1. Introduction
Health care expenditure is one of the most critical issues in today’s society. World Health Organization (WHO) statistics show that global health care expenditure was approximately US
$ 7.5 trillion, equivalent to 10% of the global GDP in 2016 [
1]. One of the reasons for these high expenses in care is the low accountability in health care in some countries, for example, inefficiencies in the US health care system result in unnecessary waste, provoking a large discrepancy between spending and returns in care [
2]. If we could predict health care costs for each patient with high certainty, problems such as accountability could be solved, enabling control over all parties involved in patients’ care. It could also be used for other applications such as risk assessment in the health insurance business, allowing competitive insurance premiums, or as input information for developing new government policies to improve public health.
With the current frequently used electronic health records (EHRs), an interest has emerged in solving accountability problems using data mining techniques [
3]. There have been various approaches to predict health care costs for large groups of people [
4,
5]. On the contrary, prediction for an individual patient has rarely been tackled. Initially, rule-based methods [
6] were used for trying to solve these problems requiring domain knowledge as if-then rules. The downside of this method is the requirement of a domain expert to create the rules, thus making the solution expensive and limited to the dataset being used. In the current state-of-the-art, statistical and supervised learning methods are preferred with the latter getting the best performance. The reason for best performance is the skewed and heavy right-hand tail with a spike at zero present in the distribution of health care costs [
7].
Supervised learning methods can be evaluated by performance and interpretability; usually, the most sophisticated methods are the ones that have best performance, sacrificing interpretation (e.g., Random Forest, Artificial Neural Networks, and Gradient Boosting). A drawback of these high performing machine learning algorithms in health care is their black-box nature, especially in critical use cases. Even though health care cost prediction is not a critical use case, using patients’ personal and clinical information for this problem could suffer biased results without an interpretable method. Interpretable methods would allow patients, physicians, and insurers to understand the rationale behind a prediction, giving them the option to accept or reject the knowledge the method is providing.
The aim of this work is to create an intrinsic interpretable regression method for health care costs prediction, with a performance comparable to state-of-the-art methods, inspired by the work of Peñafiel et al. [
8], where an interpretable classifier based on the Dempster–Shafer Theory (DST) [
9] was presented. The Dempster–Shafer Theory (DST) [
9] is a generalization of the Bayesian theory. It is more expressive than classical Bayesian models since it allows us to assign “masses” to multiple outcomes measuring the degree of uncertainty of the process. We could have extended the work of the interpretable classifier but as it is a pure classification algorithm, the output is assumed to be discrete, and some procedures do not apply to continuous outputs, e.g., the time complexity grows exponentially with the number of classes. Petit-Renaud and Denux [
10] introduced the use of Dempster–Shafer theory for regression problems; they presented a regression model that uses DST called Evidential Regression (EVREG) to find the expected value of a variable using a set of examples as evidence. We will extend EVREG using a weighted distance and gradient descent, which enables the model to do feature selection (FS) tasks and use it in the health care costs prediction problem. The weight of each feature will represent the importance of this feature to predict an outcome in a dataset; thus, a set of masses with these weights will be computed; the masses will represent the importance of samples in the training set to predict an outcome.
Previous works in health care costs prediction [
11,
12,
13] have reached to the conclusion that clinical features yield the same performance as using only cost predictors without the proper FS experiment. One aim of our work is to prove these claims with a proper FS method. Our research question is whether it is possible to develop an interpretable method with FS capabilities that has a similar performance to black-box methods for the health care cost prediction problem. We used Japanese health records from Tsuyama Chuo Hospital to test our answer. These records include medical checkups, exam results, and billing information from 2013 to 2018. We used them to compare our method performance with the performance obtained by less interpretable methods such as Artificial Neural Networks (ANNs) and Gradient boosting (GB).
First, we will describe the state-of-the-art for health care cost predictions, introduce FS and DST. Then we will describe our proposed model, which we named Weighted Evidential Regression (WEVREG) with its implementations and improvements. Finally, we will present the model performance in feature selection tasks against prediction methods with FS capabilities using synthetic data, besides its performance in health care costs prediction.
Our results show that WEVREG is able to perform FS tasks obtaining better performance for features with complex dependencies. In health care costs prediction, our method outperforms ANN, and gets similar results to GB but cannot reach the same performance. The features selected by our method show that cost variables are the most important ones to predict future costs, confirming the results obtained in previous works.
This paper extends the work presented previously in [
14] by improving the prediction algorithm and showing how this model can perform feature selection. The paper also explains which are the features in the input data that are most important for making the prediction of the health costs.
3. Data and Problem Description
The problem we address in this work is predicting future health care cost of individuals, using their past medical and cost information. This is a supervised learning problem, which can be formally specified as a regression problem where the input vector is an individual’s past medical and cost information and the target variable y is that person’s health care expenses in a future period (e.g., a year).
The records used for this work were provided by Tsuyama Chuo Hospital, a Japanese hospital located in Okayama prefecture. These records were gathered between 2013 and 2018.
Japan has universal coverage for social health insurance; the system is composed of three sub-systems, National Health Insurance (self-employment), Society Health insurance (for employees) and a Special Scheme for the elderly (75 or older). Every citizen must join one of these three sub-systems according to their occupational status and age. The premium charge for each person is set by each insurer depending on the person’s income. Each medical organization is paid by a fee-for-service principle; at the end of the month every medical facility in Japan has to send a set of claims to be reimbursed by an insurer (as a claim sheet); the insurers have the right to decline a claim if it is incorrect or seems unnecessary.
Medical facilities use a special software for the production of a claim sheet. This software registers all procedures, drugs and devices for each patient. Each procedure has a standard code set by the Ministry of Health, Labor and Welfare (MHLW) that can be translated directly to the International Statistical Classification of Diseases and Related Health Problems codification (ICD-10) [
45], a medical classification list created by the World Health Organization (WHO).
