

Adjacent Image Augmentation and Its Framework for Self-Supervised Learning in Anomaly Detection

Abstract
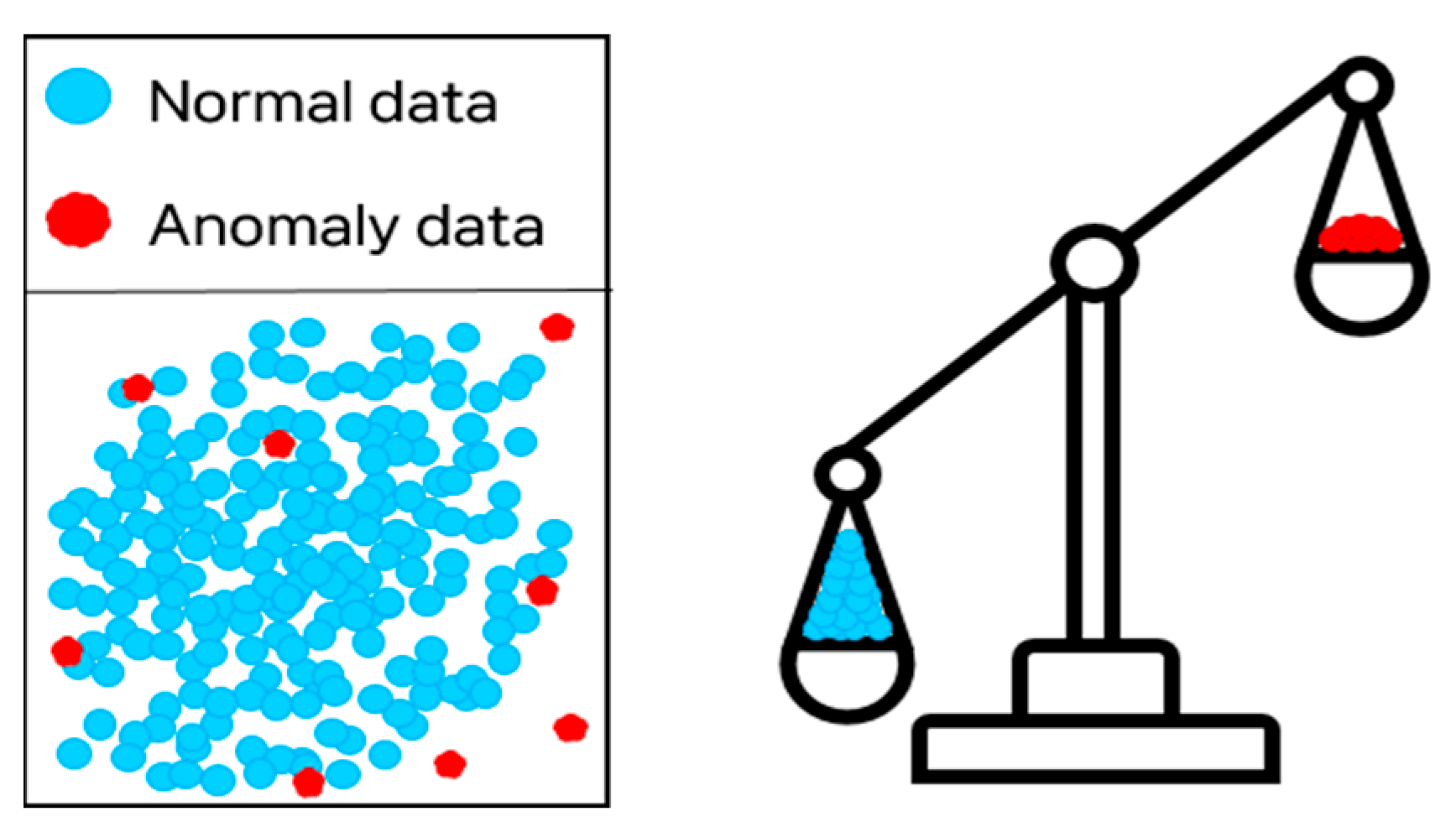
:1. Introduction
- We propose novel augmentation techniques and a framework for self-supervised learning aimed at addressing class imbalance in anomaly detection.
- Our adjacent augmentations generate synthetic anomalies with realistic contour distortions, enhancing the model’s learning process.
- We develop a contrastive learning framework that leverages characteristics from anomaly detection benchmark datasets, improving the overall effectiveness of anomaly detection models.
2. Related Work
2.1. MVTec-AD Dataset
2.2. Representative Anomaly Detection
2.3. Class Imbalance
2.4. SimCLR
3. Methods
3.1. Augmentation
3.1.1. Weak Overall
- The first step is to crop the anchor from 90% to 100% and then resize it to the size of the anchor.
- The second step is to adjust the brightness, contrast, saturation, and hue properties of the anchor to random values between 0% and 10%.
- The next step is to apply a Gaussian blur with a kernel size of 5 by 5 and a sigma value between 0.1 and 0.3.
- The final step is to apply a horizontal flip with random probabilities.
3.1.2. Strong Overall
- The first step is to crop the anchor to a random size and then resize it to the size of the anchor.
- The second step is to apply horizontal flipping with random probabilities.
- The next step is to adjust the brightness, contrast, and saturation properties of the anchor to random values between 0% and 80%, and the hue to random values between 0% and 20%.
- The random grayscale method converts images to black and white with a 20% probability.
- The final step is to apply a Gaussian blur using a kernel with a size of 10% of the anchor.
