1. Introduction
The exchanges of carbon dioxide and water vapor fluxes between the atmosphere and forest ecosystems are dominated by a variety of abiotic and biotic factors [
1,
2]. At present, a large body of available direct measurements of these fluxes as well as their related energy and environmental variables in forest stands using the eddy covariance method are being compiled, archived and distributed [
3]. In recent two decades, these measurements have been extensively utilized by the science community to explore the broad mechanisms controlling the dynamic variation of carbon and water fluxes from hourly to decadal time scales [
4,
5]. In addition, numerous efforts have focused on better quantifying and exploiting the magnitude and behavior involved in the interactions of carbon and water cycles [
6,
7]. Although remarkable advances have been obtained in our understanding of the nature and mechanisms leading to the ongoing evolution of carbon and water fluxes, their responses to different types of disturbances, such as land use changes, nutrient deposition, CO
2 elevation and fires [
8,
9,
10,
11] remain uncertain. In this context, accurate estimation of carbon and water fluxes of forest ecosystems is of particular importance for addressing the problems originated from global environmental change, and providing helpful information about carbon and water budgets for analyzing and diagnosing past and future climate change.
Process-based models that characterize complex biophysical and ecophysiological processes of land-atmosphere coupling at different temporal and spatial scales are commonly employed to quantify carbon and water budgets. According to several recent studies in relation to data-model inter-comparison of carbon and water fluxes, the evidence is convincing that appreciable errors do indeed exist between observed and estimated values by process-based models [
12,
13,
14]. More recently, data-model assimilation techniques have been proposed in order to reduce their predictive errors via assimilating high resolution multi-source remote sensing observations (e.g., surface temperature and soil moisture) into process-based models with various optimization algorithms, such as ensemble Kalman filter, three dimensional and four dimensional variational assimilation methods. However, these ecosystem models depend on a large number of constants and input variables, which are comparatively difficult to be acquired due to high heterogeneity over land surface [
15,
16]. It is therefore vital that much attention should be given to further enhance the estimates of carbon and water fluxes.
Generally, when addressing the improvement of the predictability of different issues in ecological, hydrological and environmental fields, one of the most important challenges that needs to be considered is the specific non-linear problems in the dynamically varying systems [
17,
18]. In the last decade, the use of data-driven techniques has become increasingly popular in abovementioned fields [
19,
20,
21], due to their ability to deal with nonlinearity in time series [
22,
23]. Among all data-driven techniques, artificial neural network (ANN) and support vector machine (SVM) have been broadly utilized [
24,
25,
26,
27,
28,
29,
30], aiming at a better understanding the underlying mechanisms that dominate the carbon and water fluxes, and representing the complex processes involved in the carbon and water exchanges. These studies have concentrated primarily on exploiting the relative contributions of the driving forces for the evolution of carbon and water fluxes [
24], interpolating the missing carbon and water data according to the flux tower measurements [
25], and quantifying the nonlinear processes of carbon and water interactions mainly at site scale [
26] and regional scale using the upscaling techniques [
27,
28]. In addition, these data-driven techniques are increasingly used to correct the carbon and water flux errors estimated by the process-based models [
29,
30].
With the recent advances in machine learning, many state-of-the-art data-driven techniques have been presented, mainly including group method of data handling (GMDH), generalized regression neural network (GRNN), adaptive neuro-fuzzy inference system (ANFIS) and extreme learning machine (ELM). The ability of these methods to perform with limited climatic inputs in terms of elucidating the complex processes of water vapor fluxes between land surface and the atmosphere, such as reference evapotranspiration (ET) and evaporation, has been adequately demonstrated by previous studies [
31,
32,
33]. Moreover, these methods are also widely used for regression analysis in many other fields, such as modeling of hydrological time series (e.g., stream-flow and rainfall) [
34,
35,
36], forecasting of renewable energy (e.g., solar radiation and wind power) [
37,
38], and modeling of meteorological time series (e.g., air temperature and precipitation) [
39,
40]. In contrast, comparatively few studies relevant to these methods have been carried out to map the actual ET and carbon fluxes, here including gross primary production (GPP), ecosystem respiration (
R) and net ecosystem exchange (NEE), in terrestrial ecosystems based on the data measured at the flux tower sites by the eddy covariance technique.
