1. Introduction
Electromyography (EMG) is an electrodiagnostic medical procedure to assess the health of muscles and the nerve cells that control them, with the detection, recording, and analysis of surface electromyography signals (sEMG) [
1]. EMG provides physicians and health experts with the information generated by the muscle contractions, that is the ionic flow through the muscle fiber [
2]. Research has considered EMG as an important field of study due to the diversity of its applications in clinical medicine and biomedical engineering [
3]. EMG has applications such as the diagnosis of nervous system disorders and muscular diseases like myopathy and neuropathies [
4,
5,
6]. All these applications require the preprocessing of the signals and the extraction of their features [
7]. sEMG are useful as input control signals for prosthetic limbs [
8,
9], in rehabilitation as a measurement parameter of muscular effort [
10], and for the development of muscle machine interfaces [
11].
Most EMG applications involve real-time systems, which need to run with low-cost computational features [
12]. As a matter of fact, in the development of prosthetic, orthotic, and rehabilitation devices, EMG can be employed as a part of the control system [
13]. In the results reported by [
14], EMG pattern recognition and myoelectric control were compared for the control of prosthetics, and the paper remarked that these signals were suitable for the control, highlighting the implementations of algorithms that were capable of distinguishing between signals that had similarities. These similarities presented in users that had lost a body part, as a consequence of the absence of peripheral structures in the musculoskeletal system, where the classification of EMG features becomes a challenge [
15]. EMGs features are listed on
Table 1, these characteristics have been used in different classification tasks [
16,
17,
18,
19,
20], and the classification rate increases with the use of a proper signal preprocessing stage; for instance, Chowdhury et al. considered the use of wavelet and empirical mode decomposition, first differentiation, or independent component analysis [
19]. Despite the performances achieved at the preprocessing stage, the computational complexity might increase, adding a delay to the response.
Several authors used autoregressive models and the characteristics of random processes, such as first and second moments, etc., in tasks related to the classification of myopathy or neuropathy [
21]. For example, Bozkurt et al. reported a 97% classification performance using fifteenth order AR models, Yule–Walker, Burg, covariance, modified covariance, and subspace-based methods to extract features from 1200 sEMG, applying high-resolution and a high-sampling rate invasive electrodes implanted in a bicep brachii muscle [
22].
In a different research work dedicated to hand movement, Phinyomark et al. reported a high classification rate of 97.76%, achieved by applying a quadratic discriminant analysis and four AR coefficients per channel, including a preprocessing stage whose output was the first differentiation of sEMG [
23]. They extracted information from the activity of five forearm muscles features: WL, DAMV, DASDV, DVARV, DASDV, M2, WAMP, IEMG, and MAV. They also used these features in their previous works [
24]. The features SSI, VAR, RMS, MYOP, CC, LOG, TK, and V from another point of view were used in [
23], applying the seventh order Daubechies mother wavelet and the four decomposition levels before sEMG characterization to extract RMS and MAV. They tested the behavior of these features to estimate whether they were useful for identification of six daily hand movements, while monitoring flexor and extensor carpi radialis longus muscles.
Liu et al. described the use of a support vector machine (SVM) ensemble [
25] to classify eight different hand grasps with a precision rate of 93.54%; extracting sEMG from three different forearm muscles, the fourth order AR coefficients and the histogram of EMG (HEMG) allowed building the feature vector per channel. In their work, the aim was to get significant features and a classification model that permitted increasing the classification rate of sEMG. However, the SVM ensemble used resulted in being computationally expensive [
26]. Angari et al. considered fifteen channels to digitalize sEMG and to characterize five hand movements, where they extracted twenty-one attributes per channel (MAV, WL, ZC, SSC, AR, among others) to implement feature selection methods and perform channel discrimination [
27]. In this case, the aim of the research was to train the SVM with low dimensionality patterns and the most representative forearm muscles; this work concluded that MAV and WL were appropriate for classification tasks.
The method of Khezri et al. used an adaptive neuro-fuzzy inference system to test its classification rate in a six-hand movement dataset containing four channels [
28]. The considered features were MAV, SSC, ZC, and 10 order AR model coefficients. Merging these attributes to create patterns for sEMG representation resulted in classification rates of 86–100%.