3.1.3. CutPaste
- The first step is to apply the Weak Overall augmentation.
- The second step is to set the size ratio of the patch to 2% to 15% and the aspect ratio to 0.3 to 3.
- The third step is to cut out the square patch from the anchor to the specified size.
- The final step is to paste the patch into a random location in the original image.
3.1.4. SmoothBlend
- The first step is to apply the Weak Overall augmentation.
- The second step is to set the size ratio of the patch to 0.5% to 1%, and the aspect ratio to 0.3 to 3.
- The third step is to cut out the round patch from the anchor to the specified size.
- The fourth step is to apply random contrast up to 100% to the patch, random saturation up to 100%, and random color jittering up to 50%.
- The final step is to alpha blend the original image and its patch.
3.1.5. Mosaic
- The first step is to apply the Weak Overall augmentation.
- The second step is to set the size ratio of the round area to be converted to 0.5% to 1%, and the aspect ratio to 1.
- The third step is to reduce the specified area to the rate of ζ and restore it to its original size.
- The fourth step is to apply random brightness up to 50%, random contrast up to 50%, random saturation up to 50%, and random color jittering up to 20%.
- The final step is to alpha blend the original image and the converted area.
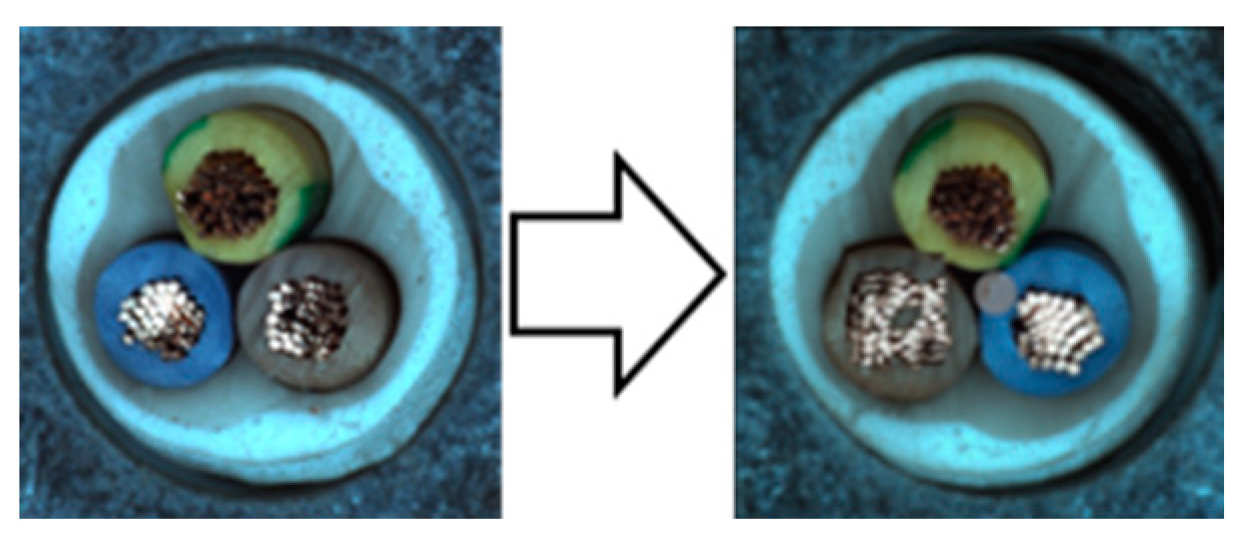
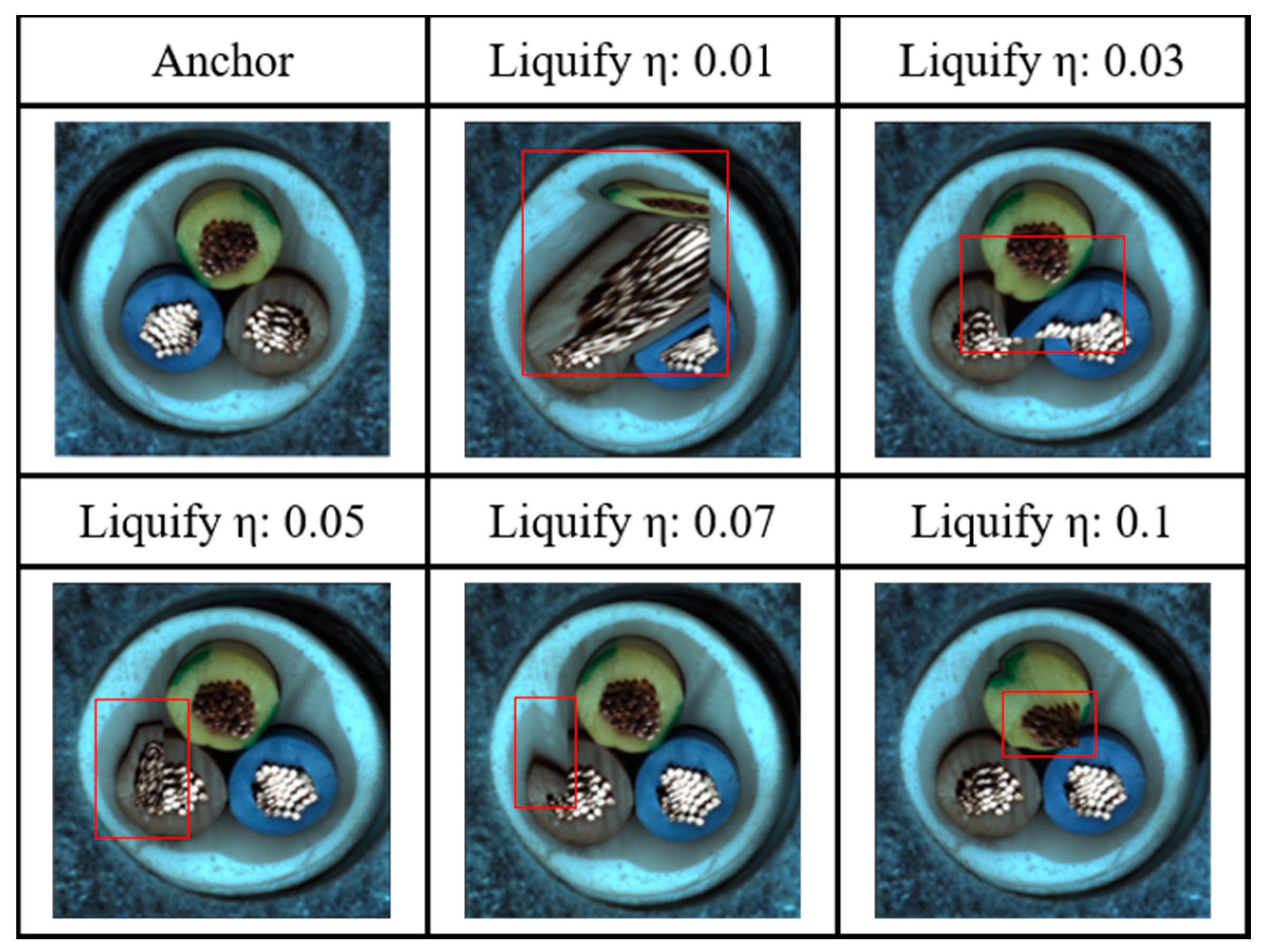
3.1.6. Liquify
- The first step is to apply the Weak Overall augmentation.
- The second step is to assign a random point to the image.
- The third step specifies each coordinate of the four triangles centered around the designated point.
- The fourth step moves the specified point to a random location at a distance of the image size × (1/η)%.
- In the final step, four triangles move as the point moves, creating contour distortion.
3.1.7. Mosiquify
- The first step is to apply the Weak Overall augmentation.
- The second step is to apply the Mosaic (ζ = 20) augmentation.
- The final step is to apply the Liquify (η = 0.05) augmentation.
3.2. Adjacent Framework
| Algorithm 1 Adjacent Framework’s main learning algorithm |
