3.2. SmartLaundry—Real-Time System Architecture
Our proposed system uses raw data collected by sensors attached to the washing machines from public washing centers to create real-time smart recommendations regarding the available machines and public laundries. We use a data-driven approach to forecast the usage of machines. The recommendations are based on real-time data and are available to mobile devices connected to the system using a mobile application and the forecasted load of the centers. Once the recommendations for available devices are received, the user can choose the one that best suits their schedule, geographic location, and available resources.
Figure 1 illustrates our proposed real-time system architecture from a high-level perspective. The sensors attached to the washing machines record the functioning data of the devices in real time. Once recorded, data are sent to the data acquisition module and preprocessed. The information extracted is stored in the cloud system, which contains the historical usage data from all the connected devices. By using this approach, the data-intensive load is moved to the cloud. Based on historical data, the forecasting module predicts future usage. The real-time recommendation module uses forecasted data regarding the usage of the devices and their current running status and will compute a list of recommended available devices to be used. The system users interact with it by using an application on their mobile phones. This way, not only will the waiting time be reduced, but resources will be allocated so that overbooking or underutilization of the machines will be avoided.
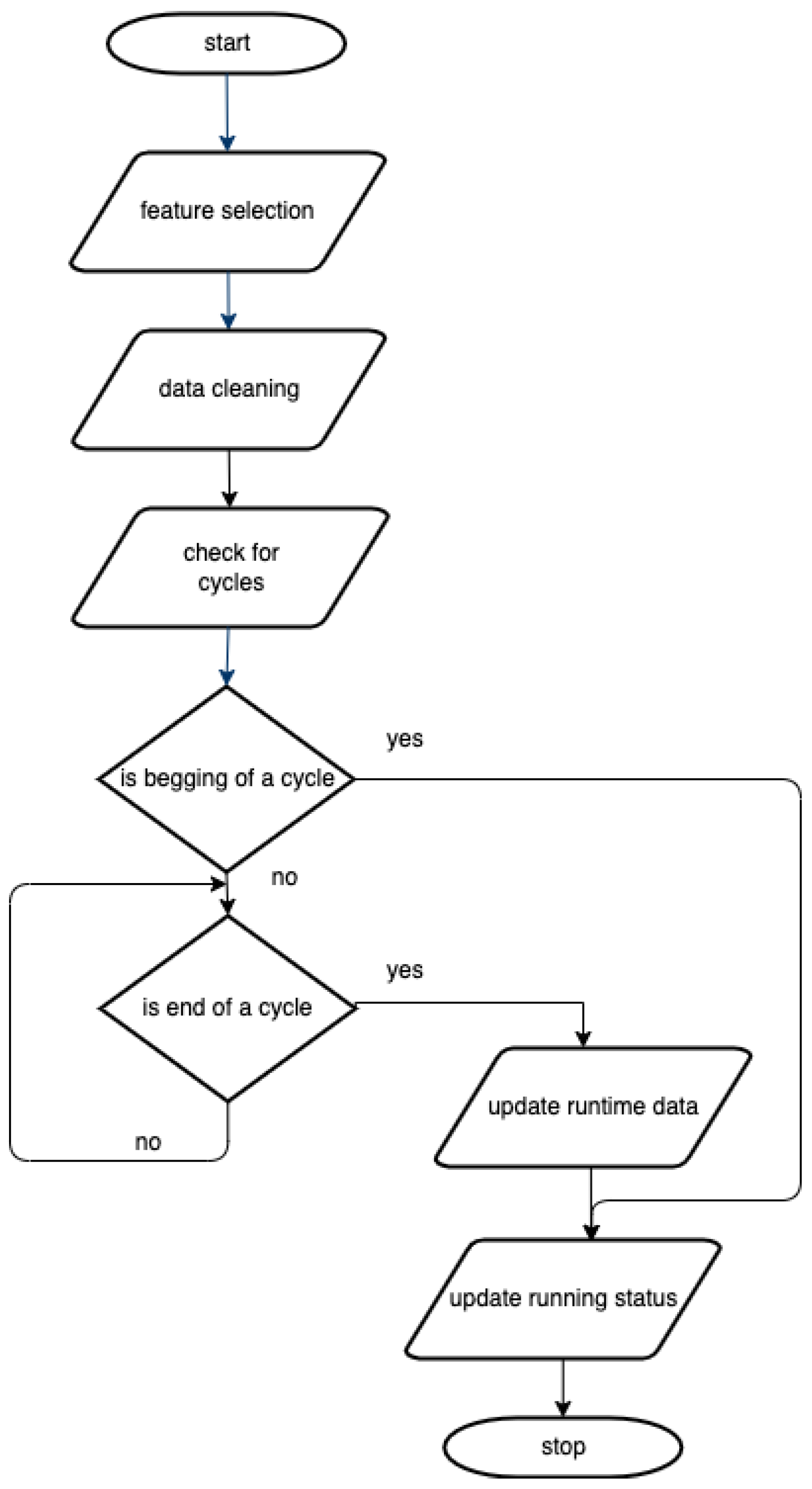
Data acquisition module. IoT data coming from devices are considered big data due to their characteristics, such as volume, variety, and velocity. Therefore, the first appropriate step in the data acquisition module is to extract the usage data of interest to overcome the dataset dimensionality complexity. The next step is the semantical and syntactical cleaning of the raw data. A comprehensive and versatile methodology tailored for data analysis and cleaning was introduced in [
36].
