
An Influence Maximization Algorithm for Dynamic Social Networks Based on Effective Links


Abstract
:1. Introduction
- The traditional propagation models mainly focus on the study of information diffusion in static networks, which cannot reflect the changes of node interaction in dynamic social networks well;
- The spread of influence should conform to the timeliness of the connection between users in social networks, and the diffusion mechanism can only play a role in the effective stage;
- The weight indicator to measure the mutual influence among users in social networks should be combined with the time factor.
- The functions of out-degree neighbors and in-degree neighbors in social networks are refined, and the influence probability between users is reset according to the topological relationship between users’ direct neighbors and indirect neighbors;
- The traditional independent cascade model is improved by taking dynamic social networks as the research object, and the time-based propagation model is proposed by combining the effective number of connections between users;
- A two-stage influence maximization algorithm, Outdegree with Effective Link (OEL), is proposed to solve the problem of selecting seed nodes on dynamic social networks by combining submodular properties;
- The effectiveness of the OEL algorithm is verified by experimental comparison.
2. Related Works
3. Problem Definition
3.1. Basic Definitions
3.2. Independent Cascade Propagation Model
4. Model and Algorithm
4.1. Propagation Model Based on Effective Link
| Algorithm 1. The work principle of ICEL model |
| Input: Activation threshold , Node and Node , Similarity threshold |
| Output: If node activates node , return true; otherwise, return false |
| (1) Calculate the probability that node u activates v |
| (2) if |
| (3) return true |
| (4) Calculate according to Equation (2) |
| (5) if |
| (6) for to do |
| (7) |
| (8) if |
| (9) return true |
| (10) return false |
4.2. Characteristics of the ICEL Model
4.3. OEL Algorithm
| Algorithm 2. OEL algorithm |
| Input:(V,E,), Seed size k, Threshold of activation , Alternative seed set , Regulatory factors |
| Output: Seed set S |
| (1) Initialize , |
| (2) For i = 1 to do |
| (3) ; |
| (4) ; |
| (5) Endfor |
| (6) For u in do |
| (7) ; |
| (8) Endfor |
| (9) Sorted according in descending |
| (10) ; |
| (11) ; |
| (12) For i = 2 to k do |
| (13) gain() = Spread(S |
| (14) if(gain() > gain()) |
| (15) ; |
| (16) ; |
| (17) else |
| (18) For u in do |
| (19) ; |
| (20) Endfor |
| (21) Sorted according in descending; |
| (22) ; |
| (23) ; |
| (24) Endif |
| (25) Endfor |
| (26) Return S |
4.4. Time Complexity Analysis
5. Experiment and Evaluation
5.1. Experimental Data
5.2. Experimental Settings
5.3. Experiment and Result Analysis
