3.2. Imaging Method for Unstructured Array Cameras
In response to the problem that a single-lens camera sensor has limited pixels and cannot capture high-quality detailed textures in large scenes, an unstructured array camera is designed. By stitching together frames captured by multiple cameras with different viewpoints and different focal lengths within the same field of view, ultra-high-resolution and ultra-large scene video synthesis are achieved. This unstructured array camera design draws inspiration from the compound eye principle in biology.
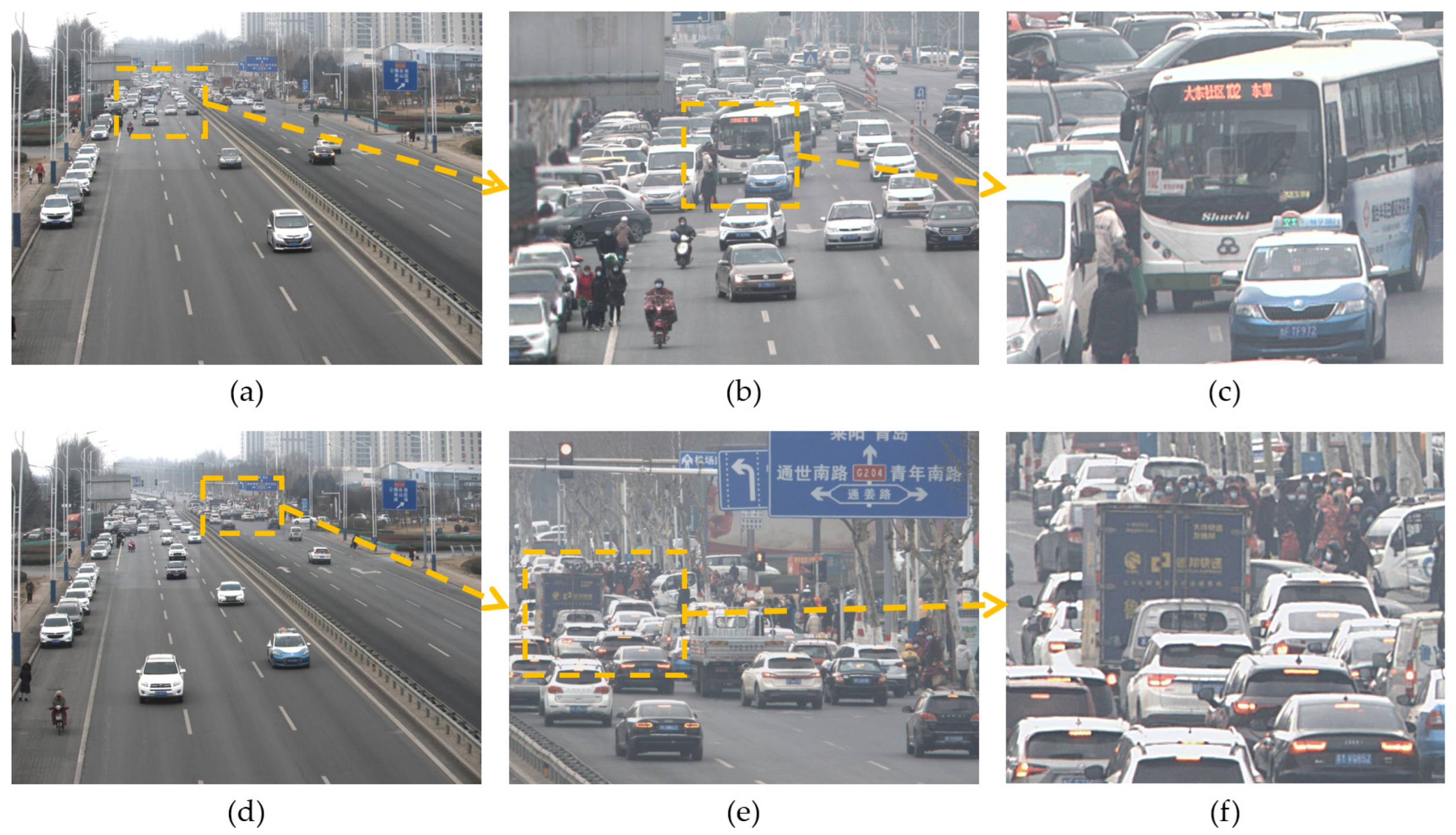
In the field of biology, human perception information only comes from a part of the field of view. Within the 120° field of view of the human eye, only a 10° field of view is a visual-sensitive area, information can be correctly recognized within a 10° to 20° field of view, and the 20° to 30° field of view is more sensitive to moving objects. Generally, the field of view that the human eye can focus on and observe is 25°, which accounts for about 20% of the entire field of view of the human eye. Therefore, the vast majority of information in human vision comes from 20% of the area in the complete field of view.
