1. Introduction
Landslides and mudslides have a significant worldwide impact, damaging various man-made structures and infrastructure from local to global scales. There is a need to prepare and manage these disasters to mitigate their effects [
1]. On 22 June 2022, a 5.9 magnitude earthquake hit eastern Afghanistan, triggering landslides that claimed the lives of at least 1570 people and left nearly 6000 others injured. According to senior Taliban officials, the direct economic damage is estimated at
$2 billion. On 9 April 2022, heavy rainfall persisted in eastern South Africa, causing floods and landslides that caused extensive damage to homes, bridges, and roads. Local officials reported that the floods caused 544 fatalities, 50 injuries, and over 40 missing persons. Moreover, over 40,000 people were left homeless, and over 8329 homes and more than 600 school buildings were damaged, including at least 4000 destroyed. The disaster affected some 13,556 households [
2,
3].
China has a varied terrain with constantly evolving geology that leads to frequent geological disasters, including landslides. These landslides have a damaging impact on local communities, affecting both their livelihoods and safety. Timely detection of landslide-prone areas can reduce the loss of life and property. Five types of landslides exist: falling, overturning, sliding, spreading, and flowing, with sizes ranging from a few hundred meters to several kilometers [
4]. Accurate techniques for identifying landslides at multiple scales are critical for preventing and mitigating disasters and for monitoring and managing landslide hazards. These techniques are essential for maintaining safety and reducing the risk of geological disasters [
5]. Traditional landslide identification and detection typically involve manual field surveys and judgments, which result in high labor and material costs. However, over time, remote sensing images have become a mainstream method for landslide identification. Currently, technologies for landslide identification based on remote sensing images can be categorized into the following parts: (1) Visual interpretation, in which geological professionals employ a combination of visual interpretation and manual judgment to accurately assess landslides. While this method relies on subjective experience, it produces more precise results than alternative approaches. However, this approach is time-consuming and laborious [
6]. (2) The machine learning method, which covers many aspects; by extracting various relevant features of data, it requires less human involvement, but the recognition accuracy is usually lower, which has been the shortcoming of this method [
7,
8]. (3) In the deep learning method, which is a derivative of the machine learning method, the network model used has a more intricate and complex inherent relationship, and it can obtain more detailed information from remote sensing images during training. However, it requires a huge amount of data to support it.
Currently, researchers primarily use mainstream deep learning methods for landslide detection. Deep learning-based algorithms for object detection are usually categorized as single-stage or two-stage detection. YOLO and SSD represent single-stage detection algorithms [
9,
10]. The algorithms do not require generating region proposals. Instead, they directly classify and regress the extracted image features according to the object’s location and category through a specific network structure. In single-stage detection algorithms, the problem of object localization is converted into a regression problem to address, and the detection model uniformly analyses regression and classification outcomes. The two-stage detection algorithms are represented by R-CNN and Fast R-CNN, necessitating the generation of region proposals and feature extraction by CNN, followed by object classification and localization using classifiers [
11,
12]. Zhao et al. [
13] enhanced the capability of YOLOv5 to identify remotely sensed images by integrating an extra cross-layer asymmetric transformer (CA-Trans) prediction head. The addition captures the asymmetric information between the head and others effectively, thanks to the use of a sparse local attention (SLA) module. Cheng et al. [
14] utilized group convolution (Gconv) and ghost bottleneck (G-bneck) residual modules to replace the convolution components and residual modules consisting of standard convolution. The purpose was to reduce the model’s parameters, which consequently made the model less accurate. Later, the selection kernel (SK) attention mechanism was introduced to help the network model minimize the attention to background noise in remotely sensed landslide images. Niu et al. [
15] integrated the attention mechanism into the Faster R-CNN network model to produce an attention-enhanced regional network model for detecting multi-scale landslides and debris flows. The study verifies that the enhanced model effectively eliminates irrelevant noise, but its larger size slightly reduces detection speed. Ju et al. [
16] conducted a study on landslide object detection in the Loess Plateau region. A database of historical records data was created utilizing Google Earth images with expert manual annotation. Three object detection algorithms were then chosen for automatic landslide identification experiments, comprising the one-stage algorithms RetinaNet and YOLOv3 and the two-stage algorithm Mask R-CNN. It was ultimately confirmed that Mask R-CNN achieved the highest accuracy, offering a reference for future research. However, the major limitation is that the recognition accuracy of Mask R-CNN’s best result is still relatively low. Yu et al. [
17] utilized Google Earth imagery to detect landslide patterns remotely through the use of the improved YOLOX algorithm, achieving a notable precision rate. Dynahead Yolo incorporates a unified attention mechanism that is scale-aware, space-aware, and task-aware into the YOLOv3 framework. This mechanism enables the network model to be more precise in capturing the details of variable-scale landslide images. It also provides valuable insight into the possibility of improving the detection accuracy of the model by including an attention mechanism. However, the model’s performance still requires detailed information for small-sample landslide detection [
18].
