1. Introduction
Among communities and agencies working to characterize and prioritize local environmental risks, there is an increasing call for addressing risks cumulatively by considering the influence of multiple chemical and non-chemical stressors on health outcomes [
1,
2]. From the perspective of environmental decision-making, this has been proposed to involve an understanding of the risks of chemical stressors in the presence of non-chemical stressors that act as effect modifiers or contribute to background processes [
2,
3].
One of the significant challenges that arises within cumulative risk assessment involves the need to simultaneously model exposures to chemical and non-chemical stressors in a manner that takes account of common predictors and root causes, as key demographic and structural factors are rarely formally evaluated. Cumulative risk assessment is also often hampered by a lack of epidemiological or toxicological information allowing for realistic evaluation of the influence of non-chemical stressors on health risks from chemical stressors.
Radon provides an ideal case example to explore methods for conducting cumulative risk assessments, due to the multiple factors that determine levels of radon risk. First, there is evidence that current and former smokers have a higher unit risk for lung cancer per unit of radon exposure than non-smokers, indicating that joint consideration of radon and smoking patterns would be informative in characterizing the distribution of lung cancer risk from radon [
4,
5]. While smoking clearly includes numerous chemicals, in the context of cumulative risk assessment, we consider it as a non-chemical stressor or “lifestyle factor” to differentiate it from those chemicals under the jurisdiction of the United States Environmental Protection Agency (EPA) [
2,
3]. Similar studies conducted internationally have reported added value to community risk reduction efforts from joint consideration of radon concentrations and smoking [
6]. Second, the attributable risk from radon is large enough that more refined information on radon concentrations, exposures, and risk would be warranted in many decision contexts. Although different risk models and uncertainty analyses employed over the years have produced a wide range of potential risk estimates attributable to radon, all results point to radon as one of the most widespread environmental hazards requiring public health monitoring and management [
4,
5,
7–
11]. Radon is the leading cause of lung cancer deaths in non-smokers, and the second leading cause of lung cancer deaths in smokers [
7]. The EPA has estimated approximately 20,000 lung cancer cases attributable to radon annually in the U.S., with an average lifetime risk of fatal lung cancer of 0.73% in the U.S. general population based on the national average concentration of 1.25 pCi/L [
7]. However, having only national-scale risk estimates available can cause radon to be underappreciated in community-based risk prioritization. Radon zone maps have been developed and are readily available, but these zone maps reflect radon concentrations rather than attributable risk, and communities in an area with low or moderate radon potential may discount radon even if its risks may exceed those associated with issues of higher current visibility.
Third, both residential radon concentrations and smoking prevalence are highly variable across different locations and different populations in the U.S. Previous studies have examined each separately, but with some key limitations, and no study has jointly evaluated the demographic and geographic patterning of variables associated with radon and smoking and the subsequent patterning of radon risk.
More specifically, the distribution of residential radon concentrations across the U.S. has been the subject of numerous studies for the past several decades, and is related to both geological and housing characteristics. Radon originates from radium in underlying bedrock, the composition of which is determined by rock type and origin. Radon travels through soil and infiltrates built structures through cracks, cavities and construction joints [
12]. Soil type, texture, moisture and permeability affect the movement of radon gas, in combination with climate and meteorology [
13,
14]. One of the primary drivers of the movement of radon from the soil into the indoor environment is pressure gradients, which can be caused by temperature differences, wind, and building heating or ventilation [
15–
17].
Due to the complex interplay of the factors described above and the lack of data on soil permeability to gas, it can be challenging to model radon concentrations, and previous investigations have had some limitations. The U.S. Geological Survey assigned a radon potential score by geological province based on expert evaluation of available geological and soil surveys, but could not capture local variability in soil and housing factors due to lack of local data on these factors [
18]. The U.S. EPA added to the above score by incorporating measured concentrations and architecture information from state residential radon surveys to produce a national zone map of estimated radon levels by county [
19]. However, state databases are of varying quality and present considerable challenges for developing nationally-consistent radon concentration estimates; in addition, they are largely based on short-term screening measurements which are limited for providing the long-term estimates needed to determine lung cancer risk. Long-term measurements are available in a limited number of state surveys, but are most well-represented nationally in the National Residential Radon Survey (NRRS) [
20]. A study using measurements from the NRRS estimated median long-term residential radon concentrations by county, but cautioned that variability within a county could be significant and did not include information necessary to link with smoking data [
21]. While numerous studies such as the above have reported limited predictive power in modeling radon concentrations [
22–
27], especially given the high level of variability and lack of sufficient local data, an approach that characterizes demographic and geographic patterns in a manner that allows for linkages with smoking models has promise for providing screening-level cumulative risk estimates.
