1. Introduction
It is a dynamic world, and the video captures this world of objects and movement. The video is composed of continuous pictures. Generally speaking, the human eye can distinguish the frame rate is 15 frames per second [
1]. More than 15 frames will be considered a motion video. The ordinary camera frame rate is generally between 30 and 60 fps, which can meet most cases of content recording, while high-speed cameras need to reach 120 fps or even higher. Although high-speed video offers rich details, it comes with higher storage space and transmission bandwidth usage.
Compressive sensing (CS) [
2] can acquire the measurements of the original signal at a rate lower than the Nyquist sampling rate and use an algorithm to reconstruct the original signal. This feature makes it widely used in the video field. On the one hand, it can be applied to construct high-speed cameras. By compressing consecutive frames into one frame at one measurement, it is possible to use a plain low-speed camera sensor to achieve high-speed cameras, e.g., single-pixel camera [
3], single-coded exposure camera [
4], and coded strobing camera [
5]. On the other hand, the VCS algorithm can alleviate the enormous demand for massive storage and transmission bandwidth required for video. VCS allows transmitting the video under 100× compression, significantly improving transmission efficiency and quickly reconstructing it at the receiving end.
According to the measurement of video frames, the existing VCS methods can be divided into temporal multiplexing VCS (TVCS) and spatial multiplexing VCS (SVCS). TVCS obtains a 2D measurement frame from sampling across the temporal axis, which superimposes
k measurement frames into one frame. Its measurement ratio is
. The method proposed in [
4,
6,
7,
8,
9,
10] belongs to this category. These methods can obtain a high spatial resolution, which is generally implemented on sensors with low frame rates.
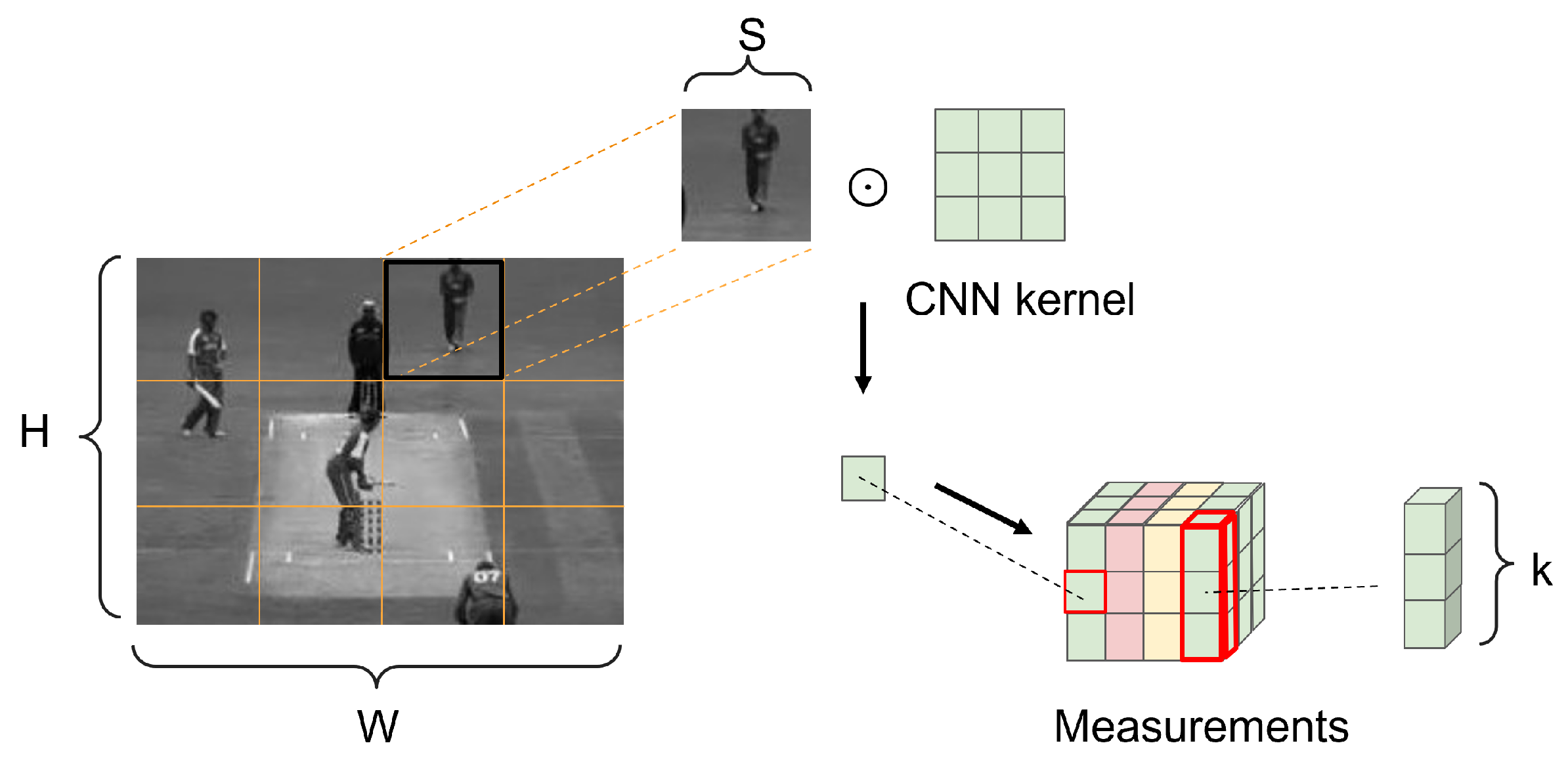
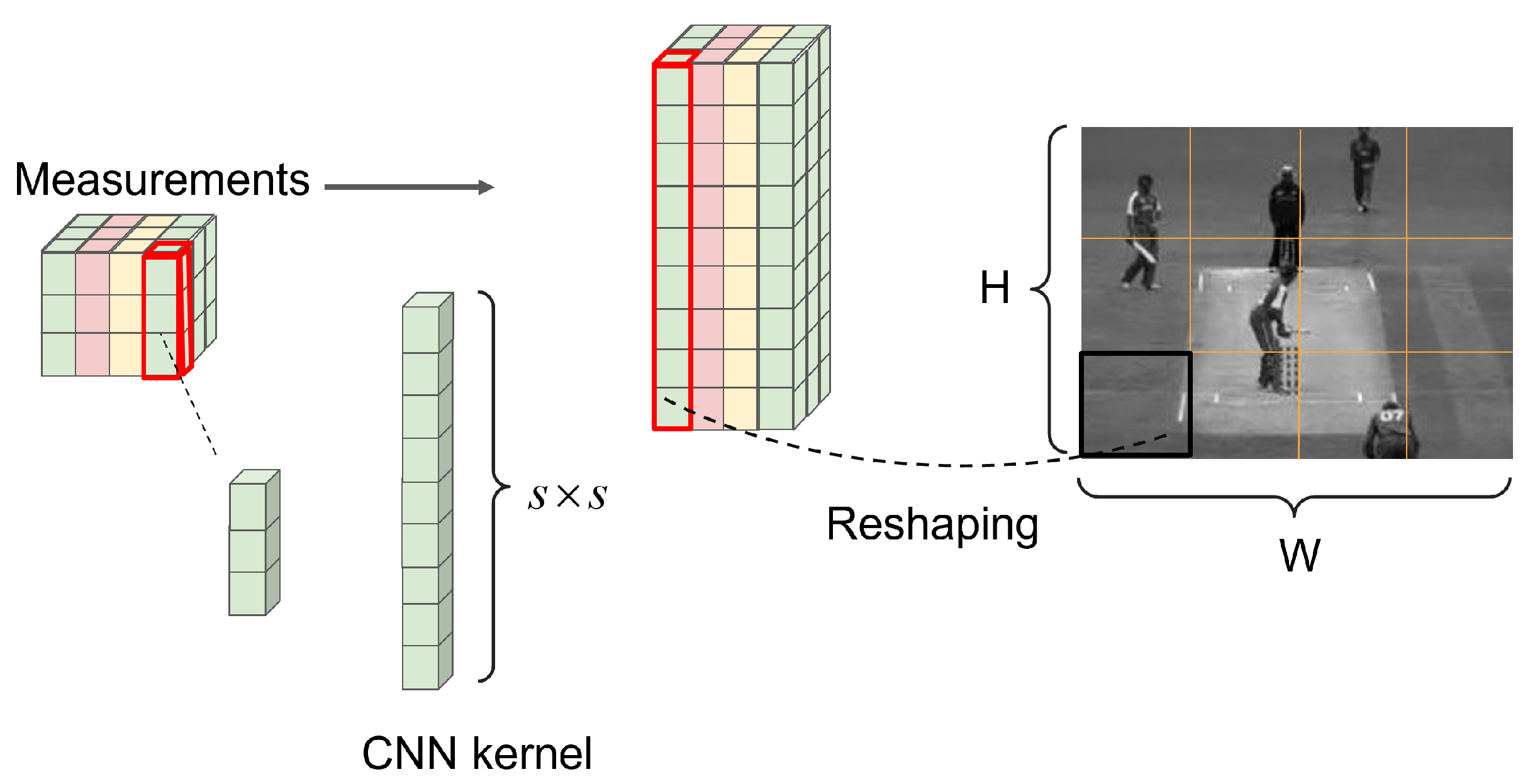
The SVCS is derived from single-pixel cameras [
3]. It uses a programmable high-speed photodetector to measure the image. Only one measurement value is output for each measurement. A set of measurement values is obtained after multiple measurements, which is used to reconstruct the original video frame.
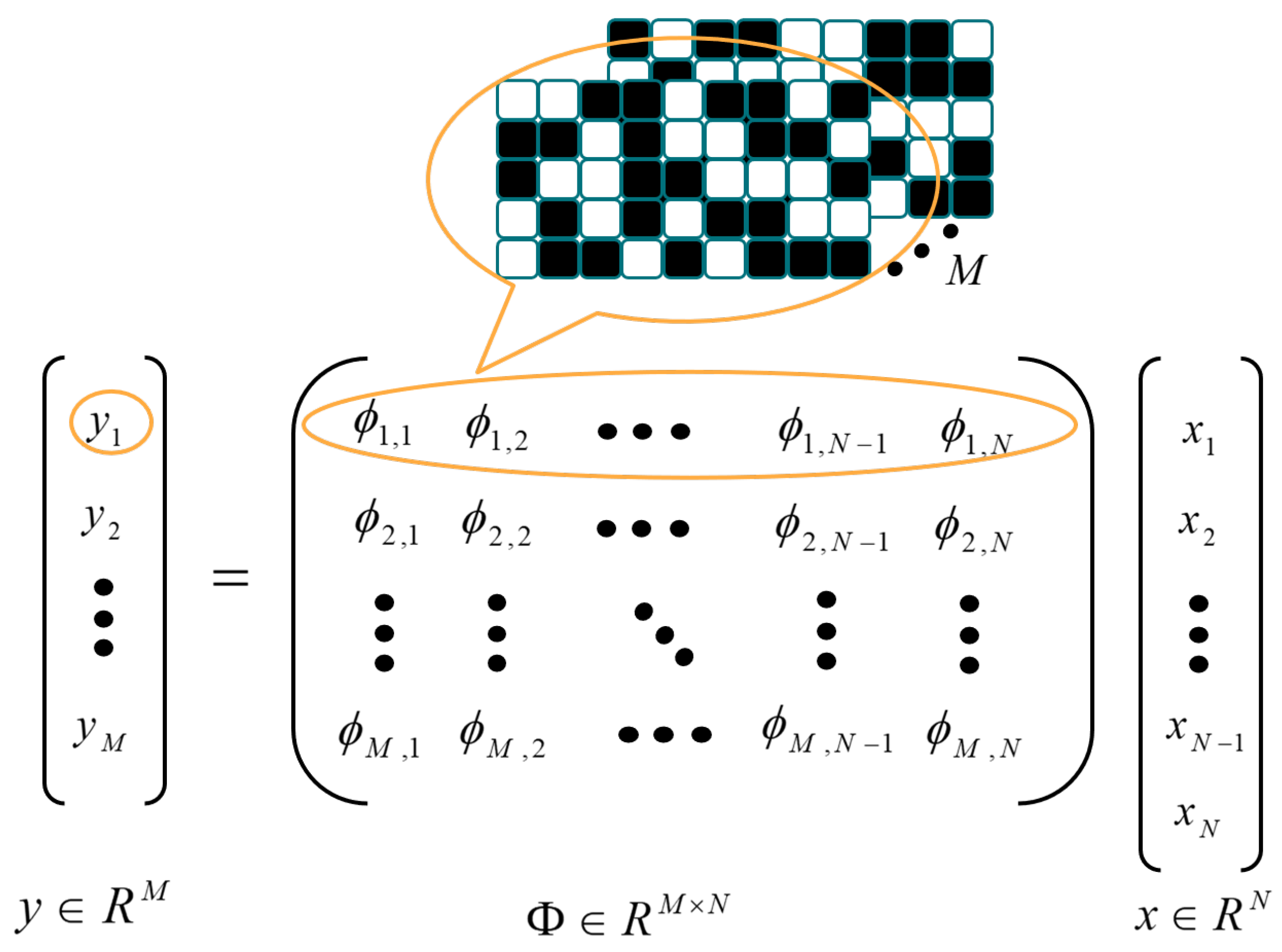
Figure 1 shows the SVCS process. The size of the input video frame is
, and it can be vectorized as
. The measurement matrix (MM) is expressed as
, which can be viewed as a set of
