In this section, we present the result of the experimental analysis in terms of descriptive statistics, hypotheses testing and classification analysis.
3.1. Descriptive Statistics
The boxplot analysis (shown in
Figure 5) suggests that distributions belonging to different Gleason score exhibit different values, symptomatic that the radiomic feature can be useful for discriminating between different Gleason score MRIs.
In detail, in
Figure 5 are depicted boxplots related to 12 radiomic features.
Figure 5a shows the boxplots related to the unique First Order feature we consider i.e., the mean. It appears that the distribution of 4 + 3 Gleason score MRIs is thin if compared with the other ones. With regard to the 3 + 4 and 4 + 4 distributions they are similar (even if the medians of the 3 + 4 and 4 + 4 distribution is different), while the 3 + 3 distribution the smallest.
Figure 5b shows the boxplots related to the Shape Sphericity feature. The 4 + 3 and 4 + 4 boxplots are thinner if compared with the 3 + 3 and 3 + 4 ones. The widest is the one related to the distribution of the 3 + 4 Gleason score (the 3 + 3 and the 3 + 4 boxplots are the most different from the Shape Sphericity feature point of view).
Figure 5c shows the boxplots related to the Gray Level Non Uniformity feature. The 3 + 3 boxplot is the more extended one, if compared with the others exhibited from the 3 + 4, 4 + 3 and 4 + 4 distributions. The boxplot exhibited from the 4 + 3 distribution is the thinner one, while the boxplot related to the 3 + 3 distribution is largest one.
Figure 5d shows the boxplots related to the Long Run Emphasis feature. The 3 + 3 boxplot is slightly wider if compared with the others exhibited from the 3 + 4, 4 + 3 and 4 + 4 distributions. The boxplots exhibited from 3 + 4, 4 + 3 and 4 + 4 distributions are similar from a length point of view, but they have a different median.
Figure 5e shows the distributions related to Long Run Low Gray Level Emphasis. In these boxplots, it appears that the 3 + 4 distribution is wider if compared with to the other ones. The second wider one is the 3 + 3 distribution, but more near the 4 + 3 and 4 + 4 distributions. In particular the smallest one is the distribution related to the 4 + 3 Gleason score: this is symptomatic that the values for the Long Run Low Gray Level Emphasis feature in the 4 + 3 Gleason score prostate cancer range in a small numeric interval.
The boxplots related to the Run Entropy feature are shown in
Figure 5f. The 3 + 4 Gleason score distribution is wider if compared with the other ones. This is symptomatic this feature can be a good candidate to discriminate between this Gleason score and the remaining ones. As a matter of fact, the values that populate the other distributions are ranging in a smaller interval. In particular the 4 + 4 distribution is the smallest.
Figure 5g shows the boxplots related to the Run Length Non Uniformity Normalized radiomic feature. These boxplots are spanning in similar numeric intervals. The 3 + 3 distributions exhibit a range slightly wider if compared with the ones related to the other Gleason scores. In this boxplot, the median exhibited by the several distributions are different, this is the reason why the features can be considered a quite good candidate to discriminate between different Gleason score MRIs.
The Large Area Emphasis radiomic feature belonging to the GLSZM category is depicted in
Figure 5h. Similary to the Run Lenght Non Uniformity Normalized feature boxplots (represented in
Figure 5g), the 3 + 3 distributions is slightly wider if compared to the other ones, while the 3 + 4, 4 + 4 and 4 + 3 distributions exhibit values belonging to similar numeric intervals but with different medians.
Figure 5i shows the comparison between the 3 + 3, 3 + 3, 4 + 4 and 4 + 3 boxplots related to the Gray Level Non Uniformity radiomic feature. The 3 + 3 distributions are the wider one if compared to the other ones. The second wider one is the distribution exhibited by the 4 + 4 Gleason score MRIs, the third wider one is the one exhibited by the 3 + 4 Gleason score MRIs while the smallest one is the distribution belonging to the 4 + 3 Gleason score MRIs.
