1. Introduction
Driving is a process of continuous sensing, processing the sensory information, making decisions and putting these decisions into action. Some parts of this loop can be done by humans, and some by machines. As all decisions related to driving are based on sensory information, sensing is maybe the most important part of the driving process. Humans are well equipped for sensing, but they are not perfect. This is why, for decades, researchers have tried to devise better sensors, and better and faster algorithms, to help perceive the environment, help the driver and increase traffic safety.
While most of the research and development effort has been dedicated to adding intelligent sensing capabilities to the vehicles themselves, especially to the higher end ones, driving assistance applications on mobile devices are a less costly alternative. Facilitated by the rapid evolution of the processing power of the smart mobile devices, and by the increasingly complex and accurate sensors that come embedded into these devices, driving assistance based on image and signal processing on mobile devices may quickly become a reliable tool for traffic safety.
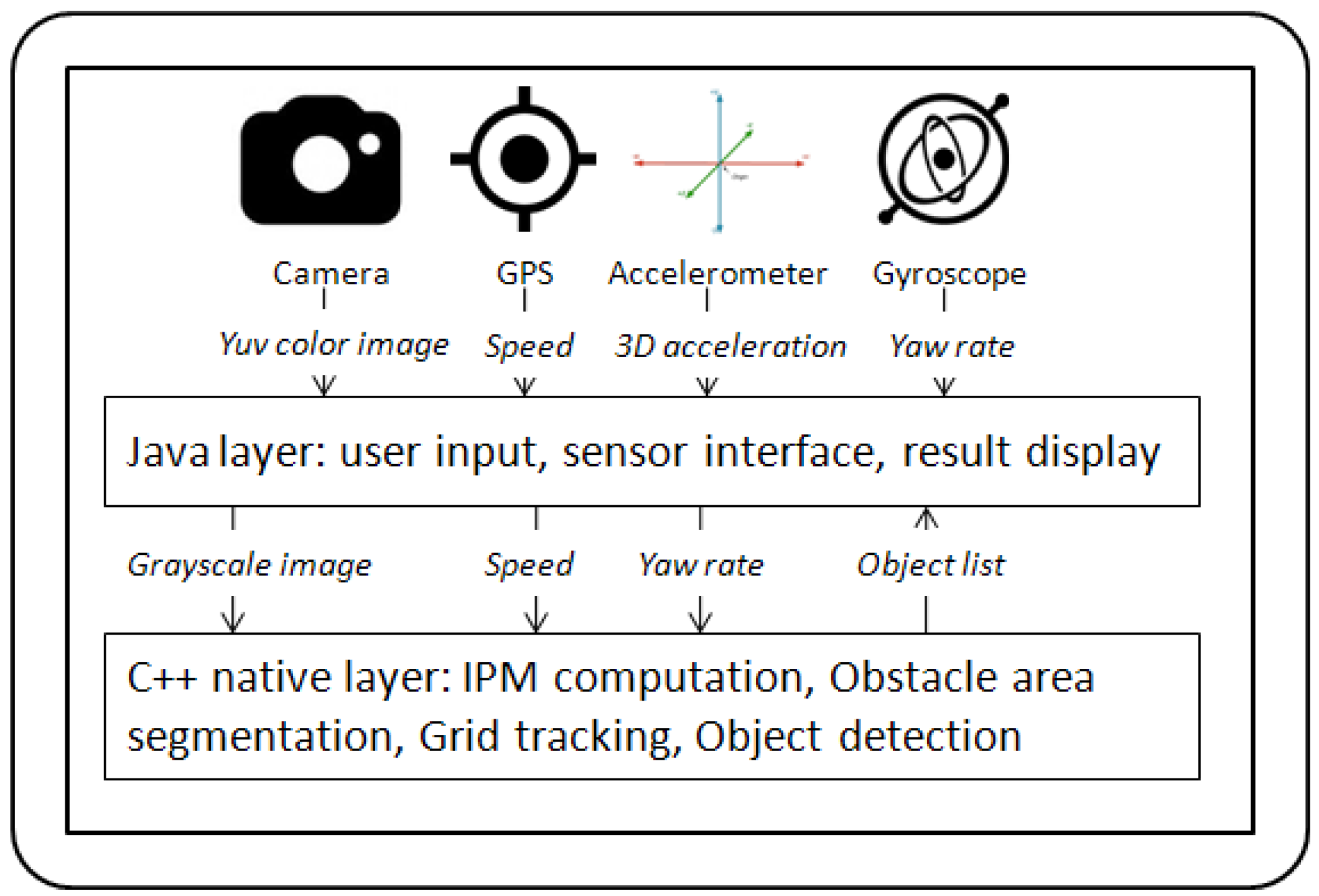
This paper presents a method for perceiving the obstacles from the dynamic driving environment based on on-board, real time processing of the images from the camera of a smart mobile device (smartphone, and tablet) that can be fitted behind the windshield of a car. Besides the image sequence stream, the algorithms will use other sensors, such as the GPS receiver, the gyroscope, and the accelerometer to know the motion of the user’s car, and delimit this motion from the proper motion of the obstacles.
The method proposed in this paper relies on segmenting obstacle areas from an image, after the perspective effect is removed, followed by using these areas to update a probabilistic occupancy grid, which is able to filter out some detection errors, and extract dynamic properties for each grid cell. The estimated occupied grid cells, having also speed and orientation, are grouped into obstacles. In this way, no assumption about the nature or shape of the obstacle is made, and detected obstacles that are the system’s result will have position, size, speed and orientation assigned to them.
2. Related Work
The set of driving assistance applications available includes iOnRoad, Drivea, and Movon FCW. iOnRoad [
1] is one of the first augmented driving solutions available for iOS and Android, using the smartphone’s camera and GPS receiver to provide time to collision to the detected vehicle in front of the ego-vehicle, and for lane departure warning. A similar application is Drivea [
2], which provides obstacle collision warning, lane departure warning, and warning about speeding. A newer application, Movon FCW [
3] is one of the few applications that can detect incoming cars, or cars that are not in full view, and can provide actual distance information.
In the research community, most of the recent obstacle detection efforts have been focused on sensors or sensory solutions that are able to deliver 3D data directly: radar, laser, or stereovision [
4]. While some mobile devices are equipped with stereo cameras, which can be used for short distance accurate detection of obstacles [
5], most devices are only capable of monocular vision.
Monocular obstacle detection faces multiple challenges, the most important being that there is no direct 3D information, and no direct, geometrical way of separating the obstacles from the road features, or the closer obstacles from the background. For the identification of the obstacle regions in the image, solutions include region segmentation [
6,
7], motion based analysis [
8,
9], or appearance analysis, either through heuristics such as symmetry [
10,
11], or through the use of machine learning [
12,
13]. For extracting the 3D position of the obstacle, monocular vision uses constraints imposed on the structure of the environment, such as the condition that the road is flat, which leads to the measurement of the points on the road by Inverse Perspective Mapping (IPM) [
14,
15].
The lack of 3D information considerably affects the robustness of an obstacle detection algorithm, and therefore most monocular applications make assumptions about the obstacles. Generic obstacle detection, independent of type or size, is much more difficult to achieve. While stereovision solutions, or other ranging solutions, can also employ assumptions about the obstacle’s nature, it also allows generic environment perception, such as in the form of dynamic occupancy grids [
16], especially if the stereovision information is dense. The solution proposed in this paper comes to bring this power of generic environment perception to the monocular sensor as well, and it does so by using the dynamic particle-based occupancy grid as the common intermediate representation, a middle environment layer between the image data and the discrete obstacle layer. The use of a probabilistic, dynamic middle layer allows inference about the presence of obstacle parts in the scene, and about their motion, and also allows modeling the uncertainties of the sensing methodology.
In order to achieve a generic environment perception, a generic scene segmentation algorithm has to be employed. This paper presents such a solution, which is a refinement of a preliminary result of ours, based on IPM images, described in [
17].