In the real world, visual information in broad areas also follows the principle of non-identical distribution. The field of view of a lens with a focal length of 16 mm is about 114°, and the images taken with this lens can simulate the visual range of the human eye. As shown in the real shot group (a) in
Figure 2, it can be found that valuable visual signals are mainly distributed in areas where vehicles and people move, such as streets and stadiums. By calculating the content changes in the image sequence in the video, the time entropy map of group (b) in
Figure 2 is obtained. The time entropy map reflects the spatial information distribution density of the scene. By observing the time entropy map, it can be found that the core information area accounts for about 25% of the entire field of view. Therefore, the unstructured array camera can make use of this principle, identify areas with visual value in the field of view through intelligent algorithms, allocate more camera field of view resources to these areas, and capture high-information videos with low-cost array cameras.
Inspired by the above biomimetic principles, this paper proposes and designs a scalable multi-scale unstructured array camera imaging method. The unstructured array camera is designed with one wide-angle camera and three long-focal length cameras. Among them, the wide-angle camera uses a 16 mm fixed-focus lens to capture large field of view images similar to the human eye, which this paper refers to as the “global camera”. A lens with a variable focal length of 25–135 mm is used to capture high-definition images of local areas, which this paper refers to as the “local camera”. All cameras are FLIR BFSU3-120S4C-CS rolling shutter cameras, equipped with Sony IMX226 sensors, capable of capturing 4000 × 3000 resolution, 10-bit color depth images at a frequency of 30 frames per second. All cameras are mounted on a gimbal fixed on a 50 cm long rail, and each camera can freely change its viewing angle, and the three local cameras can freely adjust the lens focal length. The unstructured array camera is shown in
Figure 3.
In traditional array camera systems, different cameras must capture a set of videos with overlapping fields of view. They locate matching points between different videos through image feature matching, then solve the homography matrix to get the relative positions of different cameras, and then use a planarizer for global optimization. This is a computationally intensive non-convex optimization problem. In response to the high complexity and poor practicality of image matching and stitching in traditional array cameras, this paper proposes an unstructured embedding method. Through the global camera, it can locate the field of view position of all local cameras, and no longer requires the field of view of each local camera to overlap.
The unstructured array camera uses one wide-angle camera to capture a large field of view image and multiple long-focal-length cameras to capture local high-definition images. With the use of an unstructured embedding algorithm, local cameras can be sparsely allocated to adapt to the shooting requirements of different scenes, thus achieving low-cost, high-information large field of view monitoring. Not only is the hardware cost of the unstructured array camera low, but its algorithmic process is also more efficient than that of structured array cameras.
3.3. Feature Point Extraction Based on Symmetric Auto-Encoding and Scale Feature Fusion
To synthesize the optimal large field of view ultra-high-resolution video, first adjust the global camera to the field of view area that needs to be shot, and calculate the time entropy map of the current large field of view from the video captured by the global camera. After searching for areas with high information value in the time entropy map, manually adjust the direction of the gimbal of each local camera so that the viewpoint of the local camera covers the area where the high-definition field of view needs to be captured, as shown in
Figure 4.
