


IRONEDGE: Stream Processing Architecture for Edge Applications





Abstract
:1. Introduction
- Q1:
- “What are the common components/functions that an edge Stream Processing framework should have to be reusable?”
- Q2:
- “What should be the considered implementation for the referenced case study?”
- Q3:
- “What is the processing upper limit for the chosen implementation, while minimizing global loss of messages from IoT devices?”
- Section 2 discusses existing research work and provides the background on the considered technologies;
- Section 3 presents the proposed architectural approach and technological alternatives;
- Section 4 describes the testing environment and methodology;
- Section 5 presents and discusses the obtained results, as well as points out future work directions.
2. Background and Related Work
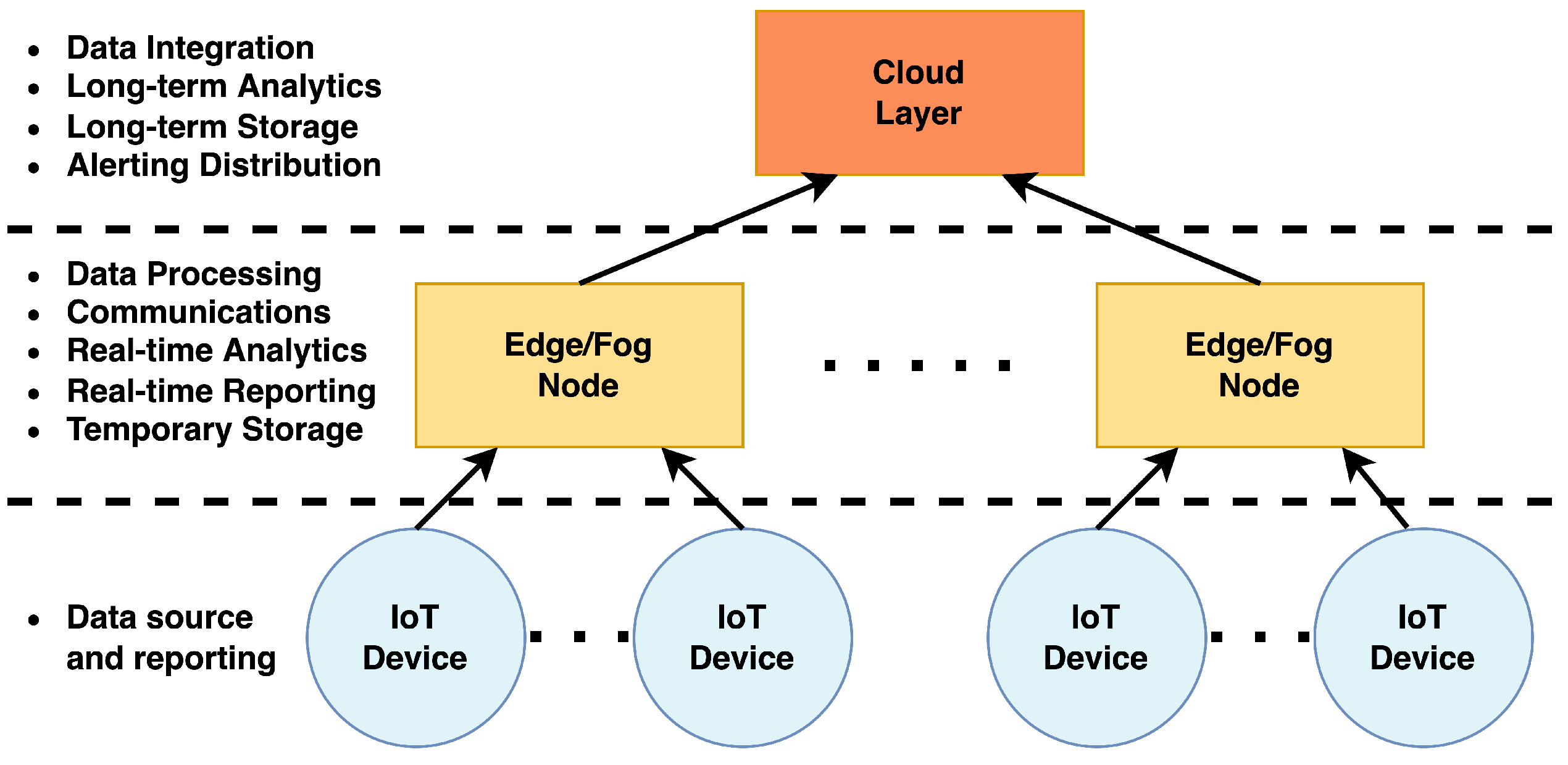
2.1. IoT and Edge Computing for “Smart Infrastructure”
- (1)
- Water distribution infrastructure (“Smart Water”);
- (2)
- Electricity distribution infrastructure (“Smart Energy”);
- (3)
- Transportation infrastructure (“Smart Transportation”);
- (4)
- Telecommunication infrastructure (“Smart Communications”).
