

Study on Transportation Carbon Emissions in Tibet: Measurement, Prediction Model Development, and Analysis

 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
2.1. The Focus of This Study
2.2. Contributions
3. Transportation Carbon Emissions Measurement
3.1. Measurement Method
3.2. Measurement Data
3.3. Measurement Results and Analysis
4. Prediction Model Construction and Improvement
4.1. Selection of Input Variables
4.2. Data Preprocessing
4.3. Model Construction
4.4. Model Evaluation
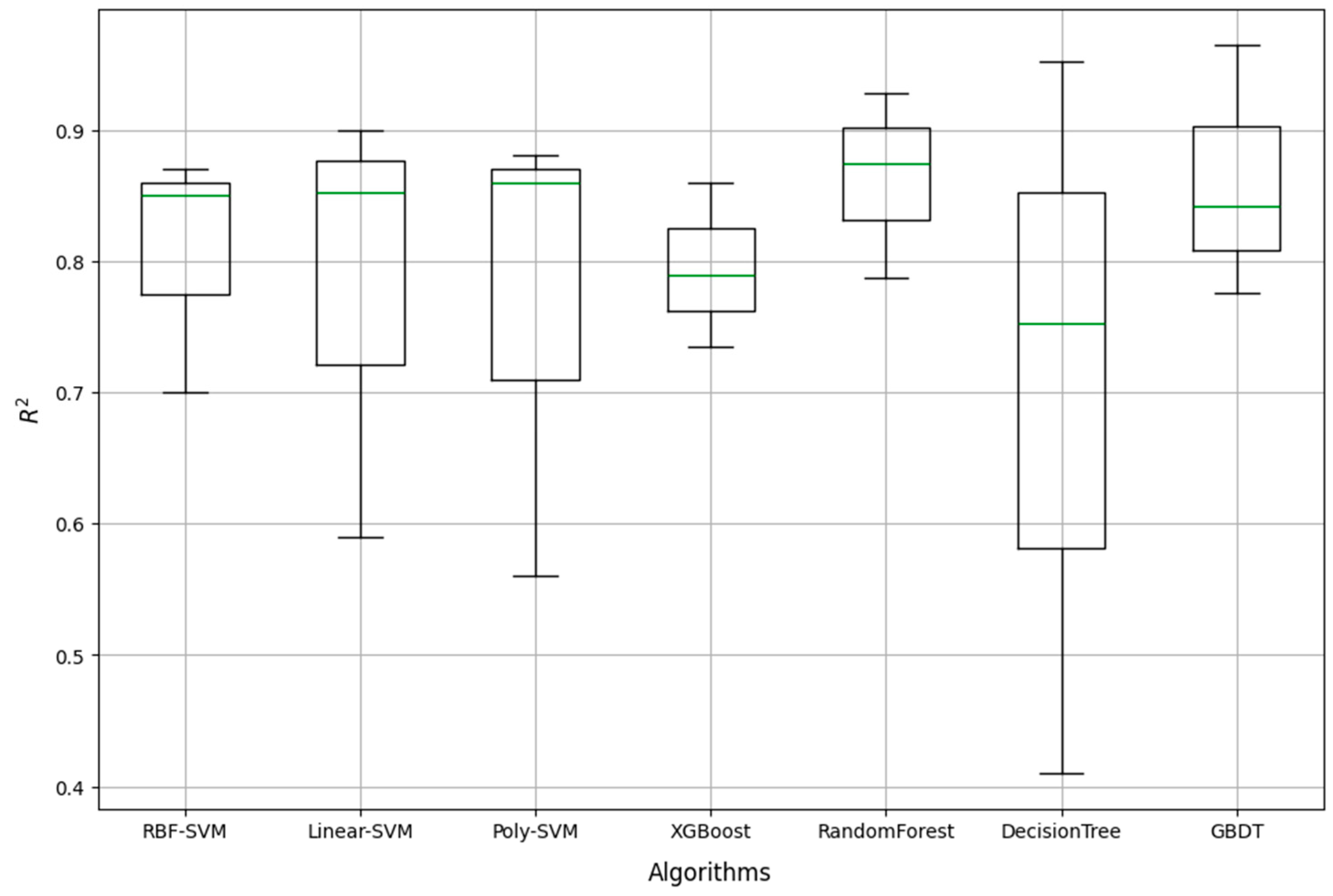
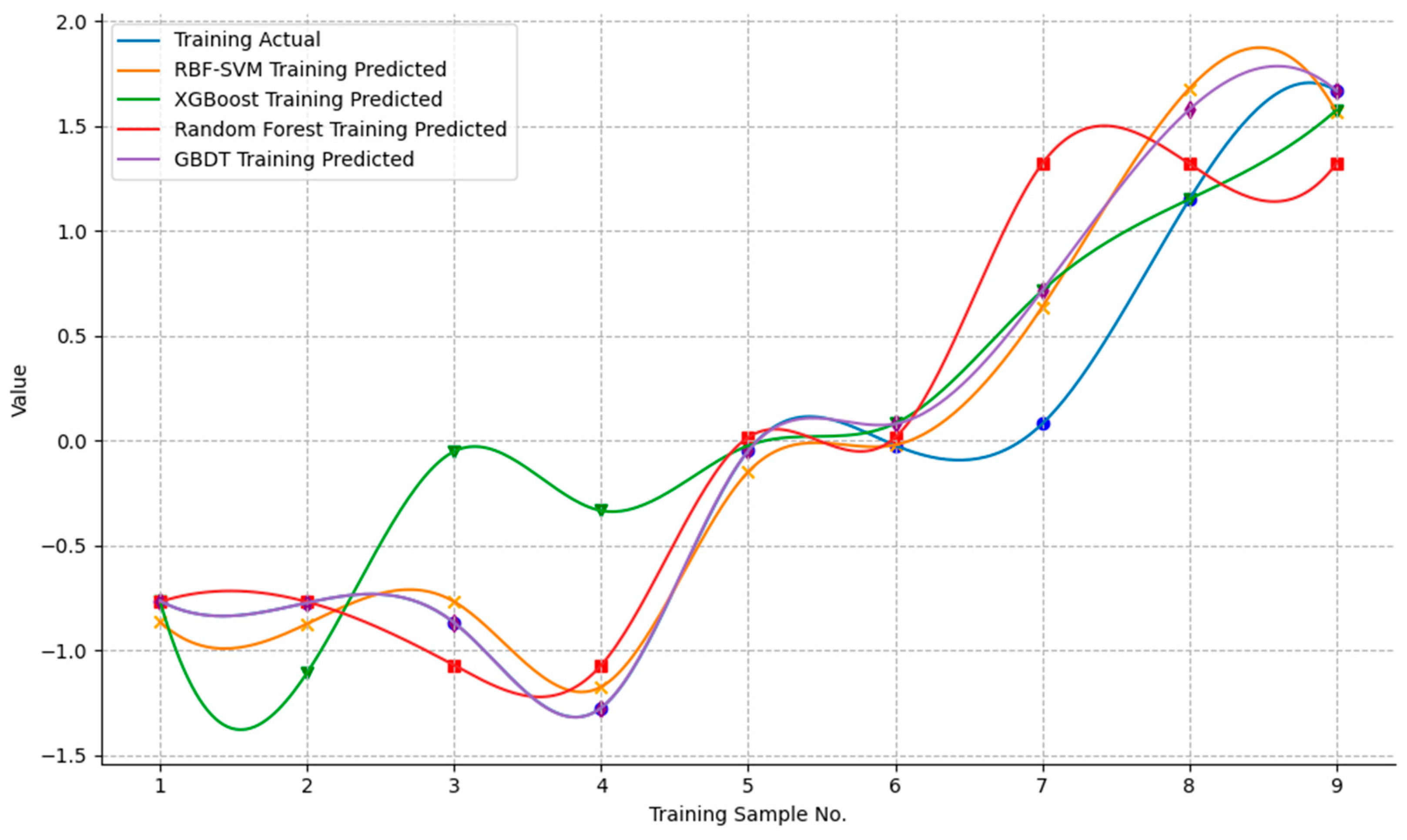
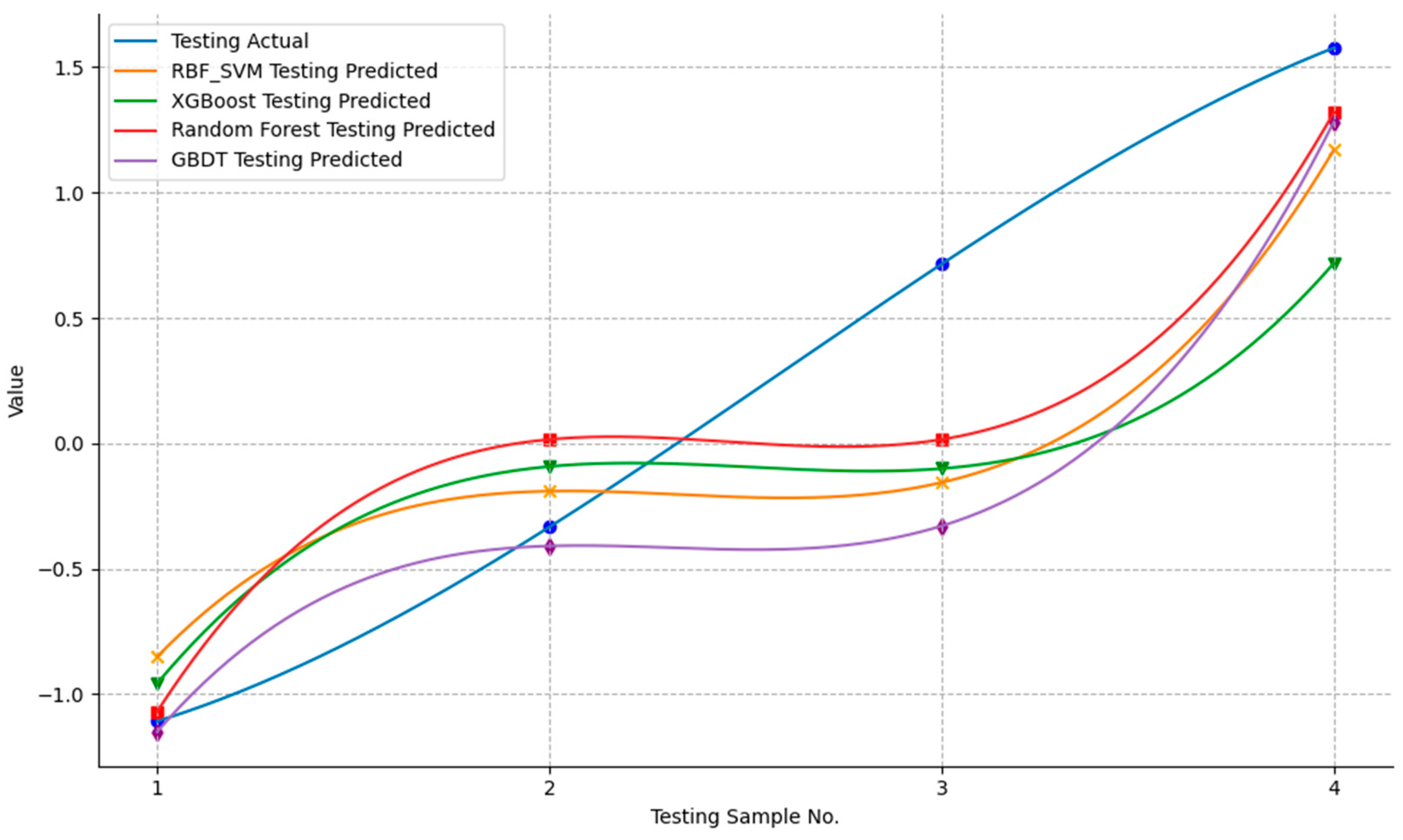
4.4.1. Model Comparison
4.4.2. Evaluation Metrics