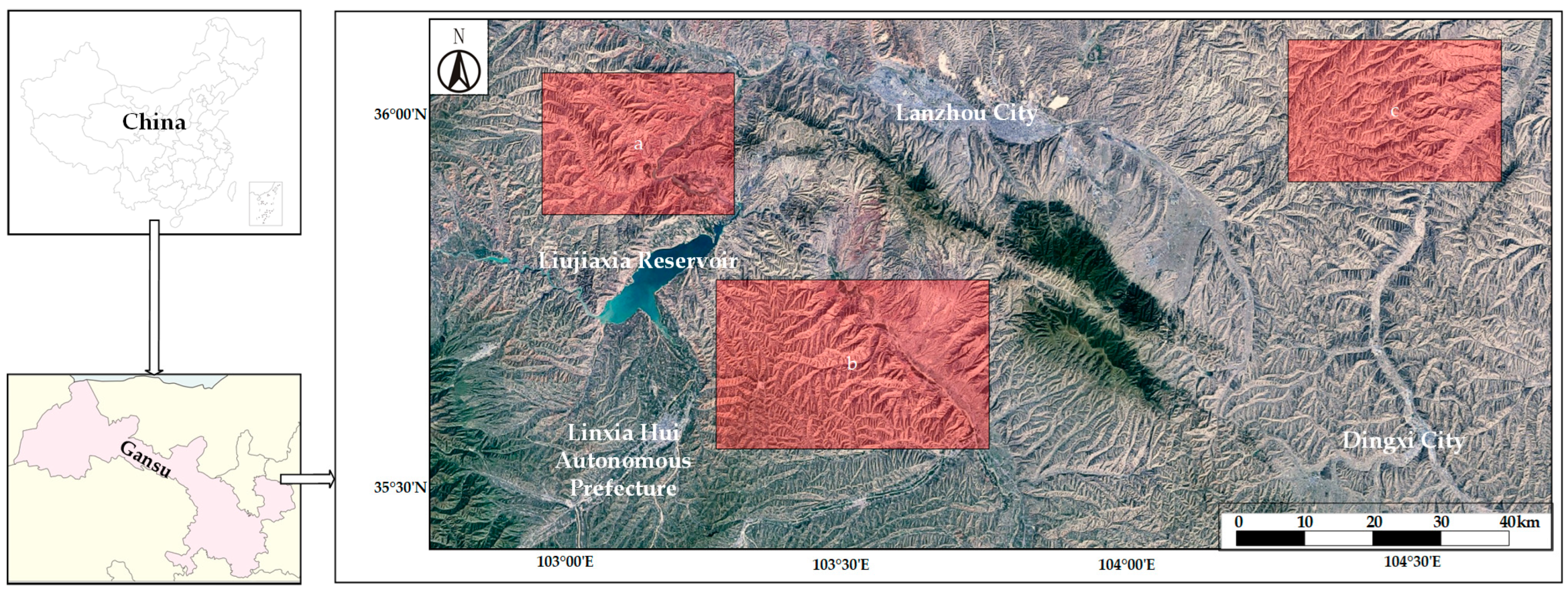
Although scholars have extensively studied object detection in remotely sensed landslide images and explored challenges in solving the landslide object detection problem, the Loess Plateau region of China faces unique challenges. The scarcity of landslide imagery, along with the multiple scales and variable shapes of landslides in this region, has resulted in landslide hazards that have not been effectively managed. This motivates us to create numerous loess landslide datasets, which is a time-consuming process, and explore various models to address the challenge of loess landslide monitoring and management. This paper proposes the use of such a model for effective monitoring and management of loess landslides. Our experimentation aims to introduce an enhanced object detection model that accurately identifies loess landslide objectives with a lightweight design.
