1. Introduction
Classification of time series is one of the main applications of pattern recognition and machine learning [
1]. From a collection of features extracted from each time series, a varied and diverse set of methods have been proposed to assign a class label to a group considered homogeneous using a certain dissimilarity criterion [
2]. These methods have been applied to any scientific or technological field where a temporal sequence of data is generated [
3,
4,
5,
6,
7,
8].
The present paper is focused specifically on the classification of time series using signal complexity features. Such features exhibit a very high discriminating power, and that is why they have been successfully employed in many applications [
9,
10,
11]. However, there are ongoing efforts to further improve this discriminating power with new complexity estimation algorithms or by tweaking current ones [
12,
13,
14,
15,
16,
17], as is the case in this paper.
Many measures or methods have been described in the scientific literature so far to quantify time series complexity, irregularity, uncertainty, predictability or disorder, among other similar terms devised to characterise their dynamical behaviour [
18]. The present study deals specifically with the concept of entropy, one of the previous terms related to expected information, and often employed as a single distinguishing feature for time series classification. Entropy, as an information gauge, has also been defined in many forms, with higher entropy values accounting for higher uncertainty.
The concept of entropy was first applied in the context of thermodynamics [
19]. A few decades later, other scientific and technological areas adapted and customised this concept to information theory [
20]. The Shannon entropy introduced in [
21] soon became one of the most used and successful of these measures. In its discrete and generic form, it is given by
where
is a random variable with probability distribution
over the probability space
, and log is usually a base 2 logarithm, although natural logarithms are fairly common too.
For the focus of interest of the present paper, classification of time series, Equation (
1) must be customised for sequences of numerical values. Assuming a stationary ergodic time series,
, containing amplitude values of a continuous process with a sampling period of
T, this time series can be written as the discrete time vector
, or, in a more compact and simple form, as
, with length
N. At this point, Equation
1 could be applied to the samples in
. However, as in most real applications
p is unknown and
N is finite, an estimation,
, based on event counting or relative frequency has to be used instead.
There are many possible available choices as for the event type related to
from which to obtain
. We adopted a block approach, but instead of directly using samples or subsequences from the time series, we used associated ordinal patterns (more details in
Section 2.1) from consecutive
m overlapping windows,
. This way, the number of different blocks is finite and known in advance, and the relative frequencies can be estimated robustly provided the length of the blocks
m is significantly shorter than the length of the time series,
[
18]. If each possible ordinal pattern is referred to as
, with
