1. Introduction
Associating data with the right target in a multi-target environment is an important task in many research areas, such as object tracking [
1], surveillance [
2,
3], and situational awareness [
4]. Image sensors can be used to acquire rich information related to each target, which will significantly simplify the data-target association problem. For example, video cameras in a multi-target tracking mission can provide colors and shapes of targets as extra features in the association process [
5]. However, considering the costs, security issues, and special environments (e.g., ocean tracking [
6], military spying), a simple, reliable, and low-cost sensor network is often a preferred option [
7]. Consequently, the data-target association problem needs to be further studied, especially in cases when the gathered data are cluttered and contains limited information related to the targets.
The existing approaches for data-target association, in general, consist of three procedures [
8]: (i) Measurements collection–preparation before data association process, such as object identification in video frames, radar signals processing, or raw sensor data accumulation; (ii) measurements prediction–predict the potential future measurements based on history data, which yields an area (validation gate) that narrows down the search space; and (iii) optimal measurement selection–select the optimal measurement that matches history data according to a criterion (varies in different approaches) and update the history dataset. With the same procedures but different choices of the optimal measurement criteria, many data-target association techniques have already been developed. Among them, the well-known techniques include the global nearest neighbor standard filter (Global NNSF) [
9], joint probabilistic data association filter (JPDAF) [
10,
11,
12,
13], and multiple hypothesis tracking (MHT) [
14].
The Global NNSF approach attempts to find the maximum likelihood estimate related to the possible measurements (non-Bayesian) at each scan (that measures the states of all targets simultaneously). For nearest neighbor correspondences, there is always a finite chance that the association is incorrect [
15]. Besides that, the Global NNSF assumes a fixed number of targets and cannot adjust the target number during the data association process. A different well-known technique for data association is JPDAF, which computes association probabilities (weights) and updates the track with the weighted average of all validated measurements. Similar to Global NNSF, JPDAF cannot be applied in scenarios with targets birth and death [
1]. The most successful algorithm based on this data-oriented view is the MHT [
16], which takes a delayed decision strategy by maintaining and propagating a subset of hypotheses in the hope that future data will disambiguate decisions at present [
1]. MHT is capable of associating noisy observations and is resistant to a dynamic number of targets during the association process. The main disadvantage of MHT is its computational complexity as the number of hypotheses increases exponentially over time.
There are other approaches available for data association. For example, the Markov chain Monte Carlo data association (MCMCDA) [
5,
17]. MCMCDA takes the data-oriented, combinatorial optimization approach to the data association problem but avoids the enumeration of tracks by applying a sampling method called Markov chain Monte Carlo (MCMC) [
17], which implements statistical probabilities in the procedure of optimal measurement selection as well. In this paper, we assume an object generates at most a single detection in each sensor scan, namely, a point-target assumption. Hence, the approaches on multiple detections per object per time step, i.e., extended-target [
18], are not discussed here. The data association in extended object tracking problems typically use data clustering techniques, such as k-means [
19], to address the extended-target issue by specifying which measurements are from the same source. Then the corresponding association problems can be simplified as point-target tracking problems. For example, the authors in [
20] proposed a clustering procedure and took into account the uncertainty and imprecision of similarity measures by using a geometric fuzzy representation, which shows the potential of applying clustering algorithms in the data association problem.
The main contribution of this paper is the development of an efficient unsupervised machine learning algorithm, called graph based multi-layer k-means++ (G-MLKM). The proposed G-MLKM differs from the existing data-target association methods in three aspects. First, in contrast to the previous developed data association approaches that estimate the potential measurement from history data for each target and select an optimal one from validated measurements based on statistical probabilities, G-MLKM solves the data-target association problem in the view of data clustering. Second, the previous approaches are mainly developed with respect to sensors that are capable of obtaining information from a multiple dimensional environment, such as radars, sonars, and video cameras. G-MLKM is proposed on sensors that only provide limited information. Interesting research on tracking targets with binary proximity sensors can be seen in [
7], whose objective is only limited to target counting, while G-MLKM can associate data to targets. Third, G-MLKM can address the case that targets move in a constrained space, which requires dealing with data separation and merging.
