1. Introduction
With the rapid development of mobile internet and the Internet of Things (IoT), as well as the widespread popularity of smart terminals, the types and quantities of mobile services have exploded, and mobile users’ demand for future networks has further increased. The rise of emerging applications such as the IoT and streaming media has triggered a rapid increase in data traffic, prompting an explosive increase in the amount of data transmitted over the network [
1]. Ericsson’s mobile market report released in 2023 pointed out that in the next few years, the annual growth rate of mobile data traffic is expected to remain between 20–30%, and so mobile data traffic will continue to rise [
2]. In order to cope with the explosive growth of mobile data traffic and large-scale device connections, as well as to adapt to emerging services and application scenarios, 5G came into being [
3].
In order to meet the challenges of 5G low-latency business requirements, the 5G core network adopts the Control and User Plane Separation (CUPS) architecture. Under the CUPS architecture, the User Plane Function (UPF) can sink to the edge of the network. By deploying UPF in a distributed manner close to the base station, traffic localization can be achieved, data processing within the network can be supported, and end-to-end latency can be effectively reduced to achieve a balance between management costs and user experience. Consider the communication scenario between a User Equipment (UE) and a remote server. When the UE switches across UPFs, the UE’s network address will change. However, in the current TCP/IP network architecture, the change of IP address will cause the TCP/IP session to be interrupted. TCP/IP reconnection will seriously affect the continuity of delay-sensitive real-time services.
Information-Centric Networking (ICN) [
4,
5,
6] is an emerging future network architecture. Different from the traditional TCP/IP network architecture, ICN takes information as the center of communication and separates identity and location. ICN’s identity-based routing can naturally support mobility, support in-network caching and multicast, and can achieve more efficient and timely content delivery [
5]. Integrating ICN with 5G networks is of great benefit to solving delay-sensitive business continuity. Currently, the industry is exploring 5G and ICN deployment solutions, and ICN can be integrated into Data Network (DN) [
7]. Indeed, while ICN as a solution integrated with 5G brings some advantages in handling mobility, the current 5G-ICN fusion solutions have not fully exploited the benefits of ICN in addressing real-time business continuity issues related to changing addresses. There is still research space for optimizing switch paths and reducing packet loss during handover.
We roughly divide seamless mobility methods in ICN into three categories, namely broadcast/multicast-based methods, active caching-based methods, and temporary buffer-based methods. When the network loses the location of mobile producers, broadcast/multicast-based methods [
8,
9,
10] achieve seamless mobility support by finding mobile producers through multicast/broadcast interests. In larger, denser network environments, multicast/broadcast interests can incur significant network overhead. Broadcast/multicast-based methods [
11,
12,
13,
14,
15,
16,
17] use an active caching method to minimize Interest retransmission during handover. These methods assume that the data already exist and proactively push future requests to the network cache before handover. However, this is not the case in real-time communication. Most real-time data (e.g., online gaming, internet phone calls, video conferencing, etc.) are data that are generated and delivered immediately upon request. Therefore, active caching approaches cannot provide seamless mobility support for real-time applications. Temporary buffer-based methods [
18,
19,
20,
21,
22] minimize packet loss during handover by buffering packets for a period of time on the access device. LPBMMS [
21] uses location prediction technology combined with data buffering to bring better handover performance. However, the existing ICN seamless mobility support solution based on data buffering lacks management of buffered data and cannot distinguish mobile business types, resulting in unreasonable allocation of buffering resources. Different types of businesses have different requirements for packet loss. In video communication and streaming media applications, especially real-time video conferencing or online live broadcast, business continuity and real-time are particularly important for mobile user performance experience. When buffering resources are limited, how to effectively allocate buffering resources to different types of mobile data flows is an urgent problem to be solved. The quality of buffer resource allocation will directly affect users’ Quality of Experience (QoE).
This paper integrates 5G with ICN, takes advantage of router data buffering capabilities, and designs a seamless mobility support method based on router buffered data suitable for real-time applications to improve the QoE of mobile users. The main contents of this article are as follows:
Referring to the 5G-ICN architecture in [
7], we propose a seamless mobility support method based on router buffered data (BDMM), which fully utilizes the identity-based routing capabilities of ICN to solve the problem of UE cross-UPF handover affecting business continuity. BDMM also uses the ICN router data buffering capabilities to reduce packet loss during handovers.
We design a dynamic buffer resource allocation strategy (DBRAS). This strategy comprehensively considers factors such as the status of the mobile buffer, the transmission rate of the mobile data flow, and the business category of the mobile data flow, and adjusts the buffer resource allocation results in a timely manner based on network traffic changes and business types to optimize the overall loss in performance of mobile data flows.
