


Econometrics 2024, 12(2), 15; https://doi.org/10.3390/econometrics12020015 - 31 May 2024
Abstract
►
Show Figures
This paper introduces a new modelling approach that incorporates nonlinear, exponential deterministic terms into a fractional integration framework. The proposed model is based on a specific test on fractional integration that is more general than the standard methods, which allow for only linear
[...] Read more.
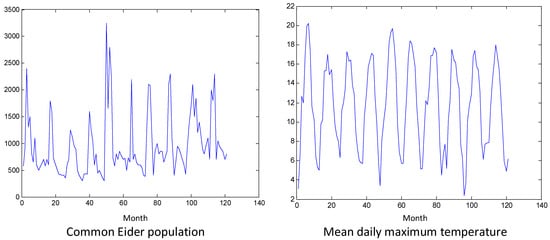
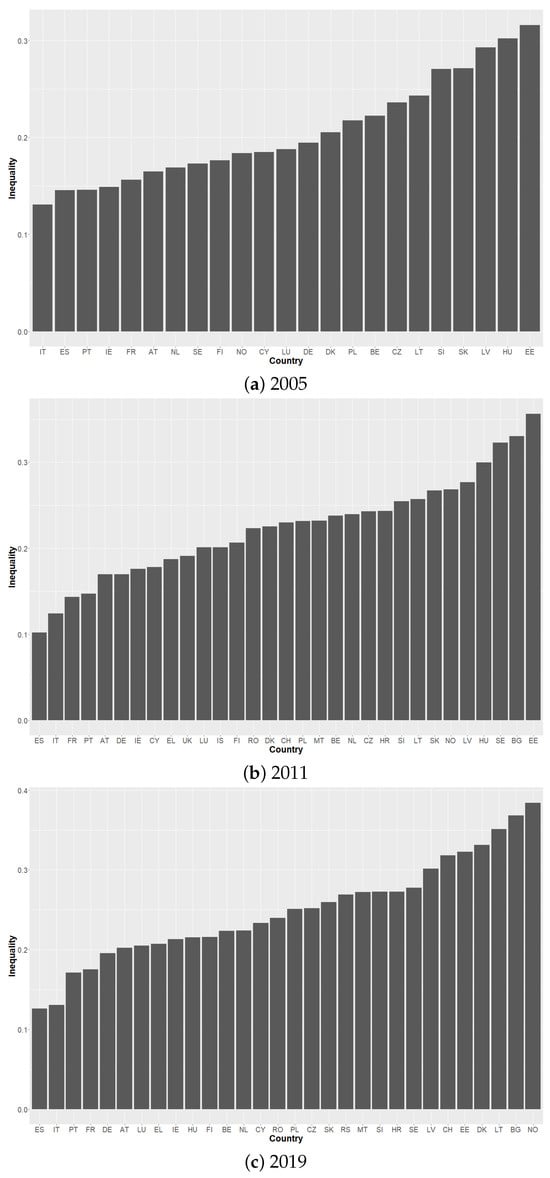
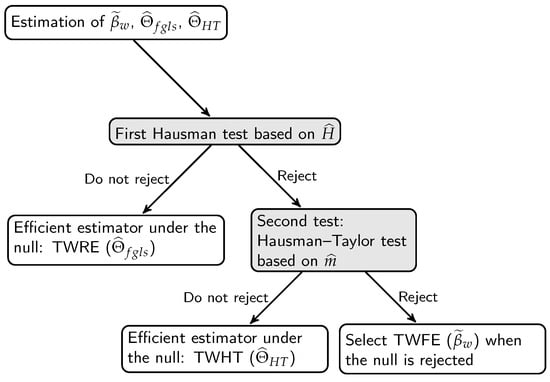
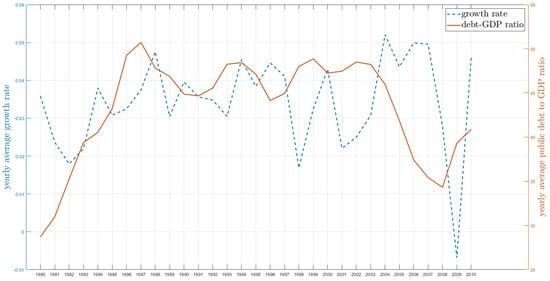
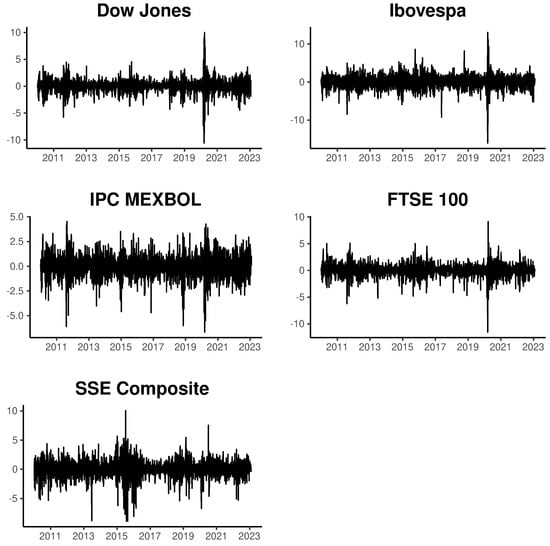
