1. Introduction
Concrete is the world’s most popular artificial building material and comprises four simple ingredients: cement, water, coarse and fine aggregates. Fine and coarse aggregates make approximately 60−75% of the concrete volume, and significantly impact the concrete’s newly mixed and cured characteristics, mixing proportions, and economy. The majority of the present research work has focused on using waste material in concrete production and improving the performance of the existing concrete mix considering the cost-effectiveness [
1,
2,
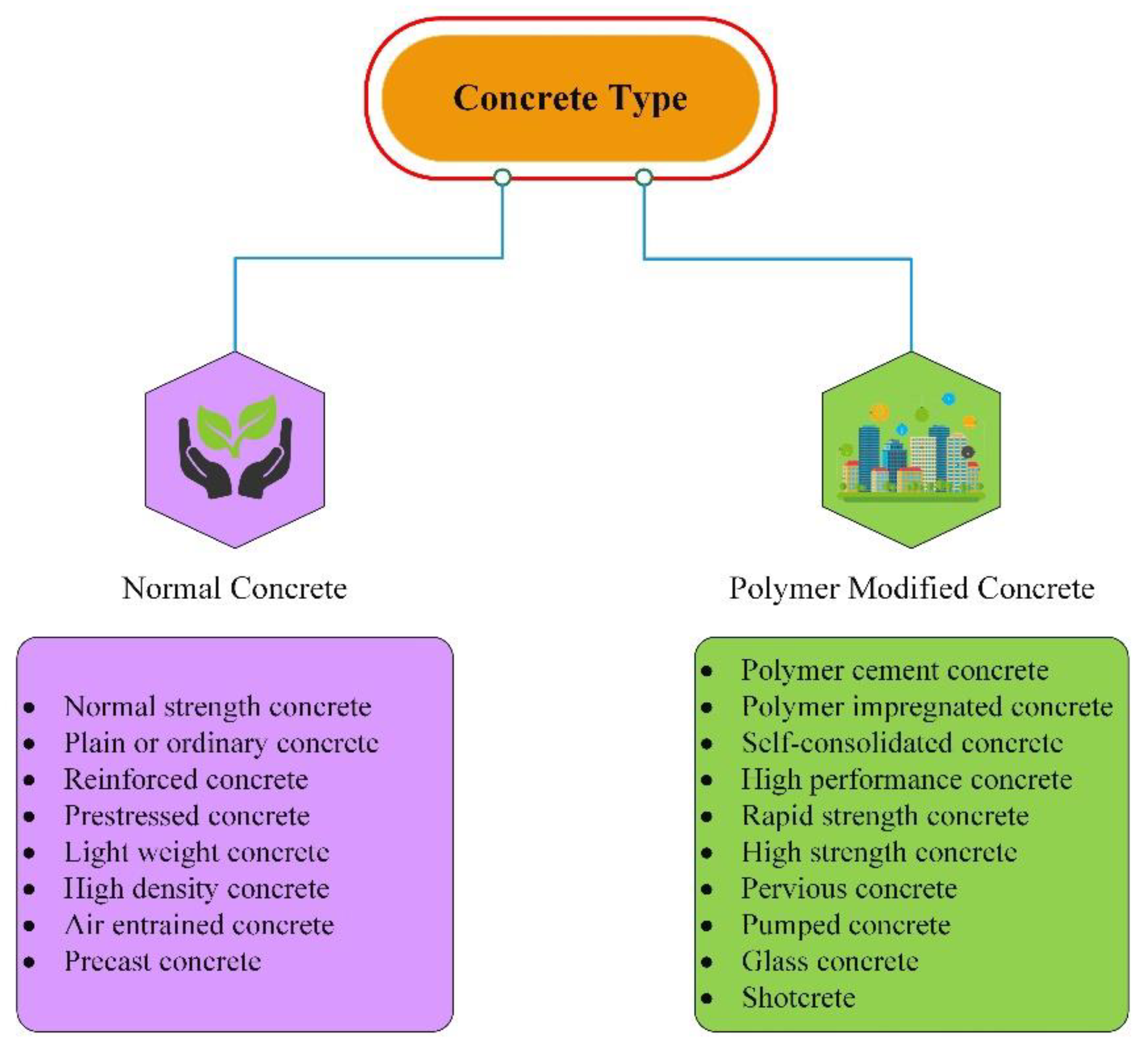
3]. The commonly used concretes are of two types, normal concrete and polymer-modified concrete, as shown in
Figure 1. The normal type of concrete contains normal-strength concrete, plain concrete, reinforced concrete, lightweight concrete, and air-entrained concrete, among other types, used in normal construction, such as small building. Polymer-modified concrete contains high-performance concrete, pervious concrete, self-consolidated concrete, and rapid-strength concrete, among other types, used in dams, tall chimneys, bridges, and multi-storey buildings. Lightweight concrete is extremely important for new construction, as well as repair and rehabilitation projects, among all kinds of concrete. The conventional technique ‘concrete jacketing’ is mainly used to strengthen/retrofit the concrete structures. However, increasing the weight, as well as a cross-section of the section, limit the use of this technique. Therefore, replacing the ordinary concrete with lightweight concrete with the same compressive strength can be an alternative solution.
Lightweight concrete is not a current concrete technology achievement. However, lightweight concrete was first used over 2000 years ago, and its innovation is still underway [
4]. The “Port of Cosa, the Pantheon Dome, and the Coliseum” are three of the most prominent lightweight concrete buildings in the Mediterranean area [
5]. They were all erected during the early Roman Empire. According to ACI 213, the term “lightweight aggregates (LWA) and lightweight concrete (LWC)” is defined “as the concrete which made up of lightweight coarse aggregates and normal weight fine aggregates with possibly some lightweight fine aggregates” [
5]. Ordinary concrete is highly heavy self-weighted, with a total deadweight of around 2400–2500 kg/m
3. LWC is 23–80% lighter than regular weight concrete, with a dry density ranging from 320 kg/m
3 to 1920 kg/m
3 [
5]. Based on the density and strength parameters, the types of LWC are categorized in
Table 1. Low-density lightweight concrete has a variety of advantages in construction, including a reduced density, low thermal conductivity, low shrinkage, and excellent heat resistance, as well as a decrease in dead load, cheaper transportation costs, and a faster construction pace [
6].
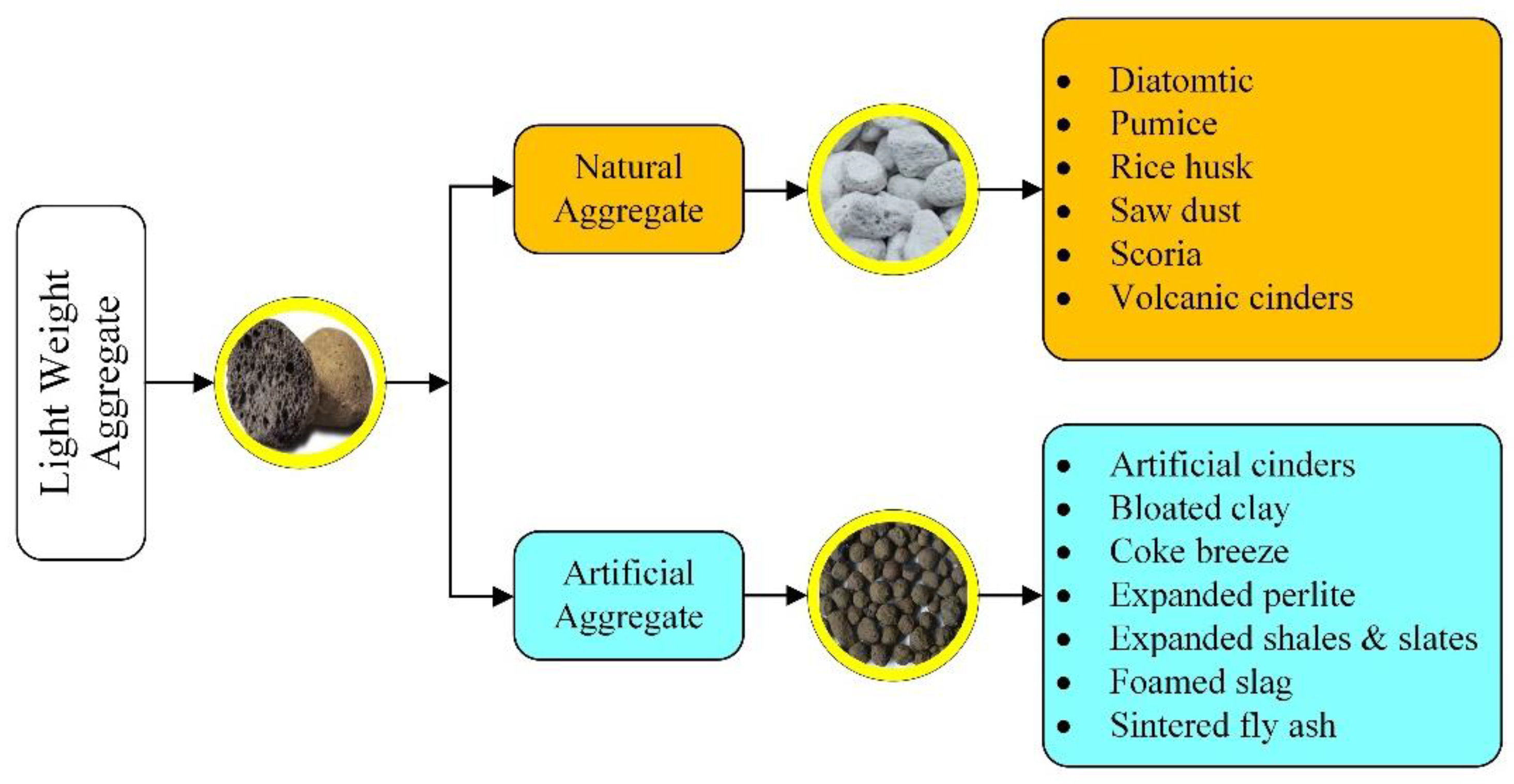
Several forms of LWA are now utilized to produce concrete lightweight, such as pumice perlite, expanded clays, shales, and other wastes, such as blended waste, agricultural waste, plastic or rubber, clay brick sintered fly ash aggregate, and oil palm shell. The commonly used methods are not considered in this study, as they are less efficient and consume more time to yield an output. In this manuscript, the most popular and efficient methods are used to determine the more accurate prediction in less time.