Ruangpaisarn et al. presented a feature extraction technique for hand movement classification, considering two pairs of EMG electrodes and the merging and transformation of both channels into a squared matrix to perform factorization via singular-value decomposition [
29]. They reported the use of singular values in the matrix’s main diagonal and the training of SVM with fifty feature instances, achieving a performance of 98.22%. The issue in this work was comprised of taking samples, where no muscular activity was investigated, and working with a 2D vector in most cases led to non-linear computational complexity. With the same dataset, Sapsanis et al. used a preprocessing stage in which signals were decomposed into three levels with empirical mode decomposition, so that the noise was reduced [
30]. For each decomposition level and raw sEMG, they extracted the following attributes: IEMG, ZC, VAR, SSC, WL, WAMP, kurtosis, and skewness. With linear discrimination analysis, the rate of correct classifications reached 89.21%.
Zhai et al. suggests a self-recalibrating classifier for hand movement, based on a convolutional neural network [
31], where the algorithm’s update has the potential to keep a stable behaviour with no user retraining. Reviews in [
18,
19] points up the variety of features needed for classifying sEMG and preprocessing approaches that might lead to improvement of the model’s performance.
Table 2 presents the classification accuracy achieved by different algorithms that worked with the EMG database from the University of California at Irvine (UCI) machine learning repository, where none of the studies adopted the reflection coefficients as features for pattern recognition.