Every claim sheet send by health facilities all over Japan are gathered by the MHLW in a National Database [
46]. The database contains a detailed information on patients such as provided service, age, sex, date of consultation, date of admission, date of discharge, procedures and drugs provided with volumes and tariffs. 1700 million records are registered annually. Unfortunately, we do not have access to the National Database, but we have access to the electronic claims (claim sheets) sent by Tsuyama Chuo hospital to the National Database between 2013 and 2018.
The claims are stored in a set of files; we had to transform these files to study the data. The format of the claims file is confusing without previous knowledge of the structure. The detailed documentation of this format can be found at the Medical Remuneration Service website (
http://www.iryohoken.go.jp/shinryohoshu/file/spec/22bt1_1_kiroku.pdf). A short summary of the file format is shown in
Table 1.
Since a patient’s data are dispersed within these files, we could not use these raw data to predict the health care expenditure of patients. We used the data in these files to create a patient’s representation that we could use for the prediction of an individual’s health care costs. Each patient in the insurance claims could be identified by a unique identifier, which enabled us to follow all patients throughout the years.
We had access to patients’ health checkups as well as to the data sent by Tsuyama Chuo hospital to the National Database. Every Japanese worker needs to take a yearly health checkup to start or continue working at a company, so there were many patients with health checkup data.
Our dataset had patients’ monthly history between 2013 and 2018. However, there were many missing values because most patients had few claims each year. Therefore, we grouped claims yearly so that we could have fewer missing values. We created three different scenarios for this purpose as follows.
Scenario 1: We used a single year of history to predict the next cost value.
Scenario 2: We used two years of data to predict the third one, and
Scenario 3: We used five years of history to predict the costs of the sixth year. We filtered out patients in each scenario if they did not have the required history available, and thus, the sets shrank in each scenario. In the case of missing health check values, we opted to use the median of the exam to replace null values.
Table 2 shows the basic statistics of the sets in each scenario.
4. Proposed Model
A regression task predicts the value of a target variable y using as input an arbitrary vector x. For a regression method to succeed at this task, the predicted target variable value needs to be as close as possible to the real target variable y value. In particular, in a Supervised Learning problem, variable is deduced from a training set or the set of examples that are taken from past observations. In summary a regression task solves the problem of finding a function which best explains the target variable y.
Petit-Renaud and Denœux presented a regression method based on the Dempster–Shafer Theory (DST) called Evidential Regression (EVREG) [
10]. The EVREG model uses a set of observations that have occurred in the past as evidence in order to predict the target value of a new observation. Each observation in this evidence set is given a mass which represents the similarity of the new observation with each observation in the set. We calculate this similarity using a distance function (e.g., Euclidean distance) in the feature space of the observations. The DST ensures that the masses of this evidence set add up to 1, so they can be easily transformed to a probability distribution. Then an expected value is computed as the mass of each past observation
, times its observed target value (
), as shown in Equation (
4).
DST is characterized for reasoning with uncertainty. EVREG uses the width of the observed target variable interval (difference between maximum and minimum target variables) to represent uncertainty as another piece of evidence. The importance given by the model to this interval represents the uncertainty the model has when predicting an outcome. For example, when the new observation is at a great distance from the evidence set, the model assigns a high value to the evidence of the variable y interval; thus we get a high uncertainty in the model outcome, resulting in upper and lower bounds for the predicted target variable proportional to the interval of the target variable observed in the evidence set.
EVREG has been used for predicting the time at which a system or a component will no longer perform its intended function (machinery prognosis) for industrial applications [
43,
44]. Niu and Yang [
43] used the EVREG in a time series task, to predict the degradation trend of a methane compressor. They compared the results of the EVREG model with six statistical indexes; the results showed the EVREG model had the best performance. Baraldi et al. [
44] used the model to estimate the remaining useful life of industrial equipment. Their results have shown the effectiveness of the EVREG method for uncertainty treatment and its superiority over the Kernel Density Estimation and the Mean-Variance Estimation methods in terms of reliability and precision.
We will first describe EVREG (
Section 4.1) in this section. Then, its time complexity and time improvement will be explained in
Section 4.2. We will extend EVREG using gradient descent and a weighted distance function in
Section 4.3 and
Section 4.4; the goal will be to improve the model regression performance and enable it to perform feature selection tasks, which will allow it to rank features in a space. Using this new distance function and optimization approach, the model will update the weight of each dimension. The extended model will be able to rule out or assign low weights to irrelevant features, and assign higher values to the ones that strongly influence the output. This is an important characteristic since feature selection has been shown to improve model accuracy and computing times [
40,
41,
47]. Our aim is that this enhanced EVREG method will perform as well as state-of-the-art regressors for tabular and time series regression problems. In addition, the model will possess a feature selection ability, ranking the features representing the correlation of each feature with the target variable, enabling its users to gain more knowledge of the used data.
4.1. Evidential Regression
EVREG [
10] is a Supervised Learning algorithm. This kind of algorithm uses a sample set as examples to make a prediction. The samples in a Supervised Learning problem are called the training set. Formally, we define the training set as:
where
is an element of the training set,
is the input vector of
and
its output or target value.
