1. Introduction
In computer science and mathematical optimization, nature–inspired methods are considered higher–level heuristics designed to find or generate potential solutions or to select a heuristic (partial search algorithm). These methods may provide near–optimal solutions in a limited amount of time. They properly work with incomplete or imperfect information or with bounded computation capacity [
1]. These metaheuristic algorithms are inspired by interesting natural phenomena, such as the species’ selection and evolution mechanisms [
2], swarm intelligence like the pathfinding skills of ants [
3] and the attraction capabilities of fireflies [
4], or the echolocation behavior of microbats [
5]. Even physical [
6] and chemical [
7] laws have also been studied to design metaheuristic methods. During the last two decades, metaheuristics have attracted the scientific community’s attention due to their versatility and efficient performance when adapted to intractable optimization problems [
8]. Different metaphors have guided the design of uncountable metaheuristic methods [
9]. By grouping the metaheuristic algorithms according to their inspiration source, it is possible to detect at least the bio–inspired computation class, swarm intelligence methods, and genetic evolution. In this context, the literature has shown that when these techniques come from similar analogies, they often share common behavioral patterns, mainly in the initial parameter task and the intensification and diversification processes [
10].
The evolutionary strategy of these bio–inspired techniques mainly depends on the appropriate balance between the diversification and the intensification phases. Diversification or exploration is the mechanism of entirely visiting new points of a search space. Intensification or exploitation is the process of refining those points within the neighborhood of previously visited locations to improve their solution quality [
11]. When the diversification phase operates, the resolution process reduces accuracy to improve its capacity to generate new potential solutions. On the other hand, the intensification strategy allows refining existing solutions while adversely driving the process to locally optimal solutions.
Although metaheuristic algorithms present outstanding performance [
12], they suffer from a common problem that arises when the exploration and exploitation process must be balanced, even more so when the number of variables in the problem increases. The greater the number of variables to handle, the more iterations will be necessary to find the best solution, thus converging the search in a specific area of the solution space [
13]. In this context, all solutions are similar and can be considered good quality. Therefore, the iterative process that tries to improve existing solutions stagnates as it cannot continue to improve without leaving the feasible zone [
1]. Different external methods have been used to solve this problem, such as random walk [
14,
15], roulette wheel [
16,
17,
18], tabu list [
19,
20], among others. These mechanics allow the solution to be modified to move it from that space area to another. This movement alters the solutions randomly. The non–deterministic behavior that governs the update procedures lacks information to discriminate when to operate and which part of the region to visit.
In this work, we propose an efficient exploration module for bio–inspired algorithms based on Shannon entropy, a mathematical component to measure the average level of uncertainty inherent in observations from random variables [
21,
22,
23]. The objective is to detect stagnation in local optimum, through a predictive entropy system, by computing entropy values of each variable. Next, solutions are moved toward a feasible region to find new and better solutions. This proposal is implemented and evaluated in three well–known population–based metaheuristics: particle swarm optimization, black hole algorithm, and bat optimization. The choice of these metaheuristics is supported by: (a) they work similarly because they belong to the same type of algorithms based on the swarm intelligence paradigm; (b) these population–based metaheuristics describe an iterative procedural structure to evolve their individuals (solutions), followed by many bio–inspired optimization algorithms; and (c) they have proven to be efficient optimization solvers for complex engineering problems. However, hybrid techniques such as [
24,
25] are also welcome. The Shannon diversification strategy runs as a background process and does not have an invasive role in the principal method.
Finally, to evidence that the proposed approach is a viable alternative that improves bio-inspired search algorithms, we evaluate it on a set of the most challenging instances of the Multidimensional Knapsack Problem (MKP), which is a widely recognized NP–complete optimization problem [
26]. MKP was selected because it is suitable for Shannon’s diversification strategy, it has a wide range of practical applications [
27], and it continues to be a hot topic in the operations research community [
28,
29]. Computational experiments run on 20 of the most challenging instances of the MKP taken from OR–Library [
30]. Generated results are evaluated with descriptive analysis and statistical inference, mainly a hypothesis contrast by applying non–parametric evaluations.