The reminder of this paper is structured as follows. The data association problem in a constrained space and the corresponding tasks are described in
Section 2. In
Section 3, the multi-layer k-means++ (MLKM) method is developed for data-target association at local space given a simplified constrained space situation. The graph based multi-layer k-means++ (G-MLKM) algorithm is then developed in
Section 4 for general constrained spaces. Simulation examples are then provided in
Section 5.
Section 6 provides a brief summary of the work presented in this paper.
2. Problem Formulation
In this paper, we consider the problem of data-target association when multiple targets move across a road network. Here, a road network is a set of connected road segments, along which low-cost sensors are spatially distributed. The sensors are used to collect information of targets, which, in particular, are the velocity of targets and the corresponding measured time. We assume (1) there is no false alarm in the sensor measurements, and (2) the target’s velocity does not change rapidly within two adjacent sensors. The collected information about a target is normally disassociated with the target itself, meaning that the target from which the information was captured cannot be directly identified using the information. Hence, data-target associations is necessary.
Figure 1 shows one road network example that consists of 6 road segments. Without loss of generality, let the total number of road segments in one road network be denoted as
L. The road segments are denoted as
, respectively. The length of road segment
is denoted as
for
. To simplify discussion, we assume the road segments are for one-way traffic, i.e., targets cannot change their moving directions within one road segment. However, when the road segment allows bidirectional traffic, we can separate it into two unidirectional road segments and the proposed approach in this paper directly applies. Let
be a set of
sensors placed along the direction of road segment
. In other words, for sensor
, the larger the sub-notation
j is, the further distance the sensor locates away from the starting point of road segment
. We denote the corresponding distance between sensor
and the starting point of road segment
as
. Hence, the position set for sensors in
related to the starting point can be denoted as
, where
.
For each sensor , its measurements are collected and stored in chronological order. The collections are denoted as a column vector , such that where , , the prime symbol represents the transpose operation for a vector, is the total number of measurements in , and , , denotes an individual measurement in . In particular, stores the measured velocity when one target passed by sensor at time . As the elements in are stored in chronological order, the recorded time for each measurement satisfies , which can be distinguished based on the superscript n. All the measurement vectors stored by sensors that locate in the same road segment are stored into a matrix , such that where , , and the column of the matrix is defined as . If , . The added all-zero row vector in is to unify the length of vectors in matrix considering that miss detection may happen or targets may remain (or stop) inside the road network for a given data collection period.
The road network collects
that only include information of target’s velocity and the corresponding measurement time. In order to solve data-target association based on the
L matrices, three tasks need to be accomplished. The first task (
Task 1) is to cluster
into
groups for each road segment. Denote the data grouping result for each road segment as a new matrix
, such that:
where
is a row vector consisting of
measurements associated with the same target, defined as:
where
is an entry of
for
. Then a new row vector
is obtained from
by excluding all zero elements.
The second task (
Task 2) is to link the trajectories of targets at road intersections by pairing sensor
from multiple road segments that are connected geometrically. In particular, let
denote the index set of road segments that have outgoing targets related to one intersection
, and
denote the index set of road segments that have ingoing targets related to the same intersection. Since the road segments are unidirectional, the two index sets have no overlaps, i.e.,
. In particular, only the dataset that has a subscript of
(according to the unidirectional road segement setting) can be the candidate for
. Similarly, only the dataset that has a subscript notation of
can be the candidate for
. Therefore, datasets that belong to targets who move towards the intersection
are denoted as:
while datasets that belong to targets who leave the intersection
are denoted as:
where
,
,
, and
. Since targets may stop in the intersection or the data collection process terminates before targets exit the intersection, the total number of targets heading into an intersection
is always greater than or equal to the number of targets leaving the same intersection, i.e.,
. For simplicity of notation, denote
and
as
and
. Then we can calculate
and
via:
The pairing task for intersection
can be denoted as a mapping function
f, such that:
where
and
. In particular, the function
f for intersection
can be denoted as a permutation matrix
.
The last task (Task 3) is to merge data groups on the road network when loops may exist, i.e., targets may pass the same road segment several times. Hence, multiple data association groups may belong to the same target. The merged results can be denoted as L symmetric matrices for each road segment . If targets only pass the road segment once, is an identity matrix.