3. Experimental Settings
3.1. Experimental Environment
This paper’s hardware platform is founded on an Intel i9-13900K CPU and an Nvidia RTX4090 GPU with 24 GB RAM. The CUDA version is 11.2, and the Pytorch version is 1.9.0, with Anaconda 4.10.3 and Python 3.9.7 being the primary supporting software. The software platform, which executes a deep neural network model, is centered on Pytorch 1.12.1—an open-source deep learning framework that leverages the Python programming language. The software can manage tensor data and includes fundamental operation units (e.g., convolution, pooling, and full connectivity) to aid users in personalizing complex neural network architectures. It enables users to have access to both automatic tensor derivation and optimization algorithms for most model training purposes.
3.2. Training Detail
In this study, 11,010 remote sensing image datasets having a resolution of 640 × 640 pixels were randomly allocated into a training set, validation set, and a test set with ratios of 80%, 10%, and 10%, respectively. The dataset display illustration is shown in
Figure 14.
The model’s primary parameters in this paper are established pre-training, and each training epoch consists of 100 iterations. During training, the optimizer employed is Stochastic Gradient Descent (SGD), with a batch size of 8, an initial learning rate of 0.01, and a weight decay coefficient of 0.0005. Following each iteration, the dataset’s order is automatically re-shuffled and re-input to decrease overfitting.
3.3. Evaluation Indicator
In this paper, we use four composite metrics—precision, recall, average accuracy, and mean average accuracy—to evaluate the performance of our landslide detection model in the dataset. These metrics are calculated as shown in Equations (14)–(17).
Precision indicates the model’s aptitude to differentiate negative samples, with higher precision signifying greater capability to distinguish such samples.
Recall measures the model’s ability to differentiate positive samples. Higher recall signifies a stronger ability of the model to identify positive samples.
The average precision () is the average of the highest precision values under various recall conditions, typically calculated separately for each category. The mean average precision () is determined by averaging the values across all categories, serving as a standard metric for evaluating multi-category object detection performance. In this study, average accuracy is computed at an IoU threshold of 0.5. Unless otherwise specified, all values mentioned in this thesis refer to mAP50.
is the true positive, is the false positive, is the false negative, is the total number of categories detected by the object, and can be interpreted as the number of objects predicted to be category objects in category . is the number of frames per second (how many images) that can be processed (detected) by the object network, which is simply understood as the refresh rate of the image, and the higher the means that the object model detects faster.