Let
x be an arbitrary vector and
y its corresponding unknown target variable. We need to derive the expected value
of variable
y from the training set
. Each element
of the training set is a piece of evidence concerning the value of
y. The relevance of each element in
can be assumed to depend on the similarity between the arbitrary vector
x and the input vectors
of
. It can be assumed that a suitable discount function that depends on a distance measure
can measure this similarity. If
x is close to a vector
in
, we assume that
y is also close to
, which makes the element
an important piece of evidence. If
x and
are at a great distance, it is safe to assume that
has a small effect on
y, and provides only marginal information concerning
y. We will use the Minkowski distance defined as:
where
and
are the values of vectors
and
at dimension
k. When
p is 1 we get the L1 or Manhattan distance and with
p equal to 2 we get L2 or also known as the Euclidean distance. In the case of high dimensional spaces, the vectors become uniformly distant from each other, the ratio between the nearest and farthest vector approaches 1. This phenomenon is more present in the Euclidean than in the Manhattan distance metric [
48,
49], which makes the Manhattan distance to yield better results in distance-based algorithms in the presence of a high dimensional space. EVREG could use any distance measure (e.g., cosine distance) to represent the similarity between two vectors. We will use the Minkowski distance for its flexibility while testing the performance for values
. The value of
p will be chosen as the one that yields the best prediction performance in each problem. We will define the discount function
between vectors
and
using this distance measure as:
where
is a decreasing function from
to
that needs to fulfill
and,
Equation (
7) is the well-known Radial Basis Function (RBF) that decreases monotonically with distance, commonly used as a kernel in the Support Vector Machine (SVM) classifier. Parameter
is the radius of the function, intuitively
defines how far the influence of a vector reaches. In
Figure 1 we can observe Equation (
7) for different
values. RBF-based methods are an active area of research [
50,
51]; various approaches exist to find the optimal parameters such as
. This parameter can be learned using an optimization approach, but often the value is set manually by trial and error. We will try to find the optimal
using a Grid Search approach in this work
The discount function
will represent the similarity between two vectors (higher value means higher similarity); we can use this similarity function to compute the mass (influence) of each element in
given an arbitrary vector
x using the Dempster rule of combination getting:
where
K is a normalization term defined by the DST as:
In Equation (
9),
determines the influence of
in
x and the product determines the effect of the evidence set between these two vectors. We can obtain the influence of every vector in set
using the previous formulas, but we need to consider one extra piece of evidence. We have observed the values of variable
y in every example of set
. EVREG takes this information into account. We will assume that variable
y is bounded to the interval
, and for this interval we will define an additional mass called domain mass
calculated as:
Since we assumed that
y is bounded to the
interval, there exists a probability density function
associated to
and
. Smets et al. [
52] showed that the Pignistic transformation could be used to transform the masses in EVREG to a probability function. In the particular case where output
y is a real number, the Pignistic probability is defined as:
Equation (
12) is a mixture of Dirac distributions and a continuous uniform distribution. With this probability function, we can get the expected value of target variable
y as the Pignistic expectation [
10]:
where
is the expected or predicted value of target variable
y. With the Pignistic expectation we have an upper and lower bound for variable
as:
We can observe that the interval contains variable . The width of this interval can be interpreted as the uncertainty of the response, which is directly associated with the mass of the domain of target variable y.
The computation time of a prediction grows quickly with the size of the training set. For a single prediction in training set
of size
n, we need to compute the mass of each element
which has a vector
of dimension
q. We start by pre-computing the discount function (
) of the input vector
x with every element
in the set
. This computation takes
time for each element in the set, taking a total time of
to compute each mass of
additionally to the discount function. In Equation (
9) we need to compute a product sequence and the normalization term
K. As we have pre-computed the discount functions for the training set, the product sequence takes only
. As for the normalization term
K (Equation (
10)) which takes most of the calculation time for computing Equation (
9), the product sequence on the left side can also be computed in
. The sum of the right side takes time
because of the product sequence contained in it. The domain mass also requires the normalization term
K and the product sequence takes time
. Thus the time complexity for a single mass in the training set is
.
4.2. Improving Computing Time
All the masses of the training set need to be calculated to compute a single prediction. The mass calculation needs to be computed
n times; since we compute a single mass in time
, the
n masses will take time
. Computing a prediction with the formula shown in Equation (
13) uses the masses of the set
, and the mass of the domain of target variables in the training set. This calculation requires to compute the maximum and minimum values, which needs time
, so we can get the prediction of input vector
x in time
.
The quadratic growth of each prediction makes it impossible for the EVREG model to work with large sets; therefore it is difficult to apply it for real-life problems. However, it has been suggested the use of a k-Nearest Neighbors (k-NN) approach [
10] to improve computation time. Their results showed that a k-NN approach did not introduce a significant penalty to the algorithm performance. It is possible to create indexes for the k-NN search in
with this approach in the following way. First, we compute the distance between
x and
for each vector in the training set, then we iterate through the distances
k times selecting the smallest distance. Now, only the masses of the
k nearest neighbors have to be calculated when computing a new prediction of a vector
x. The masses of samples that are not in the set of the nearest neighbors of
x will be assumed to be null. In particular, we use a flat index implementation by Johnson et al. [
53], for the exact nearest neighbor’s search given its better execution times and memory usage compared to other existing solutions.
Given now that only the masses of the
k Nearest Neighbors are relevant for a prediction, the mass of each sample in the training set for an input vector
x is calculated as:
where
is the set of
k Nearest Neighbors of vector
x. Now the normalization term
K can be computed as:
Just the
k neighbors are considered as evidence for a prediction of the domain mass, so the domain evidence is only attributed to its neighbors. We compute the calculation of the domain mass as:
Since now we compute only the masses of the
k Nearest Neighbors, we have to change the size of the training set
n by the number of neighbors
k instead in the expression for computing the time complexity. In Equation (
16) once we got the
k Nearest Neighbors, the normalization term
K will be computed in
. The discount function will still take
and the product sequence will have
complexity. Only the masses of the
k neighbors will be needed to compute a prediction, so only
k masses of the training set will be computed thus obtaining a complexity for a single prediction of
. Assuming that
k is always significantly less than
n, the conclusion is that the complexity for a prediction ends up being reduced to
because of the complexity of the k-NN search.