The aim of this work is to develop a classification algorithm for sEMG with low computational cost and with a competitive classification rate. The remainder of this paper is presented as follows:
Section 2 describes the hand movement database that was employed, as well as a brief review of the signal preprocessing techniques, and different features useful for classification are described. Then, the proposed classification method is presented.
Section 3 shows the results obtained by the classification technique.
Section 4 and
Section 5 are the discussion and conclusion of the results achieved by the proposed methodology for sEMG classification.
4. Discussion
The classification accuracy rate of different learning algorithms depends on the data distribution. This behavior is expected according to the “no-free-lunch theorems” [
42], which state that the best classification model for all datasets does not exist. The justification of why several models have to be compared using the same dataset concurs with that statement.
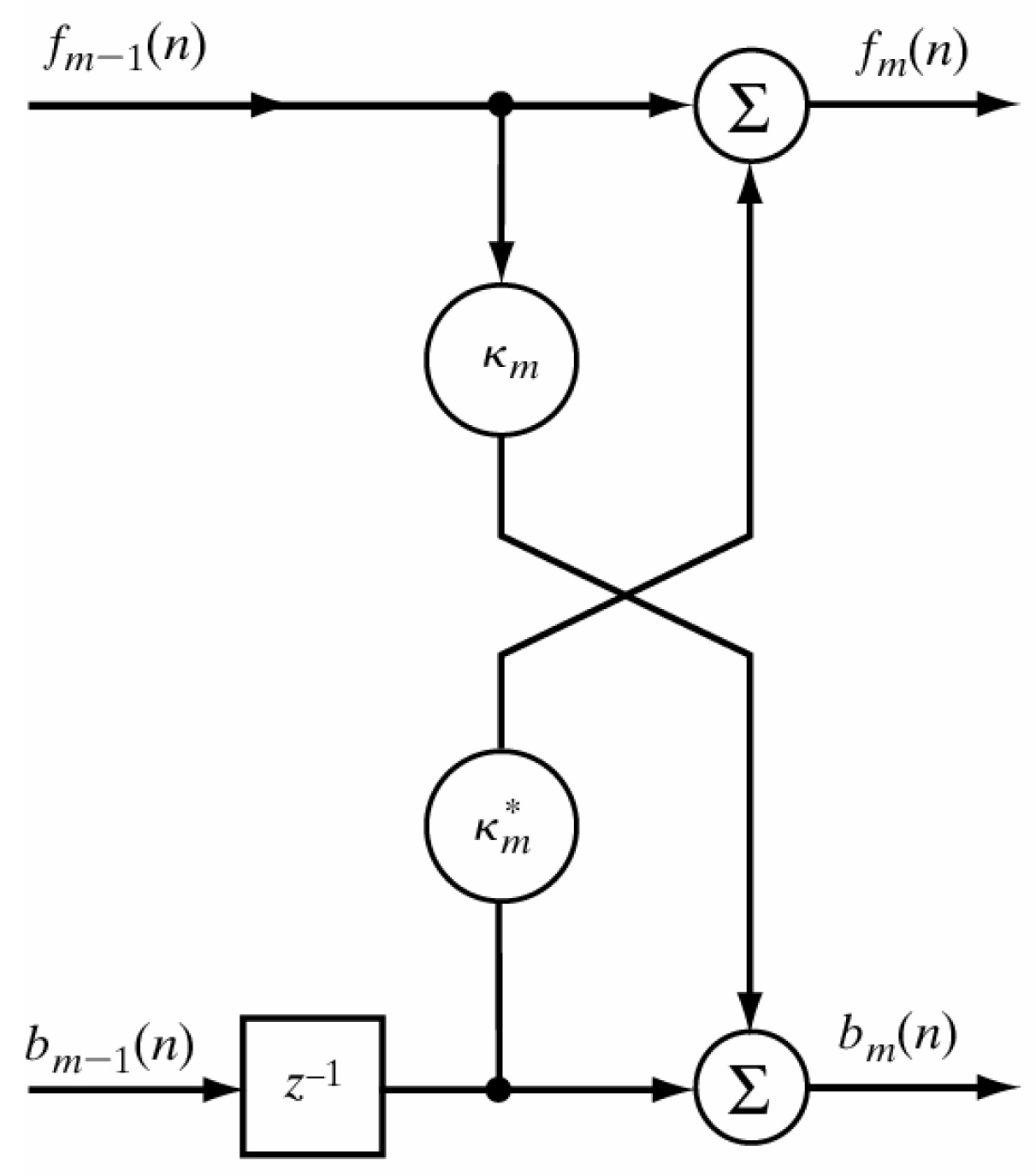
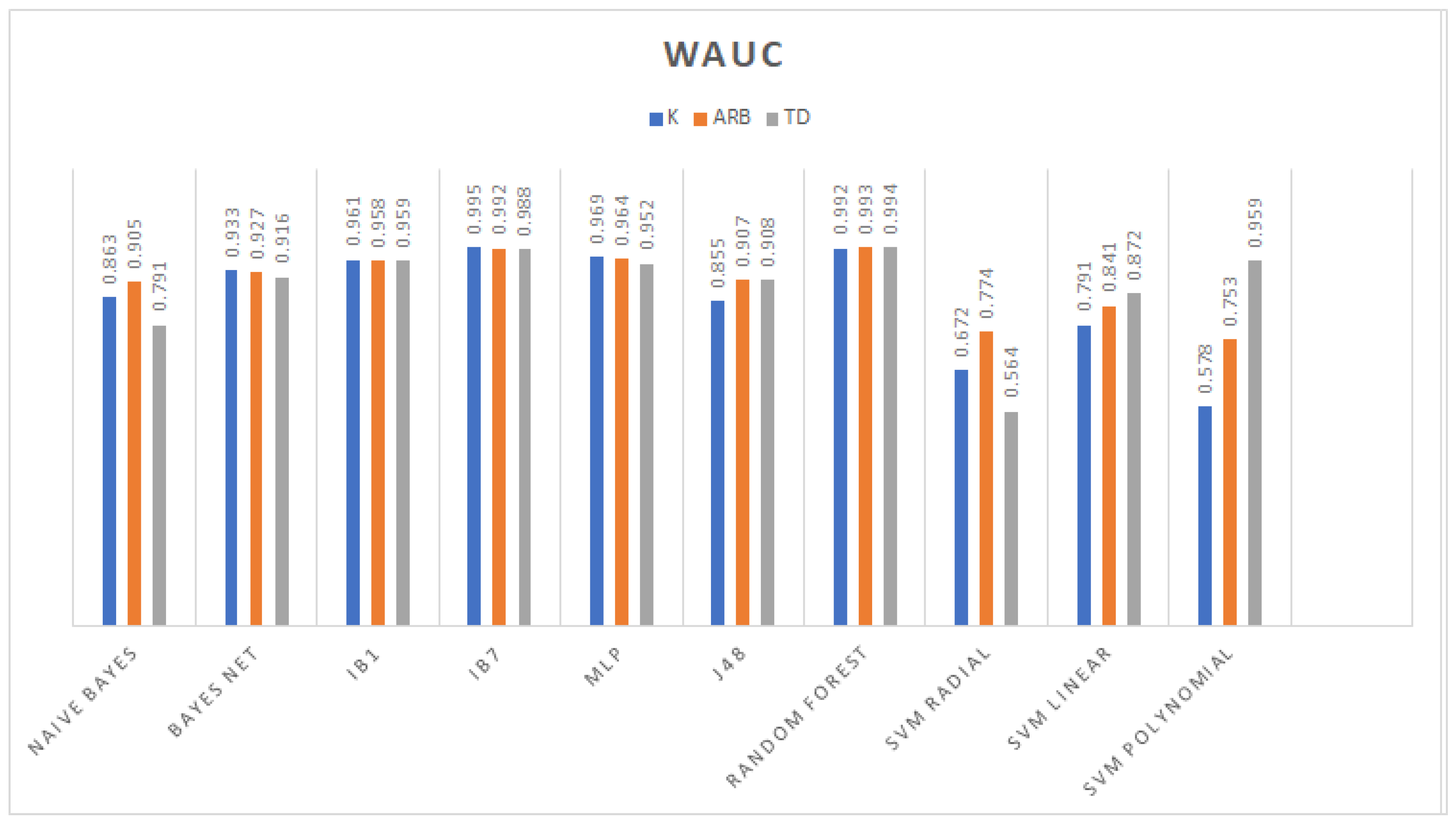
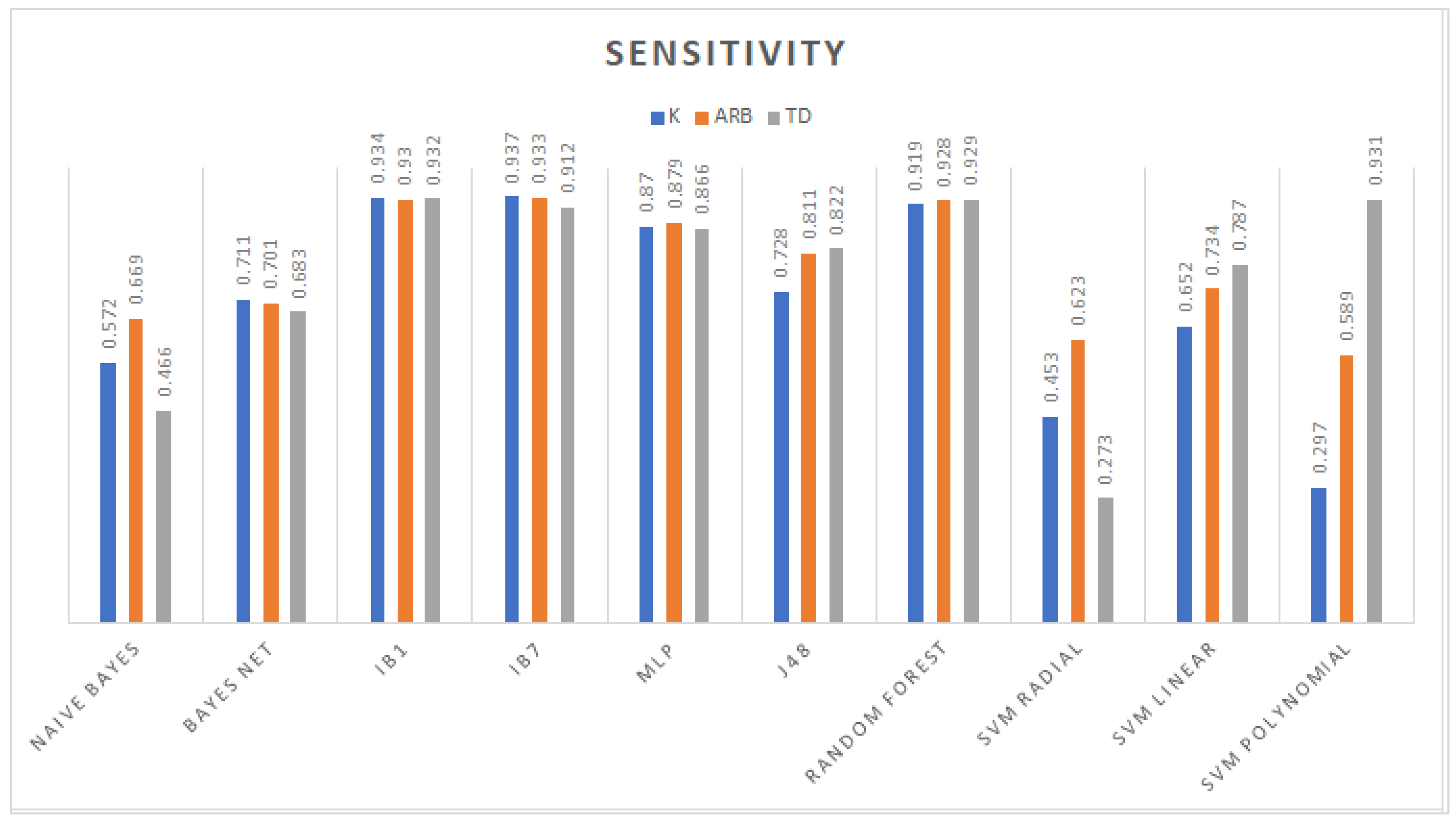
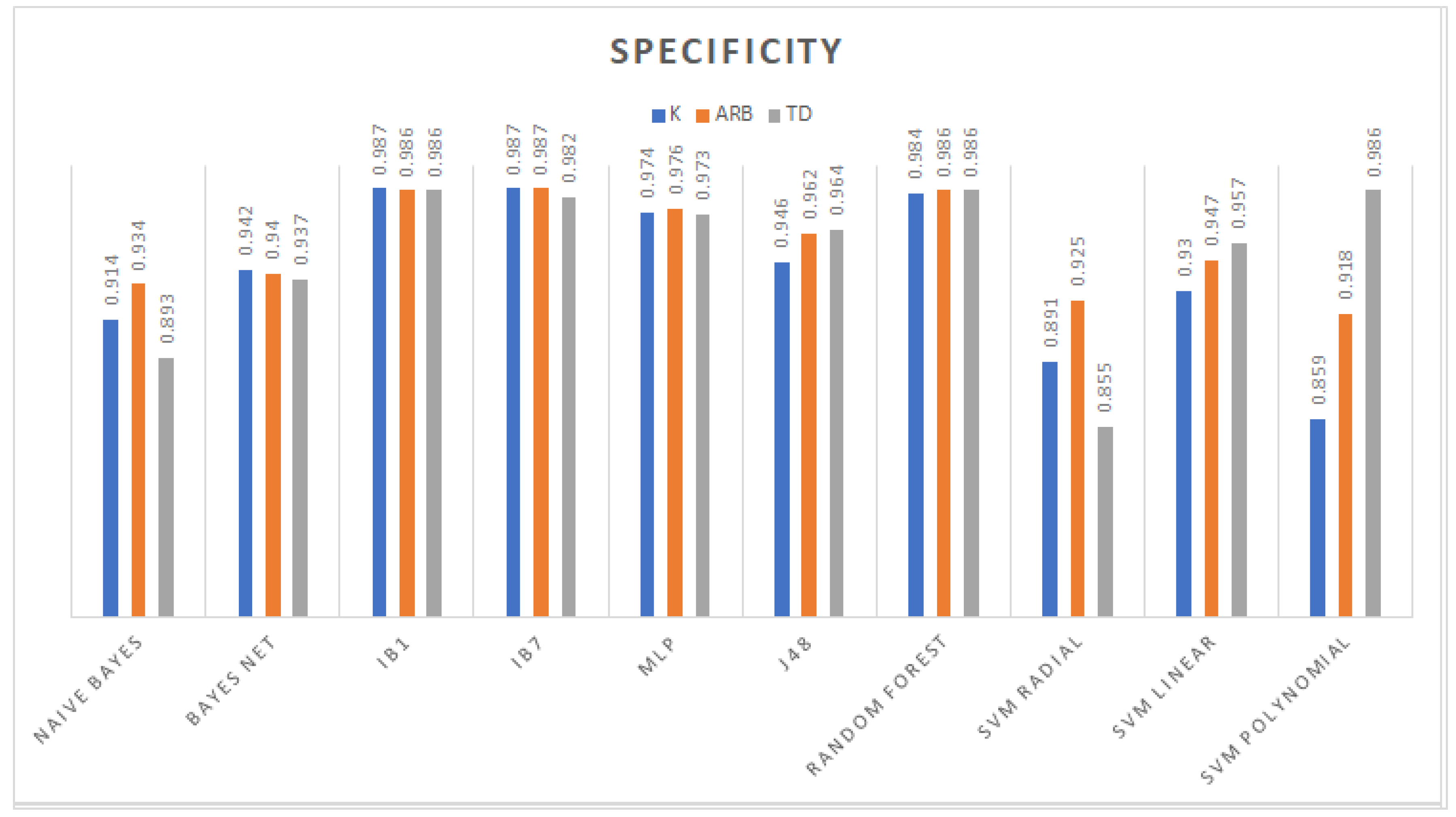
While testing classifiers with separate datasets, Burg reflection coefficients
K (
21) are more appropriate to use in conjunction with the Bayes net and IBk models. Since
K traits are needed to compute the Burg autoregressive traits, Arb (
17), their classification performances are similar. Besides, TD features have different values, which rely on amplitude or counting events. Therefore, the MLP, decision trees, and linear and polynomial kernel SVM outputs have high accuracy.
