The bi-level programming problem is a NP problem, and there is not an effective global algorithm up to now. Even if both the upper and the lower level model are convex programming problems, the bi-level programming problem is not likely to be a convex programming problem. So the solution of algorithm might be a local rather than a global optimal solution. The shuffled frog leaping algorithm (SFLA) is more likely to get global optimal solution, which has strong robustness and global optimization capability. This paper introduces the method of successive averages (MSA) and the shuffled frog leaping algorithm (SFLA) to solve the bi-level programming problem.
3.1. Algorithm 1. The Method of Successive Averages (MSA) of the Lower Level Model
The lower level of the bi-level programming model is a multi-modal transportation network equilibrium model. To solve the lower level model, the method of successive averages (MSA) is introduced. In iterations, firstly, it is necessary to evaluate which travel mode has a lower demand than the demand that it can gain by a logit split function for each OD pair. Secondly, the path must be found that currently has minimal general travel costs for the mode, and the auxiliary path flows must be determined by loading all OD demand to that path. Finally, the auxiliary path flows are loaded into current path flows using “MSA”.
Input: Transportation network , capacities , traffic demand and split capacities ; related parameters by bus: related parameters by car: , convergence precision and iteration number ;
Output: Bus related ; Car related .
Step 0: Initialization. For
Step 1: Perform an all-or-nothing assignment. For , calculate using Equation (5); For , calculate using Equation (6); Calculate using Equations (3), (4), (7) and (8);
Step 2: Calculate additional flow path. Calculate additional flow path and using Equation (12);
Step 3: Update path flow using.
For , calculate auxiliary path flows ; For , calculate auxiliary path flows ;
Step 4: Check convergence. If or , and . Then go to Step 5; otherwise, let , go to Step 1;
Step 5: Calculate using Equations (10) and (11)
3.2. Algorithm 2. The Shuffled Frog Leaping Algorithm (SFLA) of the Upper Level Model
3.2.1. Shuffled Frog Leaping Algorithm
Shuffled frog leaping algorithm (SFLA) was developed by Eusuff and Lansey [
31]. It is a meta-heuristic optimization method which combines the benefits of genetic-based memetic algorithm (MA) and the social behavior-based particle swarm optimization (PSO) algorithm. The meme is a kind of information body for distribution, reproduction, and exchange by infecting the thought of human or animal. The most obvious characteristics of meme algorithm is that memes can share and exchange experience, knowledge and information between memes or in each meme by a local search method in the process of evolution.
In the Shuffled frog leaping algorithm, the population consists of the frogs with similar structure. Each frog represents a solution. The entire population is divided into many subgroups. Each subgroup performs local search. They can communicate with each other and improve their memes among local individuals. After a pre-defined number of memetic evolution steps, information is passed between memeplexes in a shuffling process. Shuffling ensures that the cultural evolution towards any particular interest is free from bias. The local search and the shuffling processes alternate until satisfying the stopping criteria.
For the problem of D dimensions, a frog is thought as = (fi1, fi2,…, fiD). The algorithm first randomly generates F frogs as the initial population, ranks them in descending order according to the fitness of each frog. Then the entire population is divided into m subgroups, and each subgroup contains n frogs. From the initial population, the first frog is selected in the first subgroup, the second frog is selected in the second group, until the mth frog is selected in the mth subgroup. Then, the (m + 1)th frog is selected in the first subgroup. Repeat the process, until all frogs are distributed.
In each subgroup, the frog with the best fitness and the worst fitness are denoted as Fb and Fw, respectively. While, in the total population, the frog with the best fitness is denoted as Fg. The main work of SFLA is to update the position of the worst-performing frog through iterative operation in each subgroup. Its position is improved by learning from the best frog of the sub-memeplex or its own population and position. In each subgroup, the new position of the worst frog is updated according to the following equation.
Equation (25) is used to calculate the updating step vector S, Smax means the maximum step size allowed to change by frog individual. Rand ( ) is the random number between 0 and 1. Equation (26) updates the position of Fw. If a better solution is attained it will replace the worst individual. Otherwise, Fg will instead of Fb. Then, recalculate Equation (25). If it still cannot get a better solution, new explanations, generated randomly, will replace the worst individual. Repeat until a predetermined number of iterations, and complete the round local search of various subgroups. Then all subgroups of the frogs are re-ranked in mixed sort, and divided into sub-group to the next round of local search.