After obtaining the images captured by each camera, it is necessary to locate and stitch the images from each camera. Feature point extraction is a core step in image location. Its goal is to extract feature points from the image that can be used for image location matching. By converting these large amounts of image data into a small number of feature points, it greatly reduces the dimensionality of the data and reduces computational complexity.
Due to the maximum focal length difference of 6 times between the global camera and the local camera, and the unknown focal length ratio, traditional image matching methods cannot effectively solve problems such as image location, scale ratio calculation, and image rotation in array cameras. For example, traditional multi-scale pyramid-based template matching algorithms can handle image matching problems at different scales [
15,
16], which can solve the problem of large focal length differences in array cameras. However, these methods cannot solve the problem of non-parallel image horizontals between different cameras, i.e., image rotation, which leads to skewing of the pictures of each camera in the synthesized large-scene video, resulting in poor video effects. Template matching methods based on invariant moments are invariant to image rotation and translation [
17,
18]; therefore, they can solve the problem of image rotation in array cameras. However, these methods cannot handle the inconsistency and unknown focal length of different cameras, resulting in disordered image sizes in the synthesized large-scene video using this method, leading to poor video effects. Currently, widely researched deep learning-based feature point extraction algorithms [
19,
20,
21] learn and extract useful features from images automatically using convolutional neural networks, reducing the workload of feature design, and achieving better feature point extraction performance. However, deep learning-based algorithms have problems with the loss of spatial location information during convolution and pooling operations, resulting in poor robustness of feature point location capability and insufficient feature point numbers during large-scale scaling. The synthesized large-scene video is prone to staggered and offset viewing angles, and the imaging quality is not stable. For example, SuperPoint [
21] is an end-to-end trained deep learning model used to detect and describe key points in images. Its main advantage is that it combines key point detection and descriptor generation into a unified network structure, allowing it to be trained from unlabeled data. However, the SuperPoint network model has the common problems of deep neural networks, namely, large network parameters, complex operations, slow computing speed, which result in slow synthesis speed of large-scene videos, high computational power consumption, and poor practicality [
22,
23].
This article optimizes the model based on the research of deep learning models and the SuperPoint network model. By adding a symmetric structure auto-encoder, it gradually restores the position information of the features during decoding and fuses multi-scale features to improve the model’s ability to locate feature points and increase the number of extracted feature points. The deep separable convolution method is optimized to enhance the model’s operation speed. The network model proposed in this article comprises a shared encoder, three max pooling layers, and two decoders. Among them, the shared encoder is used to extract image features, and then three max pooling layers are used to reduce the dimension of image features; one decoder head is used for image feature point detection, and the other is used to generate feature point descriptions. The input and output sizes of the two encoder heads are the same, which facilitates the correspondence of positions. The design of the network model is shown in
Figure 5.
The data flow of this neural network model is as follows: given an input image, first scale its size to , then input the processed image into the shared encoder. The shared encoder is a deep separable convolution network used to obtain the deep features of the image. The deep features of the image outputted by the shared encoder are used as inputs for both the feature point decoder and the descriptor decoder. In the feature point decoder, the position information lost in the shared encoder is restored through up-sampling operations to get the feature point probability map of the image; in the descriptor decoder, convolutional filtering and differential amplification are used to obtain the corresponding feature point descriptors of the image. The obtained feature point probability map and feature point descriptors will be used for subsequent image location and scale ratio calculations.
3.3.1. Shared Encoder
The shared encoder is a convolutional neural network that takes an input image and, through a series of convolution and pooling operations, transforms the original pixel-level image data into a feature map. This feature map is a multi-channel two-dimensional array, where each channel corresponds to a specific feature of the input image. The feature point decoder uses information in the feature map to determine the key point positions in the image, while the descriptor decoder uses the feature map to generate descriptors for each key point.
