



Big Data Cogn. Comput. 2024, 8(6), 52; https://doi.org/10.3390/bdcc8060052 - 23 May 2024
Abstract
Due to the projected increase in food production by 70% in 2050, crops should be additionally protected from diseases and pests to ensure a sufficient food supply. Transfer deep learning approaches provide a more efficient solution than traditional methods, which are labor-intensive and
[...] Read more.
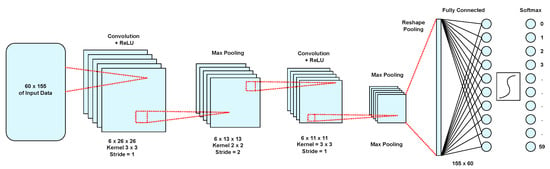
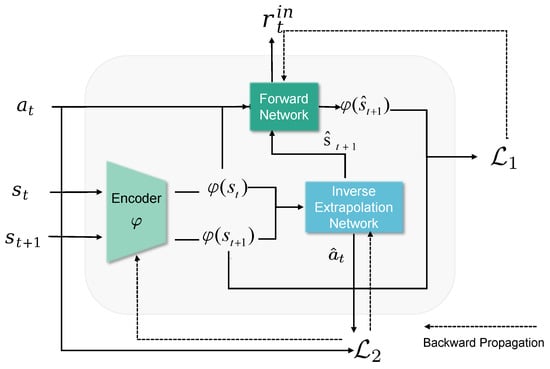
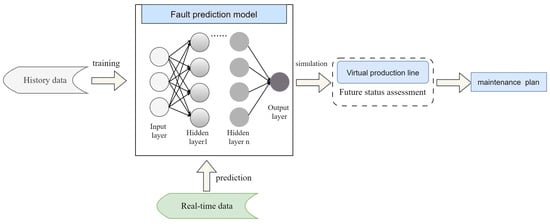
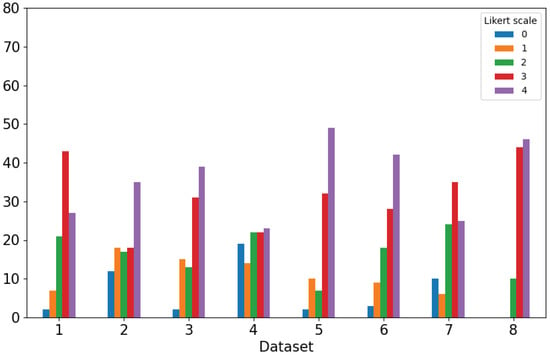
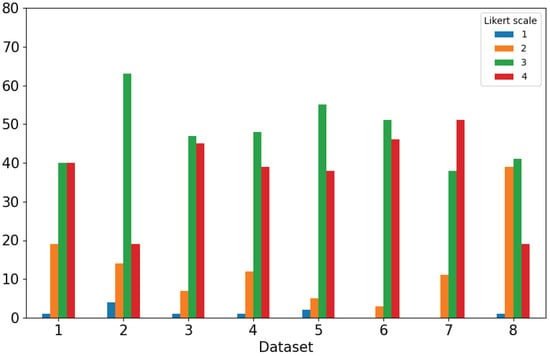
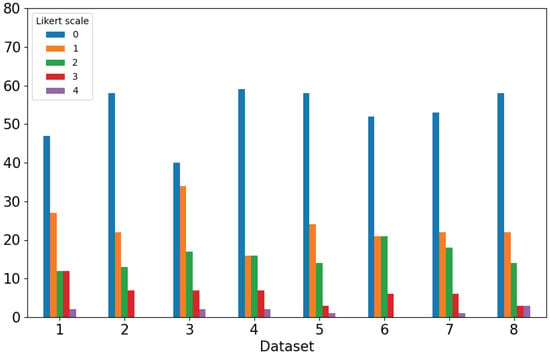
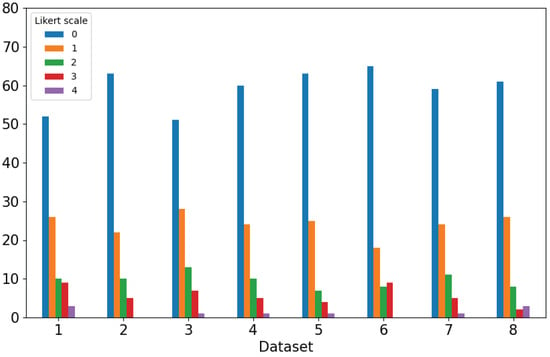
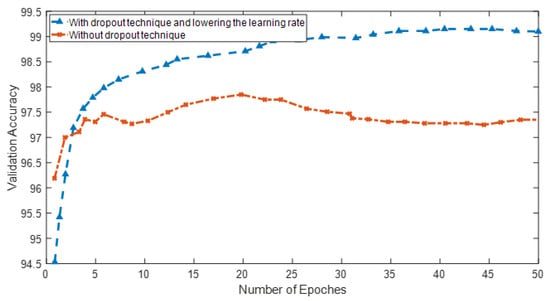
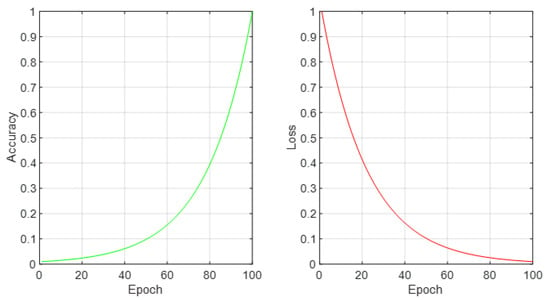
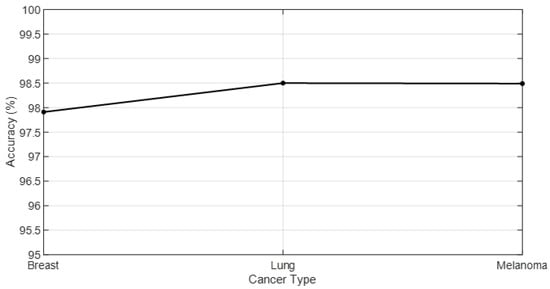
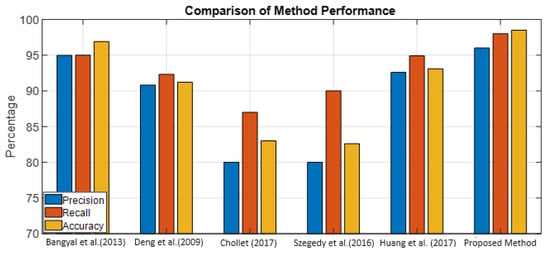