Despite the considerable technological efforts involved in addressing the aforementioned issues of carbon and water flux exchanges, however, relatively little work has been conducted to compare the ability of these traditional techniques (ANN and SVM). Moreover, with the increasing number of novel invented methods, the need for such a comprehensive comparison of conventional with advanced methods should to be more crucial. Namely, it can be considered as a helpful benchmark for ensuring the estimated accuracy of solving different issues by properly selecting an effective method from a variety of machine learning techniques. Therefore, the comparison of these methods, including ANN, SVM, GRNN, GMDH, ELM and ANFIS was carefully considered in this study.
Our major goal is to utilize six different data-driven techniques based on machine learning to estimate the carbon and water fluxes with continuous six-year observation data from a flux tower site in a forest ecosystem. The specific aims are threefold as follows: (1) to investigate the feasibility and capability of various data-driven models, including GRNN, GMDH, ELM and ANFIS, for simulating the daily carbon and water fluxes at the ecosystem level; (2) to demonstrate that these newly proposed modern models can be used as desirable complements to the traditionally accepted ANN and SVM models; and (3) to examine the modeling differences between the ET and three primary components of carbon fluxes (GPP, R and NEE). In addition, this study focuses on examining the modeling ability of aforementioned models only at a single flux tower site. It should be pointed out that these methods can also be used to upscale the carbon and water fluxes from site to regional scale with remote sensing data. However, it is beyond the scope of the present work and will be carried out in our follow-up investigation.
4. Discussion
The present study, for the first time to our best knowledge, investigated the adaptability and validity of a variety of machine learning techniques, including GRNN, ELM, ANFIS and GMDH, for modeling and predicting the terrestrial carbon and water fluxes for a forest ecosystem based on the data measured with the eddy covariance technique. In addition, to assess the generalization ability of all the approaches in our research, two conventional data-driven modeling techniques, namely ANN and SVM, were also employed as benchmarks. Furthermore, several performance indices involving R2, NSE, RMSE and MAE were adopted for the model evaluation in order to adequately manifest the efficiency of the applied models. In the following subsections, we concentrate mainly on discussing the predictive capability of various data-driven models and the discrepancy of different carbon and water fluxes in modeling ability, and providing the limitations of the current study and its potential improvements for future research.