3. Solution Description
3.1. Overview
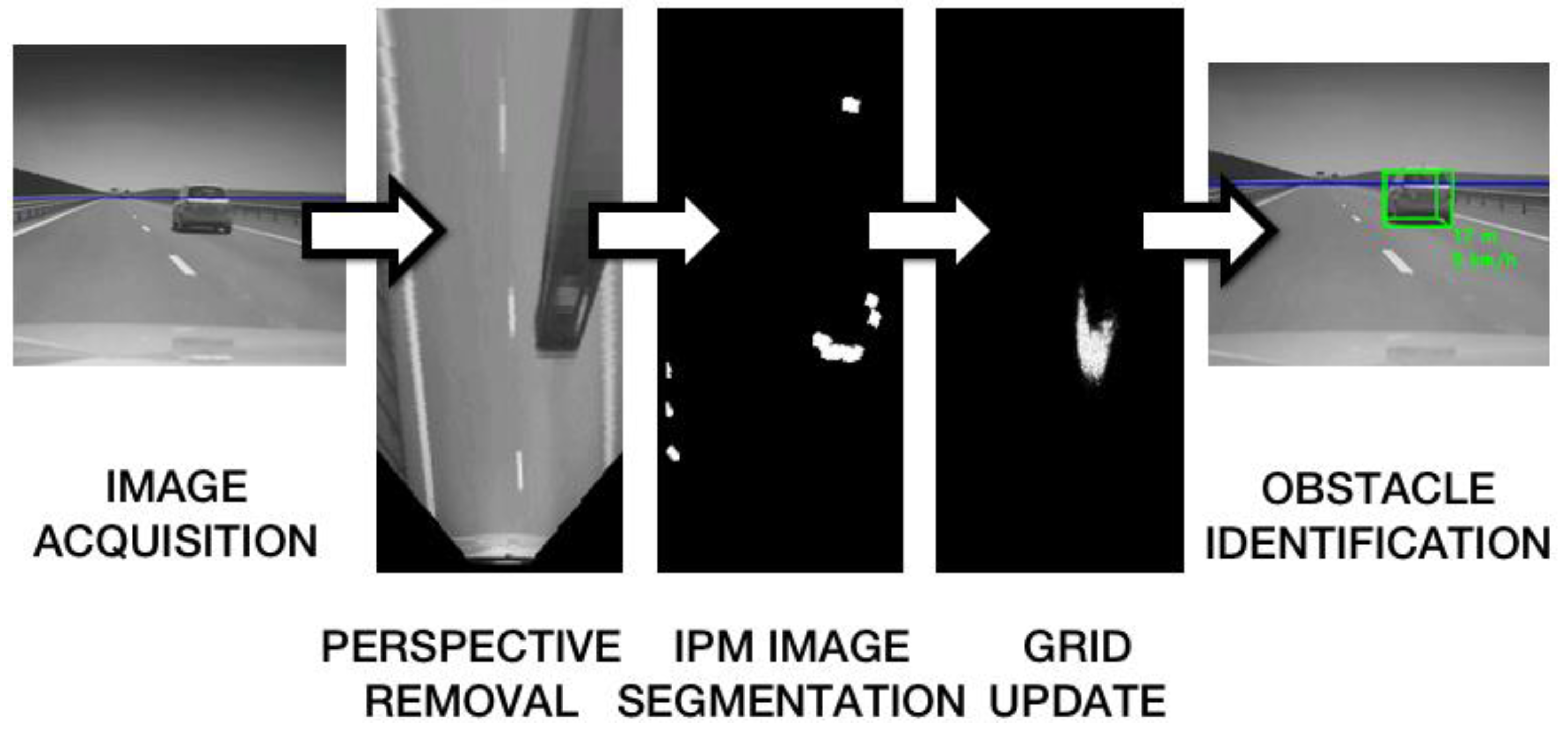
The process starts with the acquisition of an image from the mobile device’s camera. The image is then transformed into a bird’s eye view of the road by Inverse Perspective Mapping, using the camera calibration parameters. The IPM image is segmented along rays staring from the camera position, and a hypothetic obstacle map is generated. The obstacle map is used to update the particle based occupancy grid. In the update process, the vehicle motion information (speed and yaw rate) is obtained from the available sensors of the mobile device (GPS for speed, gyroscope or accelerometer for yaw rate). The occupancy grid attaches to each cell of the top view world an occupancy probability and a speed probability density.
The estimated grid cells occupancy probabilities, and the speed vectors, are used in the process of obstacle extraction. The process is depicted in
Figure 1.
3.2. Removing the Perspective Effect
Assuming that the road is flat, the perspective image can be remapped in such a way that the features that belong to the road surface are displayed as they are seen from above and their lateral and longitudinal coordinates in the real world are proportional to the pixel coordinates (
Figure 2).
In the IPM image, the obstacles are deformed, since they do not belong to the road surface and therefore their features do not obey the road geometry. For this reason, only the point of contact between the obstacle and the road is relevant for the next steps of the obstacle detection algorithm, as its position can be directly related to the position of the obstacle in the real world. The camera is assumed to be calibrated (the calibration methodology is described in
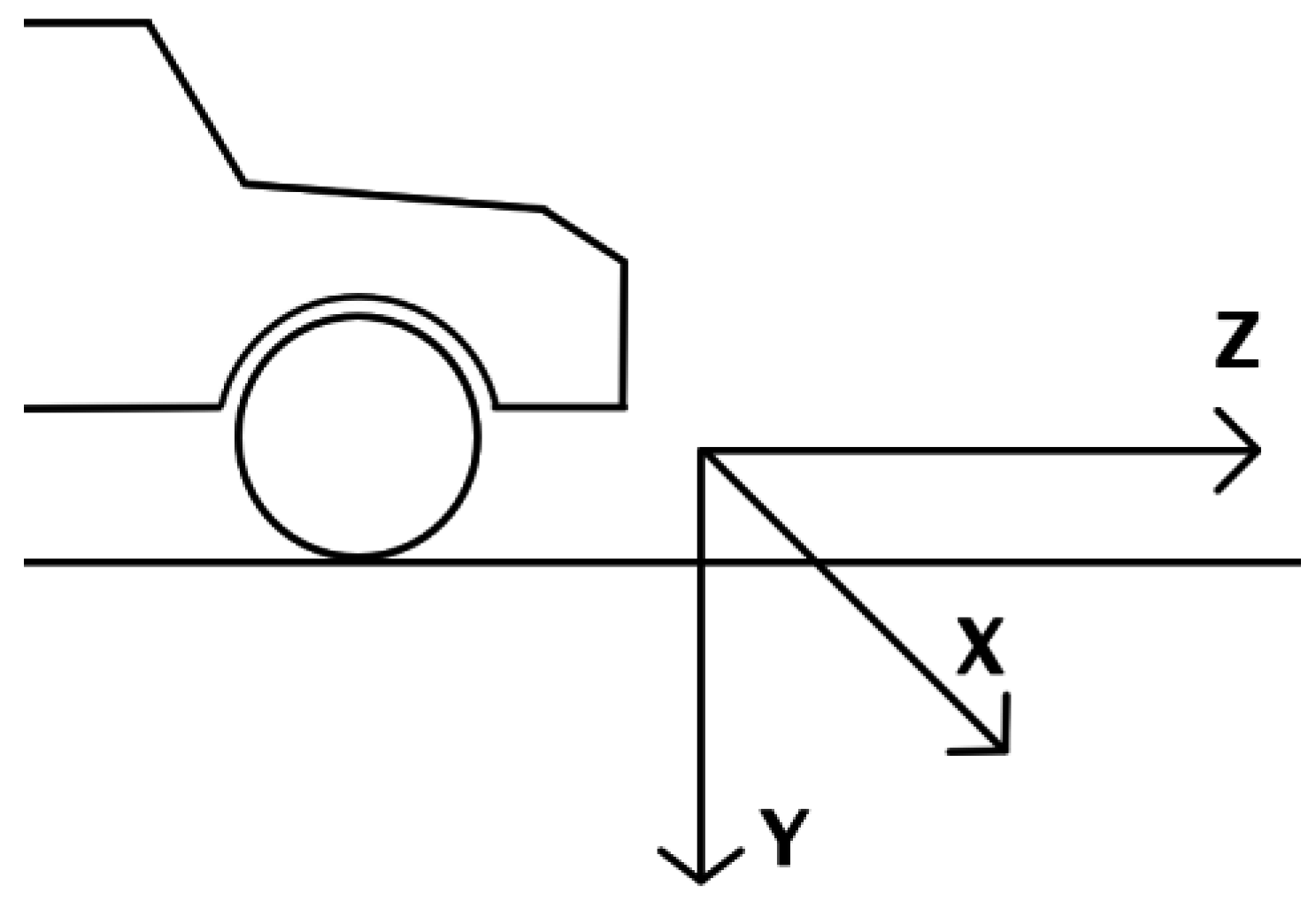
Section 4), therefore the correspondence between any point in the 3D world and its corresponding projected pixel in the image plane is known. The 3D coordinate system is assumed to have the origin on the ground, below the camera, the x axis pointing to the driver’s right, the z axis indicating the direction of travel, and the y axis the height above the road (xOz) plane.
