Recent Advances in Targeted and Untargeted Metabolomics by NMR and MS/NMR Methods


Environmental Molecular Sciences Laboratory, Pacific Northwest National Laboratory, Richland, WA 99354, USA
High-Throughput 2018, 7(2), 9; https://doi.org/10.3390/ht7020009
Submission received: 19 March 2018
/
Revised: 9 April 2018
/
Accepted: 13 April 2018
/
Published: 18 April 2018
{kind=link}
{kind=link}
{kind=link}
Abstract
:Metabolomics has made significant progress in multiple fronts in the last 18 months. This minireview aimed to give an overview of these advancements in the light of their contribution to targeted and untargeted metabolomics. New computational approaches have emerged to overcome the manual absolute quantitation step of metabolites in one-dimensional (1D) 1H nuclear magnetic resonance (NMR) spectra. This provides more consistency between inter-laboratory comparisons. Integration of two-dimensional (2D) NMR metabolomics databases under a unified web server allowed for very accurate identification of the metabolites that have been catalogued in these databases. For the remaining uncatalogued and unknown metabolites, new cheminformatics approaches have been developed by combining NMR and mass spectrometry (MS). These hybrid MS/NMR approaches accelerated the identification of unknowns in untargeted studies, and now they are allowing for profiling ever larger number of metabolites in application studies.
1. Introduction
Omics technologies have been rapidly growing and providing holistic molecular information to comprehensively study biological systems. Through the advancements in DNA sequencing, the complete determination of the genome sequence of an organism at single nucleotide resolution has become achievable in very short time frames [1,2]. One key challenge in biology is to translate this information to determine the phenotype of an organism by combining genome, transcriptome, proteome, metabolome, structural, and physiological information. Organisms perform many of the functions through the use of small molecules and metabolites; therefore, small biological molecules, metabolites provide unique piece of information to help in shedding the light on phenotypic characteristics of genome sequence [3,4,5,6,7].
Metabolites are direct read out of also non-sequence related influences on phenotypes, such as environmental perturbations; drought, temperature, light, and atmospheric CO2 concentration [8,9,10]. The analysis of metabolite profiles of common biofluids, such as urine and serum, provides diagnostic and prognostic information about diseases, dietary patterns, and drug toxicity [11,12,13]. Stable isotope labeling of metabolites followed by the analysis of positional enrichments reveals activity of alternative metabolic pathways contributing to certain biochemical reactions, such as in healthy versus cancer cells [14,15,16].
Comprehensive analysis of metabolites are performed by metabolomics technologies, which provide identities and quantities of dozens to hundreds of intracellular and extracellular metabolites in biological samples by utilizing separation technologies, such as chromatography, capillary electrophoresis and ion mobility; and, detection technologies, in particular, mass spectrometry (MS) and nuclear magnetic resonance (NMR) spectroscopy [17,18]. Data acquisition of hundreds of samples has become achievable by high-throughput automated platforms, which also reduces the cost of measurement per sample.
Metabolome profiling is typically performed either by targeted or untargeted methods, which were explained briefly in the following sections. Regardless of the approach, every metabolomics strategy includes identification and quantitation of metabolites [19,20]. This minireview aimed to give an overview of the achievements in metabolomics over the past 18 months in order to improve the quantitation and identification of metabolites by NMR and hybrid MS/NMR methods [21,22]. The review covered the advancements in the light of their contribution to targeted and untargeted metabolomics.
2. Targeted Metabolomics
2.1. Quantitation of Metabolites
Targeted and semi-targeted metabolomics studies focus on accurate identification and quantitation of a defined set of metabolites in biological samples. Typically, this set of metabolites are predetermined by the scientific question at hand or the size of the metabolite library that is available in the software used for data analysis. The resulting data sets are feed into statistical data analysis tools to see how well targeted metabolites contribute to the group separation between control and phenotype of interest [23]. Correlations are further evaluated to understand underlying metabolism differences between groups [24,25].
Metabolomics profiling by NMR has been often performed by one-dimensional (1D) 1H NMR experiments [26]. The advantage of 1D 1H NMR is its short acquisition time, which is typically less than an hour/sample and high sensitivity; it is able to detect metabolites down to single digit μM concentration [27]. When this is coupled to a manual peak fitting or a manual spike-in approach, 1D 1H NMR is capable to provide absolute concentration of dozens to hundred of metabolites in metabolomics samples [28]. Unfortunately, the manual analysis of 1D 1H NMR spectrum is labor intensive and time-consuming, especially when it is repeated for multiple samples. Speeding up this step by automation is an active research area in NMR-based metabolomics. BATMAN [29] and BAYESIL [30] are two early approaches that have been developed for automated quantitation of 1D 1H NMR spectra by probabilistic models, followed more recently by ASICS [31], rDolphin [32], and AQuA [33]. The workflow of the AQuA approach is demonstrated in Figure 1. All of these five approaches have been primarily developed for the quantitative profiling of aqueous metabolites, another new tool LipSpin [34] has been developed for the quantitative profiling of lipids by 1D 1H NMR. While these automated 1D 1H NMR approaches greatly speed up metabolite profiling, they still require up-front manual customization of the metabolite library to include only the metabolites that are observed in the biospecimen of interest [35]. Successful implementation of the approaches also requires careful adjustments of line-widths and peak shifts that could vary between metabolomics samples.
One-dimensional 1H NMR suffers from low spectral resolution along the 1H dimension, which limits the metabolome coverage as well as the accuracy of metabolite analysis. The recent progress focused on solving these challenges by reducing spectral overlap problems by advanced NMR methods. Spectral overlap problem can be resolved by measuring the samples at higher magnetic field strengths, which also increases the sensitivity. However, this is costly, as it requires new equipment. Alternatively, the overlap problem can be resolved by decoupling homonuclear 1H–1H scalar couplings in 1D 1H NMR spectra by using pure shift methods [36,37], which generate narrow peaks without multiplet splitting. However, these approaches generally cause sensitivity losses; therefore, they only allow for the profiling of high abundant metabolites. Significant improvement on resolution can be obtained by acquiring two-dimensional (2D) NMR experiments. During 2D NMR experiments, spin magnetization is transferred between neighboring nuclear spins, which are then detected in the form of cross-peaks in the final 2D spectra with much less peak overlap. Two commonly used 2D NMR experiments in metabolomics are the 2D 13C–1H heteronuclear single quantum coherence (HSQC), revealing direct one-bond correlation between the 1H spins with their directly attached 13C spins and 2D 1H–1H total correlation spectroscopy (TOCSY) experiment revealing chemical shifts of all 1H spins within a molecule or a spin system. The HSQC experiment is a very high resolution 2D NMR experiment due to the large spectral dispersion along 13C dimension and the TOCSY experiment provides connectivity information that can be reliably combined with HSQC for deconvolution of metabolites [38].