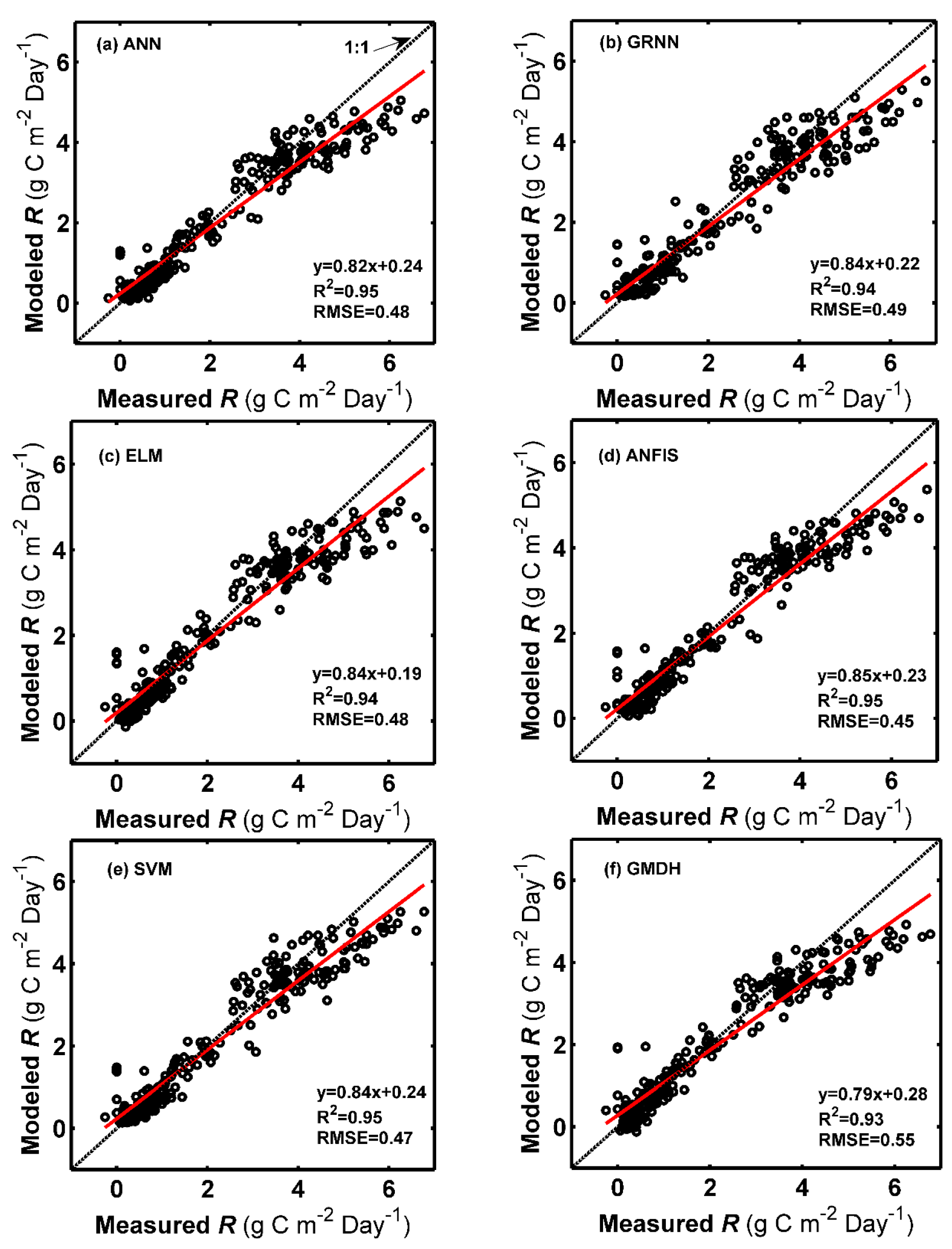
Our predictive results in the testing periods from
Table 2 and
Table 4,
Table 5 and
Table 6, demonstrated that a large amount of diurnal variance in each carbon and water flux was accounted for by our used models, with average 95%, 94%, 77% and 91% for GPP,
R, NEE and ET, respectively. Therefore, these machine learning techniques have adequate capability to describe the complex interactions between the carbon and water fluxes and environmental factors. Moreover, previous studies have also proved the effectiveness of data-driven models, primarily including ANN and SVM methods, for the terrestrial carbon and water flux prediction at ecosystem level [
66,
67,
68,
69]. In recent years, another important data-driven technique, namely regression tree method, has been successfully utilized to estimate the carbon fluxes [
28,
70]. Beer et al. [
28] used model tree ensemble and ANN models to estimate the spatial distributions of global GPP, and found that these two models obtained similar estimates, which are comparable to those of both process-based and atmospheric inversion models. Xiao et al. [
70] utilized regression tree algorithm to exclusively upscale NEE from flux tower to the continental scale with remotely sensed and AmeriFlux data. They found that the 8-day observed NEE can be reproduced reasonably well by this model at the site level (
R2 = 0.73). Additionally, it is interesting to note that, based on the site investigated in this study, Fu et al. [
71] used the regression tree model to predict the NEE using two different types of remote sensing data and obtained satisfactory results with
R2 = 0.70 for Landsat data and
R2 = 0.68 for MODIS data during 2005–2006. By comparing with these results, on the whole, our proposed models achieved higher accuracy with the average value of
R2 =0.77 in 2009. In conclusion, our presently proposed models and aforementioned regression tree method have great potential for estimating carbon fluxes, and can be considered as alternative tools to scale up eddy covariance-measured carbon flux data to regional or global scale across different vegetation types.