Existing deep learning-based feature point extraction methods mostly use VGG-like network models to extract features from input images. The VGG network model is a high-performance image feature extractor, but it has many network parameters and a large amount of computation, resulting in low efficiency in image feature point matching tasks in real-time high-resolution scenarios. To reduce the number of network model parameters and the amount of computation, and to speed up the model’s feature point extraction, this paper proposes the use of lightweight deep separable convolution [
33] as a replacement for the VGG-like network model. Deep separable convolution divides traditional convolution into intra-channel and inter-channel convolutions, as shown in
Figure 6. Suppose the size of the input image is
. Intra-channel convolution performs convolution operations separately on each channel using
kernels of size
, extracting feature vectors within each channel, and obtaining a total of
feature maps. Inter-channel convolution uses
kernels of size
to carry out traditional convolution operations on
feature maps, to extract features between different channels.
If traditional convolution operations are used, the number of parameters is and the amount of computation is . For deep separable convolution, when intra-channel convolution operations are used, the number of parameters is , which is of the traditional convolution, and the amount of computation is , which is of the traditional convolution. When inter-channel convolution operations are used, the number of parameters is , which is of the traditional convolution, and the amount of computation is , which is of the traditional convolution. Therefore, the number of parameters and the amount of computation for deep separable convolution is of traditional convolution. Compared with traditional convolution, deep separable convolution significantly reduces the amount of computation and the number of parameters in the neural network.
In response to the issue where using deep separable convolution to improve network model operation speed results in a decrease in image feature extraction capabilities, this paper proposes using point-wise convolution operations to expand the channels of the feature map, enriching the number of features and improving the accuracy of the network model. At the same time, the feature output dimension is increased from 128 dimensions to 256 dimensions to compensate for the loss of feature information. In this paper, the size of the convolution kernel of the intra-channel convolutional layer used is 3 × 3, and the size of the convolution kernel of the inter-channel convolutional layer is 1 × 1. The convolutional steps are all 1, and the final output channel dimension of the depth-separable convolutional module is 256 × 1.
3.3.2. Feature Point Decoder
After the shared encoder extracts the deep features of the image, it is necessary to identify key points in the image feature vectors. These key points are significant features of the image, such as corners, edges, etc. They provide a stable and robust relationship between images and are an important basis for array camera image stitching. In contrast to traditional image matching, image stitching requires more precise feature point locations. The pooling layers of the shared encoder lose a large amount of feature point location information while reducing the dimension of image features. To recover the location information lost in the pooling layer, the information of the three pooling layers in the shared encoder is first up-sampled using bilinear interpolation, and then the low-level feature maps at the corresponding positions are concatenated. By embedding low-level visual features as a supplement to high-level semantic features, the feature position information is gradually restored through a hierarchical restoration process. The feature point loss
is a binary cross-entropy loss, the input image size is
,
is the image feature point label,
is the model output value, and the calculation method of the feature point loss is as follows:
The output of the feature point decoder is a list of keypoint locations, each corresponding to the pixel at the same position in the input image. At the same time, each detected keypoint is assigned a probability value, representing the probability that the location is a keypoint. The output of the feature point decoder can be viewed as a probability map, where each pixel’s value represents the probability that the pixel in the original image is a keypoint.
