
Autonomous Incident Detection on Spectrometers Using Deep Convolutional Models

 and
and
Abstract
:1. Introduction
- In this paper, we proposed the novel industry computer vision system for incident detection of spectrometers. The developed framework can detect 95% of the beads and 98% of the flooding under the controlled lab environment and is able to process four frames per second, which is fast enough to be implemented in real-time.
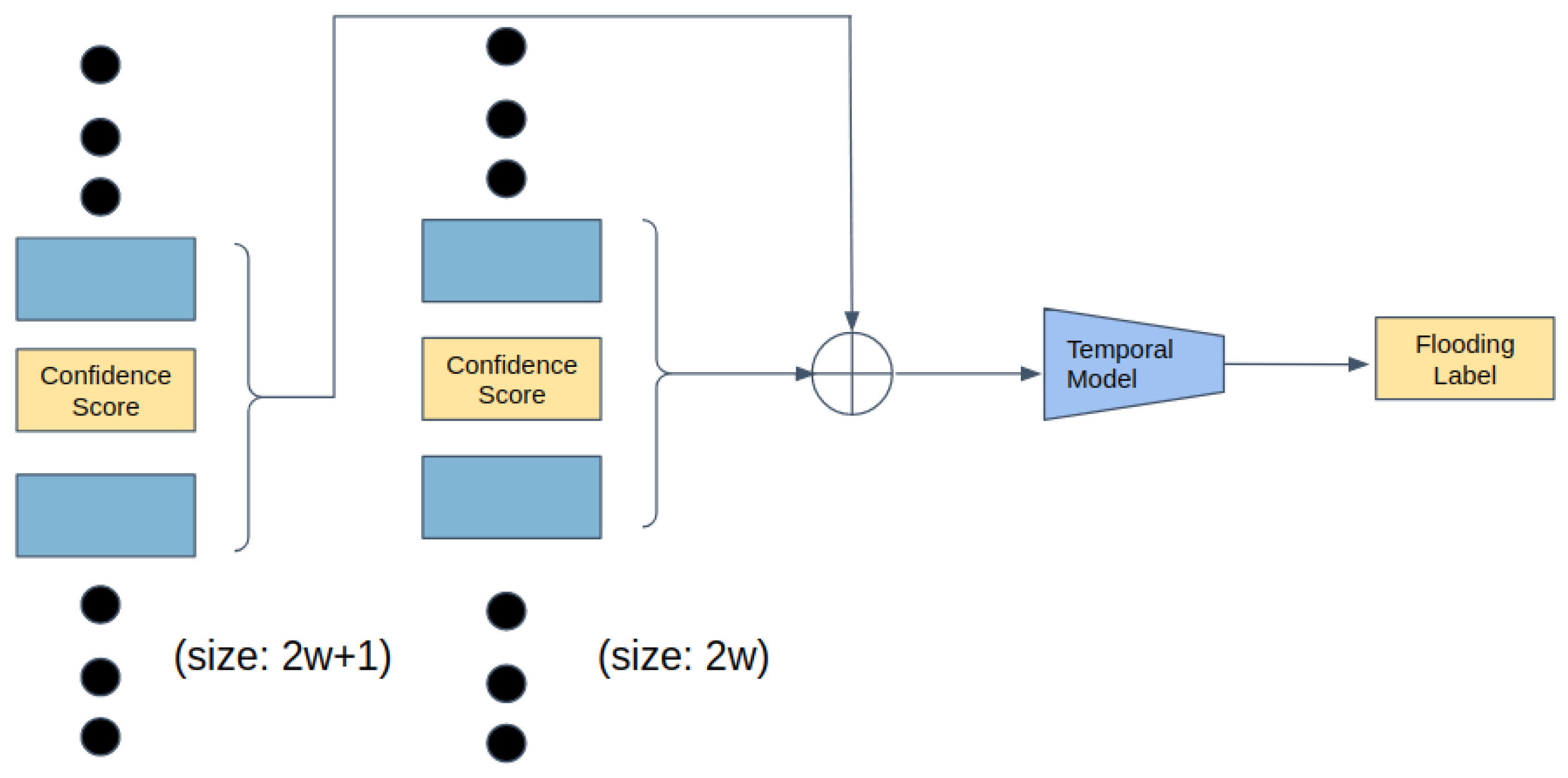
- Since there is no method with high accuracy to detect transparent and deformable flooding, based on our observation of the relationship between flooding and bubbles in the drain tube region, we convert the hard flooding detection task into a simple bubble movement detection task and propose to use a temporal model with low computation cost. We calculate the pixel differences of the drain tube region of two consecutive images to include temporal information. Then we input a sequence of pixel differences along with the confidences scores of the flooding detection bounding boxes to a basic neural network to predict the existence of floodings. This allows our pipeline to give temporal consistent predictions of flooding as well as preventing the heavy computation cost of using convolutional neural network with recurrent neural network.