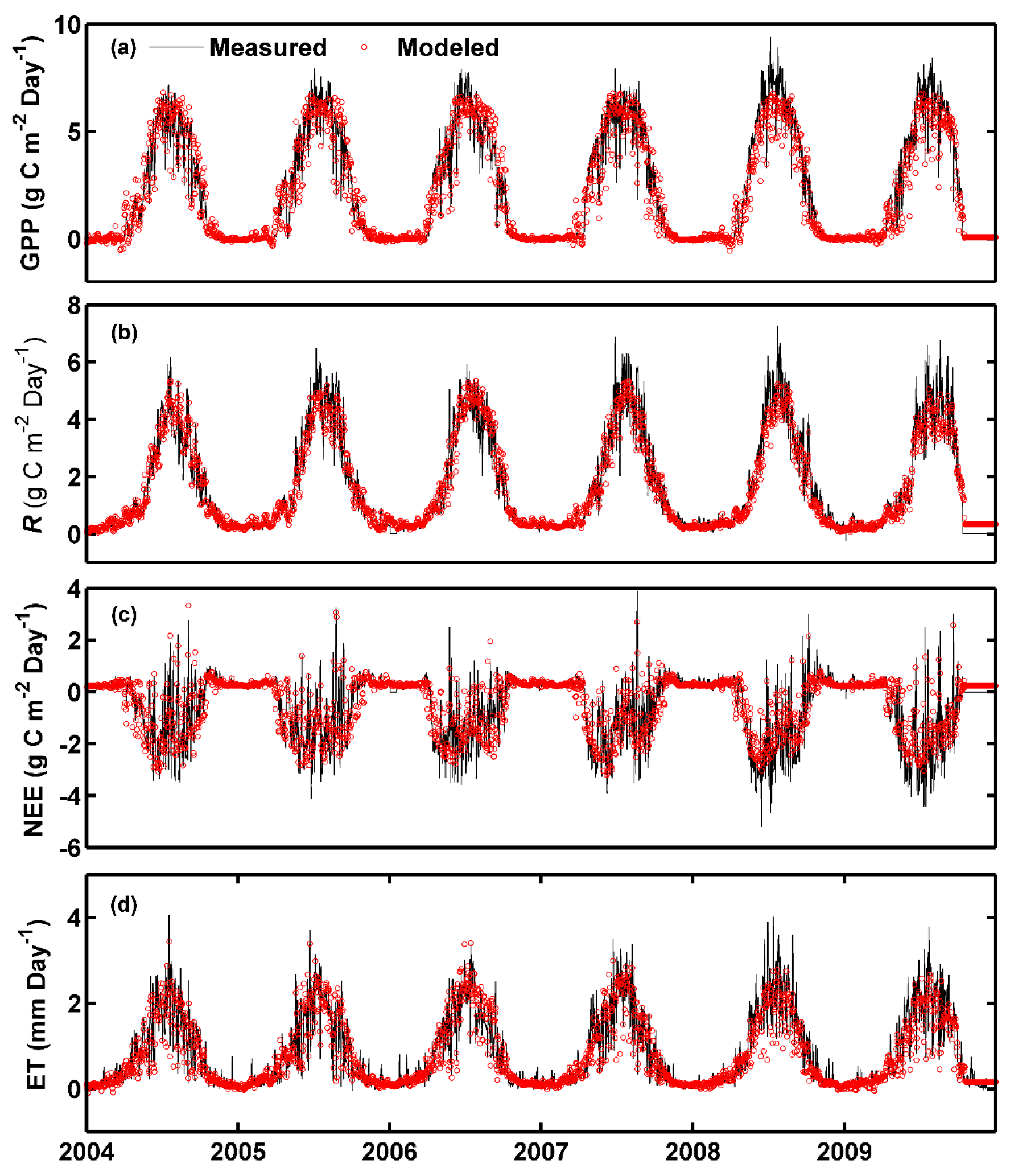
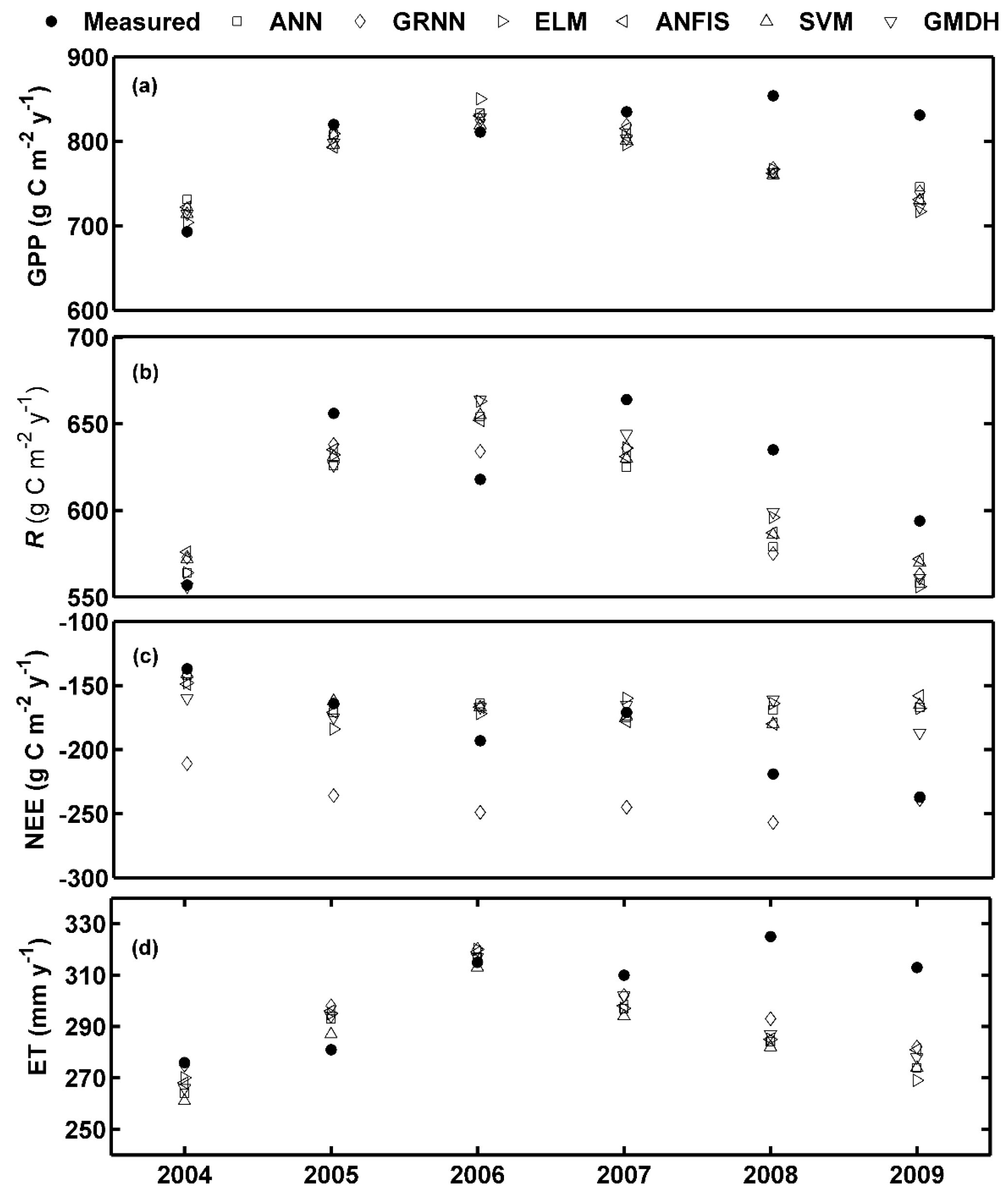
Furthermore, the seasonal and inter-annual variability in each flux caused by the environmental forcing variables can be satisfactorily captured (
Figure 3 and
Figure 4). It is noteworthy to point out that appreciable underestimations of the peaks during the growing season and annual total carbon and water fluxes by most of the used models occurred both in the validation and testing periods. In addition, although all the applied models can adequately reproduce each flux for the entire year (2009), substantial differences existed among different seasons, which is consistent with the finding reported by Xiao et al. [
70]. In general, our used models provided the worst estimates in winter (December, January and February), while produced satisfactory estimates in both summer and fall seasons. For example, according to our estimates, for GPP, a mean value of
R2 = 0.15, RMSE = 0.13 g·C·m
−2·Day
−1, and MAE = 0.11 g·C·m
−2·Day
−1 was obtained by the six models in winter, compared with 0.95, 0.51 g·C·m
−2·Day
−1, and 0.32 g·C·m
−2·Day
−1 in fall. The reasons for these discrepancies may be due to the errors induced by the eddy covariance-measured NEE [
72], the partitioning approach of NEE into GPP and
R [
73,
74], and the gap-filling methods for missing flux data [
69]. Moreover, the annual average values of
Ta,
Ts and
Rh in both 2008 and 2009 were lower compared with the 4-year means during 2004–2007. For example, in 2009, the annual average values of
Ta and
Ts were lower by 2.84 and 0.52 °C, respectively, while the annual average value of
Rn was higher by 0.57 mol·m
−2. These non-stationary features in environmental variables may lead to a potential impediment in reproducing the carbon and water fluxes.