M patterns, and each row of the MM corresponds to a vectorized pattern. The measurement process is to make the inner product of each pattern and the original signal, output a single measurement value, and obtain the measurement vector
after
M times calculation. The SVCS is formulated as follows:
Compared with TVCS, the SVCS can reconstruct the original frames with fewer measurements, thus achieving a relatively low measurement ratio. As a result, it causes severe loss of image information in the measurement, leading to decreased reconstruction quality. In this paper, our proposed method belongs to SVCS. Therefore, making a tradeoff between measurement ratio and reconstruction quality is one problem to be solved.
In the past ten years, many researchers have proposed VCS reconstruction algorithms based on optimization algorithms in the image field, e.g., [
6,
8,
11,
12]. Usually, these algorithms are based on the sparse prior of the image signal and use convex optimization or greedy algorithms to solve the reconstruction problem iteratively. These methods inevitably bring the problem of high computational complexity. As the resolution of the image increases, the time consumption for computation increases exponentially, making it challenging to meet real-time requirements. In recent years, with the wide application of deep learning, more and more methods based on deep learning have been proposed to solve the problem of VCS, e.g., [
9,
13,
14,
15,
16,
17]. These methods learn the inverse mapping directly from the measurements to the original signal through the neural networks. The reconstructed signal can be calculated through a feedforward network, which is less computationally complex than the iterative optimization algorithm. The real-time performance is improved, and the reconstruction quality is substantially improved.
The video consists of continuous frames. The video frame sequence contains the motion information of the objects in the scene. Due to the natural correlation between frames, it is possible to use spatial–temporal information, which is the key to improving the quality of reconstructed frames in the case of SVCS. In [
16,
18,
19], the spatial–temporal information of video is fully considered when studying the VCS problem, and the spatial–temporal features of video frames are extracted using deep networks to enhance the reconstruction quality. The CSVideoNet [
16] uses a classical LSTM network to extract motion features of continuous frames. In [
18], Hybrid-3DNet is proposed to extract spatial information by convolving video segments using a 3D convolutional network, while VCSNet in [
19] uses CNN residual connections to transfer interframe information and achieve inter-frame multi-level compensation.