- Targeting at the challenges and difficulties introduced by the non-rigid properties of bead objects, we select the best combination of object detection model components. To tackle with the small amount of data and annotations we have, data synthesis and augmentation are integrated into the proposed bead detection framework. Furthermore, the hard negative mining sampler is to guide our model to learn to detect more beads accurately. Our bead detection model outperforms state-of-the-art object detectors.
2. Related Work
2.1. Object Detection Models
2.2. Small Object Detection
2.3. Transparent Object Detection
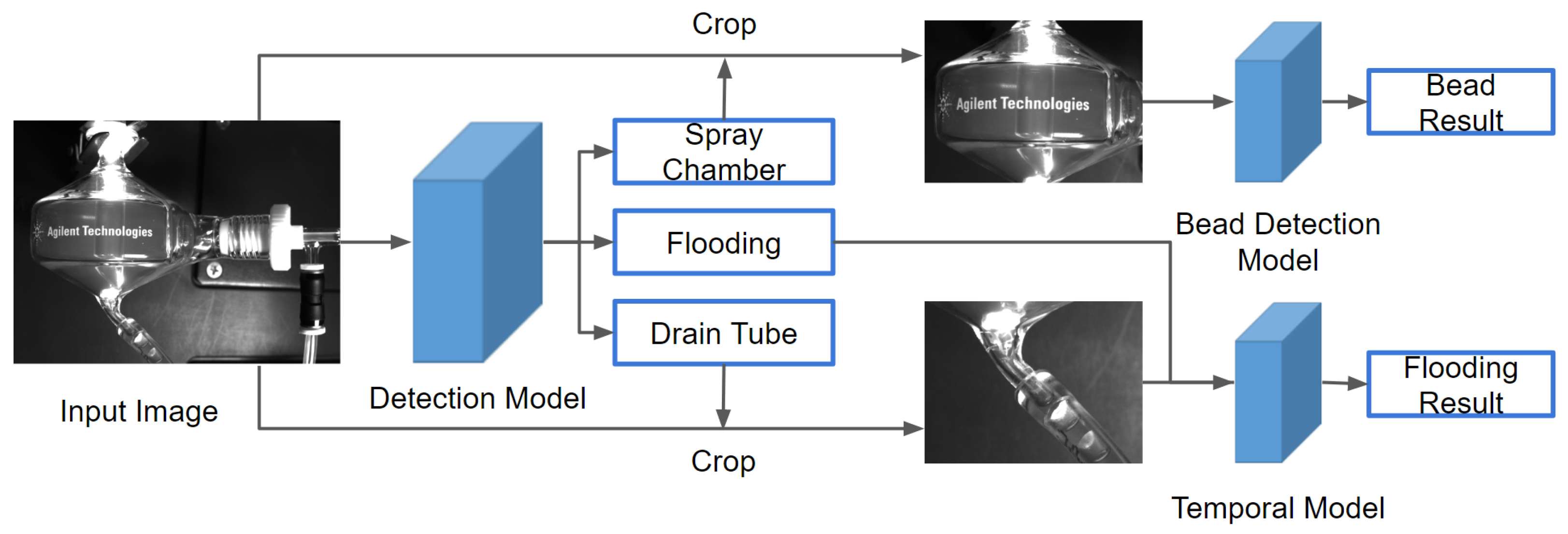
3. Methodology
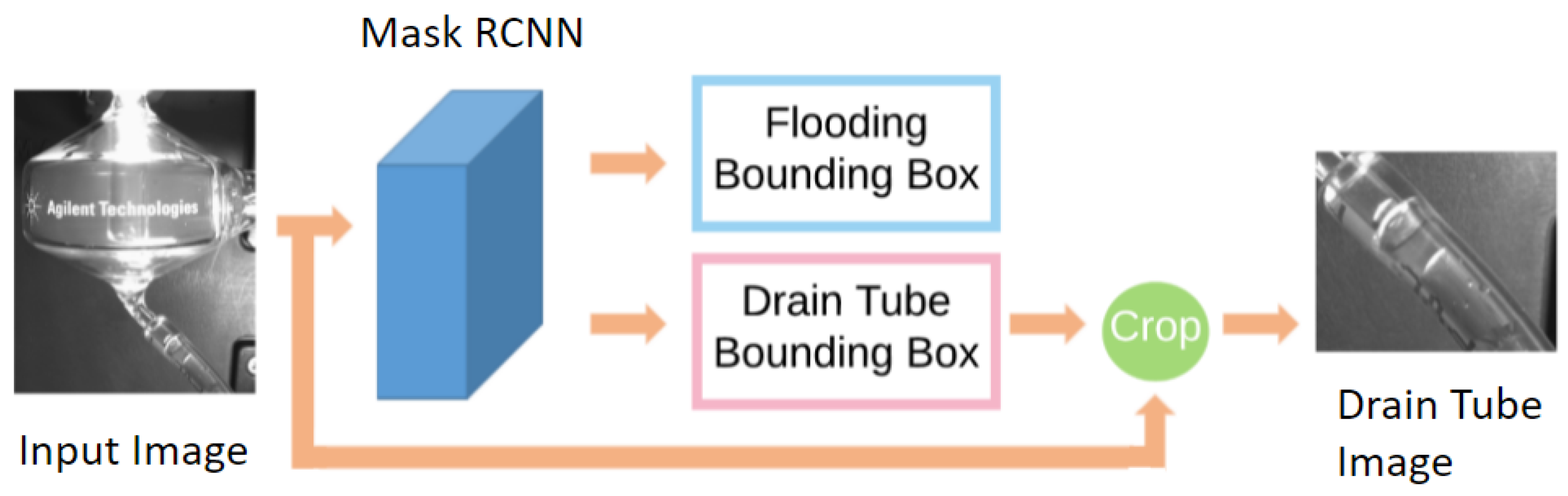
3.1. Flooding Detection
3.2. Bead Detection
4. Dataset and Instruments
5. Experiments
5.1. Flooding Detection
5.1.1. Quantitative Analysis
5.1.2. Qualitative Analysis
5.2. Bead Detection
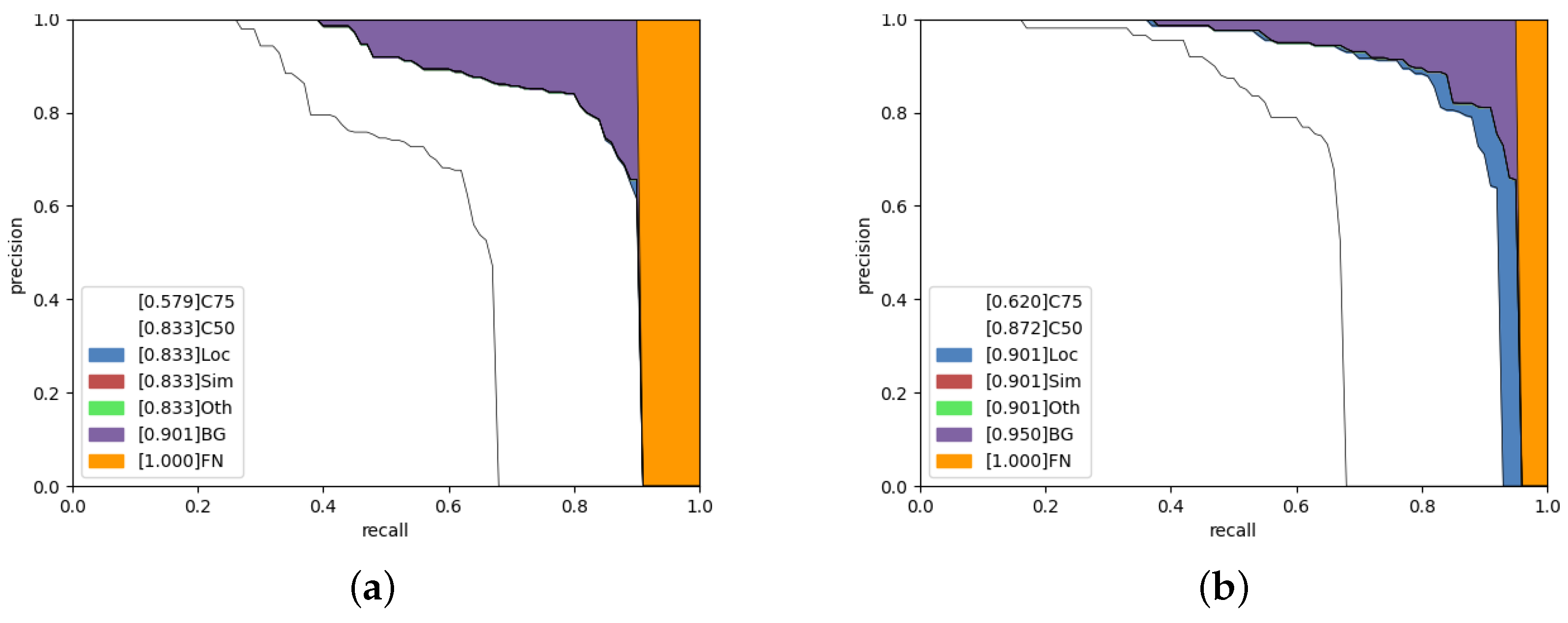
5.2.1. Quantitative Analysis
5.2.2. Qualitative Analysis
5.2.3. Ablation Study
5.3. Inference Speed Analysis
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | Average Precision |
| BG | Background Misclassification |
| MSE | Mean Square Error |
| OHDM | Hard-Negative Mining |
| HRFPN | High Resolution Feature Pyramids |
| HTC | Hybrid Task Cascade |
| IoU | Intersection over Union |
| R-CNN | Region-based Convolutional Neural Network |
References
- Lu, Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017, 6, 1–10. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-Target Recognition of Bananas and Automatic Positioning for the Inflorescence Axis Cutting Point. Front. Plant Sci. 2021, 12, 2465. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Tang, Y.; Zou, X.; Huang, Z.; Zhou, H.; Chen, S. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM. Comput. Electron. Agric. 2021, 187, 106237. [Google Scholar] [CrossRef]
- Zhang, E.; Chen, Y.; Gao, M.; Duan, J.; Jing, C. Automatic Defect Detection for Web Offset Printing Based on Machine Vision. Appl. Sci. 2019, 9, 3598. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Wang, N.; Ho, S.; Chen, X.; Song, G. Design of a New Vision-Based Method for the Bolts Looseness Detection in Flange Connections. IEEE Trans. Ind. Electron. 2020, 67, 1366–1375. [Google Scholar] [CrossRef]