According to the modeling performance of various carbon fluxes among all the examined approaches in this work, the ANN model provided the optimal estimates for GPP and NEE, while the ANFIS model achieved the best for
R, indicating that no single model consistently outperforms others for all the carbon flux estimation. For this reason, it is extremely essential to compare the estimates using a variety of data-driven modeling methods to forecast the carbon fluxes. In contrast, for all the carbon fluxes and ET prediction, the GMDH model consistently produced the worst modeling results. This may be caused in part by its inherent limitations such as selection of input arguments, reduction of complexity, multi-collinearity and over-fitting [
75,
76].
Taken as a whole, according to the estimates using our proposed techniques, it was found that the performance differences among all the models were comparatively slight for GPP,
R and ET fluxes, while considerable differences were found for NEE. Specifically, in the prediction of NEE, the ANN model achieved the optimal estimate with the approximate value of
R2 = 0.84, NSE = 0.78, RMSE = 0.63 g·C·m
−2·Day
−1 and MAE = 0.44 g·C·m
−2·Day
−1, whereas GMDH model performed the worst with the approximate value of
R2 = 0.67, NSE = 0.60, RMSE = 0.84 g·C·m
−2·Day
−1 and MAE = 0.57 g·C·m
−2·Day
−1. Moreover, it is noteworthy that evaluating the difference in predicting the carbon fluxes at different time scales (e.g., daily, monthly and annual) should take into account the influences of random errors in half-hourly flux observations. Richardson et al. [
72] demonstrated that a total random error in NEE induced by both the eddy covariance measurements and gap filling is roughly 25 g·C·m
−2·year
−1. In addition to random error, systematic errors can also add to the uncertainty of carbon flux estimates. Therefore, when ranking the performance of our proposed methods for NEE prediction, it seems difficult to find the sources of error in the estimates from these models. Furthermore, in comparison to other fluxes, the diurnal and seasonal variations of NEE in amplitude and phase are strongly affected by the complex interplay between photosynthesis and respiration. On the other hand, through comparing the estimates among the fluxes, the worst results occurred for NEE estimates. A potential explanation for the lower performance in NEE prediction could be attributed to the omission of some important variables such as soil properties and biomass pools for the establishment of our used models. Hence, it is essential to select effective driving variables as model inputs for the further improvement in the predictive ability of data-driven models, especially for NEE, in the future work. In view of the estimates of ET, all the models achieved almost consistent, high modeling accuracy, suggesting that machine learning techniques can be expected as powerful tools to simulate and predict ET. What’s more, it should be acknowledged that in recent years, these modeling techniques have been triumphantly applied in numerous branches in hydrology for nonlinear time series analysis, such as reference ET [
77,
78] and evaporation prediction [
33], rainfall [
79] and runoff forecasting [
80,
81].