Despite the Burg maximal entropy autoregressive and reflection coefficients being closely related, the classification rate increases when these two traits take a part of the dataset. This means that they are not redundant or irrelevant in feature construction tasks; however, as mentioned before, Arb characteristics take more time to compute because they rely on first computing the reflection coefficients. In addition, as a result of combining three different theoretical frameworks’ attributes, the highest classification rate was obtained. Hence, a synergy of different attributes is needed for a higher accuracy in the sEMG classification tasks.
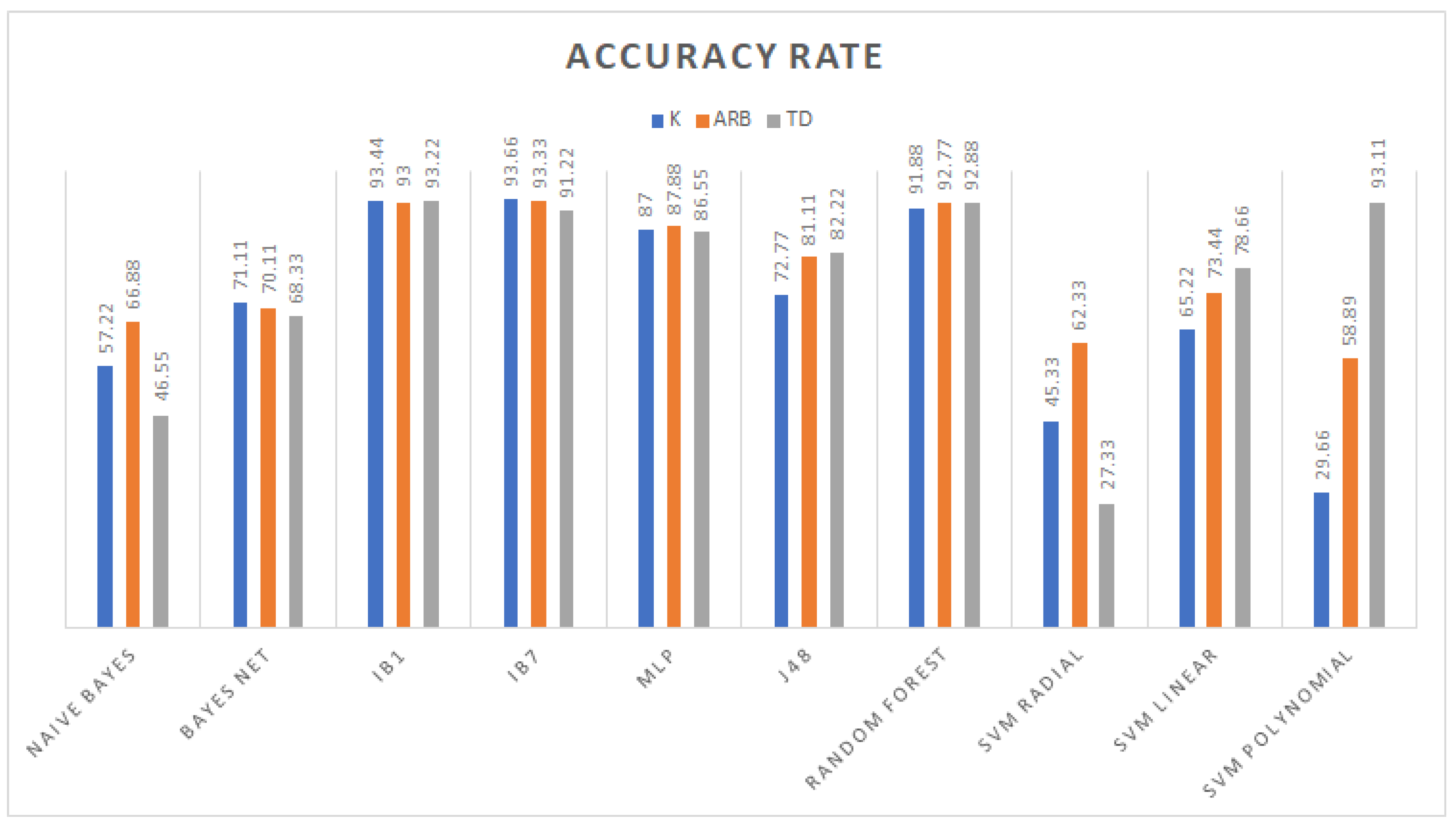
As it is shown in
Table 6 compared against the results shown in
Table 2, a high classification performance was reached with 26 or fewer features. The fact that the feature vector
X had at least 34 redundant or irrelevant traits, which needed to be removed using feature selection tools, can explain this. As a result, different data distributions were obtained; for instance, principal component analysis performed by WEKA produced a data distribution suitable for support vector machine with a radial kernel since all patterns were correctly classified.
Excluding the PC dataset, the best classifier for the remaining datasets was the IBk model with a different number of neighbors used for class assignment, because the performance of the nearest neighbors-based model depended on the value of
k. For instance, the TD and
K dataset classification rates decreased as a result of increasing the value of
k, contrasting what happened with the Arb patterns (see
Table 5). This behavior is expected because the classification phase applies the nearest neighbor to different classes, causing in the worst case a tie and a misclassified pattern.
The advantage of IBk is its simple training phase, which is based directly on the dataset, compared to the Bayesian models, which require the computation of probability distributions and the cost function. The design of the hidden layer of MLP can be complex, and the time for reducing back propagation error might be long. The decision trees, as well as multilayer perceptron are hard to design, and they require a pruning process to reduce irrelevant leaves and branches, while SVM has a complexity of to establish support vectors. The kernel selection and design of the support vectors that best fit the data distribution are needed.