For smoking, there are similar limitations in the prior literature in terms of comprehensively incorporating geographic and demographic variability. Smoking statistics are available at a national and state level, and local data are available in some communities but are not systematically collected and reported across the U.S. Variability in smoking has been related to compositional factors (individual demographic characteristics and socioeconomic indicators) and contextual factors (neighborhood characteristics, local and state legislation) [
28–
31]. These previous studies have quantified the association between smoking and compositional and contextual factors across different populations and places, but no studies have provided models with sufficient geographic and demographic stratification and coverage to allow for a refined examination of lung cancer risks from residential radon exposure in the U.S.
Despite the challenges of jointly modeling exposures to radon and smoking, community groups have repeatedly asked for assessments that take account of significant non-chemical/lifestyle stressors, and the smoking and radon interaction is one of the best understood and tractable interactions [
2,
32]. While no model can eliminate the need for radon measurements in each home, especially given the high risks from radon, a joint exposure assessment and model of radon-related health risks given smoking patterns can provide screening-level estimates for community groups and individuals in understanding the relative importance of radon in their communities,
versus other issues of environmental concern. In this study, we develop a systematic approach to model both radon and smoking at high spatial and demographic resolution across the U.S., linking multiple national databases and capturing common predictors using a multilevel modeling framework [
33]. We construct a multilevel regression model predicting radon concentrations using only sociodemographic and geographic covariates that can be included in a multilevel regression model predicting smoking, in order to link the two in a community-scale risk assessment of radon in the presence of smoking. We use predictors which are available across the U.S. from the Census, and leverage components of the EPA national risk assessment to develop a framework to provide communities and decision-makers with more refined estimates of lung cancer risk from residential radon exposure.
2. Experimental Section
2.1. Conceptual Framework
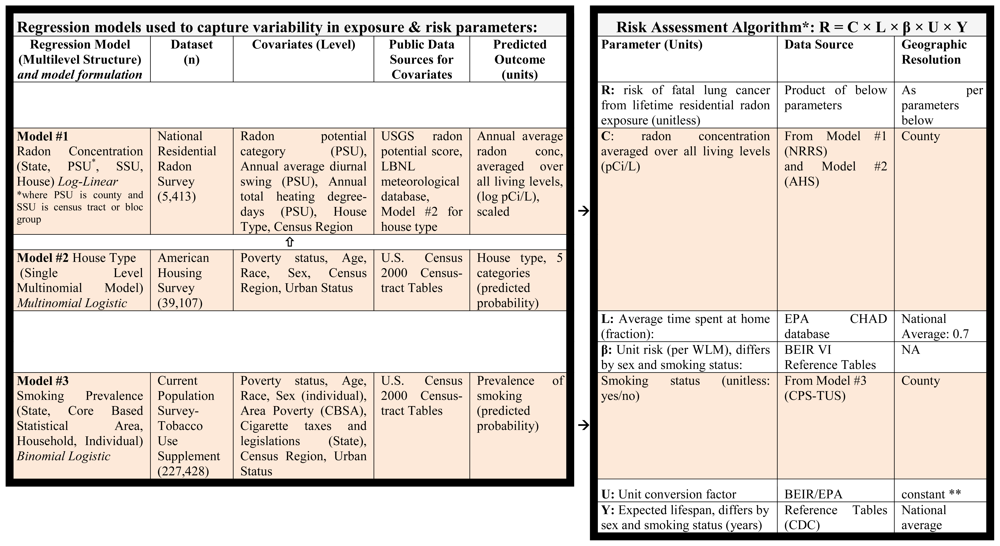
To capture variability in parameters affecting radon risk, we built three statistical regression models using three national datasets described below. The first model provides estimates of residential radon concentrations based on locational information and house type; the second model provides estimates of house type based on occupants’ sociodemographic characteristics, and the third model provides estimates of individual smoking status based on the same sociodemographic characteristics. Together, these regression models provide estimates for the association of sociodemographic and geographic variables with radon concentrations and smoking prevalence (
Table 1). Of note, each of the three models is constructed at either the housing unit or individual level, allowing us to subsequently combine parameter estimates from the three models to produce radon exposure estimates and smoking prevalence estimates for any location (e.g., county or census tract) based on its geography and composition.