The distributions related to the Large Area Emphasis radiomic feature is shown in
Figure 5j. All the distributions span in a quite extended numeric interval (for instance, the boxplots are wider if compared to the ones depicted for the Short Run Emphasis feature in
Figure 5h and the Gray Level Non Uniformity feature in
Figure 5i). In detail, the 3 + 3 distribution is the wider one, while the 3 + 4 and 4 + 4 distributions exhibit similar extension, but the minimum in the 3 + 4 is lower if compared to the one related to the 4 + 4 distribution: in fact, the 3 + 4 distribution starts from a lower point with respect to the 4 + 4 distribution, while the higher point is exhibiting a similar value (in fact the two distributions end at a similar point). The 4 + 3 distribution is similar for the extension to the 3 + 4 one, but it is less wide if compared to the 3 + 4 one.
The boxplots related to the Large Area Low Gray Level Emphasis radiomic feature belonging to the GLSZM category are shown in
Figure 5k. The wider distribution in the one belonging to the 3 + 4 Gleason score MRIs: this is symptomatic of the fact that this feature can be a good candidate to discriminate between 3 + 4 Gleason score prostate cancer MRIs and the other ones. The second wider distribution is the related to the 3 + 3 Gleason score MRIs, while the 4 + 4 and the 4 + 3 exhibit a similar extension, whit the difference that the minimum of the 4 + 4 distribution is higher with respect to the one of the 4 + 3 distribution, and the maximum of the 4 + 4 distribution is lower with respect to the one obtained from the 4 + 3 distribution.
Figure 5l shows the distributions related to the Zone Entropy radiomic feature belonging to the GLSZM category. Similarly to the distributions related to Large Area Low Gray Level Emphasis (shown in
Figure 5k), the 3 + 4 boxplot is the wider one if compared to the other distributions: also this feature represents a good candidate to discriminate between Gleason score 3 + 4 MRIs and the other ones. With regard to the other distributions, the 3 + 3 one is the second widest one, while the 4 + 4 the third widest one. The 4 + 4 distribution is the smallest one.
Figure 5m shows the distributions related to the Zone Percentage radiomic feature belonging to the GLSZM category. The 3 + 3 distribution in the wider one, while the 3 + 4, 4 + 4 and 4 + 3 distributions exhibit a similar span. The difference between these three distributions is in the starting and ending point: as a matter of fact, the 4 + 3 distribution exhibits the lower minimum value, while the higher minimum value is obtained from the 3 + 4 distribution. From the higher value point of view, the maximum value is exhibited from the 4 + 3 distribution, while the lower one is obtained to the 4 + 4 distribution. The median of the four distributions is different.
The distributions for the Zone Variance feature belonging to the GLSZM category is depicted in
Figure 5n. The 3 + 3 distribution is the wider one, while the 3 + 4, 4 + 4 and 4 + 3 distributions exhibit a similar extension. In detail the 3 + 4 and the 4 + 3 distributions are quite similar (with the difference that the maximum value of the 4 + 3 distribution is higher if compared to the one exhibited from the 3 + 4 distribution). With regard to the 4 + 4 distribution, its numeric interval range is populated by a set of numbers, which are higher if compared to the ones related to the 3 + 4 and 4 + 3 distributions.
Remark 1. From the descriptive statistics, we find that the distributions related to 3 + 3, 3 + 4, 4 + 3 and 4 + 4 Gleason score prostate MRIs range in different interval for the considered radiomic features. This may reveal that the features can be a good candidate for building a model with a good Gleason score prediction performance. Clearly, this result can be confirmed only by the hypotheses testing and by the classification analysis outcomes.
3.2. Hypothesis Testing
The idea behind the hypothesis testing is to understand if the radiomic features exhibit different distributions for the patient afflicted by different Gleason score grade with statistical evidence.