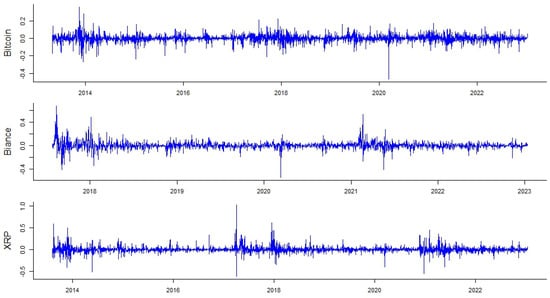
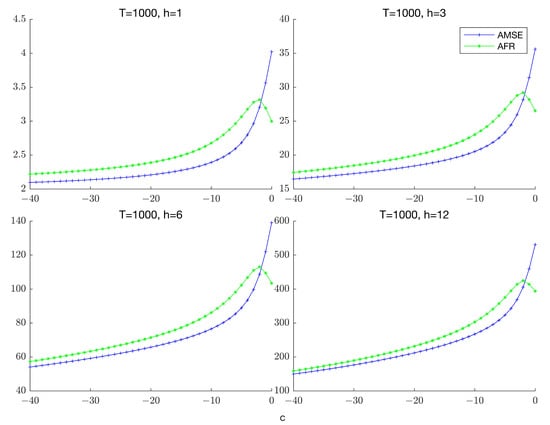
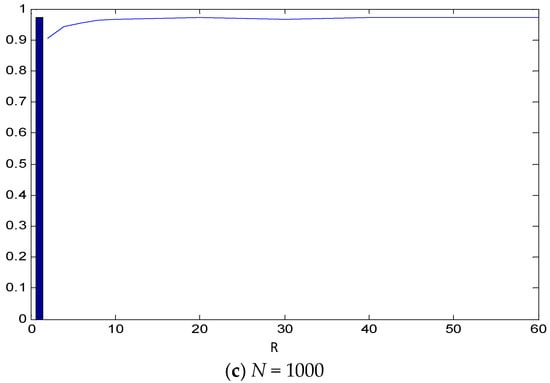
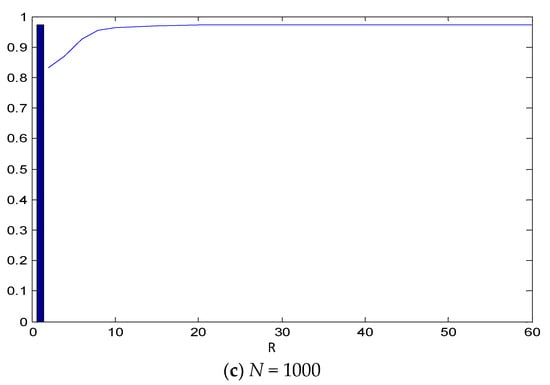
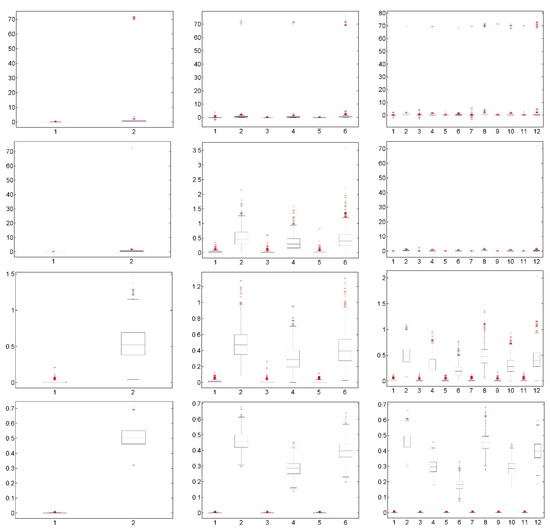
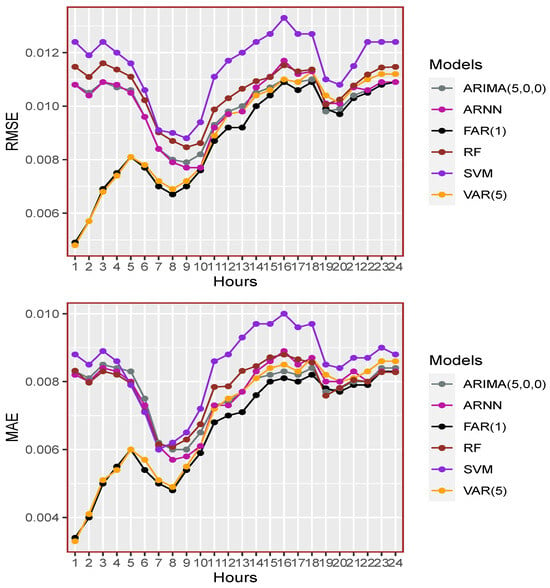
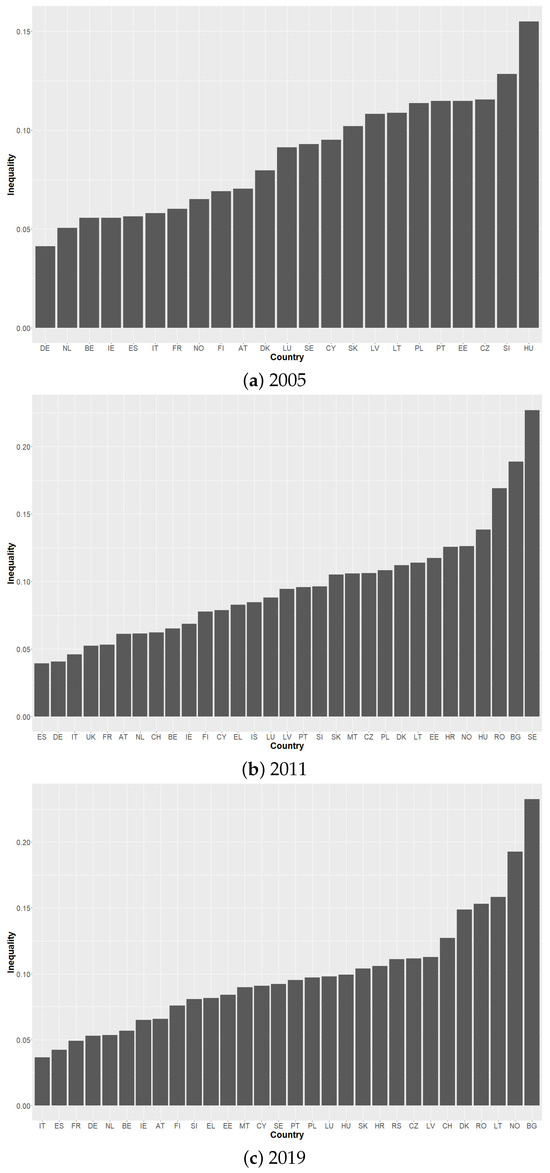
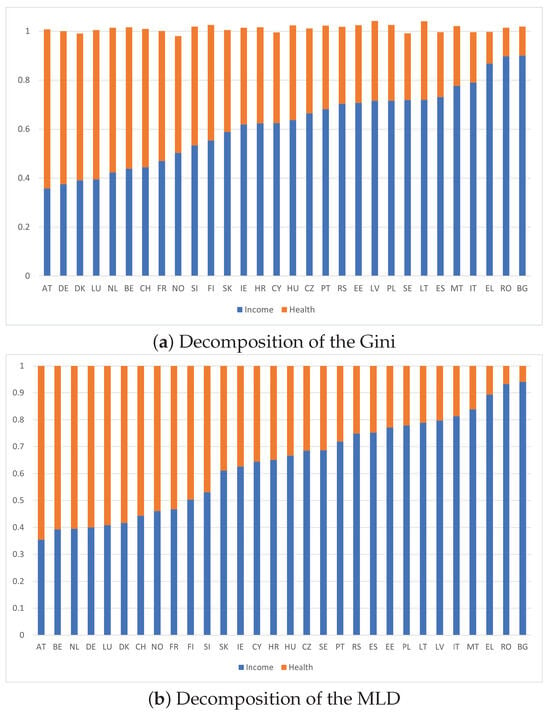