Due to the projected increase in food production by 70% in 2050, crops should be additionally protected from diseases and pests to ensure a sufficient food supply. Transfer deep learning approaches provide a more efficient solution than traditional methods, which are labor-intensive and struggle to effectively monitor large areas, leading to delayed disease detection. This study proposed a versatile module based on the Inception module, Mish activation function, and Batch normalization (IncMB) as a part of deep neural networks. A convolutional neural network (CNN) with transfer learning was used as the base for evaluated approaches for tomato disease detection: (1) CNNs, (2) CNNs with a support vector machine (SVM), and (3) CNNs with the proposed IncMB module. In the experiment, the public dataset PlantVillage was used, containing images of six different tomato leaf diseases. The best results were achieved by the pre-trained InceptionV3 network, which contains an IncMB module with an accuracy of 97.78%. In three out of four cases, the highest accuracy was achieved by networks containing the proposed IncMB module in comparison to evaluated CNNs. The proposed IncMB module represented an improvement in the early detection of plant diseases, providing a basis for timely leaf disease detection.
Full article
(This article belongs to the Topic Big Data and Artificial Intelligence, 2nd Volume)
►
Show Figures

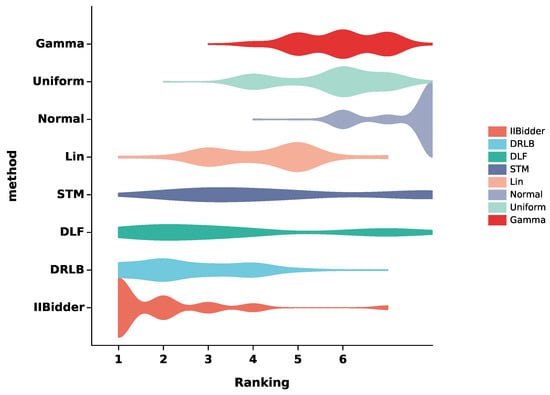
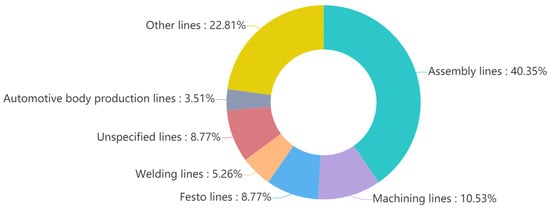
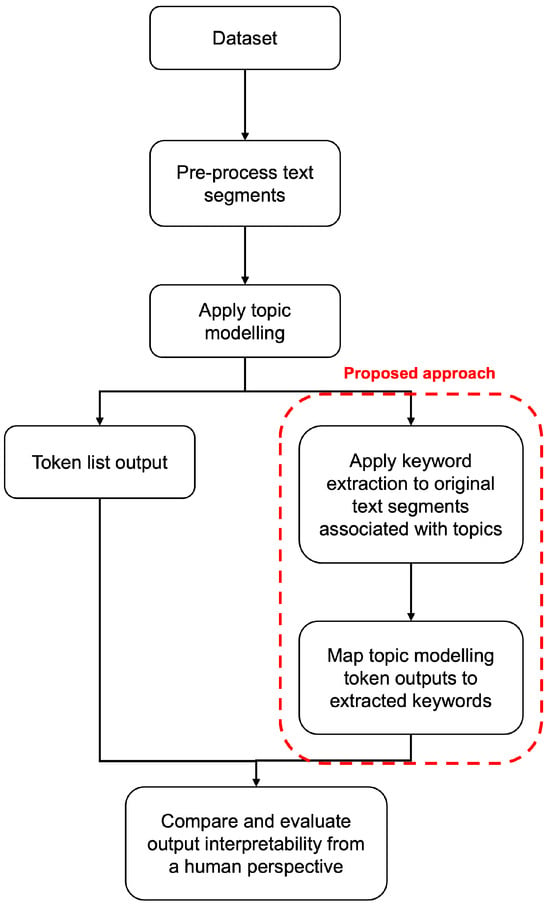
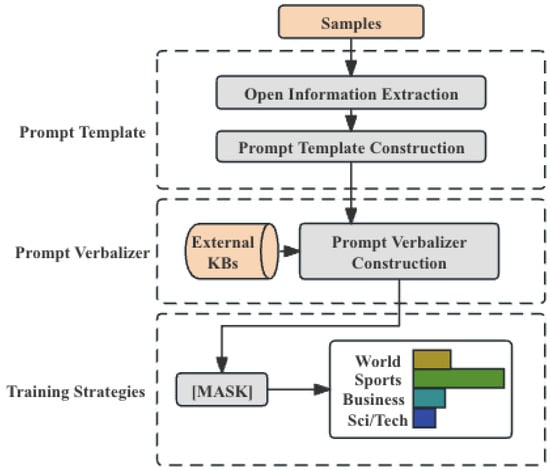
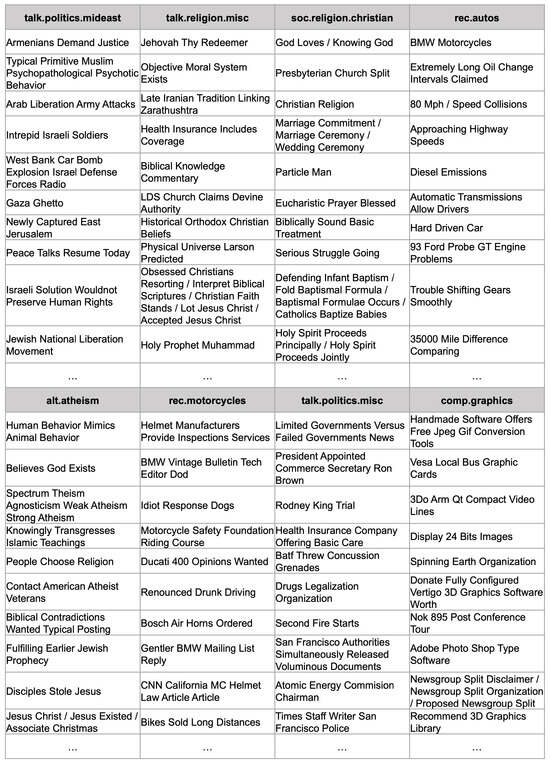
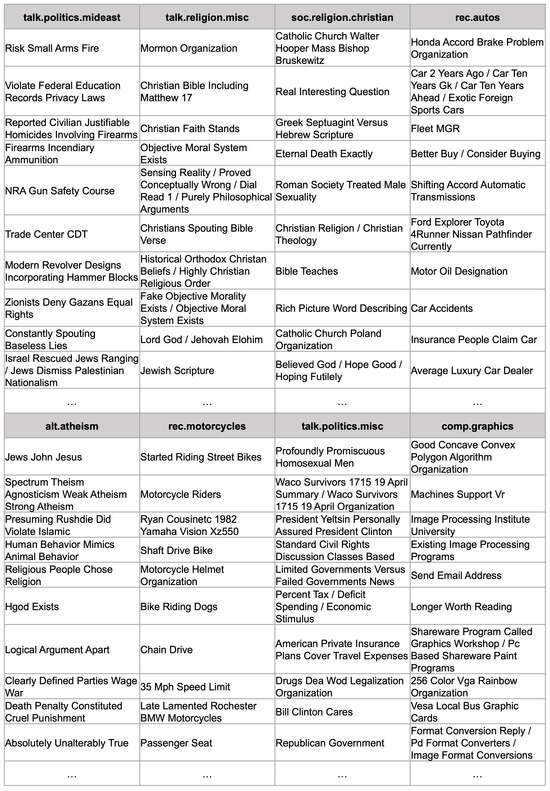
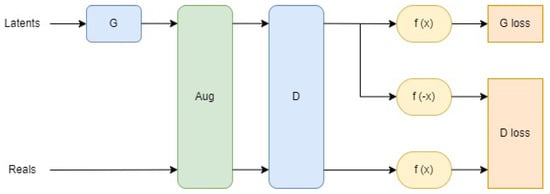
Figure 1









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}