, Equation (
1) takes the form
where
is the relative frequency of the ordinal pattern
. For example, for subsequences of length 3, with sample position indices ranging from 0 to 2, the ordinal patterns
that can be found are (0,1,2), (0,2,1), (1,0,2), (1,2,0), (2,1,0) and (2,0,1).
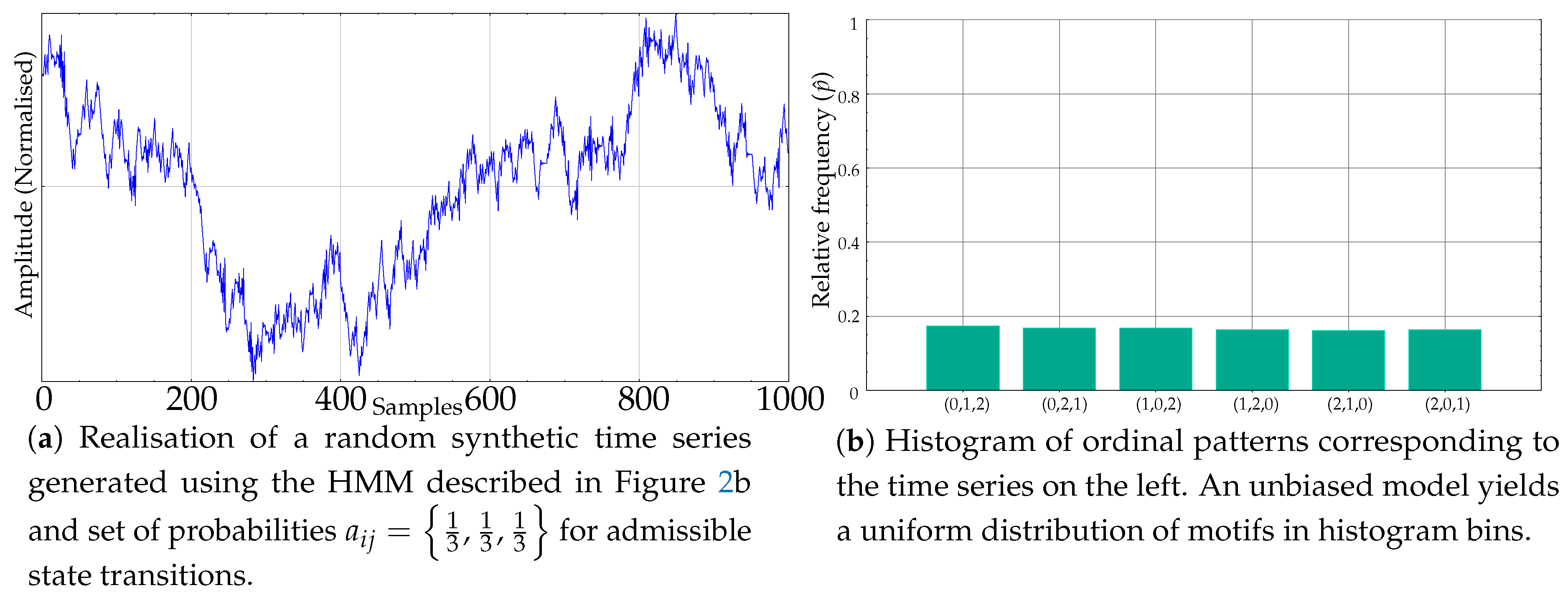
Figure 1 depicts the histograms for a few popular synthetic time series, as an example of the distribution of these relative frequencies. Specifically, the histogram in
Figure 1a belongs to a random time series with a uniform distribution, as can be inferred from the equality of the bins. At the opposite end of the spectrum of randomness,
Figure 1b shows the histogram of a sinusoidal time series, with a more polarised distribution of motifs, some of them forbidden (zero probability) [
22].
Figure 1c,d shows the histograms of other time series with a different degree of determinism, a Logistic (coefficient 3.5) and a Lorenz (parameters 10, 8/3 and 28) time series, respectively [
23,
24]. When computing the associated entropy to the relative frequencies shown in
Figure 1, the single value obtained will be arguably very different in each case.
However, the mapping of relative frequencies into a single scalar (in the sense of a size 1 vector) may entail a significant information loss, as there are infinite vectors of estimated probabilities that can yield the same . One of the most successful applications of entropy statistics is time series classification, and this information loss could have a detrimental impact on the accuracy achieved in these applications.
The present paper is aimed at characterising those situations where a single entropy measure may fail in providing discriminating information due to histogram compensation. This study will be based on a specific Shannon entropy embodiment: permutation entropy (PE) [
25]. Despite the good results achieved using this measure, there are still cases where the histogram differences are lost when computing the final PE value. We illustrate this situation with synthetic records generated using hidden Markov models (HMM), and with real body temperature records that exhibit this same behaviour. We then propose a different approach based on a clustering scheme that uses all the relative frequencies as time series features to overcome this problem. The results for both types of experimental time series demonstrate how critical this information loss may become, and how the proposed clustering method can solve it.
There is no similar study in the scientific literature, as far as we know. However, there are a few works that could use a multidimensional classification approach as ours. For example, it is worth describing the approach taken by [
26]. This paper presents a method to classify beat-to-beat intervals data series from healthy and congestive heart failure patients using classical RR features, a symbolic representation and ordinal pattern statistics. It first considers each feature individually, and then a combination of two using a linear support vector machine. The main difference with the approach described in the present paper is that the method is fully supervised, and customised for a specific biomedical record, without taking into account the full picture of the PE context.