Compressive strength in concrete design, manufacture, and construction is regarded to be a basic performance criterion [
7], and the 28-day compressive strength has been the most often utilized metric in many classical studies. The use of machine learning on laboratory data to estimate the 28-day compressive strength and other concrete parameters began in the early 2000s [
8]. The prediction using ML models reduced the laboratory time, waste of constituents of concrete, and the cost. The various studies that have used ML to predict the compressive strength of a variety of concretes are described below.
Asteris et al. [
9] used GPR, linear and non-linear multivariate adaptive regression splines (MARS-L and MARS-C), neural network (NN), and minimax probability machine regression (MPMR) to predict the compressive strength of concrete. The new hybrid model, called the hybrid ensemble model (HENSM), was used to compare the performance of four conventional models. Based on the experimental results, the HENSM model has the potential to be a new option for dealing with Conventional Machine Learning (CML) model overfitting difficulties and, therefore, may be used to forecast concrete compressive strength in a sustainable manner. Alshihri et al. [
10] forecasted the compressive strength of concrete using an artificial neural network (ANN). In the ANN, two methods were utilized, called the feed-forward backpropagation (FFBP) and cascade correlation (CC) methods. Eight input variables—cement, water, w/c ratio, lightweight fine aggregate, sand, lightweight coarse aggregate, silica fume as a solution, superplasticizer, replacement of cement with silica fume, and curing period—were used to predict the compressive strength. The correlation coefficient of training and testing were 0.972 and 0.977 for BP, and 0.974 and 0.982 for CC. Compared to the BP technique, the CC neural network model predicted marginally more accurate outcomes and learned much faster.
Omran et al. [
11] compared the data mining techniques to predict the compressive strength of environmentally friendly concrete. Four regression tree models and two ensemble methods were used in his study. The individual GPR model and its associated ensemble models had the greatest prediction accuracy in the comparison groups. Yaseen et al. [
12] used four machine learning models, namely extreme learning machine (ELM), MARS, M5 Tree models, and SVR, to estimate the compressive strength of lightweight foamed concrete. Cement content, w/c ratio, oven-dry density, and foamed volume of aggregates were input factors for the prediction models. The findings demonstrated that the suggested ELM model improved the SVR, M5 Tree, and MARS models in terms of prediction accuracy. The ELM model may be used as an accurate data-driven method for forecasting the compressive strength of foamed concrete, avoiding the need for time-consuming trial batches to achieve the desired product quality.
Kandiri et al. [
13] predicted the compressive strength of recycled aggregates using a modified ANN. The results of the ANN model were optimized with the help of the salp swarm algorithm (SSA), genetic algorithm (GA), and grasshopper optimization algorithm (GOA) techniques. The SSA-ANN model showed better accuracy compared to other models. Bui et al. [
14] used a hybrid whale optimization algorithm (WOA)-ANN to estimate the compressive strength of concrete. Two other benchmark techniques, the dragonfly algorithm (DA) and ant colony optimization (ACO), were used to validate the accuracy of the model. The findings showed that the WOA-ANN outperformed the DA-ANN and ACO-ANN models. The accuracy of the WOA-ANN, GA-ANN, and ACO-ANN models were 89.76%, 82.09%, and 80%, respectively.
Sharafati et al. [
15] predicted the compressive strength of hollow concrete prism with a bagging ensemble model. Three modelling scenarios based on distinct data divisions (i.e., 80–20%, 75–25%, and 70–30%) were used for the training and testing stages. The bagging regression (BGR) results were compared with the SVR and decision tree regression (DTR) models. The BGR model achieved a low root mean square error (RMSE = 1.51 MPa) in the testing phase while employing the 80–20% data division scenario, whereas the DTR and SVR models achieved RMSE = 2.55 and 2.33 MPa, respectively. Xu et al. [
16] used ML to forecast the compressive strength of ready-mix concrete. Random forest (RF) was used as the modelling technique to predict the compressive strength from the selected influential elements after GA was used to find the most relevant influential factors for compressive strength modeming. A case study was used to assess the efficiency of the suggested model, and the highest R-value was 0.9821 and lowest MAPE and delta values were 0.0394 and 0.395, respectively, showing that the model can produce precise and dependable outcomes.
The work in this research article is categorized into five parts.
Section 2 provides a detailed overview of the formation of lightweight concrete and defines the lightweight aggregate.
Section 3 is related to the collection of lightweight aggregate from the literature and the processing of the raw data.
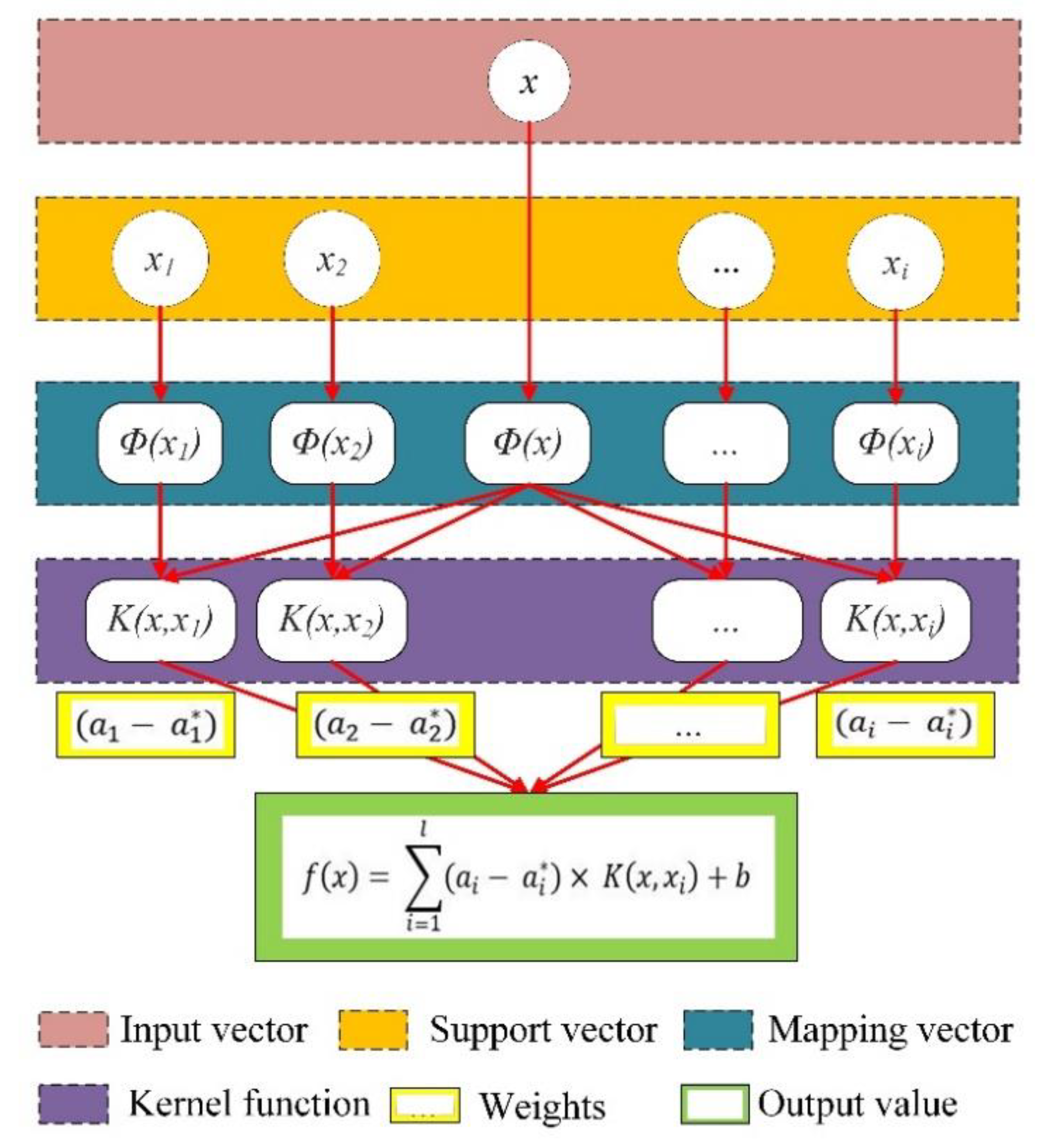
Section 4 describes the overview of the selected machine learning algorithms. The results and discussions are mentioned in
Section 5, and the conclusion of the article is explained in
Section 5.