The removal of the perspective effect is performed using Algorithm 1:
| Algorithm 1: IPM Transformation |
| 1 Input: Source image I |
| 2 Output: IPM image IT |
| 3 For each pixel of coordinates (uT, vT) of IT |
| 4 x = k uT + x0 |
| 5 z = j vT + z0 |
| 6 y = 0 |
| 7 (u, v) = Projection(xW, yW, zW) |
| 8 IT(uT, vT) = I(u, v) |
| 9 End For |
The constants k, j, x0 and z0 are chosen in such a way that the most relevant portion of the road plane is displayed in the remapped image. The projection function uses the camera intrinsic and extrinsic parameters, which compose the projection matrix, for mapping a 3D point (expressed in the 3D world coordinates x, y and z), to the image plane.
The completely flat road assumption is restrictive, and the world will often not comply with it, due to the road geometry and, most often, to the balancing of the observer vehicle. This error is modeled in the grid measurement model used for grid state update.
3.3. Finding the Candidate Obstacle Regions
From the top view IPM image we have to identify the areas corresponding to the contact points between the obstacle and the road. Since we want our system to be as form-independent as possible, we will not use shape-based clues, such as symmetry.
In the IPM image, an upright obstacle has the tendency to expand radially from the camera. We use this property to scan the IPM image with rays for each angular degree of the field of view, with each ray converging on the camera position point (
Figure 3).
For each scan ray, the angle and the minimum and maximum distance from the camera are known. If an obstacle is present on such a ray, its position along the ray must be found. As the obstacles do not comply with the flat road assumption of the IPM transformation, they will be deformed such that they will most likely stretch for the whole remainder of the ray. Thus, the only relevant information about the obstacle is its starting distance along the ray, the point where the obstacle touches the ground.
In order to find the obstacle distance along the scan ray, the grayscale values of the IPM image corresponding to the ray are recorded in a vector
gα(
d),
α denoting the angle of the ray, and
d being the distance from the camera. For each candidate obstacle distance
d, the following values are computed:
These quantities are the mean intensity values for the proximal region (
), middle region (
) and distal region (
) of a ray of angle α with respect to the camera orientation, and the hypothetical obstacle distance
d. Based on these mean values, we have to decide if a distance
d may in fact be a distance to an obstacle touching the road. First, a binary function of
d is designed, indicating whether the intensity profile of the ray of angle α supports the hypothesis of an obstacle being present at the distance
d.
In Equation (4), σ is the graylevel standard deviation of the IPM image, a measure of the image contrast. Intuitively, Equation (4) states that an obstacle point of contact with the road should be darker than the road leading to it, and also darker than the rest of the obstacle along the ray. The shadow area below a car passes this test. Darker areas that continue along the ray are also taken into consideration. Off course, this assumption is valid only during daytime, and will not be valid at night, so this solution is not aplicable at night.
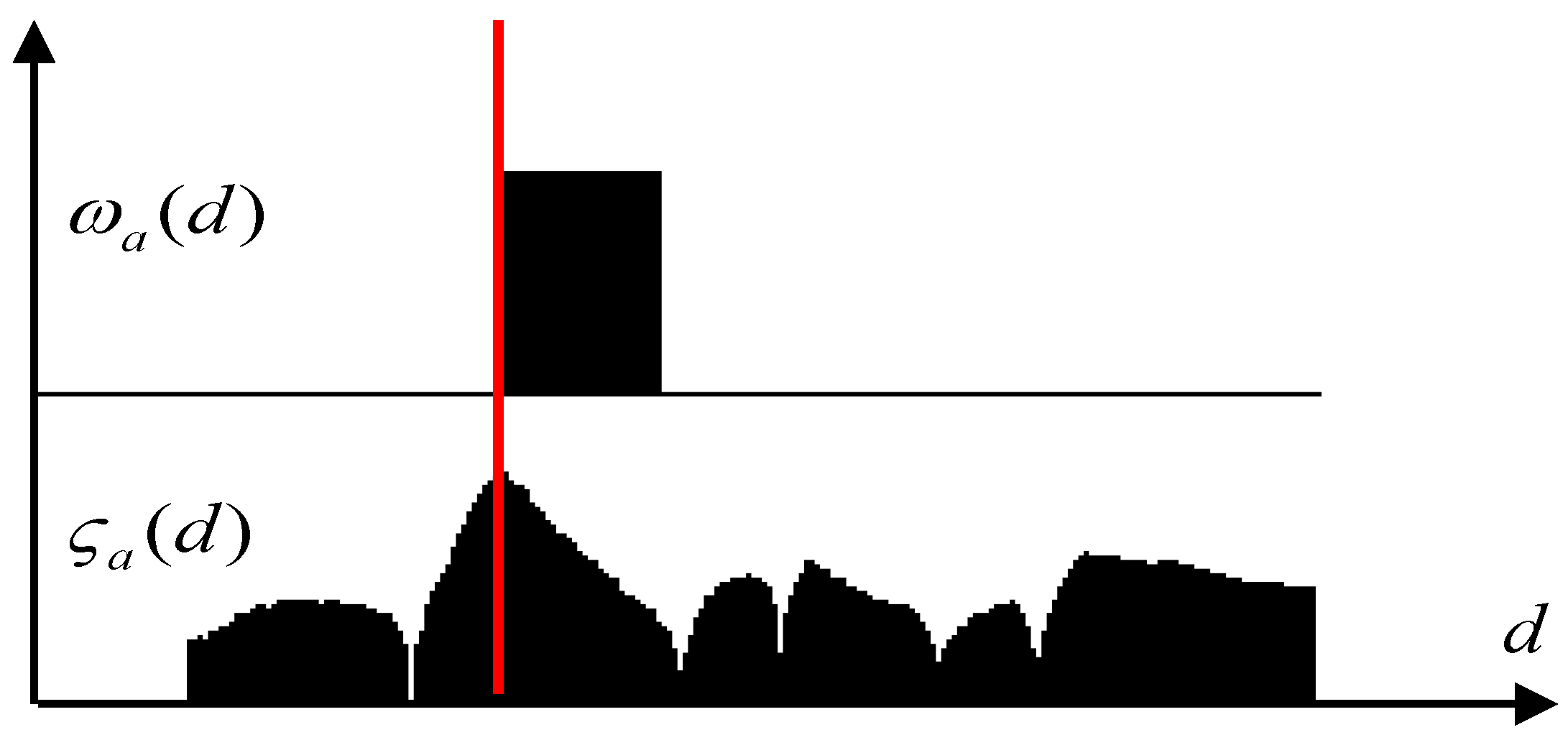
If multiple candidate distances for a ray have
> 0, the best candidate has to be selected. A continuous score function is defined:
Out of all the values
d that have
> 0, the one having a maximum
is kept as the obstacle position. The process is depicted in
Figure 4: on the first row the binary function
is shown, and the second row depicts the continuous score function. The red line indicates the choice for the obstacle’s position.