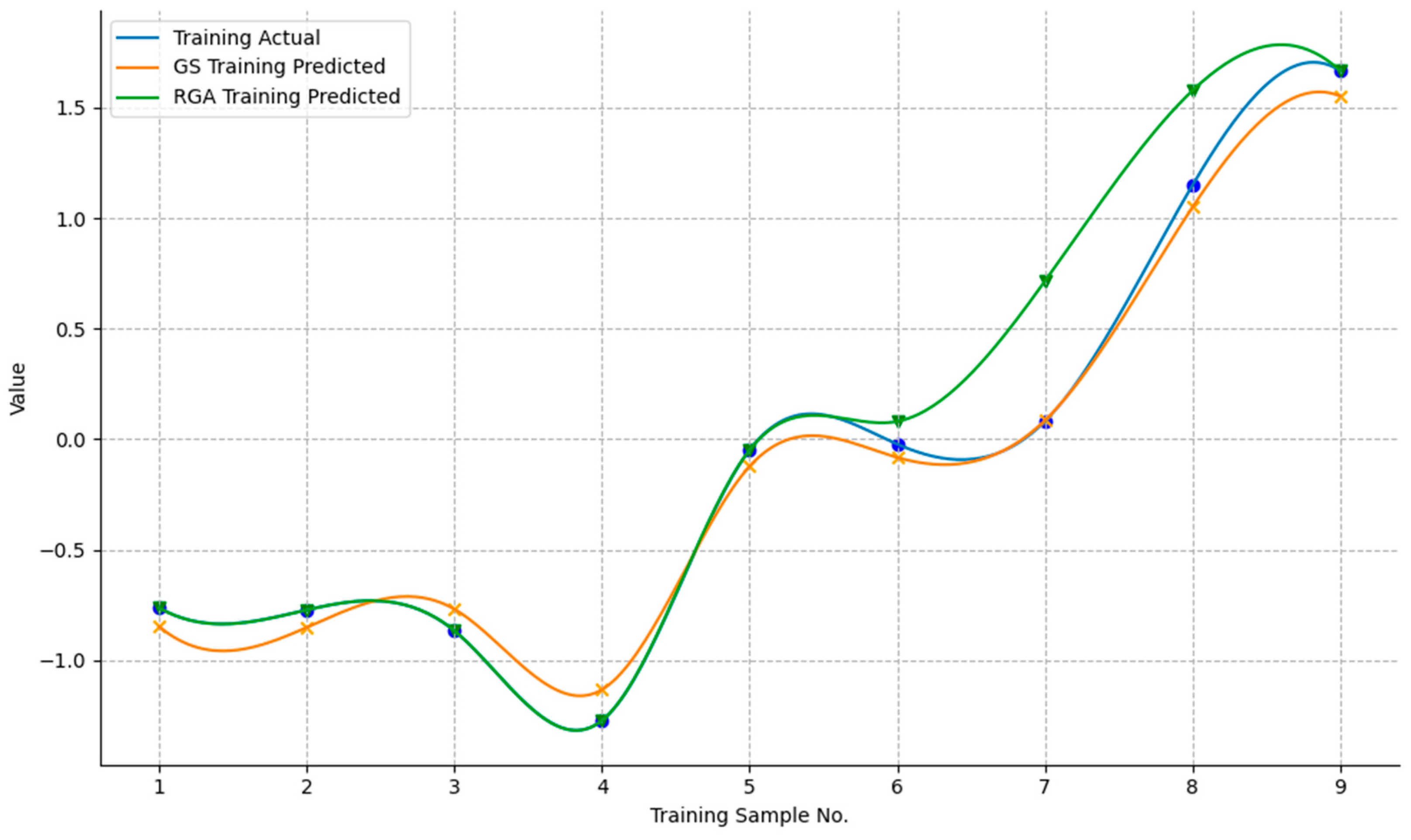
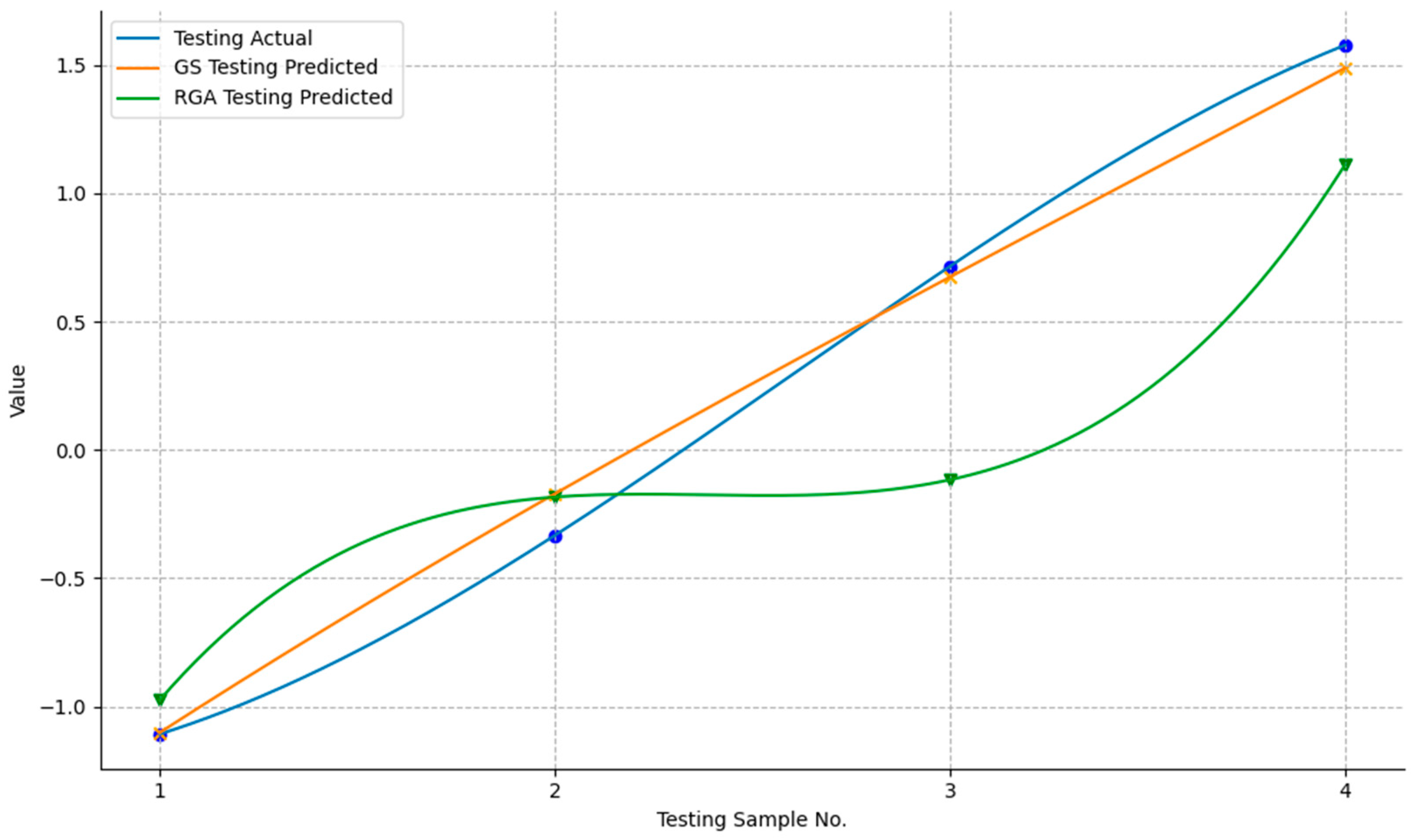
4.4.3. Model Evaluation Results
4.5. Model Improvement
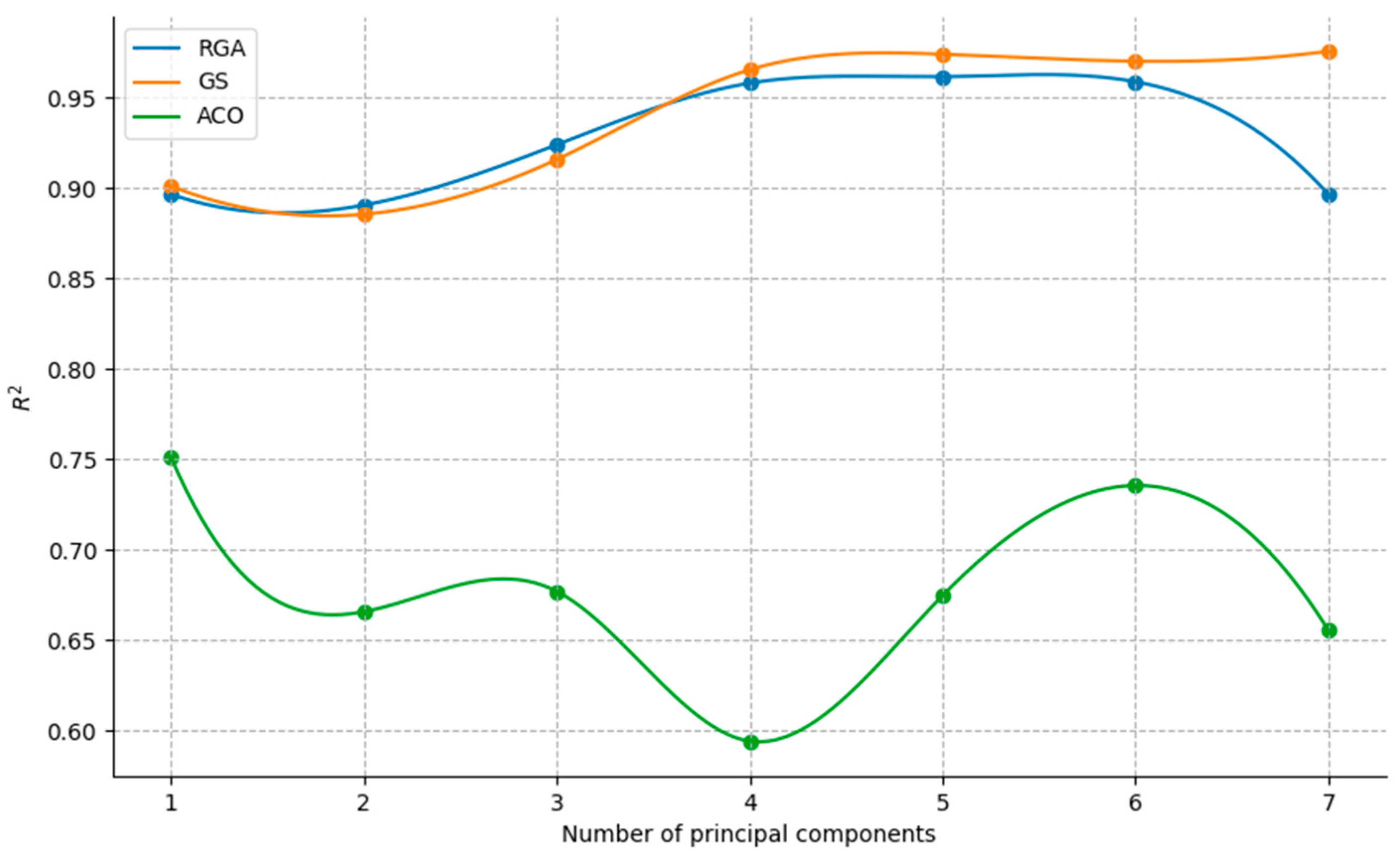
4.5.1. Initial Selection of Improved Model
4.5.2. Final Selection of the Improved Model
- Step 1. Parameter Grid: Set the parameters to be searched and their value ranges.