3.3.3. Descriptor Decoder
The descriptor decoder generates an independent descriptor for each detected feature point. A descriptor is a vector that represents the pixel pattern around a feature point, and it serves as the basis for feature matching. In tasks such as image registration, object recognition, and visual localization, the descriptors in two images are compared to find corresponding feature points, thereby determining the spatial relationship between images. Therefore, the performance of the descriptor decoder is crucial for the entire feature point extraction task. The descriptor decoder also uses the feature map generated by the shared encoder as input, then generates a descriptor at each keypoint location, ensuring that the generated descriptors are robust to small displacements, rotations, and scale changes in the image. The descriptor decoder first uses a convolutional kernel of size
to filter the features output by the shared encoder, and for an image of size
, a feature vector of size
is obtained. Then, a convolutional kernel of size
is used to obtain a feature vector of size
. To have a size matching the output image, the size is restored using bicubic interpolation, and the
normalization activation is used to obtain a
feature descriptor, where
is the descriptor length. The descriptor decoder loss is made up of all cell pairs from the input image, with each cell from the original image denoted as
, each cell from the transformed image denoted as
, the similarity between the cells is
, and
,
are the center coordinates of
and
, respectively, as follows:
The calculation method for the descriptor decoder’s loss is as follows:
The output of the descriptor decoder is a vector of dimension n. This n-dimensional vector is the descriptor of the feature point, which contains information about the image region around the feature point, and is used for subsequent image feature point matching.
3.3.4. Loss Function
In this network model, a loss function is used to measure the difference between the model’s predicted results and the true values. By minimizing the loss function, the model can learn the mapping relationship from the input image to the target output (feature points and their corresponding descriptors). The loss function of the network model comprises the feature point decoder loss and the descriptor decoder loss. The feature point decoder loss function is used to calculate the Euclidean distance between the predicted feature point locations and the actual feature point locations. By minimizing this part of the loss, the model can learn how to accurately detect feature points in the image. The descriptor decoder loss is used to calculate the Euclidean distance between the predicted descriptors and the actual descriptors. By minimizing this part of the loss, the model can learn how to generate descriptors with strong uniqueness and robustness.
Assuming the training image
is transformed to generate image
, where
is a randomly generated homography transformation matrix,
. The original image
and the transformed image
are inputted into the network simultaneously,
is the descriptor label,
is the feature point label,
and
are the corresponding model output values, and
is the parameter to balance the two losses. The final loss function is:
3.3.5. Training Parameter Optimization and Transfer Learning
The SuperPoint network model uses constrained random homography transformations in self-supervised training to construct image pairs with known pose relationships, and then uses these image pairs to learn feature point extraction and descriptor generation. The basic process is to first detect a set of feature points from the target through the basic feature point detector, then apply the random homography matrix to the mapping of the input image, and finally combine all the feature points of the mapped images.
represents the input image,
is the calculated feature points, and
is a random homography matrix. The random homography transformation can be represented as:
The SuperPoint network model is a model designed for image feature point extraction tasks in SLAM (Simultaneous Localization and Mapping). In SLAM tasks, the changes in images are characterized by large rotational variations and small scale variations. Therefore, the scale transformation in the random homography transformation is restricted to 0.8–1.2, and the rotation transformation is restricted from −180° to 180°. In unstructured array cameras, the horizon angle difference between the global camera and the local camera is generally within 10°. This paper changes the rotation restriction of the real image random homography transformation in the SuperPoint network model from −15° to 15°. The focal length ratio of the global camera and the local camera is generally 3 to 6 times, but because the image resolution in the training dataset MS COCO is around
, an overly large-scale range would cause the image resolution to be quite low to extract image feature points; therefore, this paper changes the image scale restriction in the SuperPoint network model to 0.3–1.7 to adapt to the characteristics of images in the array camera. At the same time, due to the increase in the scale ratio, this paper also expands the area restriction for random image movement. Detailed improvements on the training parameters are shown in
Table 1.
In the MS COCO dataset, there are mostly small scenes with single type objects, and the image size is relatively low. To ensure that the model trained has good feature point extraction performance in large outdoor scenes, this paper collected 5000 images with a resolution of 4000 × 3000 in three different outdoor scenes using five different focal lengths, and carried out transfer training on the well-trained network model. The collected images are shown in
Figure 7.