After the obstacles are located on each ray, a binary grid is constructed from these results (
Figure 5).
3.4. The Particle-Based Occupancy Grid
The particle based occupancy grid is a freeform dynamic world representation, which tracks a bird’s eye grid view of the world, in terms of occupancy (presence of an obstacle) and speed vector probability density for each grid cell.
The dynamic occupancy grid depicts the obstacles as composed of particles having individual position and speed. Each discrete grid cell will thus contain a certain number of particles, each particle having its own speed vector. The occupancy probability of each grid cell is described by the number of particles in that cell (more particles, more likely the cell is occupied by an obstacle). The particles in this algorithm can be regarded in two ways: as hypotheses, such as in the case of particle filtering algorithms such as CONDENSATION [
18], but also as actual building blocks of the environment, which can move from one cell to another in order to model the dynamic evolution of the environment (and, by doing this, achieve the prediction of the environment’s state).
The world is represented by a 2D grid, mapping the bird’s eye view 3D space into discrete 20 cm × 20 cm cells. The aim of the grid tracking algorithm is to estimate the occupancy probability of each grid cell, and the speed vector components on each axis (longitudinal and lateral).
Considering a coordinate system where the
z axis points towards the direction of the ego-vehicle, and the
x axis points to the right, the obstacles in the world model are represented by a set of particles:
Each particle i has a position in the grid, described by the row ri (a discrete value of the distance in the 3D world z) and the column ci (discrete value of the lateral position x), and a speed, described by the speed components vci and vri. An additional parameter, ai, describes the age of the particle, since its creation. The purpose of this parameter is to facilitate the validation and the speed estimation process, as only particles that survive in the field for several frames are taken into consideration.
The total number of particles in the scene
NS depends on the scene load (the number of obstacles in the field), and is not known a-priori, but updated each time a new obstacle cell is discovered by measurement. Having the population of particles in place, the occupancy probability of a cell
C is estimated as the ratio between the number of particles whose position coincides with the position of the cell
C and the total number of particles allowed for a single cell,
NC.
The number of allowed particles per cell NC is a constant of the system. In setting its value, a trade-off between accuracy and time performance should be considered. A large number means that on a single cell multiple speed hypotheses can be maintained, and therefore the tracker can have a better speed estimation, and can handle fast moving objects better. However, the total number of particles in the scene will be directly proportional with NC, and therefore the speed of the algorithm will decrease. The current value for NC is 50.
The speed of a grid cell can be estimated as the average speed of its associated particles, if we assume that only one obstacle is present in that cell.
Thus, the population of particles is sufficiently representative for the probability density of occupancy and speed for the whole grid. Multiple speed hypotheses can be maintained simultaneously for a single cell, and the occupancy uncertainty is represented by the varying number of particles associated to the cell. Based on the world model, the environment tracking algorithm becomes the continuous creation, moving and destroying the particles, a process driven by the measurement information, which is the binary grid described in the previous section.
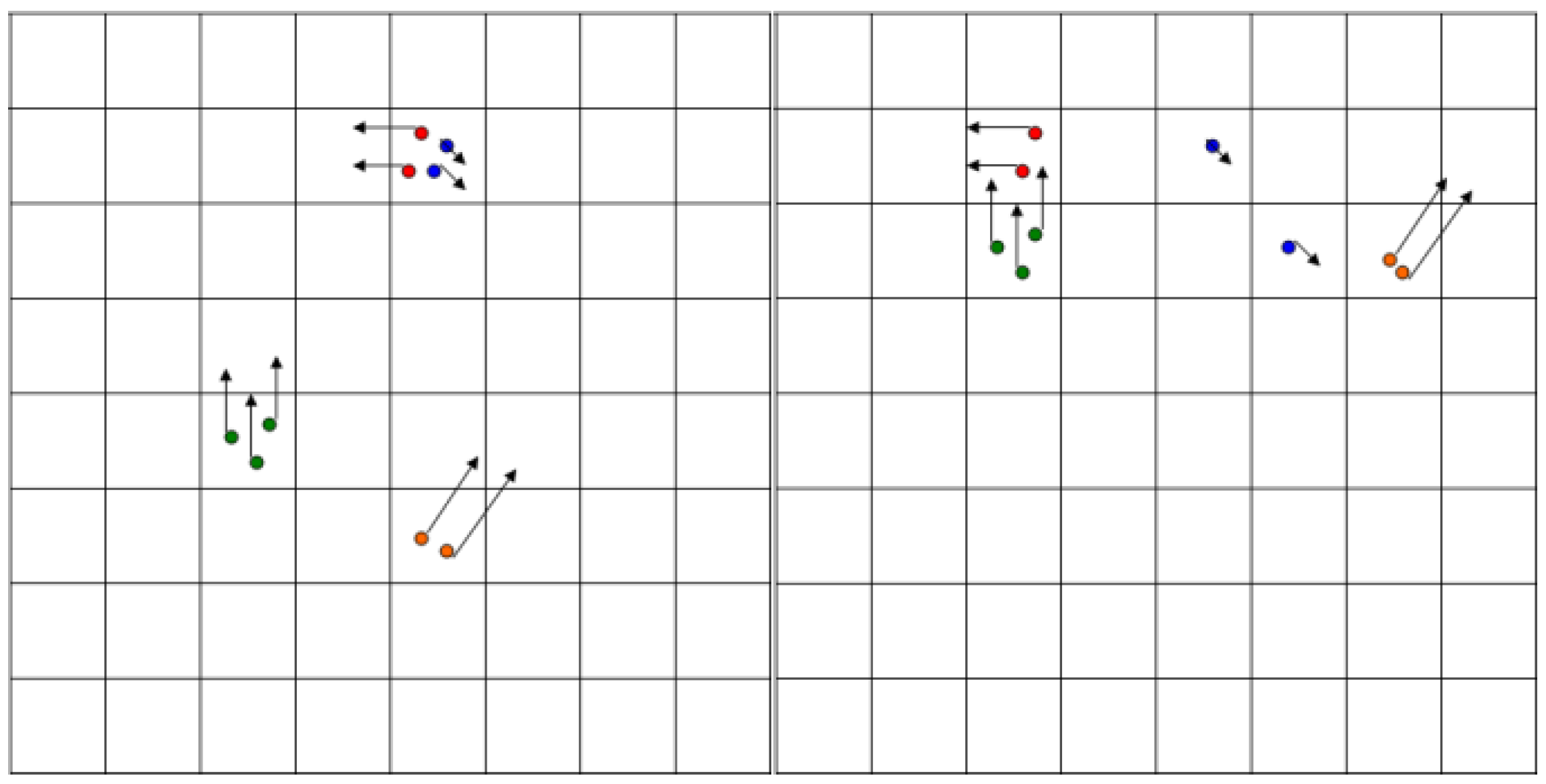
The first step of the algorithm is the
prediction, which is applied to each particle in the set. The positions of the particles are altered (see
Figure 6) according to their speed (or we can say that the particles move according to their own speed vector), and to the motion parameters of the ego vehicle (speed and yaw rate), read from the mobile device’s sensors, GPS and accelerometer/gyroscope. In addition, a random amount is added to the position and speed of each particle, for the effect of stochastic diffusion, modelling the uncertainty of the motion model with respect to the real-world movement of the obstacles. The second step is the
processing of measurement information. This step is based on the raw occupancy cells provided by processing the IPM image, and provides the measurement model for each cell.