| Input: batch size N, constant , structure of . for sampled minibatch do for all do draw three augmentation functions # anchor # the first augmentation(Weak Overall-positive) # the second augmentation(Strong Overall-positive) # the third augmentation(Liquify-negative) for all do define define update networks f and g to minimize end for end for return encoder network f(∙), and throw away g(∙) |
4. Experiments
5. Discussion
5.1. Summary of Findings
5.2. Comparison with Existing Methods
5.3. Impact of Deep Learning Architecture
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
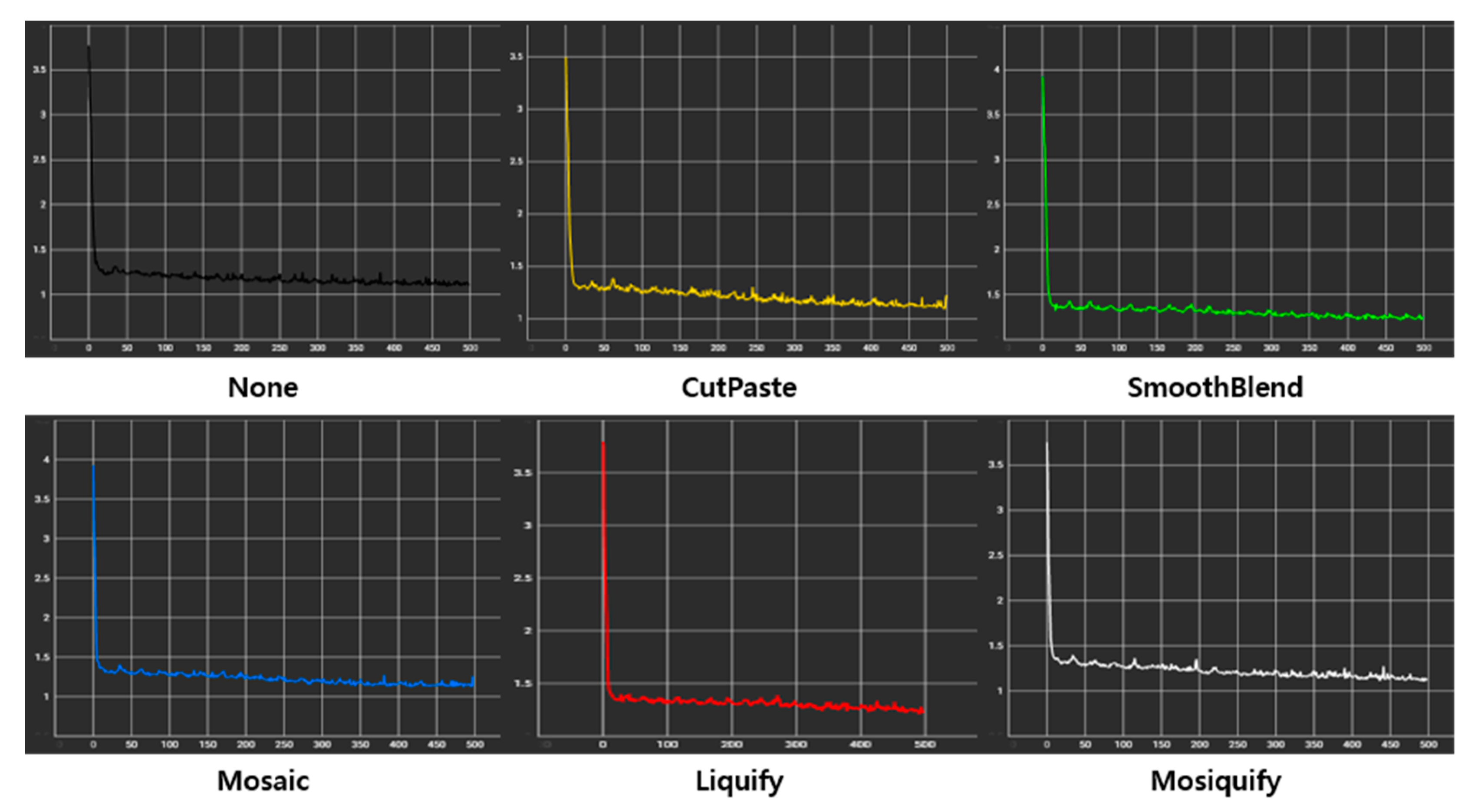

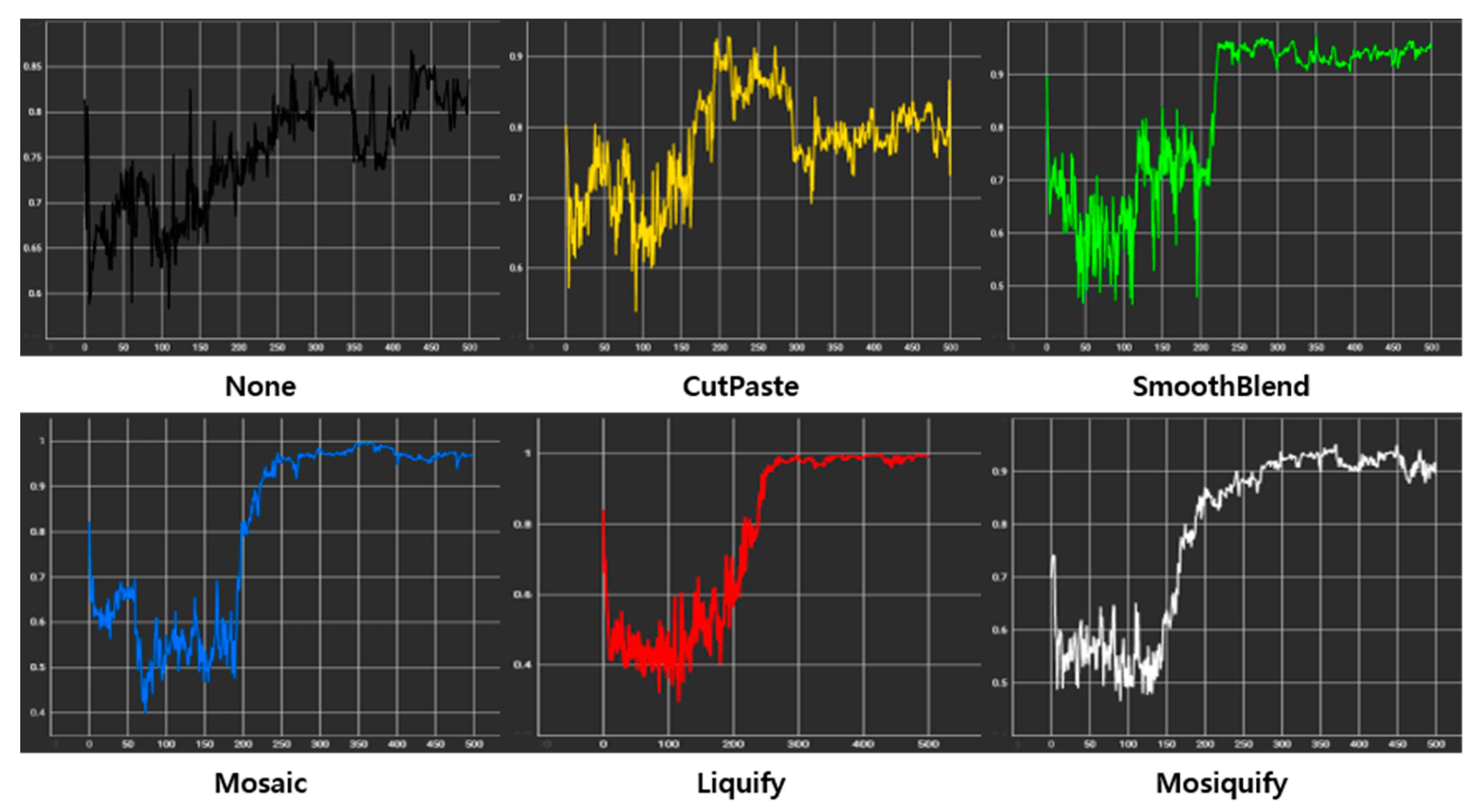

References
- Ye, F.; Huang, C.; Cao, J.; Li, M.; Zhang, Y.; Lu, C. Attribute Restoration Framework for Anomaly Detection. IEEE Trans. Multimed. 2020, 24, 116–127. [Google Scholar] [CrossRef]
- Kumari, P.; Choudhary, P.; Atrey, P.K.; Saini, M. Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets. arXiv 2022, arXiv:2207.13430. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Xie, G.; Wang, J.; Liu, J.; Lyu, J.; Liu, Y.; Wang, C.; Jin, Y. Im-iad: Industrial image anomaly detection benchmark in manufacturing. IEEE Trans. Cybern. 2024, 54, 2720–2733. [Google Scholar] [CrossRef] [PubMed]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In International Conference on Information Processing in Medical Imaging; Springer: Philadelphia, PA, USA, 2017; pp. 146–157. [Google Scholar]
- Han, D.; Wang, Z.; Chen, W.; Zhong, Y.; Wang, S.; Zhang, H.; Yang, J.; Shi, X.; Yin, X. DeepAID: Interpreting and improving deep learning-based anomaly detection in security applications. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 November 2021; pp. 3197–3217. [Google Scholar]
- Elliott, A.; Cucuringu, M.; Luaces, M.M.; Reidy, P.; Reinert, G. Anomaly detection in networks with application to financial transaction networks. arXiv 2019, arXiv:1901.00402. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. [Google Scholar]
- Bogdoll, D.; Uhlemeyer, S.; Kowol, K.; Zöllner, J.M. Perception Datasets for Anomaly Detection in Autonomous Driving: A Survey. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–8. [Google Scholar]