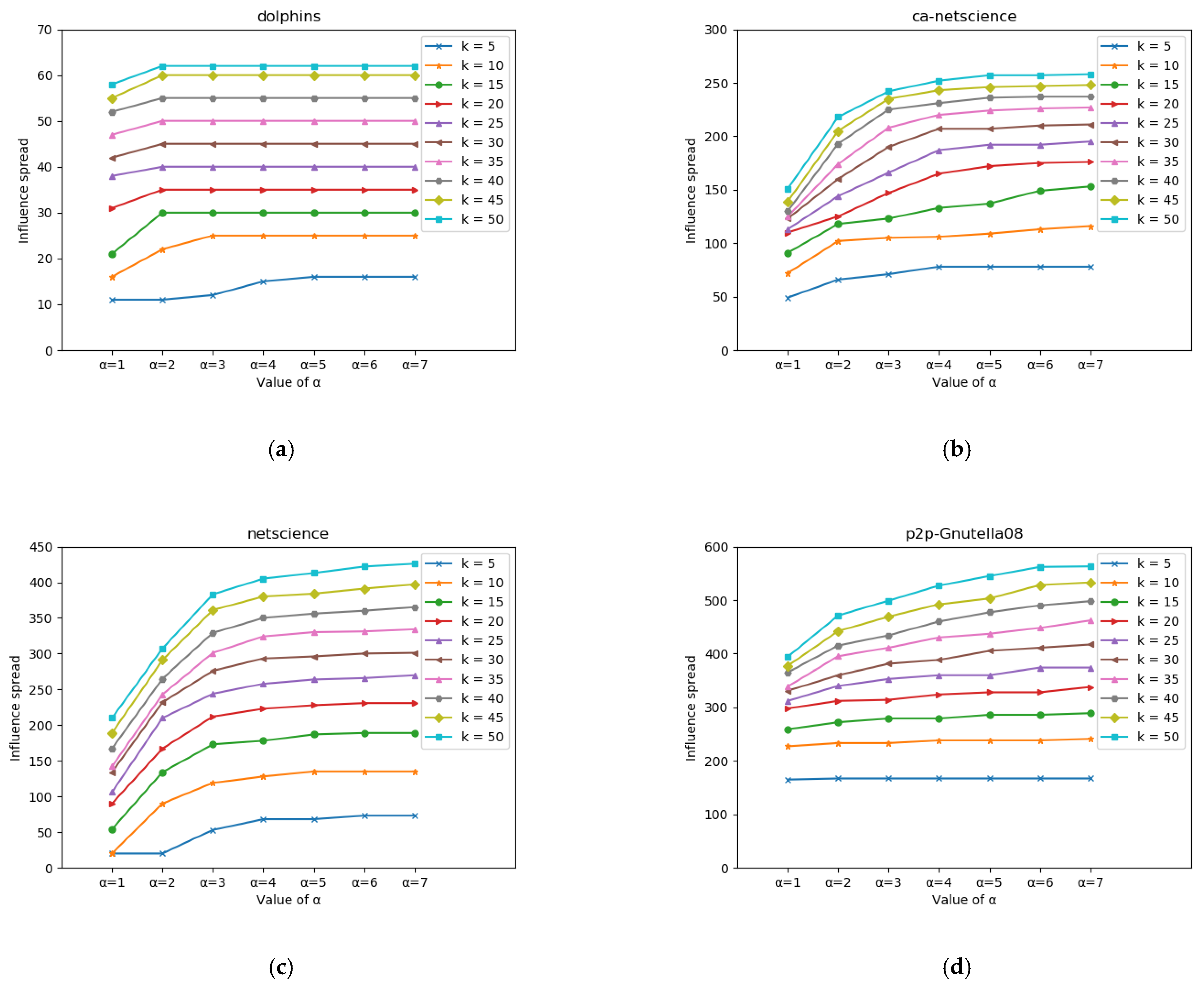
5.3.1. Parameter Analysis of the OEL Algorithm
5.3.2. Scope of Transmission
5.3.3. Time Comparison
6. Summary
- On the basic dynamic social networks, in order to avoid the problem of influence overlap, construct new metrics to explore the seed set of influence maximization;
- Modeling of the influence maximization problem in a time-constrained and cost-constrained dynamic network, so as to better measure the information dissemination process in a dynamic social network.
Author Contributions
Funding
Conflicts of Interest
References
- Leskovec, J.; Adamic, L.A.; Huberman, B.A. The dynamics of viral marketing. ACM Trans. Web 2007, 1, 5-es. [Google Scholar] [CrossRef] [Green Version]
- Keller, E.; Berry, J. One American in Ten Tells the Other Nine How to Vote, Where to Eat, and What to Buy; The Free Press: New York, NY, USA, 2003. [Google Scholar]
- Goldenberg, J.; Muller, L.E. Talk of the network: A complex systems look at the underlying process of word-of-mouth. Mark. Lett. 2001, 12, 211–223. [Google Scholar] [CrossRef]
- Domingos, P.; Richardson, M. Abstract mining the network value of customers. In Proceedings of the KDD01: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 57–66. [Google Scholar]
- Kempe, D. Maximizing the spread of influence through a social network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2003. [Google Scholar] [CrossRef] [Green Version]
- Leskovec, J.; Krause, A.; Guestrin, C.; Faloutsos, C.; Van Briesen, J.; Glance, N. Cost-effective outbreak detection in networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘07), San Jose, CA, USA, 12–15 August 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 420–429. [Google Scholar]
- Zareie, A.; Sheikhahmadi, A. A hierarchical approach for influential node ranking in complex social networks. Expert Syst. Appl. 2018, 93, 200–211. [Google Scholar] [CrossRef]
- Bian, T.; Deng, Y. Identifying influential nodes in complex networks: A node information dimension approach. Chaos 2018, 28, 043109. [Google Scholar] [CrossRef] [PubMed]
- Wen, T.; Deng, Y. Identification of influencers in complex networks by local information dimensionality. Inf. Sci. 2020, 512, 549–562. [Google Scholar] [CrossRef] [Green Version]
- Du, Z.; Tang, J.; Qi, Y.; Wang, Y.; Han, C.; Chunyang, H. Identifying critical nodes in metro network considering topological potential: A case study in Shenzhen city—China. Phys. A Stat. Mech. Appl. 2020, 539, 122926. [Google Scholar] [CrossRef]
- Li, Z.; Huang, X. Identifying influential spreaders in complex networks by an improved gravity model. Sci. Rep. 2021, 11, 22194. [Google Scholar] [CrossRef]
- Albert, R.; Barabási, A.-L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47–97. [Google Scholar] [CrossRef] [Green Version]