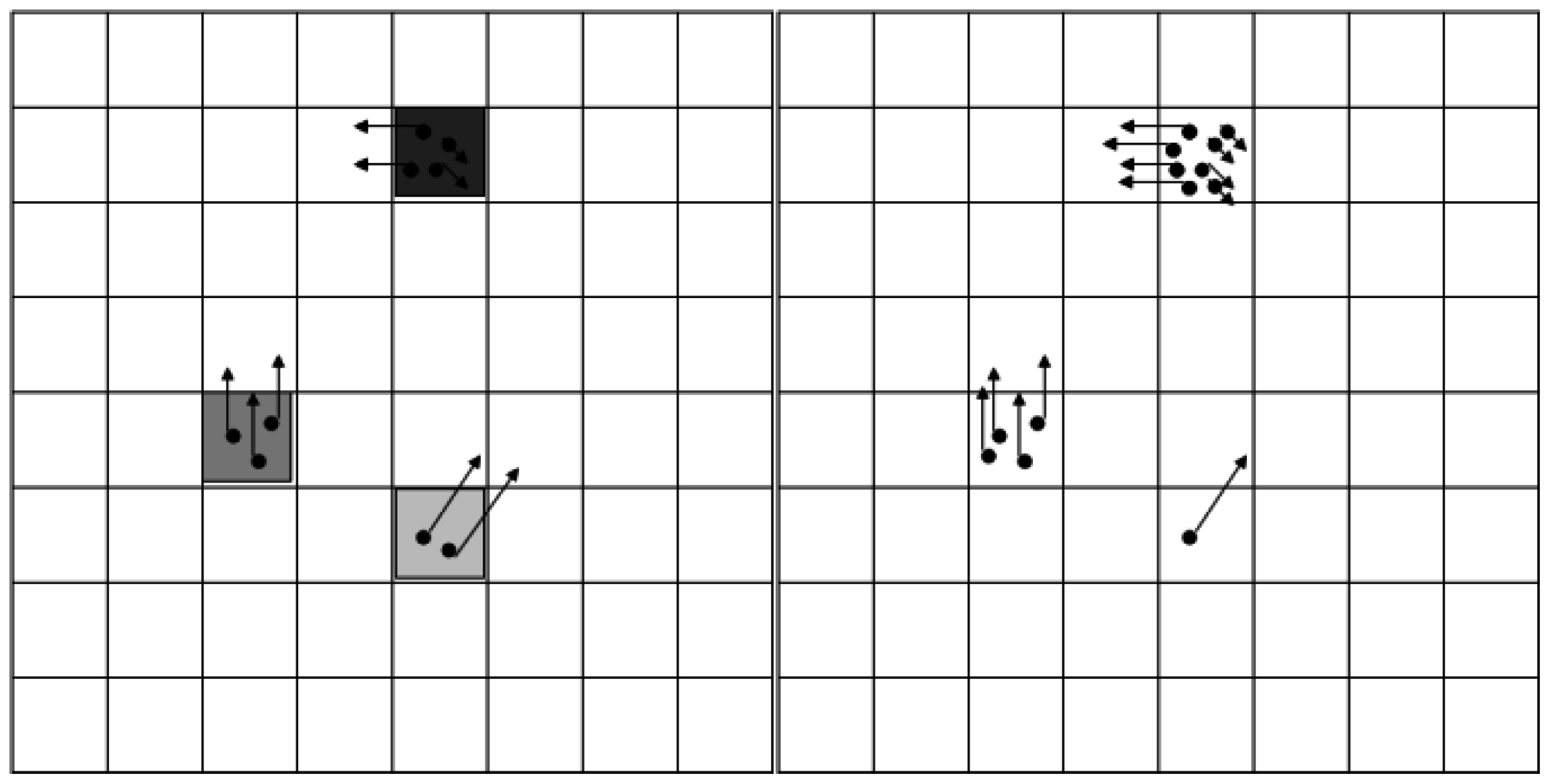
The measurement model information is used to
weight the particles, and
resample them in the same step (see
Figure 7). By weighting and resampling, the particles in a cell can be multiplied or reduced. The final step is to estimate the occupancy and speeds for each cell. More details about the grid tracking process are provided in our previously published work [
16].
3.5. Updating the Dynamic Occupancy Grid from the IPM-Based Measurement
The update process uses the measured binary grid, and the uncertainty associated to the creation of this grid, in the process of adjusting the particle population. In our previously published work, the binary grid was created from a digital map generated by processing dense stereovision data. The position uncertainty of an obstacle cell is derived from the uncertainty of the stereovision process. The standard deviation of a distance
z estimated by a stereovision system of baseline
b and focal length
f, having a matching uncertainty of
pixels, is:
The standard deviation of the other grid coordinate, the lateral position
x, is:
The lateral position uncertainty depends on the distance uncertainty, which is the most important uncertainty of the measurement process. If we want to adapt the occupancy grid tracking mechanism to use binary measurement grids generated by processing IPM images, the computation of distance uncertainty has to be adapted to the IPM method of distance computation.
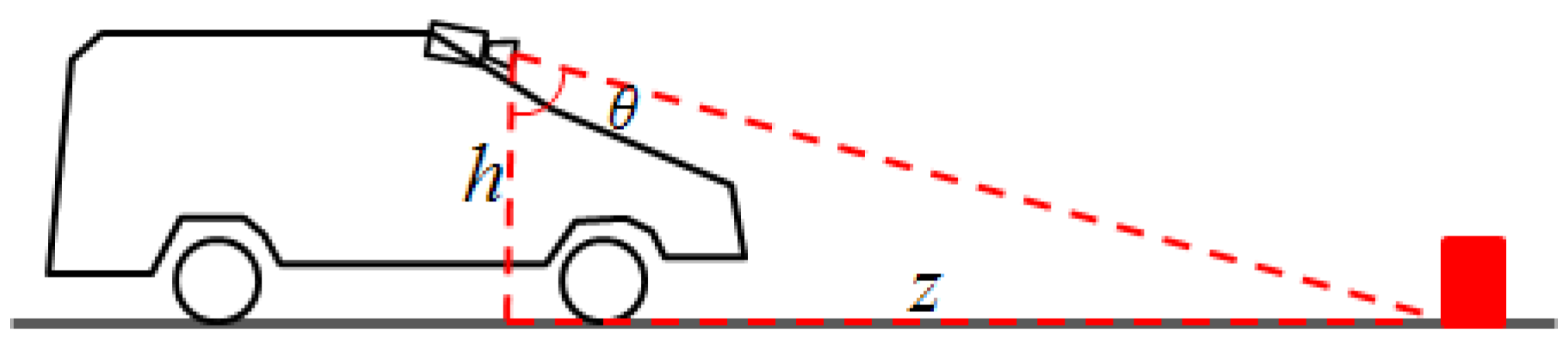
The process of estimating the distance of an obstacle from the camera when using IPM images is described in
Figure 8. The height of the camera is known, along with its orientation. A pixel in the image corresponds to a line from the camera, which makes with the vertical the angle θ. This angle depends on several factors: the angle between the camera’s optical axis and the vertical, the position of the pixel in the image plane, the focal length of the camera, and the position of the principal point. We are not concerned with these details. For all practical purposes, we can say that we know θ, and thus, from the red triangle described in
Figure 8, we can compute
z.
The IPM image is not constructed by using angles and heights, but by using the projection matrix, as described in
Section 3.2. However, the simplified model is useful in understanding the mechanism of uncertainty. As the height of the camera above the ground can be considered, to a reasonable degree, to be fixed, the uncertainty affects mostly the angle θ. This uncertainty comes from the pitching of the observing vehicle, as the car encounters uneven surfaces, accelerates or brakes. Small and temporary deviations of the real road surface from the flat road assumptions can also be modeled as errors in the θ angle, while long term, significant deviations cannot be modeled and will lead, eventually, to wrong estimations. An experimentally tuned value of σ
θ = 0.25° was chosen to account for these situations.
The relation between
z and θ is:
The relation between the uncertainty of
z and the uncertainty of θ is:
Using Equation (11), we can replace the tangent, and obtain the final equation for the uncertainty of
z:
The quantity is a constant covering other sources of uncertainty that cannot be modeled analytically.
