1. Introduction
Rolling bearings are widely used in industrial production equipment, and their health status has a huge impact on the performance, stability and service life of the entire mechanical equipment [
1,
2]. Therefore, the fault diagnosis and condition assessment of rolling bearings are of great significance. Normally, the fault diagnosis methods of bearings are mainly divided into two types, one based on mechanism experience [
3] and the other based on data driving [
4]. Affected by both external and internal factors, the failure degradation of rolling bearings often presents nonlinearity and instability. It is difficult to achieve ideal fault diagnosis results by merely relying on failure mechanism knowledge or data-operating for state identification and fault diagnosis. Therefore, the bearing fault diagnosis method based on the fusion of a knowledge graph and deep learning indicates a new research direction.
The concept of a knowledge graph was first proposed by Google in 2012 to improve the search engine [
5]. Compared with traditional knowledge bases, knowledge graphs represents richer semantic relationships, higher knowledge quality, and better visualization effects, providing great convenience for human-computer interaction. The knowledge graph is composed of entities, attributes and relationships. Knowledge graphs are widely used. For example, Oramas et al. [
6] used knowledge graphs to recommend sounds and music; Li et al. [
7] combined the knowledge graph with SQL databases, proposed the framework design of industrial software design and development process, and verified it in specific industrial scenarios; Liu et al. [
8] used the integration method of deep learning and knowledge graph to prove the effectiveness of market prediction and made stock investments. However, due to the complexity of knowledge in the field of fault diagnosis, it is extremely difficult to construct and use knowledge graphs rationally. If we can construct the knowledge graph in an accurate way, it will play a key role in maintaining the health of mechanical equipment. Therefore, this paper will attempt to construct the knowledge graph of rolling bearing fault diagnosis in order to contribute to the health maintenance of equipment.
The construction of a bearing fault graph requires fusion with data. As a subset of machine learning, deep learning has made significant progress in computer vision [
9], natural language processing [
10], biology [
11], and other fields, and it has also been widely used in the field of fault diagnosis, such as by Liang et al. [
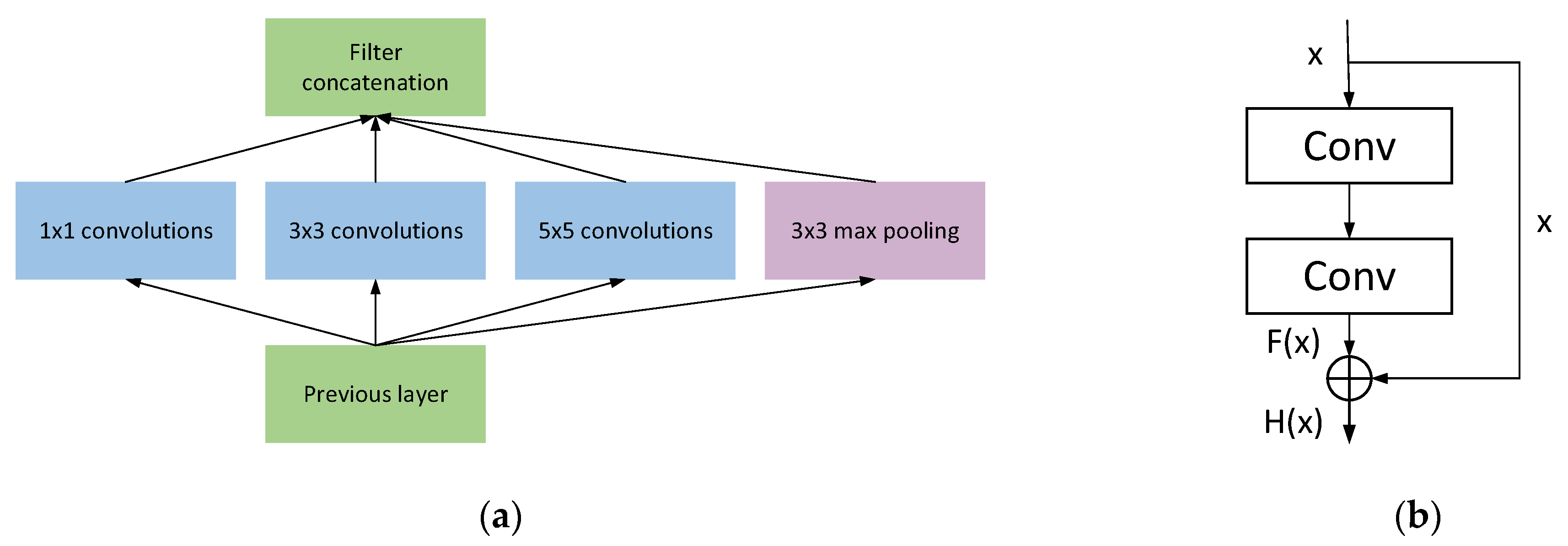
12], who proposed a gearbox fault diagnosis model that combines wavelet transform (WT) and CNN. It was verified on two gearbox datasets and achieved good results, but as the network got deeper, the model increased more, which caused performance degradation. Thus, it is difficult to achieve better results for more complex data. The proposal of the Inception network has changed people’s perception of relying on increasing the depth and width of the network to improve its performance. It changes the structure of the network so that the parameters reduce while the depth and width of the network increases [
13], and the size of the convolution kernel will directly affect the performance of the network, and a single-sized convolution kernel can lead to incomplete extraction of information [
14].