- Alsayed, A.; Higham, D.J. Betweenness in time dependent networks. Chaos Solitons Fractals Interdiscip. J. Nonlinear Sci. Nonequilibrium Complex Phenom. 2015, 72, 35–48. [Google Scholar] [CrossRef]
- Cao, J.X.; Dong, D.; Xu, S.; Zheng, X.; Luo, J.Z. Ak-core based algorithm for influence maximization in social networks. Chin. J. Comput. 2015, 38, 238–248. [Google Scholar]
- Li, M.; Xu, G.; Zhu, S.; Zhang, W. Influence maximization algorithm based on structure hole and degree discount. J. Comput. Appl. 2018, 38, 3419. [Google Scholar]
- Zhao, J.; Wang, Y.; Deng, Y. Identifying influential nodes in complex networks from global perspective. Chaos Solitons Fractals 2020, 133, 109637. [Google Scholar] [CrossRef]
- Han, Z.-M.; Yan, C.; Li, M.-Q.; Liu, W.; Yang, W.-J. An efficient node influence metric based on triangle in complex networks. Acta Phys. Sin. 2016, 65, 168901. [Google Scholar]
- Yu, E.-Y.; Fu, Y.; Tang, Q.; Zhao, J.-Y.; Chen, D.-B. A Re-Ranking Algorithm for Identifying Influential Nodes in Complex Networks. IEEE Access 2020, 8, 211281–211290. [Google Scholar] [CrossRef]
- Lv, Z.; Zhao, N.; Xiong, F.; Chen, N. A novel measure of identifying influential nodes in complex networks. Phys. A Stat. Mech. Appl. 2019, 523, 488–497. [Google Scholar] [CrossRef]
- Tong, G.; Wang, R.; Dong, Z.; Li, X. Time-constrained adaptive influence maximization. IEEE Trans. Comput. Soc. 2020, 8, 33–44. [Google Scholar] [CrossRef]
- Liu, B.; Cong, G.; Xu, D.; Zeng, Y. Time Constrained Influence Maximization in Social Networks. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012. [Google Scholar] [CrossRef]
- Wei, C.; Wei, L.; Ning, Z. Time-Critical Influence Maximization in Social Networks with Time-Delayed Diffusion Process; AAAI Press: Palo Alto, CA, USA, 2012. [Google Scholar]
- Chen, Y.; Xia, T.; Zhang, W.; Li, J. Influence diffusion model based on affinity of dynamic social networks. J. Commun. 2016, 37, 8. [Google Scholar]
- An-Biao, W.U.; Yuan, Y.; Qiao, B.Y.; Wang, Y.S.; Yu-Liang, M.A.; Wang, G.R. The influence maximization problem based on large-scale temporal graph. Chin. J. Comput. 2019. [Google Scholar] [CrossRef]
- Chen, J.; Qi, Z. Research on social network influence maximization algorithm based on time sequential relationship. J. Commun. 2020, 41, 11. [Google Scholar]
- Wang, Y.; Guo, J.L. Evaluation method of node importance in directed-weighted complex network based on multiple influence matrix. Acta Phys. Sin. 2017, 66, 050201. [Google Scholar] [CrossRef]
- Xu, X.; Zhu, C.; Wang, Q.; Zhu, X.; Zhou, Y. Identifying vital nodes in complex networks by adjacency information entropy. Sci. Rep. 2020, 10, 2691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, D.; Wen, Z.; Tong, H.; Lin, C.Y.; Song, C.; Barabási, A.L. Information spreading in context. In Proceedings of the 20th International Conference on World Wide Web (WWW ’11), Hyderabad, India, 28 March–1 April 2011; pp. 735–744. [Google Scholar] [CrossRef]