The rest of this manuscript is structured as follows.
Section 2 discusses the bibliographic search for relevant works in the field, fundamental concepts related to the diversification and the intensification phases, and it describes the information theory to measure uncertainty levels in random variables.
Section 3 exposes the formal statement for the stagnation problem.
Section 4 presents the developed solution, including the main aspects of the three bio–computing algorithms and the integration with the Shannon entropy. In
Section 5, the experimental setup is detailed, while
Section 5 discusses the main obtained results. Finally, conclusions and future work are included in
Section 8.
2. Related Work
During the last two decades, bio-inspired computing methods have attracted the scientific community’s attention due to their remarkable ability to adapt search strategies to solve complex problems [
31]. They are considered solvers devoted to tackling large instances of complex optimization problems [
32,
33]. These algorithms can be grouped according to their classification. Here, we can observe a division into nature-inspired vs. non-nature-inspired, population-based vs. single point search—or single solution—, dynamic vs. static objective function, single neighborhood vs. various neighborhood structures, and memory usage vs. memory-less methods, among many others [
34,
35,
36].
Metaheuristics can usually provide near–optimal solutions in a limited time when no efficient problem–specific algorithm pre–exists [
32]. After studying several metaheuristics, we can state that they operate similarly by combining local improvement procedures with higher-level strategies to explore the space of potential solutions efficiently [
37,
38,
39]. During the last decades, metaheuristic algorithms have been analyzed by finding improved techniques capable of solving complex optimization problems [
40]. This evolution has enabled them to merge theoretical principles from other science fields. For instance, Shannon entropy [
21,
22,
23] has been used in a population distribution strategy based on historical information [
41]. The study reveals a close relationship between the solutions’ diversity and the algorithm’s convergence. Also, ref. [
42] proposed a multi–objective version of the particle swarm optimization algorithm enhanced by the Shannon entropy. The authors propose an evolution index of the algorithm to measure its convergence. Results show that the proposal is a viable alternative to boost swarm intelligence methods, even in mono–objective procedures. Another work that deals with metaheuristics enhanced by the Shannon entropy to treat multi–objective problems is [
43]. Here, the uncertain information was employed to choose the optimum solution from the Pareto front. Shannon’s strategy was slightly lower than other proposed decision–making techniques.
Now, by considering smart alterations in search processes, we analyze [
44], which proposes an entropy–assisted particle swarm optimizer for solving various instances of an optimization problem. This approach allows for adjusting the exploitation and exploration phases simultaneously. The reported computational experiments show that this work provides flexibility to the bio–inspired solver to self–organize its inner behaviors. Following this line of research, in [
45], a hybrid algorithm between Shannon entropy and two swarm methods is introduced to improve the yield, memory, velocity, and, consequently, the move update. In [
46], Shannon entropy is integrated into a chaotic genetic algorithm for taking data from solutions generated during the execution. This process runs in deterministic time series and operates from the initial population strategy. Another work that develops a similar proposal is detailed in [
47]; here, the authors present a hybrid algorithm that includes the Shannon entropy in the evolving process of particle swarm optimization. The authors measure the convergence of solutions based on the distance between each solution and the best overall solution. They conclude that the algorithm can satisfactorily obtain outstanding results, especially regarding fitness evolution and convergence rate.
Following the integration between bio–inspired solvers and the Shannon entropy, we analyze [
48], where the information component allows measuring the population diversity, the crossover probability, and the mutation operator to adjust the algorithm’s parameters adaptively. Results show that it is possible to generate a satisfactory global exploration, improve convergence speed, and maintain the algorithm’s robustness. The same approach is explored in [
49]. Again, the convergence speed and the population diversity are key factors, balanced to improve the resolution procedure. Finally, in [
50,
51], the Shannon entropy allows handling the instance of the optimization problem. The first work solves the portfolio selection problem by minimizing the number of transactions, while the second computes the minimum loss and cost of the reactive power planning.
5. Experimental Setup
To suitably evaluate the performance of the improved swarm intelligence methods, a robust performance analysis is required. For that, we contrast the best solutions achieved by metaheuristics to the best–known result of the benchmark.