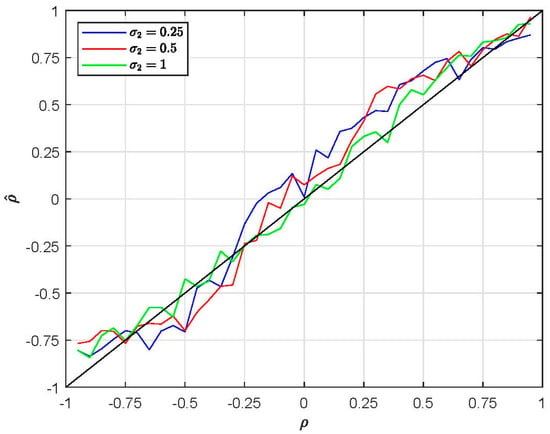
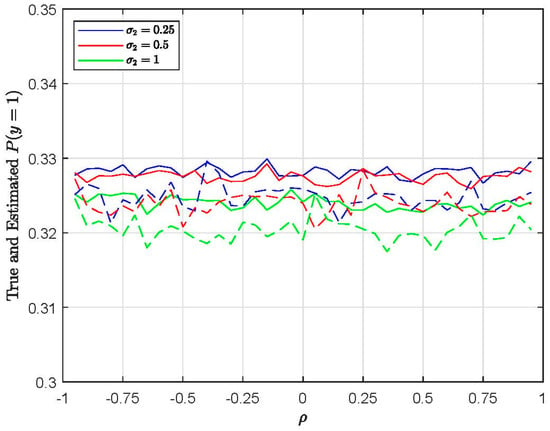
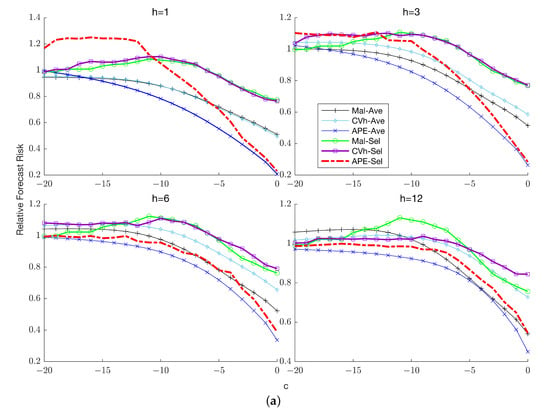
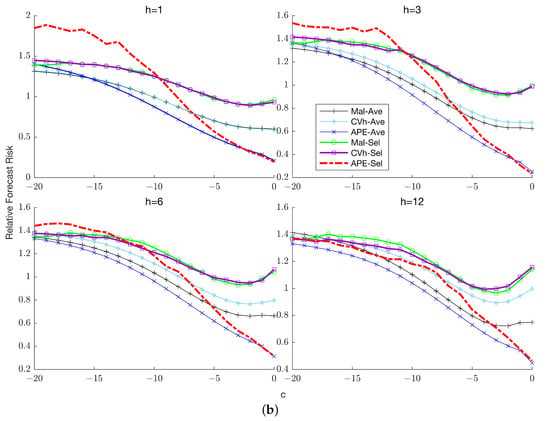
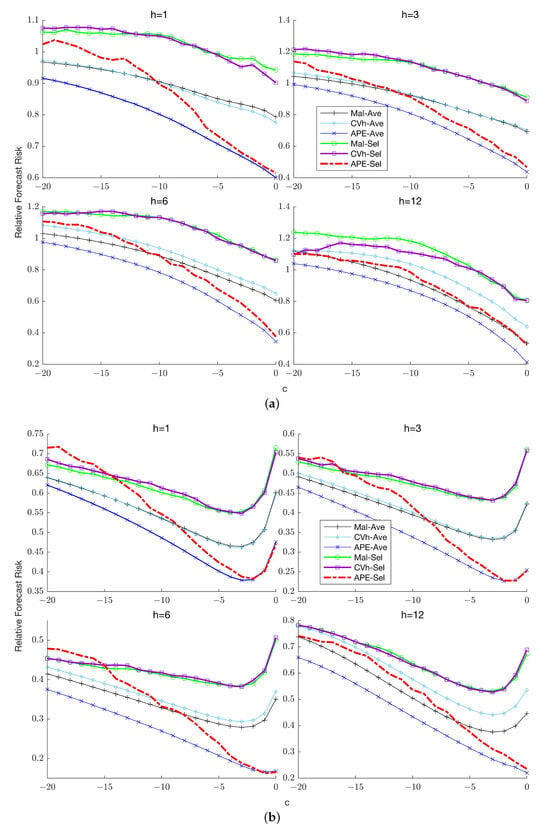
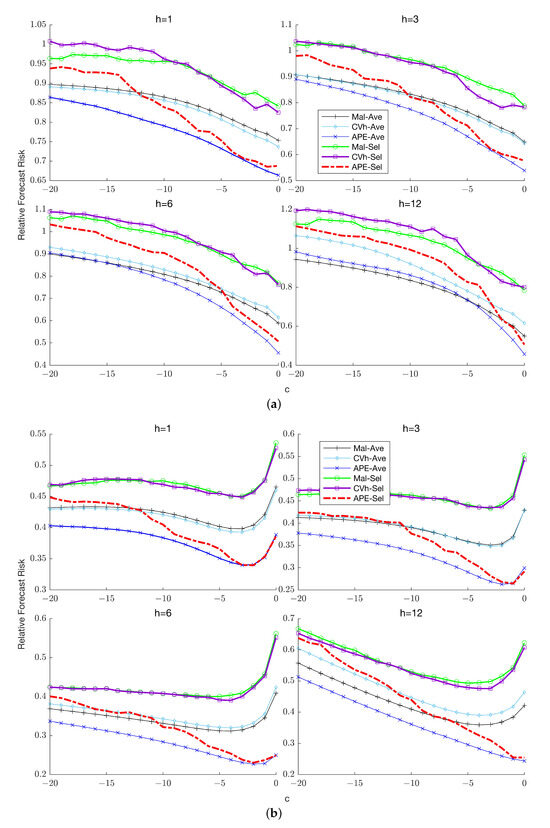
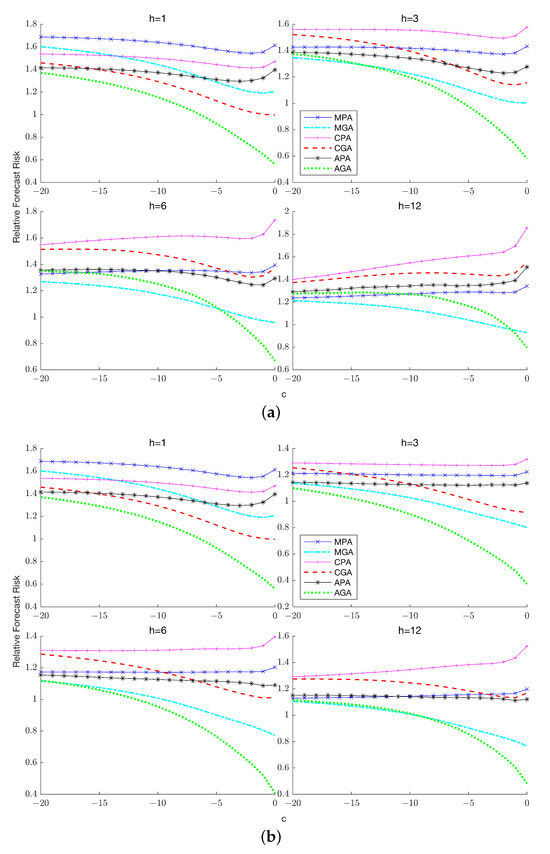
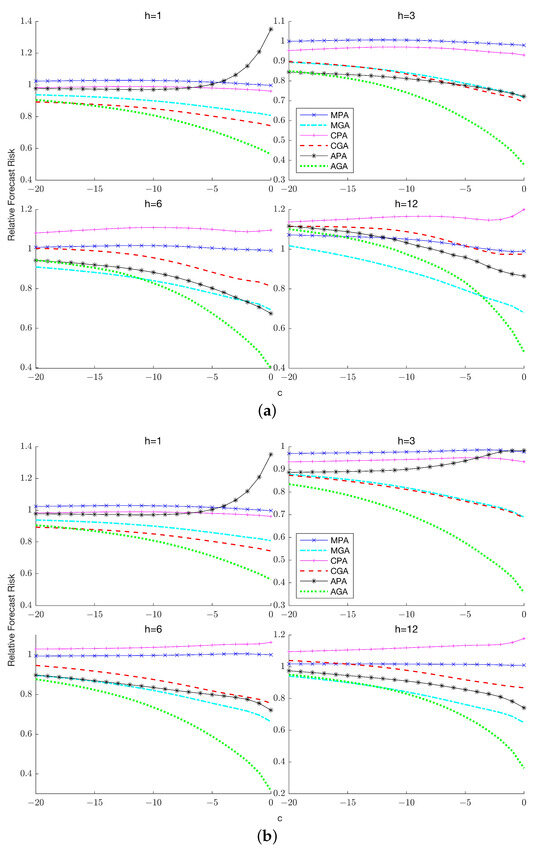