An example of kernel selection can be seen from
Table 5 with the TD dataset using the polynomial kernel, a high performance of 93.11% was reached, and merging the TD with
K features, an improvement of 0.11% was achieved. This is a sign that most of the support vectors were found in the TD traits using such a kernel. Another example is comprised of the Arb and
K traits: they were better classified with a linear kernel, and by joining these two datasets, a considerable increase in the classification rate was obtained (see
Table 5) as a consequence of more appropriate data for the support vector estimation.
The results that are considered for the discussion are those that were obtained using the same signal dataset; otherwise, any comparison concerning the feature extraction and preprocessing stage based on the classification performance would be unfair.
The feature extraction method presented in [
29] yielded fifty traits and reached a high performance (98.22%) with no previous signal treatment, while the classification rate of 89.21% was obtained with the empirical mode decomposition technique, which denoised the original signal in conjunction with the sixty four features proposed in [
30]. Our methodology succeeded in classifying all 900 sEMG instances with less than half the features (20 characteristics) as in the methods of [
29,
30]. Their results were surpassed with only eight traits, producing 99.22% correctly-classified signals. Our preprocessing stage consisted only of the reduction of noisy samples and the subtraction of the myoelectric signal mean value, which turned out to be effective because it gave signals suitable for the framework of the developed feature extraction tools, such as the Burg reflection coefficients (
21).
As shown in [
30], decomposing sEMG caused information loss, which was reflected in the classification rate; for this reason, all available signal information for the feature extraction task was taken.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}