As individual-level multivariate sociodemographic and geographic data are not nationally available, we instead calculate exposures and risks for subpopulation groups at high geographic resolution, which can then be aggregated to provide patterns of population health risk. The U.S. Census provides cross-tabulated data on the number of people by age, sex, race, and poverty status, at levels of geographic resolution down to the census tract (small statistical subdivisions of a county, usually containing between 2,500–8,000 persons) [
34]. Census tracts are therefore relatively small geographic entities with sufficient population size to yield cross-tabulated demographics, and were also designed to be homogeneous with respect to population characteristics, economic status, and living conditions. Within the present analysis, we present all exposure and risk calculations at county resolution for ease of presentation and proof of concept, but our individual-based analysis plan can ultimately provide smoking and radon concentration estimates at higher resolution, albeit with increased uncertainty.
2.2. Radon Concentration Model
We developed our radon model from the NRRS, during which long-term measurements of radon concentration were taken in all living levels of a nationally representative sample of homes from 1989–1990 [
21]. While somewhat outdated with respect to current housing stock, it represents the most robust and geographically representative data set publicly available. Information on housing characteristics collected in the NRRS was combined with data from the USGS and soil surveys based on the location of each home, which was then discarded for confidentiality reasons [
35]. We developed a log-linear model to quantify associations at the household level between geological and meteorological variables, housing characteristics, and annual average radon concentrations averaged over all living levels. Radon concentrations were scaled to adjust negative measurements recorded by the survey instruments to match minimal outdoor radon concentrations based on methods previously published by Price
et al. [
21]. Analysis was conducted using MLwiN 2.16 [
36].
To account for the geographic clustering of samples in the NRRS we built a four-level model of housing units (n = 5,336) nested within secondary sampling units (SSU, n = 977) nested within primary sampling units (PSU, n = 125) nested within states (n = 44). Indicator variables were used to represent Census Region. In the survey primary sampling units corresponded to one or more counties, and secondary sampling units corresponded to census tracts or parts of census tracts within the sampled counties.
We selected potential covariates based on results of previous statistical analysis of the NRRS data [
37]. At the county level, we included meteorological variables from a national meteorological database [
38]. Alaska and Hawaii were excluded from the analysis because complete data were not available for these states within the databases most appropriate for this assessment. Geological variables (soil texture, permeability, underlying bedrock, equivalent uranium) were evaluated both separately and using a summary score of geological radon potential provided by the USGS [
39]. The USGS score was provided within geological province boundaries; we assigned a score to each county based on the geological province in which the county is located, and for those counties located at the intersection of more than one geological province we assigned the score of the province which covered the largest area of the county.
At the household level, while numerous home characteristics would theoretically be linked with residential radon levels, our model structure (
Table 1) necessitated that we restrict potential covariates to those available in the American Housing Survey (AHS) [
40]. The AHS is the primary source of data for the U.S. housing stock and would allow for linkages with geographic and sociodemographic predictors of interest. We tested for statistically significant associations between housing variables and log radon concentrations in univariate and multivariable models, and performed chi-square tests to measure correlations between the housing variables. We then assessed the predictive power of different housing variables by comparing the reduction in variance at the state, PSU, and SSU levels in different models, as well as overall fit using log-likelihood ratio tests.
2.3. Housing Model
In order to apply the radon concentration model across the U.S. in a manner relevant to cumulative risk assessment, we needed to link housing characteristics predictive of residential radon with sociodemographic and geographic data available in all locations. We developed a multinomial logistic regression model to quantify associations between housing type for individual homes and publicly available sociodemographic and geographic covariates from the U.S. Census. As a result of the model-building described above, housing type was divided into five mutually exclusive categories: single detached unit with basement; single detached unit with crawl-space; single detached unit with slab-on-grade; other single detached unit; and all other units (which include attached units and mobile homes). Analysis was conducted using SAS 9.2 (SAS Institute Inc., NC, USA). Because the dependent variable has the same value for all individuals nested within a household, a multilevel model is not possible, thus the clustering of individuals within households is not accounted for in our model. State and county identifiers were not provided in the AHS dataset; metropolitan statistical area was identified for less than half of the houses and was thus not included in our analysis. Therefore Census Region was the only geographic covariate.