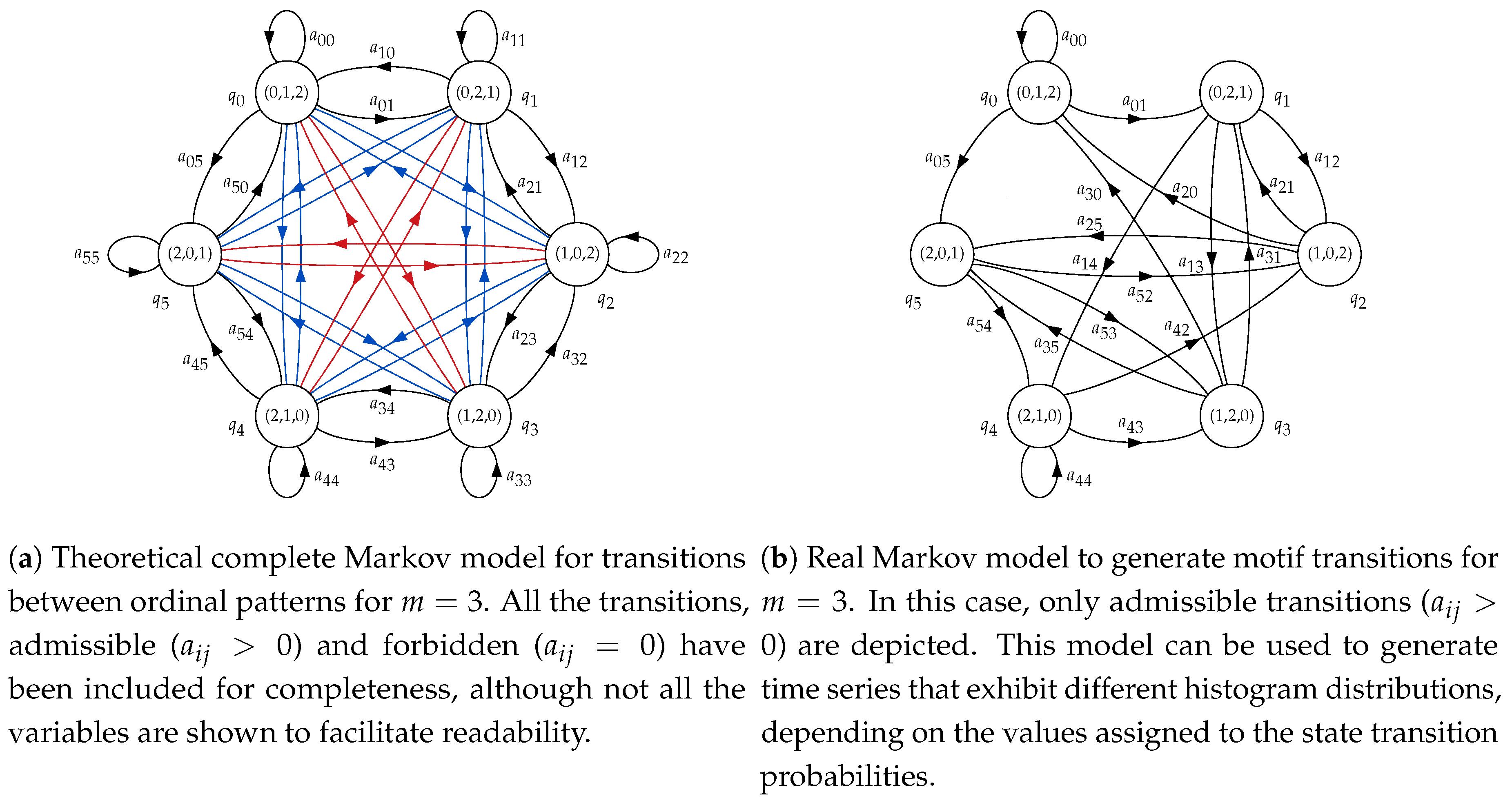
Another key concept that will play an important role in this work is the concept of forbidden ordinal pattern [
18]. In a general sense, we consider a forbidden pattern with an ordinal pattern with a relative frequency of 0 and a forbidden transition
, the impossibility to generate an ordinal pattern
j if the previous one was an ordinal pattern
i. Forbidden patterns have already demonstrated their usefulness to detect determinism in time series [
27,
28], and have even been used for classification purposes already [
22,
23], as additional distinguishing features. Specifically, the present study will use forbidden transitions as a tool to generate synthetic time series including forbidden patterns or certain histogram distributions.
3. Experiments and Results
The discriminating power of PE has been well demonstrated in a number of publications [
16,
24,
60,
61,
62]. As a single feature, using a threshold, it has been possible to successfully classify a disparity of records of different types.