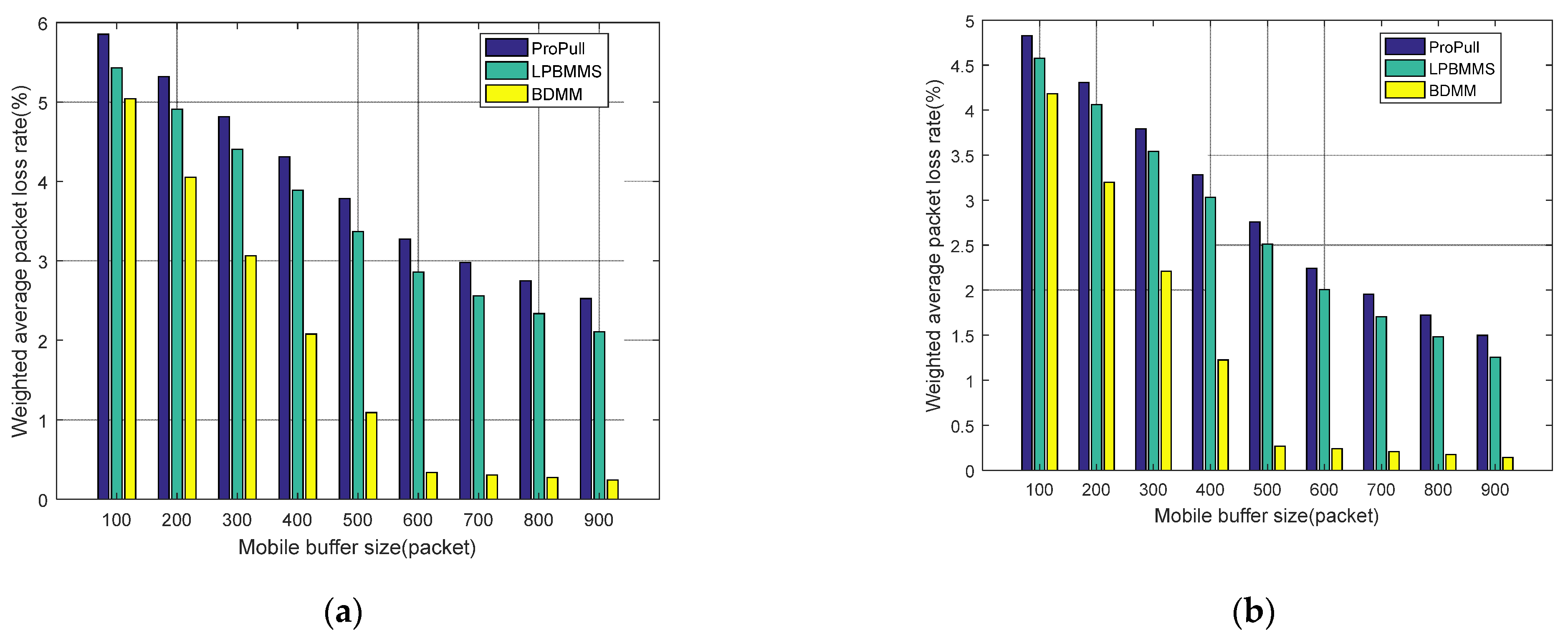
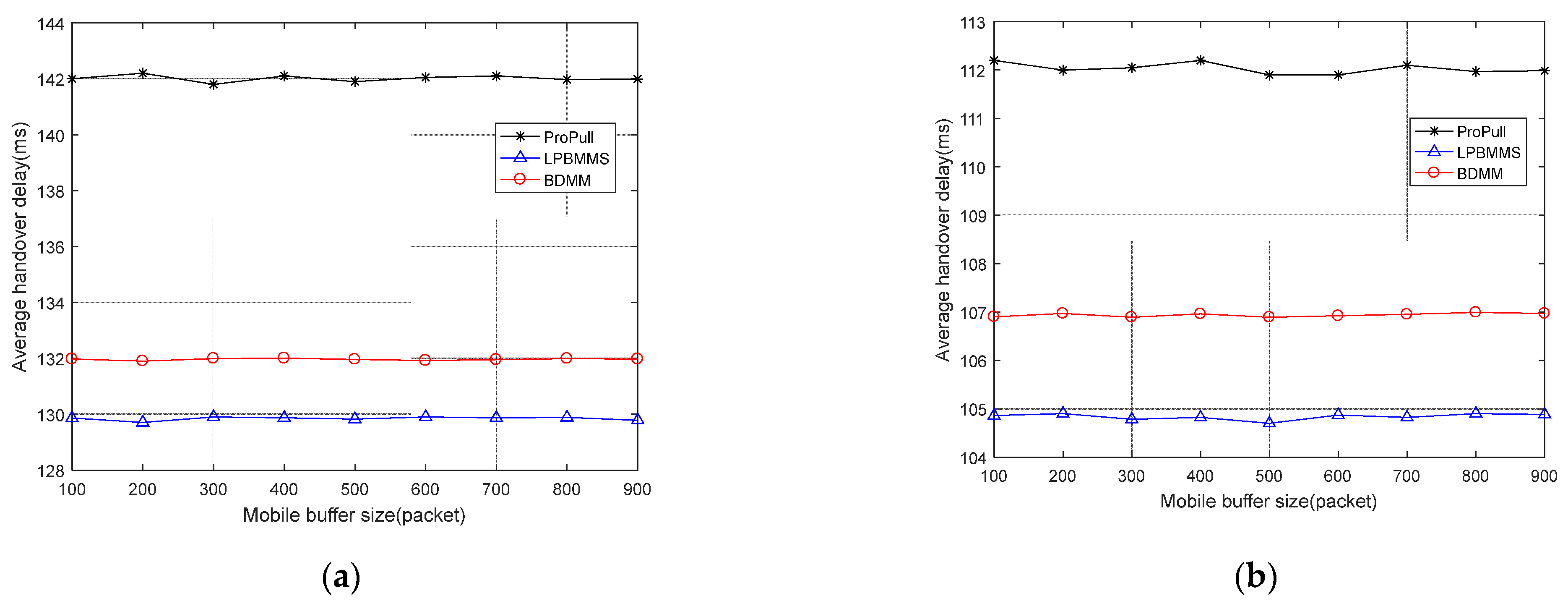
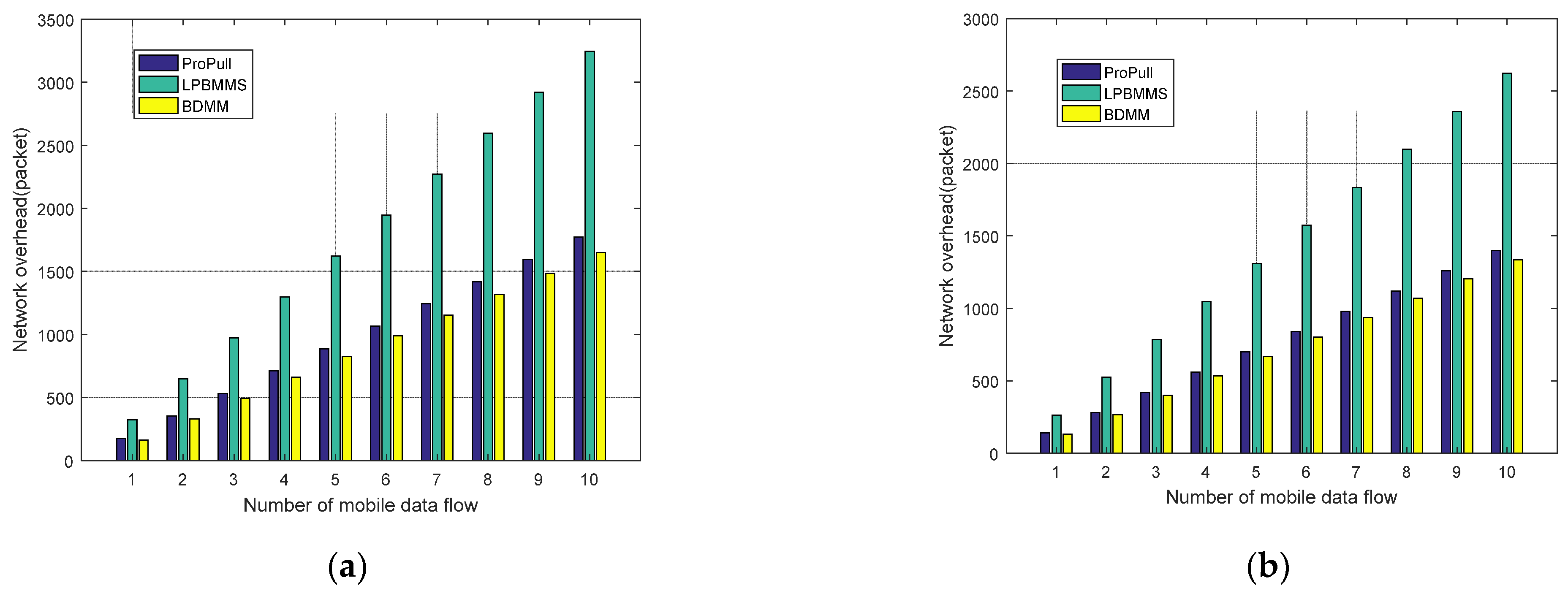
We conduct a series of experiments to evaluate the performance of the proposed method. Experimental results show that our method outperforms other methods in terms of average packet delay, weighted average packet loss rate, and network overhead. In addition, the proposed method also has good performance in average handover delay.
The rest of this paper is organized as follows. In
Section 2, we review 5G-ICN network convergence research and research on seamless mobility support methods in ICN, respectively. In
Section 3, we describe the proposed seamless mobility support method and describe the buffer resource allocation problem. In
Section 4, we present the dynamic buffer resource allocation strategy.
Section 5 discusses the experimental results of the proposed seamless mobility support method. Finally, we conclude the paper and discuss our plans for related future work in
Section 6.
3. BDMM
In
Section 3.1, we first present an overview of BDMM’s architecture. We describe how to achieve seamless mobility support in
Section 3.2. Finally, the mobile buffer resource allocation problem statement is given in
Section 3.3.
3.1. Architecture Overview
Operators can use ICN as DN and extend the 5G core network to provide session mobility support [
7]. The advantage of ICN as a DN integrated with 5G is that ICN introduces name-based identities which are location-independent, and can handle host mobility very effectively by applying the application-bound identifier and name resolution split principle. ICN also allows content to be independently replicated at network nodes or propagated through ICN routers, thereby bringing benefits to high-bandwidth/low-latency applications (such as AR/VR). Referring to [
7], our proposed seamless mobility support method adopts 5G-ICN architecture, which uses SEANet [
35] in the DN and can achieve coexistence with existing IP networks. A central feature of our approach is the use of SEANet to support session mobility.