Our applied models were trained via many attempts in order to determine the optimized internal structure, functions and parameters. And afterwards their corresponding best predictions were derived based on the cross-validation strategy, taking into account the common drawback of over-fitting. Despite all this, the uncertainty issue in estimated results remains a great challenge for further research. To a certain extent, the predictive error caused by such uncertainty could potentially undermine the credibility of the models, and may lead to some problems in the applications of interpolation and extrapolation. Unfortunately, the uncertainty issues existing in the output results are ignored by most studies of machine learning modeling techniques in practical applications. Therefore, to overcome the negative impacts brought by the uncertainty in time series prediction, the uncertainty issues of data-driven models, involving a range of sources such as input data, internal parameters as well as geometry, have been recently addressed by a number of studies [
82]. Reasonable uncertainty evaluation is needed to quantify the beneficial information related to confidence bounds and provide more rigorous and credible estimates for policy makers. Specifically, for addressing the uncertainty problem in time series prediction, a suite of algorithms, such as Markov chain Monte Carlo (MCMC) [
83] and Bayesian model averaging (BMA) [
84], have been integrated into either a single data-driven model or a set of ensemble models. For example, Zhang et al. [
85] utilized the MCMC algorithm to train the Bayesian neural networks for estimating different uncertainty sources, and effectively quantified the uncertainty of stream-flow simulation. Chitsazan et al. [
86] used a hierarchical BMA approach to estimate the uncertainty of fluoride concentration prediction based on the uncertain sources from the ANN model, and found that the most prediction variance was generated by the uncertain inputs and internal parameters of the ANN model. Consequently, to obtain more beneficial and reliable carbon and water flux prediction in the present work, examining these uncertainty algorithms combined with our applied models is essential for the follow-up study.
5. Conclusions
With the advance of machine learning techniques, many modern data-driven approaches have been developed during the past few decades, which leads to the present predicament of what modeling technique should be chosen in a practical application, predominantly due to the lack of comprehensive benchmark studies. In order to conquer this predicament, a comparative research plays an essential role in obtaining a full-scale overview of different data-driven methods, specifically aiming at gaining deep insights into their strengths and limitations and drawing some helpful conclusions with regard to their predictability and robustness. In this context, the main basis of the current work was to investigate the suitability of our newly proposed models, including GRNN, GMDH, ELM and ANFIS, in mapping the non-linear relationships that dominate the exchanges of the forest carbon and water fluxes at a flux tower site. In addition, these models were compared and evaluated for the first time with the classical ANN and SVM models in terms of several performance indices (R2, NSE, RMSE and MAE).
It was found the ANN model provided the best estimates for GPP and NEE, whereas the ANFIS model achieved the best for R, indicating that no single model was consistently superior to others for the carbon flux prediction. Therefore, the use of a variety of methods is of particular importance for obtaining adequately accurate estimates for the carbon fluxes. In contrast, for all the carbon fluxes and ET estimation, the GMDH model consistently produced somewhat worse results, and accordingly may be not recommended for the present applications. Moreover, there were considerable differences among all the carbon and water fluxes. When taken as a whole, all the models generated the similar satisfactory predictive accuracy for GPP, R and ET fluxes, and did a reasonable job of reproducing the eddy covariance NEE.
The present investigation has manifested the feasibility and validity of several novel data-driven techniques for forecasting the carbon and water fluxes measured by the eddy covariance technique. These models can be used as attractive complements to traditional ANN and SVM models, except for GMDH, which may be due to involvement of large numbers of high-dimensional matrix calculations. In addition, these modern techniques provide many new alternative approaches for data collectors and processers to interpolate the missing data during the long-term eddy covariance measurements, which is of importance for guaranteeing the estimated accuracy in the further studies, when using these related measurements for the parameterization of process-based models and the validation of their estimates for forecasting carbon and water fluxes, and the assessment of published carbon and flux products from remote sensing techniques. More importantly, it is expected that these powerful methods offer novel perspective for up-scaling the carbon and water fluxes from ecosystem to regional or global scale with remote sensing data, as our follow-up investigation, which is particularly essential for the scientific community to intentionally ascertain the carbon and water budgets and further provide helpful information for policy makers responding to present and future climate change.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}