In response to the problems above, this paper proposes a fault diagnosis method based on the fusion of convolutional neural networks and knowledge graphs. The main contributions are as follows:
- (1)
Extracting entities based on the equipment mechanism and knowledge rules of bearing data, then applying the MOCNN to categorize faults through data labeling to complete extraction of data relationship, and eventually, the knowledge graph of bearing faults is established. Furthermore, by forming the graph to assist decision-making as well as to display detailed fault information, it realizes a complete fault diagnosis, which moves away from a single reliance on mechanism knowledge or a data-driven diagnosis technique and toward the union of data and knowledge.
- (2)
This paper offers an end-to-end one-dimensional multiscale convolutional neural network model (MOCNN) that combines advantages of one-dimensional convolutional networks in processing one-dimensional input. The model first implements sensitive feature extraction of the input 1D signals from different angles using the modified Inception module, and then adds a residual link to the Inception block to learn more abundant features. Following that, the retrieved features are fine-tuned using the channel attention and spatial attention modules. To improve the performance of the model and the effectiveness of defect diagnosis, the L2 regularization is introduced to the attention module and the classification layer.
- (3)
The model is combined with the knowledge graph, marked by the CWRU data set, and adopted a new experimental division method. Compared with Resnet and Inception, this model has a good diagnosis impact. It is more suitable for large data and multi-classification problems and also features fast and stable convergence on small data sets and multi-classification problems. Moreover, it performs well in noise environment tests in various noise environments, working situations, and variable working conditions.
The rest of this paper is organized as follows: Related work is described in
Section 2.
Section 3 introduces the fault diagnosis method, fault diagnosis model and data processing proposed in this paper. In
Section 4, entities and relationships are extracted and a knowledge graph is constructed. At the same time, the fault diagnosis model is compared and discussed from different angles. A conclusion is provided in
Section 5.
5. Conclusions
In this paper, we propose a deep learning and knowledge graph fusion method for bearing fault diagnosis which combines the mechanistic knowledge of rolling bearings with vibration signal data to improve the efficiency of fault diagnosis. By using this method, the bearing data is firstly extracted by rules, entities are extracted, then the data is labeled and the optimized convolutional neural network model MOCNN is used to classify faults, realize relation extraction and obtain triad for knowledge graph construction to assist fault diagnosis decision and visualize the results. In addition, this paper also compares and discusses the models. Using the CWRU dataset, a new classification method can still achieve an accuracy of 97.86% when the faults are up to 160 classes, and it is fully compared with other models in environments such as multiple operating conditions and noise environments. The experimental results show that the one-dimensional fault diagnosis model proposed in this paper, regardless of the size of the dataset, not only has a fast convergence rate and stable operation, but also has the best noise immunity and migration performance, which proves the practicality of the fault diagnosis model proposed.
This study provides a new solution for fault diagnosis of mechanical equipment and also illustrates the difficulty of diagnosing compound faults in industrial equipment. The model in this paper is currently only for historical data, and in the future, we will also try real-time diagnosis and add other kinds of data to build a richer knowledge graph using deep learning algorithms.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}