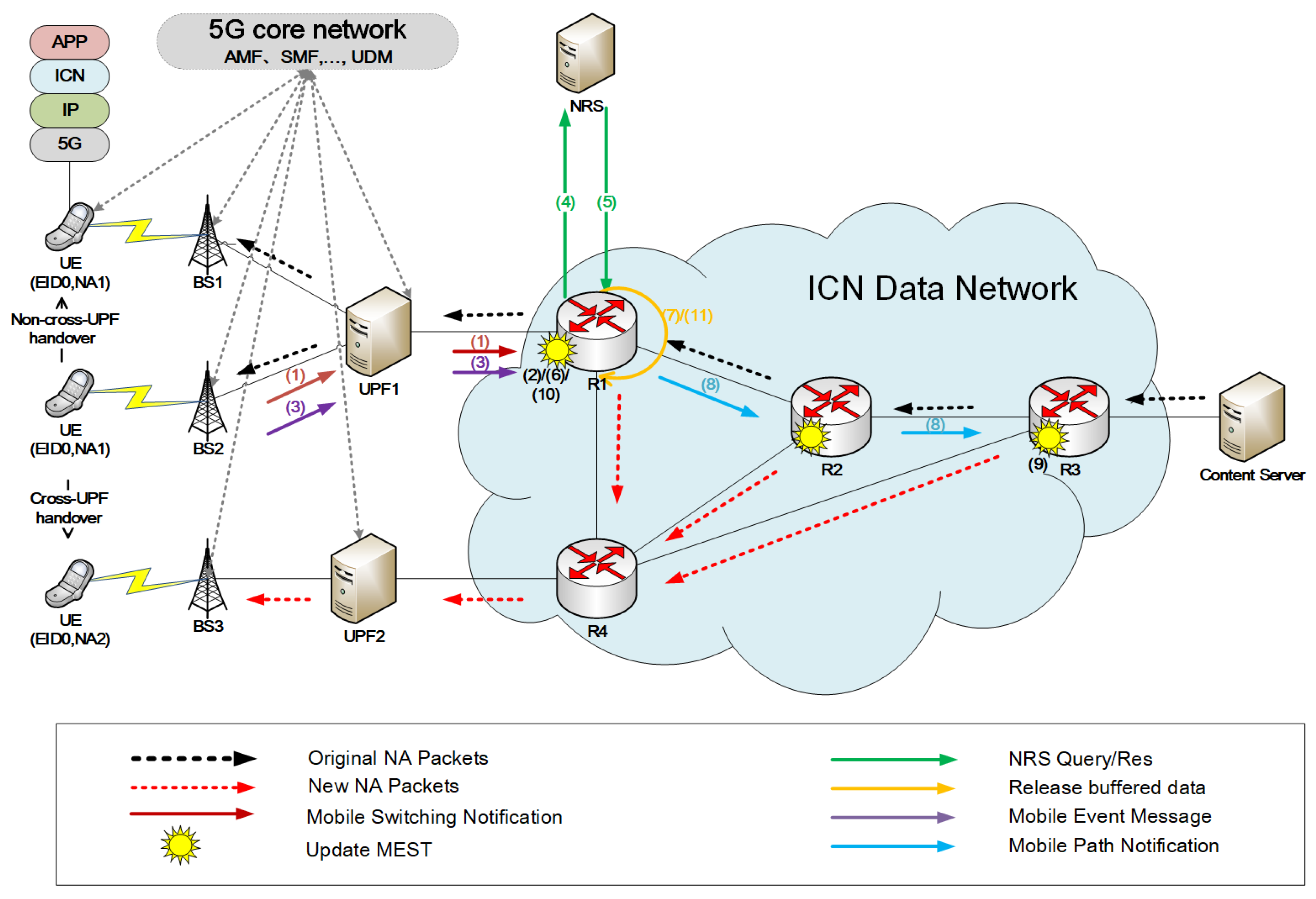
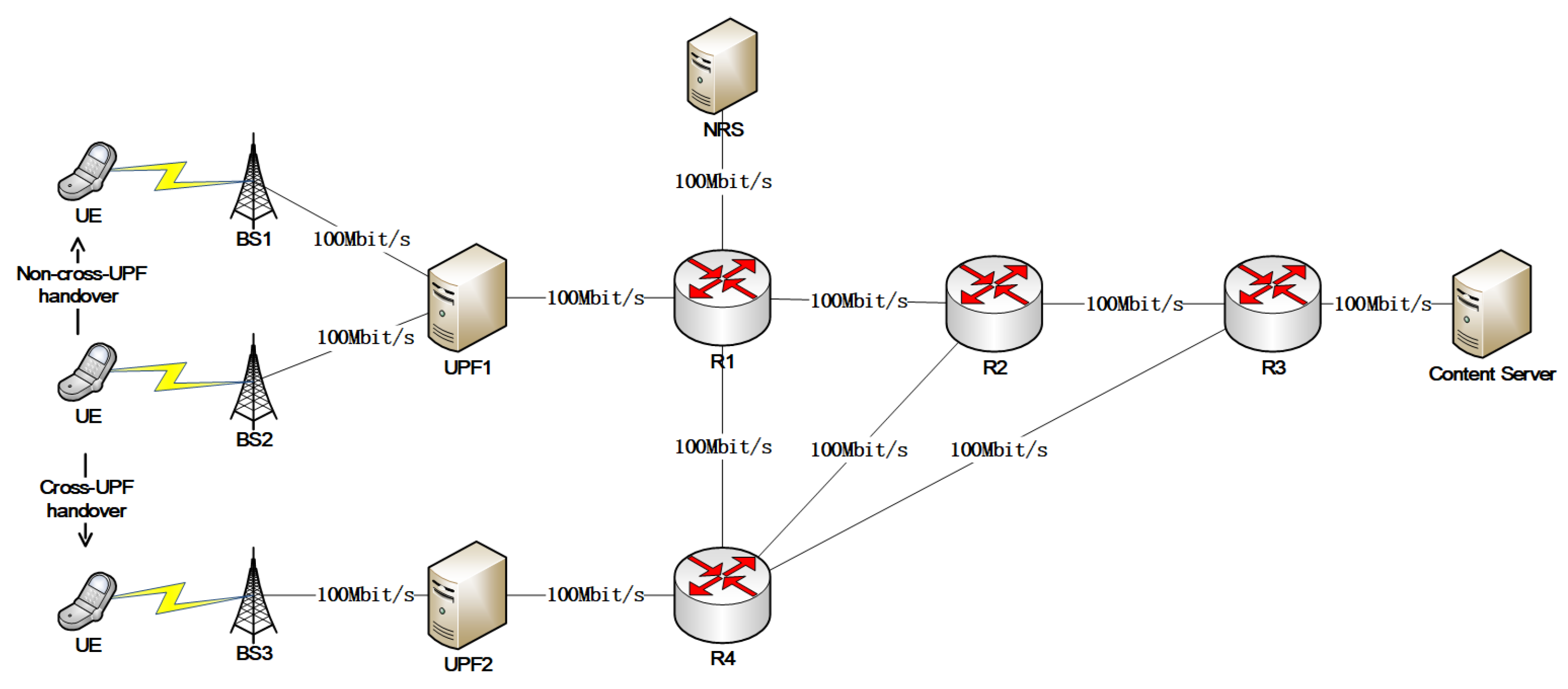
As shown in
Figure 1, the UPF sinks to the edge of the network and is deployed in a distributed manner close to the base station (BS). In dense base station deployment scenarios, one UPF can connect multiple base stations. When the UE switches to the base station under the same UPF, the network address does not change. We define the above handover as a non-cross-UPF handover (as shown in
Figure 1, the UE switches from BS2 to BS1). When the UE switches between base stations under different UPFs, the network address changes. We define the above handover as a cross-UPF handover (as shown in
Figure 1, the UE switches from BS2 to BS3).