Quantitation of metabolites by 2D NMR is also an active research area in NMR-based metabolomics [39]. There are multiple approaches that have been developed primarily by using 2D 13C-1H HSQC, these methods were reviewed recently [40]. The main drawback of 2D NMR experiments is the longer acquisition time; they can easily take half a day per sample. Faster experiments are promising to speed up the data acquisition by using new pulse sequences, non-uniform sampling (NUS), and parameter optimization [40]. Sensitivity is another major problem of heteronuclear 2D NMR experiments, and progress has been achieved by combining NMR with dynamic nuclear polarization (DNP) [41,42].
2.2. Identification of Known Metabolites with the Use of a Database for Matching
Targeted metabolite identification is typically performed by comparing 1D 1H NMR spectrum of a metabolite mixture with a 1D 1H NMR spectral database, followed by validation of these identifications on a subset of samples by 2D NMR methods, primarily 2D HSQC and TOCSY [43,44,45]. So far, the common way of validating metabolites by these experiments have been separate and independent querying of experimental HSQC and TOCSY data against HSQC and TOCSY metabolomics databases, respectively, without taking the complementary nature of these experiments into account. To resolve this disconnectivity issue, recently, an integrated metabolite identification and validation approach, COLMARm has been introduced.
COLMARm allows for the simultaneous analysis of 2D 13C–1H HSQC, 2D 1H–1H TOCSY, and 2D 13C–1H HSQC–TOCSY spectra of a metabolomics sample on a publicly available web server (http://spin.ccic.ohio-state.edu/index.php/colmarm/index). When the user uploads an HSQC and TOCSY-type spectra to the web server, the metabolite identification occurs at two steps. At first, the COLMARm web server queries the HSQC spectrum against COLMAR HSQC metabolomics database [46] and returns a list of candidate metabolite hits. Next, for each returned hit, the corresponding TOCSY and/or HSQC–TOCSY spectrum is generated from the COLMAR 1H-(13C) TOCCATA database [47,48] and is overlaid on the experimental TOCSY spectra [49]. Finally, depending on how well the TOCSY cross-peaks superimpose with the corresponding experimental peaks, the candidate metabolite is either manually confirmed or rejected (Figure 2). By using this strategy, the authors confidently identified 62 metabolites in human serum, 14 of these were identified in human serum for the first time by NMR, which would not be possible with high accuracy by using 1D 1H NMR or any other 2D NMR spectrum alone [49].
Although the NMR approaches are capable of identifying the majority of detectable metabolites in a given sample, they can fail in the discrimination of metabolites with very similar structures and chemical shifts, such as creatine versus creatine phosphate, or uridine diphosphate versus uridine triphosphate. Since often these types of metabolites possess different mass-to-charge (m/z) ratios, it should be possible to distinguish them by combining NMR and MS information. To accomplish this task, the NMR/MS Translator approach has been introduced [50]. The fully automated NMR/MS Translator approach first generates the metabolite candidates by querying experimental 1D or 2D NMR spectra of a sample against NMR metabolomics database. Then, for the returned candidates, it calculates the masses (m/z) of all their possible ions and adducts, together with their characteristic isotope distributions. Finally, it compares the expected m/z ratios with the experimental high resolution MS1 spectrum of the same sample for direct validation of the candidate metabolites that are identified by both NMR and MS [50]. The NMR/MS Translator approach has been applied to human urine, tomato extract, and Arabidopsis thaliana metabolome [51], by increasing the confidence of the identifications over the use of NMR or MS method alone.
3. Untargeted Metabolomics
Untargeted studies focus on measuring and comparing as many signals as possible across a sample set, followed by the assignment of these signal to metabolite ID’s by using metabolomics databases. Although excellent progress has been made in expanding metabolomics databases with new metabolites, a significant portion of signals detected in untargeted studies still cannot be identified through this approach due to the absence of their spectra in the databases. Untargeted studies are highly interested in the identification of unknown metabolites, especially when they are the biomarkers of a study.
Identification of unknowns is generally accepted as the bottleneck of untargeted metabolomics. Traditionally, their identification have been performed by extensive isolation of the molecule from extracts in sufficient amount for detailed analysis by MS, NMR, X-ray, circular dichroism, and other analytical techniques [52,53,54]. While this approach has been proven to be useful, complete fractionation is time-consuming. Moreover, a low yield of purification may not allow for the downstream structure elucidation process for low-abundance metabolites. Alternatively, structure elucidation can be performed in the mixture environment, such as in crude extract or the partially fractionated sample.
There are three main approaches that are proposed for unknown identification in mixtures; the first approach uses only mass spectrometry techniques. This approach compares the experimental fragmentation spectra of unknown metabolite with the predicted fragmentation of all the possible candidate isomeric structures to find the best match [55,56,57,58]. The second strategy, on the other hand, only relies on NMR, in which the experimental chemical shifts of unknown metabolites are sequentially assigned and deconvoluted by multidimensional NMR [59,60]. These assignments are further verified through comparison against their quantum NMR chemical shift predictions [61]. While these MS- and NMR-based approaches greatly facilitate the structural characterization, they have limited power, since they only rely on a single technique. Recently, several hybrid MS/NMR metabolite identification strategies have been proposed [62,63,64]. They were recently reviewed in detail [65].
One of the latest hybrid techniques, ISEL NMR/MS2 (Integrated Structure ELucidation by NMR/MS2) is a novel approach that combines in silico MS/MS and NMR predictions into a single analysis platform to improve the accuracy of automated unknown metabolite identification. In this approach, the unknown metabolites are first identified by determining their chemical formula from high resolution mass spectrometry coupled with liquid chromatography (LC–MS1). Next, all of the feasible candidate structures that are consisted with the chemical formula are generated by using a structure generator. MS/MS and NMR spectra of each candidate structures are predicted and compared with the experimental MS/MS and NMR spectra of the same sample, and finally ranked according to the level of agreement to determine the best matching candidate [66]. The authors first compared the performances of MS/MS and NMR predictions on a mixture of ten commonly known metabolites. Based on these comparisons, the NMR predictions turned out to be a more effective filter than MS/MS predictions. However, MS/MS predictions provided an orthogonal method that allowed for distinguishing between molecules that yield similar NMR chemical shifts. Thus, combining NMR and MS/MS predictions further improved the accuracy of unknown metabolite identification. As a real-world example, the authors applied the ISEL NMR/MS2 approach on the identification of an uncatalogued secondary metabolite in Arabidopsis thaliana extract, which allowed for the successful identification of glucoraphanin, a type of glucosinolate in Arabidopsis (Figure 3).
