
A Straightforward and Efficient Instance-Aware Curved Text Detector


Abstract
:1. Introduction
- (1)
- We propose a text detector, which can accurately locate curved text appearing in the scene through several consecutive straightforward and effective steps.
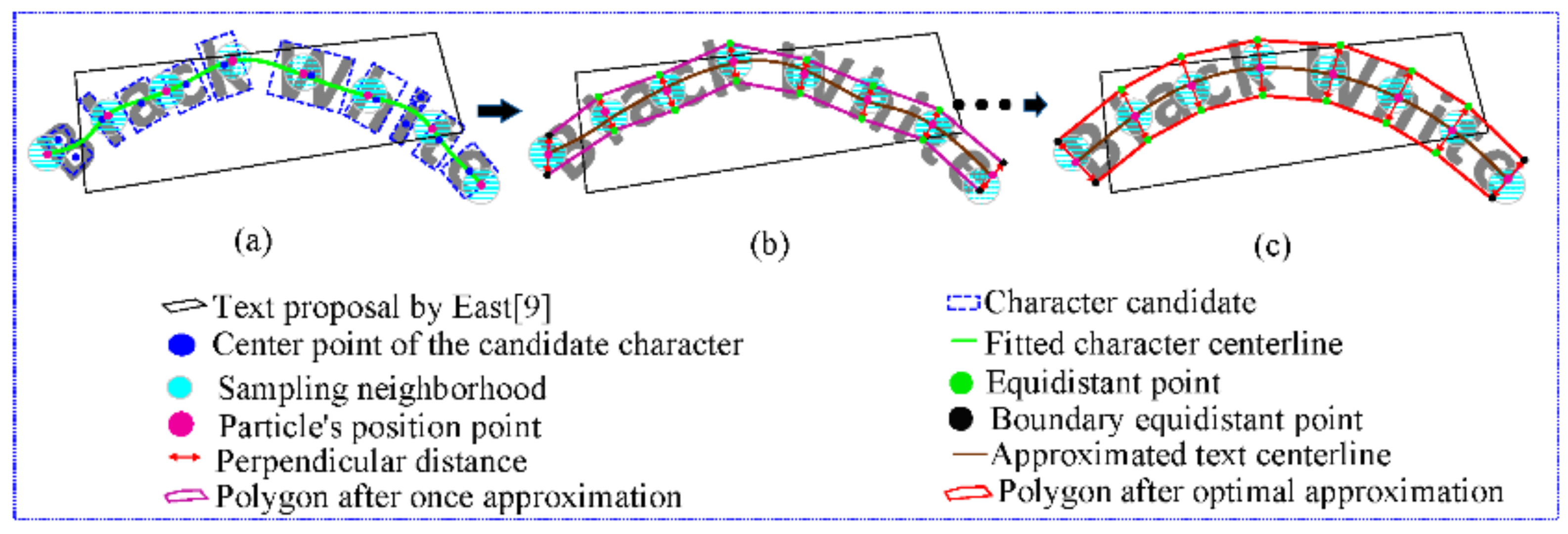
- (2)
- To fine-tune the result of the regression-based text detector, we propose a particle swarm optimization-based text shape approximator called PSO-TSA, which can quickly approach text shapes without heavy pre-training or pre-learning in advance.
- (3)
- To improve the text instance completeness, an instance-aware component merging network (ICMN) is designed to merge adjacent text subparts, which can be flexibly adapted to text detection results of any shape.
- (4)
- Although the entire pipeline is not an end-to-end mechanism, the experiments on five text benchmark datasets show that our method not only achieves excellent harmonic mean (H-mean) performance but also has relatively high speed.