Following the basic principle of identity-location separation in ICN, each network entity is assigned an Entity-ID (EID) as an identifier (or name) and a Network Address (NA) as a locator. Entities such as content, devices, and services are considered network entities. In order to ensure compatibility with existing IP networks, the IP address is used as NA. The Name Resolution System (NRS) maintains a mapping between identifiers and locators. UE and ICN routers in the DN support identity-based ICN packet forwarding, and other network devices (BS, UPF, etc.) support IP packet forwarding. Considering the scenario where the UE requests the Content Server, the request packet has the same format as the data packet, and both need to carry the source EID (UE’s/Content Server’s identifier), destination EID (Content Server’s/UE’s identifier), source network address (UE’s/Content Server’s network address) and destination network address (Content Server’s/UE’s network address). We collectively refer to request packets and data packets as packets. In order to implement the dynamic buffer resource allocation strategy, the data packet also needs to carry the service type that identifies its business type. Referring to MobilityFirst [
36], the function of the ICN router, which alters the destination address of packets based on the identification (destination EID), is identified as a late-binding function. We designate the ICN router executing late-binding processing as a late-binding node (LBN). The ICN router can locate the valid network address of the mobile entity in the Name Resolution System (NRS) using the identifier of the mobile entity.
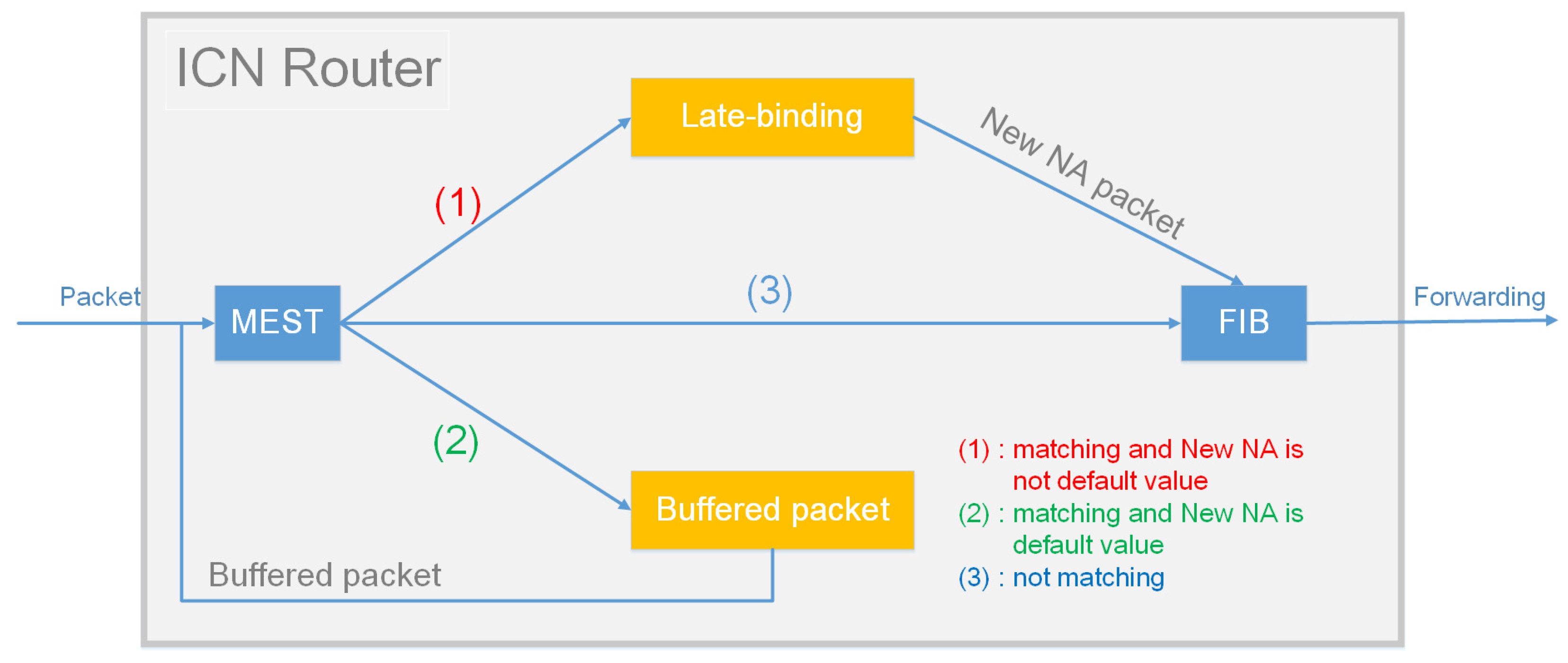
In order to implement packet buffering and packet redirection, each ICN router needs to provide a buffer and to maintain a Mobile Entity State Table (MEST), which consists of a set of Mobile Entity State Table Entries (MESTEs). Each MESTE includes the EID and the New NA (the latest network address of the EID or the default value).