5. Discussion
5.1. Landslide Detection Accuracy of Different Models
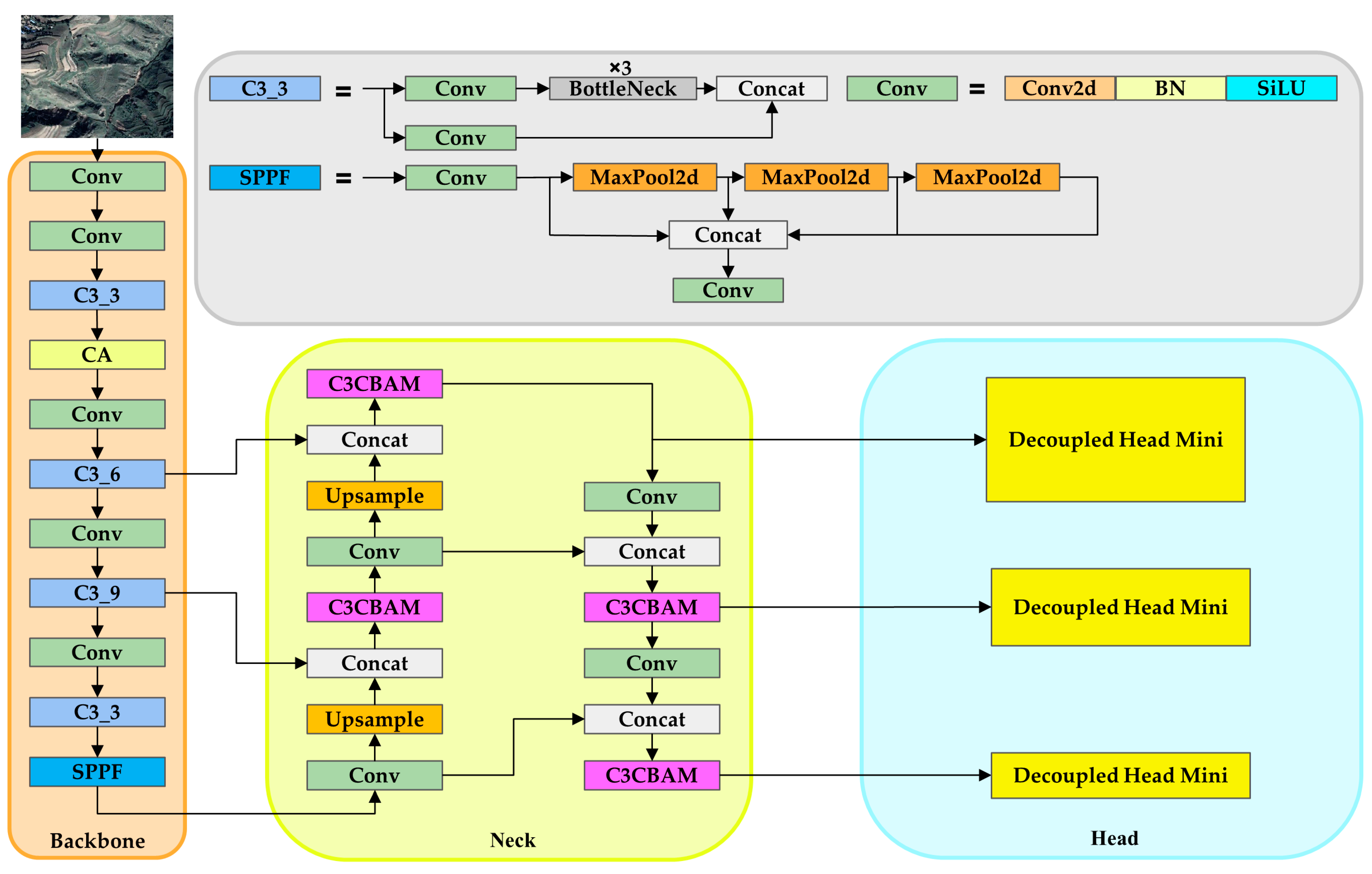
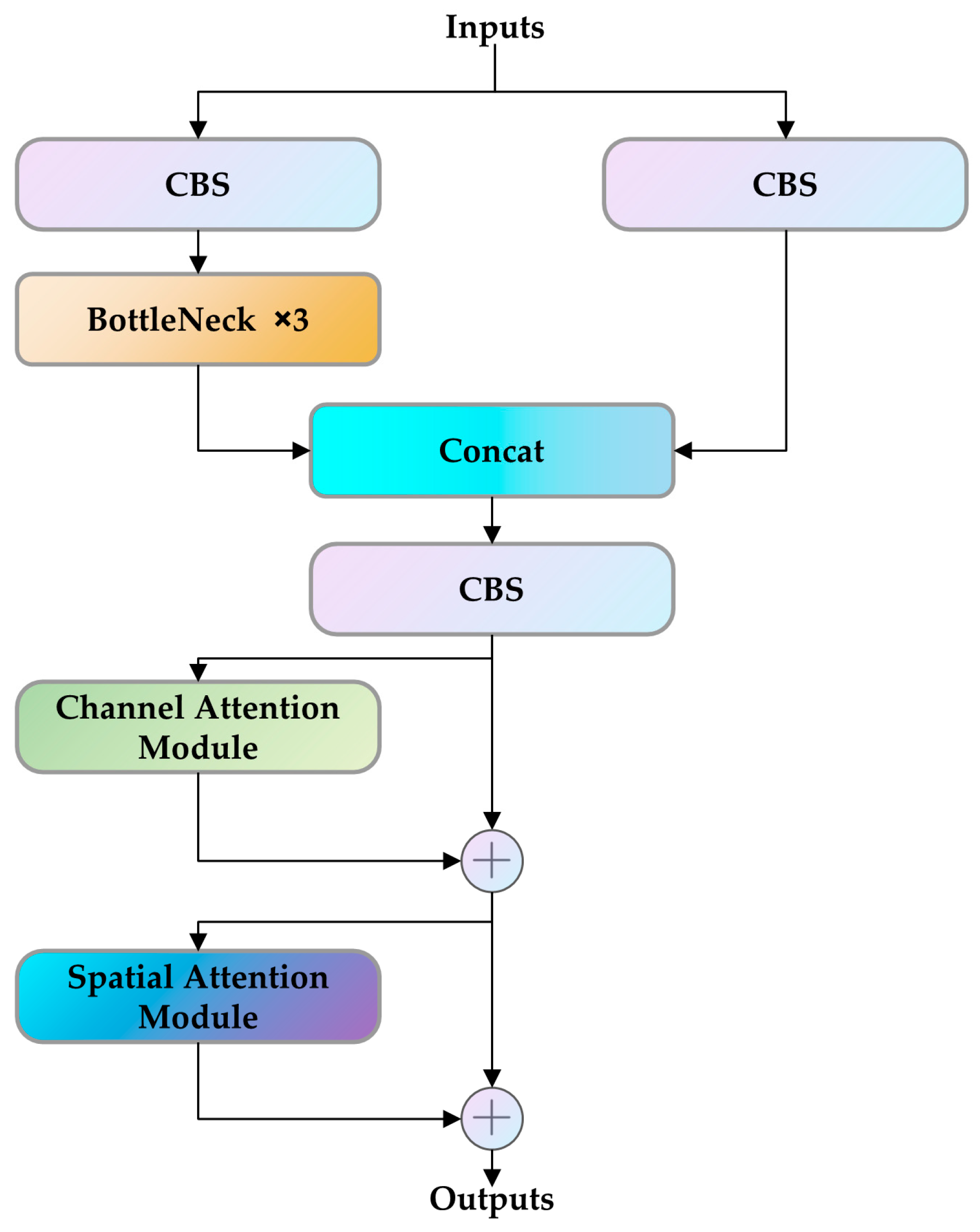
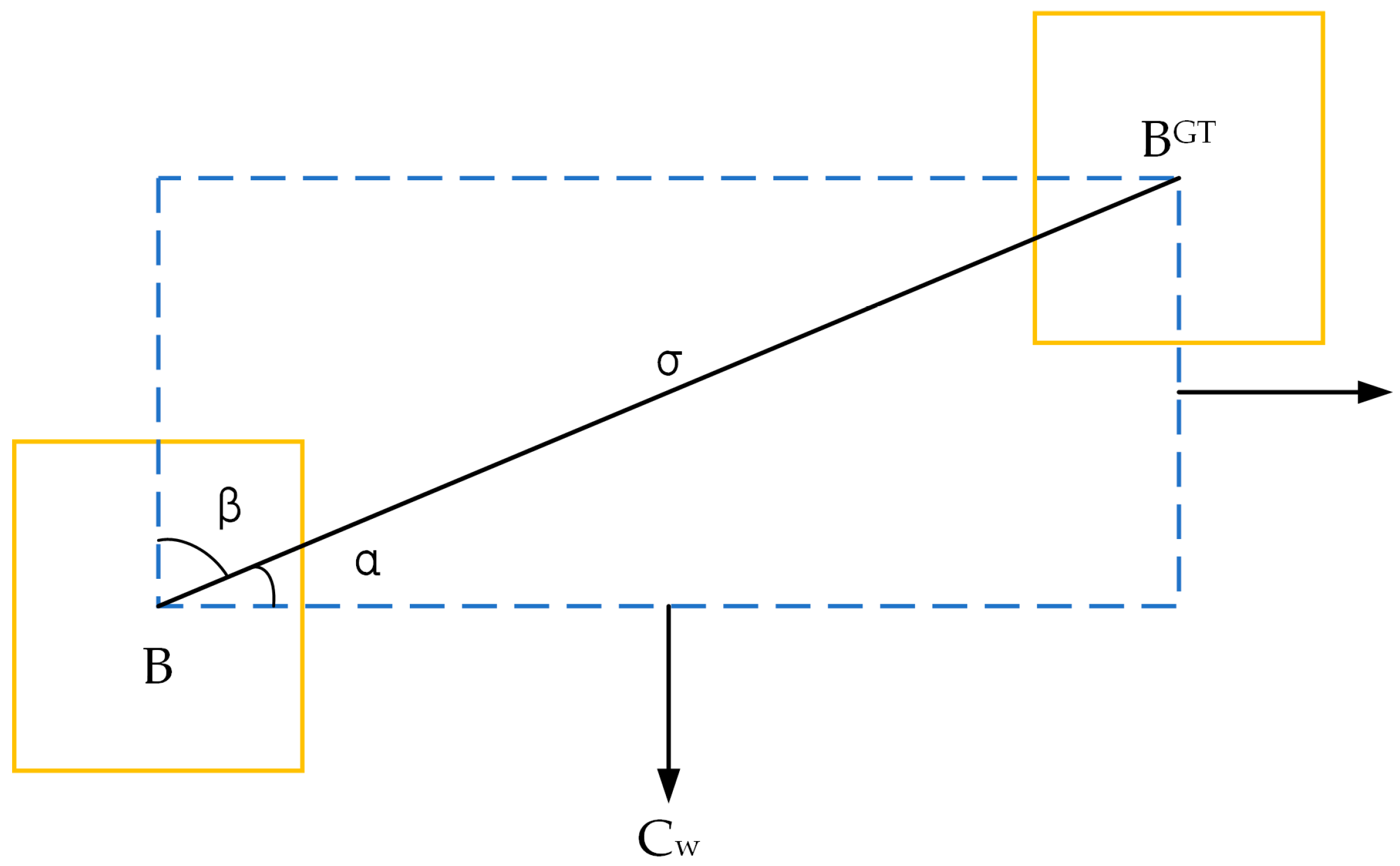
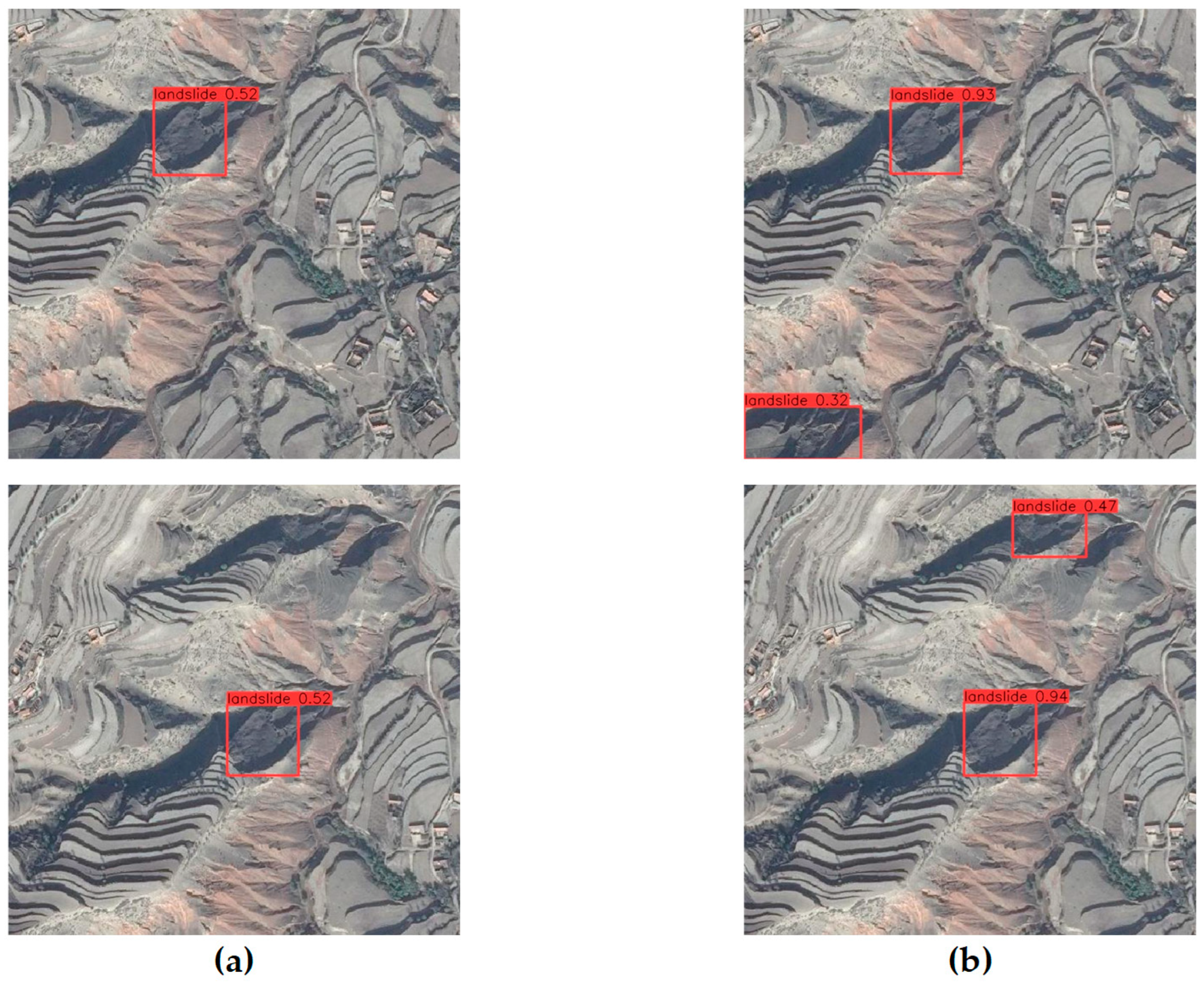
This study compares our loess landslide detection model with three object detection models: YOLOX and SSD, which are single-stage algorithms, and Fast R-CNN, which is a two-stage algorithm. Our model outperforms the others in all metrics, with 4.87% higher precision than YOLOX, 8.39% higher recall than SSD, 6.2% higher mAP than YOLOX, and 5% higher FPS than SSD. The improvements made in this study are closely linked to the enhanced detection capabilities of the model. By integrating CA into the backbone network, accurate location information and remote sensing spatial interaction information can be obtained from landslide images. Remote sensing images are often affected by complex background noise, but we propose using the CBAM module to filter out this noise and focus on the landslide object. Additionally, the use of a lightweight Decoupled Head can enhance the model’s ability to detect landslide objects without significantly increasing its complexity. Furthermore, we have introduced the SIoU loss function, which considers the vector angle between the ground truth frames and the predicted frames, to further improve the model’s accuracy.