Initially, the experiments were devised to assess the sensitivity of PE in terms of histogram differences that led to PE differences as well. The two class synthetic records used in these experiments where generated using unbiased and biased versions of the HMM described above. The unbiased model using equal transition probabilities (Class A) and biased versions, with unbalanced probabilities defined by the relationship , with (Class B). In this case, PE was expected to achieve a classification accuracy close to 100% using records from the synthetic dataset, given that Class A and B are very different.
The results of this test are shown in
Table 2. Class A was always fixed to an unbiased version (only the initial state was chosen at random), compared against different probability combinations featuring a biased histogram for Class B. The results confirmed that these two classes were easily separable, with poor classification performance only for values of
really close to the unbiased version of
. The classification accuracy is given as the average value and standard deviation of the 10 realisations of each experiment, where at least the initial state could vary.
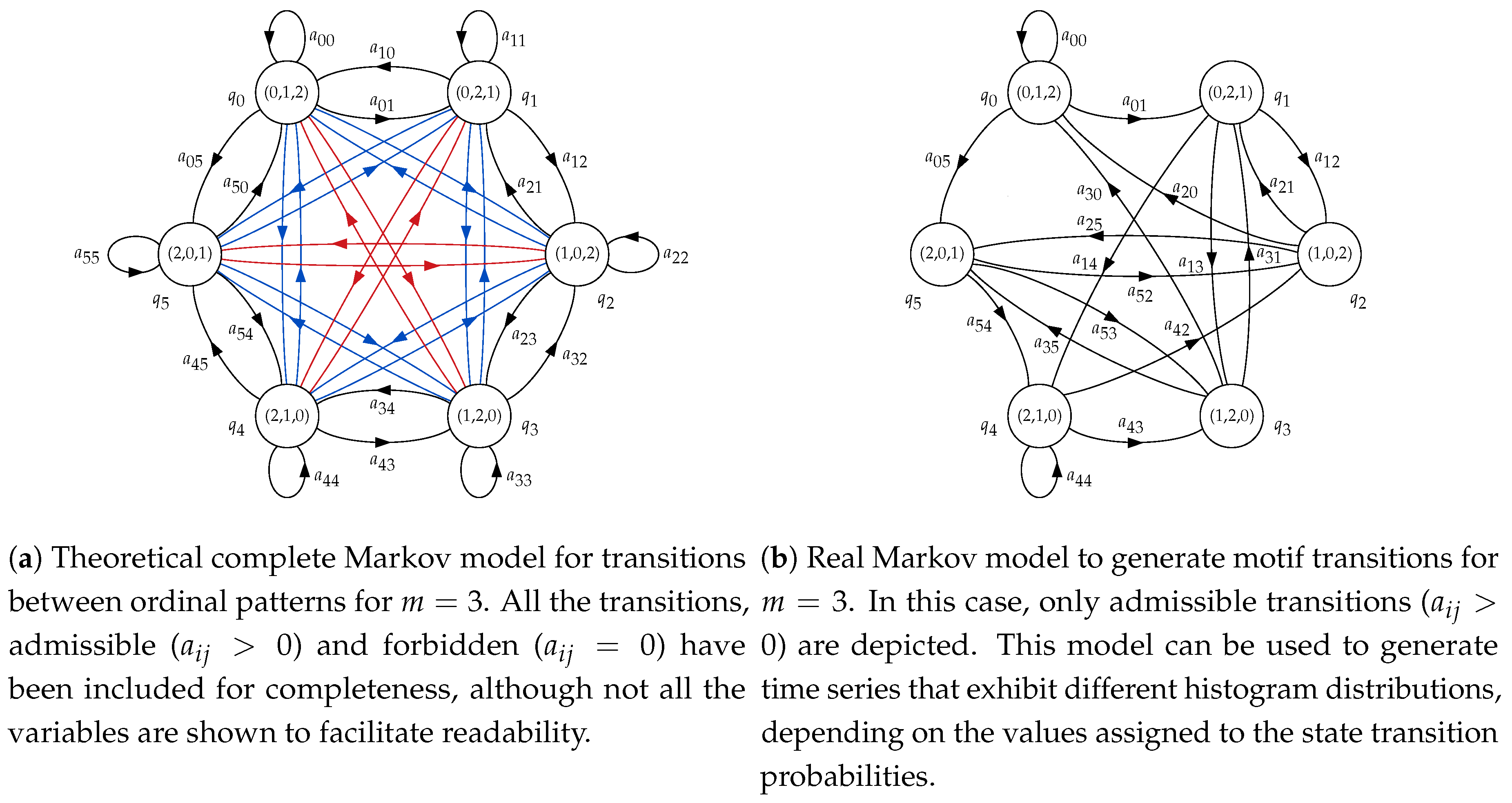
In the next set of experiments, transition probabilities were more varied for both synthetic classes. The main objective in this case was to find histograms with similar amplitude bins but at different locations (motifs) in order to assess the possible PE loss of discriminating power. Note that the relationship between probabilities and motifs is given by the graphical structure of the model shown in
Figure 2b. In other words, an asymmetry in the transition probabilities does not necessarily entail the same asymmetry in the histogram bins, since the state (motif emitter) can be reached from multiple paths. These results are shown in
Table 3.
