7.1. Effectiveness Evaluation
First, we evaluated the impact of the controllable parameters on the different index-based dynamic optimization approaches.
Table 1 shows the values of the fixed parameters, that is, the fixed parameter values which were set while varying the value of a specific parameter.
We chose the Centralized routing algorithm as the fixed value for the routing algorithm (ALG) parameter as it strikes a balance between the Baseline and the Distributed routing algorithms. This means it leverages the available computing and network resources in the P2P network while avoiding overloading the peers with the consensus calculation. Furthermore, the following experiments (
Figure 8 and
Figure 9) as well as prior research [
13] comparing the performance of these three algorithms shows that the Centralized approach generally reports better results. We set
to achieve a minimum consensus of 40%, and
. Increasing these values also increases the computational costs, while reducing them may lead to a decrease in the quality of volunteers’ votes. Finally, we set the
h to avoid prematurely dropping tasks, while considering that a 24 h wait is sufficient for disaster scenarios [
13,
50].
Table 2 shows the mean and standard deviation (std) reported by the Index, the IndexLimit, and the IndexF algorithms for the consensus (Cons.); the processing time of the platform (workT); and the ISP utilization (ISP_Util). We processed a total of
= 10,000 images.
By controlling only the H parameter, the index-based algorithms achieve a consensus greater than 99%. If we only control the voting threshold C the algorithms achieve consensus values between 49% and 52%, the routing algorithm (ALG) allows us to obtain consensus between 39% and 48% when individually manipulated, and the allows us to achieve consensus values between 35% and 39%. Regarding the processing time (workT), by controlling the H parameter, the algorithms report values between 109 and 125 h, controlling the parameter C reports a workT between 228 and 230 h, the is between 194 and 213 h, and the routing algorithm ALG is between 228 and 231 h. Finally, controlling the H parameter individually allows us to achieve ISP average utilization values between 47% and 48%, the ALG is between 34% and 42%, the is between 58% and 62%, and the voting threshold C is between 57% and 58%.
When controlling different combinations of parameters, including all of them together (All), the highest percentage of consensus is 0,998, which is achieved by combining H and the routing algorithm ALG using the approach. However, similar results are obtained with the other metric-indexed approaches and when using the H parameter or any combinations including H. Thus, the H parameter drastically impacts the percentage of consensus.
On the other hand, the lower processing time, 99.167,is reported by the approach with the ALG-H- combination of controllable parameters. In this case, the consensus reported is 0.994. However, the ISP utilization is higher than 60%. On the other hand, the Index approach with the same controllable parameter configuration manages to keep the average utilization of the ISP network close the limit of 40%, and the processing of the tasks is completed in approximately 102 h. Finally, when all parameters are controlled at the same time, the approach returns a high consensus value of 0.964, a total processing time of 108 h, and the average ISP utilization is 53%. The approach reports a consensus of 0.96, the processing time is 134 h, and the ISP utilization is 34%. The achieves a consensus of 0.987, a processing time of 123 h, and the ISP utilization is 42%.
Therefore, in
Table 2 we show that controlling some parameters in isolation, like the
and
C, does not help to achieve efficient results. On the other hand, the parameter
H allows one—in most cases—to achieve a high level of consensus. When controlling
H and ALG at the same time, we can reduce the average utilization of the ISP.
Figure 8 shows the average consensus obtained with different dynamic optimization approaches and when no optimization is applied (None). The
x-axis shows the name of the routing algorithm used at the beginning of the experiment. At the top, we show the results obtained when
at the beginning of the experiment, and at the bottom we show the results obtained when
. The results show that the Baseline routing algorithm obtains a 100% consensus for the case without optimization when the initial value of
, but with
it reports a low consensus close to 30%. On the other hand, all dynamic parameter optimization approaches achieve consensus levels between 90% and 100%, with
-
being the one that obtains the lowest values.