- Steinbuss, G.; Böhm, K. Benchmarking Unsupervised Outlier Detection with Realistic Synthetic Data. ACM Trans. Knowl. Discov. 2021, 15, 1–20. [Google Scholar] [CrossRef]
- Ali, R.; Khan, M.U.K.; Kyung, C.M. Self-Supervised Representation Learning for Visual Anomaly Detection. arXiv 2020, arXiv:2006.09654. [Google Scholar]
- Wang, G.; Wang, Y.; Qin, J.; Zhang, D.; Bao, X.; Huang, D. Video Anomaly Detection by Solving Decoupled Spatio-Temporal Jigsaw Puzzles. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Cham, Switzerland, 2022; pp. 494–511. [Google Scholar]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9664–9674. [Google Scholar]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. SPot-the-Difference Self-supervised Pre-training for Anomaly Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 392–408. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 21271–21284. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. arXiv 2020, arXiv:2006.09882. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Bergmann, P.; Batzner, K.; Fauser, M.; Sattlegger, D.; Steger, C. The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. Int. J. Comput. Vis. 2021, 129, 1038–1059. [Google Scholar] [CrossRef]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. VT-ADL: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Ruff, L.; Görnitz, N.; Deecke, L.; Siddiqui, S.A.; Vandermeulen, R.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the Thirty-Fifth Intetnational Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Yi, J.; Yoon, S. Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation. arXiv 2020, arXiv:2006.16067. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP), SCITEPRESS, Prague, Czech, 25–27 February 2019. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. PaDiM: A Patch Distribution Modeling Framework for Anomaly Detection and Localization. arXiv 2020, arXiv:2011.08785. [Google Scholar]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards Total Recall in Industrial Anomaly Detection. arXiv 2021, arXiv:2106.08265. [Google Scholar]