Figure 3 depicts the procedures involved in thoroughly examining the enhanced metaheuristics. We design goals and suggestions for the experimental phase to show that the proposed approach is a viable alternative for enhancing the inner mechanisms of metaheuristics. Solving time is computed to determine the produced gap when the Shannon strategy runs on the bio–inspired method. We evaluate the best value as a vital indicator for assessing future results. Next, we use ordinal analysis and statistical testing to evaluate whether a strategy is significantly better. Finally, we detail the hardware and software used to replicate computational experiments. Results will visualize in tables and graphics.
A set of optimization problem instances were solved for the experimental process and, more specifically, to measure the algorithms’ performance. These instances come from OR–Library, which J.E. Beasley originally described in 1990 [
56]. This “virtual library” has several test data sets of different natures with their respective solutions. We take 20 binary instances of the Multidimensional Knapsack Problem. Instances are identified by a name and a number, in the form MKP1 to MKP20, respectively.
Table 1 details the size of each instance.
The exact methods have not solved the instances from MKP17 to MKP20. For this reason, we use unknown to describe that this value has not yet been found.
The MKP is formally defined in Equation (
15):
where
describes whether the object is included or not in a knapsack, and the
n value defines the total number of objects. Each object has a real value
that represents its profit and is used to compute the objective function. Finally,
stores the weight for each object in a knapsack
k with maximum capacity
. As can be seen, this is a combinatorial problem between including or not an object. The execution of continuous metaheuristics in a binary domain requires a binarization phase after the solution vector changes [
60]. A standard Sigmoid function compared to a uniform random value
between 0 and 1 was employ as a transformation function, i.e.,
, then a discretization method is employed, in this case, if
. Otherwise,
.
The performance of each algorithm is evaluated after solving each instance 30 times on it. Once the complete set of outputs of all the executions and instances has been obtained, an outliers analysis is performed to study possible irregular results. Here, we detect influence outliers using the Tukey test, which takes as a reference the difference between the first quartile (Q1) and the third quartile (Q3), or the interquartile range. In our case, in box plots, an outlier is considered to be 1.5 times that distance from one of those quartiles (mild outlier) or three times that distance (extreme outlier). This test was implemented by using a spreadsheet, so the statistics are calculated automatically. Thus, we remove them to avoid distortion of the samples. Immediately, a new run is launched to replace the eliminated solution.
In the end, descriptive and statistical analyses of these results are performed. For the first one, metrics such as max and min values, mean, standard quasi–deviation, median, and interquartile range are used to compare generated results. The second analysis corresponds to statistical inference. Two hypotheses are contracted to evidence a major statistical significance: (a) test of normality with Shapiro–Wilk and (b) test of heterogeneity by Wilcoxon–Mann–Whitney. Furthermore, it is essential to note that given the independent nature of instances, the results obtained in one of them do not affect others. The repetition of an instance neither involves other repetitions of the same instance.
Finally, all algorithms were coded in Java programming language. The infrastructure was a workstation running Windows 10 Pro operating system with eight processors i7 8700, and 32 GB of RAM. Parallel implementation was not required.
6. Discussion
The first results are illustrated in
Table 2, which is divided into three parts: (a) number of best reached, (b) minimum solving time, and (c) maximum solving time. Results show that modified methods (S–PSO, S–BAT, and S–BH) exhibit better performance achieving greater optimum values than their native versions.
Regarding the minimum and maximum solving times, PSO and S–PSO have similar performance, and a significant difference is not appreciable, being who better yield shows of all studied techniques. When BAT and S–BAT are contrasted, we again note that the Shannon Entropy strategy does not cause a significant increase in required solving time by the bio–solver algorithm, except in a few instances where BAT needs less time than S–BAT. Now, let us compare the results generated by the black hole optimizer and the improved S–BH. It is possible to observe that, in general terms, there is no significant difference between the minimum solving times required by the original bio–inspired method and its enhanced version.