In this paper, we are going to propose a new unsupervised machine learning algorithm to associate data-target for the collected L matrices. In particular, this algorithm first creates a new clustering structure for data grouping in each matrix (associated with each road segment), and then leverages graph theory and clustering algorithms to link the matrices from different road segments for each intersection. Finally, the entire dataset can be analyzed and associated properly to the targets. The output of this new algorithm will be a detail trajectory path for each target with the captured velocities along the road segments. In the next two sections, the new data-target associations algorithm will be explained in detail. We begin the discussion with a special case when the road network is consisted of a single road segment.
5. Simulation
In this section, the performance of the proposed G-MLKM algorithm is evaluated. We first introduce the testing datasets generation process. Then the performance of the MLKM method on one road segment is evaluated and compared with k-means++ and DNN. Then the complete G-MLKM algorithm performance is evaluated. A detailed example presenting the output via using G-MLKM is given to show how matrices and are created for data pairing at intersections and group merging.
5.1. Testing Data Generation
In order to obtain a quantitative performance evaluation of the data association techniques, labeled data is needed to obtain the percentage of true association between targets and their measurements. One convenient way to have accurate labeled dataset for data-target association is to generate it artificially. Let the generated testing dataset from the road network be
, where
has the same data structure as
defined in (
1). In particular, each element in
is a data group that belongs to one target. Moreover, for any
collected from road segments that have both incoming and outgoing flows, multiple rows may belong to the same target.
We utilize the road network structure shown in
Figure 1 as a prototype for testing data generation. Moreover,
sensors are assumed to be equally distributed on each road segment, where the length of the road segment is
. The position set for sensors is selected as
with respect to the starting point of road segment
. The intersections are considered to have the same radius with the value of
. Hence, the distance between any two adjacency sensors is
d. To further simplify the data generation process, we assume road segment
is the only entrance of the road network during the data collection period with incoming targets number
, and targets have equal possibilities of valid heading directions at each intersection. The targets are assumed to move with a constant velocity and the velocity is also discretely affected by Gaussian noise, such that,
where
is one velocity measurement at sensor
and
is the velocity measurement at the previous sensor. The corresponding time measurement is calculated as
The initial velocity and time for the
targets are uniformly selected from the range
and
, respectively (refer to
Table 2). The testing dataset generating process stops when all targets move out of the road network.
With the generated testing datasets, we may evaluate the performance of the data-target association techniques by calculating the data association accuracy, which is defined as the ratio between correctly classified number of data () and the total number of data (), such that, where returns the number of elements in M. As multiple testing datasets are generated, the provided statistical information about performance includes the minimum (left - blue bar), average (middle - orange bar), and maximum (right - yellow bar) accuracies.
5.2. MLKM Performance and Comparisons
Before evaluating the entire accuracy of the proposed G-MLKM algorithm, the MLKM method is evaluated and compared with the other two common data clustering machine learning techniques, in particular, k-means++ and DNN, based on the collected dataset in road segment .
5.2.1. K-means++
The first set of simulations evaluate the performance of k-means++ based on two criteria: (i) Unprocessed vs. preprocessed data, and (ii) using different values of
and
. When the values of
and
increase, more data points are introduced into the dataset, leading to more overlapping among these data points.
Figure 6 and
Figure 7 show the performance of K-means++ using the parameters listed in
Table 2.
As can be observed, a higher accuracy is achieved using the preprocessed data than that using the unprocessed data. This can be seen by comparing the average, and maximum and minimum accuracy for the two methods that use the preprocessed data versus unprocessed data, as shown in
Figure 6. Using the raw data, the measurements associated with a specific target are sparse along the time axis. However, the velocity measurements from the same sensor are closely grouped along the velocity axis. These conditions contribute to incorrect clustering of the data. The preprocessing technique reduces the distance between target related measurements, therefore reducing the effect of the velocity measurements on the clustering.
A low accuracy is obtained for large values of
and
. This can be observed by comparing average, maximum and minimum accuracy for different
and
, as shown in
Figure 6 and
Figure 7. Similar to the unprocessed data, a large number of sensors/targets increases the density of measurement points. The concentration of measurements increases the probability that k-means/k-means++ clusters the data incorrectly (even with preprocessing).