- Han, S.; Hu, X.; Huang, H.; Jiang, M.; Zhao, Y. ADBench: Anomaly Detection Benchmark. arXiv 2022, arXiv:2206.09426. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A survey on contrastive self-supervised learning. Technologies 2020, 9, 2. [Google Scholar] [CrossRef]
- Zheng, M.; You, S.; Wang, F.; Qian, C.; Zhang, C.; Wang, X.; Xu, C. Ressl: Relational self-supervised learning with weak augmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 2543–2555. [Google Scholar]
- Golan, I.; El-Yaniv, R. Deep anomaly detection using geometric transformations. Adv. Neural Inf. Process. Syst. 2018, 31, 9781–9791. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 622–637. [Google Scholar]
- Cohen, N.; Hoshen, Y. Sub-Image Anomaly Detection with Deep Pyramid Correspondences. arXiv 2020, arXiv:2005.02357. [Google Scholar]

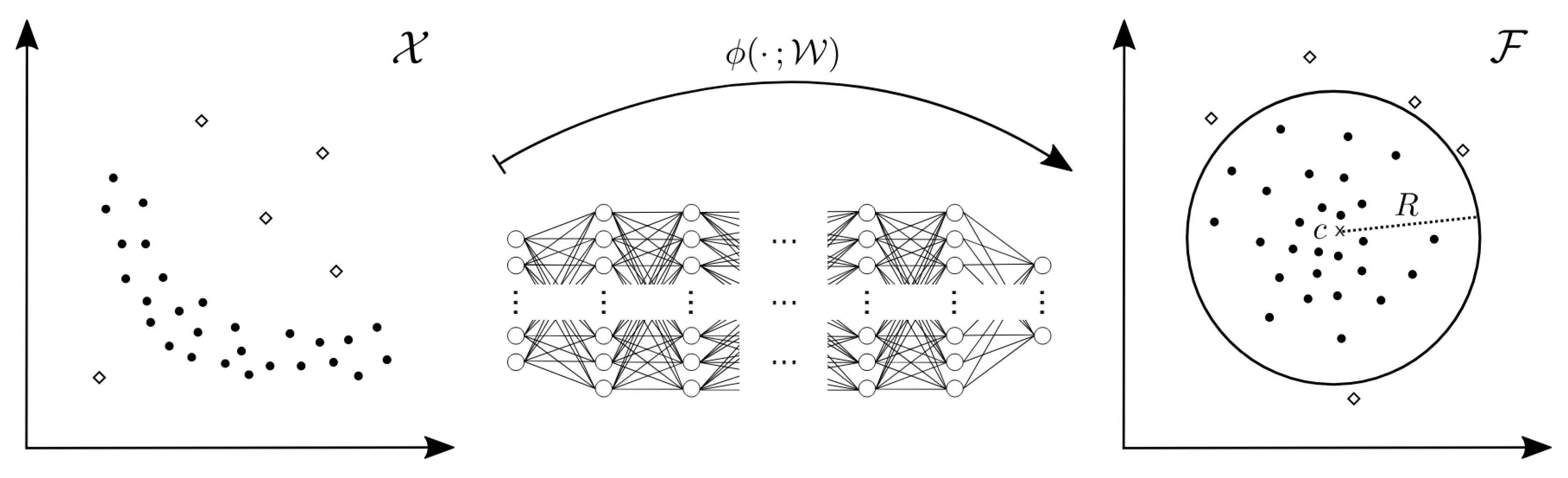

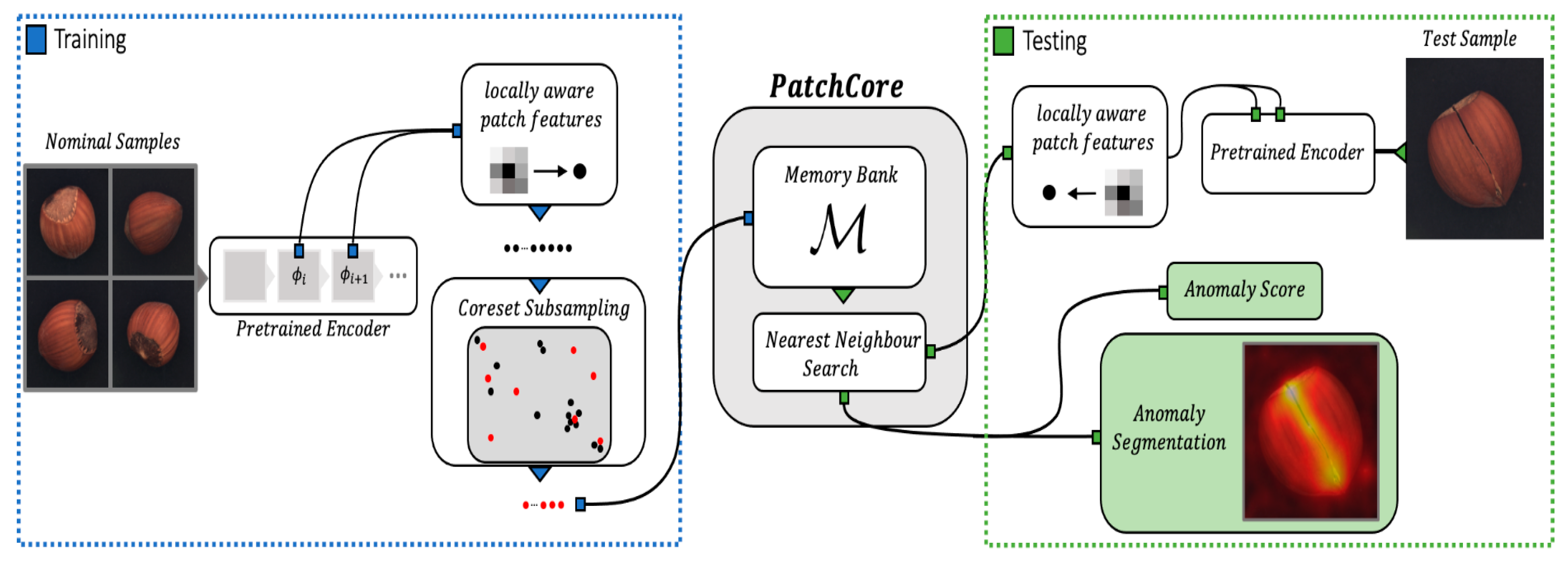











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CutPaste [13] | SmoothBlend [14] | Mosaic | Liquify | Mosiquify | |
|---|---|---|---|---|---|
| Millisecond | 227.393 | 180.518 | 95.744 | 207.446 | 267.289 |
| Category | #Train | #Test (Good) | #Test (Defect.) | #Defect Groups | #Defect Regions | Image Side Length | |
|---|---|---|---|---|---|---|---|
| Textures | Carpet | 280 | 28 | 89 | 5 | 97 | 1024 |
| Grid | 264 | 21 | 57 | 5 | 170 | 1024 | |
| Leather | 245 | 32 | 92 | 5 | 99 | 1024 | |
| Tile | 230 | 33 | 84 | 5 | 86 | 840 | |
| Wood | 247 | 19 | 60 | 5 | 168 | 1024 | |
| Objects | Bottle | 209 | 20 | 63 | 3 | 68 | 900 |
| Cable | 224 | 58 | 92 | 8 | 151 | 1024 | |
| Capsule | 219 | 23 | 109 | 5 | 114 | 1000 | |
| Hazelnut | 391 | 40 | 70 | 4 | 136 | 1024 | |
| Metal Nut | 220 | 22 | 93 | 4 | 132 | 700 | |
| Pill | 267 | 26 | 141 | 7 | 245 | 800 | |
| Screw | 320 | 41 | 119 | 5 | 135 | 1024 | |
| Toothb. | 60 | 12 | 30 | 1 | 66 | 1024 | |
| Trans. | 213 | 60 | 40 | 4 | 44 | 1024 | |
| Zipper | 240 | 32 | 119 | 7 | 177 | 1024 | |
| Total | 3629 | 467 | 1258 | 73 | 1888 | - |
| AU-ROC AU-PR | SimCLR [15] Mosaic ζ: 20 | A.F. Mosaic ζ: 20 | SimCLR [15] Liquify η: 0.05 | A.F. Liquify η: 0.05 | SimCLR [15] Mosiquify ζ = 20, η = 0.05 | A.F. Mosiquify ζ = 20, η = 0.05 |