The ablation experiment partially explains the effectiveness of the improvements made to the model implementation in this study. Firstly, the experiments confirmed that adding moderately different attentional mechanism modules to the trunk and neck of the model did not decrease the model’s accuracy. The model’s mAP increased by 2.22% with the addition of the CA module and by another 1.36% with the addition of the CBAM module to the neck. The location of the attention mechanism module was adjusted multiple times to enhance the model’s ability to extract landslide features by increasing its focus on landslide objects in landslide detection. However, the model’s accuracy still requires improvement. We recommend including the lightweight Decoupled Head, which improves the mAP by 0.24% despite a slight increase in model complexity. Finally, it was found that landslide objects come in various shapes and sizes. The introduction of the SIoU loss function improved the model’s mAP by 0.19%. The experiments demonstrate that these improvements enhance the model’s ability to detect landslides, resulting in a final mAP of 92.28%. The mAP is crucial in landslide detection as it determines the model’s detection accuracy, while the FPS determines the actual detection speed. The model can offer a more efficient response in real-world scenarios where faster detection speeds are necessary.
5.2. Limitations and Future Research
This study proposes a high-precision detection model for loess landslide detection in complex environments. The contribution of various improvements to achieve high-precision landslide detection is discussed and compared with other models. However, there are still some shortcomings and areas for improvement. The relatively small number of publicly available landslide datasets makes it difficult to compare our constructed dataset with previous ones. Although our manually labeled dataset has been checked and validated by experts, this still produces unavoidable bias. Furthermore, our landslide dataset only has two categories, landslide and non-landslide, which limits the ability to tailor specific responses to different types of landslides. Multi-category landslide detection would allow for targeted local monitoring and management of landslide hazards.
6. Conclusions
In conclusion, our study presents a lightweight network model for landslide recognition in disaster protection, built upon the YOLOv5 framework, Coordinate Attention, C3CBAM, SIoU loss function of YOLOv6, and Decoupled Head Mini. The proposed model effectively identifies multi-scale and small-object landslide features, achieving a notable mean average precision (mAP) of 92.28%, showcasing a significant improvement of 4.01% compared to YOLOv5. This research contributes to the ongoing trend in developing network models for landslide object detection, emphasizing the importance of lightweight models that balance accuracy and computational efficiency.
Adding Coordinate Attention enhances the robustness of the YOLO model, improving feature extraction from remote sensing landslide images and subsequently enhancing detection accuracy. The fusion of the neck’s C3 module with CBAM further augments the model’s capability to identify landslide-specific attributes and distinguish them from background noise. The incorporation of a lightweight feature enhancement module and a feature extraction model addresses the challenge of maintaining accuracy while reducing model volume, making the enhanced landslide detection model well-suited for monitoring and managing landslides. While the Decoupled Head enhances object detection model accuracy, it comes at the expense of increased computational power. Striking a balance between accuracy and computational effort is crucial, with adjustments such as a 1 × 1 dimensionality reduction operation being typical before decoupling. Recognizing the unique angles and directional features of remote sensing images of landslides, traditional object detection models may fall short. The introduction of SIoU, considering the vector angle between the ground truth box and the prediction box, proves beneficial in reducing deviation and improving the recognition performance of landslide images in object detection. Looking forward, future research in landslide detection could explore additional challenges and advancements, building upon the insights gained from this study. The developed model holds promise for applications in disaster management, remote sensing, and related domains, contributing to the ongoing efforts to enhance our understanding and mitigation of landslide risks.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}