We performed the following experiment to demonstrate the importance of the k-NN approach for speeding up the prediction computing time. We had two different settings, one for each approach: (i) the first approach used all the training set as evidence; we started with 1000 examples and ended at 30,000 with steps of size 500 in this case. (ii) the k-NN approach; the examples started at 100,000 and finished at 5,000,000 examples with steps of size 100,000. We fixed the number of neighbors to 10 and the number of dimensions used was only 1. The results are shown in
Figure 2. Each value shown in the figure corresponds to the mean execution time of 100 experiments.
The plot in
Figure 2 is in a logarithmic scale. The slope of each curve was computed to observe the complexity of each approach. The
x axis corresponds to the logarithmic number of samples in the training set, and the
y axis is the logarithmic execution time of a single prediction in seconds. The number of vectors varied in each approach due to hardware constraints: case (i) we had to limit the number of vectors that could be tested because of excessive execution time and memory consumption. Case (ii) the machine where the experiment ran could not register execution times properly for a low number of vectors in the training set. As expected, the time complexity of the implemented EVREG with no optimization grew dramatically faster than the k-NN approach as seen by their slopes. The complexity of using all the training set approach seemed to have a larger time complexity than theoretically expected, as the slope in a complexity of
was
. In the k-NN approach we could easily observe a linearity with the size of the training set. Consequently, it became obvious that the k-NN approach significantly dropped execution times and made EVREG a viable option for real world problems.
4.3. Weighted Evidential Regression
This section proposes an improvement to the discount function used in EVREG based on ideas which has been previously introduced to enhance the well-known k-Nearest Neighbors Regressor (k-NN Regressor) [
54], which is another regressor, similar to EVREG. The improved model will be called Weighted Evidential Regression (WEVREG) Model. The aim of this improvement is to boost prediction performance and allow the model to perform feature selection tasks. The k-NN Regressor is a simple and intuitive non-parametric regression method to estimate the output value of an unknown function for a given input. It “guesses” the output value using samples of known values as a training set, and computing the mean output value of the nearest neighbors of the input vector. All neighbors in this method are equally relevant for predicting the target variable in its original version. There is a variation of this algorithm where the importance of each neighbor depends on a distance measure between them, thus using a weighted average of the k-NN vectors in the training set. This weighted k-NN Regressor is a kind of locally weighted regression [
55]. The weight of each neighbor is proportional to its proximity to the input vector. The prediction is computed with this approach by the following expression:
where
is the set of
k Nearest Neighbors of vector
x,
is the value of the target variable of neighbor
,
is a distance function between vector
x and its neighbor
(commonly the Euclidean distance),
is a parameter of the estimator and
Z is a normalization function with value
.
Similar to the EVREG, the weighted k-NN regression uses the Euclidean distance and a Gaussian Radial Basis discount function to assign a weight to each one of its neighbors. Further improvements have been made to the weighted k-NN Regression based on the assumption that the target variable is most accurately predicted using only the most relevant features of the neighbors which adds a Feature Selection process to the algorithm. Navot et al. [
40] introduced a weighted distance function for the weighted k-NN Regressor, which improved the model performance and enabled the model to perform a feature selection task. Given a weights vector
w over the features of size
q the distance function induced by
w is defined as:
where input vector
and
have the same size
q as the weights vector
w. Each value of vector
w represents the importance for each dimension in computing the distance between two vectors, i.e., the amount which a feature contributes to the distance between these two vectors. The model assumes that every dimension contributes the same to the distance between two vectors in EVREG Equation (
6), and consequently, to our discount function (Equation (
7)). However, this is not always the case; for example we could have a feature in our input that has no impact in the target variable we are trying to predict thus it contributes nothing to the similarity between those vectors. For instance, a patient age could have a great impact on that individual health care costs so to predict the costs we want to be closer to patients in the same age group, but maybe the eye color does not influence this cost, so we would not want to include two patients with the same eyes color just for this fact.
We will change the distance function in Equation (
6) with the one that uses weights as presented in Equation (
20) in order to improve the prediction performance of the EVREG model and to gain further understanding about the data.
We will also use the distance measure described in Equation (
20), to compute the k-NN of each input vector
x. The k-NN search implementation we use does not have a feature to use a custom distance measure to compute a k-NN search, so we will have to create the indexes with a transform training set space (applying the weights vector), and then transform the input vector
x that will be predicted. We will get the same distance measure as described in Equation (
20) with this operation.
A simple example is presented to ease the understanding of the chain of thoughts behind this idea. Let us assume we have a sample set of size 5 in a two dimensional space and we want to predict its third dimension. The input vectors (two dimensions) are shown in
Figure 3a. The optimization discussed in
Section 4.2 is used in this example, taking into account only the three closest neighbors to predict the target variables. If we want to predict the output value for vector
C using the three closest neighbors, then we should consider
A,
B and
E as its closest neighbors, shown in
Figure 3a by the distance between
C and all the vectors. Nevertheless, what if we find that the dimension
y is not as significant as
x for predicting the target dimension? This observation means a variation in
y does not affect in the same magnitude the prediction as a difference of the same size in
x. The space to reflect the variation in magnitude is scaled, getting
Figure 3b.
If we now compute the three closest neighbors for vector C then we get vector A, E and D, replacing vector B, thus reflecting the importance of feature x in the similarity function.
If we want the weight of a feature to represent the importance in an input vector, then the range of each one of the feature domains has to be of the same size. Otherwise, we could get a bigger weight of a dimension only to compensate the size of the domain. Therefore, it is recommended to normalize the input features (all values must be between 0 and 1) so that the weights are comparable among features.
We can find the optimal weight vector using an optimization approach such as gradient descent. We will describe the process of finding the optimal weights for a known training set in the next subsection.
4.4. Weight Learning
This subsection will present the process of finding the optimal weights vector in a known training set. We will use a gradient descent algorithm to find a vector w that minimizes the error of the prediction model.