5.2.2. DNN
The k-means++ fails to correctly cluster data when overlapping of measurements occurs. A deep neural networks (DNN) is used as an alternative approach because it has been shown to provide good results to uncover patterns for large dataset classification. One necessary condition for DNN is the availability of labeled datasets for training. To meet the requirements of DNN, it is assumed that labeled data is available for training.
The results for DNN are obtained using
targets and
sensors. Assuming that a portion of the data association has already been identified, the objective is to train a neural network to label the unidentified measurements. The number of ‘training’ sensors that provide labeled information and ‘testing’ sensors that provide unlabeled information are provided in
Table 3. The accuracy is obtained for various proportions of ‘training’ sensors to ‘testing’ sensors.
Table 3 also shows the accuracy obtained for different dataset configuration.
It can be observed that the training (respectively, testing) accuracy is high (respectively, low), when the testing dataset is relatively small. However, when the testing dataset is relatively high, the testing performance increases significantly (up to 91%). A high training accuracy with a low testing accuracy means that DNN suffers from overfitting due to the small size of the training dataset. Given this comparison, DNN is applicable when a large portion of a training dataset is available to train the network for classifying a relatively small amount of measurements.
5.2.3. MLKM
K-means++ does not provide good accuracy for a high number of measurements but performs well when clustering small amounts of data. DNN can cluster large datasets but requires a large training dataset. MLKM combines the multi-layer back-propagation error correction from DNN and the clustering capabilities of k-means++. The DNN-inspired error correction significantly improves the performance of MLKM by preventing the clustering errors in layer 1 to propagate to the cluster association in layer 3.
The results for the MLKM method are obtained using
number of targets and
number of sensors. In addition, the time and velocity parameters are set to
and
, receptively.
Figure 8 shows the performance of the MLKM method with and without error correction, as well as results using the standard k-means++ method with preprocessing.
It can be observed that a higher accuracy is achieved using MLKM than that using k-means++.
Figure 8 shows the average, and maximum and minimum accuracy for both methods. The error correction performed in layer 2 improves the average accuracy of MLKM by approximately 7% (MLKM w/ EC 91.65%; MLKM w/o EC 84.3%).
5.3. G-MLKM Overall Performance
The results for the G-MLKM method are obtained using
number of targets and
number of sensors. In addition, the time and velocity parameters are set to
and
, respectively.
Figure 9 shows the performance of the G-MLKM algorithm with and without error correction.
It can be observed that a higher accuracy is achieved using G-MLKM with error correction than the result without error correction.
Figure 9 shows the average, and maximum and minimum accuracy for both methods. The second error correction performed in the algorithm improves the average accuracy of G-MLKM by approximately 11% (G-MLKM w/ EC 92.2%; G-MLKM w/o EC 81%).
5.4. Matrix Output of the G-MLKM Algorithm
The proposed G-MLKM algorithm implements multiple (determined by the structure of road networks) permutation matrices and L symmetric matrices to represent the data cluster classification results at intersections and road segments, respectively. A detail example is illustrated to show the use of the proposed G-MLKM matrix output.
Suppose 5 targets (named as
, respectively) go through the road network as shown in
Figure 1 during a certain time. The trajectory ground truth is listed in
Table 4. In particular, road segment
has three data groups denoted as
,
has six data groups denoted as
,
has five data groups denoted as
,
has three data groups denoted as
,
has one data groups denoted as
, and
has two data groups denoted as
.
Take target as an example, it travels through road segment , then heads to road segment . After that, it keeps on moving through road segment and finally leaves the road network through road segment . The connections among associated data groups in each road segment that are related to target is represented as which means data group 1 in road segment , data groups 1 and 6 in road segment , data group 1 in road segment , data group 3 in road segment , and data group 5 in road segment all belong to the measurements extracted from target .
As the road segment
has two data groups belong to one target, the ideal matrix
should be:
with respect to its data groups
. For the other road segments, the corresponding matrix
is an identity matrix related to its own data groups. Especially,
,
,
,
, and
.
Let the intersection formed by road segments
, and
be denoted as
a. The incoming dataset
can be stored in the sequence of
and the outgoing dataset
can be stored in the sequence of
. Therefore, the permutation matrix
may be determined as:
Similarly, for the intersection formed by road segment
, and
(named as intersection
b), matrix
may be determined as:
with
stored in the sequence of
,
,
,
,
,
and the outgoing dataset
in the sequence of
,
,
,
,
,
. For the intersection formed by road segment
, and
(named as intersection
c),
may be determined as:
with
stored in the sequence of
,
,
,
,
,
and the outgoing dataset
in the sequence of
,
,
,
,
,
.