2.2. Stream Processing
2.3. Asynchronous Messaging Middleware
- (1)
- Not all components need to be available at the same time. If a component is unavailable, it may consume the message at a later date;
- (2)
- They offer a queuing service to handle temporary bursts of messages or may drop messages above a set threshold;
- (3)
- Differing delivery guaranties, depending on the implementation details.
2.4. Related Work
3. Proposed Architectural Framework
- (1)
- The capability to collect data from Data Sources, the Data Collection;
- (2)
- The capability to execute processing over the collected data, the Stream Processing;
- (3)
- The capability to store some local state, the Local Storage;
- (4)
- The capability to replicate obtained results, an Event Output;
- (5)
- The previous capabilities are supported by an interconnecting layer allowing for message passing between components, an Asynchronous Messaging Middleware.
3.1. Generic Pipeline for Stream Processing
- (1)
- Input Stage—Read data from the Data Collection component, with no transformations applied. Messages should be tagged with the current timestamp;
- (2)
- Mapping Stage—Data Reports are parsed and mapped into a use-case-specific Data Model, a Data Point. Additional context may be fetched from the Local Storage;
- (3)
- Windowing Stage—Data Points are grouped by common characteristics in the use case (e.g., time intervals, geographic area);
- (4)
- Aggregation Stage—The created groupings are aggregated into a data aggregate;
- (5)
- Predictive Stage—Given a data aggregate, a use-case-specific predictive model is applied, which allows the detection and classification of Events. Additional parameters may be fetched or stored in the Local Storage;
- (6)
- Output Stage—The resulting Events are output into the Event Output component.
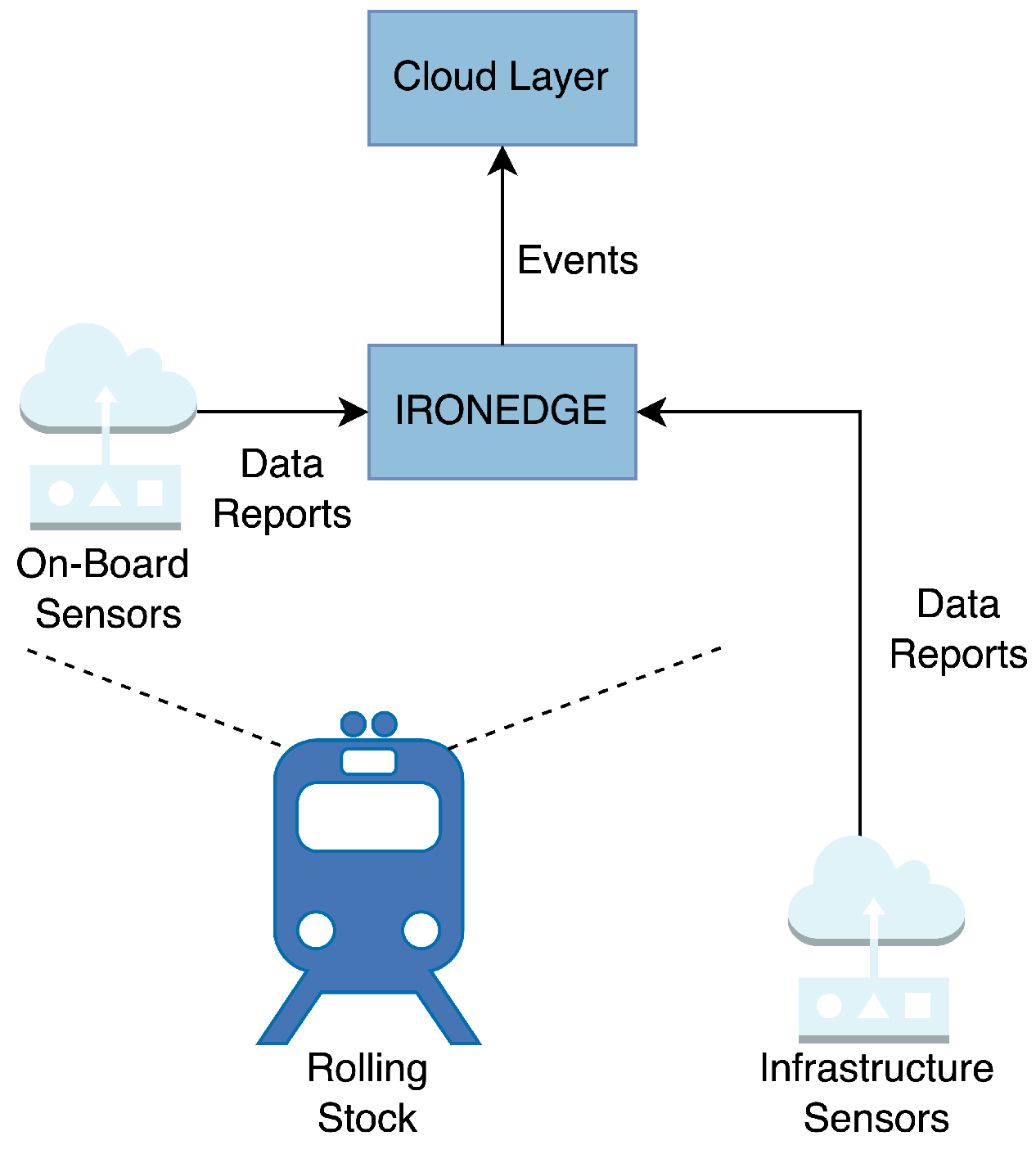
3.2. Case Study of the Ferrovia 4.0 Project
- (1)
- Limited resources—There will be limited mounting space and energy supplied to the node. Care must be taken to minimize these aspects, resulting in predictably low computational and storage resources. Each edge node must be able to process all data collected from the set of IoT devices in the assigned rolling stock, or railway section. It is not that data from each sensor may not be offloaded to a different edge node then the one that was initially assigned;