- Goel, S.; Watts, D.J.; Goldstein, D.G. The Structure of Online Diffusion Networks. In Proceedings of the 13th ACM Conference on Electronic Commerce, Valencia, Spain, 4–8 June 2012. [Google Scholar]
- Cao, J.X.; Wu, J.L.; Shi, W.; Liu, B.; Luo, J.Z. Sina microblog information diffusion analysis and prediction. Chin. J. Comput. 2014. [Google Scholar] [CrossRef]
- Buscarino, A.; Fortuna, L.; Frasca, M.; Latora, V. Disease spreading in populations of moving agents. EPL (Europhys. Lett.) 2008, 82, 38002. [Google Scholar] [CrossRef] [Green Version]
- Kandhway, K.; Kuri, J. Using Node Centrality and Optimal Control to Maximize Information Diffusion in Social Networks. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1099–1110. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, Y.; Yang, S. Efficient influence maximization in social networks. In Proceedings of the ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, Paris, France, 28 June–1 July 2009. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definition |
|---|---|
| Dynamic social network | |
| Activation probability of node u to v in static network | |
| Activation probability of node u to v in dynamic network | |
| Out edge neighbor of node u | |
| In edge neighbor of node u | |
| The set of effective contact times between node u and node v | |
| Tuning coefficient | |
| Similarity threshold between two nodes | |
| Activation threshold | |
| Activation times | |
| Number of alternative seed nodes | |
| Number of seed nodes |
| Data Set | M | N | MaxD | MinD | <D> | T |
|---|---|---|---|---|---|---|
| dolphins | 62 | 159 | 12 | 1 | 5 | 285 |
| ca-netscience | 379 | 914 | 34 | 1 | 4 | 2.8 K |
| netscience | 1.6 K | 2.7 K | 34 | 0 | 3 | 11.3 K |
| p2p-Gnutella08 | 6.3 K | 20.8 K | 97 | 1 | 6 | 7.1 K |
| Data Set | Number of Seeds | Algorithm Running Time (Seconds) | ||||
|---|---|---|---|---|---|---|
| OEL | Betweeness | DegreeDiscount | Degree | Greedy | ||
| dolphins | k = 5 | 0.00298 | 0.00182 | 0.00032 | 0.00005 | 0.03191 |
| k = 10 | 0.01894 | 0.00185 | 0.00038 | 0.00009 | 0.12566 | |
| k = 15 | 0.03092 | 0.00186 | 0.00043 | 0.00011 | 0.21542 | |
| k = 20 | 0.04092 | 0.00189 | 0.00044 | 0.00014 | 0.29721 | |
| k = 25 | 0.04787 | 0.00193 | 0.00049 | 0.00015 | 0.32708 | |
| k = 30 | 0.05485 | 0.00197 | 0.00049 | 0.00017 | 0.36907 | |
| k = 35 | 0.05883 | 0.00199 | 0.00051 | 0.00018 | 0.42582 | |
| k = 40 | 0.06383 | 0.00200 | 0.00054 | 0.00020 | 0.46381 | |
| k = 45 | 0.07879 | 0.00202 | 0.00062 | 0.00021 | 0.50266 | |
| k = 50 | 0.08076 | 0.00203 | 0.00064 | 0.00023 | 0.53354 | |
| ca-netscience | k = 5 | 0.03990 | 0.02873 | 0.00154 | 0.00034 | 1.01827 |
