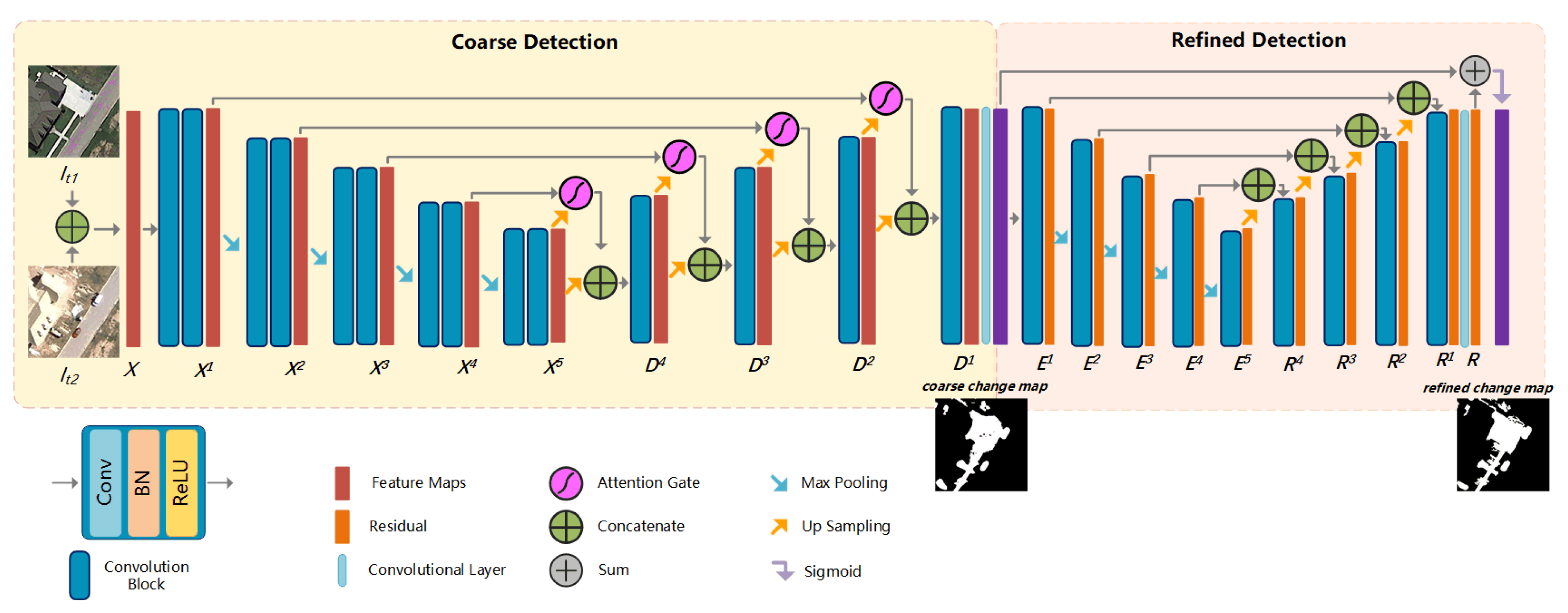
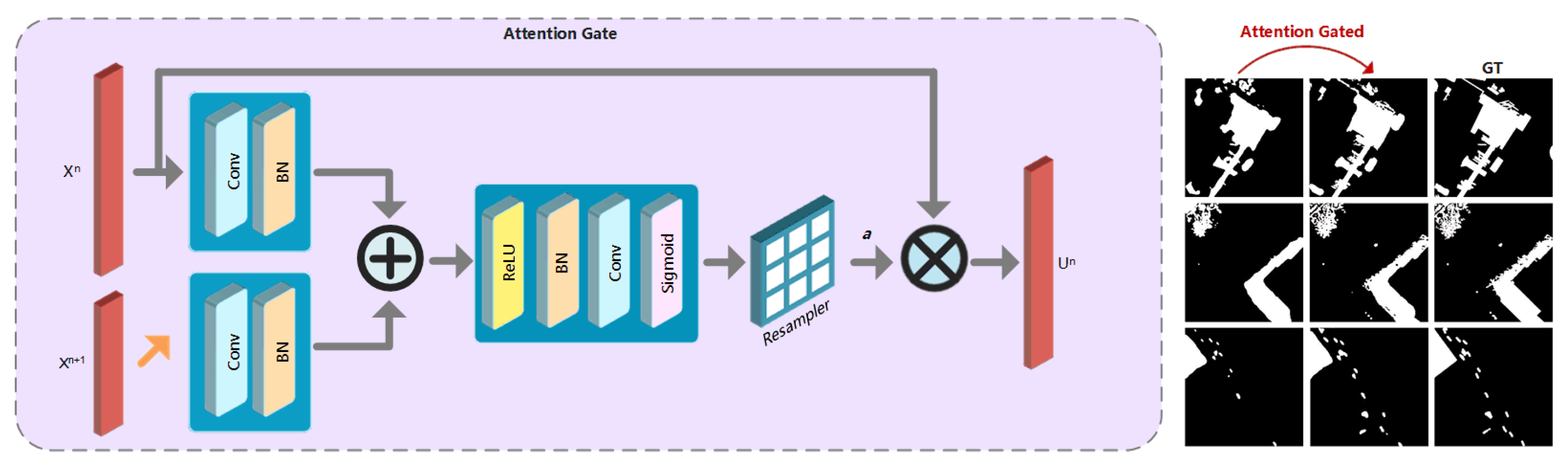
3.1. Datasets and Settings
Limited by manual labeling labor, the satellite image change detection datasets which can be used for deep learning are not so abundant. We implement our models on two benchmark datasets: LEBEDEV and SZTAKI.
The dataset provided by LEBEDEV [
37] is one of the suitable datasets. There are two types of images in this dataset: composite images with small target offset or not, and real optical satellite images with seasonal changes, obtained by Google Earth. We apply our models on the real images, which are 11 pairs of optical images, including seven pairs of seasonal variation images of
pixels without additional objects and four pairs of
pixels with additional objects. For convenience of training, the original image sets are clipped into subset with about 16,000 image sets of real-temporal seasonal images with size of
, distributed with 10000 train sets, 3000 test sets also validation sets. The results in
Table 1,
Table 2,
Table 3 and
Table 4 are performed on the 3000 test sets.
The spatial resolution is 3 cm to 10 cm per pixel. As shown in
Figure 3, this dataset is quite challenging due to its largely seasonal differences. The manually labeled change maps only consider the appearance or disappearance of objects as the changed area, while the visual differences caused by seasonal or brightness difference are defined as the unchanged.
The SZTAKI AirChange Benchmark dataset contains three sets of registered optical aerial images provided by the Hungarian Institute of Geodesy cartography and Remote Sensing (
). (1) SZADA consists of seven pairs of
pixels images marked manually, which were captured in 2000 and 2005, covering about 9.5 square kilometers at a resolution of 1.5 m per pixel. (2) TISZADOB consists of five pairs of images taken in 2000 and 2007 with similar resolution and size with SZADA. (3) ARCHIVE is an image obtained by
in 1984 and Google Earth in 2007, respectively. Due to the large time span and low image quality, the experiment is mainly carried out on SZADA and TISZADOB, pairs of bi-temporal pairs from each are shown in
Figure 4.