- (2)
- Infrequent connectivity—The rolling stock will not have network connectivity over an entire voyage; in particular, there may only be connectivity close to each station or smaller sections of the voyage.
3.2.1. Apache Kafka for Messaging and Storage
3.2.2. Distributing Data Reports and Events
- (1)
- K0-WC (with Connect)—This architecture continues the path of using existing integrations from the Kafka ecosystem by using Kafka Connect to read Data Reports from the MQTT broker and inject them into Apache Kafka (see Figure 5a);
- (2)
- K1-NC (without Connect)—As shown in Figure 5b, the architecture forgoes the closer integration for a more lightweight approach, requiring that each topology in Apache Storm consumes Data Reports directly from the MQTT broker.

3.2.3. Apache Storm
- (1)
- Input Stage—While following the same sequence, K0-WC uses a KafkaSpout to access the Apache Kafka broker and K1-NC uses an MqttSpout to access the MQTT broker. For K1-NC, the read-time timestamp is inserted. For K0-WC, the write-time is obtained from the Apache Kafka topic;
- (2)
- Mapping Stage—A generic Bolt converts Data Reports into Data Points, associating the MQTT/Kafka topic with the Data Model;
- (3)
- Windowing and Aggregation Stages—These two stages are implemented as a single Bolt, aWindowedAggregator. The Data Points are grouped in a rolling window by time interval, using the injected timestamps. As a default value, a windowing value of 5 s was selected;
- (4)
- Predictive Stage—During the initial development phase of the project, with domain knowledge still being gathered, a more simple approach, the CUSUM [43,44] method, was selected, to detect changes in accelerator data. This corresponds to the implementation of a CusumBolt. Initially, Events are always transmitted, even when no change is detected, with the current state of the aggregation;
- (5)
- Output Stage—For both variations, a KafkaBolt is implemented to inject Events into Apache Kafka topics marked for distribution by Kafka Mirrormaker v2.