In the glucoraphanin example in Figure 3, which considered one unknown metabolite at a time, the NMR spectrum was paired with a single LC–MS feature by an off-line LC fractionation procedure. However, it is common in metabolomics to analyze complex mixtures that are consisting of multiple metabolites within unfractionated samples. In these cases, multiple LC–MS features and multiple deconvoluted NMR spectra are generated, without knowing which pairs correspond to the same metabolite. This increases the challenge of high-throughput metabolite identification in mixtures.
Fortunately, in cohort studies, MS and NMR features can be paired by statistical correlation. This has been recently shown in a systematic study of 26 metabolites over 200 samples. The authors showed that in a majority of cases, the highest correlated NMR and MS signals belong to the same metabolite [67]. Therefore, this approach can be utilized to inter-relate NMR and MS signals of unknowns in complex mixtures without the need for LC-fractionation.
Unfortunately for the analysis of a single sample, statistical correlation is not an option; in this case, the ISEL NMR/MS2 approach can still be applied. When multiple unknowns are present, the workflow is modified to consider all pairwise combinations; NMR predictions are generated for all of the structural isomers of each LC-MS feature (chemical formula), and they are all compared to every deconvoluted experimental NMR spectra of the mixture. Proof-of-principle was demonstrated on a ten-compound model mixture [66]. In 8 out of 10 cases, the rank orders of metabolite identifications did not increase from being the only metabolite in the NMR spectrum to being one of the ten metabolites in the mixture, which is a promising result for the identification of the real unknowns in mixtures.
While hybrid MS/NMR approaches are powerful, one of their limitation is the large sensitivity difference between NMR and MS instruments [68]. Dynamic nuclear polarization and small-volume NMR technologies are expected to continue to improve and close the sensitivity gap between NMR and MS for mass limited samples [69].
4. Conclusions
The metabolomics field is rapidly progressing, with strong applications in parallel with methodological advancements. Most of the recent advances in NMR and MS/NMR methods have been covered in this minireview with a specific emphasis on their contribution to targeted and untargeted metabolomics. Technologies for rapid, accurate, and automated identification, and quantitation have been improving in the last 18 months. We expect that this trend to continue. For targeted metabolomics, to further increase the automation, speed, and accuracy of absolute metabolite quantitation is critical. On the identification side, there are currently about a thousand metabolites that are present in the metabolite libraries of NMR software and web servers. This number is much smaller than the estimated several hundred thousand metabolites that are present in nature. Therefore, these libraries need to continue to expand by adding more metabolites, such as by purchasing and recording more authentic standards, by extracting data from literature, and by structure elucidation of novel metabolites, for which hybrid MS/NMR methods are clearly going to be powerful. Overall, these efforts will contribute to quantitative profiling of an ever-growing number of metabolites in application studies.
Acknowledgments
This work was performed under Proposal ID: 49679 (KB) with Early Career Laboratory Directed Research Development (LDRD) Program funding using Environmental Molecular Sciences Laboratory, a national scientific user facility sponsored by DOE’s Office of Biological and Environmental Research and located at PNNL. PNNL is operated by Battelle for the DOE under Contract DE-AC05-76RL01830.
Conflicts of Interest
The author declares no conflict of interest.
References
- Shendure, J.; Balasubramanian, S.; Church, G.M.; Gilbert, W.; Rogers, J.; Schloss, J.A.; Waterston, R.H. DNA sequencing at 40: Past, present and future. Nature 2017, 550, 345–353. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, S.; Seshadri, R.; Varghese, N.J.; Eloe-Fadrosh, E.A.; Meier-Kolthoff, J.P.; Goker, M.; Coates, R.C.; Hadjithomas, M.; Pavlopoulos, G.A.; Paez-Espino, D.; et al. 1003 reference genomes of bacterial and archaeal isolates expand coverage of the tree of life. Nat. Biotechnol. 2017, 35, 676–683. [Google Scholar] [CrossRef] [PubMed]
- Jansson, J.K.; Baker, E.S. A multi-omic future for microbiome studies. Nat. Microbiol. 2016, 1, 16049. [Google Scholar] [CrossRef] [PubMed]
- Zampieri, M.; Sauer, U. Metabolomics-driven understanding of genotype-phenotype relations in model organisms. Curr. Opin. Syst. Biol. 2017, 6, 28–36. [Google Scholar] [CrossRef]
- White III, R.A.; Rivas-Ubach, A.; Borkum, M.I.; Köberl, M.; Bilbao, A.; Colby, S.M.; Hoyt, D.W.; Bingol, K.; Kim, Y.-M.; Wendler, J.P. The state of rhizospheric science in the era of multi-omics: A practical guide to omics technologies. Rhizosphere 2017, 3, 212–221. [Google Scholar] [CrossRef]