We consider valid the results when both the considered tests reject the null hypothesis, which results is shown in
Table 1.
For the features #15, #16, #21, #27, #28, #43, #44, #56, #66, while the Mann-Whitney test is not passed by features #16, #21, #27, #28, #43, #44 and #66 the Wald-Wolfowitz test is not passed. The #16, #21, #27, #28, #43, #44 and #66 features not passed both the Wald-Wolfowitz test and the Mann-Whitney one.
To conclude, the features that have not passed the null hypothesis test are the following: #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #17, #18, #19, #20, #22, #23, #24, #25, #26, #29, #30, #31, #32, #33, #34, #35, #36, #37, #38, #39, #40, #41, #42, #45, #46, #47, #48, #49, #50, #51, #52, #53, #54, #55, #57, #58, #59, #60, #61, #62, #63, #64, #65, #67, #68, #70 and #71 i.e., 60 features on the 71 considered in the study.
Remark 2. The radiomic feature distributions show a statistically significant difference by running both the tests. In particular, 59 features on 71 passed the Mann–Whitney test and the Kolmogorov–Smirnov tests. The classification analysis with the designed deep neural network will confirm if the considered radiomic features are able to discriminate between prostate cancer MRIs labeled with different Gleason scores.
3.3. Classification Analysis
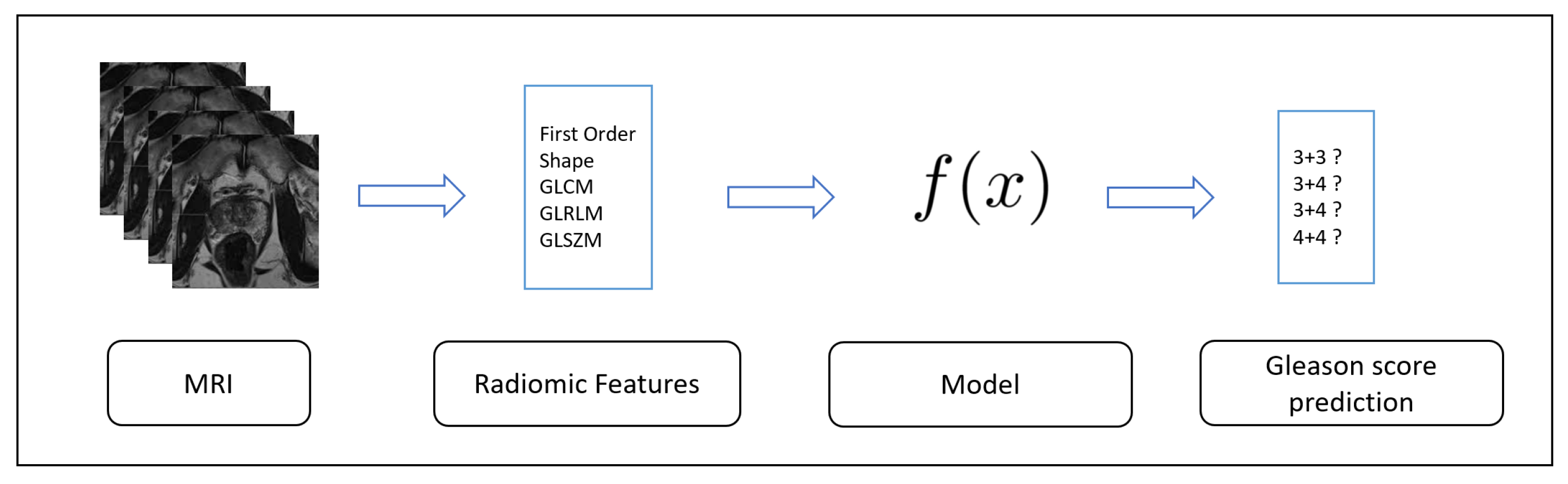
In this section, we present the results of the experiment aimed to verify whether the designed deep neural network is able to discriminate between prostate cancer MRIs labeled with different Gleason score.