3.2.4. Orchestrator and Resource Monitoring
4. Testing Methodology
4.1. Dataset
4.2. Metrics
4.2.1. Latency
4.2.2. Actual Throughput
4.2.3. Loss Rates
4.2.4. Memory Utilization
4.2.5. CPU Utilization
4.2.6. Log Time
4.3. Testing Conditions
5. Results and Comparison
5.1. Resource Usage
5.2. Loss Rates and Latency
5.3. Actual Throughput and Log Time
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AMM | Asynchronous Messaging Middleware |
| CPU | Central Processing Unit |
| IoT | Internet of Things |
| MQTT | MQ Telemetry Transport |
| K0-WC | Apache Kafka with Kafka Connect |
| K1-NC | Apache Kafka with No Kafka Connect |
References
- Friess, P.; Riemenschneider, R. IoT Ecosystems Implementing Smart Technologies to Drive Innovation for Future Growth and Development. In Digitising the Industry Internet of Things Connecting the Physical, Digital and VirtualWorlds; River Publishers: Aalborg, Denmark, 2022; pp. 5–13. [Google Scholar]
- Syafrudin, M.; Fitriyani, N.L.; Alfian, G.; Rhee, J. An Affordable Fast Early Warning System for Edge Computing in Assembly Line. Appl. Sci. 2019, 9, 84. [Google Scholar] [CrossRef] [Green Version]
- Kolajo, T.; Daramola, O.; Adebiyi, A. Big data stream analysis: A systematic literature review. J. Big Data 2019, 6, 1–30. [Google Scholar] [CrossRef]
- Aleksic, S. A survey on optical technologies for IoT, smart industry, and smart infrastructures. J. Sens. Actuator Netw. 2019, 8, 47. [Google Scholar] [CrossRef] [Green Version]
- Annaswamy, A.M.; Malekpour, A.R.; Baros, S. Emerging research topics in control for smart infrastructures. Annu. Rev. Control. 2016, 42, 259–270. [Google Scholar] [CrossRef] [Green Version]
- Ferrovia 4.0. A Smart, Sustainable and New Generation of Rail System. Available online: http://ferrovia40.pt/?lang=en (accessed on 10 December 2021).
- Abouaomar, A.; Cherkaoui, S.; Mlika, Z.; Kobbane, A. Resource provisioning in edge computing for latency-sensitive applications. IEEE Internet Things J. 2021, 8, 11088–11099. [Google Scholar] [CrossRef]
- de Assuncao, M.D.; da Silva Veith, A.; Buyya, R. Distributed data Stream Processing and edge computing: A survey on resource elasticity and future directions. J. Netw. Comput. Appl. 2018, 103, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Sajjad, H.P.; Danniswara, K.; Al-Shishtawy, A.; Vlassov, V. Spanedge: Towards unifying Stream Processing over central and near-the-edge data centers. In Proceedings of the 2016 IEEE/ACM Symposium on Edge Computing (SEC), Washington, DC, USA, 27–28 October 2016; pp. 168–178. [Google Scholar]
- Geldenhuys, M.K.; Will, J.; Pfister, B.J.; Haug, M.; Scharmann, A.; Thamsen, L. Dependable iot data Stream Processing for monitoring and control of urban infrastructures. In Proceedings of the 2021 IEEE International Conference on Cloud Engineering (IC2E), San Francisco, CA, USA, 4–8 October 2021; pp. 244–250. [Google Scholar]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Papageorgiou, A.; Poormohammady, E.; Cheng, B. Edge-computing-aware deployment of Stream Processing tasks based on topology-external information: Model, algorithms, and a storm-based prototype. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 27 June–2 July 2016; pp. 259–266. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog computing and its role in the internet of things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, Helsinki, Finland, 17 August 2012; pp. 13–16. [Google Scholar] [CrossRef]
- Andrade, H.C.; Gedik, B.; Turaga, D.S. Fundamentals of Stream Processing: Application Design, Systems, and Analytics; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Apache Storm. Available online: https://storm.apache.org/ (accessed on 10 December 2021).
- Toshniwal, A.; Taneja, S.; Shukla, A.; Ramasamy, K.; Patel, J.M.; Kulkarni, S.; Jackson, J.; Gade, K.; Fu, M.; Donham, J.; et al. Storm@twitter. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 147–156. [Google Scholar] [CrossRef]
- Apache Flink: Stateful Computations over Data Streams. Available online: https://flink.apache.org/ (accessed on 10 December 2021).
- Apache Spark- Unified Engine for Large-Scale Data Analytics. Available online: https://spark.apache.org/ (accessed on 10 December 2021).
- Bejeck, B. Kafka Streams in Action: Real-Time Apps and Microservices With the Kafka Streams API; Simon and Schuster: New York, NY, USA, 2018. [Google Scholar]
- Messaging That Just Works—RabbitMQ. Available online: https://www.rabbitmq.com/ (accessed on 10 December 2021).