|---|---|---|---|---|---|---|
| Framework and Aug. Category | ||||||
| Zipper | 0.789391 0.928752 | 0.773897 0.924250 | 0.829832 0.948985 | 0.942752 0.985565 | 0.788340 0.933215 | 0.738183 0.925600 |
| Hazelnut | 0.912143 0.954757 | 0.848929 0.911285 | 0.869286 0.932978 | 0.954286 0.975100 | 0.842143 0.908097 | 0.962500 0.979674 |
| Bottle | 0.917460 0.975251 | 0.998413 0.999500 | 0.986508 0.995740 | 1.000000 1.000000 | 0.938095 0.980658 | 0.950794 0.981918 |
| AU-ROC AU-PR | CutPaste [13] | SmoothBlend [14] | Mosaic ζ = 20 | Liquify | Mosiquify ζ = 20, η = 0.05 |
|---|---|---|---|---|---|
| Aug. Category | |||||
| Leather | 0.713315 0.889585 | 0.830163 0.942820 | 0.853940 0.944785 | 0.906590 0.967224 η: 0.01 | 0.635870 0.860233 |
| Zipper | 0.884979 0.964362 | 0.764968 0.929153 | 0.773897 0.924250 | 0.942752 0.985565 η: 0.05 | 0.738183 0.925600 |
| Screw | 0.923140 0.974795 | 0.819840 0.932187 | 0.792785 0.919263 | 0.927649 0.975877 η: 0.1 | 0.724739 0.892260 |
| Hazelnut | 0.863929 0.925698 | 0.916786 0.958774 | 0.848929 0.911285 | 0.954286 0.975100 η: 0.05 | 0.962500 0.979674 |
| Tile | 0.871573 0.942547 | 0.823232 0.920362 | 0.936869 0.976487 | 0.876263 0.952038 η: 0.01 | 0.898990 0.964675 |
| Transistor | 0.800417 0.763719 | 0.781250 0.706233 | 0.849167 0.813358 | 0.888750 0.877592 η: 0.1 | 0.772083 0.766140 |
| Bottle | 0.929365 0.978421 | 0.973810 0.992562 | 0.998413 0.999500 | 1.000000 1.000000 η: 0.05 | 0.950794 0.981918 |
| Metal nut | 0.886608 0.973357 | 0.804008 0.950171 | 0.838710 0.958632 | 0.927175 0.981952 η: 0.05 | 0.871457 0.966081 |
| Toothbrush | 0.672222 0.854802 | 0.880556 0.952743 | 0.758333 0.899457 | 0.894444 0.958447 η: 0.01 | 0.819444 0.930904 |
| Wood | 0.785088 0.927378 | 0.879825 0.964844 | 0.868421 0.959927 | 0.908772 0.971883 η: 0.1 | 0.858772 0.957199 |
| AU-ROC AU-PR | None | Mosaic ζ = 20 | Liquify | Mosiquify ζ = 20, η = 0.05 |
|---|---|---|---|---|
| Neg. Sample Category | ||||
| Leather | 0.697351 0.869883 | 0.853940 0.944785 | 0.906590 0.967224 η: 0.01 | 0.635870 0.860233 |
| Zipper | 0.867122 0.965440 | 0.773897 0.924250 | 0.942752 0.985565 η: 0.05 | 0.738183 0.925600 |
