Wireless signals are susceptible to the effect of a variety of physical factors during transmission, such as signal source position, obstacles, antenna gain, transmit power, and so on. In order to ensure the validity and reliability of information transmission, it is necessary to change the transmission code rate according to different channel conditions. We usually use channel estimation techniques to judge the quality of channel states. However, the channel estimation algorithm with computational complexity would reduce the effectiveness of the communication system.
The partition-based clustering algorithm is one of the most commonly used algorithms. Usually, the method based on distance division is used to divide the objects with approximate characteristics into the same cluster. The distances of objects in the same cluster are as close as possible. The distance between objects in different clusters is as far as possible. Partition-based clustering algorithms often need to enumerate the possibilities of all categories in order to obtain an optimal solution.
3.1. Channel Environment Clustering Based on the K-Means++ Algorithm
The k-means algorithm is one of the most common partition-based clustering algorithms. K-means clustering aims to partition observations into clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. The k-means algorithm is simple and flexible, but sensitive to outliers and isolated points.
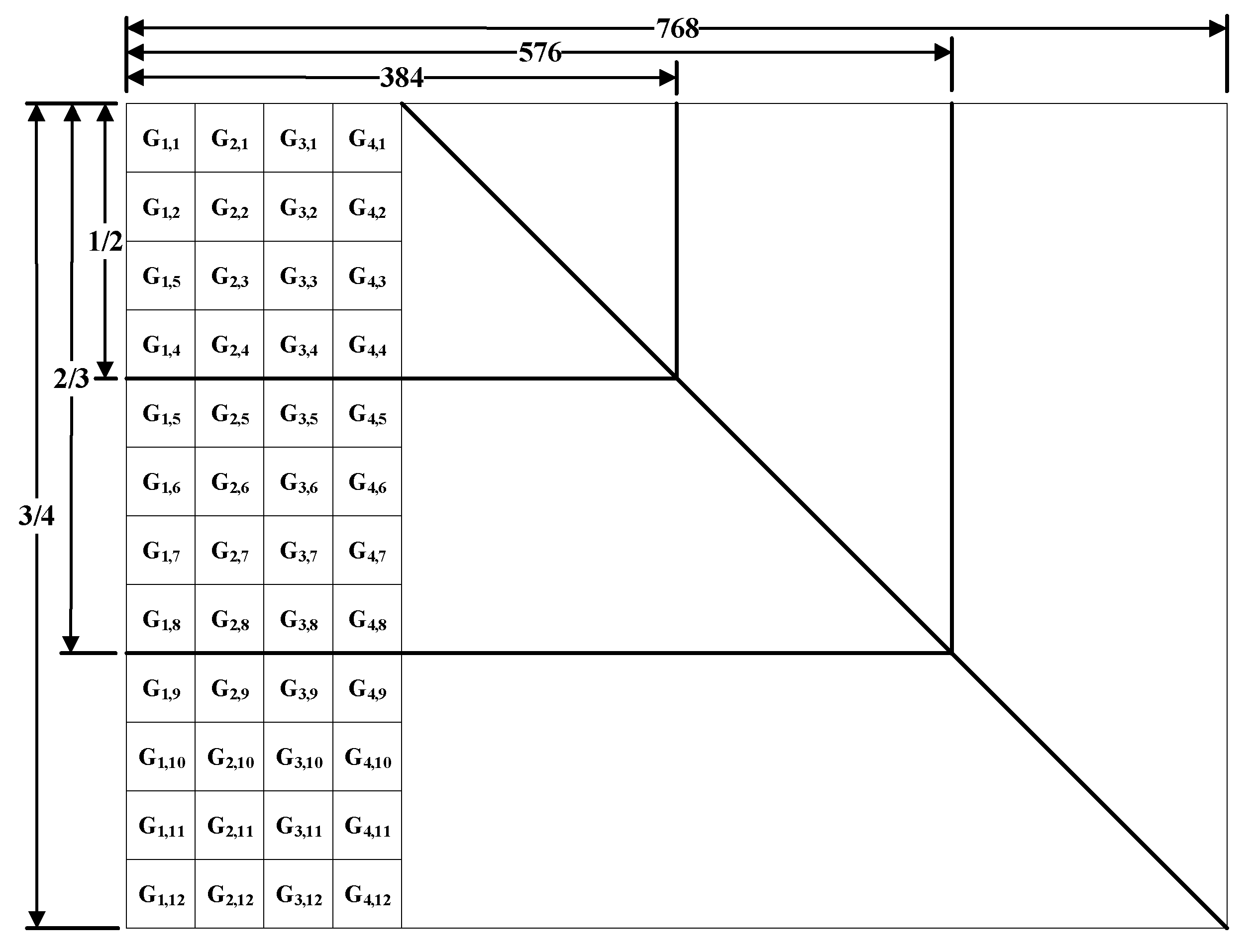
In addition to the impact of the physical factors, the number of users under the same hotspot, as well as the user usage behavior (occupied bandwidth), will have an impact on the actual available channel state. In this paper, we abstract these influencing factors into data vectors and form the data vectors into a sample set, and then cluster them with the k-means algorithm.