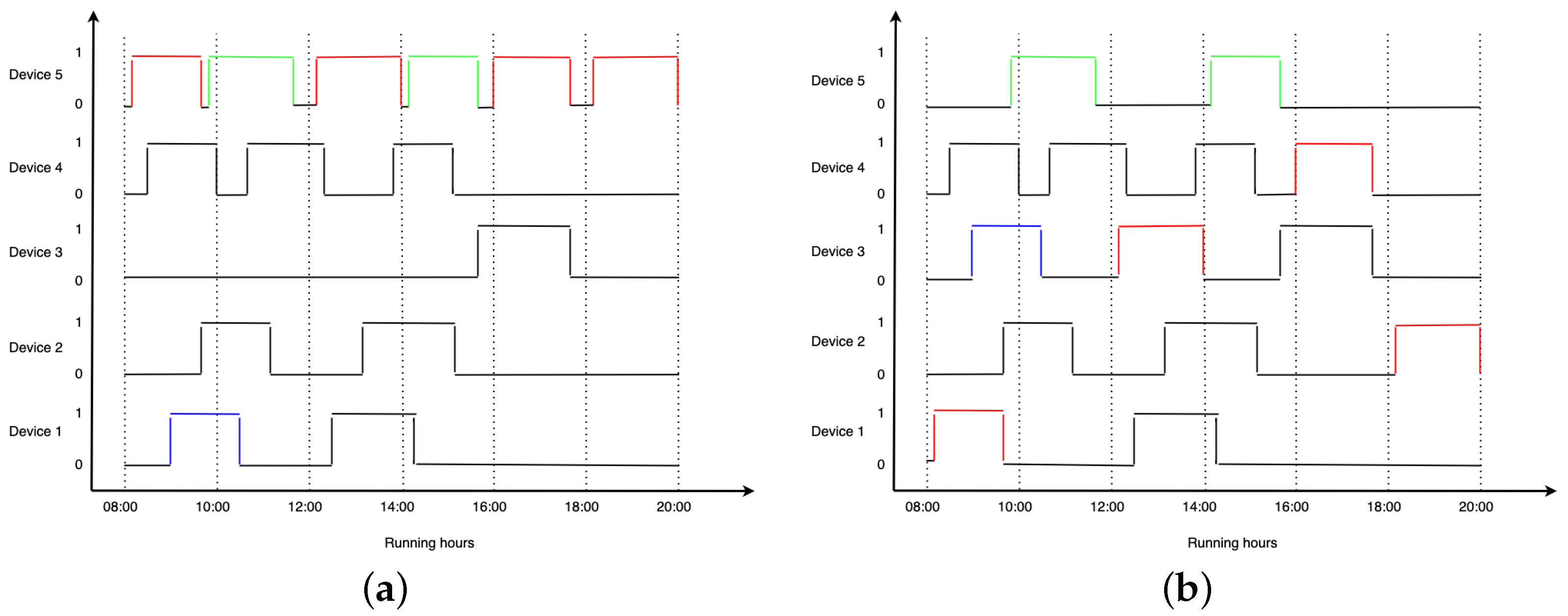
Our system’s devices are designed to function in cycles. One cycle is defined by the beginning of a task, its running (with the purpose of solving the task), and its stopping. For example, in the case of washing machines, the task is to clean the clothes. In [
37], a method for detecting cycles from raw data recorded from devices with running patterns similar to the ones described above is introduced.