Figure 2 describes the process of ICN router forwarding packets. After receiving the packet, the ICN router first queries MEST based on the destination EID carried in the packet. If there is a matching MESTE and the New NA in the table entry is not the default value, the packet will be late-binding, that is, the destination network address in the packet will be replaced with the corresponding NA in the MESTE, and then the FIB will be matched for forwarding. If a matching MESTE exists and New NA in the table entry is the default, the ICN router will buffer the packet. If there is no matching MESTE, the ICN router will directly match the FIB for forwarding. When the ICN router releases the buffered packets, it will schedule the buffered packets in the buffer to enter MEST again to implement redirection of buffered packets.
3.2. How to Achieve Seamless Mobility Support?
As shown in
Figure 1, assuming that the UE is initially connected to BS2, the UE continuously requests content published by the Content Server. Before the UE moves, the Content Server replies to the UE that the original packet forwarding path is Content Server → R3 → R2 → R1 → UPF1 → BS2 → UE. When the source BS (BS2) senses that the UE is about to switch, the source BS (BS2) sends a Mobile Switching Notification to the uplink UPF (UPF1) (step 1). The Mobile Switching Notification carries the UE’s identifier (EID0). The source UPF (UPF1) relays the Mobile Switching Notification to the uplinked access router (R1). After receiving the Mobile Switching Notification, the access router (R1) adds/updates the local MEST-related entry, sets the “EID” field of the entry to the UE identifier (EID0) and sets the “New NA” to the default value (Step 2). At this time, the access router (R1) will buffer the packets destined for the UE. The buffer resource allocation strategy used by the access router (R1) is as described in
Section 4.
After the UE handover is completed, the source BS (BS2) senses the UE address change result, constructs and sends a Mobile Event Message to the uplink UPF (UPF1) (step 3). The Mobile Event Message needs to carry both the UE’s identifier (EID0) and the address change flag. The address change flag can be identified by “0” and “1”, indicating that the UE network address has not changed and that the UE network address has changed, respectively. The source UPF (UPF1) relays the Mobile Event Message to the uplinked access router (R1). If the access router (R1) receives the Mobile Event Message, it will determine its address change flag field. If this field is “1”, it proves that the UE has changed its address (referring to the scenario where the UE switches from BS2 to BS3, the UE performs cross-UPF handover). Then, the access router (R1) will query the NRS for the latest network address of the UE based on the UE’s identifier (EID0) carried in the Mobile Event Message (step 4). When the access router (R1) receives the response from the NRS, it learns the UE’s latest network address (NA2) (step 5). Next, the access router (R1) updates the local MEST-related entry and sets the “New NA” field of the entry corresponding to the UE’s identifier (EID0) to the UE’s latest network address (NA2) to redirect the packet to the UE’s latest location (step 6). The access router (R1) then releases the relevant buffered packets (step 7). The packet forwarding path is Content Server → R3 → R2 → R1 → R4 → UPF2 → BS3 → UE. The access router (R1) also constructs a Mobile Path Notification to propagate to the Content Server’s access router (R3) in the opposite direction to that of the original packet (step 8). The mobility path notification carries the UE’s identifier and the UE’s latest network address (NA2). After receiving the Mobile Path Notification, the intermediate router (R2) and the access router (R3) of the Content Server update the local MEST to achieve handover routing optimization (step 9). Finally, the optimized packet forwarding path is Content Server → R3 → R4 → UPF2 → BS3 → UE.
If the access router (R1) receives the Mobile Event Message with the address change field “0”, this proves that the UE has not switched to changing the address (referring to the scenario where the UE switches from BS2 to BS1, the UE performs non-cross-UPF handover). The access router (R1) will delete the relevant entries corresponding to EID0 in the local MEST (step 10). After that, the access router (R1) will no longer buffer packets. At the same time, the access router (R1) releases the relevant buffered packets (step 11). The packet forwarding path after switching is Content Server → R3 → R2 → R1 → UPF1 → BS1 → UE.
Our method utilizes the ability of ICN routers to forward packets based on identifiers to solve the problem of session interruption caused by UE cross-UPF handover in 5G networks. Our method also makes full use of the buffering packet capability of the ICN router to buffer packets during UE handover to achieve seamless handover. In addition, in the cross-UPF handover scenario, our method optimizes the handover path by propagating Mobile Path Notification.