- Step 2. Model Training and Validation: Train the model and perform cross-validation for each parameter combination in the grid.
- Step 3. Select Best Parameters: Select the parameter combination with the best performance based on cross-validation metrics.
- Step 1. Initialization: Randomly generate a set of real-number candidate solutions.
- Step 2. Fitness Evaluation: Evaluate the quality of each candidate solution using a predefined fitness function.
- Step 3. Selection: Apply a fitness-based selection strategy to choose superior candidate solutions as parents for the next generation.
- Step 4. Crossover: Generate new candidate solutions by exchanging parts of the variables between parent solutions.
- Step 5. Mutation: Randomly modify the genes of some candidate solutions to enhance diversity.
- Step 6. Replacement: Replace the old generation with the new generation and iterate until the termination condition is met.
5. Analyzing the Contribution of Variables to Model Output
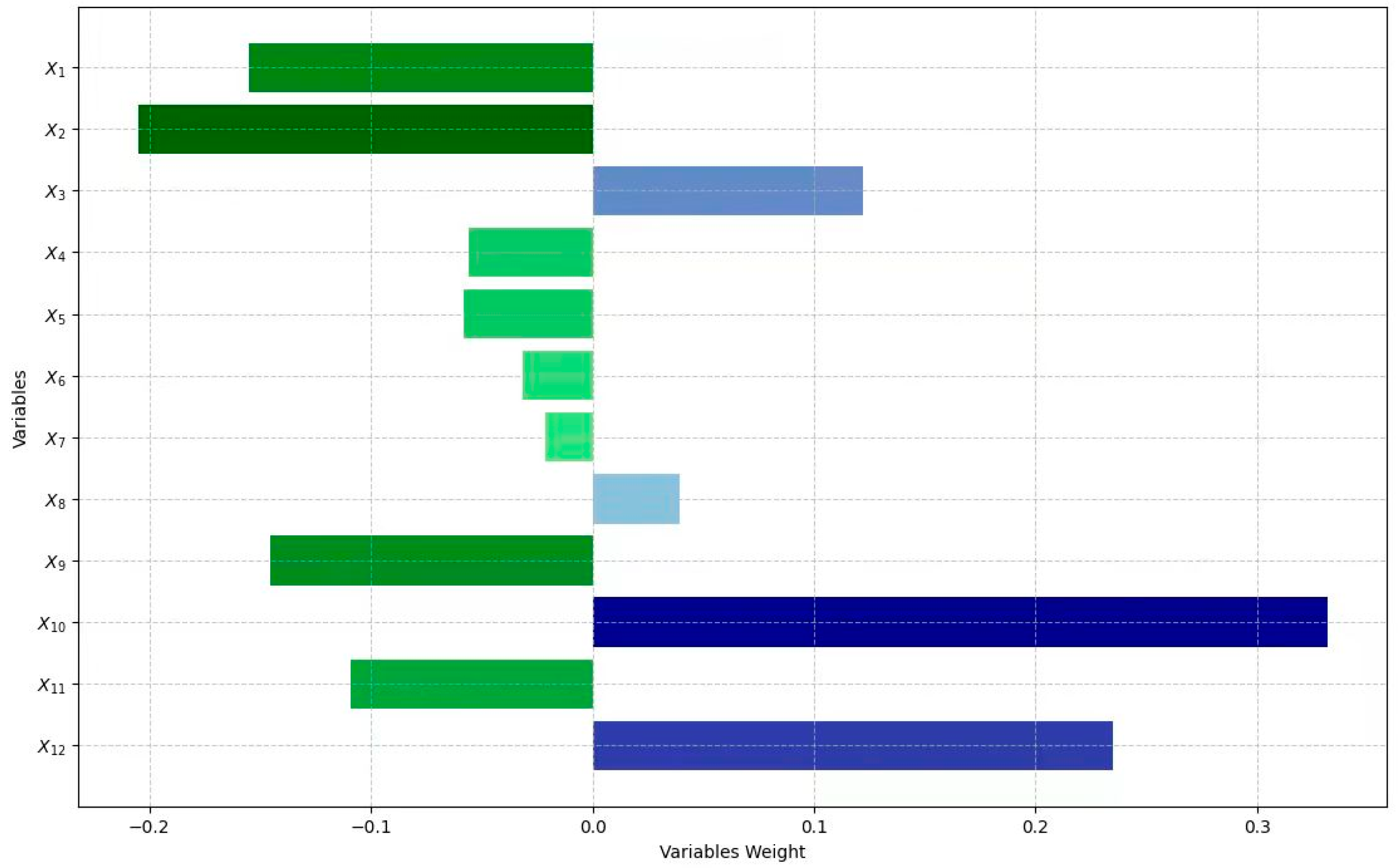
5.1. Local Sensitivity Analysis
5.2. Interpretability Analysis
- Step 1. Generate multiple perturbed samples around the data point to be explained.
- Step 2. Use the original model to predict these perturbed samples.
- Step 3. Train an interpretable model using these perturbed samples and their prediction results.
- Step 4. The coefficients of the surrogate model indicate the importance of each feature to the original model’s prediction.
6. Discussion on Variables Affecting Transportation Carbon Emissions
6.1. Transportation Development Level
6.2. Public Transportation Development Level
6.3. Tourism Development Level
6.4. Tertiary Industry Development Level
6.5. Socio-Economic Development Level
7. Conclusions
- (1)
- The total carbon emissions from Tibet’s transportation sector show a significant upward trend. Notably, emissions from civil aviation passenger transport see the most dramatic rise, surging from 15.54 thousand tons in 2011 to 884.45 thousand tons in 2020, a 56.91-fold increase. Road freight remains the largest contributor, responsible for 62.29% of the transportation carbon emissions in Tibet.
- (2)
- The model construction reveals that the RBF-SVM algorithm is the most suitable for predicting Tibet’s transportation carbon emissions. After optimizing RBF-SVM using GS and RGA, the enhanced model (Model_gs_rs) achieves superior performance, with an R2 value exceeding 0.99, significantly enhancing the prediction accuracy.
- (3)
- Regarding the impact on Tibet’s transportation carbon emissions, factors like total public transport passenger volume, the number of buses and electric vehicles per 10,000 people, tourism revenue, and the number of tourists have minimal influence. In contrast, the number of civilian vehicles, transportation land-use area, transportation output value, urban green coverage areas, per capita GDP, and built-up area exert a more significant impact. Dimensionally, the levels of transportation development and socio-economic development are the most critical determinants of carbon emissions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, S.; Ge, M. Everything You Need to Know about the Fastest-Growing Source of Global Emissions: Transport. World Resources Institute 16 October 2019. Available online: https://www.wri.org/insights/everything-you-need-know-about-fastest-growing-source-global-emissions-transport#:~:text=1.%20How%20big%20a%20problem%20are%20emissions%20from (accessed on 18 October 2023).