We considered the following metrics in order to evaluate the results of the classification: Sensitivity, Specificity, Accuracy and Loss.
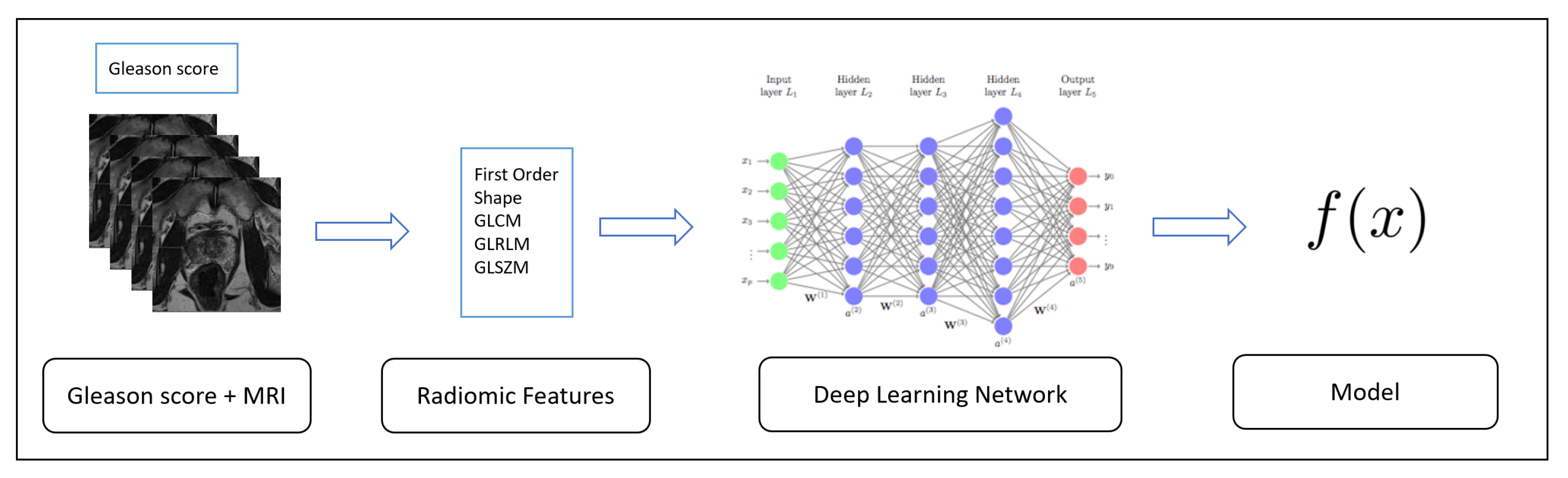
The deep learning network training, with which a number of epochs equal to 10, is performed by splitting the dataset in two sub-dataset with an equal percentage of instances belonging to the four considered classes: 80% of the instances belonging to the 3 + 3, 3 + 4, 4 + 3 and 4 + 4 Gleason scores were included into the training dataset, while the remaining 20% were included in the testing dataset. We performed five different classifications, in order to evaluate the full dataset (we performed a five-fold cross validation).
The deep learning network training is performed by splitting the D#1 dataset into two sub datasets with an equal percentage of instances belonging to the four considered classes (i.e., GS): 80% of the instances belonging to the 3 + 3, 3 + 4, 4 + 3 and 4 + 4 classes into the training data-set (i.e., TD#1), while the remaining 20% was included in the testing dataset (i.e., ED#1). We performed five different classifications, in order to evaluate the full dataset (we performed a five-fold cross-validation). The full D#2 data-set (i.e., ED#2) is considered as the testing set. We consider the D#1 data-set for model training and for cross-validation, while the D#2 data-set is fully considered for the testing with the aim to evaluate the performances of the proposed method with data-set belonging to different institutions. In fact, the D#1 dataset was gathered from the Boston Medical Center, while the D#2 one from the National Cancer Institute in the USA.