The accuracy of a regressor is commonly measured by computing the difference between the predicted value
and the actual value of the target variable
Y. The estimation error is expressed by a loss function L(
Y,
),
. Likewise in a Supervised Learning problem, our goal is to find a vector
w that induces the smallest error in
L using the training set
and a small generalization error in a validation set at the same time. We will use a gradient-based algorithm such as gradient descent with an Adam optimizer to get the optimal value for
w, because of its clear mathematical justification for reaching optimum values [
56].
The gradient descent algorithm is an iterative algorithm that optimizes variable values in order to find a function minimal value. We use the Mean Squared Error (MSE) as our error function [
57], and we define the loss function
L induced by
w as:
where
n is the number of samples in the training set,
Y is a vector of size
n with the actual values for the target variable of each sample in the training set, and
is the predicted value for each one of the samples in the training set.
y and
are elements of
Y and
respectively.
After defining the function error
L which is induced by the weights vector
w, our goal is to find a vector
w that yields the smallest error possible for the training set given. The estimator
for vector
w is obtained by minimizing this criterion:
Since our loss function
is continuous and differentiable, we can use gradient descent algorithm to find
. The gradient of
needs to be computed in every iteration of our algorithm in order to update the weights
w, then
w is updated by taking a step proportional to the negative of the gradient. We need the partial derivation of
for the gradient computation. This derivation is calculated as:
We need to calculate the partial derivative of the predicted target variable
with respect to
w in order to solve Equation (
23). Therefore, the calculation of the derivative of Equation (
13) gives:
where the derivative of a single mass in set
is calculated as,
With the derivatives of discount function
and the normalization term
K as,
The derivative of the product sequence is calculated as,
Finally, the derivative of the mass assigned to the domain can be calculated as,
Then we can apply this calculated gradient, predicting the target variable
of every example
in the training set
. When we predict the output value of a sample
, we leave out this sample from set
and use all the other
samples for which the actual output value is known in the set as evidence. We will perform this operation multiple times through all the training set, a single pass through all the training set will be called an epoch. The algorithm will perform a fixed number of epochs. At the end of each epoch the weights will be updated by the calculated gradient multiplied by a learning rate factor
and we will store the weight vector only if a local minimum is found. Finally, the method will return the weight vector
which minimizes the loss function
L, as we show in Algorithm 1.
| Algorithm 1 Weight learning. |
| 1: functionWeight Learning()
|
| 2: |
| 3: |
| 4: |
| 5: for do |
| 6: |
| 7: for do |
| 8: | ▹ Remove from training set
|
| 9: | ▹ Predict example with training set S
|
| 10: | ▹ Insert in |
| 11: end for |
| 12: | ▹ Compute loss
|
| 13: | ▹ Compute gradient
|
| 14: | ▹ Update weights vector
|
| 15: if then | ▹ Save best weight vector
|
| 16: |
| 17: |
| 18: end if |
| 19: end for |
| 20: return |
| 21: end function |
The introduction of the weight learning process makes the EVREG model not only better predict the output of a given variable, but also gain the ability to perform feature selection tasks. The main advantage of EVREG is its transparency. This means we can easily track any prediction made by the model; we can get the contribution (mass) of each piece of evidence in the training set , which makes it intrinsically interpretable. The model can now present a ranking of features according to their importance (weight), i.e., the contribution of a feature to each mass computed, thus helping the end user get a better understanding of her/his data.
5. Synthetic Data Experiments
We use synthetic datasets in this section to show the prediction capabilities of WEVREG, testing its prediction performance in various configurations. First we compare its performance with the ones of other well-known regression methods previously used in the health care costs prediction problem. The synthetic datasets that will be used are detailed in
Table 3.
These datasets were previously used by Bugata and Drotár [
41] to test the performance of WkNN. WkNN is a k-NN based algorithm that, like our method, finds the weight of each feature and then uses a k-NN regressor to make a prediction. WkNN will be one of the methods that will be compared to WEVREG.
The Linear Regression dataset is generated using a random linear regression model, then a gaussian noise with deviation 1 is applied to the output. The Friedman regression problem is a synthetic dataset described in [
58], which has only 5 relevant features. The input is uniformly distributed on the interval
. Again a gaussian noise with 1 standard deviation is applied; the formula is shown in Equation (
30).
We used the Mean Absolute Error (MAE) to objectively measure the performance of each method. This error computes the average absolute difference between the predicted cost
and the real value
y, as shown in Equation (
31). Where
and
y are vectors of size
n.
We used three regression methods to compare their performance to the one of WEVREG. The first method was WkNN due to its similarity with WEVREG. Then the two tree-based algorithms to be used were RT and GB. Every method had a unique configuration in each set for simplicity. We used a grid search approach to find the best parameter for each method, except for WkNN where the same configuration as WEVREG was used to demonstrate the difference between both methods. WEVREG used the closest 20 neighbors with a learning rate of
iterating for 100 times. RT considered all features to create a split and 1 was the minimum number of samples required to be at a leaf node. For GB we used 500 boosting stages and 4 as the minimum number of samples to split a node, with a learning rate of
. The output was scaled to be bound to
. The performance of these methods is shown in
Table 4.