For each cell in the grid, the difference
dz in grid row coordinates and the difference
dx in grid column coordinates is computed between the position of the grid cell and the position of the nearest obstacle cell in the binary obstacle map segmented from the IPM image. Using these distances and the uncertainty values computed from Equations (14) and (10), we can compute the measurement probability density under the assumption of the cell being occupied, by employing the bivariate Gaussian function:
Based on the measurement probability value, the predicted particles in a cell may be multiplied or decimated.
The particle creation, movement, multiplication and destruction mechanisms of the dynamic occupancy grid [
16] can now be used with the IPM binary obstacle grid as measurement data.
3.6. Detection of Individual Obstacles
The dynamic grid’s cells that hold a significant number of particles are considered occupied, and therefore parts of obstacles. A grouping algorithm, which takes into account the proximity of occupied cells, but also the agreement of their speed vectors, extracts connected regions from the grid, regions that describe individual objects. An oriented rectangle shape is matched to these connected regions, and the 3D object is extracted as a cuboid (obviously, the height of the object above the road cannot be computed, and a fixed value is set).
Due to the nature of the occupancy grid, its cells will have a speed vector, computed as the resultant of the individual speed vectors of the particles. After the grid cells are grouped into individual obstacles, a resultant speed vector for the cell group is computed, and this vector is assigned to the detected object.
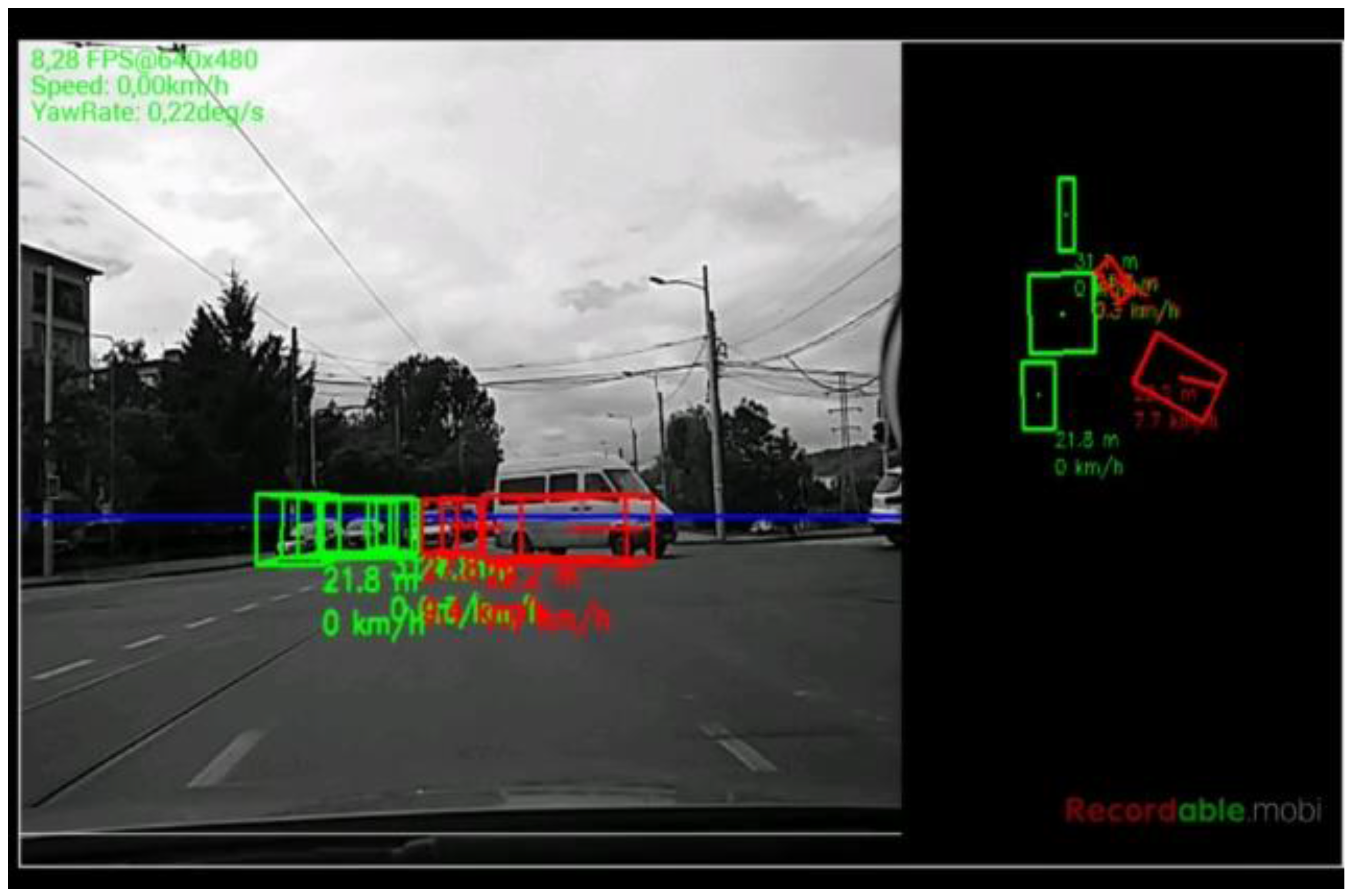
The resulted objects have length, width, orientation and speed, and can be therefore classified into static and dynamic. The process is seen in
Figure 9, where the stationary vehicles are shown in green, and the moving vehicle is shown in red.
5. Experimental Setup and Evaluation
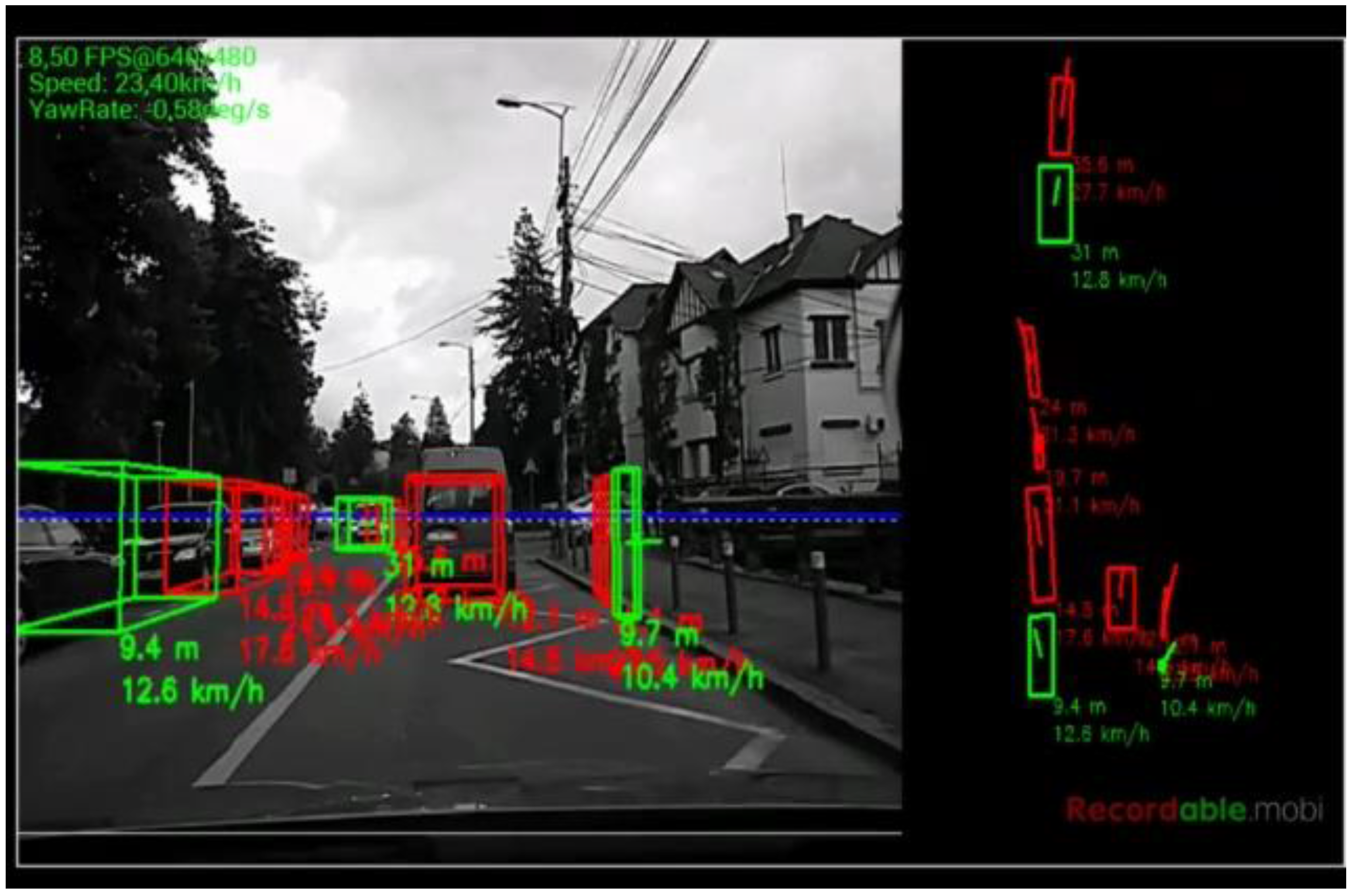
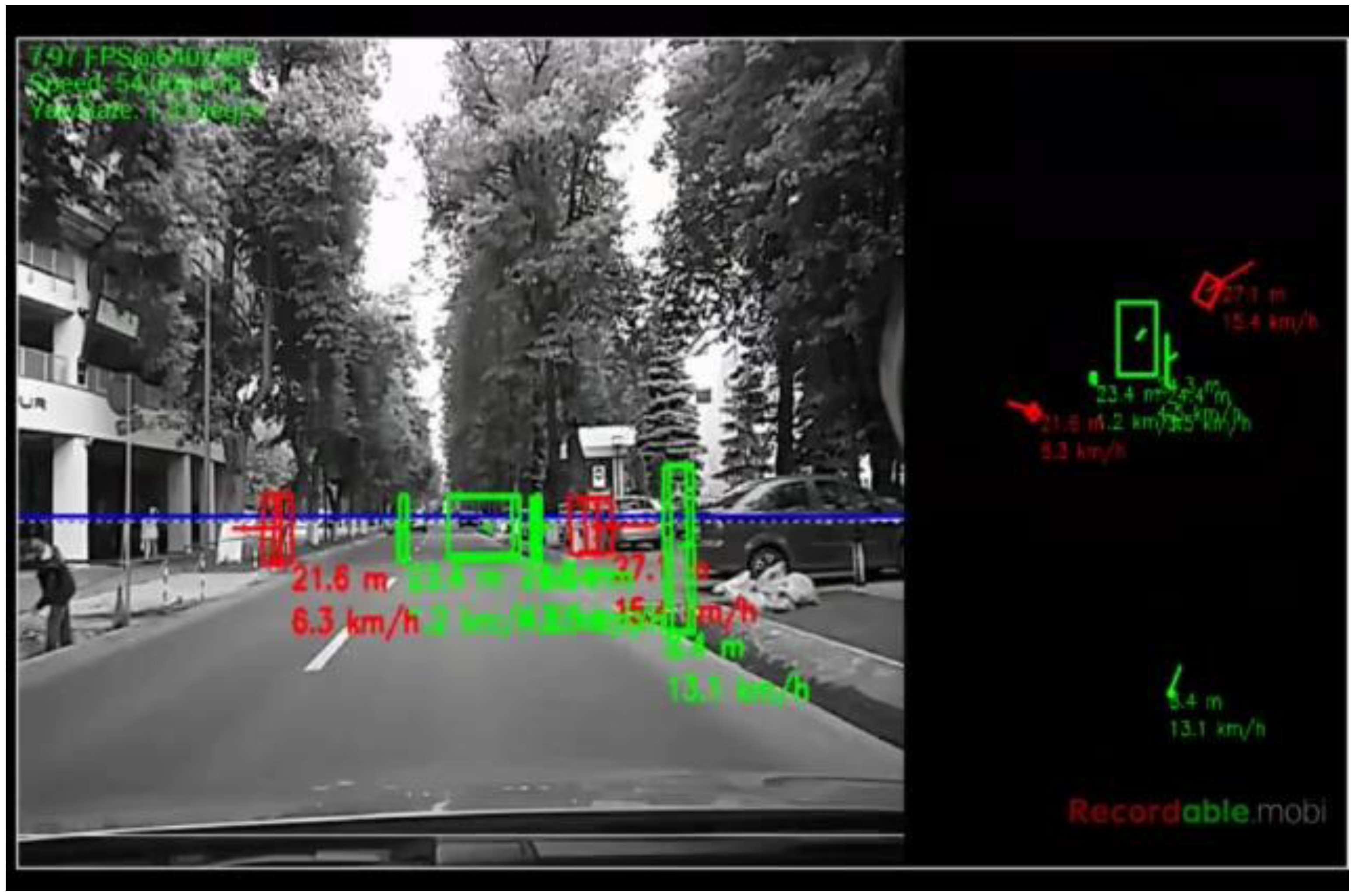
The algorithm was tested on recorded sequences from mostly urban scenarios, under a various range of lighting conditions. Obstacles from a wide range of shapes, speeds and orientations have been successfully detected, and their static and dynamic properties successfully measured. The IPM image, the binary obstacle grid, the estimated occupancy grid with color coding of speed and orientation for each cell (see
Figure 13), and the projected cuboids on the original perspective image are shown for several real traffic scenarios, in
Figure 14,
Figure 15 and
Figure 16.
In
Figure 14 and