2.4. Smoking Model
We used a multilevel logistic modeling approach to develop predictors of smoking, using individual-level data from the 2006–2007 Current Population Survey-Tobacco Use Supplement (CPS-TUS). This approach has been described in detail elsewhere [
41]. For the purposes of the current study, the binomial outcome modeled was ever-smoking rather than current smoking only, as the unit risk for lung cancer from radon exposure differs for non-smokers compared to ever-smokers (which includes former and current smokers). Covariates were: individual-level variables that would be available from Census cross-tabulations (age, sex, poverty, race), area poverty at the CBSA (core-based statistical area) level, and tax laws and legislation at the state level. Analysis was conducted in MLwiN 2.16.
2.5. Exposure and Risk Estimates
Census 2000 Summary File 3 tables were obtained to provide the number of people in each sociodemographic bin (as defined by age, sex, race, and poverty status) in each county in the U.S. Because our smoking model was based on an adult study population, we included only individuals aged 18 and above in the risk calculations.
To estimate radon risk, we first determined the predicted probability of ever-smoking for all of the individuals in each sociodemographic bin in each county by summing fixed effects of age, sex, race, poverty status, CBSA poverty, state tax, state legislation, and previous state smoking prevalence, in addition to state and CBSA residuals. Subpopulations with Black race were also assigned state-specific effect estimates for race. One hundred and eighty CBSAs were not included in the CPS sample, and only state residuals were applied for these. Second, the predicted probability of each housing type was calculated for all individuals in each bin based on the housing model by summing fixed effects of age, sex, race, poverty status, and Census Region. Third, for each housing type, the predicted radon concentration was calculated for all individuals in each bin by summing fixed effects of age, sex, race, poverty status, county meteorological variables, radon geological potential score, and state residuals (as well as county residuals for the 125 counties that were included in the NRRS sample). Five states were not included in the NRRS sample and were assigned zero residuals. Thus, we obtained estimates of the prevalence (predicted probability) of ever-smokers and of the five different housing types and corresponding radon concentrations for each sociodemographic bin in each county.
Based on this information, we estimated the population average risk associated with radon exposures for each county, following the EPA risk assessment algorithm (
Table 1) and assuming (lacking evidence to the contrary) that there is no differential distribution of non-smokers and current/former smokers among the different housing types within each geographic and demographic subpopulation. We applied an exposure rate of 0.144 working level months (WLM) per year for each pCi/L of radon gas, assuming that on average people spend about 70% of their time indoors at home, and that the equilibrium fraction for radon progeny is 40% [
42]. WLM is the cumulative exposure measure used in the epidemiologic literature on uranium miners, from which the unit risk factors for lung cancer were derived. The central estimates for unit risk factors per WLM are 0.00106 and 0.000851 for male and female ever-smokers; 0.000174 and 0.000161 for male and female nonsmokers, respectively [
4]. Although debates have been published in the scientific literature concerning discrepancies between previous studies, there is largely a consensus on the unit risk factor established by the National Academies for indoor radon risk assessment [
5,
43,
44], supported by recent meta-analyses which found comparable unit risk factors among the general population as in the study of uranium miners [
45,
46]. These meta-analyses also indicated comparable odds ratios for radon among smokers and non-smokers, which would indicate a significantly greater unit risk factor for smokers given the higher baseline risk of lung cancer, consistent with our assumptions.
We note that there are appreciable uncertainties in these radon risk calculations, given uncertainty in the regression models for radon concentrations, home type, and smoking prevalence; uncertainty in the unit risk factors for radon and the extent to which effect modification by smoking occurs; and broad-based uncertainty related to the representativeness of the NRRS measurements, assumptions of a stationary population, and so forth. A comprehensive Monte Carlo analysis to characterize the magnitude of the uncertainties was not conducted because it was not considered informative in light of the complex multivariate structure of the regression models and the number of important factors that would elude quantification. Instead, following recent guidance to conduct uncertainty analyses that relate to the decision context and increase understanding about the problem under study [
1], we provide some quantitative and qualitative uncertainty information to determine whether our core conclusions are robust.