- Jelti, F.; Allouhi, A.; Tabet Aoul, K.A. Transition Paths towards a Sustainable Transportation System: A Literature Review. Sustainability 2023, 15, 15457. [Google Scholar] [CrossRef]
- Wang, J.; Yi, L.; Chen, L.; Hou, Y.; Zhang, Q.; Yang, X. Coupling and Coordination between Tourism, the Environment and Carbon Emissions in the Tibetan Plateau. Sustainability 2024, 16, 3657. [Google Scholar] [CrossRef]
- World Tourism Organization; United Nations Environment Programme. Climate Change and Tourism: Responding to Global Challenges; World Tourism Organization: Madrid, Spain, 2008; pp. 139–143. [Google Scholar]
- Cai, B.; Yang, W.; Cao, D.; Liu, L.; Zhou, Y.; Zhang, Z. Estimates of China’s National and Regional Transport Sector CO2, Emissions in 2007. Energy Policy 2012, 41, 474–483. [Google Scholar] [CrossRef]
- Zhu, C.; Wang, M.; Du, W. Prediction on peak values of carbon dioxide emissions from the Chinese transportation industry based on the SVR model and scenario analysis. J. Adv. Transp. 2020, 2020, 8848149. [Google Scholar] [CrossRef]
- Ağbulut, Ü. Forecasting of transportation-related energy demand and CO2 emissions in Turkey with different machine learning algorithms. Sustain. Prod. Consum. 2022, 1, 141–157. [Google Scholar] [CrossRef]
- Ma, S.; Chen, X.; Yang, L.; Zhao, Y.; Zeng, Y. Impacts of Accessibility on Sspatial Heterogeneity of Multimodal Transportation Carbon Emissions in an Urban Agglomeration. J. Transp. Syst. Eng. Inf. Technol. 2024, 24, 64–74. [Google Scholar]
- Gao, J.; Huang, W.; Jiang, H. Comparison of Multiple Forecast Models of Urban Traffic Carbon Emissions. J. Chongqing Jiaotong Univ. (Nat. Sci.) 2020, 39, 33–39. [Google Scholar]
- Li, N.; Chen, S.; Liang, X.; Tian, P. Prediction of Transportation Industry Carbon Peak in China. J. Transp. Syst. Eng. Inf. Technol. 2024, 24, 2–13+54. [Google Scholar]
- Jiao, L.; Liu, Y.; Wu, Y.; Huo, X. Transportation Carbon Emission Prediction Based on Convolutional Neural Network. Railw. Transp. Econ. 2024, 1–9. [Google Scholar]
- Zhao, J.; Li, J.; Wang, P.; Hou, G. A Study on Carbon Peaking Paths in Henan, China Based on Lasso Regression-BP Neural Network Model. Environ. Eng. 2022, 40, 151–156+164. [Google Scholar]
- Wei, S.; Wang, Y.; Zhang, C. Forecasting CO2 emissions in Hebei, China, through moth-flame optimization based on the random forest and extreme learning machine. Environ. Sci. Pollut. Res. 2018, 25, 28985–28997. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wang, J.; Zhu, C.; Hao, F. Carbon Emission Prediction of Transportation Industry Based on VMD and SSA-LSSVM. Environ. Eng. 2023, 41, 124–132. [Google Scholar]
- Huo, Z.; Zha, X.; Lu, M.; Ma, T.; Lu, Z. Prediction of carbon emission of the transportation sector in Jiangsu province-regression prediction model based on GA-SVM. Sustainability 2023, 15, 3631. [Google Scholar] [CrossRef]
- Liu, H.; Hu, D. Construction and Analysis of Machine Learning Based Transportation Carbon Emission Prediction Model. Environ. Eng. 2024, 45, 3421–3432. [Google Scholar]
- Zhao, G.; Gao, Y.; Wang, Z. A Transportation Carbon Emission Analysis Method Based on Decision Tree and Monte Carlo Simulation. Highway 2015, 60, 191–195. (In Chinese) [Google Scholar]
- Jiang, Y.; Zhou, Z.; Liu, C. The impact of public transportation on carbon emissions: A panel quantile analysis based on Chinese provincial data. Environ. Sci. Pollut. Res. 2019, 26, 4000–4012. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yan, Y.; Huang, Q.; Song, Y. Analysis of Carbon Emission Reduction Potential of China’s Transportation. Sci. Technol. Manag. Res. 2021, 41, 200–210. [Google Scholar]
- Hou, L.; Wang, Y.; Zheng, Y.; Zhang, A. The Impact of Vehicle Ownership on Carbon Emissions in the Transportation Sector. Sustainability 2022, 14, 12657. [Google Scholar] [CrossRef]
- Hussain, Z.; Khan, M.K.; Shaheen, W.A. Effect of economic development, income inequality, transportation, and environmental expenditures on transport emissions: Evidence from OECD countries. Environ. Sci. Pollut. Res. 2022, 29, 56642–56657. [Google Scholar] [CrossRef]
- Tian, P.; Mao, B.; Tong, R.; Zhang, H.; Zhou, Q. Analysis of carbon emission level and intensity of China’s transportation industry and different transportation modes. Clim. Change Res. 2023, 19, 347–356. [Google Scholar]
- Wang, Z.; Li, J.; Peng, B.; Xiang, W. Driving Factors and Decoupling Effect Analysis of Transportation Carbon Emissions in Western China. Environ. Eng. 2023, 41, 213–222. [Google Scholar]
- Wang, C.; Wu, L. Factors Driving the Carbon Emission Reduction in Transport Along the Silk Road Economic Belt: An Analysis from the Perspective of “Double Carbon”. J. Arid Land Resour. Environ. 2024, 38, 9–19. [Google Scholar]
- Liu, J.; Liu, Y.; Huang, L. Measurement and Driving Factor Analysis of Carbon Emissions from Tourism Transportation in East China. Res. Environ. Sci. 2024, 37, 626–636. [Google Scholar]
- Li, J.; Li, M.; Yuan, M.; Li, M. Study on the Spatial and Temporal Evolution and Influencing Factors of Tourism Traffic Carbon Emissions in Provinces along the Grand Canal Cultural Belt. Ecol. Econ. 2024, 40, 145–152+173. [Google Scholar]
- He, M.; Xie, J.; Wu, X.; Luo, J. Factors Decomposition of Carbon Emissions from Transportation Energy Consumption in Jiangsu Province Based on LMDI. Math. Pract. Theory 2015, 45, 16–22. [Google Scholar]
- Bian, L.; Ji, M. Research on Influencing Factors and Prediction of Transportation Carbon Emissions in Qinghai. Ecol. Econ. 2019, 35, 35–39+100. [Google Scholar]
- Liu, X.; Wu, P.; Wang, H. Analysis of Driving Factors of Transport Carbon Emissions in Inner Mongolia Based on LMDI Model. Transp. Energy Conserv. Environ. Prot. 2024, 20, 89–93+100. [Google Scholar]
- Huang, L.; Liu, J.; Liu, Y.; Ju, X.; Wang, P. Spatial and temporal evolution characteristics and driving factors of urban traffic carbon emissions in Jiangsu Province. Environ. Ecol. 2024, 6, 1–8. [Google Scholar]
- Liu, Y.; Wu, M.; Mu, R. Carbon Emission Measurement, Factor Decomposition and Low Carbonization Strategies of Transportation Industry in Tibet. J. Tibet Univ. 2021, 36, 126–133. [Google Scholar]
- Gong, J.; Hu, J.; Wang, X. Analysis of the Influencing Factors of Carbon Emissions from Urban Transportation. Automob. Technol. 2024, 49, 170–174. [Google Scholar]
- Eggleston, S.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K. 2006 IPCC Guidelines for National Greenhouse Gas Inventories; Institute for Global Environmental Strategies: Hayama, Japan, 2006. [Google Scholar]
- Su, X.; An, J.; Zhang, Y. Support vector machine regression forecasting of O3 concentrations based on wavelet transformation. China Environ. Sci. 2019, 39, 3719–3726. [Google Scholar]
- Zhao, N.; Lu, Y. Remote-sensing estimation of near-surface ozone concentration based on XGBoost. Acta Sci. Circumstantiae 2022, 42, 95–108. [Google Scholar]
- Montes, C.; Kapelan, Z.; Saldarriaga, J. Predicting non-deposition sediment transport in sewer pipes using Random forest. Water Res. 2021, 189, 116639. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Shu, Q.; Jin, C.; Zheng, S.; Luo, L. Regional Transport Carbon Emission Forecasting and Peak Carbon Pathway Planning in China. Environ. Sci. 2024, 1–18. [Google Scholar] [CrossRef]
- Shekar, B.H.; Dagnew, G. Grid Search-Based Hyperparameter Tuning and Classification of Microarray Cancer Data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Majitar, East Sikkim, India, 25–28 February 2019; pp. 1–8. [Google Scholar]
- Alibrahim, H.; Ludwig, S.A. Hyperparameter optimization: Comparing genetic algorithm against grid search and bayesian optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Krakow, Poland, 28 June–1 July 2021; pp. 1551–1559. [Google Scholar]
- Gustafson, P.; Srinivasan, C.; Wasserman, L. Local sensitivity analysis. Bayesian Stat. 1996, 5, 197–210. [Google Scholar]
- Tortorelli, D.A.; Michaleris, P. Design sensitivity analysis: Overview and review. Inverse Probl. Eng. 1994, 1, 71–105. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Bao, Z.; Ou, Y.; Chen, S.; Wang, T. Land use impacts on traffic congestion patterns: A tale of a Northwestern Chinese City. Land 2022, 11, 2295. [Google Scholar] [CrossRef]
- Palden, N.; Da, Q. Electric Vehicle Sales Increase in Tibet as Infrastructure Expanded. The China Daily Global, 18 October 2023. Available online: https://usa.chinadaily.com.cn/a/202310/18/WS652f1cefa31090682a5e91a0.html (accessed on 18 October 2023).