- Rueedi, R.; Mallol, R.; Raffler, J.; Lamparter, D.; Friedrich, N.; Vollenweider, P.; Waeber, G.; Kastenmuller, G.; Kutalik, Z.; Bergmann, S. Metabomatching: Using genetic association to identify metabolites in proton NMR spectroscopy. PLoS Comput. Biol. 2017, 13, e1005839. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Tohge, T.; Cuadros-Inostroza, Á.; Tong, H.; Tenenboim, H.; Kooke, R.; Méret, M.; Keurentjes, J.B.; Nikoloski, Z.; Fernie, A.R. Mapping the Arabidopsis metabolic landscape by untargeted metabolomics at different environmental conditions. Mol. Plant 2018, 11, 118–134. [Google Scholar] [CrossRef] [PubMed]
- Fernandez, O.; Urrutia, M.; Bernillon, S.; Giauffret, C.; Tardieu, F.; Le Gouis, J.; Langlade, N.; Charcosset, A.; Moing, A.; Gibon, Y. Fortune telling: Metabolic markers of plant performance. Metabolomics 2016, 12, 158. [Google Scholar] [CrossRef] [PubMed]
- Geng, S.; Misra, B.B.; Armas, E.; Huhman, D.V.; Alborn, H.T.; Sumner, L.W.; Chen, S. Jasmonate-mediated stomatal closure under elevated CO2 revealed by time-resolved metabolomics. Plant J. 2016, 88, 947–962. [Google Scholar] [CrossRef] [PubMed]
- Kikuchi, J.; Ito, K.; Date, Y. Environmental metabolomics with data science for investigating ecosystem homeostasis. Prog. Nucl. Magn. Reson. Spectrosc. 2018, 104, 56–88. [Google Scholar] [CrossRef] [PubMed]
- Ussher, J.R.; Elmariah, S.; Gerszten, R.E.; Dyck, J.R. The emerging role of metabolomics in the diagnosis and prognosis of cardiovascular disease. J. Am. Coll. Cardiol. 2016, 68, 2850–2870. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Perez, I.; Posma, J.M.; Gibson, R.; Chambers, E.S.; Hansen, T.H.; Vestergaard, H.; Hansen, T.; Beckmann, M.; Pedersen, O.; Elliott, P. Objective assessment of dietary patterns by use of metabolic phenotyping: A randomised, controlled, crossover trial. Lancet Diabetes Endocrinol. 2017, 5, 184–195. [Google Scholar] [CrossRef]
- Everett, J.R. NMR-based pharmacometabonomics: A new paradigm for personalised or precision medicine. Prog. Nucl. Magn. Reson. Spectrosc. 2017, 102, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Lane, A.N.; Fan, T.W. NMR-based stable isotope resolved metabolomics in systems biochemistry. Arch. Biochem. Biophys. 2017, 628, 123–131. [Google Scholar] [CrossRef] [PubMed]
- Vinaixa, M.; Rodríguez, M.A.; Aivio, S.; Capellades, J.; Gómez, J.; Canyellas, N.; Stracker, T.H.; Yanes, O. Positional enrichment by proton analysis (PEPA): A one-dimensional 1H-NMR approach for 13C stable isotope tracer studies in metabolomics. Angew. Chem. Int. Ed. 2017, 56, 3531–3535. [Google Scholar] [CrossRef] [PubMed]
- Pandey, R.; Caflisch, L.; Lodi, A.; Brenner, A.J.; Tiziani, S. Metabolomic signature of brain cancer. Mol. Carcinog. 2017, 56, 2355–2371. [Google Scholar] [CrossRef] [PubMed]
- Markley, J.L.; Brüschweiler, R.; Edison, A.S.; Eghbalnia, H.R.; Powers, R.; Raftery, D.; Wishart, D.S. The future of NMR-based metabolomics. Curr. Opin. Biotechnol. 2017, 43, 34–40. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Su, X.; Klein, M.S.; Lewis, I.A.; Fiehn, O.; Rabinowitz, J.D. Metabolite measurement: Pitfalls to avoid and practices to follow. Annu. Rev. Biochem. 2017, 86, 277–304. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Brüschweiler, R. Multidimensional approaches to NMR-based metabolomics. Anal. Chem. 2013, 86, 47–57. [Google Scholar] [CrossRef] [PubMed]
- Nagana Gowda, G.; Raftery, D. Recent advances in NMR-based metabolomics. Anal. Chem. 2016, 89, 490–510. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Brüschweiler, R. Two elephants in the room: New hybrid nuclear magnetic resonance and mass spectrometry approaches for metabolomics. Curr. Opin. Clin. Nutr. Metab. Care 2015, 18, 471–477. [Google Scholar] [CrossRef] [PubMed]
- Marshall, D.D.; Powers, R. Beyond the paradigm: Combining mass spectrometry and nuclear magnetic resonance for metabolomics. Prog. Nucl. Magn. Reson. Spectrosc. 2017, 100, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Weljie, A.M.; Newton, J.; Mercier, P.; Carlson, E.; Slupsky, C.M. Targeted profiling: Quantitative analysis of 1H NMR metabolomics data. Anal. Chem. 2006, 78, 4430–4442. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Wishart, D.S. Using metaboanalyst 3.0 for comprehensive metabolomics data analysis. Curr. Protoc. Bioinform. 2016, 55, 14.10.1–14.10.91. [Google Scholar] [CrossRef]
- Date, Y.; Kikuchi, J. Application of a deep neural network to metabolomics studies and its performance in determining important variables. Anal. Chem. 2018, 90, 1805–1810. [Google Scholar] [CrossRef] [PubMed]
- Takis, P.G.; Schäfer, H.; Spraul, M.; Luchinat, C. Deconvoluting interrelationships between concentrations and chemical shifts in urine provides a powerful analysis tool. Nat. Commun. 2017, 8, 1662. [Google Scholar] [CrossRef] [PubMed]
- Nagana Gowda, G.; Raftery, D. Whole blood metabolomics by 1H NMR spectroscopy provides a new opportunity to evaluate coenzymes and antioxidants. Anal. Chem. 2017, 89, 4620–4627. [Google Scholar] [CrossRef] [PubMed]