To obtain the learning clips, we crop out the upper left corner with a size of
of each image as the test part. For the rest part, we apply
sliding windows clipping with overlap as the training set. The training set is augmented by rotation of
,
,
, horizontal flip and vertical flip. Following other benchmark methods [
3], we choose the SZADA/1 and TISZADOB/3 from subsets as two testing sets and the rest of each as training sets, independently. The results in
Table 5 are performed on these two subsets. The adopted evaluation protocols are the same as the compared methods. We implement our proposed method under PyTorch on GPU environment. During the training process, the network is optimized with a learning rate of
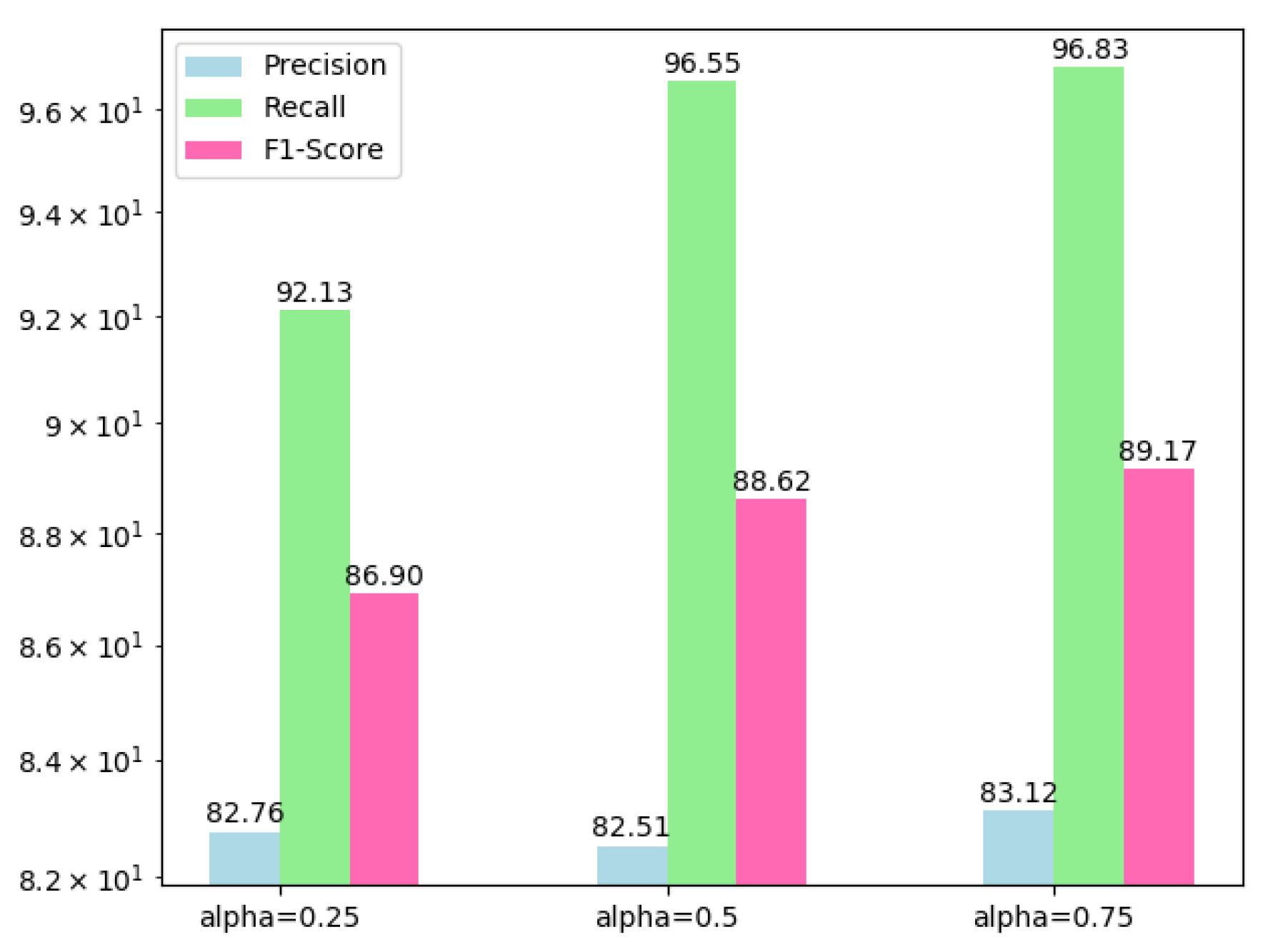
. Based on our GPU memory, the batch size is set to 4. Furthermore, we apply auto augmentation during the training. The data loader will automatically augment the batch of images with transformations according to the random augmentation probability value, including random rotation clipping, rotation, flip and brightness, contrast, saturation changing. For loss functions, the coefficient
of
is set to
. Parameters for
are set to:
,
. For
, the sliding window size is 11,
and
.
3.4. Result Comparisons
To verify the effectiveness and superiority of our proposed BA2Net, we compare it with some SOTA methods, introducing briefly as:
CD-Net [
35] is a pixel-wise change detection net, which is constructed on the structure of a typical Siamese network with contraction blocks and expansion blocks. The change map is generated by a Softmax layer.
DSCN [
22] trains AlexNets sharing parameters and cutting off the pooling layers as the streams of Siamese network. By discarding pooling operations, it keeps the respective field and feature maps dimensions.
FC-EF [
3] refers to fully convolutional early fusion. It stacks an image pair as one input and feeds it into a standard U-Net. This network is structurally simple and effective.