- Li, H.; Luo, N. Will improvements in transportation infrastructure help reduce urban carbon emissions?—Motor vehicles as transmission channels. Environ. Sci. Pollut. Res. 2022, 29, 38175–38185. [Google Scholar] [CrossRef]
- Zhang, Y.; Kong, Y.; Quan, J.; Wang, Q.; Zhang, Y.; Zhang, Y. Scenario analysis of energy consumption and related emissions in the transportation industry—A case study of Shaanxi Province. Environ. Sci. Pollut. Res. 2024, 31, 26052–26075. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Qiu, X.; Fang, Y.; Xu, Y.; Zhu, F. Spatial variation of the relationship between transport accessibility and the level of economic development in Qinghai-Tibet Plateau, China. J. Mt. Sci. 2019, 16, 1883–1900. [Google Scholar] [CrossRef]
- Xu, J.; Liu, J.; Xu, Y.; Pei, T. Visualization and analysis of local and distant population flows on the Qinghai-Tibet Plateau using crowd-sourced data. J. Geogr. Sci. 2021, 31, 231–244. [Google Scholar] [CrossRef]
- Sang, S.; He, W.; Ni, M. How off-season tourism promotion affects seasonal destinations? A multi-stakeholder perspective in Tibet. Tour. Rev. 2021, 76, 229–240. [Google Scholar]
- Wang, B.; Yang, Z.; Han, F.; Shi, H. Car Tourism in Xinjiang: The Mediation Effect of Perceived Value and Tourist Satisfaction on the Relationship between Destination Image and Loyalty. Sustainability 2017, 9, 22. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Liu, L.; Aloisi, J.; Zhao, J. Impacts of remote work on vehicle miles traveled and transit ridership in the USA. Nat. Cities 2024, 1, 346–358. [Google Scholar] [CrossRef]
- Jabbar, M.; Yusoff, M.M.; Shafie, A. Assessing the role of urban green spaces for human well-being: A systematic review. GeoJournal 2022, 87, 4405–4423. [Google Scholar] [CrossRef] [PubMed]
- Lombardía, A.; Gómez-Villarino, M.T. Green infrastructure in cities for the achievement of the un sustainable development goals: A systematic review. Urban Ecosyst. 2023, 26, 1693–1707. [Google Scholar] [CrossRef]
- Ma, H.; Chen, W.; Ma, H.; Yang, H. Influence of publicity and education and environmental values on the green consumption behavior of urban residents in Tibet. Int. J. Environ. Res. Public Health 2021, 18, 10808. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Research Content | Model and Algorithm | Research Factors |
|---|---|---|---|
| Ağbulut [7] | Prediction of Turkey’s transportation energy demand and CO2 emissions | Random Forest, SVM, XGBoost, etc. | GDP, per capita income, total population, urbanization rate, energy consumption, energy prices, number of vehicles, road length, vehicle efficiency |
| Gao et al. [9] | Driving factors for transportation carbon emission reduction in the Silk Road Economic Belt | LMDI | Converted transportation turnover, total energy consumption, gross transportation output, regional GDP, population size |
| Wang et al. [14] | Transportation carbon emissions prediction | Integrated VMD and SSA-LSSVM | GDP, energy consumption, number of vehicles, population size |
| Wang et al. [23] | Driving factors and decoupling effects of transportation carbon emissions in the western region | LMDI | Energy consumption in the transportation sector, equivalent turnover, added value of the transportation sector, GDP, resident population |
| Liu et al. [25] | Measurement and driving factors of tourism transportation carbon emissions in East China | LMDI | Added value of the tertiary industry, regional GDP, tourism revenue, number of tourists, number of scenic spots, passenger turnover, passenger volume, energy consumption in transportation, scale of tourism |
| Li et al. [26] | Spatiotemporal evolution and influencing factors of tourism transportation carbon emissions in the provinces along the Grand Canal Cultural Belt | GIS and regression analysis | Regional GDP, number of inbound tourists, added value of the tertiary industry, energy consumption per passenger turnover, number of libraries, number of museums, number of community cultural centers |
| Liu et al. [29] | Driving factors of transportation carbon emissions in Inner Mongolia | LMDI | Energy consumption in transportation, total energy consumption in transportation, total transportation output, population size |
| Huang et al. [30] | Spatiotemporal evolution characteristics and driving factors of urban transportation carbon emissions in Jiangsu Province | Spatial autocorrelation analysis and regression analysis | Added value of the transportation sector, regional GDP, resident population, total urban bus passenger volume, built-up area, urban green coverage areas |
| Liu et al. [31] | Driving factors and decoupling effects of transportation carbon emissions in Tibet | LMDI and DPSIR | GDP, energy consumption, total population, equivalent turnover |
| Gong et al. [32] | Influencing factors of transportation carbon emissions in Lhasa | PLSR | Total population, GDP, vehicle ownership, passenger turnover, freight turnover, public transport passenger volume, number of tourists |
| This paper | Measurement, prediction model development, and analysis of transportation carbon emissions in Tibet | GS-RBF-SVM, central difference method, and LIME algorithm | Number of civilian vehicles, transportation land-use area, transportation output, total public transport passenger volume, number of buses and electric vehicles per 10,000 people, tourism revenue, number of tourists, total retail sales of consumer goods, added value of the tertiary industry, urban green coverage areas, per capita GDP, built-up area |
| Year | Passenger Turnover (100 Million Passenger–Kilometers) | Freight Turnover (100 Million Ton–Kilometers) | |||||