3. Results and Discussion
3.1. Radon Concentration Model
At the county level, the USGS summary score had higher statistical significance and improved the fit of the model more than the separate geological and soil covariates (as assessed using log-likelihood ratio tests). Annual heating infiltration degree days and average diurnal temperature difference were retained as meteorological variables (
Table 2).
At the house level, statistically significant variables which improved the fit of the model and were available in the AHS dataset were: type of unit (detached vs. attached), presence of basement, presence of central air conditioning, use of gas fuel for heating, use of steam or hot water distribution system for heating, number of gas appliances, and year built. However, chi-square tests showed multiple correlations between these housing variables, and the use of numerous housing variables complicates linkages with individual Census data. We fit a model containing a five-category house type variable (type of unit, basement) and it explained 85% of between-state variance, 51% of between-county variance, and 25% of between-census tract variance, compared to a model including all housing variables which explained 86% of between-state variance, 50% of between-county variance, and 29% of between-census tract variance. We therefore utilized the five-category house type variable in subsequent analyses. The reference groups for categorical variables in this model were detached homes with basements; Midwest geographic region; and Low Geological Potential.
Census Region was a statistically significant predictor (p = 0.005), although with no statistically significant differences among the South, West, and Midwest. All county-level and house-level covariates in the final model were significant, with the exception of the crawl-space indicator in the house type variable.
3.2. Housing Model
House types were significantly associated with Census Region, poverty status, age, and race. (No significant differences were observed by gender.) White subpopulations living above the poverty threshold in the Midwest had the highest odds of living in detached homes with basements compared to attached homes. Subpopulations with the lowest odds of living in detached homes with basements compared to attached homes were Black race, below poverty threshold, ages 25–34, living in the West. Parameter estimates for the housing model are presented in
Appendix I.
3.3. Smoking Model
The prevalence of ever-smokers in the CPS-TUS 06–07 was 38.6% (17.9% current smokers, 20.7% former smokers). Associations of sociodemographic variables with ever-smoking were comparable to the associations reported previously by the CDC using CPS-TUS data for current smoking prevalence, with a few exceptions [
47]. The inverted U-shaped association for age peaked at a higher age than in the model for current smoking prevalence. State legislation restricting smoking in public venues and percent poverty at the CBSA level were not significant predictors of ever-smoking and did not show the same directionality as for the previously published current-smoking model. State cigarette excise tax showed a significant negative association with ever-smoking; this association persisted after controlling for previous state smoking prevalence, and is therefore not likely due to endogeneity or reverse causation. Men showed higher odds of smoking than women, and this effect was modified by race. The variance of the random parameters at the state and CBSA levels were 0.005 and 0.040 respectively, compared to 0.004 and 0.013 in the previously published current smoking model, which was not constrained to covariates available for all subpopulations nationally. Parameter estimates for the smoking model are listed in
Appendix II.