- Lenty, B.; Kwiek, P.; Sioma, A. Quality control automation of electric cables using machine vision. In Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics; International Society for Optics and Photonics: Bellingham, WA, USA, 2018. [Google Scholar]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-Driven Fault Diagnosis for Traction Systems in High-Speed Trains: A Survey, Challenges, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2020, 1–17. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2019, arXiv:1908.07919. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. arXiv 2019, arXiv:1901.07518. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R.B. Training Region-based Object Detectors with Online Hard Example Mining. arXiv 2016, arXiv:1604.03540. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. arXiv 2020, arXiv:2012.07177. [Google Scholar]
- Ren, Z.; Fang, F.; Yan, N.; Wu, Y. State of the Art in Defect Detection Based on Machine Vision. Int. J. Precis. Eng. Manuf.- Green Technol. 2021, 1–31. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.; Dollár, P. Microsoft COCO: Common Objects in Context; European Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. Computer Vision and Pattern Recognition. arXiv 2014, arXiv:1311.2524v5. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection; CVPR: Long Beach, CA, USA, 2019. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 12 December 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. arXiv 2018, arXiv:1808.01244. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Lim, J.; Astrid, M.; Yoon, H.; Lee, S. Small Object Detection using Context and Attention. arXiv 2019, arXiv:1912.06319. [Google Scholar]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:cs.CV/1804.02767. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kong, T.; Sun, F.; Huang, W.; Liu, H. Deep Feature Pyramid Reconfiguration for Object Detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: A Backbone network for Object Detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhou, Z.; Chen, X.; Jenkins, O. LIT: Light-field Inference of Transparency for Refractive Object Localization. Robot. Autom. Lett. 2020, 5, 4548–4555. [Google Scholar] [CrossRef]