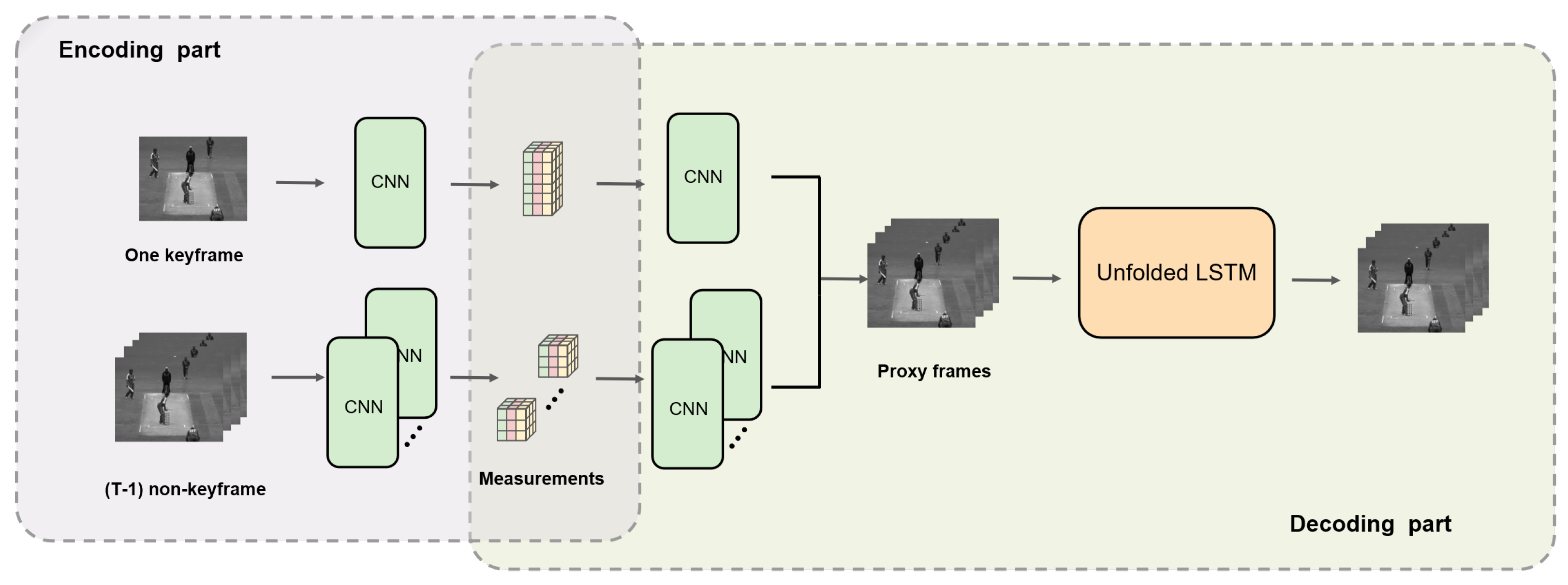
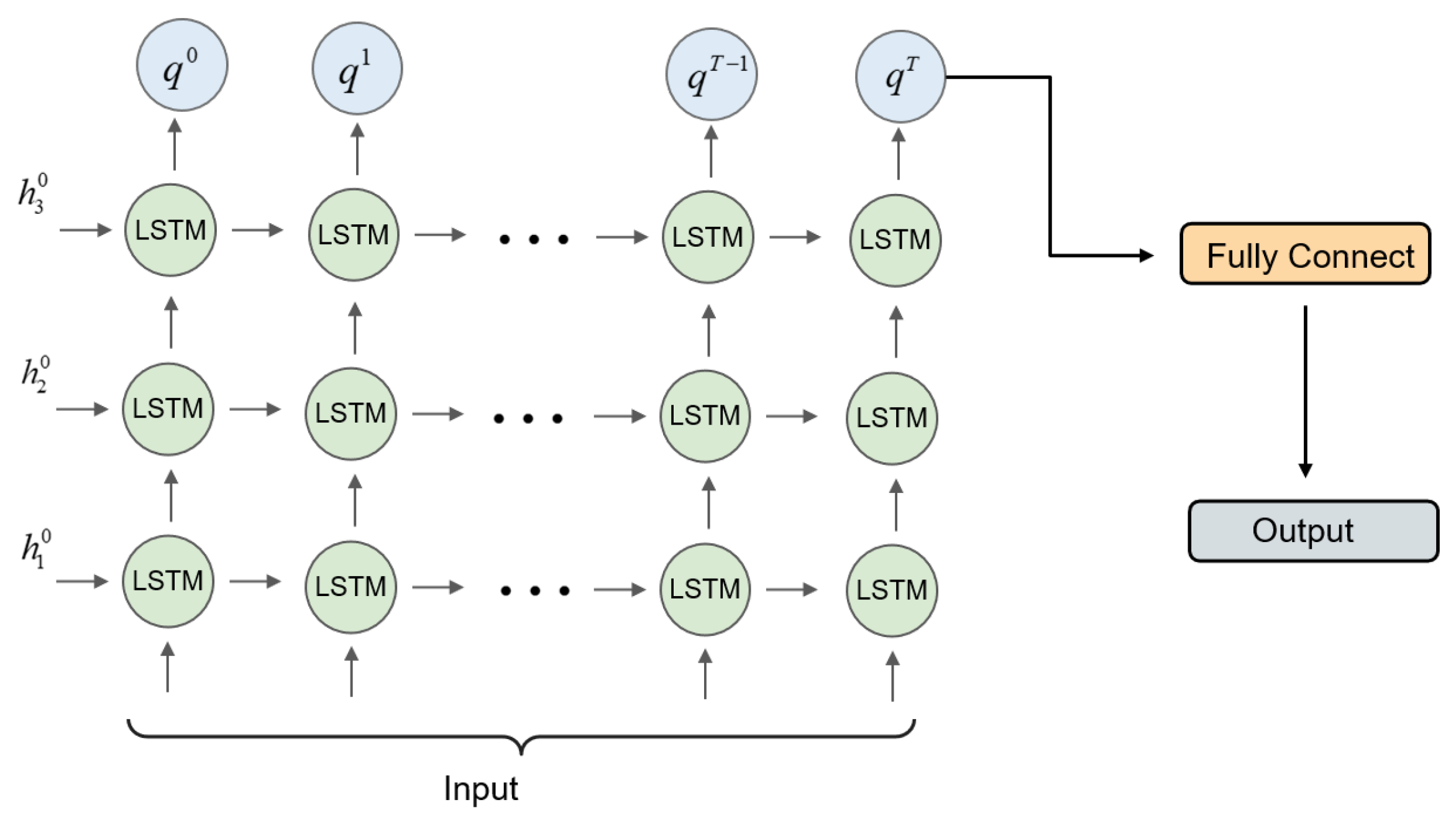
This paper uses an unfolded LSTM structure to model the spatial–temporal feature in the video frame sequence. This structure is first proposed in [
20] for solving sparse Bayesian learning optimization problems by mapping the traditional process of iterative SBL to an LSTM structure. The model shows good convergence performance using the unfolded LSTM for sparse optimization, which can greatly accelerate the SBL optimization solution process. Inspired by this method, we try to use the unfolded LSTM model in the VCS problem, and it provides surprisingly good performance. In the experiment, we found that the structure can not only take advantage of the LSTM’s property of long-time memory of sequences to efficiently fuse the spatial–temporal information from intra- and interframes but also fix the LSTM, which originally iterates according to the length of sequences, to a finite length. In that case, it essentially forms a feedforward network, which converges rapidly in the training process compared with the classical LSTM network. It can greatly reduce training time consumption and make the reconstruction process faster.
In addition, compared with CSVideoNet and VCSNet, since the proposed method does not adopt the multi-layer CNN structure, we use Xavier [
21] to initialize the network parameters without pre-training, which makes our proposed network more efficient.