- Apache Pulsar. Hello from Apache Pulsar. Available online: https://pulsar.apache.org/ (accessed on 10 December 2021).
- Apache Kafka. Available online: https://kafka.apache.org/ (accessed on 10 December 2021).
- Auradkar, A.; Botev, C.; Das, S.; De Maagd, D.; Feinberg, A.; Ganti, P.; Gao, L.; Ghosh, B.; Gopalakrishna, K.; Harris, B.; et al. Data infrastructure at LinkedIn. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1370–1381. [Google Scholar] [CrossRef]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A distributed messaging system for log processing. Proc. NetDB 2011, 11, 1–7. [Google Scholar]
- Narkhede, N.; Shapira, G.; Palino, T. Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Kleppmann, M. Designing Data-Intensive Applications: The Big Ideas behind Reliable, Scalable, and Maintainable Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- ksqlDB: The Database Purpose-Built for Stream Processing Applications. Available online: https://ksqldb.io/ (accessed on 10 December 2021).
- Bhogaraju, S.D.; Korupalli, V.R.K. Design of smart roads-a vision on indian smart infrastructure development. In Proceedings of the 2020 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bengaluru, India, 7–11 January 2020; pp. 773–778. [Google Scholar]
- Nammouchi, A.; Aupke, P.; Kassler, A.; Theocharis, A.; Raffa, V.; Di Felice, M. Integration of AI, IoT and Edge-Computing for Smart Microgrid Energy Management. In Proceedings of the 2021 IEEE International Conference on Environment and Electrical Engineering and 2021 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Bari, Italy, 7–10 September 2021; pp. 1–6. [Google Scholar]
- MQTT—The Standard for IoT Messaging. Available online: https://mqtt.org/ (accessed on 14 December 2021).
- Hidalgo, N.; Rosas, E.; Saavedra, T.; Morales, J. SLedge: Scheduling and Load Balancing for a Stream Processing EDGE Architecture. Appl. Sci. 2022, 12, 6474. [Google Scholar] [CrossRef]
- Kubernetes Documentation. Available online: https://kubernetes.io/docs/home/ (accessed on 22 December 2021).
- Javed, A.; Heljanko, K.; Buda, A.; Främling, K. CEFIoT: A fault-tolerant IoT architecture for edge and cloud. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 813–818. [Google Scholar] [CrossRef] [Green Version]
- Syafrudin, M.; Fitriyani, N.L.; Li, D.; Alfian, G.; Rhee, J.; Kang, Y.S. An Open Source-Based Real-Time Data Processing Architecture Framework for Manufacturing Sustainability. Sustainability 2017, 9, 2139. [Google Scholar] [CrossRef] [Green Version]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.L.; Rhee, J. Performance Analysis of IoT-Based Sensor, Big Data Processing, and Machine Learning Model for Real-Time Monitoring System in Automotive Manufacturing. Sensors 2018, 18, 2946. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gauttam, H.; Pattanaik, K.; Bhadauria, S.; Saxena, D.; Sapna. A cost aware topology formation scheme for latency sensitive applications in edge infrastructure-as-a-service paradigm. J. Netw. Comput. Appl. 2022, 199, 103303. [Google Scholar] [CrossRef]
- Hesse, G.; Matthies, C.; Uflacker, M. How fast can we insert? an empirical performance evaluation of apache kafka. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, 2–4 December 2020; pp. 641–648. [Google Scholar]
- Apache Kafka. Available online: https://kafka.apache.org/documentation/#connect (accessed on 10 December 2021).
- Apache Software Foundation. KIP-382: MirrorMaker 2.0-Apache Kafka. Available online: https://cwiki.apache.org/confluence/display/KAFKA/KIP-382%3A+MirrorMaker+2.0 (accessed on 19 December 2021).
- Grafana: The Open Observability Platform. Available online: https://grafana.com/ (accessed on 19 December 2021).
- Prometheus. Prometheus-Monitoring System & Time Series Database. Available online: https://prometheus.io/ (accessed on 19 December 2021).
- 6.3.2.3. Cusum Control Charts. Available online: https://www.itl.nist.gov/div898/handbook/pmc/section3/pmc323.htm (accessed on 19 December 2021).