FC-Siam-conc [
3] processes each image by the encoder part of U-Net, separately. Furthermore, then concatenates each feature map pair in encoding connecting into the decoder part by skip connections.
FC-Siam-diff [
3] is a network similar to FC-Siam-conc. The different point is its skip connections link with the difference of encoding feature map pairs, instead of concatenating directly.
FCN-pp [
32] is an FCN applied with pyramid pooling which can capture a wider receptive field and overcome the drawbacks of global pooling.
DSMS-FCN [
5] proposes a unit that is able to extract multiscale features in the same layer. Based on the proposed unit, deep Siamese multiscale fully convolutional network is designed for supervised change detection. The structure is similar to the FC-Siam-diff.
UNet++MSOF [
2] is a 2-channel network introducing multiple dense intermediate nodes and skip connections into standard U-Net. The advantage of this structure is that it can learn from multiple scale feature maps more automatically. While using deep supervised strategy by obtaining four output maps supervised by multiple side-outputs fusion (MSOF) loss. It has excellent performance on LEBEDEV, but for the boundary accuracy and multiple small objects, it still can be improved.
IFN [
1] utilizes a feature extraction network with shared parameters to encode the original images, which is similar to the FC-Siam-conc. In the decoding process, it implements discrimination learning on the difference between the features of each layer in the former streams. Different from the FC-Siam-conc, it applies the deep supervision strategy to enhance the performance on the boundary integrity and internal compactness. However, it still misses a few objects when images contain multiple objects.
For quantitative comparisons, the evaluation metrics were calculated and summarized as shown in
Table 4 and
Table 5, on LEBEDEV and SZTAKI, respectively. The best scores are highlighted with bold and red, while green and blue indicate the second best and the third best, respectively.
As can be observed from the
Table 4, CD-Net and DSCN scores are the lowest and far lower than other methods. CD-Net operates decoding directly on the features obtained by encoding layers to generate original sized change maps, while DSCN abandons the pooling operations in the common process of convolutional encoding to maintain the respect fields and the feature maps sizes. These simple strategies without design of cross-scales features learning result in a certain amount of error accumulation, which leads to their low scores in all measurement metrics. Besides these two networks, all methods are designed to build on the encoder-decoder structure with cross-scale designs. By using skip connections with different fusion strategies, FC-EF, FC-Siam-conc and FC-Siam-diff achieve higher scores. Among them, FC-EF using the early fusion strategy boosts F1 scores by about 10% than the previous two networks. On the basis of that, by applying late fusion strategy, FC-Siam-conc and FC-Siam-diff improve their F1 scores by about another 5%, achieving at around 83%. In order to further utilize the multiscale features, FCN-PP introduces pyramid pooling on the FCN framework. Compared with FC-EF, which has a similar framework, FCN-PP improves the F1 score by about 3% but is still lower than FC-Siam-conc and FC-Siam-diff. Instead of conventional convolution units, DSMS-FCN designs a multiscale convolution unit to utilize features in multiple scales. Compared to its backbone framework FC-Siam-diff, it enhances all evaluation scores obviously.
The top three scores are concentrated in UNet++MSOF, IFN and our BA2Net which further enhance the evaluation scores compared to the previous methods. For the multi-scale issue, UNet++MSOF adopts UNet++ as the detection model. This fully and densely design of automatically learning strategy can take fully use of multiple features at all scales. At the same time, through the combination of four shallow outputs supervised by its multiple fusion loss, UNet++MSOF reaches superior results than previous methods. Based on the framework of FC-Siam-conc, IFN introduces spatial and channel attentions and gradually carries out supervised fusion in the process of decoding. IFN achieves the current highest precision (94.96%) due to its design for sufficient depth and parameters on multiple scales.
These two networks have rich designs for multiple scale features, which ensures good precision. However, they pay nearly even attention to multiple scales and weakly to help the detection rate of changed areas. Our proposed BA2Net reaches the current highest recall, under the premise of the third precision, which is attributed to the introduction of attention mechanism guided by deeper features into our network. Such a mechanism allows a higher ability to locate more changed areas under the guidance of more semantic context information.
To qualitatively compare with other SOTA methods, we select top-2 methods (UNet++MSOF, IFN) other than our proposed method and a classic framework (FC-EF) as the quality comparison. As illustrated in
Figure 9, the proposed BA
2Net is obviously superior to other methods in quality.