Some of the experiments in
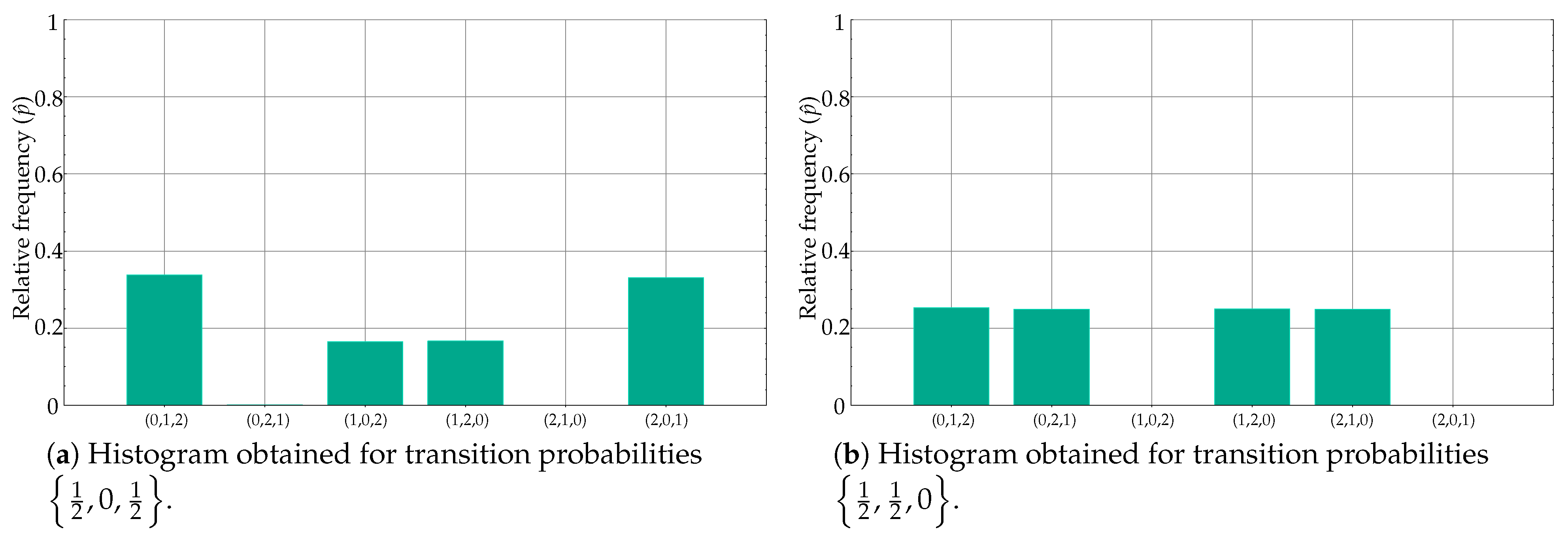
Table 3 are representative of the PE weakness addressed in the present paper: very similar relative frequencies in different motifs lead to the same PE value, and therefore classes become indistinguishable from a classification perspective. Specifically, this is the case generated by means of transition probabilities
and
. The time series generated using these probabilities are shown in
Figure 6a,b, respectively. Despite having a very different motif distribution, the
values are almost identical, at different positions, yielding similar PE values.
For example, for
, the main motifs were (0,1,2) and (2,0,1), followed by (1,0,2) and (1,2,0). Motifs (0,2,1) and (2,1,0) were negligible, as depicted in
Figure 6c. On the other hand, for
, the main motifs were (1,0,2) and (2,1,0), then (0,2,1) and (2,1,0), with no ordinal patterns (0,1,2) and (1,2,0) (see
Figure 6d). However, bin amplitudes were very similar, with an equal mapping on a single PE value.