Based on the status of the devices, if the beginning of a cycle is detected, the running status information is updated to notify that the machine is currently busy. If the end of a cycle is detected, the current run time of the device is updated in the cloud, and the information regarding the new status of the device is sent.
The flow diagram of the data acquisition module is presented in
Figure 2.
Forecasting module. The forecasting module uses historical data stored in the cloud system to forecast the usage of washing devices. We are allocating cloud computing resources to the forecasting task so that the overall timing constraints of the smart devices remain intact. The forecasting module returns a list of the predicted values per device for a given period of time. Based on the predicted usage, the devices with the highest demand are identified and, therefore, not considered for the suggested list of recommended devices in case enough devices are available.
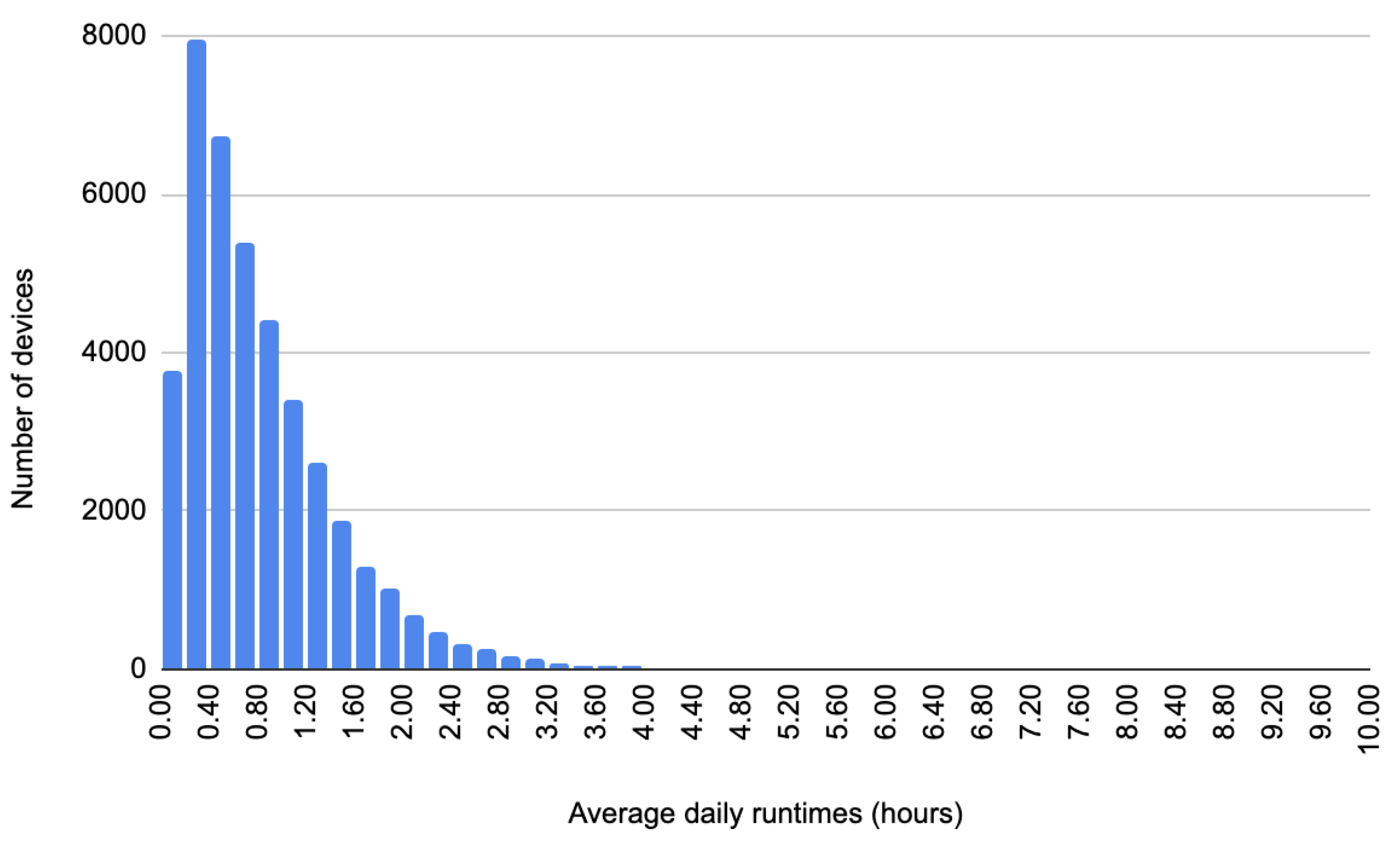
The granularity level refers to the time interval for which we are performing the prediction. For example, a granularity of a day means the system will predict the daily usage of the devices. This implies that the forecasting task should be a periodic task that runs daily. Smaller granularities, such as a couple of hours, could be used for a more adequate prediction. Our system can be easily configured to select the granularity of the prediction.