As the showing samples shown in
Figure 9, five sets illustrate the effectiveness of our model with positive areas from less to more. In the first set, there are certain false positive detection for FC-EF, and minimal false positive for UNet++MSOF and IFN. Furthermore, for the upper right region of change with jagged detail, other comparing methods are weaker in describing edges than our model. The second set contains multiple variation changed regions, FC-EF and IFN appear obvious regional missed detection and false positive. UNet++MSOF is more accurate, but the shape errors in the lower left corner are obvious. The third group has various changed regions with smooth shapes. On the basis of basically locating the variation areas, our model is superior to other methods in the accurate description of shapes. The fourth group is similar to the third group but more challenging, with smaller, more shapes-rich regions. FC-EF and IFN miss detection on multiple small pieces of changed regions, and the shape description is less accurate. UNet++MSOF has no obvious mistake locating in detection, but the edges are not exact enough. Comparatively, our model performs particularly well on this type of data, being able to basically locate all the various regions and to describe shapes exactly. The variation areas in the fifth set are characterized by multiscale and multi-shape. It can be observed from the highlighted boxes that our model is obviously superior to other methods.
On the dataset of SZTAKI quantitative summarization
Table 5, the subsets SZADA/1 and TISZADOB/3 are treated as two test-sets separately. It can be observed that the top three scores are not concentrated in a few methods, but are scattered in various methods. At the same time, though both subsets belong to one dataset, except for the proposed model, none of the other comparing methods can simultaneously be ranked in the top three on F1 scores.
The two methods with weak performance in the LEBEDEV, CD-Net and DSCN are also relatively weak in SZADA/1, while the DSCN reaches a third precision on TISZADOB/3 and a good F1 score. The three models (FC-EF, FC-Siam-conc, FC-Siam-diff) that perform well on LEBEDEV work still well on these subsets, with FC-Siam-diff reaching SZADA/1’s second best F1 score and FC-EF ranking first on TISZADOB/3. FCN-PP, which introduces pyramid pooling, is similar to FC-EF on SZADA/1 and surpasses some other complex frameworks. Although DSMS-FCN reaches the top F1 score and precision on SZADA/1, it is the lowest F1 score and recall on TISZADOB/3. UNet++MSOF, which has an advantage in precision, has the highest precision on TISZADOB/3. IFN, on the other hand, is relatively weak on both these subsets. Our model ranks the third and the second best F1 scores and reaches the highest recall on these subsets.
In general, there is hardly a method with absolute superior performance over the SZTAKI. By utilizing more multi-scale features, DSMS-FCN and UNet++MSOF obtain the highest precision in these two subsets, respectively. However, neither of them can guarantee excellent effectiveness on both subsets, especially DSMS-FCN’s performance on TISZADOB/3 ranks much lower than on SZADA/1. Benefit from high-level features guided attention mechanism, our model shows a stable and excellent performance in recall, and is the highest model on both datasets. In addition, it ranks second and third in F1-score, respectively, and the robustness of the proposed method is obviously superior to the compared methods. In terms of F1 scores, the models with the highest scores have no obvious commonality except that both are based on the FCN framework. Though proposed model have no obvious advantage in precision may due to the limited training data, it still shows stable and promising recall and competitive F1 score.
Meanwhile, we illustrate qualitative comparison with the top three quantitative methods in
Figure 10 on SZADA/1 and TISZADOB/3.
In the bi-temporal image pair from SZADA/1, it contains a large number of multiple small objects with sorts of appearances. Our model is more accurate than the other top three ranking methods in expressing the shape form of the changed regions, especially the region with more winding boundaries. However, there are some false positive dots in the broad background region. In the pair has large areas of change with smooth edges, the TISZADOB/3, our model performs well. It can accurately locate the large changed areas and clearly represent edges.
To sum up, abundant comparative experiments on LEBEDEV and SZTAKI prove the effectiveness of our BA2Net. From the perspective of qualitative analysis, our model shows the boundary delineation ability superior than other methods in both datasets, which can represent boundary clearer and closer to GTs. Furthermore, our model can detect and locate multiple changed areas in excellent detection rate. In quantitative analysis, the promising recall on both datasets also illustrate the detection capability of our model. However, the visually closer boundary may not be sensitive to precision, so there is no obvious advantage in precision. In combination with the above, there are still advantages in F1 scores of our model.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}