- Daly, R.A.; Borton, M.A.; Wilkins, M.J.; Hoyt, D.W.; Kountz, D.J.; Wolfe, R.A.; Welch, S.A.; Marcus, D.N.; Trexler, R.V.; MacRae, J.D. Microbial metabolisms in a 2.5-km-deep ecosystem created by hydraulic fracturing in shales. Nat. Microbiol. 2016, 1, 16146. [Google Scholar] [CrossRef] [PubMed]
- Hao, J.; Liebeke, M.; Astle, W.; De Iorio, M.; Bundy, J.G.; Ebbels, T.M. Bayesian deconvolution and quantification of metabolites in complex 1D NMR spectra using batman. Nat. Protoc. 2014, 9, 1416–1427. [Google Scholar] [CrossRef] [PubMed]
- Ravanbakhsh, S.; Liu, P.; Bjordahl, T.C.; Mandal, R.; Grant, J.R.; Wilson, M.; Eisner, R.; Sinelnikov, I.; Hu, X.; Luchinat, C.; et al. Accurate, fully-automated NMR spectral profiling for metabolomics. PLoS ONE 2015, 10, e0124219. [Google Scholar] [CrossRef] [PubMed]
- Tardivel, P.J.; Canlet, C.; Lefort, G.; Tremblay-Franco, M.; Debrauwer, L.; Concordet, D.; Servien, R. Asics: An automatic method for identification and quantification of metabolites in complex 1D 1H NMR spectra. Metabolomics 2017, 13, 109. [Google Scholar] [CrossRef]
- Cañueto, D.; Gómez, J.; Salek, R.M.; Correig, X.; Cañellas, N. Rdolphin: A GUI R package for proficient automatic profiling of 1D 1H-NMR spectra of study datasets. Metabolomics 2018, 14, 24. [Google Scholar] [CrossRef]
- Röhnisch, H.E.; Eriksson, J.; Müllner, E.; Agback, P.; Sandström, C.; Moazzami, A.A. AQuA—An automated quantification algorithm for high-throughput NMR-based metabolomics and its application in human plasma. Anal. Chem. 2018, 90, 2095–2102. [Google Scholar] [CrossRef] [PubMed]
- Barrilero, R.; Gil, M.; Amigó, N.; Dias, C.B.; Wood, L.G.; Garg, M.L.; Ribalta, J.; Heras, M.; Vinaixa, M.; Correig, X. Lipspin: A new bioinformatics tool for quantitative 1H-NMR lipid profiling. Anal. Chem. 2018, 90, 2031–2040. [Google Scholar] [CrossRef] [PubMed]
- Mediani, A.; Khatib, A.; Ismail, A.; Hamid, M.; Lajis, N.H.; Shaari, K.; Abas, F. Application of BATMAN and BAYESIL for quantitative 1H-NMR based metabolomics of urine: Discriminant analysis of lean, obese and obese-diabetic rats. Metabolomics 2017, 13, 131. [Google Scholar] [CrossRef]
- Zangger, K. Pure shift NMR. Prog. Nucl. Magn. Reson. Spectrosc. 2015, 86, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Moutzouri, P.; Chen, Y.; Foroozandeh, M.; Kiraly, P.; Phillips, A.R.; Coombes, S.R.; Nilsson, M.; Morris, G.A. Ultraclean pure shift NMR. Chem. Commun. 2017, 53, 10188–10191. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Brüschweiler, R. Deconvolution of chemical mixtures with high complexity by NMR consensus trace clustering. Anal. Chem. 2011, 83, 7412–7417. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Zhang, F.; Bruschweiler-Li, L.; Brüschweiler, R. Quantitative analysis of metabolic mixtures by two-dimensional 13C constant-time TOCSY NMR spectroscopy. Anal. Chem. 2013, 85, 6414–6420. [Google Scholar] [CrossRef] [PubMed]
- Marchand, J.; Martineau, E.; Guitton, Y.; Dervilly-Pinel, G.; Giraudeau, P. Multidimensional NMR approaches towards highly resolved, sensitive and high-throughput quantitative metabolomics. Curr. Opin. Biotechnol. 2017, 43, 49–55. [Google Scholar] [CrossRef] [PubMed]
- Bornet, A.L.; Maucourt, M.L.; Deborde, C.; Jacob, D.; Milani, J.; Vuichoud, B.; Ji, X.; Dumez, J.-N.; Moing, A.; Bodenhausen, G. Highly repeatable dissolution dynamic nuclear polarization for heteronuclear NMR metabolomics. Anal. Chem. 2016, 88, 6179–6183. [Google Scholar] [CrossRef] [PubMed]
- Lerche, M.H.; Yigit, D.; Frahm, A.B.; Ardenkjær-Larsen, J.H.; Malinowski, R.M.; Jensen, P.R. Stable isotope-resolved analysis with quantitative dissolution dynamic nuclear polarization. Anal. Chem. 2017, 90, 674–678. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.K.; Kostidis, S.; Choi, Y.H. NMR analysis of fecal samples. Clin. Metab. 2018, 317–328. [Google Scholar] [CrossRef]
- Johns, C.W.; Lee, A.B.; Springer, T.I.; Rosskopf, E.N.; Hong, J.C.; Turechek, W.; Kokalis-Burelle, N.; Finley, N.L. Using NMR-based metabolomics to monitor the biochemical composition of agricultural soils: A pilot study. Eur. J. Soil Biol. 2017, 83, 98–105. [Google Scholar] [CrossRef]
- Rådjursöga, M.; Karlsson, G.B.; Lindqvist, H.M.; Pedersen, A.; Persson, C.; Pinto, R.C.; Ellegård, L.; Winkvist, A. Metabolic profiles from two different breakfast meals characterized by 1H NMR-based metabolomics. Food Chem. 2017, 231, 267–274. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Li, D.W.; Bruschweiler-Li, L.; Cabrera, O.A.; Megraw, T.; Zhang, F.; Brüschweiler, R. Unified and isomer-specific NMR metabolomics database for the accurate analysis of 13C–1H HSQC spectra. ACS Chem. Biol. 2014, 10, 452–459. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Zhang, F.; Bruschweiler-Li, L.; Brüschweiler, R. TOCCATA: A customized carbon total correlation spectroscopy NMR metabolomics database. Anal. Chem. 2012, 84, 9395–9401. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Bruschweiler-Li, L.; Li, D.-W.; Brüschweiler, R. Customized metabolomics database for the analysis of NMR 1H–1H TOCSY and 13C–1H HSQC-TOCSY spectra of complex mixtures. Anal. Chem. 2014, 86, 5494–5501. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Li, D.-W.; Zhang, B.; Brüschweiler, R. Comprehensive metabolite identification strategy using multiple two-dimensional NMR spectra of a complex mixture implemented in the COLMARm web server. Anal. Chem. 2016, 88, 12411–12418. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Brüschweiler, R. NMR/MS translator for the enhanced simultaneous analysis of metabolomics mixtures by NMR spectroscopy and mass spectrometry: Application to human urine. J. Proteome Res. 2015, 14, 2642–2648. [Google Scholar] [CrossRef] [PubMed]