3.4. Exposure and Risk Estimates
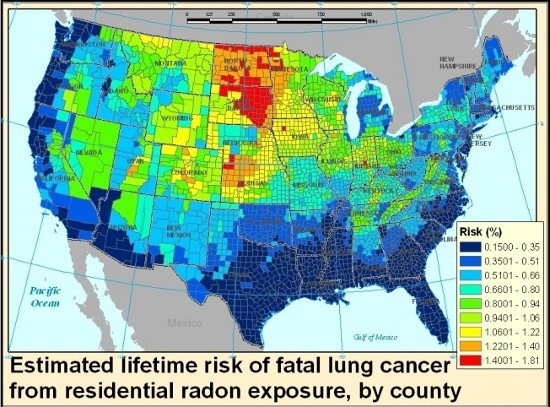
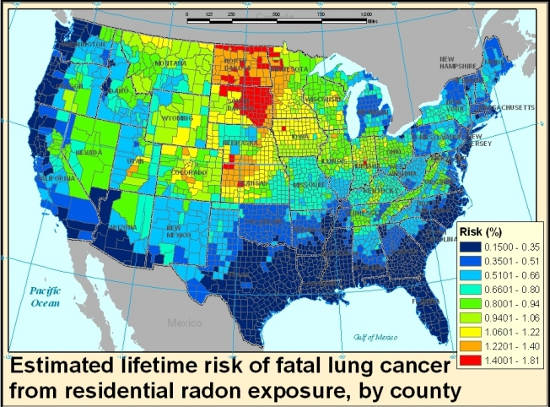
Central estimates for county average lifetime radon lung cancer risk estimates ranged from 0.15% to 1.8%, with a mean by county of 0.66% and a median of 0.64% (standard deviation = 0.3%), in agreement with the national average risk of 0.7% previously reported by the EPA [
7]. High-risk clusters were observed in the northern Midwest states, which had relatively high predicted levels of both radon and ever-smoking; South Dakota in particular shows a number of counties which contained among the highest estimated mean radon concentrations (
Figure 1a), and the same counties were also on the higher end of estimated ever-smoking prevalence (
Figure 1b). Two of the six counties nationwide which show predicted mean concentrations greater than 4 pCi/L were observed in Utah; however, because Utah has among the lowest smoking rates in the country, these counties did not emerge among the highest risk counties in the risk map (
Figure 1c). High-smoking clusters were predicted in selected states in the Midwest and Southeast, where radon concentrations were on the lower end, and therefore risk clusters did not emerge in these states. Missouri and Kentucky in particular were among the states with the highest predicted probability of ever-smokers, but had average radon risk levels. Coastal states had the lowest radon concentrations, and many of these were also below-average smoking states, therefore resulting in the lowest average population risk. The population-weighted average risk for the continental U.S. was lower than the above-mentioned mean county-level average of 0.66%, at 0.5% (
Appendix III), given low risk clusters in some heavily populated areas. Population-weighted national average values for radon concentration and ever-smoking prevalence were in agreement with previous results published by the EPA and CPS-TUS at 1.3 pCi/L and 38.6% respectively [
7,
47]. The lower national risk in our study relative to the EPA risk assessment may be attributable in part to correlations between radon and smoking in our dataset.
3.5. Patterns of Variability
The interplay between radon concentrations and smoking, and the demographically and geographically variable nature of both, results in a spatial distribution of radon-related lung cancer risk within a cumulative risk assessment framework that has not been captured in previous studies. Although there is considerable uncertainty in the estimates (see Section 3.6 below), the models represent previously-documented spatial patterns of each of the individual exposures, and help illustrate the influence of including smoking patterns on the estimated spatial variability of radon-related risk.
Comparing the radon risk map and concentration map shown in
Figure 1, the patterns follow a similar trend in many places but are far from identical. The shifting of patterns between the two maps can be illustrated by comparing areas with similar radon concentrations but different smoking patterns; for example, while Indiana does not stand out as a high radon area in the concentration map relative to Utah, its risk levels are higher due to the large difference in smoking prevalence between the two states. Comparing our risk map with previous screening maps such as the EPA map of radon zones, the overall patterns agree but nuances emerge within the highest potential zone, as illustrated by the high risk cluster in the northern Midwest. Whether this is a reflection of uncertainty in our models or the use of categorical rather than continuous outcomes in the EPA radon zone map would require further exploration.
The underlying Census sociodemographic data behind our risk map form a key factor which contributes directly to the smoking predictions through the strong association between compositional variables and smoking prevalence, and indirectly to the radon concentration predictions through the housing model component. For example, white men in the Midwest region have higher odds of living in detached single units with basements and have higher odds of smoking. When such individuals are located in counties with high geological radon potential and higher than average diurnal temperature swings and total infiltration heating degree days, their lung cancer risk from residential radon exposure will likely exceed the national average. On the other hand, multi-directionality in exposure and risk factors was also observed; for example, living below the poverty threshold was negatively associated with the presence of a basement, thus likely to have lower radon concentrations after controlling for location, while it was positively associated with probability of smoking. Cumulative risk assessments that capture the positive and negative correlations among chemical and non-chemical stressor exposures will provide a more nuanced characterization of individual and subpopulation health risks. Broadly, jointly examining the patterns of demographic and geographic predictors associated with radon and smoking allows for identifying the locations of clusters with the highest predicted probability of lung cancer from residential radon exposure given effect modification associated with smoking.