To robust the experimental phase, we evaluate the quality of solutions based on the number of optimal findings. Thus, taking the generated data, we note that the modified algorithms S–PSO, S–BAT, and S–BH perform better than their native versions. Based on the result in
Table 3 regarding the solution quality, S–PSO has a better performance than PSO. The latter is because S–PSO has a smaller maximum RPD, implying that his solutions are larger. Moreover, considering the standard deviations, we can see that values achieved by PSO are usually lower than those generated by S–PSO. Therefore, the results distribution and their differentiation concerning the average is better in the algorithm based on the Shannon entropy.
The result of PSO in the median RPD is equal to or slightly lower than S–PSO. Thus, PSO has a slightly better performance. For the average RPD, both S–PSO and PSO had a similar performance. Finally, considering that the proposed approach S–PSO found a more significant number of optima, with a higher quality of solutions and a lower deviation, then we can conclude that S–PSO has a better general performance than native PSO.
The results shown in
Table 4 show how S–BAT presents a much higher general performance than his native version. S–BAT has, for the 20 instances, maximum, mean, and average RPDs equal to, or less than, those presented by the native bat optimizer, in addition to having a smaller standard deviation for their values. This set of characteristics implies that the solutions found by S–BAT are significantly larger than those found by the bat algorithm, and, therefore, have a higher general performance compared to its native version.
Concerning
Table 5, we can infer that S–BH algorithm has a higher general performance than the BH algorithm. There are no significant differences between both algorithms in the mean RPD and average RPD, but the maximum RPD in 18 of the 20 instances is lower in S–BH. The above means that the solutions found by S–BH have a larger size and, therefore, a better performance. On the other hand, concerning its standard deviations, in 13 of the 20 instances, the native version of the algorithm has a lower variation. Therefore, both algorithms generally present a high dispersion in their data. Since both algorithms have a similar widespread distribution, based on the number of optima found, we can conclude that the S–BH algorithm has a higher overall performance because it can find a more significant number of better quality optima.
Figure 4 shows the convergence of the solutions found by PSO and S–PSO. The above indicates how the solution changes as the iterations go by (increases its value).
For all instances, in early iterations, S–PSO has at least a similar performance to PSO. As the execution progresses, S–PSO gradually acquires higher–value solutions. In MKP instances 2, 7, 9, 10, and 11, both algorithms have the same final performance. S–PSO is superior in all other instances (15 of 20).
Also,
Figure 5 shows the dispersion of the values found by both algorithms. The above allows knowing how close the values found are to their respective medians and their quartiles and extreme values. A better spread is smaller in size (more compact) and/or has larger medians and tails. As with convergences, the spreads of the S–PSO algorithm are usually at least similar to those of PSO. For MKP instances 3, 4, 5, 8, 10, and 12, the S–PSO spread is slightly lower. In MKP instances 1 and 9, both algorithms have the same dispersion. For the remaining 12 instances, S–PSO has values with lower dispersion and/or higher median. Therefore, it is considered to have better performance.