- Walker, L.R.; Hoyt, D.W.; Walker, S.M.; Ward, J.K.; Nicora, C.D.; Bingol, K. Unambiguous metabolite identification in high-throughput metabolomics by hybrid 1D 1H NMR/ESI MS1 approach. Magn. Reson. Chem. 2016, 54, 998–1003. [Google Scholar] [CrossRef] [PubMed]
- Molinski, T.F. Microscale methodology for structure elucidation of natural products. Curr. Opin. Biotechnol. 2010, 21, 819–826. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Bruschweiler-Li, L.; Li, D.; Zhang, B.; Xie, M.; Brüschweiler, R. Emerging new strategies for successful metabolite identification in metabolomics. Bioanalysis 2016, 8, 557–573. [Google Scholar] [CrossRef] [PubMed]
- Allard, P.-M.; Genta-Jouve, G.; Wolfender, J.-L. Deep metabolome annotation in natural products research: Towards a virtuous cycle in metabolite identification. Curr. Opin. Chem. Biol. 2017, 36, 40–49. [Google Scholar] [CrossRef] [PubMed]
- Ruttkies, C.; Schymanski, E.L.; Wolf, S.; Hollender, J.; Neumann, S. MetFrag relaunched: Incorporating strategies beyond in silico fragmentation. J. Cheminform. 2016, 8, 3. [Google Scholar] [CrossRef] [PubMed]
- Schymanski, E.L.; Ruttkies, C.; Krauss, M.; Brouard, C.; Kind, T.; Dührkop, K.; Allen, F.; Vaniya, A.; Verdegem, D.; Böcker, S. Critical assessment of small molecule identification 2016: Automated methods. J. Cheminform. 2017, 9, 22. [Google Scholar] [CrossRef] [PubMed]
- Guijas, C.; Montenegro-Burke, J.R.; Domingo-Almenara, X.; Palermo, A.; Warth, B.; Hermann, G.; Koellensperger, G.; Huan, T.; Uritboonthai, W.; Aisporna, A.E.; et al. METLIN: A technology platform for identifying knowns and unknowns. Anal. Chem. 2018, 90, 3156–3164. [Google Scholar] [CrossRef] [PubMed]
- Lai, Z.; Tsugawa, H.; Wohlgemuth, G.; Mehta, S.; Mueller, M.; Zheng, Y.; Ogiwara, A.; Meissen, J.; Showalter, M.; Takeuchi, K.; et al. Identifying metabolites by integrating metabolome databases with mass spectrometry cheminformatics. Nat. Methods 2018, 15, 53. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Zhang, F.; Bruschweiler-Li, L.; Brüschweiler, R. Carbon backbone topology of the metabolome of a cell. J. Am. Chem. Soc. 2012, 134, 9006–9011. [Google Scholar] [CrossRef] [PubMed]
- Clendinen, C.S.; Pasquel, C.; Ajredini, R.; Edison, A.S. 13C NMR metabolomics: Inadequate network analysis. Anal. Chem. 2015, 87, 5698–5706. [Google Scholar] [CrossRef] [PubMed]
- Komatsu, T.; Ohishi, R.; Shino, A.; Kikuchi, J. Structure and metabolic-flow analysis of molecular complexity in a 13C-labeled tree by 2D and 3D NMR. Angew. Chem. 2016, 128, 6104–6107. [Google Scholar] [CrossRef]
- Bingol, K.; Bruschweiler-Li, L.; Yu, C.; Somogyi, A.; Zhang, F.; Brüschweiler, R. Metabolomics beyond spectroscopic databases: A combined MS/NMR strategy for the rapid identification of new metabolites in complex mixtures. Anal. Chem. 2015, 87, 3864–3870. [Google Scholar] [CrossRef] [PubMed]
- Clendinen, C.S.; Stupp, G.S.; Wang, B.; Garrett, T.J.; Edison, A.S. 13C metabolomics: NMR and IROA for unknown identification. Curr. Metab. 2016, 4, 116–120. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; He, L.; Li, D.-W.; Bruschweiler-Li, L.; Marshall, A.G.; Brüschweiler, R. Accurate identification of unknown and known metabolic mixture components by combining 3D NMR with fourier transform ion cyclotron resonance tandem mass spectrometry. J. Proteome Res. 2017, 16, 3774–3786. [Google Scholar] [CrossRef] [PubMed]
- Bingol, K.; Brüschweiler, R. Knowns and unknowns in metabolomics identified by multidimensional NMR and hybrid MS/NMR methods. Curr. Opin. Biotechnol. 2017, 43, 17–24. [Google Scholar] [CrossRef] [PubMed]
- Boiteau, R.M.; Hoyt, D.W.; Nicora, C.D.; Kinmonth-Schultz, H.A.; Ward, J.K.; Bingol, K. Structure elucidation of unknown metabolites in metabolomics by combined NMR and MS/MS prediction. Metabolites 2018, 8. [Google Scholar] [CrossRef] [PubMed]
- Hao, J.; Liebeke, M.; Sommer, U.; Viant, M.R.; Bundy, J.G.; Ebbels, T.M. Statistical correlations between NMR spectroscopy and direct infusion FT-ICR mass spectrometry aid annotation of unknowns in metabolomics. Anal. Chem. 2016, 88, 2583–2589. [Google Scholar] [CrossRef] [PubMed]
- Gowda, G.N.; Djukovic, D.; Bettcher, L.F.; Gu, H.; Raftery, D. NMR-guided mass spectrometry for absolute quantitation of human blood metabolites. Anal. Chem. 2018, 90, 2001–2009. [Google Scholar] [CrossRef] [PubMed]
- Ardenkjaer-Larsen, J.H.; Boebinger, G.S.; Comment, A.; Duckett, S.; Edison, A.S.; Engelke, F.; Griesinger, C.; Griffin, R.G.; Hilty, C.; Maeda, H. Facing and overcoming sensitivity challenges in biomolecular NMR spectroscopy. Angew. Chem. Int. Ed. 2015, 54, 9162–9185. [Google Scholar] [CrossRef] [PubMed]
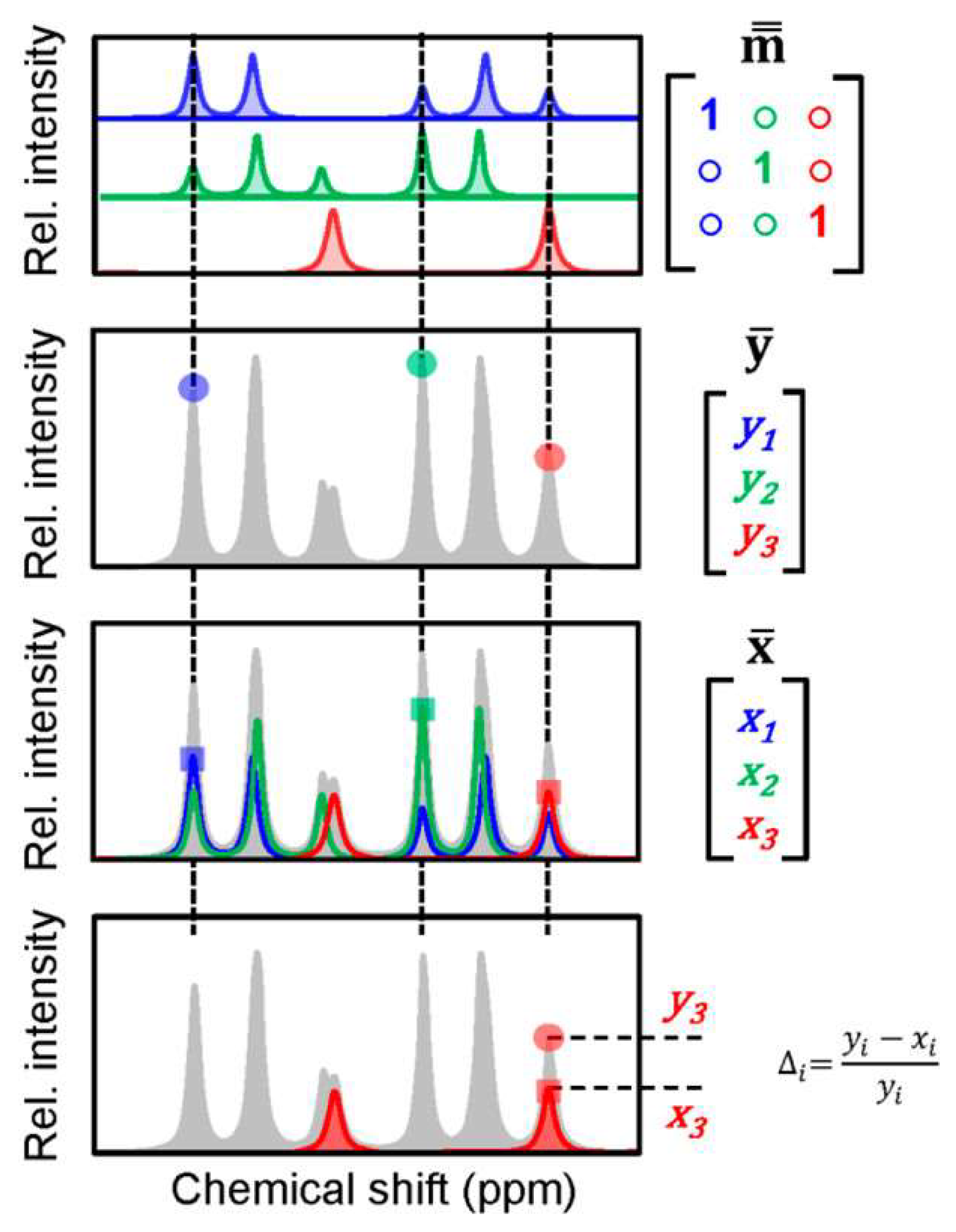
Figure 1.