This section provides a detailed description of the proposed feature point extraction method based on symmetric self-encoding and scale feature fusion. By using depthwise separable convolution to replace the VGG network model, the number of model parameters and the amount of computation are significantly reduced, making the model faster in inference time. At the same time, due to the reduction in the number of parameters, the model using depthwise separable convolution is less prone to overfitting than the VGG network, demonstrating better generalization ability. This section designs a feature point extraction method based on symmetric self-encoding and scale feature fusion. The symmetric structure enhances the interpretability of the model, as the representation of the hidden layer can be clearly mapped back to the input space through the decoder, allowing the model to better learn and understand the feature point information of the image; scale feature fusion embeds the deep image features extracted by depthwise separable convolution into low-level visual features, gradually restores feature point position information through hierarchical restoration, and can obtain feature representations with rich semantic information and high spatial resolution. At the same time, this section optimizes network model training parameters for the characteristics of array camera images, and uses high-resolution images taken with an array camera for transfer learning to improve the model’s feature point detection performance.
3.4. Optimization of Image Localization and Scale Alignment
After obtaining the set of feature point matches between the local camera image and the global camera image, it is necessary to solve for the corresponding positional relationship. According to the principles of lens imaging, if the projection mapping matrix from a point
in real space to a point
on the image sensor is denoted as
, then point
, point
, and the projection mapping matrix
have the following relationship:
In real space, there is a surjective relationship between point
and point
projected onto the image sensor, namely, starting from point
and drawing a ray in the direction of point
, all points in real space on this ray will be projected onto point
on the image sensor. Therefore, the projection mapping matrix
can be simplified by selecting a specific plane in real space. Here, we choose plane
in the real-world coordinate system, and the mapping relationship can be simplified as follows:
At this point, the real-world space is simplified to a plane parallel to the image sensor, and the points on this plane have a one-to-one mapping relationship with the points projected onto the image sensor. The projection matrix is represented by
, namely:
By reducing the real-world space to a plane, the projection transformation relationship between this plane and the image sensor plane is called a homography transformation, and matrix
is called a homography matrix. Further extending the homography transformation, the projection transformation relationship between two image sensor planes can be obtained. When two cameras capture the same real-world plane image at the same time, we have:
The homography matrix represents the image projection mapping matrix from the plane where camera A is located to the plane where camera B is located.
By setting the last element of matrix
to 1, we have:
After expanding the matrix, we obtain:
After calculating the homography matrix that transforms the local camera image to the global camera image, this paper uses the lower left vertex of the local camera image as the origin of the coordinate system, and constructs a Cartesian coordinate system with the local camera image as the first quadrant of the coordinate system. By left-multiplying the coordinates of the four vertices of the local camera image by the homography matrix, the coordinates of the local camera image mapped to the global camera image can be obtained, as shown in
Figure 8.
Since the image after homography transformation must be a convex quadrilateral, the scale relationship between the two can be calculated using the ratio of the area of the transformed convex quadrilateral to the area of the global image. This section proposes an area calculation method based on the coordinates of the four vertices of the convex quadrilateral, with the formula as follows:
Here,
represents the area of the transformed local camera image,
and
represent the horizontal and vertical coordinates of the four vertices of the transformed local camera image, and
. The final scale ratio between the global camera image and a particular local camera image is obtained as:
Here, represents the area of the global camera image. This method allows for the quick and accurate calculation of the scale ratio between different cameras.
Since each local camera has a different focal length, the images captured are also of different scales. In order not to lose image information when embedding, and to avoid redundant information, all images captured by the cameras need to be adjusted to the same scale before they can be embedded and fused. Since there can be a maximum scale difference of up to 6 times between the global camera and the local camera, to reduce jagged edges that can occur after enlarging the global camera image, this paper uses a bilinear interpolation algorithm to enlarge the image.
The main idea of the bilinear interpolation algorithm is to calculate the pixel points added after enlarging by using the pixel values of the adjacent 4 points in the original image, as shown in
Figure 9.