| Screw | 0.876819 0.961209 | 0.792785 0.919263 | 0.927649 0.975877 η: 0.1 | 0.724739 0.892260 |
| Hazelnut | 0.925714 0.964005 | 0.848929 0.911285 | 0.954286 0.975100 η: 0.05 | 0.962500 0.979674 |
| Tile | 0.797619 0.906408 | 0.936869 0.976487 | 0.876263 0.952038 η: 0.01 | 0.898990 0.964675 |
| Transistor | 0.641250 0.543602 | 0.849167 0.813358 | 0.888750 0.877592 η: 0.1 | 0.772083 0.766140 |
| Bottle | 0.869048 0.954794 | 0.998413 0.999500 | 1.000000 1.000000 η: 0.05 | 0.950794 0.981918 |
| Metal Nut | 0.773216 0.940585 | 0.838710 0.958632 | 0.927175 0.981952 η: 0.05 | 0.871457 0.966081 |
| Toothbrush | 0.830556 0.930351 | 0.758333 0.899457 | 0.894444 0.958447 η: 0.01 | 0.819444 0.930904 |
| Wood | 0.715789 0.878648 | 0.868421 0.959927 | 0.908772 0.971883 η: 0.1 | 0.858772 0.957199 |
| AU-ROC AU-PR | Liquify η: 0.01 | Liquify η: 0.03 | Liquify η: 0.05 | Liquify η: 0.1 |
|---|---|---|---|---|
| Liquify (η) Category | ||||
| Leather | 0.906590 0.967224 | 0.866168 0.942729 | 0.861753 0.954633 | 0.791440 0.926733 |
| Tile | 0.876263 0.952038 | 0.855700 0.944713 | 0.858225 0.951333 | 0.825758 0.927673 |
| Toothbrush | 0.894444 0.958447 | 0.844444 0.943854 | 0.816667 0.930320 | 0.802778 0.914638 |
| Zipper | 0.849002 0.953625 | 0.847952 0.951083 | 0.942752 0.985565 | 0.877363 0.954699 |
| Hazelnut | 0.904286 0.943691 | 0.927143 0.958012 | 0.954286 0.975100 | 0.896071 0.941236 |
| Carpet | 0.519663 0.836309 | 0.508026 0.812877 | 0.731942 0.919088 | 0.676164 0.895256 |
| Bottle | 0.865873 0.952921 | 0.996825 0.999755 | 1.000000 1.000000 | 0.994444 0.998320 |
| Metal Nut | 0.822092 0.956493 | 0.817204 0.952127 | 0.927175 0.981952 | 0.810850 0.949913 |
| Cable | 0.794978 0.871893 | 0.846130 0.909616 | 0.802849 0.874685 | 0.847639 0.917611 |
| Screw | 0.726173 0.893507 | 0.703423 0.884927 | 0.782332 0.917255 | 0.927649 0.975877 |
| Pill | 0.633115 0.907203 | 0.729951 0.928439 | 0.655210 0.899663 | 0.735952 0.936548 |
| Transistor | 0.844167 0.823265 | 0.834583 0.818871 | 0.815000 0.804524 | 0.888750 0.877592 |
| Wood | 0.818421 0.939274 | 0.868421 0.960217 | 0.811404 0.942707 | 0.908772 0.971883 |
| Grid | 0.765246 0.900952 | 0.794486 0.920962 | 0.782790 0.920473 | 0.812865 0.921557 |