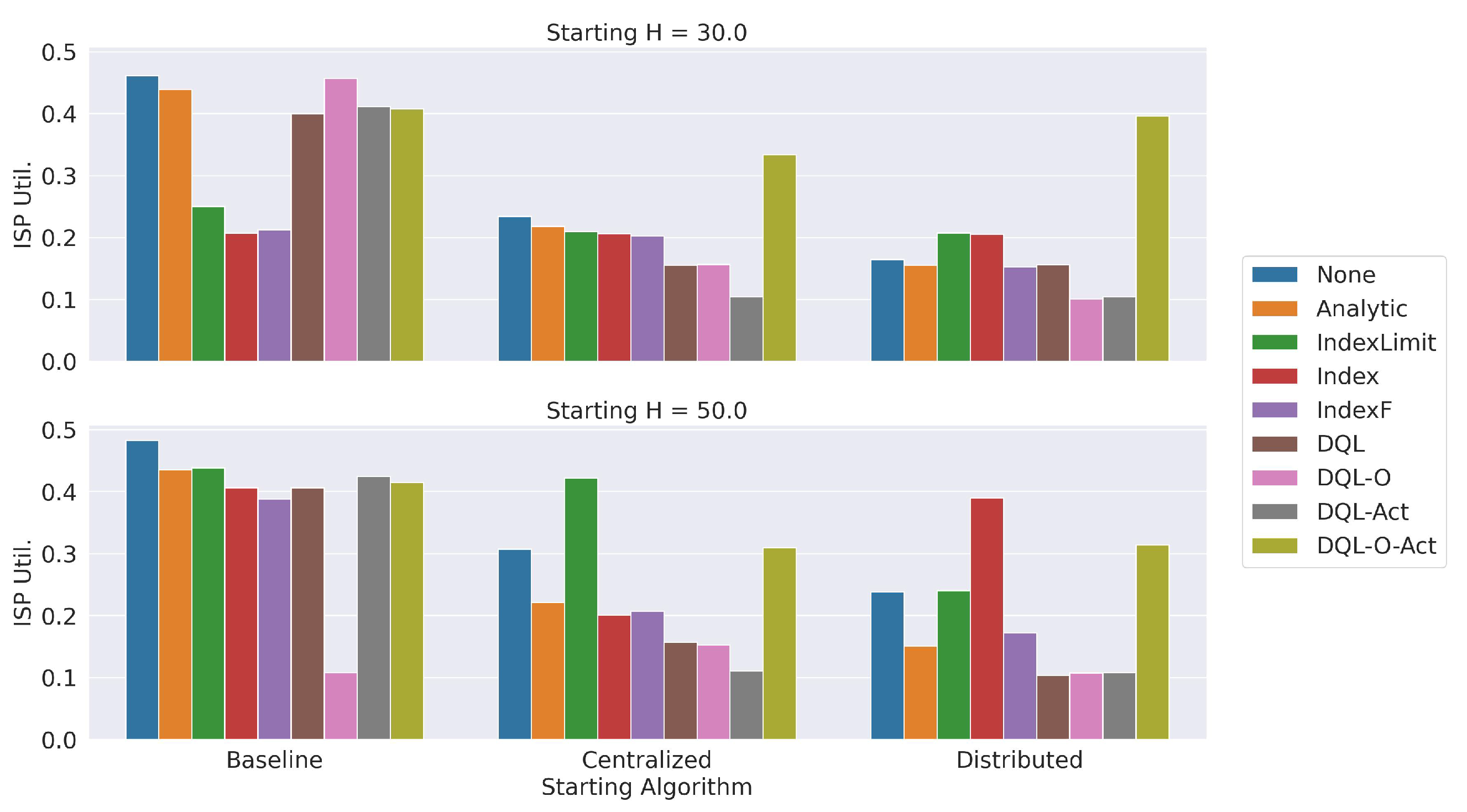
Figure 9 shows the average utilization of the ISP network. The
x-axis shows the name of the routing algorithm used at the beginning of the experiment. Again, at the top we show the results obtained when
at the beginning of the experiment, and at the bottom we show when
. The results show that the ISP utilization tends to be higher than 40% when the experiment begins with the Baseline routing algorithm, which uses point-to-point communication between the server and the peers through the ISP. If the initial value
, only the dynamic optimization approaches based on a metric index can keep the average utilization of the ISP below 40%. Meanwhile, when the initial value
, the DQL-O approach drastically reduces the ISP utilization. When we use the Centralized or Distributed routing algorithms at the beginning of the experiment and
, the results show that the
-
o-
dynamic optimization approach reports the highest utilization. All the remaining approaches tend to keep the ISP utilization below 40%. With
, again the dynamic optimization approaches tend to keep the ISP utilization below 40%. Only the
approach, initializing the execution with the Centralized algorithm, and the
approach, using Distributed as the initial routing algorithm, report a high ISP utilization.