The contributions of this paper are summarized as follows:
A unified end-to-end deep learning VCS reconstruction framework is proposed, including the measurement and reconstruction part, both of which consist of deep neural networks. We train the framework using a single loss function in a data-driven method, which makes the training process more efficient and faster;
The spatial–temporal information fusion reconstruction with multiple sampling rates is accomplished by using the unfolded LSTM network, which obtains better reconstruction effects and improves the convergence performance significantly;
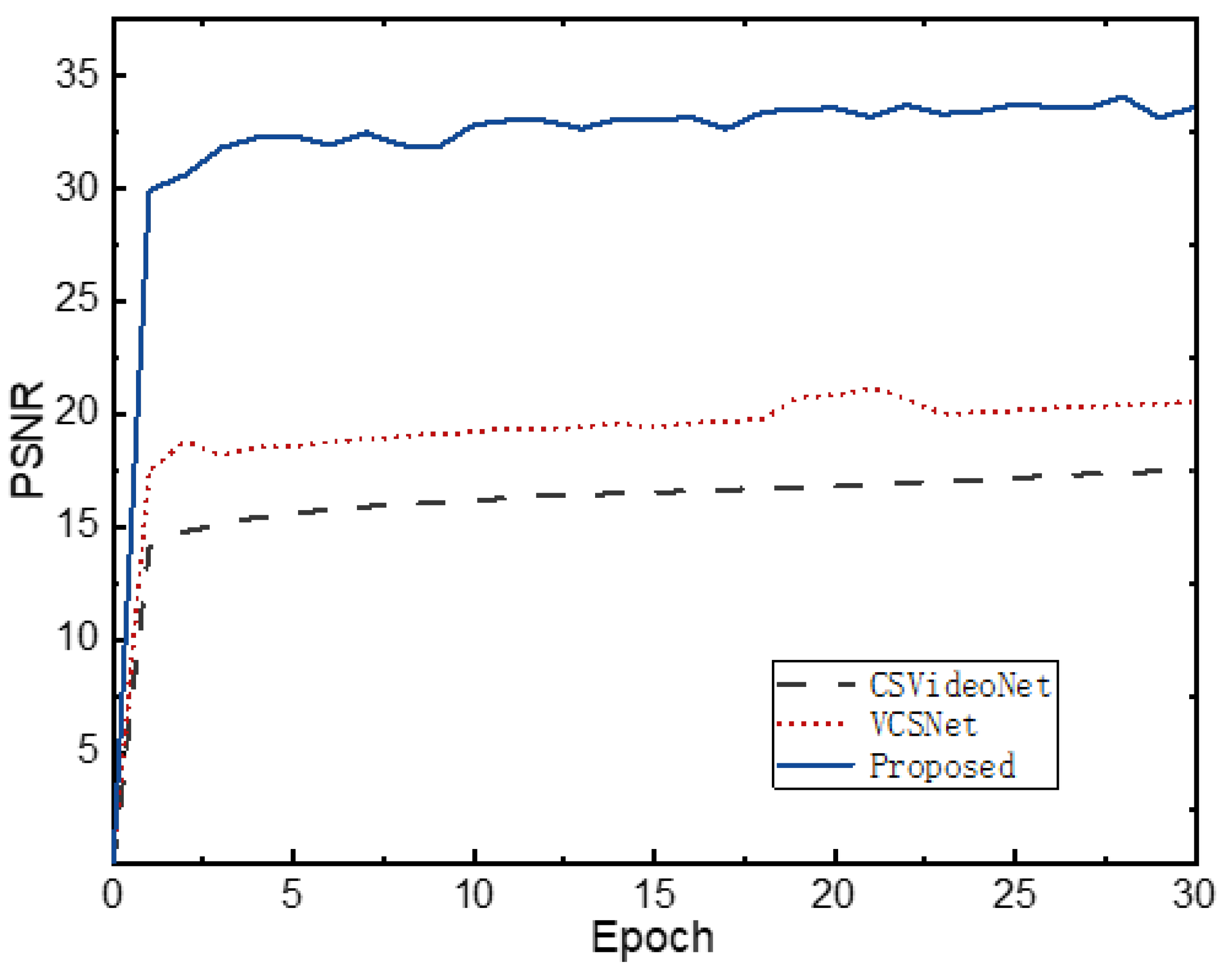
Compared with the existing VCS methods, we demonstrate that the proposed network provides better reconstruction results under a wide range of measurement ratios, even under the measurement ratio as low as 0.01. We also experimentally demonstrate that the network has good convergence without pre-training and converges faster than the comparison methods.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}