Our problem is similar to task scheduling, which is an NP-hard problem. Data-driven approaches offer better solutions when qualitative and quantitative data are available. Machine learning models can outperform traditional statistical methods and are well-suited for handling large volumes of data. Therefore, our proposed method uses machine learning algorithms for forecasting.
Real-time recommendation module. The purpose of selection is to reduce the usage of the devices that are used the most so that resources can be allocated better. The real-time recommendation module uses the devices’ real-time data status and forecasted usage to suggest a list of possible laundries to be used.
This module uses two different customizable parameters:
represents the maximum load a machine allows. It is a parameter set depending on the number of machines and overall system usage.
represents the targeted minimum number of machines recommended for the user of the system at a given moment of time. The user should select it according to the possibility of movement and could incorporate the distance from a suggested location (not yet incorporated).
This module uses the implementation of two algorithms presented in the next session to select the suggested machines list. Only the running status of devices is used in this module to minimize the real-time module’s computational cost. The forecasting data are already computed on the previous layer.
3.3. Algorithmic Method for Smart Real-Time Recommendations of Machines
Algorithm 1 illustrates the construction of the list with the devices for which we want to reduce the usage. A better load balancing between machines can be achieved by implementing a penalization method and recommending the devices that tend to be overutilized. The algorithm’s output is a list ordered ascending based on the forecasted usage data. Only the devices that, according to forecasting, will be used over a given threshold will be included in this list.
| Algorithm 1: GetPenalizedDevices: Determination of the list of the devices with high forecasted usage. |
![Sensors 24 02159 i001]() |
The output list of the algorithm is initially empty in step 1. The algorithm takes all the devices from the system. In steps corresponding to lines 3 and 4 of the algorithm, the output list is constructed only by those devices with the forecasted value over the given parameter. In order to reduce the load of the most used forecasted one, the list is sorted in ascending manner based on the forecasted values of the devices in step 5. Therefore, the devices that are forecasted to be used the most will be suggested the least and will appear in the suggestion list only if there are not enough devices available.
Algorithm 2 is used to construct and return the recommendation list of the devices to be used. At the beginning of the algorithm, the output list is initialized with the empty list. In line 2, our proposed algorithm takes the list of the devices with high forecasted usage by calling Algorithm 1. Further on, it creates a list of recommended devices from all the devices that are not currently running and are not on the penalization list. The running status information data come from the preprocessed real-time data (output of the data acquisition module).
The algorithm aims to create a list of lengths of at least of the best-suited machines. After step 5, the list will be returned if we have already achieved the goal. Otherwise, in steps 7–10, the algorithm will add devices that are not currently running from the penalization list (output of Algorithm 1). If we achieve the needed device list length or there are no more devices in the penalization list, we will end the algorithm and return the recommended devices list.
Algorithm 2 uses the current time for the suggested list. If a list of potentially free devices in a time interval is preferred, a slight modification of Algorithm 2 is required. A new parameter should be added, representing the time the system user would arrive at the possible locations. At this point, the information about the device’s current running status is insufficient to determine if the device will still be busy after the time. To overcome this, the expected number of minutes in which the machine will finish its running cycle must be computed in the data acquisition module. The running status conditions from lines 4 and 9 from Algorithm 2 should be changed from to or .
By updating the recommended list based on the current status of the devices and by adding last to the list OF the devices that are forecasted to be used the most (only if there are not enough available devices with a small predicted load), the overall load of the most used centers will be reduced. Moreover, using our proposed algorithm leads to a reduction in the waiting time because only the free devices will be visible.
| Algorithm 2: GetRecommendedDevices: Determination of the list of the recommended devices to be used. |
![Sensors 24 02159 i002]() |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}