Figure 10 shows the time required to process the
images. With an initial value
, we can reduce the processing time by 20% when applying a dynamic optimization approach. In this case, the
approach reports the lowest processing times. With
and stating with the Baseline routing algorithm, we can reduce the processing time by 80% by using a dynamic optimization approach. In this case, the
approach presents the lowest processing time when the experiment begins with the Baseline or with the Centralized routing algorithms. The index-based approaches present competitive results. Otherwise, when starting with the Distributed routing algorithm, the
approach presents the lowest processing time.
Overall, the analytical approach reports a good percentage of consensus and low processing times, but the ISP utilization tends to be high. Regarding the metric index-based approaches, all the proposed versions report a high percentage of consensus and an ISP utilization below 40%, but the version reports lower processing times with and the version with . Finally, the approach is the one that generally obtains the best results for all the metrics among the reinforcement-learning-based approaches.
7.2. Execution Time of the Dynamic Optimization Approaches
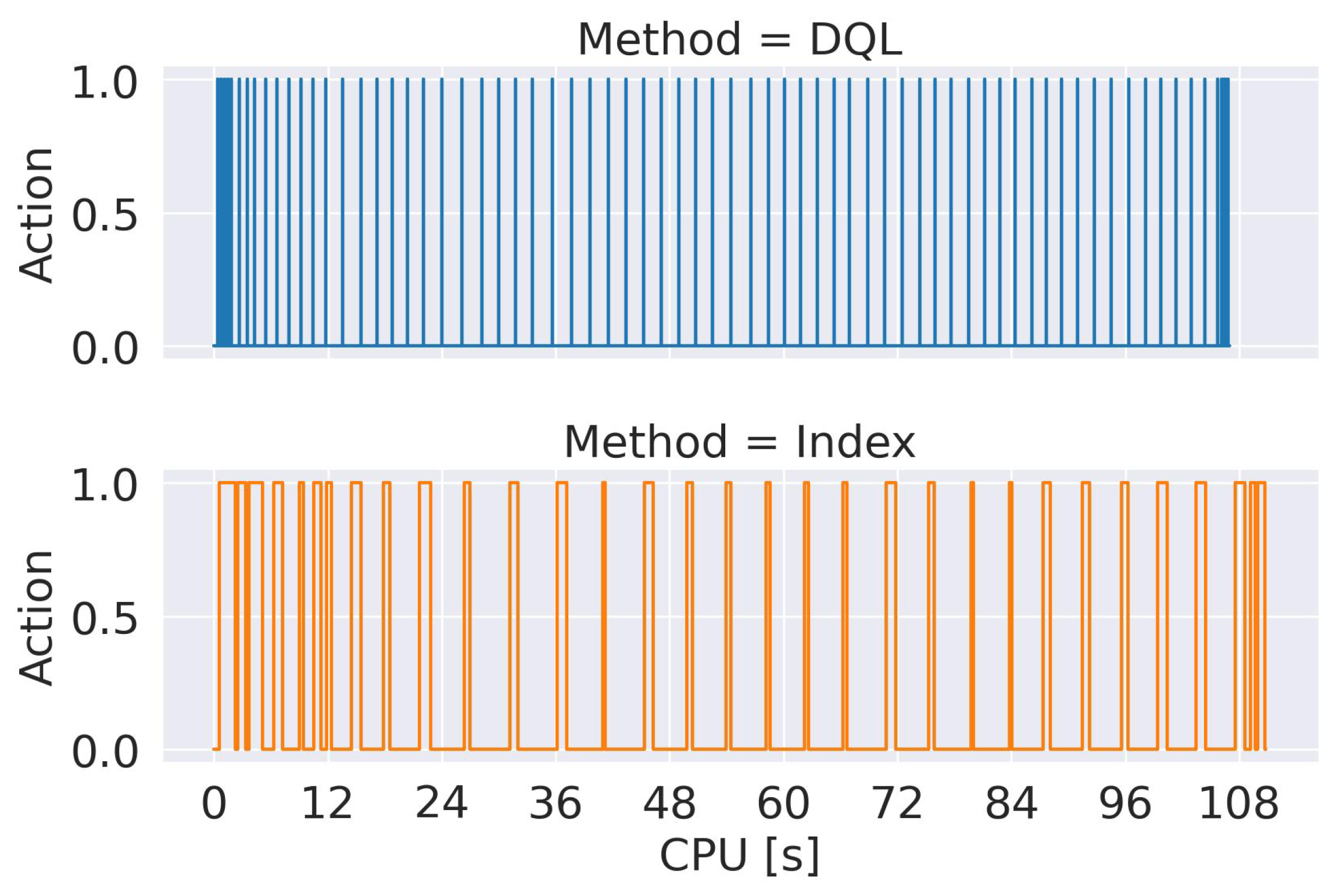
Figure 11 shows the CPU time of the actions performed by the parameter optimization approaches with the metric index (