3. Collection of LWC Data
To build the models for predicting compressive strength in this study, a complete database of 194 different experimental records of concretes was compiled from the literature [
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40]. In this study, only one target parameter was considered, that is, the compressive strength of concrete (f
ck). The input parameters used in this article are the basic constituents of the concrete mix, such as cement (C), water content (W), fine aggregate (FA), normal weight coarse aggregate (NWCA), lightweight coarse aggregate (LWCA), and water-cement ratio (w/c). The only one output parameter is considered that is compressive strength (f
ck) of LWC.. The ranges of these parameters are from 208.57 to 640 Kg/m
3, from 93.86 to 251 Kg/m
3, from 150 to 1096 Kg/m
3, from 0 to 1083 Kg/m
3, from 0 to 730 Kg/m
3, from 0.25 to 0.55, and from 19 to 96 N/mm
2, respectively, as shown in
Table 2.
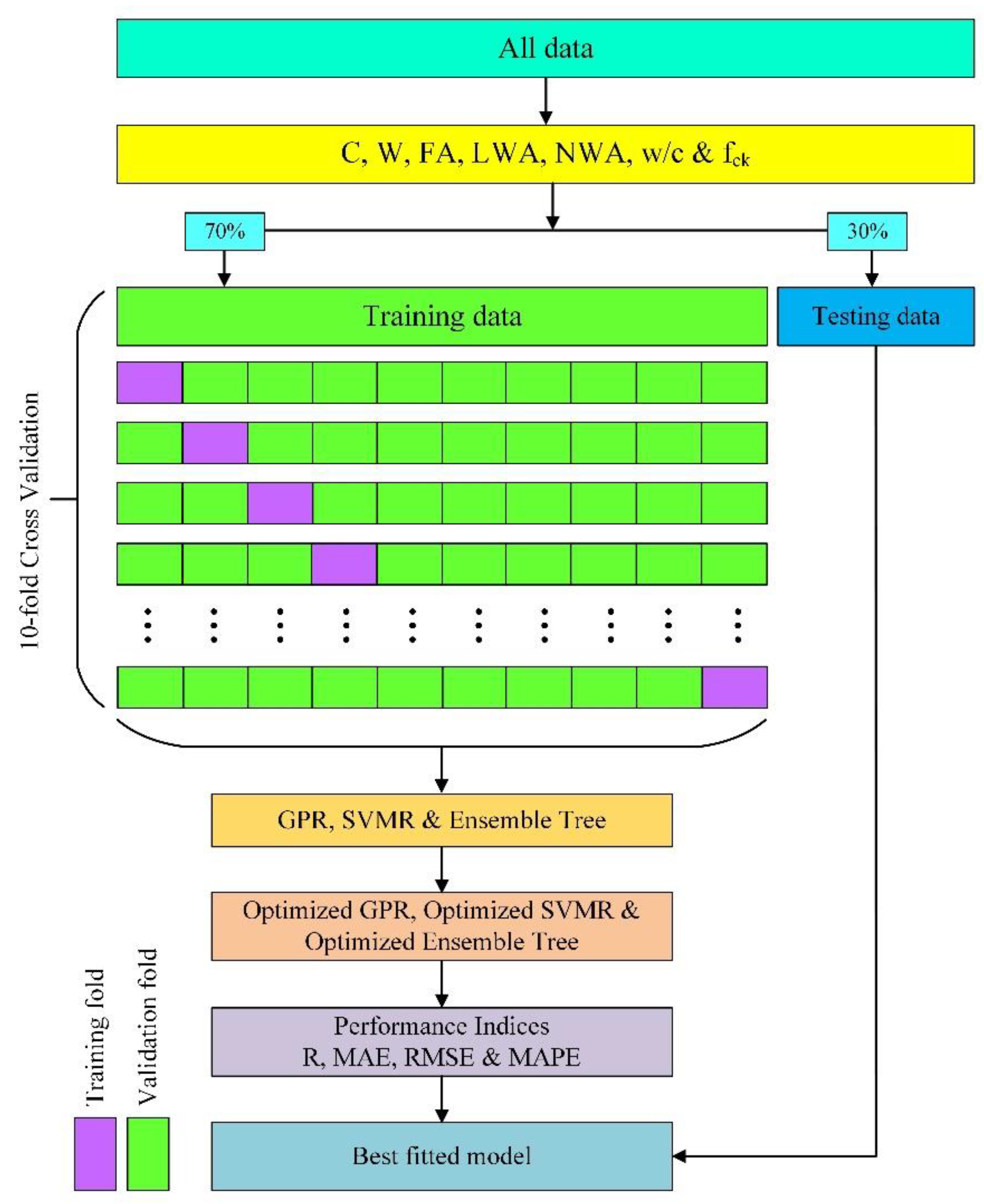
The original test database was filtered according to the following principles to increase the database’s dependability: (a) One test dataset should be removed from a dataset with the same test parameters if the goal value compressive strength differs by more than 15% from the other test data and the other test data points differ by less than 15%. (b) If the difference between any two test data points in a set of data under the identical test conditions is greater than 15%, the entire data group must be discarded. The 194 test data points were eventually reduced to 120 remaining data points using the aforementioned data filtering procedures.
Table 2 shows the descriptive statistics of the collected database.
Data normalization was performed before processing the data in the machine learning algorithms. The normalization process reduces the undesired feature scaling effects and provides higher computational stability. All parameters were normalized in the range from 0 to 0.9 using Equation (1) [
41].
where
y* is the value to be normalized,
y is the original value in the dataset,
ymax is the maximum value in the desired dataset, and
ymin is the minimum value in the desired dataset.