Demonstration of the Automated Quantification Algorithm (AQuA) on a hypothetical mixture of three metabolites. AQuA first applies a data reduction step to predetermine a specific signal for the quantitation of each metabolite in the mixture. Then by using a calibration spectrum for each metabolite from a library, it establishes the signal height vs. concentration relations for the selected target peaks. Finally, by using this information in the application study, AQuA determined the concentration of 67 metabolites in more than a thousand human plasma samples in less than a second, which is much faster than the previously developed quantitation approaches that were relying on all of the data points for the curve-fitting based quantitation. Adapted with permission from reference [33]. Copyright 2018 American Chemical Society. ppm: parts per million.
Figure 1.
Demonstration of the Automated Quantification Algorithm (AQuA) on a hypothetical mixture of three metabolites. AQuA first applies a data reduction step to predetermine a specific signal for the quantitation of each metabolite in the mixture. Then by using a calibration spectrum for each metabolite from a library, it establishes the signal height vs. concentration relations for the selected target peaks. Finally, by using this information in the application study, AQuA determined the concentration of 67 metabolites in more than a thousand human plasma samples in less than a second, which is much faster than the previously developed quantitation approaches that were relying on all of the data points for the curve-fitting based quantitation. Adapted with permission from reference [33]. Copyright 2018 American Chemical Society. ppm: parts per million.

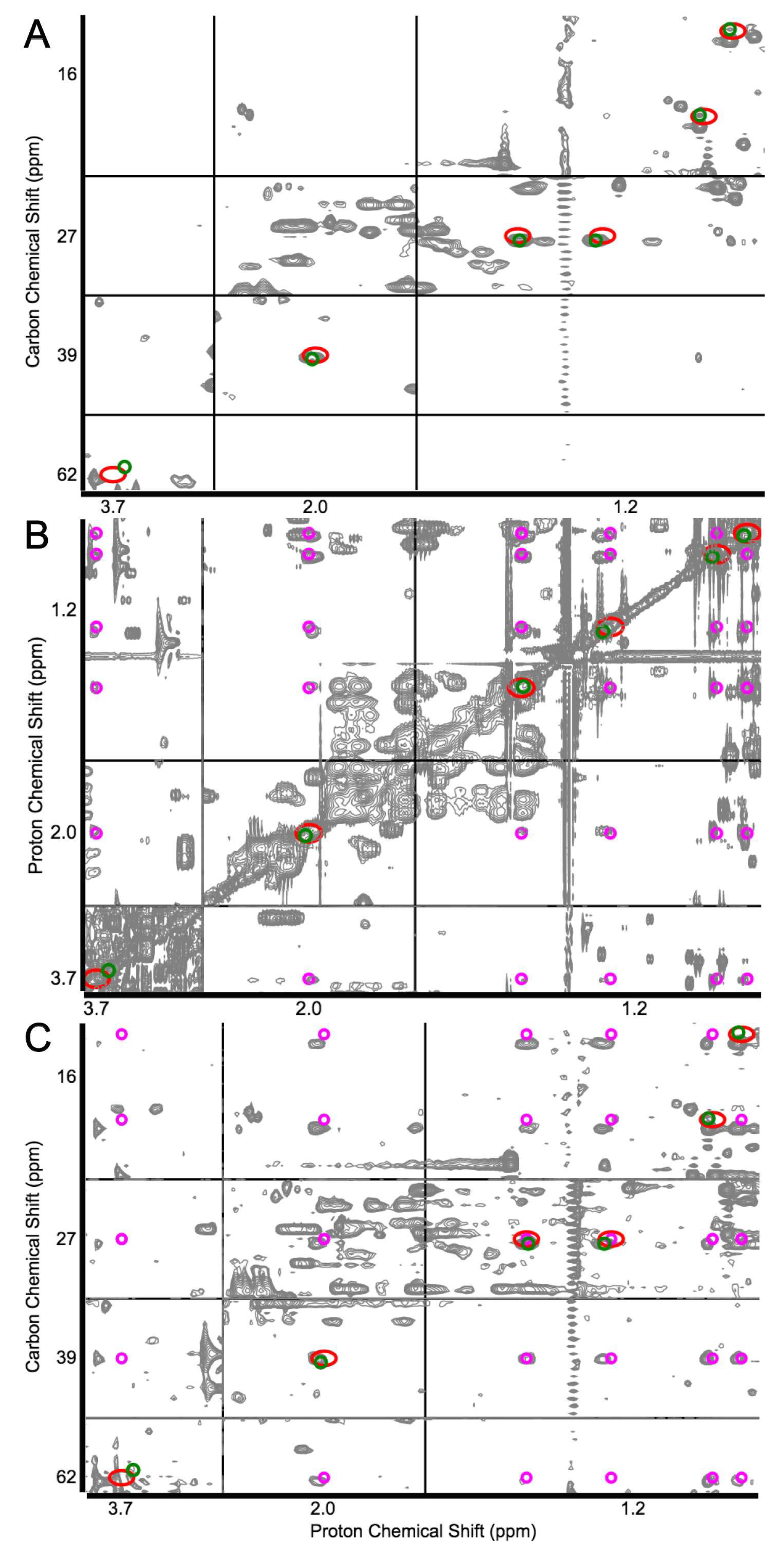
Figure 2.