We assume that the inputs are the sample set , the cluster number , the maximum number of iterations , and the output is cluster partition . The k-means algorithm flow is as follows:
We randomly select samples from data set as the initial cluster center vector .
For
- (a)
Initialize cluster partition to .
- (b)
For , calculate the distance between the sample and cluster center vector : . Mark as the category corresponding to the smallest and update .
- (c)
For , recalculate the new cluster center for all sample points in by .
- (d)
If all cluster center vectors have not changed, go to step 3.
Output cluster division .
The k-means algorithm is sensitive to the initially selected cluster center, and the position selection of the k initial cluster centers has a great influence on the final clustering result. Therefore, it is necessary to select the appropriate cluster centers. The k-means++ algorithm randomly initializes the cluster center, which is the optimization of the k-means algorithm.
The optimization strategy of k-means++ for initializing the cluster center is as follows:
According to the process of the algorithm, different initial clustering centers may result in different results. In this paper, we select the k-means++ algorithm in order to optimize the initial clustering center. The k-means++ algorithm is an improvement of the k-means algorithm. Try to choose the k-measuring point distance as the initial cluster center. The specific steps are as follows:
Randomly select sample data from the data set as the first cluster center in clusters.
Calculate the distance
between the data sample
in the dataset and the nearest cluster center.
According to the value of , select a new data point in the remaining sample data as a new cluster center. The larger the , the greater the probability of being selected;
Repeat steps 2 and 3 until cluster centers are selected;
Implement the standard k-means algorithm by using the centers as the initial cluster centers.
3.2. Complexity Optimization of the End-to-End Distortion Model Based on the Clustering Algorithm
Traditional rate allocation schemes often need to traverse all combinations of coding parameters to achieve adaptive-rate allocation by iterating all combinations. In this paper, the clustering algorithm is introduced to quickly cluster the channel environment to obtain the channel-coding scheme, so as to achieve the goal of adaptive-rate allocation. Compared with the traditional scheme, the proposed method can effectively reduce the computational complexity.
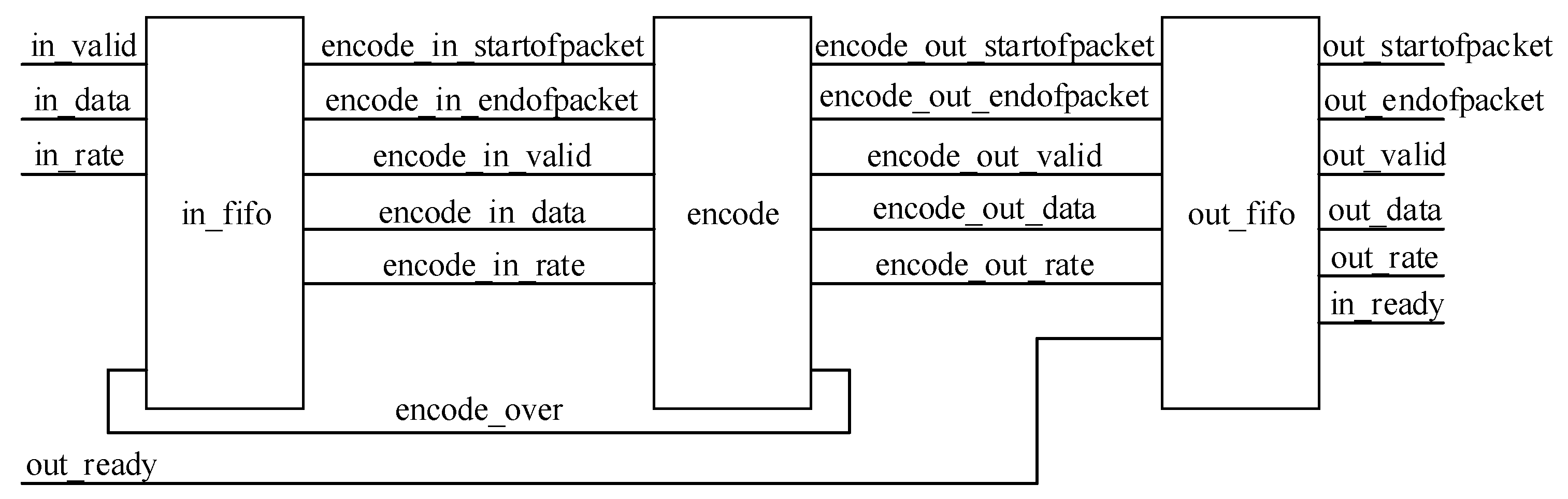
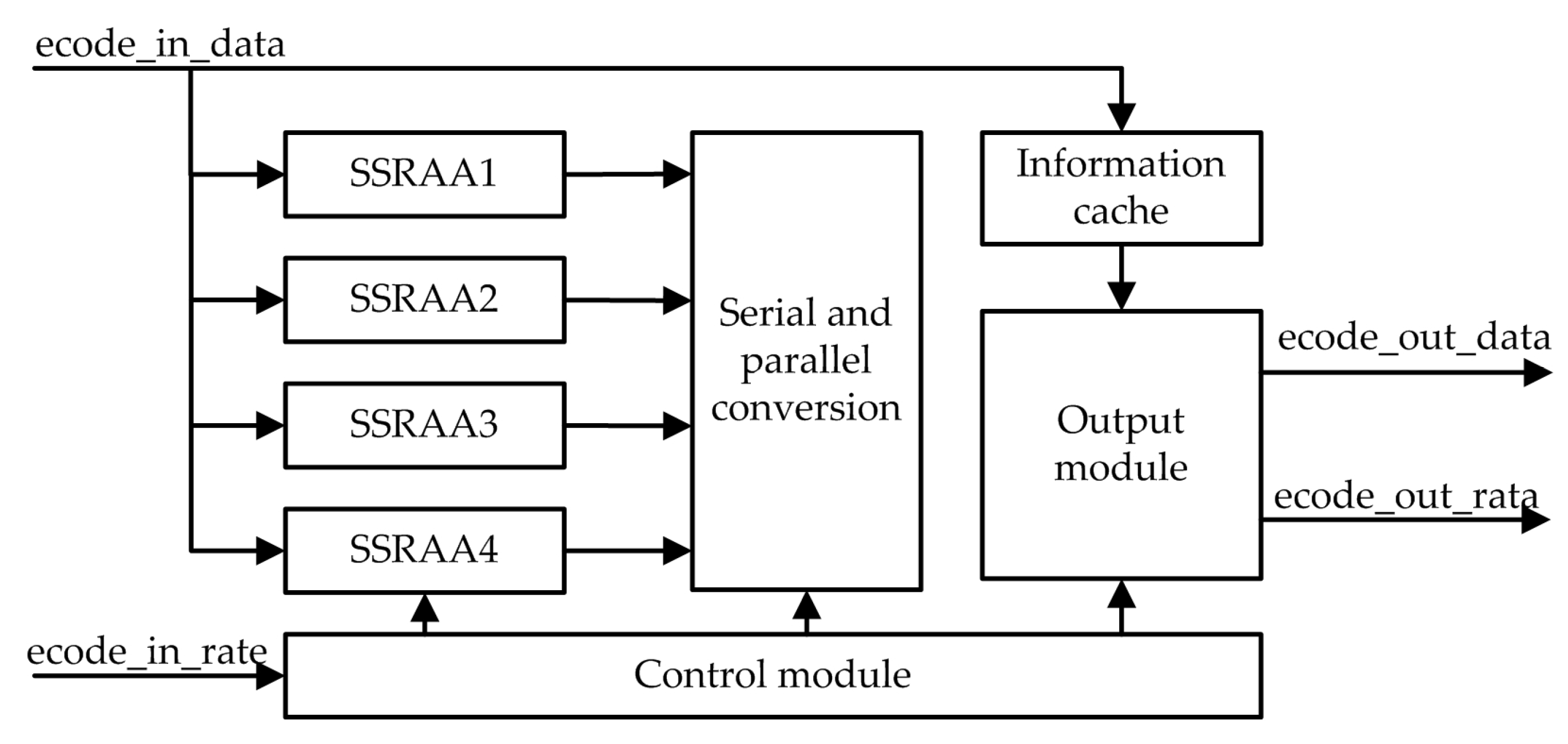
The joint source channel-coding design based on rate allocation is to obtain the optimal video reconstruction quality through bit allocation between the channel and the source in the case of limited bandwidth and channel interference. A block diagram of the bit allocation strategy for joint source channel coding is shown in
Figure 11.