|---|---|---|---|---|---|---|---|
| Rail | Road | Civil Aviation | Rail | Road | Civil Aviation | Pipeline | |
| 2008 | 6.24 | 24.14 | / | 6.7 | 25.4 | / | 1.15 |
| 2009 | 8.25 | 21.73 | / | 9.93 | 26.56 | / | 1.54 |
| 2010 | 9.44 | 22.77 | / | 11.97 | 27.1 | / | 1.32 |
| 2011 | 10.38 | 22.5 | 1.99 | 12.92 | 27.1 | 0.01 | 1.52 |
| 2012 | 10.25 | 23.2 | 7.88 | 18.3 | 27.87 | 0.04 | 1.62 |
| 2013 | 11.4 | 31.03 | 16.1 | 21.45 | 86 | 0.08 | 1.5 |
| 2014 | 12.34 | 32.78 | 20.53 | 22.94 | 86 | 0.09 | 1.6 |
| 2015 | 14.09 | 24.2 | 29.41 | 22.01 | 96.1 | 0.15 | 0.9 |
| 2016 | 16.04 | 23.74 | 41.38 | 28.36 | 94.5 | 0.25 | 0.8 |
| 2017 | 18.1 | 26.66 | 61.17 | 29.19 | 105.82 | 0.4 | 1.3 |
| 2018 | 18.86 | 27.97 | 78.28 | 33.22 | 116.84 | 0.55 | 1.18 |
| 2019 | 18.08 | 27.23 | 85.3 | 39.91 | 114.47 | 0.65 | 1.12 |
| 2020 | 12.34 | 14.61 | 58.33 | 39.8 | 116.73 | 0.43 | 1.22 |
| Year | Passenger Transport (gCO2/Passenger–Kilometer) | Freight Transport (gCO2/Ton–Kilometer) | |||||
|---|---|---|---|---|---|---|---|
| Rail | Road | Civil Aviation | Rail | Road | Civil Aviation | Pipeline | |
| 2005 | 10.78 | 106.83 | 141.22 | 10.78 | 235.31 | 1835.86 | 28.95 |
| 2010 | 10.61 | 120.15 | 120.24 | 10.61 | 264.64 | 1563.12 | 28.95 |
| 2014 | 12.42 | 46.39 | 112.06 | 12.42 | 102.17 | 1456.78 | 28.95 |
| 2015 | 13.68 | 47.23 | 106.63 | 13.68 | 104.02 | 1386.19 | 28.95 |
| 2016 | 15.11 | 43.13 | 109.7 | 15.11 | 95 | 1426.1 | 28.95 |
| 2017 | 14.89 | 43.89 | 106.66 | 14.89 | 96.68 | 1386.58 | 28.95 |
| 2018 | 14.03 | 41.67 | 105.93 | 14.03 | 91.78 | 1377.09 | 28.95 |
| 2019 | 13.53 | 51.49 | 95.47 | 13.53 | 113.42 | 1241.11 | 28.95 |
| 2020 | 17.17 | 50.15 | 158.22 | 17.17 | 110.45 | 2056.86 | 28.95 |
| Year | Passenger Transport (gCO2/Passenger–Kilometer) | Freight Transport (gCO2/Ton–Kilometer) | |||||
|---|---|---|---|---|---|---|---|
| Rail | Road | Civil Aviation | Rail | Road | Civil Aviation | Pipeline | |
| 2006 | [7.87, 13.49] | [66.79, 169.67] | [122.09, 149.17] | [7.87, 13.49] | [147.12, 373.72] | [1587.22, 1939.26] | 28.95 |
| 2007 | [7.79, 13.41] | [76.01, 178.89] | [116.86, 143.94] | [7.79, 13.41] | [167.42, 394.02] | [1519.12, 1871.16] | 28.95 |
| 2008 | [7.74, 13.36] | [76.01, 178.89] | [116.86, 143.94] | [7.74, 13.36] | [167.42, 394.02] | [1519.12, 1871.16] | 28.95 |
| 2009 | [7.74, 13.36] | [79.15, 182.03] | [108.81, 135.89] | [7.74, 13.36] | [174.34, 400.94] | [1519.12, 1871.16] | 28.95 |
| 2011 | [7.95, 13.57] | [48.90, 151.78] | [106.00, 133.08] | [7.95, 13.57] | [107.70, 334.30] | [1378.06, 1730.10] | 28.95 |
| 2012 | [8.26, 13.88] | [25.26, 128.14] | [105.46, 132.54] | [8.26, 13.88] | [55.64, 282.24] | [1371.04, 1723.08] | 28.95 |
| 2013 | [8.78, 14.40] | [25.26, 128.14] | [103.50, 130.58] | [8.78, 14.40] | [10.82, 237.42] | [1345.46, 1697.50] | 28.95 |
| Year | Passenger Transport (gCO2/Passenger–Kilometer) | Freight Transport (gCO2/Ton–Kilometer) | |||||
|---|---|---|---|---|---|---|---|
| Rail | Road | Civil Aviation | Rail | Road | Civil Aviation | Pipeline | |
| 2005 | 10.78 | 106.83 | 141.22 | 10.78 | 235.31 | 1835.86 | 28.95 |
| 2006 | 10.68 | 118.23 | 135.63 | 10.68 | 260.42 | 1763.24 | 28.95 |
| 2007 | 10.60 | 127.45 | 130.40 | 10.60 | 280.72 | 1695.14 | 28.95 |
| 2008 | 10.55 | 132.30 | 125.85 | 10.55 | 291.39 | 1636.08 | 28.95 |
| 2009 | 10.55 | 130.59 | 122.35 | 10.55 | 287.64 | 1590.57 | 28.95 |
| 2010 | 10.61 | 120.15 | 120.24 | 10.61 | 264.64 | 1563.12 | 28.95 |
| 2011 | 10.76 | 100.34 | 119.54 | 10.76 | 221.00 | 1554.08 | 28.95 |
| 2012 | 11.07 | 76.70 | 119.00 | 11.07 | 168.94 | 1547.06 | 28.95 |
| 2013 | 11.59 | 56.35 | 117.04 | 11.59 | 124.12 | 1521.48 | 28.95 |
| 2014 | 12.42 | 46.39 | 112.06 | 12.42 | 102.17 | 1456.78 | 28.95 |
| 2015 | 13.68 | 47.23 | 106.63 | 13.68 | 104.02 | 1386.19 | 28.95 |
| 2016 | 15.11 | 43.13 | 109.70 | 15.11 | 95.00 | 1426.10 | 28.95 |
| 2017 | 14.89 | 43.89 | 106.66 | 14.89 | 96.68 | 1386.58 | 28.95 |
| 2018 | 14.03 | 41.67 | 105.93 | 14.03 | 91.78 | 1377.09 | 28.95 |
| 2019 | 13.53 | 51.49 | 95.47 | 13.53 | 113.42 | 1241.11 | 28.95 |
| 2020 | 17.17 | 50.15 | 158.22 | 17.17 | 110.45 | 2056.86 | 28.95 |
| Year | Passenger Transport (Thousand Tons CO2) | Freight Transport (Thousand Tons CO2) | Total Emissions (Thousand Tons CO2) | |||||
|---|---|---|---|---|---|---|---|---|
| Rail | Road | Civil Aviation | Rail | Road | Civil Aviation | Pipeline | ||
| 2008 | 65.83 | 3193.62 | / | 70.68 | 7401.43 | / | 33.29 | 1076.49 |
| 2009 | 87.02 | 2837.75 | / | 104.74 | 7639.70 | / | 44.58 | 1071.38 |
| 2010 | 100.16 | 2735.82 | / | 127.00 | 7171.74 | / | 38.21 | 1017.29 |
| 2011 | 111.71 | 2257.55 | 237.89 | 139.04 | 5988.98 | 15.54 | 44.00 | 879.47 |
| 2012 | 113.42 | 1779.50 | 937.75 | 202.50 | 4708.36 | 61.88 | 46.90 | 785.03 |
| 2013 | 132.18 | 1748.64 | 1884.29 | 248.70 | 10,674.06 | 121.72 | 43.43 | 1485.30 |
| 2014 | 153.26 | 1520.66 | 2300.59 | 284.91 | 8786.62 | 131.11 | 46.32 | 1322.35 |
| 2015 | 192.75 | 1142.97 | 3135.99 | 301.10 | 9996.32 | 207.93 | 26.06 | 1500.31 |
| 2016 | 242.36 | 1023.91 | 4539.39 | 428.52 | 8977.50 | 356.53 | 23.16 | 1559.14 |
| 2017 | 269.51 | 1170.11 | 6524.39 | 434.64 | 10,230.68 | 554.63 | 37.64 | 1922.16 |
| 2018 | 264.61 | 1165.51 | 8292.20 | 466.08 | 10,723.58 | 757.40 | 34.16 | 2170.35 |
| 2019 | 244.62 | 1402.07 | 8143.59 | 539.98 | 12,983.19 | 806.72 | 32.42 | 2415.26 |
| 2020 | 211.88 | 732.69 | 9228.97 | 683.37 | 12,892.83 | 884.45 | 35.32 | 2466.95 |
| Internal/External Factors | Dimension | Input Variable | Unit | Code |
|---|---|---|---|---|
| Internal factors | Transportation development level | Number of civilian vehicles | 10,000 vehicles | |