Six frequently used performance indices such as correlation coefficient (R), root mean squared error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) [
42], a20-index [
43], and Nash-Sutcliffe (NS) efficiency index [
44]—are used to analyse the performance of selected machine learning models. R and NS values closer to one indicate a better relationship between the desired result, but R values greater than 0.85 indicate a substantial relationship. The lower the values of MAPE, RMSE, and MAE, the greater the performance of the selected models. Equations (2)–(7) [
42,
43,
44] show the relevant expressions of the R, MAE, MAPE, RMSE, NS, and a20-index, respectively. These indices’ relevant expressions are given in Equations (2)–(7). The scatterplot matrix of the collected data is shown in
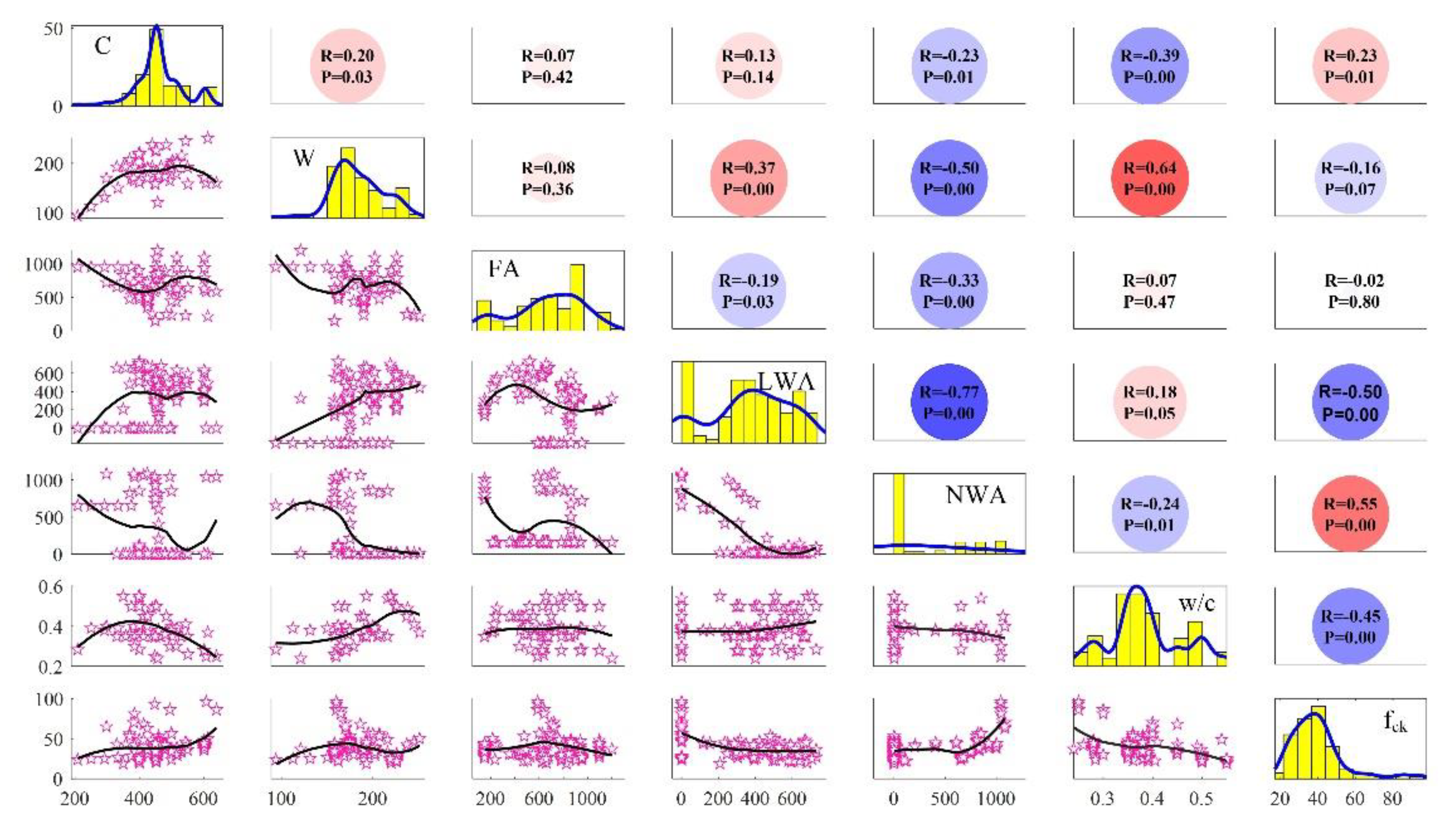
Figure 4.
Figure 4 shows the correlation coefficient of each input and output value, as well as the correlation with each variable. A probability (
p-value) is assigned to the correlation coefficients, indicating the likelihood that the link between the two variables is zero (null hypotheses; no relationship). Strong correlations have low p-values because the chances of the correlations not being related are exceedingly small.
where
N is the number of samples in the datasets,
is the experimental value at the
ith level,
is the mean of experimental values,
is the predicted value at the
ith level, and
is the mean of predicted values.
m20 is the number of samples with values rate measured/predicted values (range between 0.8 and 1.2).
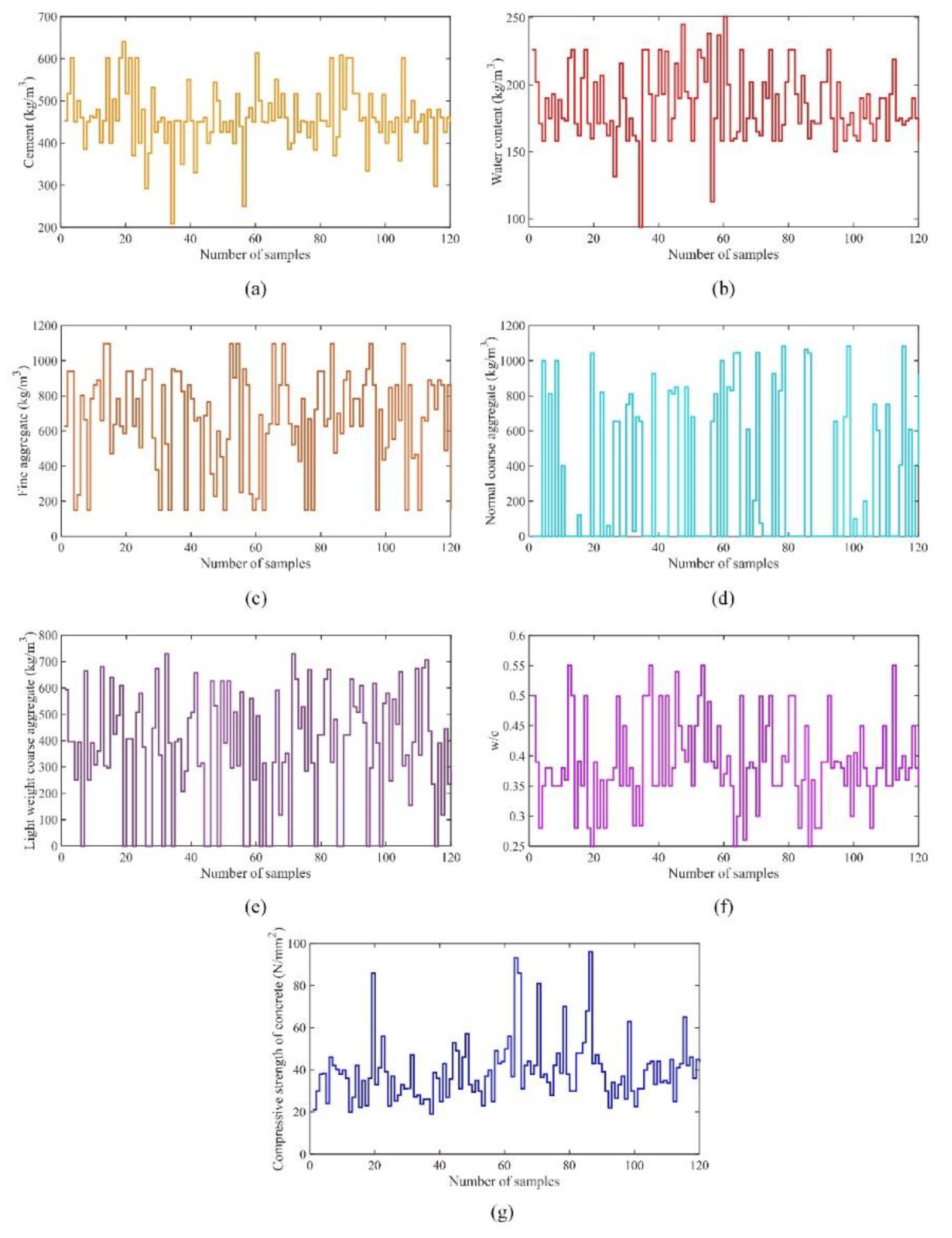
Figure 5 shows the distribution of the input and output parameters for each dataset.
Figure 5a shows the distribution of cement content with the number of samples in the dataset,
Figure 5b shows the distribution of water content with the number of samples in the dataset,
Figure 5c shows the distribution of fine aggregate with the number of samples in the dataset,
Figure 5d shows the distribution of normal weight coarse aggregate with the number of samples in the dataset,
Figure 5e shows the distribution of lightweight coarse aggregate with the number of samples in the dataset,
Figure 5f shows the distribution of the water-cement ratio with the number of samples in the dataset, and
Figure 5g shows the distribution of the compressive strength of concrete with the number of samples in the dataset.