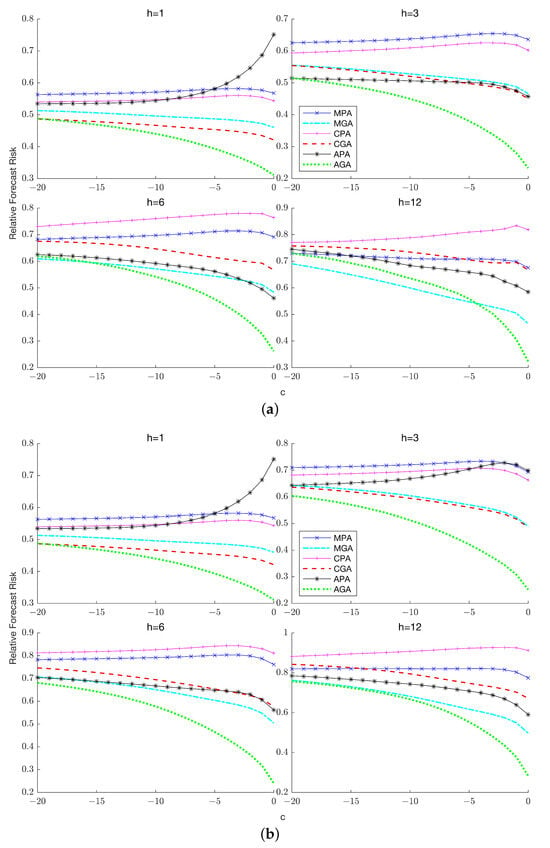
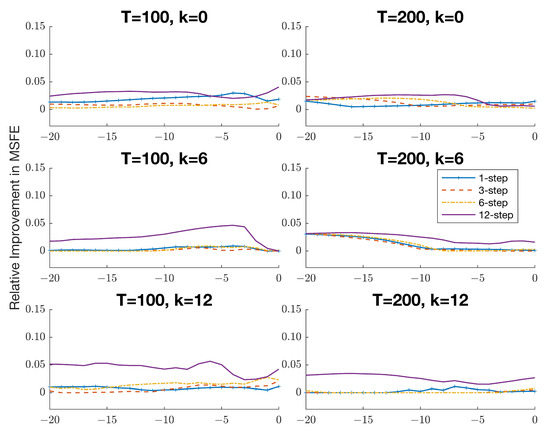
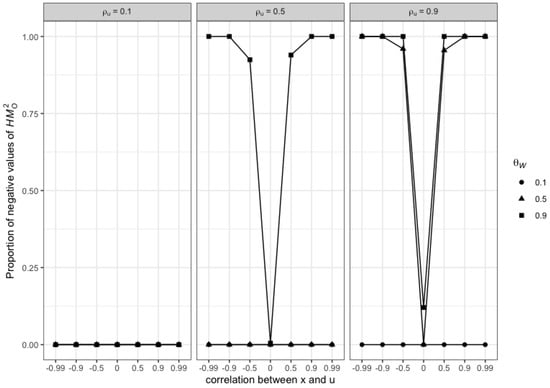
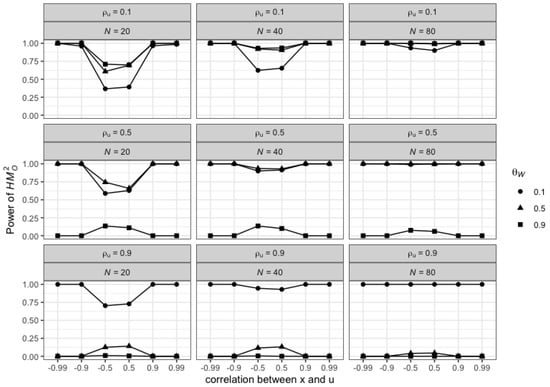
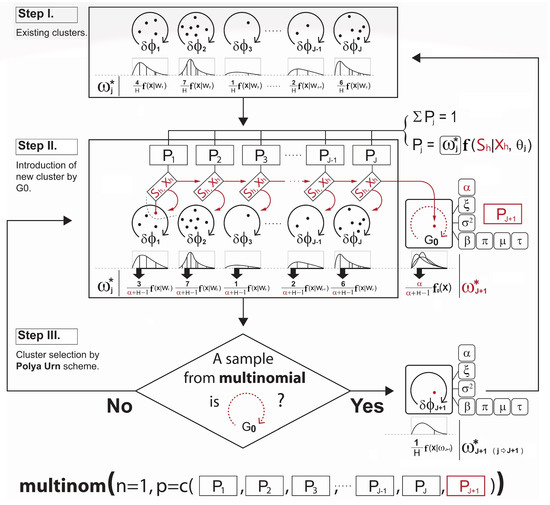
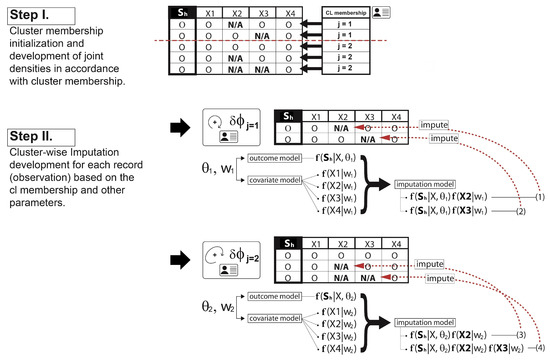
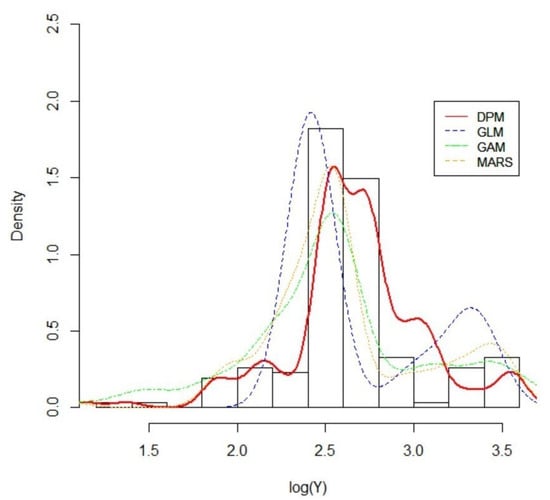
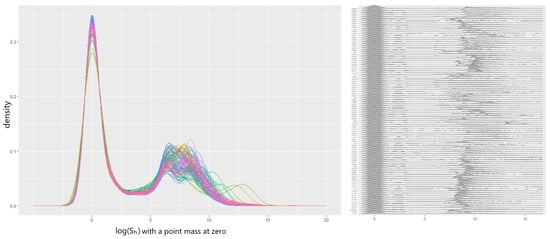