) and with DRL (
). The intervals in which the signal is 1 correspond to the intervals where the CPU is used by the
or the
, that is, the active intervals of the optimization algorithms. In periods when the signal is 0, only the crowdsoursing platform is active. The graph shows the results obtained for 10,000 images, an initial value of
, and applying the Distributed routing algorithm. Similar results were obtained for other configurations.
The results show that the reports a larger number of optimization actions, but each one is very fast. On the other hand, the approach reports a lower number of optimization actions but each one consumes more time than in the case of the . The result of accumulating the CPU time of the optimization actions of each algorithm is 23.86 s for the metric index-based approach and 11.73 ms for the optimization with . However, the execution time of the simulation with both approaches tends to be similar, close to 108 s. Notice that the time of the crowdsourcing campaign is higher than 90 h; therefore, the execution times of both dynamic optimization approaches are negligible when operating on a real system.
Regarding the time required to set up the index-based dynamic optimization engine, it is important to notice that the database and the index are only built once, and it depends on the size of the database, but generally it takes a couple of hours at most. When using the -based approach, we also have to build the configuration vectors (databases) from previous simulations and then we have to train the model. The training process can take several days, and it must be repeated for each trained model until the desired result is obtained. So, there is a higher uncertainty in the amount of time required to fine-tune the accuracy of the -based approach.
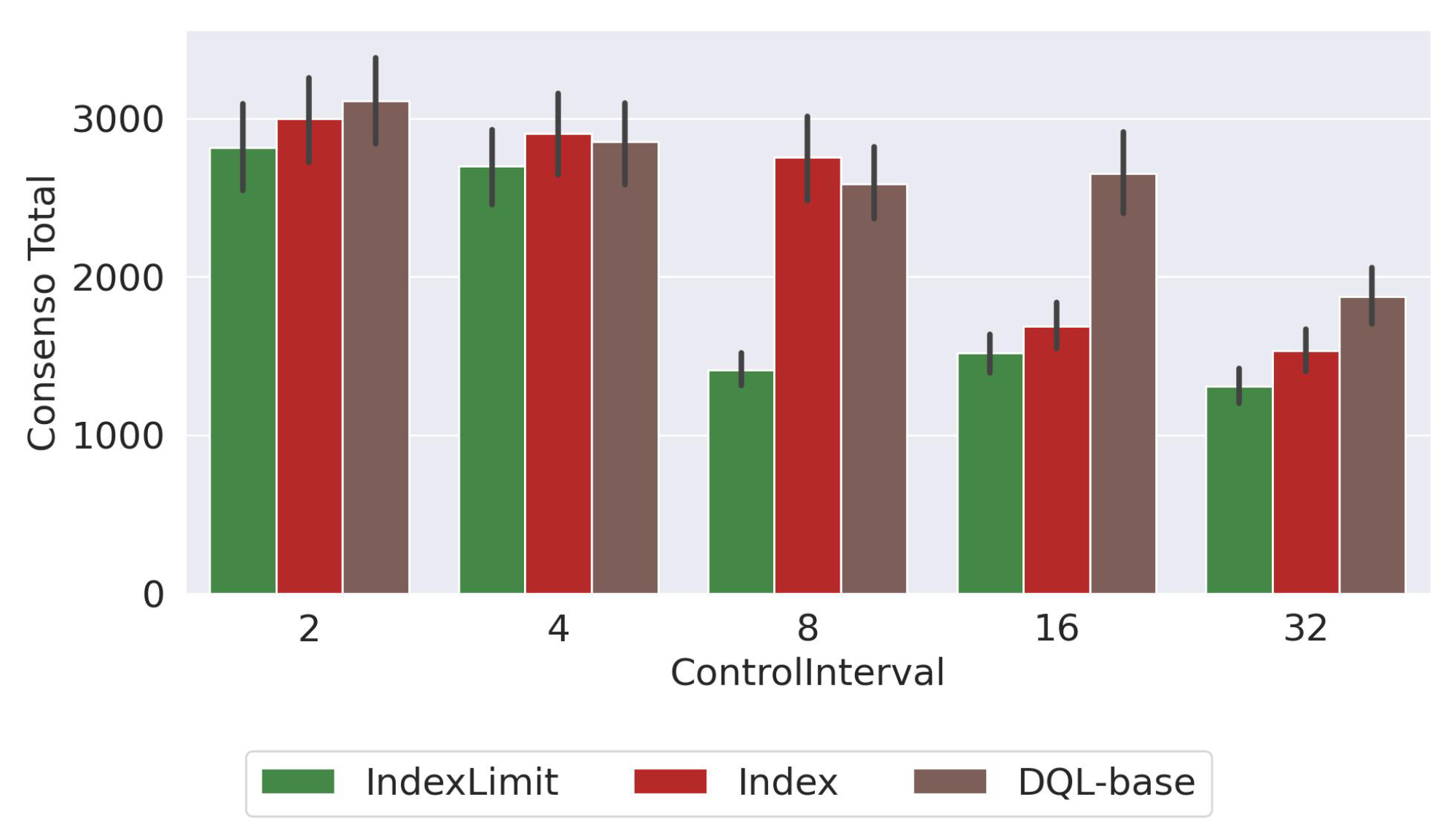
7.4. Size of the Control Window
This section discusses the impact of using different time intervals (called control intervals or control windows) to run the dynamic optimization engine. That is, as the crodwsourcing platform processes images, the dynamic optimization algorithm is activated every
units of time. We show the results obtained with
and using the Baseline routing algorithm at the beginning of the experiment. In
Figure 14, we show the ISP utilization obtained with an interval of
hours.
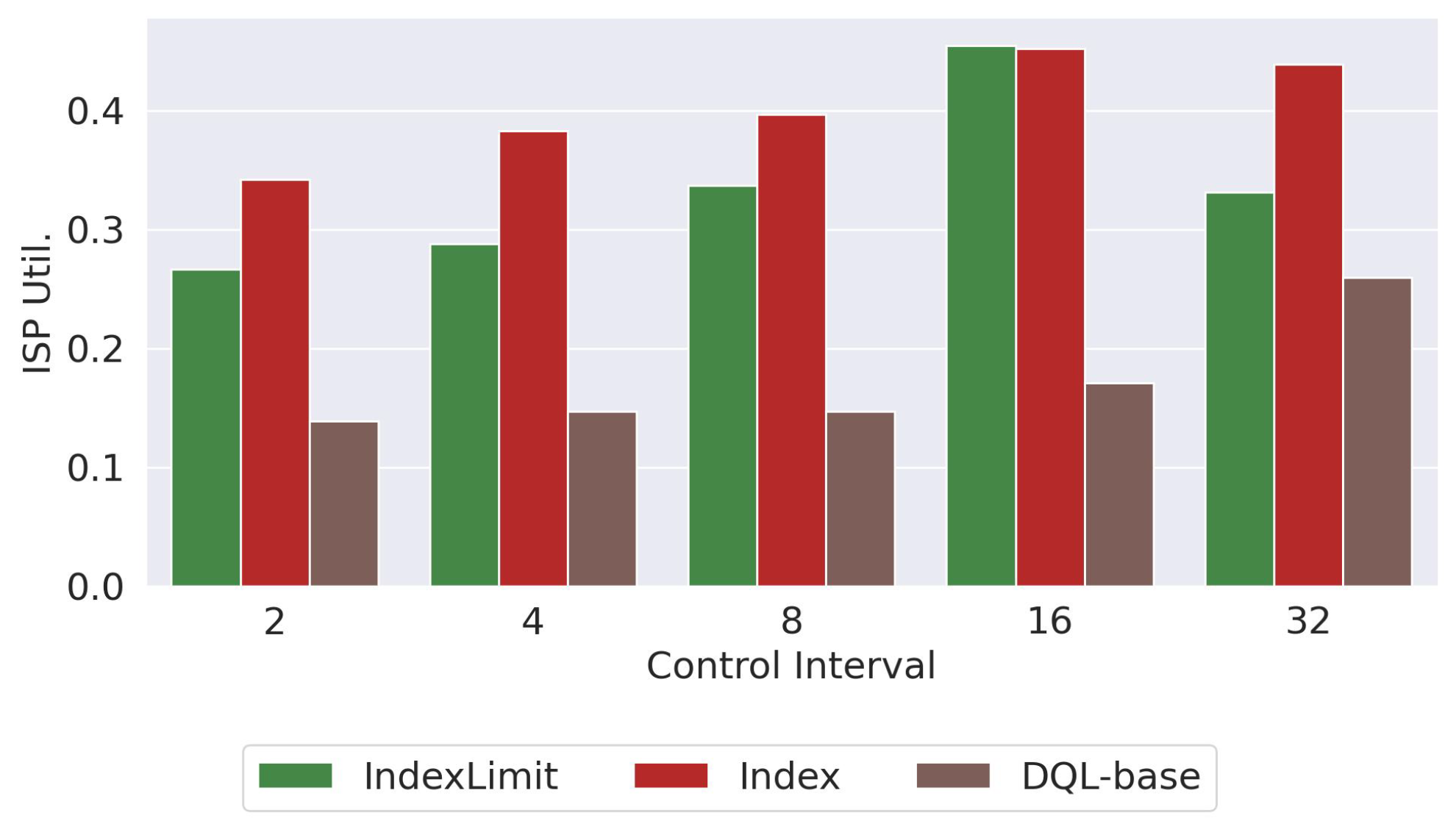
Figure 15 shows the average consensus obtained and
Figure 16 shows the processing time (
). We show the results for the
,
, and
approaches, since similar trends have been observed for the other variants.
The results show that a larger
tends to increase the IPS utilization (
Figure 14). This is mainly because as we increase the time in which the changes are made in the parameters, it takes more time to correctly adjust the values of the parameters. Then, as expected, a larger value of
increases the processing time (
Figure 16) and decreases the consensus percentage not only because the parameter control takes more time to correctly adjust the values but also because a higher ISP utilization creates a bottleneck between the peers and the server and therefore the tasks take more time to be processed.
Therefore, a large value of delays the parameter adjustment and can affect the performance of the platform. On the other hand, a small value of changes the parameters of the platform more frequently, making the platform unstable (some tasks are solved with more peers than others, the routing algorithm can change every time interval, etc.). The results show that with a all approaches achieve high consensus, low ISP utilization, and small processing times.
Additionally, using a small
time interval increases the CPU time of the metric index-based dynamic optimization approach by 66%. In the case of the
, the CPU time increases four times with the smallest
. In other words, using small intervals allows one to obtain good estimates for the metrics evaluated at the cost of a longer simulation execution time. However, as shown in previous sections (in
Figure 11), the execution time of the simulations is close to 100 s.