- Khaing, M.; Masayuki, M. Transparent Object Detection Using Convolutional Neural Network. In Big Data Analysis and Deep Learning Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 86–93. [Google Scholar]
- Sajjan, S.; Moore, M.; Pan, M.; Nagaraja, G.; Lee, J.; Zeng, A.; Song, S. ClearGrasp: 3D Shape Estimation of Transparent Objects for Manipulation. arXiv 2020, arXiv:1910.02550. [Google Scholar]
- Uijlings, J.; Sande, K.; Gevers, T.; Smeulders, A. Selective Search for Object Recognition. IJCV 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xing, Z.; Pei, J.; Keogh, E. A brief survey on sequence classification. ACM Sigkdd Explor. Newsl. 2010, 12, 40–48. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P.H.S. Res2Net: A New Multi-scale Backbone Architecture. arXiv 2019, arXiv:1904.01169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. arXiv 2019, arXiv:1901.01892. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. arXiv 2019, arXiv:1906.09756. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. arXiv 2017, arXiv:1708.01642. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop on Autodiff, Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Everingham, M.; Eslami, S.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. IJCV 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.V.; Williams, C.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2010 Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2010/workshop/index.html (accessed on 3 June 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.B.; He, K.; Dollár, P. Designing Network Design Spaces. arXiv 2020, arXiv:2003.13678. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13039–13048. [Google Scholar]
- Lin, T.Y.; Patterson, G.; Ronchi, M.R.; Cui, Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hayes, J.; Perona, P.; et al. Common Objects in Context; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Hoiem, D.; Chodpathumwan, Y.; Dai, Q. Diagnosing Error in Object Detectors. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 340–353. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MR | TM | TML | AP | P | R | F1 |
|---|---|---|---|---|---|---|