In the joint source channel-coding system, end-to-end distortion is one of the important means to measure the quality of the system. The performance of the transmission system is measured by calculating the mean square error between the reconstructed video image and the original video image at the encoder end. The end-to-end distortion model is derived below.
First, define the pixel in the
frame as
, and the pixel of the reference frame
is
. Let
be the original value of the pixel, let
and
be the reconstructed values of the encoder and decoder, respectively, and let
be the reconstructed residual of the encoder, i.e.,
. If the current pixel is lost at the decoder side, it will copy the pixels of the
frame. Assuming that the transmission error rate is
, the pixel value of the reconstructed image can be expressed by:
Therefore, the estimated end-to-end distortion of the decoder can be expressed as:
It can be seen that the end-to-end distortion can be represented by the sum of the three items , and , where represents source distortion, represents error propagation distortion from the reference frame, and represents error concealment distortion. Error propagation distortion refers to the use of predictive coding in HEVC coding. If an error occurs in a reference frame or a referenced module, the distortion is propagated to the corresponding frame or pixel with reference to it. Error concealment refers to the distortion caused by the recovery of errors or lost modules generated by transmissions in the channel using temporal or spatial correlation. Usually, in the time domain, the motion-compensated content of the previous frame is used to replace the lost portion of the current frame, and the spatial correlation is used to recover the lost portion in the spatial domain.
Since
can be obtained by source-encoded parameters at the encoder side, end-to-end distortion mainly depends on the calculation of
and
. The result shown in Equation (9) can be obtained by calculating
:
As can be seen from the above formula, consists of two items, and , where represents the mean square error between the original image and the encoder-side error-coded pixels, called the original error concealment distortion. can also be obtained by parameter calculation on the encoder side.
It can be seen that
in Equation (9) and
in Equation (8) represent error propagation distortion. The calculation method of
is as shown in:
It can be seen that consists of three parts, where represents the reconstructed image and the error concealment distortion at the encoder end, which is called reconstructed error concealment distortion. The expression can be obtained by parameter calculation at the decoder end. Therefore, A is mainly generated by the error propagation distortion of its reference frame and the previous frame. In addition, since the first frame in the video sequence is usually an intra-coded frame, the value of the first frame can be directly obtained without considering error propagation and the values of the remaining frames can be recursively calculated by Equation (10) on a frame-by-frame basis. In the end-to-end distortion model, the end-to-end distortion of the current frame is obtained by referring to the error propagation distortion of the previous frame, and the subsequent frame is updated by the error propagation distortion of the current frame.
Therefore, from the above analysis, the end-to-end distortion estimation is related to the selection of source-coding, channel-coding, and reference frames.
According to the derivation of the end-to-end distortion estimation method, in the JSCC algorithm based on the rate allocation, in order to select the optimal rate allocation strategy, it is necessary to comprehensively consider the parameters of the source, the channel and the like, so it will be introduced. There is a large number of iterative calculations, so how to choose an effective means to reduce the computational complexity is also a problem worth studying.
Since the end-to-end distortion of the video transmission system is related to the source-coding parameters, the channel-coding parameters, and the reference frame, let
denote the set of all source-coding options,
denote the set of all channel-coding options, and
denote the set of all reference frames. The candidate parameters of the source-coding, channel-coding, and reference frame are
, respectively. A system description that minimizes distortion at the decoder is shown in:
The traditional JSCC algorithm is based on the principle of minimizing end-to-end distortion as a scheme for selecting a code rate allocation. It is often necessary to traverse all combinations of coding parameters, and the worst case computational complexity is . However, the JSCC scheme based on rate allocation proposed in this paper divides the selection method of the parameter combination into two steps. Firstly, the channel environment is estimated by the clustering algorithm, that is, the code rate of the channel coding can be obtained by simple clustering before encoding, and then the obtained channel-coding parameters are brought into the minimum end-to-end distortion estimation to obtain the source-coding parameters and the choice of the best reference frame. In the worst case, the computational complexity is . In addition, in practice, since not all of the source-coding options can be used in any of the FCC coding modes of the channel-coding candidate set , the computational complexity may be even lower.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}