| Transportation land-use area | km2 | |||
| Transportation output value | 100 million CNY | |||
| Public transportation development level | Total public transport passenger volume | 10,000 persons | ||
| Number of buses and electric vehicles per 10,000 people | vehicles | |||
| External factors | Tourism development level | Tourism revenue | 100 million CNY | |
| Number of tourists | 10,000 persons | |||
| Tertiary industry development level | Total retail sales of consumer goods | 100 million CNY | ||
| Added value of tertiary industry | 100 million CNY | |||
| Socio-economic development level | Urban green coverage areas | km2 | ||
| Per capita GDP | 10,000 CNY | |||
| Built-up area | km2 | |||
| Control variables | Passenger turnover | 100 million passenger-kilometers | ||
| Freight turnover | 100 million ton-kilometers |
| Variables | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | x10 | x11 | x12 | c1 | c2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | |||||||||||||||
| 2008 | 19.30 | 240.00 | 19.90 | 6861.00 | 12.76 | 22.59 | 224.64 | 145.47 | 229.84 | 22.00 | 1.37 | 79.00 | 30.38 | 33.25 | |
| 2009 | 19.86 | 333.47 | 21.19 | 5618.00 | 12.60 | 55.99 | 561.06 | 178.89 | 255.09 | 26.67 | 1.52 | 81.30 | 29.98 | 38.03 | |
| 2010 | 22.03 | 336.20 | 22.12 | 5295.90 | 20.91 | 71.44 | 685.14 | 217.94 | 293.05 | 27.78 | 1.72 | 84.90 | 32.21 | 40.39 | |
| 2011 | 25.78 | 347.13 | 23.95 | 7251.00 | 9.02 | 97.06 | 869.76 | 270.42 | 346.14 | 31.57 | 2.01 | 89.70 | 34.87 | 41.55 | |
| 2012 | 27.38 | 348.60 | 26.23 | 7139.00 | 8.59 | 126.48 | 1058.39 | 318.39 | 408.78 | 43.98 | 2.28 | 119.70 | 41.33 | 47.83 | |
| 2013 | 31.30 | 355.47 | 29.21 | 8001.00 | 7.70 | 165.18 | 1291.06 | 371.48 | 476.21 | 42.63 | 2.62 | 120.30 | 58.53 | 109.03 | |
| 2014 | 33.47 | 366.60 | 30.80 | 8380.00 | 8.43 | 204.00 | 1553.14 | 422.75 | 541.29 | 56.30 | 2.93 | 126.30 | 65.65 | 110.63 | |
| 2015 | 37.45 | 375.27 | 31.76 | 9128.00 | 9.05 | 281.92 | 2017.53 | 477.07 | 607.58 | 63.34 | 3.18 | 144.50 | 67.70 | 119.16 | |
| 2016 | 40.46 | 418.67 | 31.26 | 8688.00 | 6.20 | 330.75 | 2315.94 | 539.05 | 672.07 | 72.70 | 3.50 | 145.20 | 81.16 | 123.91 | |
| 2017 | 44.68 | 421.60 | 34.08 | 9120.00 | 10.43 | 379.37 | 2561.43 | 618.84 | 761.24 | 54.12 | 3.92 | 147.60 | 105.93 | 136.71 | |
| 2018 | 58.24 | 786.35 | 47.70 | 9615.00 | 12.97 | 490.14 | 3368.73 | 711.76 | 837.33 | 63.86 | 4.41 | 163.70 | 125.10 | 151.79 | |
| 2019 | 63.61 | 1666.00 | 47.80 | 9257.00 | 7.62 | 559.28 | 4012.15 | 773.40 | 924.01 | 64.15 | 4.75 | 164.40 | 130.61 | 156.15 | |
| 2020 | 70.21 | 2754.40 | 45.70 | 7588.00 | 8.30 | 366.42 | 3505.01 | 745.78 | 953.84 | 66.56 | 5.23 | 168.40 | 85.28 | 158.18 | |
| Model | Python Library | Grid Search Parameters | Parameters |
|---|---|---|---|
| Model_rs | Machine learning library: Scikit-learn | Regularization parameter: [0.01, 0.1, 1, 10, 100, 1000] Kernel coefficient: [0.0001, 0.001, 0.01, 0.1, 1] | Regularization parameter: 1000 Kernel coefficient: 0.001 |
| Model_xg | Machine learning library: Scikit-learn and XGBoost | Number of trees: [100, 200, 300] Maximum tree depth: [3, 5, 7] Learning rate: [0.01, 0.05, 0.1] | Number of trees: 300 Maximum tree depth: 3 Learning rate: 0.05 |
| Model_rf | Machine learning library: Scikit-learn | Number of trees: [100, 200, 500] Maximum tree depth: [10, 20] Minimum samples per leaf node: [1, 2, 4] | Number of trees: 200 Maximum tree depth: 10 Minimum samples per leaf node: 2 |
| Model_gb | Machine learning library: Scikit-learn | Number of trees: [100, 150, 200] Maximum tree depth: [1, 2, 3] Minimum samples per leaf node: [1, 2, 5] Learning rate: [0.01, 0.05, 0.1] | Number of trees: 200 Maximum tree depth: 3 Minimum samples per leaf node: 1 Learning rate: 0.05 |
| Metric | Model | |||
|---|---|---|---|---|
| Model_rs | Model_xg | Model_rf | Model_gb | |
| MSE | 0.0629 | 0.1301 | 0.0821 | 0.0754 |
| MAE | 0.2117 | 0.2577 | 0.2182 | 0.2002 |
| R2 | 0.9350 | 0.8020 | 0.9134 | 0.9118 |
| MAPE | 1.0427 | 1.8969 | 1.0942 | 1.2280 |
| Model | Python Library | Optimization Algorithm Parameters | RBF-SVM Parameters |
|---|---|---|---|
| Model_gs_rs | Machine learning library: Scikit-learn | Regularization parameter: [0.01, 0.1, 1, 10, 100, 1000] Kernel coefficient: [0.0001, 0.001, 0.01, 0.1, 1] | Regularization Parameter: 1000 Kernel coefficient: 0.001 |
| Model_rga_rs | Machine learning library: Scikit-learn and DEAP | Selection: Grid Search Crossover: Uniform Crossover Fitness function: Evaluate Population size: 50 Generations: 40+ Crossover rate: 0.5 Mutation rate: 0.2 | Regularization Parameter: 42.76 Kernel coefficient: 0.02 |
| Metric | Model | |
|---|---|---|
| Model_gs_rs | Model_rga_rs | |
| MSE | 0.0089 | 0.0220 |
| MAE | 0.0907 | 0.1200 |
| R2 | 0.9924 | 0.9835 |
| MAPE | 0.2990 | 0.1198 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bo, W.; Zhao, K.; Cheng, G.; Wang, Y.; Zhang, J.; Cheng, M.; Yang, C.; Da, W. Study on Transportation Carbon Emissions in Tibet: Measurement, Prediction Model Development, and Analysis. Sustainability 2024, 16, 8419. https://doi.org/10.3390/su16198419
Bo W, Zhao K, Cheng G, Wang Y, Zhang J, Cheng M, Yang C, Da W. Study on Transportation Carbon Emissions in Tibet: Measurement, Prediction Model Development, and Analysis. Sustainability. 2024; 16(19):8419. https://doi.org/10.3390/su16198419
Chicago/Turabian StyleBo, Wu, Kunming Zhao, Gang Cheng, Yaping Wang, Jiazhe Zhang, Mingkai Cheng, Can Yang, and Wa Da. 2024. "Study on Transportation Carbon Emissions in Tibet: Measurement, Prediction Model Development, and Analysis" Sustainability 16, no. 19: 8419. https://doi.org/10.3390/su16198419