6. Conclusions
The purpose of this study was to compare the different ML-based prediction models used for predicting the compressive strength of LWC based on the dataset characteristics. The compressive strength of LWA was predicted using various algorithms, such as GPR, SVMR, EL, optimized GPR, optimized SVMR, and optimized EL. In total, 120 datasets were used in this study, which were taken from the literature. The prediction of the lightweight concrete fck was predicted using all the concrete parameters (C, W, FA, LWCA, NWCA, w/c) provided in the database. R, RMSE, MAE, MAPE, NS, and a20-index statistical indices were used to evaluate and compare the prediction accuracy of different models. The following conclusions were drawn:
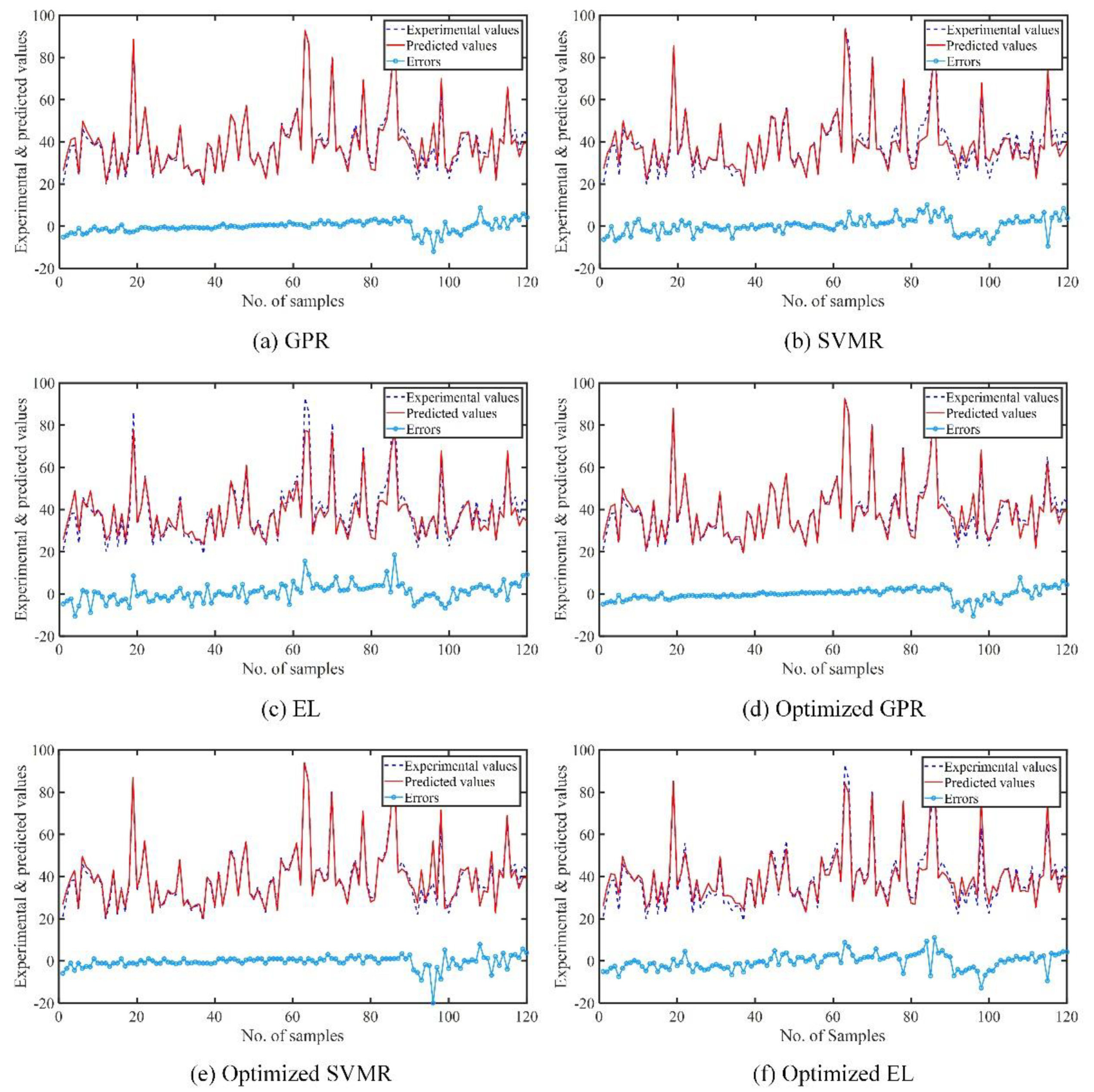
The conventional and optimized machine models used for forecasting the compressive strength of LWC performed well.