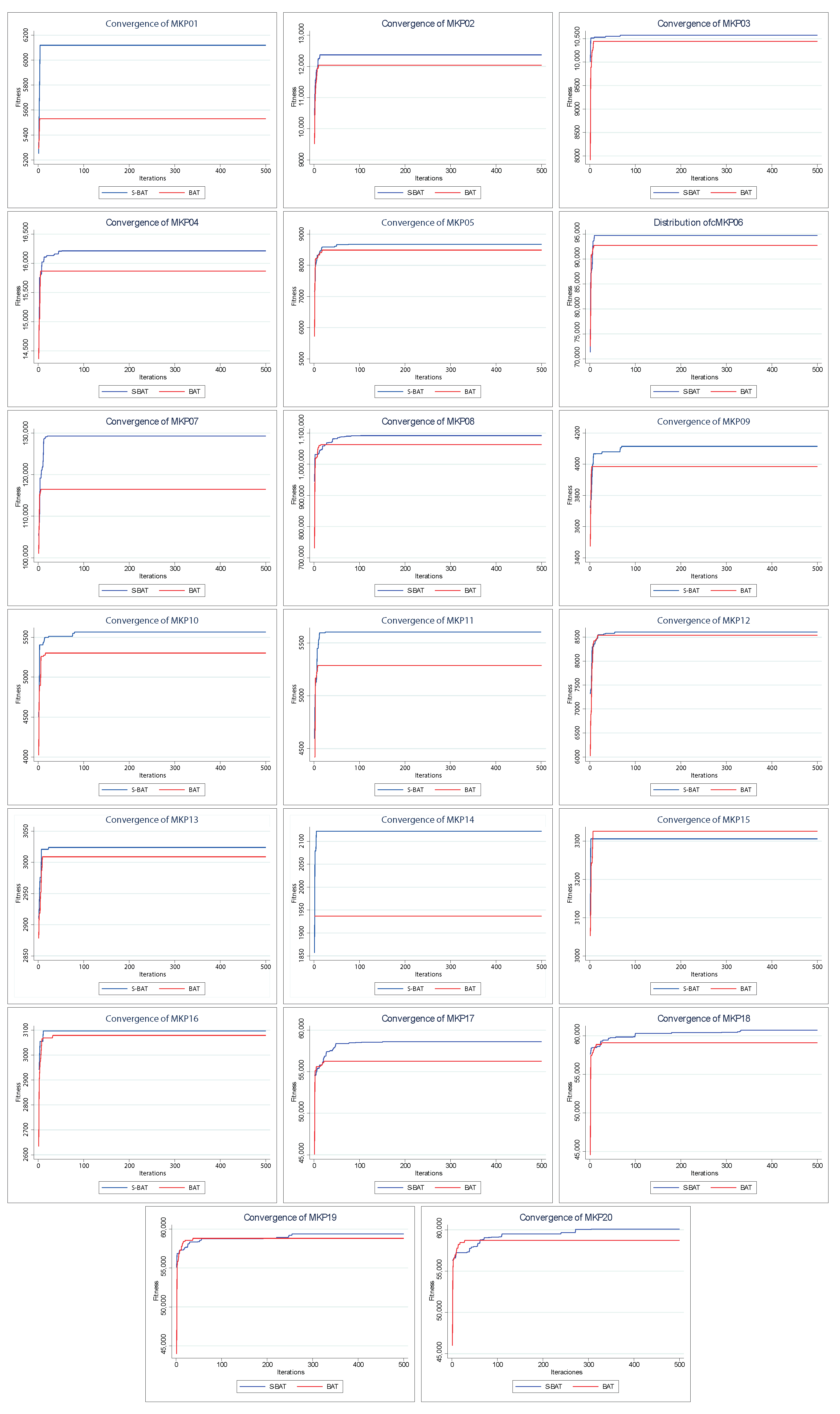
Figure 6 shows the convergence of the solutions found by BAT and S–BAT. In 19 of the 20 instances, S–BAT outperforms BAT. BAT is superior only in the MKP 15 instance. Both algorithms present similar values in early iterations, but S–BAT overlaps significantly as the execution progresses. On the other hand,
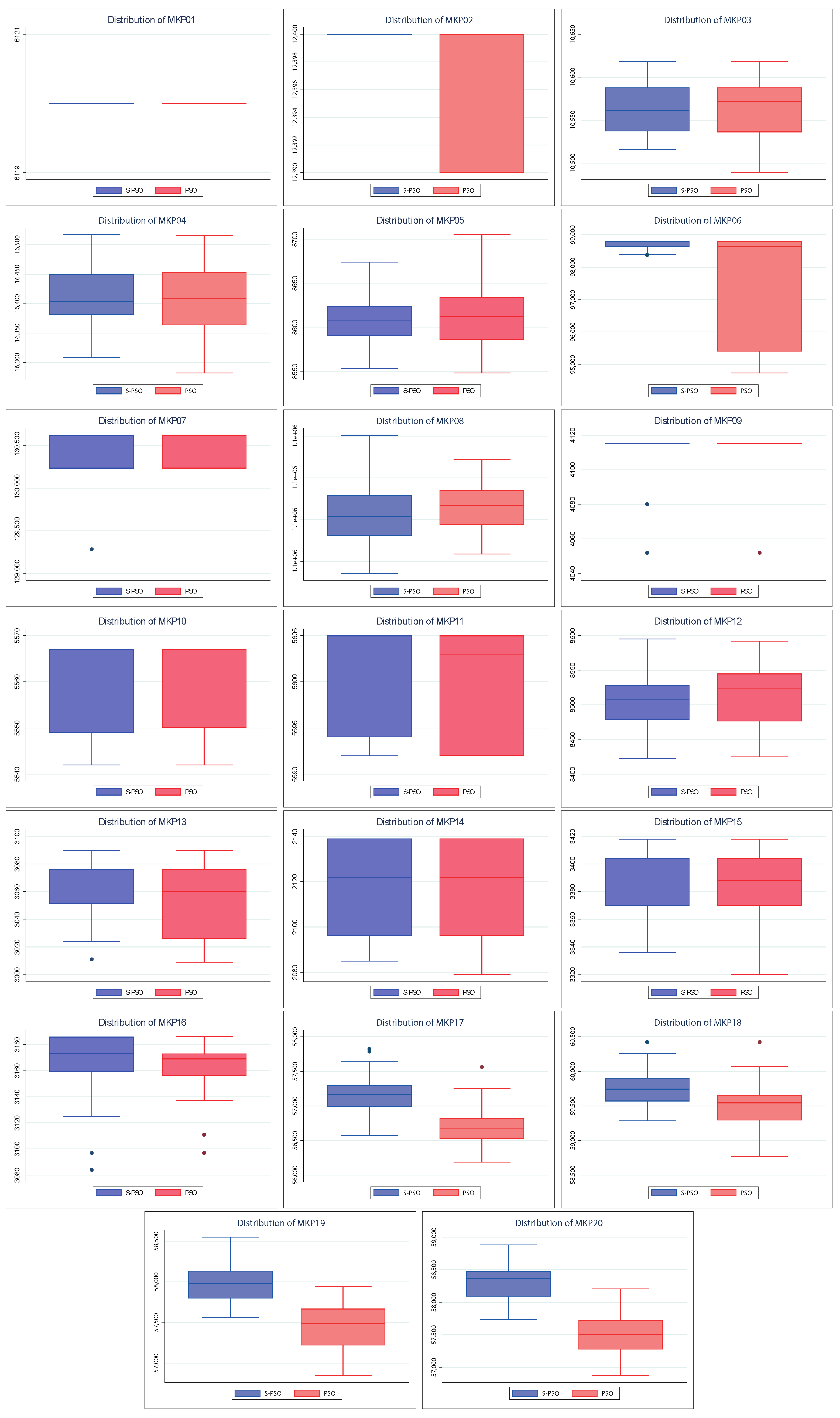
Figure 7 shows the dispersion of the values found by both algorithms. In the 20 instances, the dispersion of the values found by S–BAT is smaller, presenting larger values and closer to their medians. Given the above, S–BAT has a significantly higher overall performance than BAT.
Figure 8 shows the convergences of the solutions found by BH and S–BH. For MKP instances 1, 3, 6, 16, 17, and 18, both algorithms present similar final values, with S–BH slightly higher. Only in three instances (MKP 2, 9, and 11) is the native BH algorithm slightly superior to S–BH. In the remaining eleven instances S–BH presents values significantly higher than BH.
Furthermore,
Figure 9 shows the dispersion of the values found by both algorithms. Because the behavior of these algorithms is more similar to each other than the previously seen ones (PSO and BAT), it is necessary to highlight that our performance approach is based on the largest values (maximization problem). Given the above, considering the MKP instances 1, 2, 5, 9, 17, 18, 19, and 20, we can say that S–BH has a better dispersion than BH. The above is because it has a median slightly higher than BH or larger extreme values. For MKP 6, 8, and 11 instances, native BH has superior performance for similar reasons. In the MKP 14 instance, both algorithms have the same dispersion. For the remaining eight instances, S–BH has a significantly higher dispersion in quality.