7.4.1. Constants , and
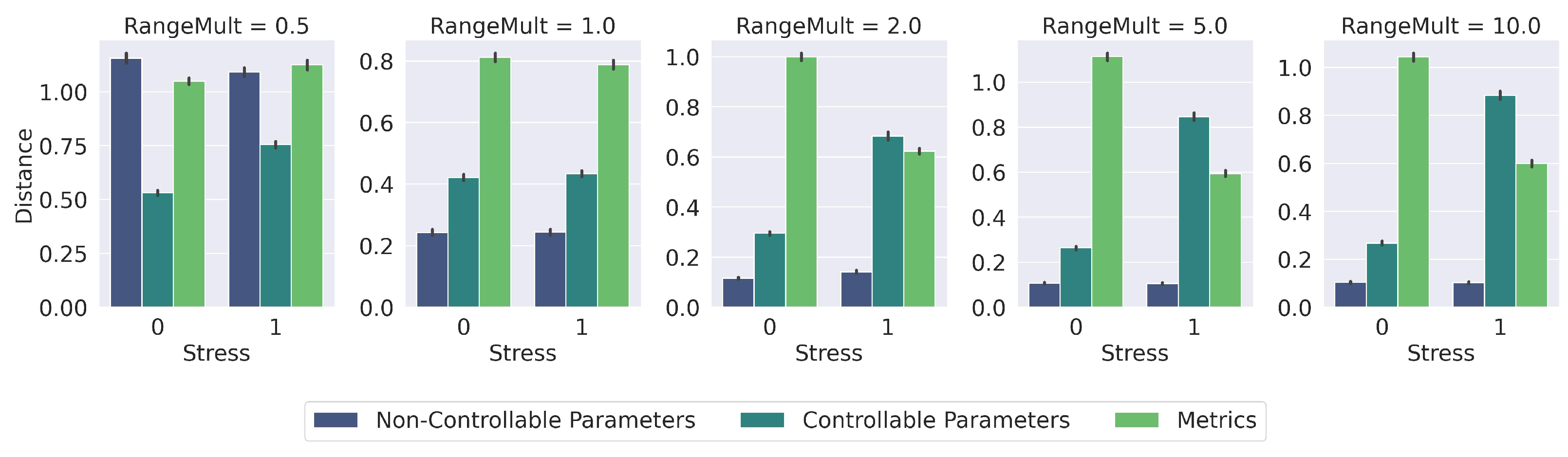
In this section, we evaluate the impact of the constants , , and that multiply the groups of variables in the vectors of the metric index. To this end, we use a ratio, . If , then, in stressful situations, , , and . If the situation is not stressed, , , and . To assess the influence of , we search for 1000 vectors in the index using different values of , for situations with and without stress.
Figure 17 shows the distance between the subset of elements of the configuration vectors. That is, given a search vector
, the index searches the top-
k closest configuration vector to
. Then, we report the distance between the subset formed of the non-controllable parameters of
and the non-controllable parameters of the top-
k vectors (blue bars). We also report the distance between the subset formed of the controllable parameters of
and the controllable parameters of the top-
k vectors (dark green bars). Finally, we report the distance between the subset formed of the metrics of
and the metrics of the top-
k vectors (light green bars). The
x-axis indicates that the evaluated scenario is under stress, 1, or without stress, 0.
To retrieve configuration vectors that match the non-controllable parameters, it is expected to obtain the smallest distances between the values of this subset of elements of search vector
and the top-
k vectors. That is, we want to retrieve configurations with similar arrival rates and numbers of volunteers as in the current situation. In
Figure 17, we show this is true when
, since the blue bars report the lowest average distance.
In non-stress situations, it is expected that the distance reported by the subset of controllable parameters is less than the distances of the subset of metrics. On the other hand, under stress situations, it is expected that the distances of the subset of metrics is less than the distances reported by the subset of controllable parameters. This is fulfilled when . With larger values of this tendency is amplified. Therefore, to grant the appropriate priority to each subset of variables in stress and non-stress situations, we have to set .
7.4.2. Metric Index Evaluation
In this section, we analyze the impact of using different metric indices on the dynamic optimization engine.
Figure 18 shows the average number of distance evaluations for a total of 1000 images. In this experiment, we use different metric space indices like the pivot index with 6 and 10 pivots and the Sparse Spatial Selection (SSS) [
58] method with different values of the
parameter. We also evaluate the List of Clusters [
59] index with different cluster sizes.
The results show that the performance of the List of Clusters (Lcluster) is highly dependent on the cluster size, reporting better results for larger cluster sizes. On the other hand, the results show that a six-pivot index—the configuration used in this work—obtains the best results. Nevertheless, if necessary, the metric index can be easily changed to a new one.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}