However, the results in
Table 3 for
and
, despite having a similar transition probability set of values, are completely different from an histogram perspective, and that is why the classification accuracy was 100%. This is very well illustrated in
Figure 7a,b.
Figure 6 and
Figure 7 very well summarise what can occur in a real case using PE as the distinguishing feature of a classification procedure (or any other similar mapping approach). Although the case in
Figure 7 is the most frequent case, it is worth exploring alternatives to deal with poor time series classification performances based on PE, as this study proposes. Along this line, the results shown in
Table 4 correspond to the same experiments as in
Table 2 and
Table 3, but using the relative frequencies instead and the clustering algorithm as described in
Section 2.2.
The classification performance achieved in the experiments in
Table 4 were clearly superior to those achieved using only PE, as hypothesised. For those cases where PE had a high discriminating power already, using the raw estimated probabilities vector and the
k-Means clustering algorithm, such power was maintained or even slightly increased. For the specific case described in
Figure 6, where PE failed as commented above, this time the performance achieved an expected 100%, given the differences in the motif distribution. Only when there were no significant differences, with equal transition probabilities, both methods obviously failed.
The experiments were repeated using real body temperature time series from the Control and Pathological datasets described in
Section 2.4.2. The relative frequencies of each motif for the first subset are numerically shown in
Table 5 for each record. The same for pathological records, in
Table 6.
Temperature records of the experimental dataset exhibit the same behaviour than synthetic records with transition probabilities and . Using PE as the single classification feature, it was not possible to find differences between classes, with a nonsignificant accuracy of 60%. With the clustering and probability vector approach, this accuracy raised up to the 90%, with only three misplaced time series (19 objects assigned to the Control class, 16 really Control ones and the three errors, and 11 to the pathological one). The final centroids for each class were and .
Although it was not the objective of the present study to design a classifier, to better support the results using the estimated probabilities instead of PE, a leave-one-out (LOO) [
63] classification analysis was conducted on the temperature data. A total of 100 realisations are used. In each realisation, a record from each class (with replacement) was randomly omitted in the
k-means analysis. Then, the resulting centroids were used for classification of the omitted records using a nearest neighbour approach. The number of errors in this case were 18, that is, 18 records of the Pathological group were incorrectly classified as Control records, whereas no Control record was misclassified as Pathological. Therefore, the global accuracy using LOO and the probability vectors of the temperature records was 82%.
4. Discussion
The initial results in
Table 2 give a sense of the PE general behaviour, in terms of discriminating power. For very significantly different transition probabilities, the classification performance easily reaches 100%. As these probabilities become closer, the error increases, and obviously, for the same models, it is impossible to distinguish between the two classes (54.8%). It is important to note that the probability window for which performance is not 100% is very narrow, from 0.33 to 0.3 accuracy goes from 54.8% up to 96.1%, which, in principle, confirms the high discriminating power of PE.
When both state transition probabilities are biased, the classification results are not 100% so often, as
Table 3 illustrates. Moreover, although the probabilities are the same but in a different order, they result in significant differences in the histograms translated into a still high classification accuracy due to the asymmetry of the model (
Figure 2b). In a few transition probabilities cases, as for
and
, these histogram differences can be numerically compensated and lose the discriminating capability, as hypothesised in this study.
Table 4 demonstrates this point by applying a clustering algorithm to the set of relative frequency values instead of the resulting PE value. For all the theoretically separable cases, this scheme yields a performance of at least 96%, and, in all cases, the performance is higher than that achieved using only PE. It is especially significant the
and
case, a clear representative of the possible detrimental effects of mapping to a single feature. From a nonsignificant classification accuracy of 55%, the clustering approach achieves a 100% accuracy, since the class differences are very apparent in the set of relative frequencies (
Figure 6c,d). Obviously, all methods fail when the state transition probabilities are the same (51.1% accuracy in this case for
probabilities). Although with PE the result was 54.8% accuracy, it should not be interpreted as an improvement over the 51.1%, since both results were not significant, and correspond to a plain random guess that can exhibit a minor bias due to the limited number of realisations, 10 in this case.