2. Related Works
3. The Proposed Method
3.1. Background
3.2. LOMT
3.2.1. PSO-TSA
| Algorithm 1. Particle Swarm Initialization. |
| 1. Define particle swarm , in which , and , respectively. |
| 2. Construct spatial neighborhoods, each denoted as , . 3. Set the range of equidistant values of particle position points as . 4. for each do 5. Randomly sample a point in each , and all sampled points form a point set . 6. Randomly sample values in interval to form a equidistant set . 7. for each do 8. , and . 9. end for 10. end for |
3.2.2. ICMN
4. Experiment and Discussion
4.1. Datasets and Implementation Details
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Comparison with State-of-the-Arts
4.2.1. Experiments on Multi-Oriented Text (IC15, IC17 and TD500)
4.2.2. Experiments on Two Curve Text Datasets (Total-Text and CTW1500)
4.2.3. Speed and Ablation Analysis
4.2.4. Disadvantages and Advantages
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Epshtein, B.; Ofek, E.; Wexler, Y. Detecting Text in Natural Scenes with Stroke Width Transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2963–2970. [Google Scholar]
- Neumann, L.; Matas, J. A method for text localization and recognition in real-world images. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; pp. 770–783. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–10 December 2015; pp. 91–99. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Process. 2018, 27, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Zhao, L.; Li, X.; Wang, X. Geometry-aware scene text detection with instance transformation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1381–1389. [Google Scholar]
- Liu, F.; Chen, C.; Gu, D.; Zheng, J. Ftpn: Scene text detection with feature pyramid based text proposal network. IEEE Access 2019, 7, 44219–44228. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Zhang, S. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognit. 2019, 90, 337–345. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2642–2651. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S. Total-text: A comprehensive dataset for scene text detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 935–942. [Google Scholar]
- Bušta, M.; Patel, Y.; Matas, J. E2e-mlt-an unconstrained end-to-end method for multi-language scene text. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; Springer: Cham, Switzerland; pp. 127–143. [Google Scholar]
- Zhang, C.; Liang, B.; Huang, Z.; En, M.; Han, J.; Ding, E.; Ding, X. Look more than once: An accurate detector for text of arbitrary shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10552–10561. [Google Scholar]
- Tang, J.; Yang, Z.; Wang, Y.; Zheng, Q.; Xu, Y.; Bai, X. Seglink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping. Pattern Recognit. 2019, 96, 106954. [Google Scholar] [CrossRef]
- NguyenVan, D.; Lu, S.; Tian, S.; Ouarti, N.; Mokhtari, M. A pooling based scene text proposal technique for scene text reading in the wild. Pattern Recognit. 2019, 87, 118–129. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Zhang, X.-Y.; Yin, F.; Luo, Z.; Ogier, J.-M.; Liu, C.-L. Realtime multi-scale scene text detection with scale-based region proposal network. Pattern Recognit. 2020, 98, 107026. [Google Scholar] [CrossRef]
- Zhu, Y.; Ma, C.; Du, J. Rotated cascade R-CNN: A shape robust detector with coordinate regression. Pattern Recognit. 2019, 96, 106964. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9336–9345. [Google Scholar]
- Liu, X.; Liang, D.; Yan, S.; Chen, D.; Qiao, Y.; Yan, J. Fots: Fast oriented text spotting with a unified network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5676–5685. [Google Scholar]