3.6. Uncertainty Characterization
As described above, given our application of multiple multivariate regression models and the presence of numerous uncertainties that cannot be readily quantified, formal propagation of uncertainty does not provide readily interpretable information. Given the context of our work, we are primarily concerned with whether any of the assumptions in our analysis could invalidate either the approach or the general spatial patterns presented in
Figure 1. With this perspective in mind, we evaluate key uncertainties both quantitatively and qualitatively below.
One of the key assumptions in our analysis is the unit risk factor for radon and the evidence for effect modification from smoking. In its assessment of risks from radon in the home, EPA conducted a Monte Carlo simulation to characterize uncertainty in the unit risk factor for lung cancer from radon, though with the caveat that many factors were omitted [
7]. The resulting estimates for risk per WLM had a median estimate of 0.00098 with a 90% uncertainty interval of 0.0004–0.0020 for ever-smokers; and a median estimate of 0.00054 for the general population (including ever-smokers and never-smokers) with a 90% uncertainty interval of 0.0002–0.0012. This suggests that the unit risk factors are accurate within a factor of 2–3, albeit with many significant uncertainties omitted. If applied across the board, this would influence the magnitude of our risk estimates but not the patterns.
A more significant question from the perspective of our analysis is whether effect modification due to smoking is robust, as the omission of this factor would imply that the patterns of radon-related lung cancer risk would closely resemble concentration patterns (and obviate the need to account for smoking patterns). While this is clearly uncertain, we note that the effect modification is submultiplicative, with a higher odds ratio for never-smokers than ever-smokers. The large difference in risk per WLM is largely attributable to the much higher baseline risk of lung cancer among smokers, an assumption with little uncertainty. Thus, unless the odds ratio of lung cancer from radon were an order of magnitude lower for ever-smokers than never-smokers, which seems unlikely, the risk per WLM would remain higher for ever-smokers and our general conclusions about the importance of accounting for smoking would remain robust [
4,
48,
49].
Going beyond risk per WLM, while EPA reported that the uncertainty in the exposure parameters (radon concentration, decay rate, time spent at home) are minor compared to uncertainty in the unit risk factor [
7], in our study the reverse is likely to be the case. Because we rely on three linked regression models to capture variability in radon exposure and smoking prevalence, it is not only the magnitude of risk that is subject to considerable uncertainties, but also the patterns of risk variability which our models capture. However, quantifying uncertainty across these models would be technically challenging, given the need for information on the covariance among the parameter estimates and across the regression models, and would omit many key factors. We instead discuss important uncertainties that go beyond the standard errors reported in our three regression models.
For example, while the sociodemographic data employed in our model captures variability in housing types and smoking patterns with respect to the national average, many factors remain which influence these outcomes and which were not included as predictors in our models, given a lack of available cross-tabulated data. These include other socioeconomic indicators (for example education, occupation, immigrant status, marital status) as well as contextual factors (for example local variations in construction patterns and smoking restrictions). Additionally, it is important to note that our risk model implicitly assumes that lifetime radon exposures are correlated with predictions based on the current residential location. The migration of individuals and populations from one part of the country to another would clearly complicate radon exposure models and would tend to blur the association between current location and risk.
Our models have a number of additional uncertainties and should be considered for illustrative or screening purposes only. As in any statistical regression, statistical inferences are drawn about the true population distribution based on a limited number of samples. The NRRS is nationally representative but included samples from only 125 counties and does not capture housing structures built within the past 20 years. Although the radon concentration model benefited from a multilevel structure in which state and county effects were drawn from a random distribution, random parameter variance was not fully captured by the available data. Thus there remain unexplained state and county effects, and some high radon concentration counties were not captured, such as those in eastern Pennsylvania and northwestern New Jersey. Another limitation is that the housing model did not benefit from a multilevel structure because of the nature of the outcome variable, which is the same for all individuals in a household. Among the predictors of the housing model, poverty status is the most relevant for interpretation because it is a shared household characteristic (although measured as individual level variables in this dataset). On the other hand, sex and age and race are individual characteristics, and the nesting of individuals within households was not accounted for due to the lack of multilevel structure. A further weakness of the housing model was lack of higher levels such as county, metropolitan statistical area, or state, which were not included due to limited geographic identifiers in the AHS. Finally, our models were limited by the lack of contemporaneous data across models; the NRRS measurements were collected in 1989–1990, and the unit risk coefficient used in our risk estimates was developed by EPA based on 1990 mortality rates and smoking prevalence, but we aimed to develop a predictive model keyed on demographic data from 2000 and smoking patterns from 2006–2007. This contributes some uncertainty to our risk estimates, though the broad-based demographic and geographic patterns of smokers and housing characteristics are relatively stable over time.