| Capsule | 0.735939 0.932523 | 0.768249 0.939492 | 0.799761 0.952384 | 0.814120 0.954620 |
| AU-ROC AU-PR | CutPaste [13] | SmoothBlend [14] | Mosaic ζ = 20 | Liquify η: 0.01 | Mosiquify ζ = 20, η: 0.05 |
|---|---|---|---|---|---|
| Method Category | |||||
| Pipe_fryum | 0.869000 0.926897 | 0.917400 0.955720 | 0.874600 0.940887 | 0.958800 0.979326 | 0.899800 0.953652 |
| AU-ROC | Avg. | Bottle | Cable | Capsule | Carpet | Grid | Hazeln. | Leather |
|---|---|---|---|---|---|---|---|---|
| Category Method | ||||||||
| GeoTrans [31] | 67.2 | 74.4 | 78.3 | 67.0 | 43.7 | 61.9 | 35.9 | 84.1 |
| GANomaly [32] | 76.2 | 89.2 | 75.7 | 73.2 | 69.9 | 70.8 | 78.5 | 84.2 |
| SPADE [33] | 85.5 | - | - | - | - | - | - | - |
| Liquify | 88.3 | 100 η: 0.05 | 84.8 η: 0.1 | 88.6 η: 0.03 | 73.2 η: 0.05 | 81.3 η: 0.1 | 95.4 η: 0.05 | 90.7 η: 0.01 |
| PaDiM [26] | 95.3 | - | - | - | - | - | - | - |
| PatchCore [27] | 99.1 | 100 | 99.5 | 98.1 | 98.7 | 98.2 | 100 | 100 |
| AU-ROC | Metal nut | Pill | Screw | Tile | Toothb. | Trans. | Wood | Zipper |
| Category Method | ||||||||
| GeoTrans [31] | 81.3 | 63.0 | 50.0 | 41.7 | 97.2 | 86.9 | 61.1 | 82.0 |
| GANomaly [32] | 70.0 | 74.3 | 74.6 | 79.4 | 65.3 | 79.2 | 83.4 | 74.5 |
| SPADE [33] | - | - | - | - | - | - | - | - |
| Liquify | 92.7 η: 0.05 | 73.6 η: 0.1 | 92.8 η: 0.1 | 87.6 η: 0.01 | 89.4 η: 0.01 | 88.9 η: 0.1 | 90.9 η: 0.1 | 94.3 η: 0.05 |
| PaDiM [26] | - | - | - | - | - | - | - | - |
| PatchCore [27] | 100 | 96.6 | 98.1 | 98.7 | 100 | 100 | 99.2 | 99.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, G.S.; Choi, Y.S. Adjacent Image Augmentation and Its Framework for Self-Supervised Learning in Anomaly Detection. Sensors 2024, 24, 5616. https://doi.org/10.3390/s24175616
Kwon GS, Choi YS. Adjacent Image Augmentation and Its Framework for Self-Supervised Learning in Anomaly Detection. Sensors. 2024; 24(17):5616. https://doi.org/10.3390/s24175616
Chicago/Turabian StyleKwon, Gi Seung, and Yong Suk Choi. 2024. "Adjacent Image Augmentation and Its Framework for Self-Supervised Learning in Anomaly Detection" Sensors 24, no. 17: 5616. https://doi.org/10.3390/s24175616