- Wang, X.; Jiang, Y.; Luo, Z.; Liu, C.L.; Choi, H.; Kim, S. Arbitrary shape scene text detection with adaptive text region representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6449–6458. [Google Scholar]
- He, W.; Zhang, X.-Y.; Yin, F.; Liu, C.-L. Deep direct regression for multi-oriented scene text detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 745–753. [Google Scholar]
- Wu, Y.; Natarajan, P. Self-organized text detection with minimal post-processing via border learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5009. [Google Scholar]
- He, D.; Yang, X.; Liang, C.; Zhou, Z.; Ororbi, A.G.; Kifer, D.; Giles, C.L. Multi-scale fcn with cascaded instance aware segmentation for arbitrary oriented word spotting in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 474–483. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the AAAI-18 AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2017; pp. 6773–6780. [Google Scholar]
- Xue, C.; Lu, S.; Zhan, F. Accurate scene text detection through border semantics awareness and bootstrapping. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 35–372. [Google Scholar]
- Zhang, Z.; Zhang, C.; Shen, W.; Yao, C.; Liu, W.; Bai, X. Multi-oriented text detection with fully convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4159–4167. [Google Scholar]
- Bazazian, D.; G’omez, R.; Nicolaou, A.; Gomez, L.; Karatzas, D.; Bagdanov, A.D. Fast: Facilitated and accurate scene text proposals through fcn guided pruning. Pattern Recognit. Lett. 2019, 119, 112–120. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. Textfield: Learning a deep direction field for irregular scene text detection. IEEE Trans. Image Process. 2019, 28, 5566–5579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Zhang, C.; Sun, Y.; Han, J.; Ding, E. Detecting text in the wild with deep character embedding network. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Liu, Y.; Jin, L.; Fang, C. Arbitrarily Shaped Scene Text Detection with a Mask Tightness Text Detector. IEEE Trans. Image Process. 2020, 29, 2918–2930. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Xie, E.; Zang, Y.; Shao, S.; Yu, G.; Yao, C.; Li, G. Scene text detection with supervised pyramid context network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9038–9045. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-oriented scene text detection via corner localization and region segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character region awareness for text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9365–9374. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.i.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; de las Heras, L.P. ICDAR 2013 robust reading competition. Document Analysis and Recognition (ICDAR). In Proceedings of the 2013 12th International Conference on IEEE Computer Society, Niigata, Japan, 16–20 June 2013; pp. 1484–1493. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; J Matas, L.N.; Chandrasekhar, V.R.; Lu, S. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 18–20 June 2012; pp. 1083–1090. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Kennedy, J.; Eberhar, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Nayef, N.; Yin, F.; Bizid, I.; Choi, H.; Feng, Y.; Karatzas, D.; Luo, Z.B.; Pal, U.; Rigaud, C.; Chazalon, J.; et al. ICDAR2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) IEEE, Kyoto, Japan, 9–15 November 2017; pp. 1454–1459. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Year | IC15 | IC17 | MSRA-TD500 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | H (%) | P (%) | R (%) | H (%) | P (%) | R (%) | H (%) | |||