3.3. Buffer Resource Allocation Problem Statement
Existing seamless mobility support solutions based on temporary data buffering only propose data buffering at the access devices (Access Point or access router), and do not clearly define the specific solution design for buffering resource allocation. When buffer resources are unlimited, all packets during handover can be buffered. However, in a real environment, there is an upper limit on the buffer resources of access network devices. Assume that the buffering resources of the access network devices have been consumed and the UE has not completed the handover. In this scenario, subsequent packets sent to the UE continue to arrive, and cannot be buffered. It is assumed that there are two different types of mobile data flows in the UE, such as real-time data flow and non-real-time data flow. If the mobile buffer only adopts the Complete Sharing (CS) strategy [
37], the buffer resources will be allocated to the two data flows according to the rate of the data flow. When the real-time data flow rate is much lower than the non-real-time data flow rate, more buffer resources are allocated to the non-real-time data flow. This will result in the loss of a large number of real-time packets during the handover. Real-time services are sensitive to packet loss, and the loss of a large number of data packets will seriously affect the quality of mobile user experience.
From the above discussion, it can be seen that when there are multiple mobile data flows sharing buffer resources in the network, the buffer resource allocation strategy is related to multiple attributes of the mobile data flows. Therefore, when buffering resources are limited, how to allocate appropriate buffering resources to multiple mobile data flows is a major issue in seamless mobility support.
4. Dynamic Buffer Resource Allocation Strategy
In order to optimize the overall performance loss across all mobile data flows in the network, inspired by literature [
38,
39], we designed a dynamic buffer resource allocation strategy (DBRAS). This strategy comprehensively considers three factors: the status of the mobile buffer, the transmission rate of the mobile data flow, and the business category of the mobile data flow.
Referring to [
39], we divide a buffer with fixed resources into
virtual partitions according to the business type. We define
as the
-th virtual partition, and define
as the threshold of
. If
is the total buffer resource and
is the total business category, then
. The threshold
is related to different types of business traffic and business priorities, so
is redefined as shown in Formula (1).
In the Formula (1),
is the coefficient of virtual partition
, which follows Pareto distribution. The calculation formula of
is as follows.
Among them,
(
) is the priority of the
-th type of business traffic. For the highest priority category, the priority is equal to 1.
is the proportion of the
-th type of business traffic.
Business traffic changes dynamically over time, so virtual partition thresholds need to be updated regularly. It can be seen from Formula (2) that we need to regularly calculate the proportion of different types of business traffic. Let
represent the number of packets received by the
-th virtual partition in the
-th statistical period. The formula for calculating the proportion
of the
-th type of business traffic in the
-th statistical period is:
In the mobile buffer, we create a buffer queue for each mobile data flow. Virtual partition
maintains information related to the buffer queue of mobile data flows belonging to business type
.
is the buffer queue set in virtual partition
, and
is the identifier of the buffer queue of the mobile data flow
in the virtual partition
. This identifier can be jointly identified by the source EID and destination EID of the mobile data flow. The buffer queue information includes its length, the total number of received packets, and the total number of discarded packets.
is the length of the buffer queue
.
is the total number of packets received by the buffer queue
.
is the total number of packets dropped by the buffer queue
. The total queue length
of virtual partition
is calculated by Formula (4).
Assuming
is the total queue length of
virtual partitions, then the
calculation formula is as follows.
DBRAS is related to the status of the mobile buffer. After receiving the packet, the mobile buffer decides whether to buffer the packet based on the current status. If
Q <
B, we call the buffer state the allowed state, and the packet is allowed to be added to the buffer. If
Q ≥
B, we call it a diagonal state, and a replacement or discard operation will occur.
To implement dynamic resource allocation strategies, a set of primitive operations is defined. At any time, the basic operations that can be taken include join operations, replace operations, and drop operations. Typically, such an action can be taken at any time. However, due to the memoryless nature of arrival and service times, in the absence of losses we assume that actions are taken only upon arrival or departure.
(1) Join operation: Use the source EID and destination EID of the arriving packet to jointly query whether the corresponding buffer queue exists in the corresponding virtual partition. If there is a corresponding buffer queue, insert it directly into the tail of the corresponding queue. If there is no corresponding buffer queue, a new buffer queue is created. Then update the relevant status value of the buffer queue.
(2) Replacement operation: Drop a packet from the end of a selected buffer queue; next, add the arriving packet to the buffer. Then update the relevant status value of the buffer queue.
(3) Discard operation: Discard the packet that has just arrived. If there is a corresponding buffer queue, the relevant status value needs to be updated.
The dynamic buffer resource allocation strategy is shown in Algorithm 1. When the mobile buffer receives the incoming packet belonging to the mobile data flow
, it first finds its business type
I according to the service type field carried by the packet and updates
. Next, use Formulas (4) and (5) to calculate the total queue length of all virtual partitions. Then use Formula (6) to determine the current mobile buffer status. When the buffer state is in the allowed state, the incoming packet is allowed to join the virtual partition
and perform the joining operation. If the buffer state is in a diagonal state, it is necessary to determine whether the total queue length
of the virtual partition
exceeds its threshold
. If the total queue length
of the virtual partition
does not exceed its threshold
, a replacement operation is required. Find the virtual partition
whose total queue length exceeds the threshold and has the lowest priority. In order to ensure packet loss fairness among multiple data flows belonging to the same type, the buffer queue
with the smallest packet loss rate is selected from the virtual partition
for replacement operation. If the total queue length
of the virtual partition
exceeds its threshold
, the discard operation is performed. Assuming that there are
business types, that is, there are
virtual partitions, and each virtual partition has
data flows, then the algorithm complexity of DBRAS is
.