GB was the method that obtained the best overall performance as can be observed in
Table 4. In particular, WEVREG obtained a good performance resulting in the second best method in most of the sets. WEVREG obtained similar results to WkNN, with slightly better performance of WEVREG. Furthermore, we tested the performance of the methods with a variable number of features. We could observe the performance of each method in the Linear Regression and Friedman dataset using between 50 and 1000 features in
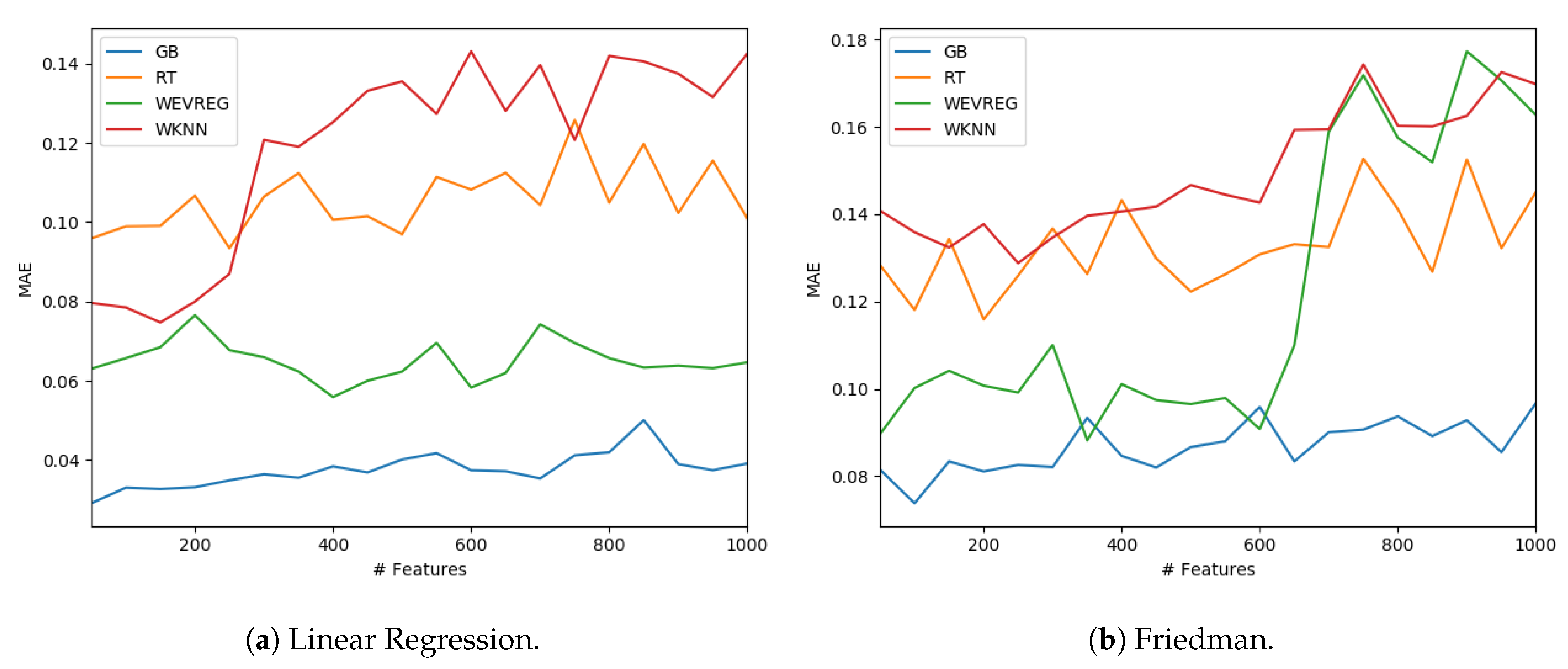
Figure 4.
As shown in
Figure 4, WEVREG did not decrease its performance with the inclusion of more features in the Linear Regression problem (
Figure 4a). This was not the case in the Friedman dataset, where it had an abrupt drop when the 600 features were exceeded, resulting in a performance similar to WkNN. However, WEVREG was able to maintain its performance with the increase of unimportant features for a good portion of the tests, which was more than necessary in the real problem we were trying to solve.
6. Experiments and Results
We had access to claims sent by Tsuyama Chuo hospital to the National database and patients’ yearly health checkups, as mentioned in
Section 3. We crossed data from both sources to obtain:
Demographics: Patients’ gender and age.
Patients’ attributes: General information about patients such as height, weight, body fat and waist measurement.
Health checks: Results from health check exams a patient had undergone. Japanese workers undergo these exams annually by law. Each exam is indexed by a code, and the result is also included. Some examples are creatinine levels and blood pressure. There were 28 different types of exams, and the date when they were collected was also included.
Diagnosis: Diagnosis for a patient illness registered by date and identified by their ICD-10 codes.
Medications: Detailed information of the dosage and medicine administered, including dates and charges.
Costs: Billing information of each patient’s treatment. Including medicine, procedures and hospitalization costs. The sum of these costs in a year is the value that was predicted.
The goal of our experiments was to test the model presented here and compare it to the results that most successful models reported by the up-to-date literature in terms of accuracy and ability to interpret the results. In this work we tried to predict the costs of each patient in the future year.