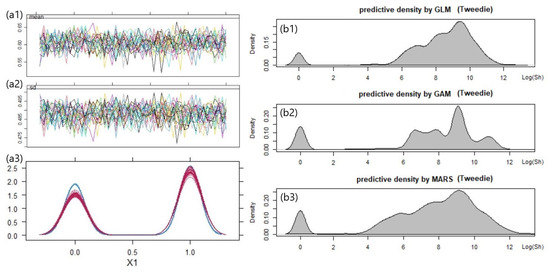
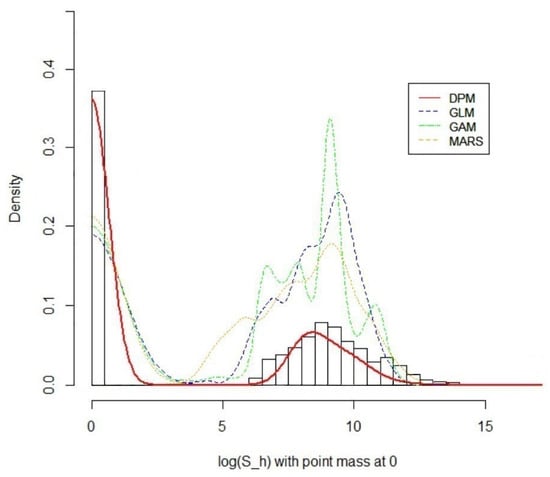
This paper introduces a new modelling approach that incorporates nonlinear, exponential deterministic terms into a fractional integration framework. The proposed model is based on a specific test on fractional integration that is more general than the standard methods, which allow for only linear trends.. Its limiting distribution is standard normal, and Monte Carlo simulations show that it performs well in finite samples. Three empirical examples confirm that the suggested specification captures the properties of the data adequately.