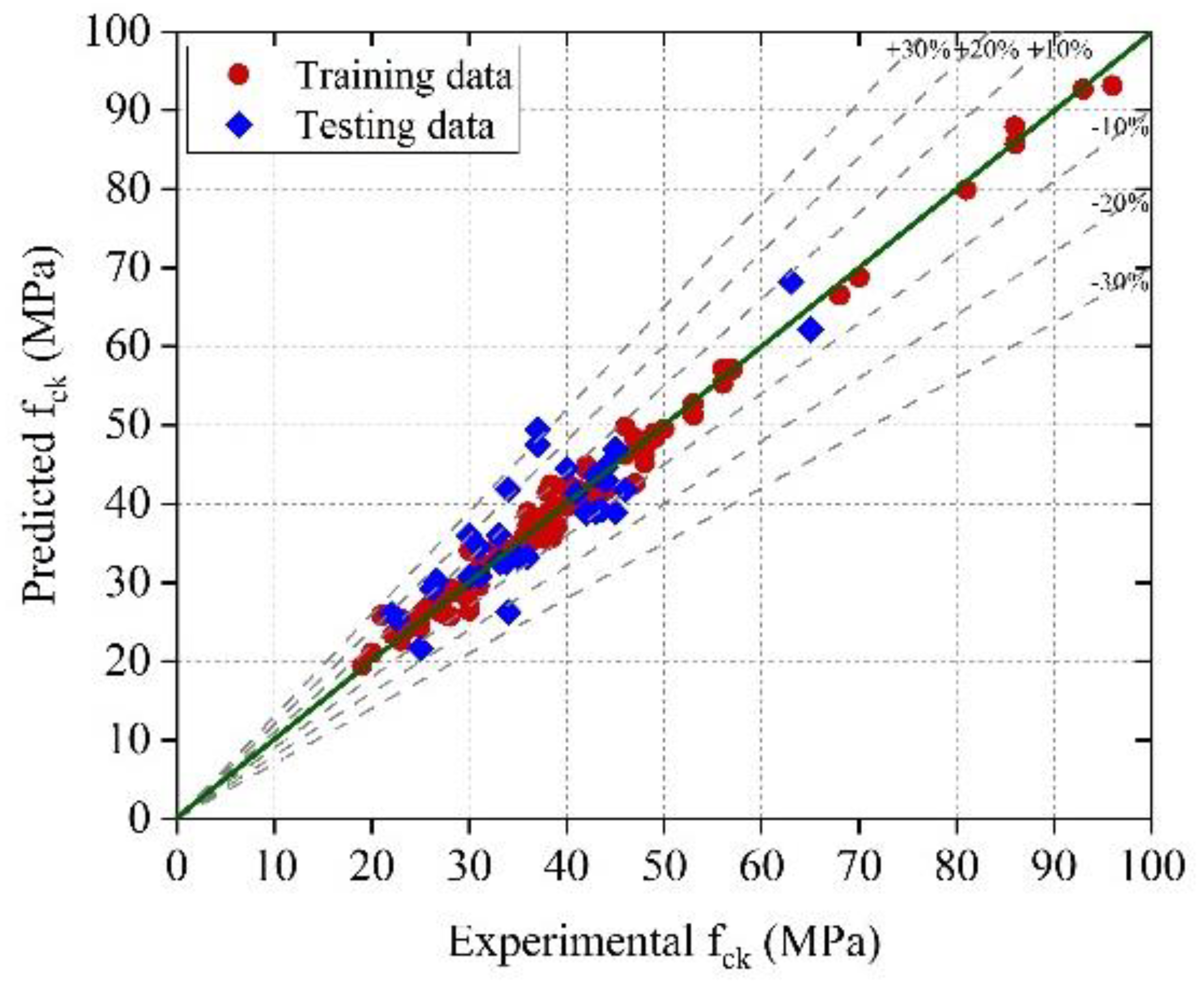
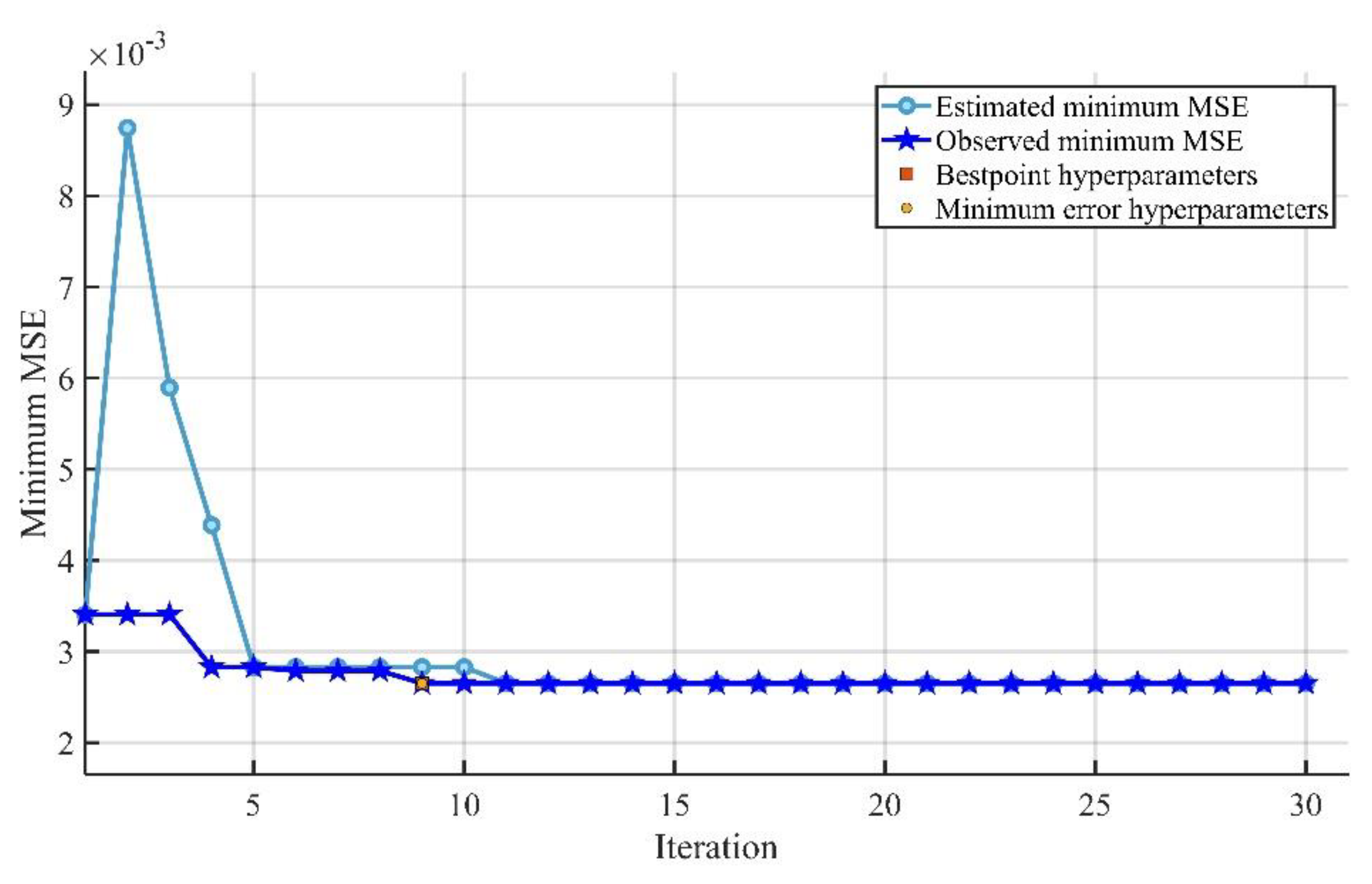
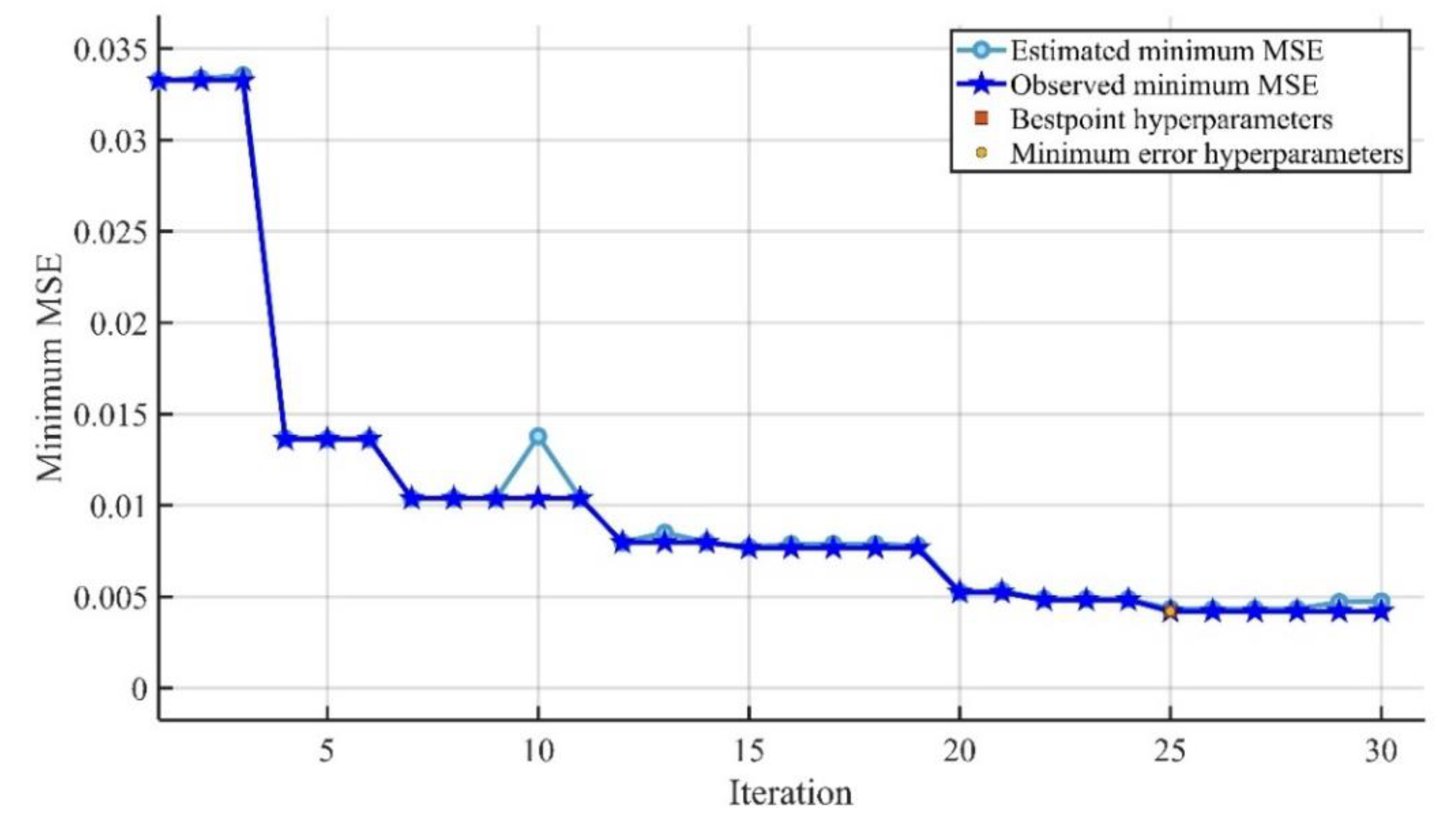
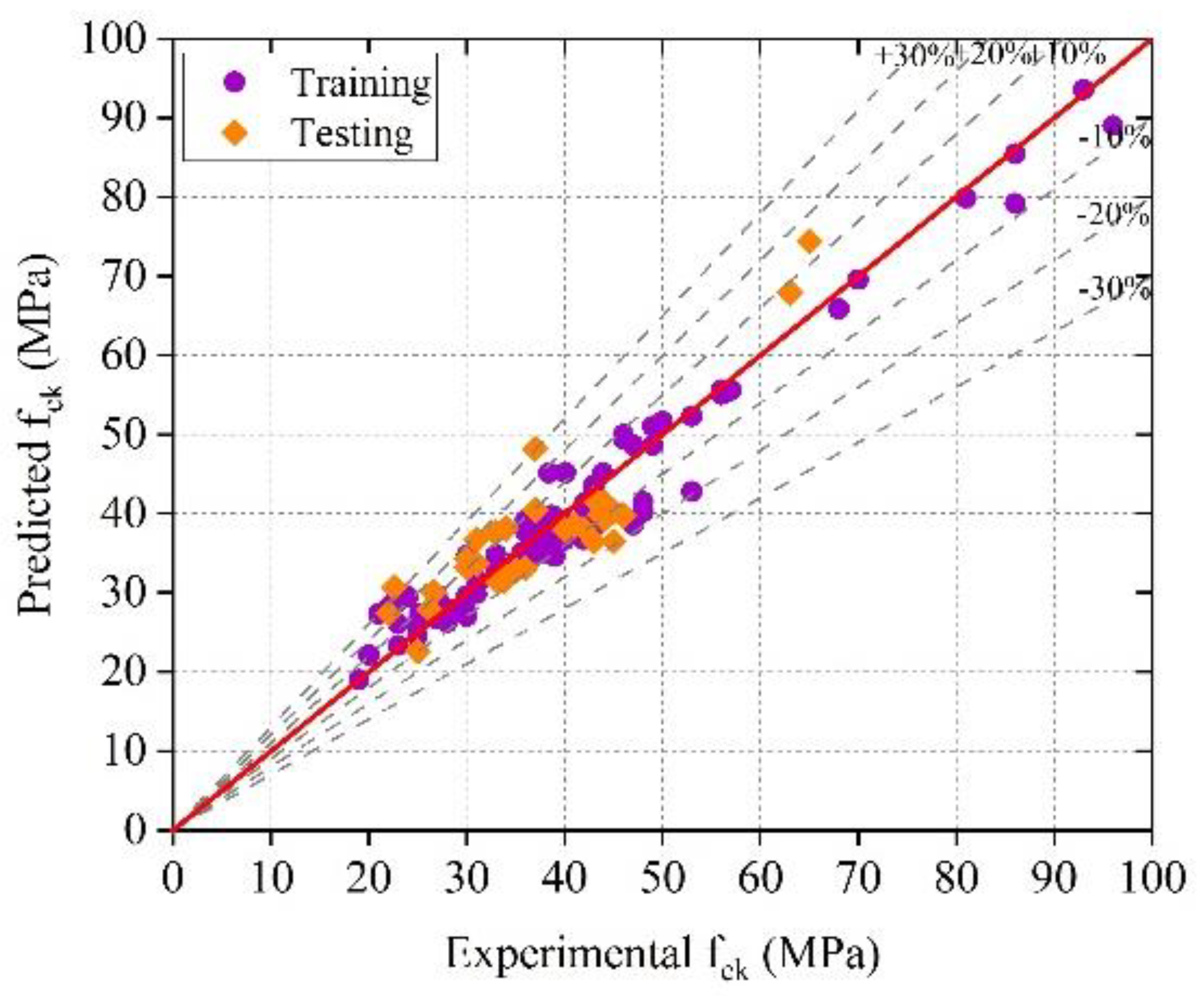
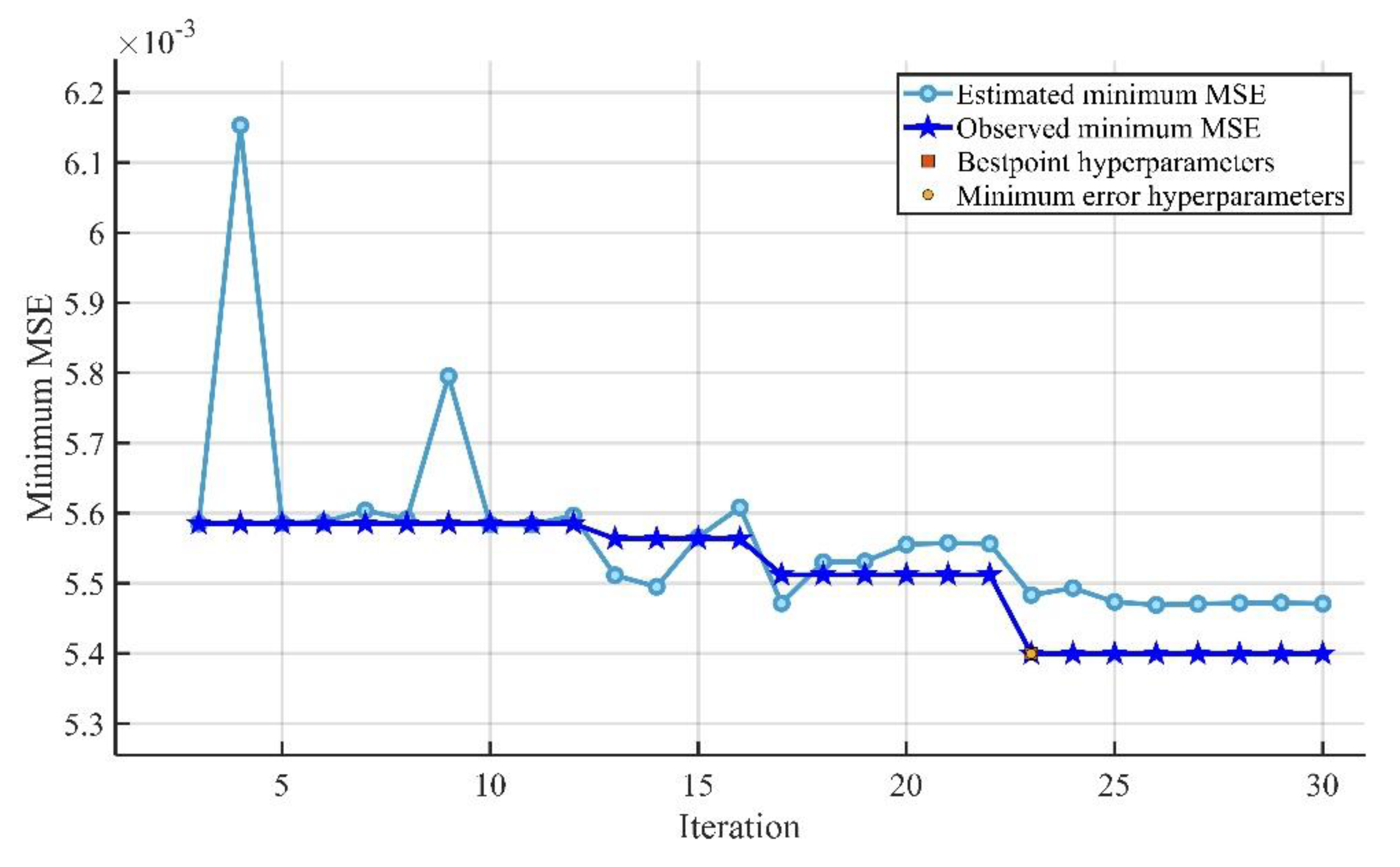
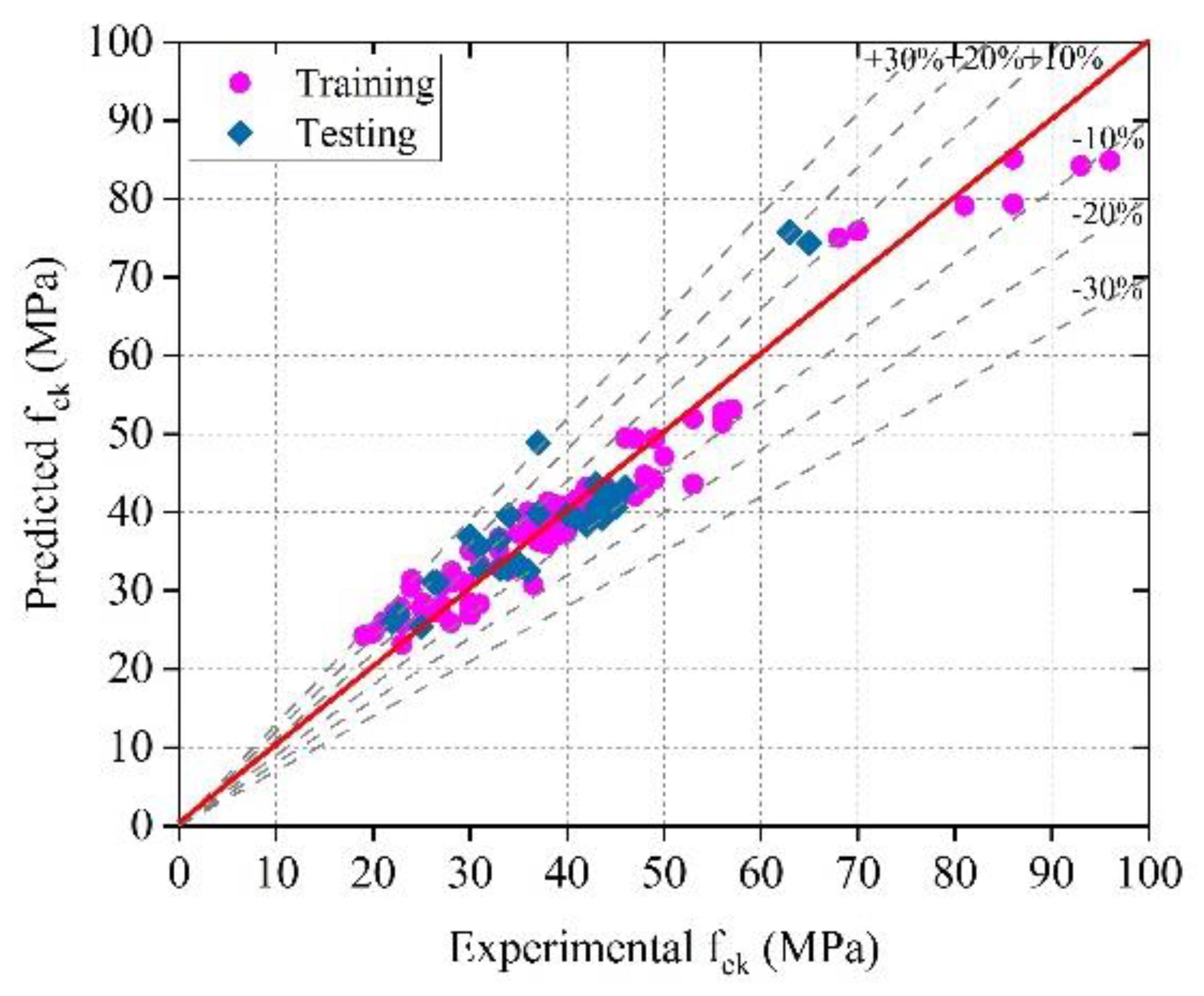
The optimized GPR model had the greatest accuracy, with less variation in the experimental and predicted values in terms of errors.