| k = 10 | 0.18747 | 0.02881 | 0.00156 | 0.00049 | 3.33109 | |
| k = 15 | 0.39994 | 0.02886 | 0.00165 | 0.00071 | 6.94841 | |
| k = 20 | 0.66926 | 0.02901 | 0.00166 | 0.00087 | 10.66042 | |
| k = 25 | 1.10308 | 0.02989 | 0.00173 | 0.00098 | 15.06065 | |
| k = 30 | 1.22966 | 0.03007 | 0.00179 | 0.00122 | 18.93035 | |
| k = 35 | 2.15124 | 0.03047 | 0.00194 | 0.00134 | 25.21152 | |
| k = 40 | 2.99598 | 0.03089 | 0.00199 | 0.00143 | 29.50102 | |
| k = 45 | 3.59338 | 0.03130 | 0.00202 | 0.00161 | 34.58282 | |
| k = 50 | 4.02626 | 0.03175 | 0.00213 | 0.00186 | 41.33540 | |
| netscience | k = 5 | 0.04986 | 0.57858 | 0.00516 | 0.00141 | 6.41057 |
| k = 10 | 0.18758 | 0.57941 | 0.00544 | 0.00210 | 23.41469 | |
| k = 15 | 0.50365 | 0.58139 | 0.00559 | 0.00272 | 47.60400 | |
| k = 20 | 0.90489 | 0.58219 | 0.00560 | 0.00352 | 73.26150 | |
| k = 25 | 1.59267 | 0.58240 | 0.00572 | 0.00411 | 109.89939 | |
| k = 30 | 2.92622 | 0.58416 | 0.00591 | 0.00480 | 142.60642 | |
| k = 35 | 3.62019 | 0.58432 | 0.00603 | 0.00554 | 194.50416 | |
| k = 40 | 4.41875 | 0.58439 | 0.00615 | 0.00612 | 223.39536 | |
| k = 45 | 5.28926 | 0.58608 | 0.00620 | 0.00674 | 264.54489 | |
| k = 50 | 6.62509 | 0.58975 | 0.00649 | 0.00757 | 320.53333 | |
| p2p-Gnutella08 | k = 5 | 0.06084 | 65.30030 | 0.03375 | 0.00722 | 53.91473 |
| k = 10 | 0.12068 | 66.15388 | 0.03440 | 0.01075 | 207.79511 | |
| k = 15 | 0.51766 | 66.58277 | 0.03485 | 0.01340 | 463.83709 | |
| k = 20 | 0.73904 | 66.98780 | 0.03491 | 0.01636 | 846.52928 | |
| k = 25 | 1.00833 | 66.99675 | 0.03512 | 0.01938 | 1280.93165 | |
| k = 30 | 1.26561 | 67.00286 | 0.03541 | 0.02290 | 1745.55211 | |
| k = 35 | 1.76430 | 67.02671 | 0.03574 | 0.02579 | 2256.53356 | |
| k = 40 | 2.01059 | 67.06866 | 0.03607 | 0.02986 | 2791.33391 | |
| k = 45 | 2.45837 | 67.18037 | 0.03656 | 0.03130 | 3371.98843 | |
| k = 50 | 2.81152 | 67.38176 | 0.03780 | 0.03610 | 4015.44560 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, B.; Zhang, J.; Bai, H.; Yang, Y.; He, Y. An Influence Maximization Algorithm for Dynamic Social Networks Based on Effective Links. Entropy 2022, 24, 904. https://doi.org/10.3390/e24070904
Fu B, Zhang J, Bai H, Yang Y, He Y. An Influence Maximization Algorithm for Dynamic Social Networks Based on Effective Links. Entropy. 2022; 24(7):904. https://doi.org/10.3390/e24070904
Chicago/Turabian StyleFu, Baojun, Jianpei Zhang, Hongna Bai, Yuting Yang, and Yu He. 2022. "An Influence Maximization Algorithm for Dynamic Social Networks Based on Effective Links" Entropy 24, no. 7: 904. https://doi.org/10.3390/e24070904
APA StyleFu, B., Zhang, J., Bai, H., Yang, Y., & He, Y. (2022). An Influence Maximization Algorithm for Dynamic Social Networks Based on Effective Links. Entropy, 24(7), 904. https://doi.org/10.3390/e24070904