Table 2 shows the number of MRI slices considered for each Gleason score and the normal cases for the training and the testing of the proposed network, while
Table 3 shows the performances obtained by the proposed deep neural network in Gleason score and normal cases prediction. The 300 slices belonging to the 10 patients normal cases, belonging to the third data-set, have been distributed in the following way: 200 slices in the TD#1 data-set, 50 slices in the ED#1 and the remaining 50 slices in the ED#2 data-set.
As shown in
Table 3, the proposed method obtains a sensitivity ranging from 0.96 to 0.98, a specificity ranging from 0.97 to 0.99 and accuracy from 0.96 to 0.98 in Gleason score prediction. A sensitivity equal to 0.96, a specificity equal to 0.97 and an accuracy of 0.96 are reached in normal cases identification, confirming that the proposed deep learning network is able to discriminate between different Gleason scores, but also from prostate cancerous and healthy areas.
Figure 6 shows the Accuracy and Loss plots.
Figure 6a,b shows, respectively, accuracy and the loss obtained for the 3 + 3 Gleason score prediction. The average accuracy is equal to 0.98473, while the average Loss is equal to 0.05509 considering 10 epochs. From the plots in
Figure 6a,b the deep neural network reaches the lowest (highest) Loss (Accuracy) values after eight epochs: as a matter of fact, in the 9th and 10th epochs there is not Loss worsening (Accuracy improvement).
The performances obtained for 3 + 4 Gleason score prediction are shown in
Figure 6c,d. The average accuracy is equal to 0.96667 and the average loss is equal to 0.54316 in the 10 considered epochs. Differently from the 3 + 3 plots (depicted in
Figure 6a,b), after four epochs the deep neural network reaches the best tuning.
Plots in
Figure 6e,f are related to the performances obtained for the Gleason 4 + 3 prediction. The deep neural network obtains an accuracy equal to 0.98780 and a loss equal to 0.20396 on the 10 epochs. The deep neural network employs three epochs to reach the best tuning.
Average accuracy and average loss related to the 4 + 4 Gleason score prediction are plotted in
Figure 6g,h. An accuracy equal to 0.97561 and a loss equal to 0.42098 is reached by the deep neural network. The number of epochs employed to reach the lowest (highest) loss (accuracy) values are equal to 5.
Furthermore, to demonstrate the effectiveness of the designed deep network in Gleason score detection, we performed the experiment with supervised machine learning algorithms: J48, RandomForest (RF), Bayesian Network (BN), Neural Network (NN), Support Vector Machine (SVM) and K-nearest neighbors (kNN) with a five-cross fold validation (i.e., the same folds involved in the evaluation of the deep learning network). The difference between the proposed deep learning network and the NN algorithm relies on the architecture: as a matter of fact, the neural network in the machine learning experiment is very simple considering that contains only one hidden layer. From the other side, the deep learning network we propose is composed of four 1D convolutional layers, one pooling layer, one flatten layer, one dropout Layer and one dense layer.
The supervised machine learning algorithms take into account with following parameters:
J48: bathSize equal to 100, confidence factor of :
RF: bathSize 100, bagSizePercent 100, numIterations 100;
BN: bathSize 100, maxParents 1.
NN: epoch 10, batchsize of 100,
SVM: kernel function degree equal to 3, batchsize of 100,
kNN nearest neighbours equal to 1, batchsize of 100.
Table 4 shows the machine learning results in Gleason score detection.
As shown by the results in
Table 4, the best results are obtained by the SVM model with an accuracy ranging from 0.85 (
Gleason score), 0.86 (
Gleason score), 0.87 (
and
Gleason score) and 0.88 for the normal cases detection.