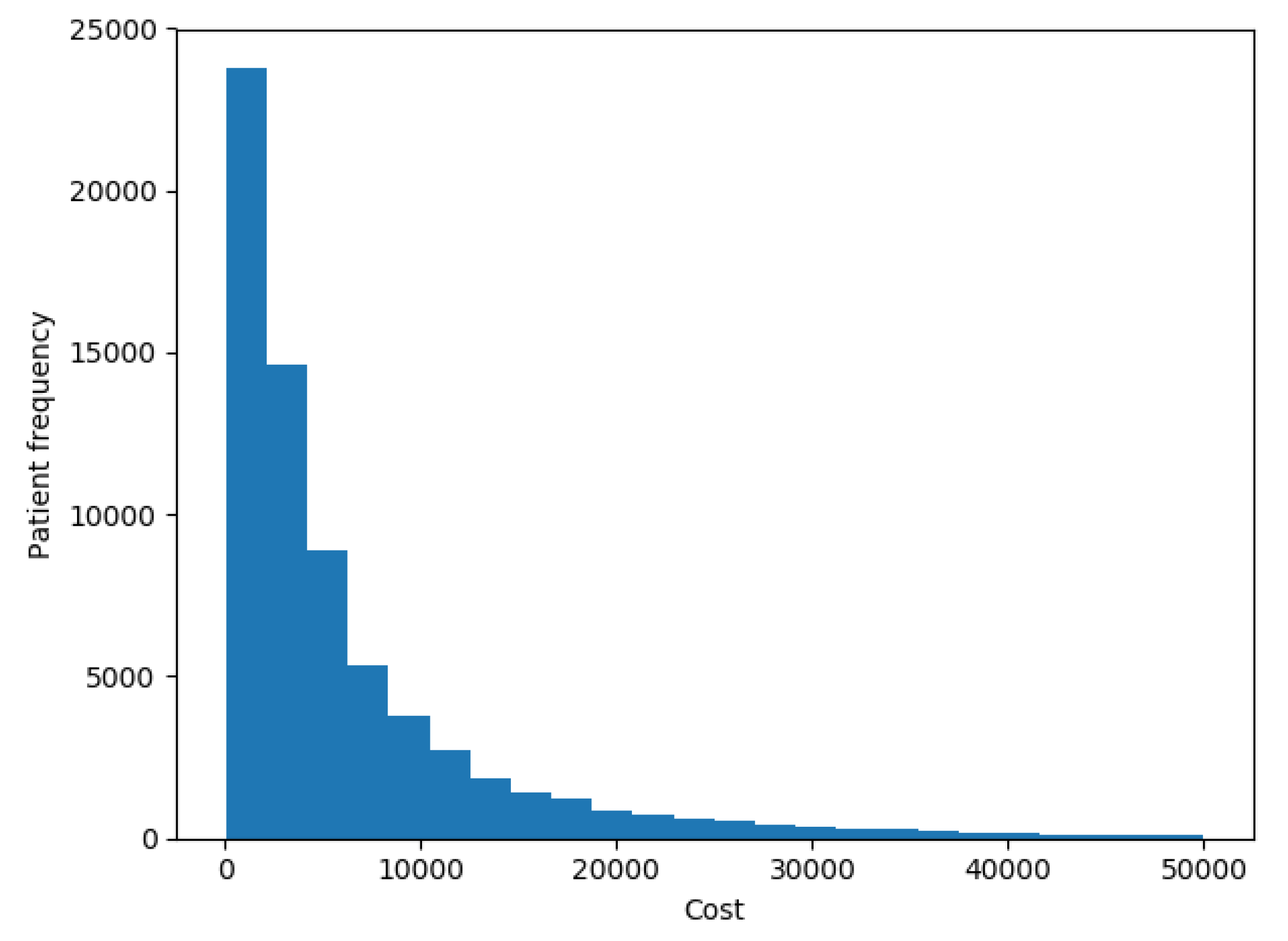
Figure 5 shows the distribution of patients’ costs. The chart shows that costs had the same distribution as described in [
7], with a spike at 0 and a long right-hand tail.
It has been reported [
11,
12,
13] that the use of clinical features (health checks, diagnosis and medications) yields the same performance as using only cost features. This conclusion has been reached without the proper use of an FS algorithm, just by testing the use and omission of clinical data, thus it is not clear whether or not specific clinical data helps to determine a patient’s costs. We will use the clinical features to properly test this hypothesis.
Encoding a patient’s history was done by using all sources available as features. The sources are demographics, health checkups, diagnosis in ICD-10 codification, previous and actual costs.We will only consider chronic conditions for the diagnosis as these can be carried from one year to the next. We will use as chronic conditions the diseases defined by Koller et al. [
59] in a study of the impact of multi-morbidity on long-term care dependency. In the study they used 46 chronic conditions based on ICD-10 codes defined by the Central Research Institute of Statutory Ambulatory Health Care in Germany.
Table 5 shows a description of the patient’s vector representation with the number of variables of each type in each scenario. As an input vector, we used all dimensions shown in
Table 5 except for the actual cost that was used as our target variable.
The evaluation of the performance of our model was done by comparing its results with the methods reported by Sushmita et al. [
12], Morid et al. [
7] and Duncan et al. [
13] for the health cost prediction problem; these works used RT, GB and ANN methods respectively. We also tested a similar regressor algorithm: WkNN.
We used the MAE (Equation (
31)) to measure the performance of each method. However, the MAE is useful to compare algorithms in the same set but not to compare results in different datasets, so we also used the Mean Absolute Percentage Error (MAPE), a modified absolute error where the difference between the predicted variable
and the real value
y is divided by value
y; it is computed as:
where again
n is the size of vectors
and
y. One disadvantage of this error measure is that it does not support zero values in the output of a dataset. It is expected that most individuals did not incur any cost (healthy individuals). This not the case for our dataset, as we have information of individuals that have concurred to Tsuyama Chuo Hospital for treatment or for a health check. Therefore, we can use MAPE as a performance measure.
We also used another measure,
which is the Pearson correlation between the predicted and actual health care cost. It represents the proximity of the predicted cost curve to the real cost curve. This value is calculated as:
where
is the mean of variable
y defined as:
We transformed our target variable (actual costs) to its logarithmic value in each one of the scenarios, as recommended by Diehr et al. [
5], so the distribution of patients’ costs in
Figure 5 was distributed as shown in
Figure 6.
We used a grid search approach for the GB model. We found that the best performance for our dataset was reached when the maximum depth of the individual estimators was 1, the minimum number of samples required to split an internal node was 2 and the number of boosting stages was 125 with a learning rate of . We tried multiple configurations (number of layers, number of neurons in each layer and activation function) for the ANN; the best configuration had two hidden layers, the first with double the number of inputs and the other with 10, the learning rate was set to , and with a Rectified Linear Unit () as an activation function. We let it iterate for 30 epochs so it did not overfit. Concerning WkNN configuration, we used 20 neighbors with a Euclidean distance and a RBF kernel. The learning rate was set to and was let to iterate for a maximum of 30 epochs. Finally, the WEVREG configuration was the following: we trained the fixed weights for each dimension using gradient descent with a learning rate of for 25 epochs, and we used the closest 20 neighbors to improve prediction times, the same quantity used in WkNN.
