---|---|
| Positive | Negative | Neutral | ||
| Food | 500 | 126 | 87 | 713 |
| Price | 102 | 60 | 16 | 178 |
| Service | 186 | 118 | 32 | 336 |
| Ambiance | 138 | 53 | 43 | 234 |
| Miscellaneous | 300 | 120 | 193 | 613 |
Table 10.
Performance of proposed datasets.
| Dataset | Model | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Cricket | SVM | 0.71 | 0.22 | 0.34 |
| RF | 0.60 | 0.27 | 0.37 | |
| KNN | 0.45 | 0.21 | 0.25 | |
| Restaurant | SVM | 0.77 | 0.30 | 0.38 |
| RF | 0.64 | 0.26 | 0.33 | |
| KNN | 0.54 | 0.34 | 0.42 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rahman, M.A.; Kumar Dey, E. Datasets for Aspect-Based Sentiment Analysis in Bangla and Its Baseline Evaluation. Data 2018, 3, 15. https://doi.org/10.3390/data3020015
AMA Style
Rahman MA, Kumar Dey E. Datasets for Aspect-Based Sentiment Analysis in Bangla and Its Baseline Evaluation. Data. 2018; 3(2):15. https://doi.org/10.3390/data3020015
Chicago/Turabian StyleRahman, Md. Atikur, and Emon Kumar Dey. 2018. "Datasets for Aspect-Based Sentiment Analysis in Bangla and Its Baseline Evaluation" Data 3, no. 2: 15. https://doi.org/10.3390/data3020015