Moreover, as additional comparison to show the radiomic features effectiveness, we consider the Embedded Localisation Features (ELF) [
20], aimed at extracting the feature locations from a pre-trained network with the aim to build a detector, by avoiding hand-crafted feature detection. This information is computed from the gradient of the feature map with respect to the input image. This provides a saliency map with local maxima on relevant keypoint locations. In particular we consider as a pre-trained network the VGG model, a convolutional neural network achieving 92.7% top-5 test accuracy in the ImageNet dataset evaluation, composed of over 14 million images belonging to 1000 different classes. ELF requires neither supervised training nor fine-tuning and it is considered as preprocessing with the aim to compare the features obtained by exploiting ELF with the considered radiomic features. As stated from authors in [
20] high-level feature maps usually exhibit a wider receptive field hence take higher context into account for the description of a pixel location. This leads to more informative descriptors which motivate us to favor higher level maps. As a matter of fact, whether the feature map level is too high, the interpolation of the descriptors generate vectors too similar to each other. For instance, the VGG pool4 layer produces more discriminative descriptors than pool5 even though pool5 embeds information with higher-level semantics. We experiment on the VGG pool4 layer considering the task of discrimination between different Gleason score and normal patients. Authors in [
20] provide the code repository freely available for research purposes (
https://github.com/abenbihi/elf) Results of this experiment are shown in
Table 5.
As shown from the ELF experiment result, it emerges that the method proposed in [
20] obtains an accuracy ranging from 0.94 (for the normal patient detection) to 0.97 (for the 3 + 3 Gleason score detection), overcoming the performances reached from the machine learning experiment: as a matter of fact the best performances reached in the supervised machine learning experiment are the SVM one with an accuracy ranging from 0.85 (for the 3 + 4 Gleason score detection) to 0.88 (for the normal patient detection). We highlight that the ELF method does not overcome the proposed method, based on the adoption of radiomic features: as a matter of fact, we obtain slightly higher accuracy, from 0.96 for normal patient detection to 0.98 for 3 + 4 and 4 + 3 Gleason score detection. We think that the proposed method obtains higher accuracy because the area of interest (i.e., the cancerous one) is selected by radiologist and it is not gathered by a model.
Below we show the performances obtained by the proposed method in patient classification. As a matter of fact the proposed method considers a single slice as an instance, and for this reason we compute the sensitivity, the specificity and the accuracy metrics for each patient, with the aim to provide to radiologists a diagnostic tool.
In particular, we apply the following formula for the patient-grain performance:
where
stands for Patient Prediction,
represents the number of MRI predicted with the right Gleason score and
is the total number of MRI belonging to the patient under analysis.
We mark a patient as rightly predicted if ≥ .
In
Table 6 we show the results obtained for the patient-grain experiment.
This analysis is confirming the results previously obtained: the accuracy is ranging from 0.96 to 0.98 even for the patient-grain experiment.
Considering the importance in the medical context to reduce the time and effort for the analysis we report below the time performance analysis.
With respect to computational time the proposed method for training employed approximately 24 min for training and 5 min for testing. With regard to the supervised machine learning experiments, in average the machine learning models employed 6 min for training and 2 min for testing.
The time employed to make a prediction for a patient under analysis is approximately 27 s. The experiments were performed on a Microsoft Windows 10 machine equipped with the following configuration: 8th Generation Intel Core i7 2.0 GHz CPU, NVIDIA GeForce MX150 graphic card, 16 GB RAM memory and 500 GB Hard Disk.
Remark 3: The classification analysis suggests that the developed deep neural network input with the considered radiomic features is able to discriminate between different Gleason score prostate cancer MRIs with encouraging performances. As a matter of fact the Accuracy obtained is equal to 0.98473 for the Gleason 3 + 3 detection, 0.96667 for the Gleason 3 + 4 detection, 0.98780 for the Gleason 4 + 3 detection and 0.97561 for the Gleason 4 + 4 detection.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}