While these uncertainties are significant, the general spatial patterns of radon concentrations and prevalence of ever-smokers in
Figure 1 are consistent with previous publications, indicating that we have reasonably captured the geographic areas with high/low radon and high/low ever-smoking prevalence. Similarly, the demographic and structural predictors are in agreement with previous models. Thus, the quantitative uncertainties are large for a given subpopulation within a given location, but our general conclusions about exposure variability and the importance of accounting for both radon and smoking are robust.
3.7. Lessons for Cumulative Risk Assessment
In spite of these limitations and appreciable uncertainties, our approach toward cumulative risk assessment offers some insights and lessons for future studies. First, in spite of the significant constraints in covariates available for our exposure models, given the need to rely on broadly available information common to radon and smoking models, we demonstrated predictive power similar to prior studies. Although radon is difficult to predict due to the local variation in soil factors for which no national-scale data are available, and our regression models used a more limited set of covariates than in previous investigations, our model was built on the only known national database of measured long-term radon concentrations in the U.S. and our radon concentration predictions compare well with previous estimates employing both long-term and short-term national and state datasets [
21]. Furthermore, the multinomial house type variable retained in our final model performed well when compared to multiple individual and often highly correlated housing variables. The covariates in our ever-smoking model explained a comparable amount of state and CBSA variance to previously published smoking models, despite being constrained to publicly available covariates only.
Because of this reasonable model performance, we were able to jointly estimate the geographic and sociodemographic patterns of both radon and smoking in a manner that allows for modeling of radon risk given the influence of a key non-chemical/lifestyle stressor, relying exclusively on publicly available data. In theory, one could use our models to also estimate the direct effects of smoking on lung cancer, allowing for a comparison between these stressors. While doing so could inform certain policy applications, it would go against the general principle that cumulative risk assessment should focus on decision-relevant analyses considering plausible alternative policies [
1], which would typically not involve agencies comparing radon mitigation and smoking cessation programs. Regardless, our work provides a template for a variety of applications relevant to different stakeholders and decision-makers.
This type of modeling could provide insight to communities seeking screening-level information on their radon exposure and risk, though further development and evaluation would clearly be warranted. In particular, although we presented county average estimates within this paper for ease of presentation, our focus on individual-level exposure prediction means that smaller geographic aggregates (such as census tracts) could be characterized in a computationally identical fashion. Though uncertainty would be increased for some steps in the analysis, there could be some improvements in the interpretability of our models (including for housing, where urban/rural status could be incorporated as a covariate). Future research can also improve the strength of these models by considering variability in other parameters affecting exposure and risk, such as time spent at home (which may also vary by age, sex, poverty, and race) and equilibrium fraction (which depends on factors such as particle size distributions in homes, in turn affected by smoking patterns). Model evaluation is also needed using measured long-term residential radon concentrations within selected geographic areas and demographic subpopulations, or through evaluation of lung cancer risk patterns among non-smokers. These and other local-scale validation activities could provide more meaningful insight about the magnitude of uncertainty in radon-related lung cancer risks than would be available strictly from propagation of parametric uncertainties.
Beyond the specific application to radon, our approach provides a first step in developing approaches for cumulative risk assessment at the community level. Other chemical and non-chemical stressors could be similarly evaluated, provided that there were large nationally representative data sets available (i.e., the National Health and Nutrition Examination Survey). A near-term effort could involve the incorporation of additional indoor air hazards within the cumulative lung cancer inhalation risk pathway, which would leverage the present work and provide a more comprehensive cumulative evaluation. To facilitate these and other cumulative risk assessments at high geographic resolution, we recommend that national survey bureaus make efforts to provide increased geographic identifiers in public use data files such as the AHS, subject to confidentiality constraints, given the importance of location in determining variability in population exposure and risks.





{kind=link}
{kind=link}
{kind=link}