- Zhang, M.; Li, X.; Wang, L. An adaptive outlier detection and processing approach towards time series sensor data. IEEE Access 2019, 7, 175192–175212. [Google Scholar] [CrossRef]
- Jain, S.; Pattanaik, K.K.; Verma, R.K.; Shukla, A. EDVWDD: Event-Driven Virtual Wheel-based Data Dissemination for Mobile Sink-Enabled Wireless Sensor Networks. J. Supercomput. 2021, 77, 11432–11457. [Google Scholar] [CrossRef]
- MicroK8s. Zero-Ops Kubernetes for Developers, Edge and IoT MicroK8s. Available online: http://microk8s.io (accessed on 19 December 2021).
- Böhm, S.; Wirtz, G. Profiling Lightweight Container Platforms: MicroK8s and K3s in Comparison to Kubernetes. In Proceedings of the 13th Central European Workshop on Services and their Composition (ZEUS), Bamberg, Germany, 25–26 February 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Local Orchestration | Edge | Stream Processing | AMM | Limited Computing | Intermittent Connectivity |
|---|---|---|---|---|---|---|
| Bhogaraju et al. [29] | No | Yes | No | No | No | No |
| Nammouchi et al. [30] | No | Yes | No | Yes (MQTT) | No | No |
| Hidalgo et al. [32] | Partially | Yes | Yes (Apache Storm) | No | Yes (Only latency. Offloads to mobile devices) | No |
| Geldenhuys et al. [10] | Yes | No (Adaptable) | Yes (Apache Flink) | Yes (MQTT/Apache Kafka) | Partially (only cluster) | Partially (only cluster) |
| Javed et al. [34] | Yes | Yes | No | Yes (Apache Kafka) | Partially (not evaluated) | Partially (not evaluated) |
| Syafrudin et al. [35] | No | No | Yes (Apache Storm) | Yes (Apache Kafka) | No | No |
| Syafrudin et al. [36] | No | No | Yes (Apache Storm) | Yes (Apache Kafka) | No (performance for cloud scenario) | No |
| Gauttam et al. [37] | No | Yes | No | No | Partially (only cluster) | Yes |
| Syafrudin et al. [2] | No | Yes | No | No | Partially | No |
| Resources | Details |
|---|---|
| CPU cores | 4 |
| Memory | 8 Gb |
| Storage | 128 Gb |
| Network | 1 Gpbs vNIC |
| Operating system | Ubuntu 20.04.3 LTS |
| Kernel | 5.4.0-99-generic |
| Parameters | Value | Default |
|---|---|---|
| Apache Storm | ||
| topology.stats.sample.rate | 0.001 | 1 |
| topology.producer.batch.size | 5000 | 1 |
| topology.executor.receive.buffer.size | 32,000 | 1 |
| Mosquitto | ||
| listener | 1883 | - |
| allow_anonymous | true | false |
| Apache Kafka | ||
| offsets.topic.replication.factor | 1 | 3 |
| transaction.state.log.replication.factor | 1 | 3 |
| transaction.state.log.min.isr | 1 | 2 |
| inter.broker.protocol.version | 3.1 | N.A |
| Kafka Mirrormaker v2 | ||
| offset.flush.timeout.ms | 20,000 | 5000 |
| producer.buffer.memory | 2,194,304 | 33,554,432 |
| max.request.size | 2,194,304 | 1,048,576 |
| batch.size | 524,288 | 16,384 |
| max.poll.records | 20,000 | 500 |
| config.namestorage.replication.factor | 3 | |
| offset.storage.replication.factor | 3 | |
| status.storage.replication.factor | 3 | |
| Kafka Connect | ||
| config.namestorage.replication.factor | 3 | |
| offset.storage.replication.factor | 3 | |
| status.storage.replication.factor | 3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vitorino, J.P.; Simão, J.; Datia, N.; Pato, M. IRONEDGE: Stream Processing Architecture for Edge Applications. Algorithms 2023, 16, 123. https://doi.org/10.3390/a16020123
Vitorino JP, Simão J, Datia N, Pato M. IRONEDGE: Stream Processing Architecture for Edge Applications. Algorithms. 2023; 16(2):123. https://doi.org/10.3390/a16020123
Chicago/Turabian StyleVitorino, João Pedro, José Simão, Nuno Datia, and Matilde Pato. 2023. "IRONEDGE: Stream Processing Architecture for Edge Applications" Algorithms 16, no. 2: 123. https://doi.org/10.3390/a16020123
APA StyleVitorino, J. P., Simão, J., Datia, N., & Pato, M. (2023). IRONEDGE: Stream Processing Architecture for Edge Applications. Algorithms, 16(2), 123. https://doi.org/10.3390/a16020123