We performed a 5-fold cross validation procedure to evaluate the performance of each model [
60]. The 5-fold cross validation is a statistical procedure where the dataset is randomly divided into five groups, then one of these groups is treated as a validation set and the other four become the training set. This validation is then performed with every group for a total of five times. Finally, the mean performance for each validation group is calculated to obtain the performance of each algorithm. We performed the 5-fold validation five times (resulting in 25 validations) for every tested method. The median of each performance measure is shown in
Table 6 with its corresponding standard deviation.
Every method increased its prediction performance through every scenario even though the sets shrank in every step; this could be attributed to the availability of longer history for every patient in the sets. RT was the only method that did not increase its performance drastically with each scenario, obtaining the overall worst performance. The best results across all scenarios were obtained by GB. WEVREG obtained similar results to GB, even obtaining a slightly better in the second scenario, but it had a noticeable difference in the last scenario that could be attributed to the smaller size of the set. WkNN obtained worst metrics compared to WEVREG across all scenarios, although it used the same similarity function and similar weight learning. The higher complexity of the masses computation in WEVREG seemed to benefit its prediction power compared to WkNN.
The most important characteristic of WEVREG was its FS capabilities. Weights for each input feature were learned during its training phase. Each feature started with an initial weight of 1, and it was updated in every iteration of the gradient descent. These weights represented the importance of each feature to predict the target variable which in this case was patients’ health care costs. After obtaining the weight of each feature we could select a sub-sample of the features by setting a threshold. We set this threshold to 1, so every weight that increased a little of its value from its starting value would be considered. The top five features on each scenario are shown in
Table 7.
As we can observe across each scenario, the most noticeable features were cost features. WEVREG assigned larger weights to the closest previous costs. These results are in line with previous works [
11,
12,
13], where it was reported that cost features alone are a good indicator for future health expenses.
Patient’s age seemed to be a small differentiable feature, that had a small effect in the search of similar patients. Diagnosis features and health checkups features did not have a noticeable effect for health care costs prediction. In the case of the last scenario, even though it was overshadowed by cost features, diabetes mellitus was a meaningful diagnosis to reach a correct cost prediction. This could be related to the fact that patients with this diagnosis incurred high expenses attributed to inpatient care [
61,
62]. An important feature across all scenarios was the diagnosis of dementia in the previous year; it seemed to be a small factor to group patient with similar costs in cases where it was present.
We used the weights learned by the model to filter out unnecessary features. The selected features were the ones that had been assigned a weight larger than 1.
Table 8 shows the number of selected features by scenario.
We tested once more the performance of the methods with significantly smaller sets in each scenario. The results can be seen on
Table 9.
Every model, except GB, increased its performance in all scenarios, as observed in
Table 9. In particular, WkNN and RT had a significant improvement in its MAE and
scores. ANN and WEVREG had a high improvement in the last scenario, which could be attributed to the large number of unnecessary features in the first place. The initial features seemed to induce too much noise for the models to make precise predictions. On the other hand, GB did not seem to be benefited as the other models with the filtered features since it obtained similar performances, showing the GB resilience in the presence of noise in its features compared to the other tested models. These results show the capability of WEVREG to complete FS tasks, allowing us to decrease the number of features considerably, speeding up training times and model performance. They also show that the most important features for health care costs prediction were cost features; other features such as demographics and some diagnosis such us diabetes mellitus helped to determine a patient’s costs but were not as indicative as previous costs.
7. Discussion and Conclusions
We presented a new regression method with the ability to do FS tasks; it has comparable prediction performance as state of the art regression methods. It can easily show the most relevant features for health care cost prediction; in particular, we obtained that cost features for our dataset are the most relevant to determine a patient’s future health care costs.
Since WEVREG uses a k-NN approach we can easily keep track of how a prediction is made; this is a desirable ability in the health care domain. We compared its results with the predictions made by four models; two of them (GB and ANN) are the best ones from the eleven models analyzed and reported by Morid et al. [
7]. When comparing results we can conclude that our method obtains comparable performances to these methods, proving that it is possible to create and use more transparent models for a regression problem like health care cost prediction, challenging the common belief that complex and black-box like methods are always the solution with the best performance for every problem being presented.
We improved Evidential regression presented by Petit-Renaud and Denœux [
10] to be used in the prediction of health care costs. Our results were obtained using data of electronic health records from Tsuyama Chuo Hospital. The results showed that our Weighted Evidential Regression method obtained
in the best scenario, which shows that a transparent and interpretable method, could perform as current state of the art supervised learning algorithms such as ANN (
) and GB (
).
Even though results are similar or better than previous works, we believe our results are still improvable. One of the approaches to improve performance is classifying patients in cost buckets as recommended by various studies [
7,
11,
13]; this strategy results in better performance but escapes the goal of this work, so we can apply this classification process in future work to obtain a patient’s risk class as first step to try to improve the performance of WEVREG. Another approach could be the use of a nearness to death feature as it has been found that costs rise sharply with it [
26,
27,
28]. It is impossible to know a patient’s near death status with our current data. We could include census data to create the new feature, obtaining nearness to death by age group taking into account the change in life expectancy depending on patients’ age [
63]. We can also try to solve the prediction of health care cost using deep learning methods, but this purpose may become feasible with the availability of a larger dataset. Finally, we also plan to apply this model to other regression problems in the health care domain, such as predicting the hospital length of stay and predicting the days of readmission based on each patient’s diagnosis and history, which are two classic prediction problems in this domain.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}