Figure 15, successful situations are shown in a variety of challenging scenarios, and two clear failure cases are shown in
Figure 16. The scenarios are explained in the captions of the figures. The detected moving objects are displayed with the color red, and the stationary objects with green.
The qualitative analysis shows that most of the obstacles are correctly detected, but there are still problems with objects of low contrast (especially at the point of contact with the road, which is the point that matters for IPM), and with strong shadows in bright daylight. A video showing results for a 11 min drive sequence (recorded and processed offline) can be seen at
http://vimeo.com/107588262. Obstacles on the road are detected at various distances, up to 40 m. Each obstacle is bounded by a cuboid and the distance from the ego-vehicle to the obstacles is written below the cuboid. Stationary obstacles are shown as green cuboids, while moving obstacles are shown as red cuboids. On the top left of the frame, the occupancy grid is displayed, using the color coding for speed and orientation of each cell, as described by
Figure 13.
The system was tested on multiple mobile devices: the Samsung Galaxy S5 phone, and the LG GPad 8.3 and the Samsung Galaxy Tab Pro tablets. Tests were performed in city traffic with the devices plugged in, allowing them to run at full processing power. The usage of vocal assistance and feedback will reduce the necessity of the device screen to be on. Depending on the complexity of the scene, the system’s processing time ranged from 50 to 80 ms. The resulted frame rate ranged between 9 and 15 fps, as the whole frame cycle includes the acquisition process and the result display. A frame rate comparison, using the same recorded video, is presented in
Table 2.
In order to assess the battery consumption of the system, we have conducted power tests with the devices running on battery power, during 20 min runs, and the overall battery drain was measured. The results are presented in
Table 3. Battery consumption is also influenced by the fact that currently the output of the system is visual, requiring the device screen to be on all the time. However, the real use of such a driving assistance system will be either as an audio warning system, or as a data source for other devices (such as the car’s computer itself), connected into an Internet of Things configuration, and the need for the screen to be on all the time will disappear.
Due to the monocular, grayscale nature of the information used for detection, the results are sometimes affected by false positives, due to shadows on the road (
Figure 20), or by false negatives when the contrast between the road and the obstacle is not high enough.