| Zhang et al. [25] | VGG-16 + FCN | 2016 | 71 | 43 | 54 | - | - | - | 83 | 67 | 74 |
| EAST * [9] | VGG-16 | 2017 | 80.5 | 72.8 | 76.4 | - | - | - | 81.7 | 61.6 | 70.2 |
| TextSnake [33] | VGG-16 + UNet | 2018 | 84.9 | 80.4 | 82.6 | - | - | - | 83.2 | 73.9 | 78.3 |
| TextBoxes++ * [5] | VGG-16 | 2018 | 87.8 | 78.5 | 82.9 | - | - | - | - | - | - |
| PixelLink [23] | VGG-16 | 2018 | 85.5 | 82 | 83.7 | - | - | - | 83 | 73.2 | 77.8 |
| Lyu et al. [32] | VGG-16 + FCN | 2018 | 89.5 | 79.7 | 84.3 | 74.3 | 70.6 | 72.4 | 87.6 | 76.2 | 81.5 |
| E2E-MLT [11] | ResNet-34 + FPN | 2018 | - | - | - | 64.6 | 53.8 | 58.7 | - | - | - |
| FOTS [18] | ResNet-50 + FPN | 2018 | 88.8 | 82.0 | 85.3 | 79.5 | 57.5 | 66.7 | - | - | - |
| PSENET-1s [17] | ResNet + FPN | 2019 | 86.9 | 84.5 | 85.7 | 75.3 | 69.2 | 72.2 | - | - | - |
| CRAFT [34] | VGG-16 + UNet | 2019 | 89.8 | 84.3 | 86.9 | 80.6 | 68.2 | 73.9 | 88.2 | 78.2 | 82.9 |
| FTPN [7] | ResNet + FPN | 2019 | 68.2 | 78.0 | 72.8 | - | - | - | - | - | - |
| ICG (SegLink++) [13] | VGG-16 | 2019 | 83.7 | 80.3 | 82.0 | - | - | - | - | - | - |
| LOMT | ResNet-50 + FPN | 2020 | 86.9 | 84.6 | 85.7 | 79.1 | 70.6 | 74.6 | 88.9 | 77.3 | 82.7 |
| Method | Year | Total-Text | CTW1500 | ||||
|---|---|---|---|---|---|---|---|
| P (%) | R (%) | H (%) | P (%) | R (%) | H (%) | ||
| EAST * [9] | 2017 | 50.0 | 36.2 | 42.0 | 78.7 | 49.1 | 60.4 |
| DeconvNet * [10] | 2017 | 33.0 | 40.0 | 36.0 | - | - | - |
| TextSnake [33] | 2018 | 82.7 | 74.5 | 78.4 | 67.9 | 85.3 | 75.6 |
| PSENet-1s [17] | 2019 | 81.8 | 75.1 | 78.3 | 80.6 | 75.6 | 78.0 |
| LOMO-1s [12] | 2019 | 88.6 | 75.7 | 81.6 | - | - | - |
| CTD + TLOC [8] | 2019 | 77.4 | 69.8 | 73.4 | 77.4 | 69.8 | 73.4 |
| ICG (SegLink++) [13] | 2019 | 82.1 | 80.9 | 81.5 | 82.8 | 79.8 | 81.3 |
| CRAFT [34] | 2019 | 87.6 | 79.9 | 83.6 | 86.0 | 81.1 | 83.5 |
| Wang et al. [19] | 2019 | 80.9 | 76.2 | 78.5 | 80.1 | 80.2 | 80.1 |
| Mask-TTD [29] | 2020 | 74.5 | 79.1 | 76.7 | 79.7 | 79.0 | 79.4 |
| LOMT | 2020 | 88.2 | 79.6 | 83.7 | 85.1 | 79.9 | 82.5 |
| Dataset | EAST | MSER Extraction | PSO-TSA | ICMN | H (%) |
|---|---|---|---|---|---|
| CTW1500 | √ | X | X | X | 60.4 |
| √ | √ | √ | X | 71.2 | |
| √ | √ | √ | √ | 81.5 | |
| Total-Text | √ | X | X | X | 42.0 |
| √ | √ | √ | X | 81.7 | |
| √ | √ | √ | √ | 83.7 |
| Data Sets | CRAFT-IC15-20k.pth | CRAFT-MLT-25k.pth | LOMT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P (%) | R (%) | H (%) | P (%) | R (%) | H (%) | P (%) | R (%) | H (%) | |
| IC15 | 89.8 | 84.3 | 86.9 | 81.7 | 82.5 | 82.0 | 86.9 | 84.6 | 85.7 |
| IC17-MLT | 51.2 | 47.7 | 49.4 | 80.6 | 68.2 | 73.9 | 79.1 | 70.6 | 74.6 |
| TD500 | 16.1 | 29.6 | 20.9 | 88.0 | 78.1 | 82.9 | 88.9 | 77.3 | 82.7 |
| CTW1500 | 69.8 | 70.6 | 70.2 | 86.0 | 81.1 | 83.5 | 85.1 | 79.9 | 82.5 |
| Total-Text | 72.5 | 76.3 | 74.3 | 87.6 | 79.9 | 83.6 | 88.2 | 79.6 | 83.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Shao, S.; Zhang, L.; Wen, Z. A Straightforward and Efficient Instance-Aware Curved Text Detector. Sensors 2021, 21, 1945. https://doi.org/10.3390/s21061945
Zhao F, Shao S, Zhang L, Wen Z. A Straightforward and Efficient Instance-Aware Curved Text Detector. Sensors. 2021; 21(6):1945. https://doi.org/10.3390/s21061945
Chicago/Turabian StyleZhao, Fan, Sidi Shao, Lin Zhang, and Zhiquan Wen. 2021. "A Straightforward and Efficient Instance-Aware Curved Text Detector" Sensors 21, no. 6: 1945. https://doi.org/10.3390/s21061945
APA StyleZhao, F., Shao, S., Zhang, L., & Wen, Z. (2021). A Straightforward and Efficient Instance-Aware Curved Text Detector. Sensors, 21(6), 1945. https://doi.org/10.3390/s21061945