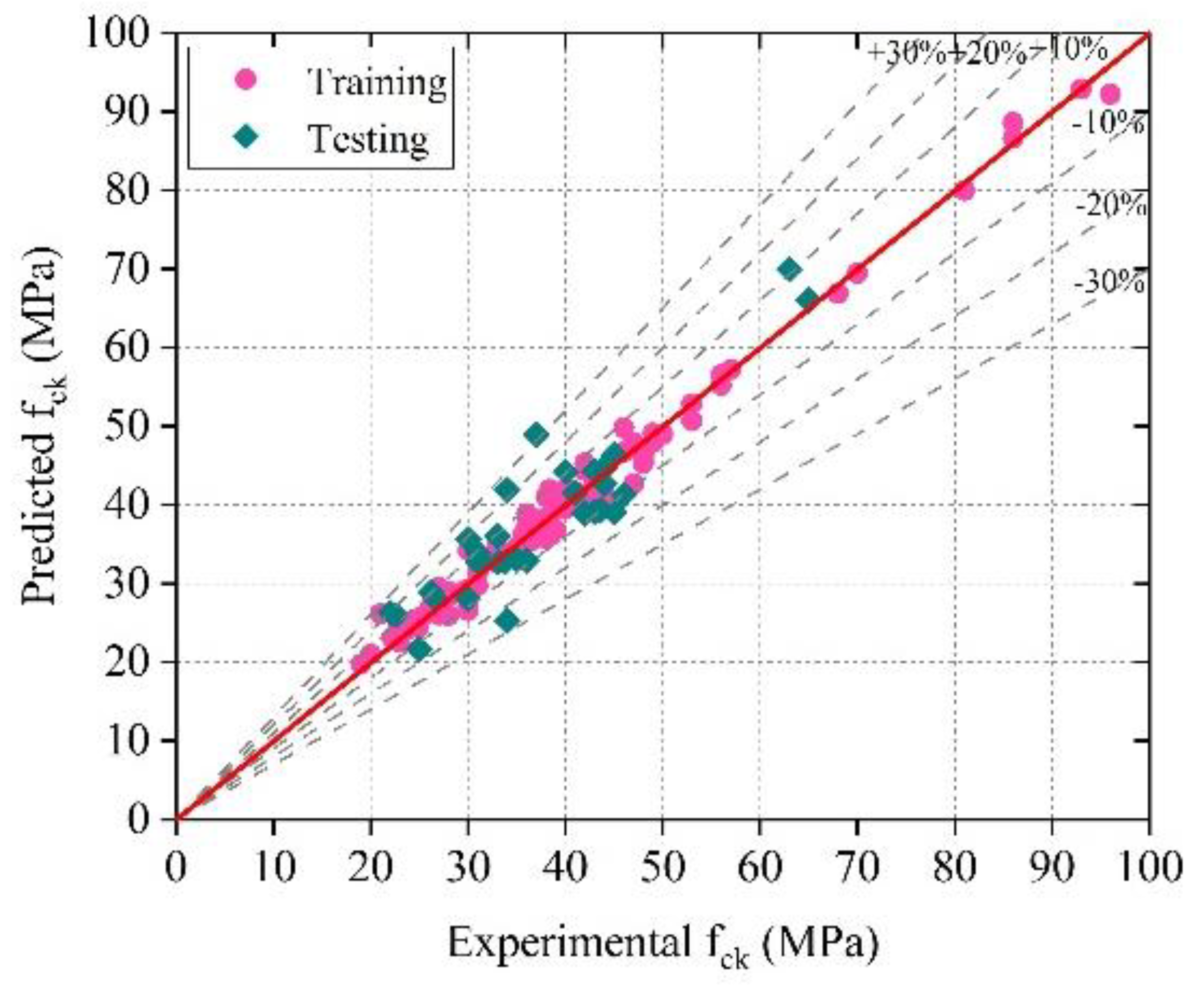
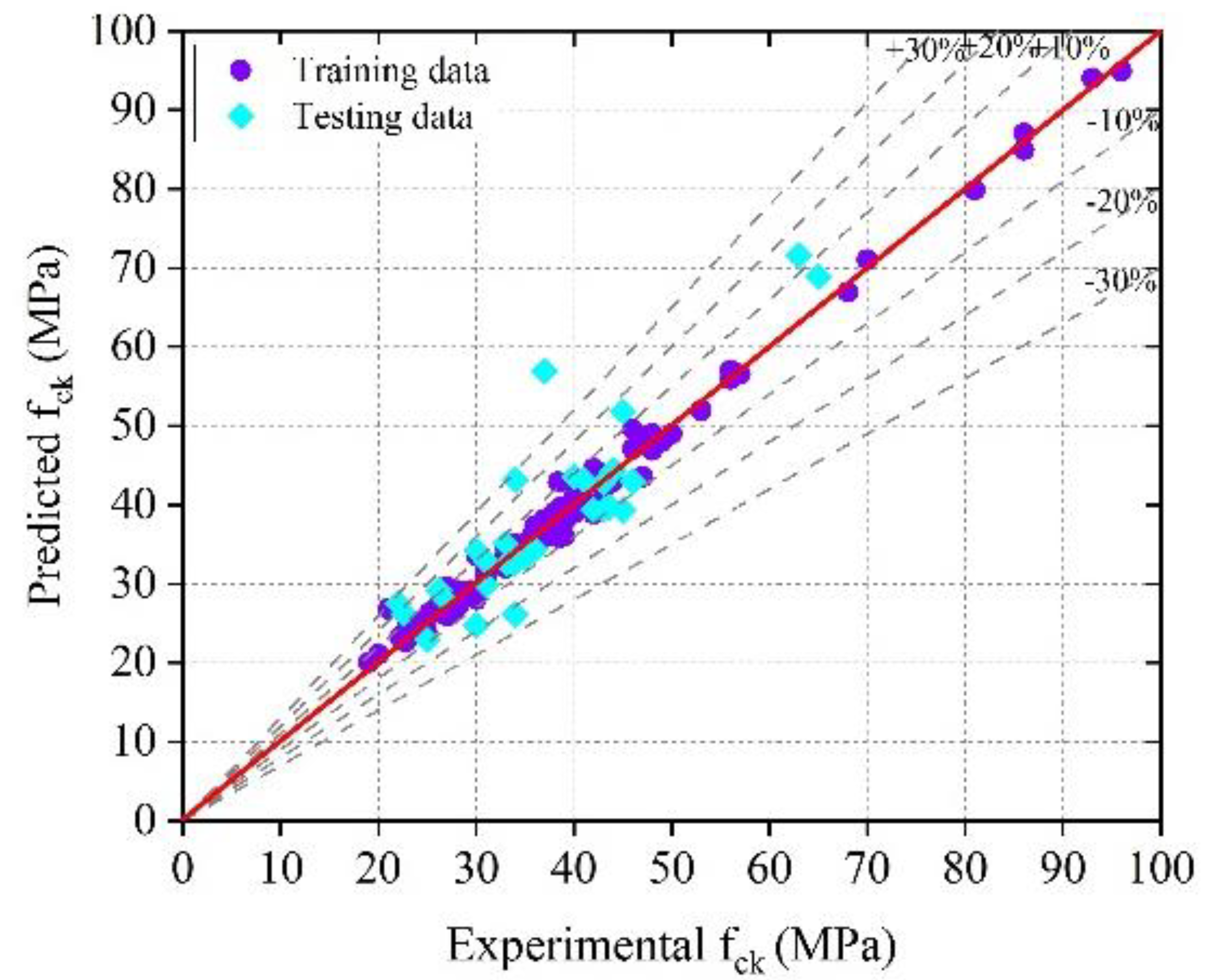
The optimized GPR model provided training and testing correlation coefficients (R) of 0.9933 and 0.8915, respectively, and the optimized SVMR model provided training and testing correlation coefficients (R) of 0.9947 and 0.8882, respectively. The results indicate that the optimized GPR and SVMR models can predict the compressive strength with higher reliability and accuracy.
The accuracy of the ML models decreased (based on the R, MAE, MAPE, and RMSE assessment criteria) in the following sequence: optimized GPR, optimal SVMR, GPR, SVMR, Optimized EL, and EL.
The machine learning models were excellent in capturing the intricate nonlinear correlations between the six input parameters and compressive strength. They may be used to quickly assess the compressive strength of LWC without the need to perform expensive and time-consuming experiments. More crucially, the machine learning-based estimation tools enable easy exploration of essential parameters, resulting in a cost-effective and trustworthy design. The machine learning approach is a strong instrument for engineering analysis. The proposed optimized GPR model can only perform effectively for data that fall within the range of the datasets used for creating the models, which is a limitation of this study. The accuracy of these models can be further enhanced using a metaheuristic algorithm and by adding more parameters in the database. In future work, the density of lightweight concrete can be predicted.



 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}