Table 5 and
Table 6 demonstrate, with real data, the possible detrimental impact on PE discriminating power mapping all the relative frequencies on a single scalar may exert, confirming what synthetic records already showed. The numerical values listed enable a detailed comparison of each motif contribution to the possible differences between classes. The main differences take place for patterns (0,1,2) and (2,1,0), at the first and fifth data columns, respectively. When using PE values, these differences become less noticeable, and that is why it is not possible to separate significantly the Control and Pathological groups of these records. Moreover, these relative frequencies go in opposite directions, that is, they are greater for the Control group in the first case
and smaller in the second case
, with relatively small standard deviations, and therefore compensation is more likely. It is also important to note that the final clustering centroids very well captured the histogram structure of both classes.
The LOO analysis provided a more realistic picture of the possible performance if a classifier had to be designed for the experimental dataset of temperature records. The accuracy went down slightly, from 90% using the entire dataset, down to 82% when a record of each class was omitted in the centroid computation. Anyway, this is still a very high classification accuracy, and it is important to note that PE alone was unable to find significant differences in this case, even when using all the records.
The computational cost using features instead of a single PE value was obviously expected to be higher. Therefore, a trade–off between accuracy and execution time should be considered. Using a Windows© 8 computer with an Intel Core i7-4720HQ© 2.60GHz processor, with 16GB of RAM and C++ programming language, the execution time for the 100 LOO iterations using temperature records was 5.92s for , 21.1s for and 104.1s for , without any algorithm optimisation. With a single feature, PE, the execution time was 2.48s.
The embedded dimension
m is also related to the amount of information captured by a subsequence. A multiscale approach, with different time scales for PE [
64,
65], could also contribute to gain more insights into the dynamics of the time series. In this regard, it has been demonstrated that higher values of
m frequently provide more discriminating power [
24,
60], as well as an optimal set of time delays [
66]. However, using the approach proposed, it would be first necessary to assess the significance of the
features, even for each time delay, to keep the computational cost reasonably low.
5. Conclusions
The distinguishing power of PE is very high and is sufficient for many time series classification applications. PE has been successfully employed as a single feature in a myriad of technological and scientific fields.
However, sometimes the distinguishing features embedded in the histogram bins can become blurred when Equation
3 is applied. In order to avoid this problem, before discarding PE as the classification feature, or any other measure based on this kind of many-to-one mapping approach, we propose to look at the previous step of the PE algorithm and analyse the discriminating power of the relative frequencies instead.
The experimental set had to be chosen with this problem in mind. To control, up to a certain extent, the distribution of ordinal patterns in the time series used, we first developed a method based on HMM to create synthetic time series that satisfied certain motif emission constraints, and caused PE to fail at least in some cases. In addition, real-time series and body temperature records were also included, as they also exhibited this same problem under study.
The use of a vector of features instead of a single value can be seen as a typical multifeature extraction stage of a pattern recognition task. Almost any clustering algorithm is perfectly suited to deal with this task. For illustrative purposes only—not for optimisation—we applied a classical Means algorithm and a standard configuration.
The results using this approach confirmed, for both datasets, that using the original histogram values, the discriminating power of PE can be enhanced. As a consequence, we propose, when possible, to analyse the information provided by each histogram bin jointly, as is the case in the present study, or separately, in a kind of feature selection analysis, as in [
23], to maximise the information provided by ordinal pattern distribution beyond the scalar PE value. This approach can be arguably be exported to many other methods, and open a new line of research combining event-counting metrics with pattern recognition or machine learning algorithms.
Obviously, if there are no differences at the histogram level; for example, when temporal correlations are the same, any method based on such information will fail, that is, both PE and the method proposed. This scenario can be illustrated trying to distinguish time series with random Gaussian or uniform amplitude distributions. Despite the amplitude differences, it was not possible to distinguish between both classes using PE or the method proposed. For such cases, we conducted a few additional tests using measures better suited to amplitude differences in order to propose alternatives to overcome this drawback. The most straightforward approach is to use methods such as ApEn or SampEn, both amplitude-based, which achieved a classification accuracy close to 100% using Gaussian and uniform amplitude distributions for classes. A solution more related to the present paper was to use a PE derivative that included amplitude information [
24]. In this regard, Weighted Permutation Entropy [
67] also achieved a very high classification accuracy, well above 80%.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}