Full article

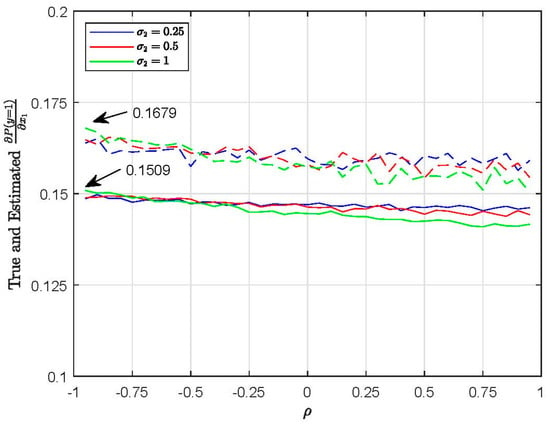
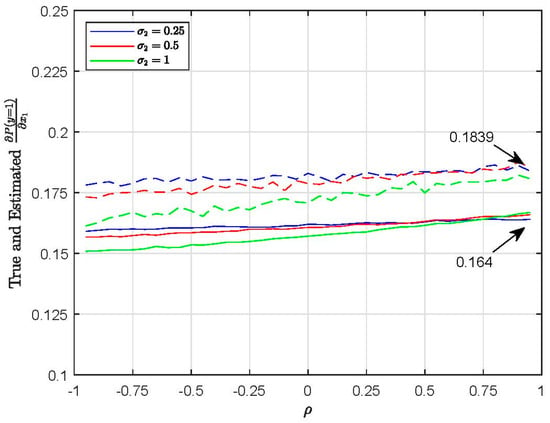
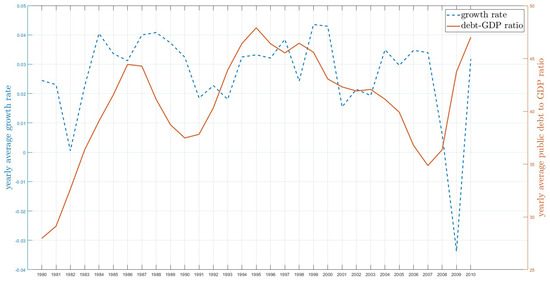
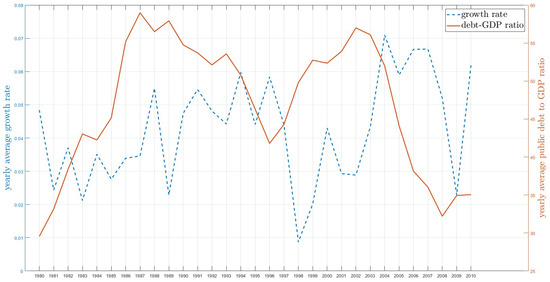
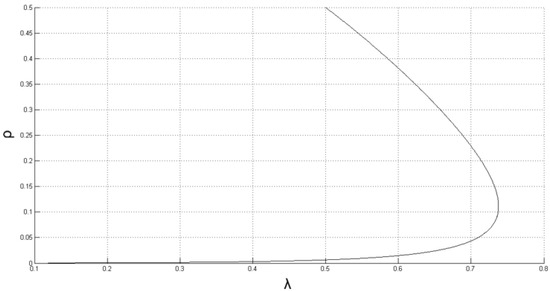
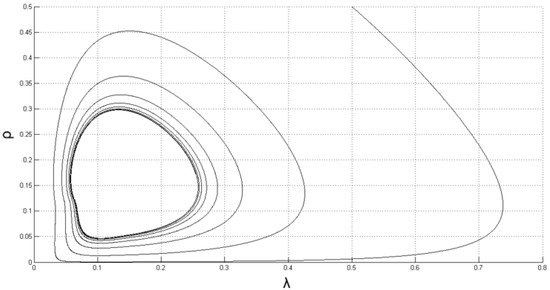
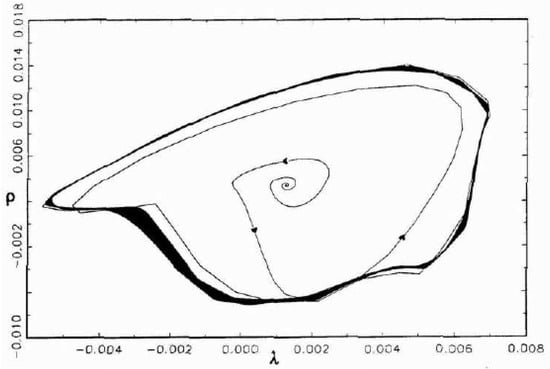
Figure 1





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}