Finally, considering everything mentioned above, we can say that approximately half of the S–BH instances have at least a dispersion equal to or higher (quality) than that of BH. Therefore, it is considered to have better performance.
7. Statistical Analysis
To evidence a statistical significance between the native bio-inspired algorithm and its improved version by the Shannon strategy, we perform a robust analysis that includes normality assessment and contrast of hypotheses to determine if the samples come or not from an equidistributed sequence. Firstly, Shapiro–Wilk is required to study the independence of samples. It determines if observations (runs per instance) draw a Gaussian distribution. Then, we establish
as samples follow a normal distribution. Therefore,
assumes the opposite. The traditional limit of
p-value is
, for which results under this threshold state the test is said to be significant (
rejects).
Table 6 shows
p-values obtained by native algorithms and their enhanced versions for each instance. Note that ∼0 indicates a small
p-value near 0, and the hyphen means the test was not significant.
About 63% of the results confirm that the samples do not follow a normal distribution, so we decide to employ the non-parametric test Mann—Whitney—Wilcoxon. The idea behind this test is the following: if the two compared samples come from the same population, by joining all the observations and ordering them from smallest to largest, it would be expected that the observations of one and the other sample would be randomly interspersed [
61].
To develop the test, we assume
as the null hypothesis that affirms native methods generate better (smaller) values than their versions improved by the Shannon entropy. Thus,
suggests otherwise.
Table 7 exposes results of contrasts. Again, we use
as the upper threshold for
p-values and smaller values allow us to reject
and, therefore, assume
as true. To detail the results obtained by the test, we deployed more significant digits, and we applied hyphens when the test was not significant.
Finally, and consistent with the previous results, the test strongly establishes that the bat optimizer is the bio–inspired method that benefits the most from the Shannon strategy (see
Figure 6 and
Figure 7). The robustness of this test is also evident with PSO and BH. We can see that the best results are adjusted to those already shown. For example, S–PSO on MKP02 and MKP06 instances is noticeably better than its native version (see
Figure 4 and
Figure 5). Similarly, S–BH on MKP12, MKP13, MKP15, and MKP16 instances performs better than the original version (see
Figure 8 and
Figure 9).
8. Conclusions
Despite the efficiency shown over the last few years, bio-inspired algorithms tend to stagnate in local optimal when facing complex optimization problems. During iterations, one or more solutions are not modified; therefore, resources are spent without obtaining improvements. Various methods, such as Random Walk, Levy Flight, and Roulette Wheel, use random diversification components to prevent this problem. This work proposes a new exploration strategy using the Shannon entropy as a movement operator on three swarm bio-inspired algorithms: particle swarm optimization, bat optimization, and black hole algorithm. The mission of this component is first to recognize stagnated solutions by applying information given by the solving process and then provide a policy to explore new promising zones. To evidence the reached performances by three optimization methods, we solve twenty instances of the 0/1 multidimensional knapsack problem, which is a variation of the well–known traditional optimization problem. Regarding the solving time, the results show that including an additional component increases the required time to reach the best solutions. However, in terms of accuracy to achieve optimal solutions, there is no doubt that this component significantly improves the resolution process of metaheuristics. We performed a statistical study on the results to ensure this conjecture was correct. As samples are independent and do not follow a normal distribution, we employ the Wilcoxon—Mann—Whitney test, a non-parametric statistical evaluation, to contrast the null hypothesis that the means of two populations are equal. Effectively, the swarm intelligence methods improved by the Shannon entropy exhibit significantly better yields than their original versions.
In future work, we propose comparing this proposal against other entropy methods, such as linear, Rényiand, or Tsallis, because they work an occurrence probability similar to Shannon. On the other hand, this research opens a challenge to analyze data generated by metaheuristics when internal search mechanisms operate. For example, the local search, exploration, or exploitation processes can converge on common ground. If this information is used correctly, we can be in front of powerful self-improvement techniques. In this scenario, we can design data-driven optimization algorithms capable of solving the problem and self-managing to perform this resolution in the best possible way.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}