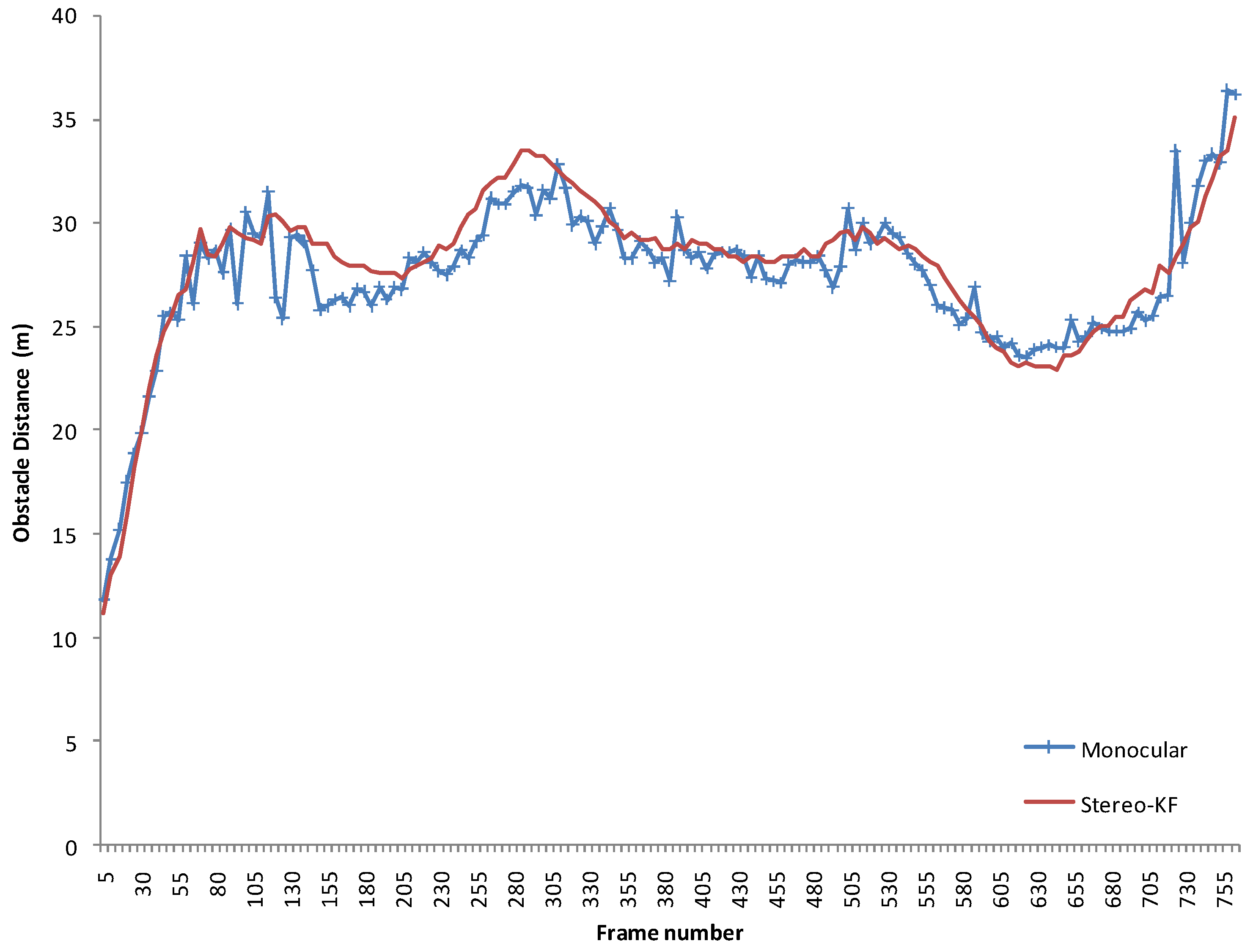
In order to assess the accuracy of the obstacle measurement process, the obstacle range obtained from the proposed solution is compared with the range provided by a stereovision-based obstacle tracking system. The monocular solution was tested on the left frame of the stereo pair, and the stereo system used both images. The stereo images were acquired with a 22 cm baseline stereo rig, using two 2/3” CCD cameras (8.3 μm × 8.3 μm pixel size) equipped with 8 mm lenses, the images being down sampled to a resolution of 512 × 383 pixels. This stereovision system is a custom rig, built for accuracy, not a stereo system of a mobile device, which have a too small baseline to be used for measuring distances in the ranges required for the driving environment.
An obstacle in front of the observing vehicle was tracked form approximately 800 frames, or about 80 s. During this time, the target vehicle increased and decreased its distance from the observer multiple times, and the observing vehicle was following. The target vehicle was not knowledgeably involved in the experiment, and its actions were independent. The track was lost when the target vehicle passed beyond 35 m, which seems to be the detection limit of our system.
The range estimation results are shown in
Figure 21. While noisier, the estimations of the monocular system follow closely the stereovision results. For the whole sequence, the Root Mean Square Error was 1.33 m, and the Mean Average Error 1.02 m.
In order to estimate the detection rate, we have used the sequence presented in the video available at the link
http://vimeo.com/107588262, for which we have also the right image of the stereo pair, and therefore a comparison between the monocular and the stereovision method can be performed. A manual identification of the objects in the distance range of 0 to 40 m, and spanning a lateral distance of three lanes (the current lane and two side lanes), was performed on 40 frames of the sequence, equally spaced in time at approximately 15 s, covering a driving time of 11 min. The obstacles were heterogeneous, including cars, pedestrians, and scenery. The detection results are presented in
Table 4. As expected, the monocular solution shows a poorer detection rate performance compared with stereovision, but this rate was computed taking into account all types of obstacles, including scenery such as poles, which have a low contrast with respect to the road surface, and also the obstacles which are only partially visible in the image, such as overtaking/overtaken cars, which are easily detected by stereovision, but cannot be reliably detected by the monocular solution. If the comparison were limited to only cars and pedestrians clearly visible in front of the vehicle (at risk of being hit), the detection rates would be much more similar.
The distance measuring capabilities of the monocular application was also tested against ground truth data acquired with laser measuring equipment. In the absence of a laserscanner, distances to stationary targets were measured using a Leica Disto D5 laser ranging tool, having a measurement of error of ±1 mm, and an effective range of 0.05 m to 200 m. The mobile application was run on a Samsung Galaxy S6 mobile phone. A comparison between the distance reported by the monocular mobile application for the detected objects, and the ground truth from laser measurements is provided in
Table 5. The relative error of distance measurement is around 10%, which is expected from a monocular vision system.
6. Conclusions and Future Work
This paper describes a mobile device based, monocular computer vision solution for detecting the position, size and speed of the obstacles in traffic. The detection method uses a simple and fast segmentation technique, followed by free-form tracking of the obstacle areas using the particle based occupancy grid. The tracked grid cells are grouped into discrete obstacles. As the grouped cells already have a speed vector, the resulted obstacles will have speed vector as well, with magnitude (absolute speed) and orientation. While most existing solutions are able to detect clearly visible vehicles, especially those that are followed by the host vehicle, the proposed system makes little assumptions about the appearance of the obstacles.
The system was tested in real, heavy urban traffic, and shows promising results, turning a mobile device into a driving assistance sensory system.
There is significant room for improvement. Due to monocular vision limitations, the false positives or the false negatives are always a threat, especially for a generic obstacle detection system. The reduction of the error rate can be achieved by using color data (as they are already provided by the device’s camera) or optical flow. The integration of a lane tracker algorithm to the system is in progress, and the estimated pitch angle of the lane can reduce the distance measurement errors caused by forward-backward balancing.
In order to transform the method into a useful system for driving assistance, the detection results have to be communicated non-disruptively. A basic audio warning signal can be issued when collision is likely, but a more detailed description of the obstacles, including all their parameters, can be transmitted using Bluetooth or WiFi, to be used by other systems which may take active steps to prevent accidents, log data for traffic analysis or real time mapping, or monitor the driver’s behavior.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}