Demonstration of COLMARm web server with the identification of isoleucine in human serum by the coanalysis of (A) heteronuclear single quantum coherence (HSQC), (B) total correlation spectroscopy (TOCSY), and (C) HSQC–TOCSY. Green and red circles show experimental and database cross-peaks of isoleucine, respectively. Magenta circles indicate the expected isoleucine peaks from the TOCCATA database. The close agreement between green and red circles returned isoleucine as a strong candidate. This was validated by the close match between magenta peaks with the experimental TOCSY cross-peaks observed in the TOCSY and HSQC–TOCSY spectra. Adapted with permission from reference [49]. Copyright 2016 American Chemical Society.
Figure 2.
Demonstration of COLMARm web server with the identification of isoleucine in human serum by the coanalysis of (A) heteronuclear single quantum coherence (HSQC), (B) total correlation spectroscopy (TOCSY), and (C) HSQC–TOCSY. Green and red circles show experimental and database cross-peaks of isoleucine, respectively. Magenta circles indicate the expected isoleucine peaks from the TOCCATA database. The close agreement between green and red circles returned isoleucine as a strong candidate. This was validated by the close match between magenta peaks with the experimental TOCSY cross-peaks observed in the TOCSY and HSQC–TOCSY spectra. Adapted with permission from reference [49]. Copyright 2016 American Chemical Society.

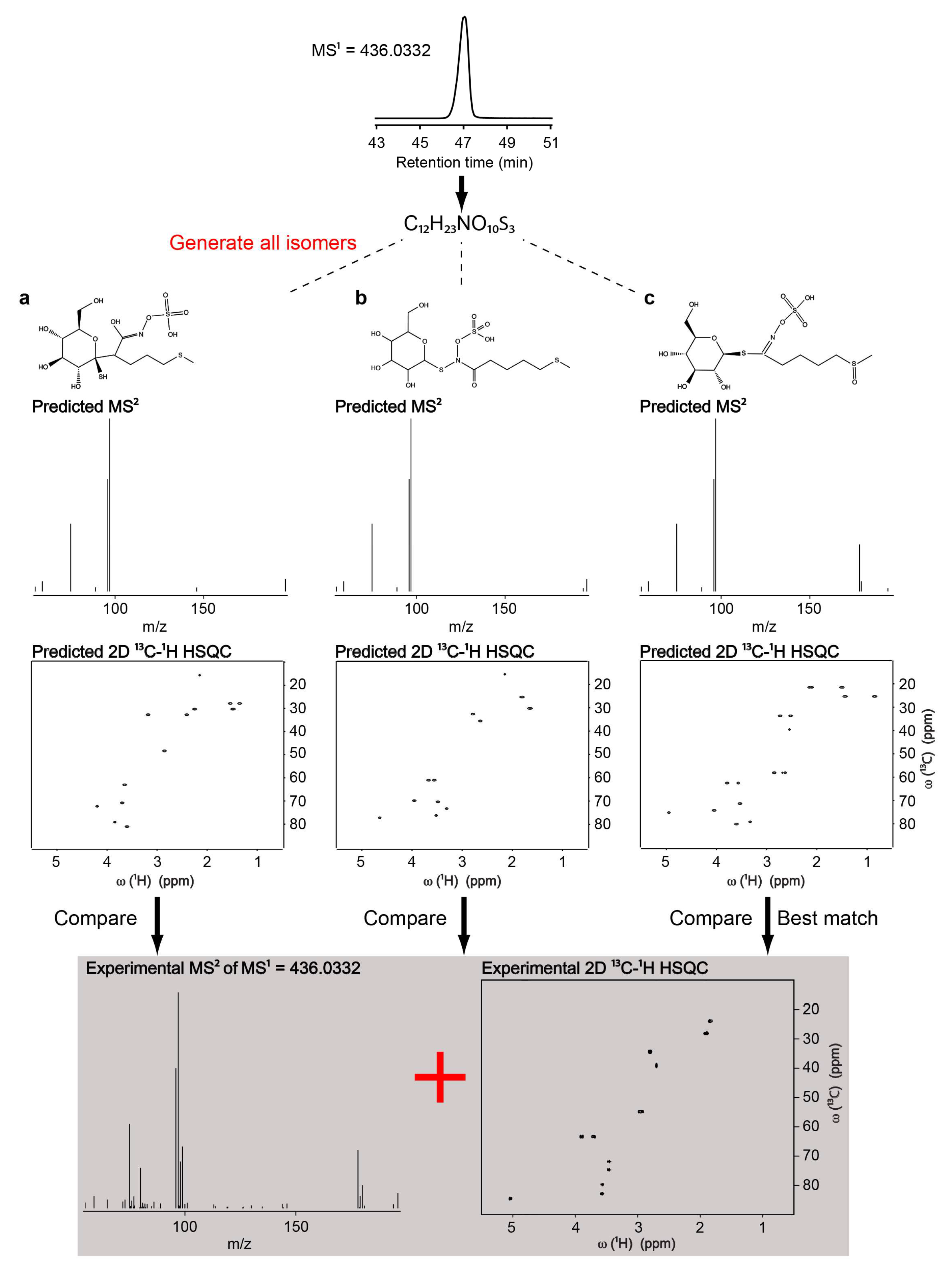
Figure 3.
Illustration of the workflow of the Integrated Structure Elucidation (ISEL) NMR/MS2 approach on identification of glucoraphanin in Arabidopsis extract. Chemical formula of the unknown metabolite was first determined from high resolution LC-MS1 spectrum. Next, all of the feasible candidate structures consisted with the chemical formula were generated. MS/MS and NMR spectra of each candidate structures were predicted and compared with the experimental MS/MS and NMR spectra of the same sample and ranked according to the level of agreement to determine the best matching candidate. Adapted from reference [66].
Figure 3.
Illustration of the workflow of the Integrated Structure Elucidation (ISEL) NMR/MS2 approach on identification of glucoraphanin in Arabidopsis extract. Chemical formula of the unknown metabolite was first determined from high resolution LC-MS1 spectrum. Next, all of the feasible candidate structures consisted with the chemical formula were generated. MS/MS and NMR spectra of each candidate structures were predicted and compared with the experimental MS/MS and NMR spectra of the same sample and ranked according to the level of agreement to determine the best matching candidate. Adapted from reference [66].

© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bingol, K. Recent Advances in Targeted and Untargeted Metabolomics by NMR and MS/NMR Methods. High-Throughput 2018, 7, 9. https://doi.org/10.3390/ht7020009
AMA Style
Bingol K. Recent Advances in Targeted and Untargeted Metabolomics by NMR and MS/NMR Methods. High-Throughput. 2018; 7(2):9. https://doi.org/10.3390/ht7020009
Chicago/Turabian StyleBingol, Kerem. 2018. "Recent Advances in Targeted and Untargeted Metabolomics by NMR and MS/NMR Methods" High-Throughput 7, no. 2: 9. https://doi.org/10.3390/ht7020009
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.