With these matrices determined, the output result from G-MLKM can be clearly presented.











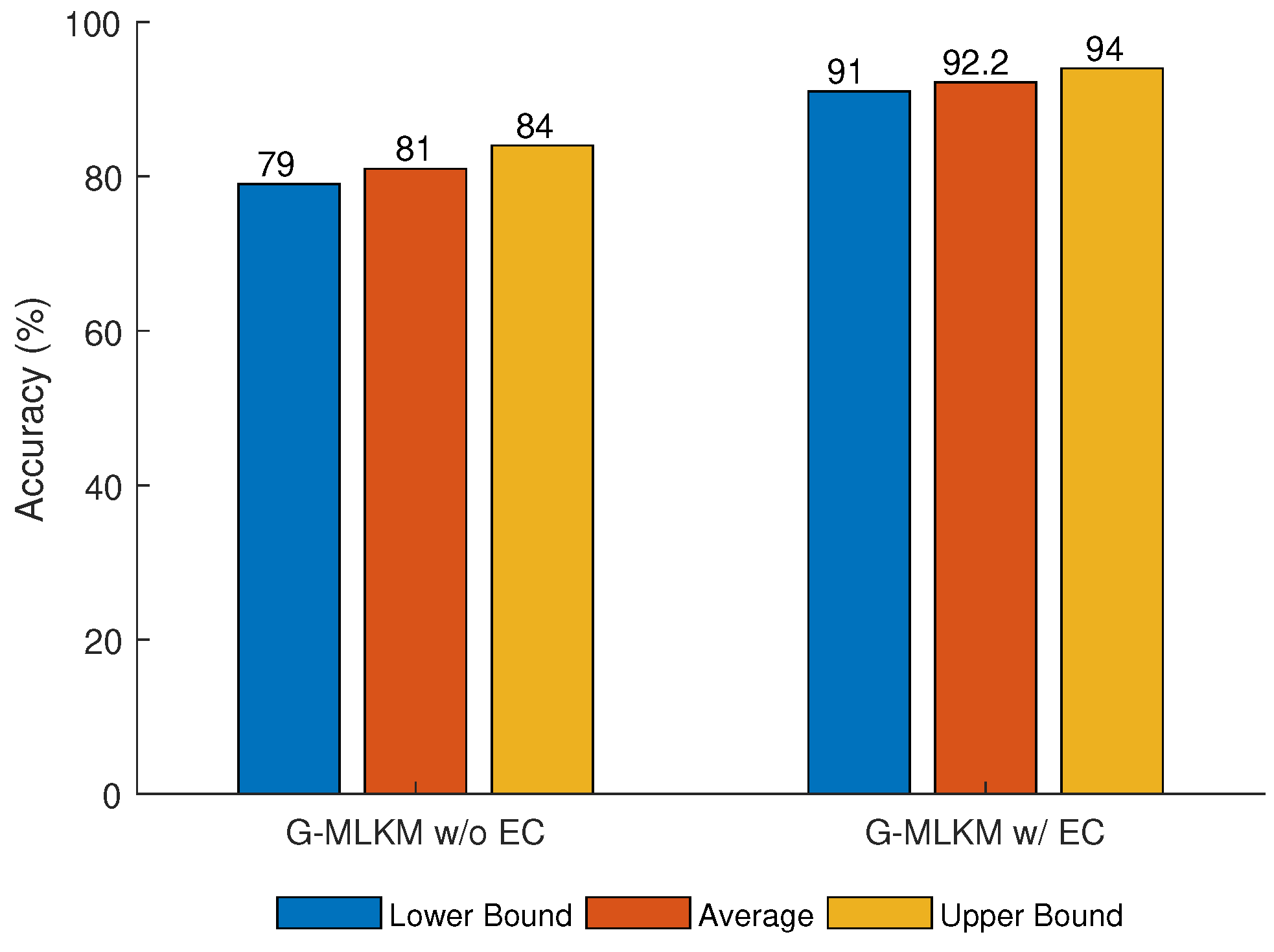

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}