For the pixel points to be added, the pixel values of the four surrounding pixel points
,
,
, and
are
,
,
, and
, respectively. The bilinear interpolation algorithm first performs interpolation twice in the horizontal direction:
Then, an interpolation operation in the vertical direction is performed:
Next, the maximum value among all the scale ratios of the local camera and the global camera is denoted as
:
Then, the global camera image is enlarged by
times using the bilinear interpolation algorithm. The enlargement ratio corresponding to different local camera images is denoted as
, and calculated as follows:
All local camera images are enlarged using the bilinear interpolation method. At this point, the global camera image and all local camera images are at the same scale.
Since different camera images have different scale ratios, all image scales need to be aligned before image stitching can be performed. However, after the image is scaled, the original homography matrix is no longer valid. To reposition the scaled image, this section proposes a homography matrix scaling algorithm with scale changes.
Let the homography transformation matrix from each local camera image to the global camera image be
, the global camera image be
, the mapping matrix for enlarging the global camera image be
, the enlarged image of the global camera be
, the local camera image be
, the mapping matrix for enlarging the local camera image be
, and the enlarged image of the local camera be
. For the global camera image, we have:
Similarly, for the local camera image, we have:
From
, we get:
Let
be the mapping matrix that transforms the local camera image to the global camera image at the same scale, we have:
For the problem of calculating the scale ratio of array camera images, this section proposes a method based on the area ratio of a convex quadrilateral, which can quickly calculate the scale ratio relationship between different cameras based on the homography matrix. For the positioning problem of array camera images, this section proposes a homography matrix scaling algorithm with scale changes. By decomposing and performing matrix operations on the homography matrix , a calculation method is obtained that quickly positions the scaled camera image in the final ultra-large scene image. With this formula, the image position of different cameras can be quickly located after scaling, without the need for additional feature point extraction and positioning on high-resolution images, thus improving the speed and accuracy of image positioning.
3.5. Image Stitching Optimization
After obtaining the positions of the images from each camera, all the images captured by the cameras can be stitched together to form a super high-resolution image. However, due to the different physical spatial positions of each camera, they have different shooting angles when shooting the same physical plane, resulting in images with different degrees of distortion and deformation. If the local camera images are directly embedded into the global camera image, the stitched edge parts will have a clear segmentation, as shown in
Figure 10. Since the field of view of all local cameras is within the field of view of the global camera, this section proposes a stitching optimization algorithm based on second image positioning. Taking the viewpoint of the global camera as the benchmark, it transforms the viewpoint of all local cameras into the viewpoint of the global camera, solving the image distortion problem caused by different camera viewpoints.
To build an image stitching model, the first step is to use perspective transformation to describe the change in viewpoint in three-dimensional space, the expression is:
Analysis and Decomposition of the Perspective Transformation Matrix:
In this context,
represents the linear transformation of the image,
represents the perspective transformation of the image, and
represents the translational transformation of the image:
Formulas (9) and (10) can be used to calculate the perspective plane transformation matrix
for the local camera and global camera, i.e., the transformation matrix
is calculated using the feature point matching set of the local camera image and the global camera image. Since the pixel density of the original image has changed after the global camera image has been interpolated and enlarged, re-extraction and matching of feature points can help achieve better results.
Section 3.2 obtained the position of the local camera in the global camera; therefore, it is only necessary to extract and match feature points between the local camera image and the sub-image of the global image at the corresponding position, and then calculate the perspective transformation matrix
of the local camera image. This will yield a more precise image viewpoint correction stitching matrix.
This section proposes a stitching optimization algorithm based on secondary image positioning to address the image distortion problem caused by the difference in viewpoints of array cameras. By extracting and matching feature points between the local camera image and the sub-image of the global image at the corresponding position, not only is the computation amount of feature point extraction reduced, but also errors in matching in featureless areas of the global camera image are avoided. This enhances the accuracy of feature point matching and effectively improves the effect of image stitching.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}