| ✔ | 0.603 | 0.885 | 0.750 | 0.812 | ||
| ✔ | 0.941 | 0.963 | 0.952 | |||
| ✔ | ✔ | 0.986 | 0.988 | 0.987 |
| Backbone | mAP | AP30 | AP50 | AP75 | APs | APm |
|---|---|---|---|---|---|---|
| DarkNet [28] | 62.1 | 86.7 | 86.5 | 66.6 | 58.1 | 68.9 |
| x101 64-4d [55] | 60.5 | 84.9 | 82.9 | 55.1 | 47.2 | 66.8 |
| RegNet [56] | 59.0 | 85.5 | 82.2 | 52.8 | 49.2 | 64.1 |
| ResNeSt [42] | 64.7 | 89.9 | 88.0 | 59.7 | 56.7 | 69.4 |
| Res2Net [40] | 58.7 | 83.3 | 80.4 | 53.1 | 46.3 | 64.8 |
| Swin-96 [43] | 56.3 | 82.4 | 78.9 | 46.5 | 49.3 | 60.1 |
| TridentNet [41] | 42.2 | 76.6 | 67.3 | 19.2 | 37.7 | 44.9 |
| HRNetV2p [9] | 69.6 | 90.1 | 89.0 | 71.7 | 59.1 | 74.8 |
| Detector | mAP | AP30 | AP50 | AP75 | APs | APm |
|---|---|---|---|---|---|---|
| SSD-512 * [22] | 27.2 | 59.8 | 46.9 | 7.50 | 9.70 | 36.8 |
| RetinaNet * [44] | 42.2 | 76.6 | 67.3 | 19.2 | 37.7 | 44.9 |
| YOLOv3 * [28] | 62.1 | 86.7 | 86.5 | 66.6 | 58.1 | 68.9 |
| YOLOF * [57] | 56.4 | 85.5 | 78.8 | 49.9 | 49 | 61.1 |
| Faster [18] | 56.3 | 82.4 | 78.9 | 46.5 | 49.3 | 60.1 |
| Libra [19] | 66.0 | 87.2 | 86.6 | 69.3 | 56.0 | 70.9 |
| Cascade [45] | 69.3 | 91.2 | 90.4 | 69.9 | 60.6 | 73.6 |
| Cascade Mask [47] | 69.6 | 90.1 | 89.0 | 71.7 | 59.1 | 74.8 |
| HTC [10] | 70.3 | 90.9 | 90.1 | 70.9 | 61.3 | 74.8 |
| Proposed | 83.9 | 96.0 | 95.1 | 84.7 | 65.6 | 71.4 |
| HTC | OHEM | Aug. | mAP | AP30 | AP50 | AP75 |
|---|---|---|---|---|---|---|
| ✔ | 70.3 | 91.3 | 90.1 | 61.3 | ||
| ✔ | ✔ | 80.4 | 95.8 | 94.9 | 82.6 | |
| ✔ | ✔ | ✔ | 83.9 | 96.0 | 95.1 | 84.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, D.; Leye, A.; Scott, A.; Visser, L.; Ge, Z.; Bonnington, P. Autonomous Incident Detection on Spectrometers Using Deep Convolutional Models. Sensors 2022, 22, 160. https://doi.org/10.3390/s22010160
Zhang X, Zhang D, Leye A, Scott A, Visser L, Ge Z, Bonnington P. Autonomous Incident Detection on Spectrometers Using Deep Convolutional Models. Sensors. 2022; 22(1):160. https://doi.org/10.3390/s22010160
Chicago/Turabian StyleZhang, Xuelin, Donghao Zhang, Alexander Leye, Adrian Scott, Luke Visser, Zongyuan Ge, and Paul Bonnington. 2022. "Autonomous Incident Detection on Spectrometers Using Deep Convolutional Models" Sensors 22, no. 1: 160. https://doi.org/10.3390/s22010160