| Algorithm 1 Dynamic Buffer Resource Allocation Strategy |
| Input: incoming packet, , , , , , , B, , |
| Output: |
| 1: for each incoming packet do |
| 2: Find the business type I of the incoming packet |
| 3: |
| 4: calculate by Equation (4) |
| 5: calculate by Equation (5) |
| 6: if then |
| 7: if then |
| 8: The incoming packet is inserted into the |
| 9: else |
| 10: Create a new queue and insertthe incoming packet |
| 11: , |
| 12: end if |
| 13: else |
| 14: if then |
| 15: Find the lowest priority overlimit |
| 16: |
| 17: discard a packet at the end of the |
| 18: , |
| 19: goto 7 |
| 20: else |
| 21: drop the incoming packet |
| 22: if then |
| 23: |
| 24: end if |
| 25: end if |
| 26: end for |
6. Conclusions
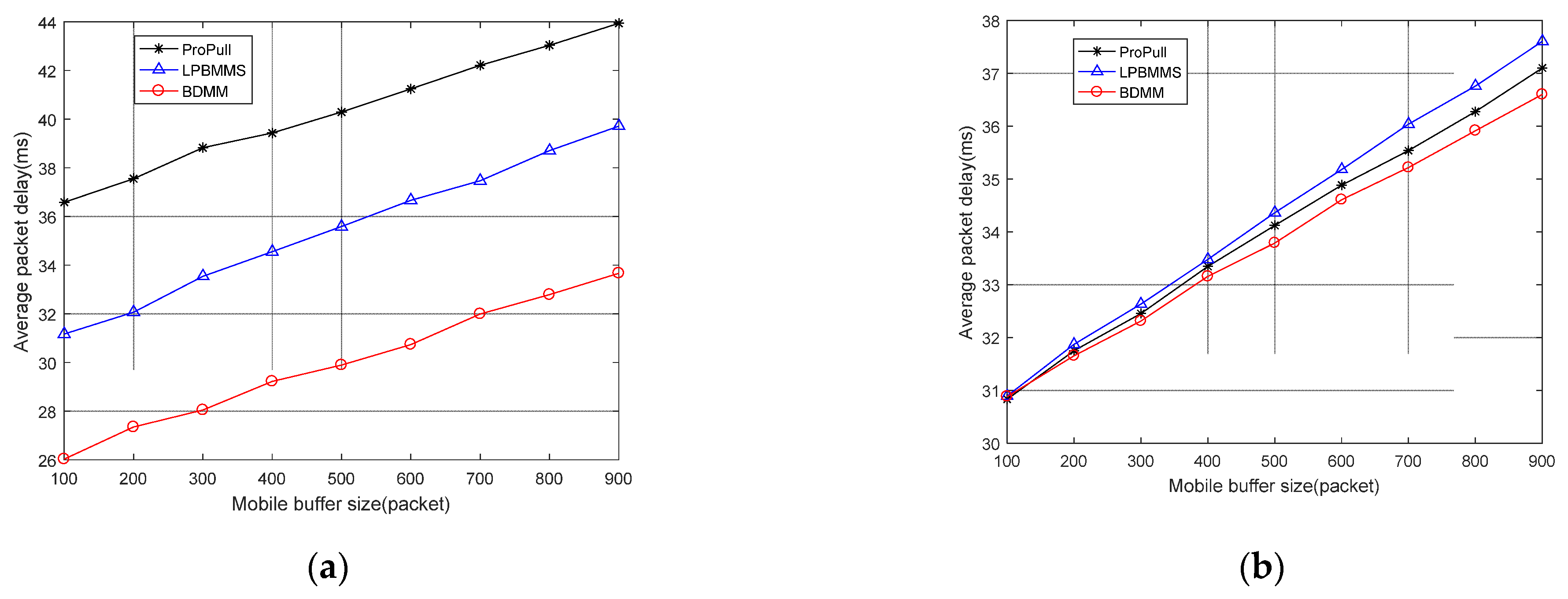
This paper proposes a seamless mobility support method based on router buffered data (BDMM) to address the challenges of real-time business mobility support under the 5G-ICN converged network architecture. This method uses ICN identity-based routing to solve business continuity problems caused by network address changes. In addition, BDMM also uses the ICN router to temporarily buffer data during handover, reducing the loss of data packets and achieving seamless handover. In order to improve mobile users’ QoE, we design a dynamic buffer resource allocation strategy (DBRAS). This strategy comprehensively considers factors such as the status of the mobile buffer, the transmission rate of the mobile data flow, and the business category of the mobile data flow, and instantly adjusts buffer resource allocation by sensing changes in different types of business traffic to optimize the loss in performance of mobile data flows in the overall network. Experimental results show that, under the guarantee of a low-latency deterministic Name Resolution System, the proposed method outperforms other seamless mobility support methods in multiple performance indicators, including average packet delay, weighted average packet loss rate, network overhead, etc. At the same time, our method also shows satisfactory performance in terms of average handover delay.
In future work, we plan to further optimize the buffer resource allocation strategy, which can be combined with machine learning and artificial intelligence technologies to design more intelligent algorithms to predict future network traffic and business needs, and adjust buffer resource allocation accordingly. Additionally, we plan to conduct a field-test measurement that uses a Software-Defined Radio (SDR) device to simulate a serving Base Station (BS)/Base Transceiver Station (BTS)/Access Point (AP) and uses a smartphone, tablet, or other SDR device as the UE. We will simulate different types of mobility conditions in real-life scenarios and evaluate the performance of our method under these conditions. For example, we will thus seek to understand how network performance behaves under high-speed movement and changes in communication quality in NLOS environments with severe occlusion to further optimize the design of our method.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}