3.2.2. Coding
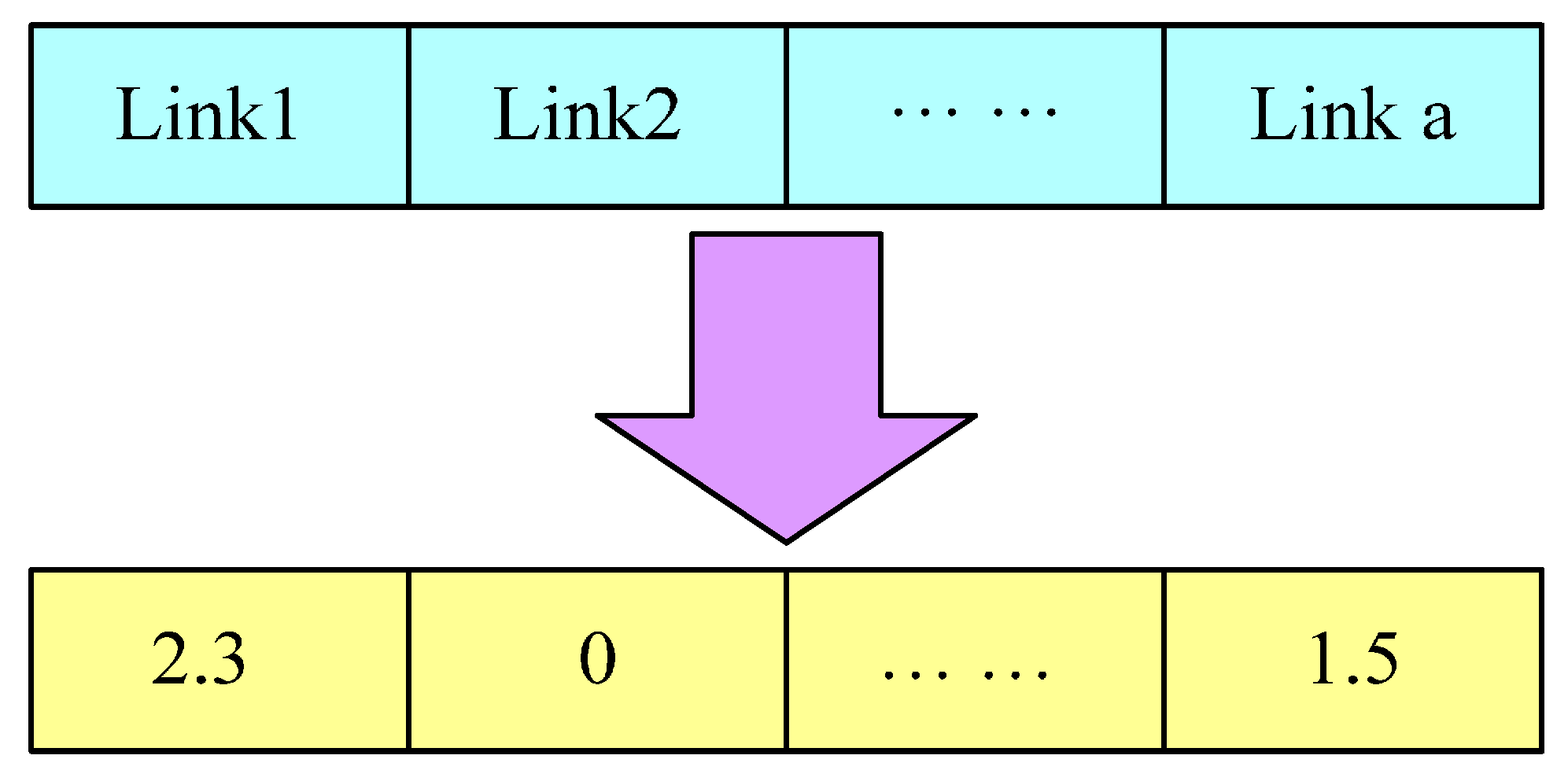
In this paper, a multi-dimensional code format based on real numbers is introduced. Each gene value of the individual is in a range of a floating point number. The coding length of individuals is equal to the number of links. In this paper, each coding can be shown as in
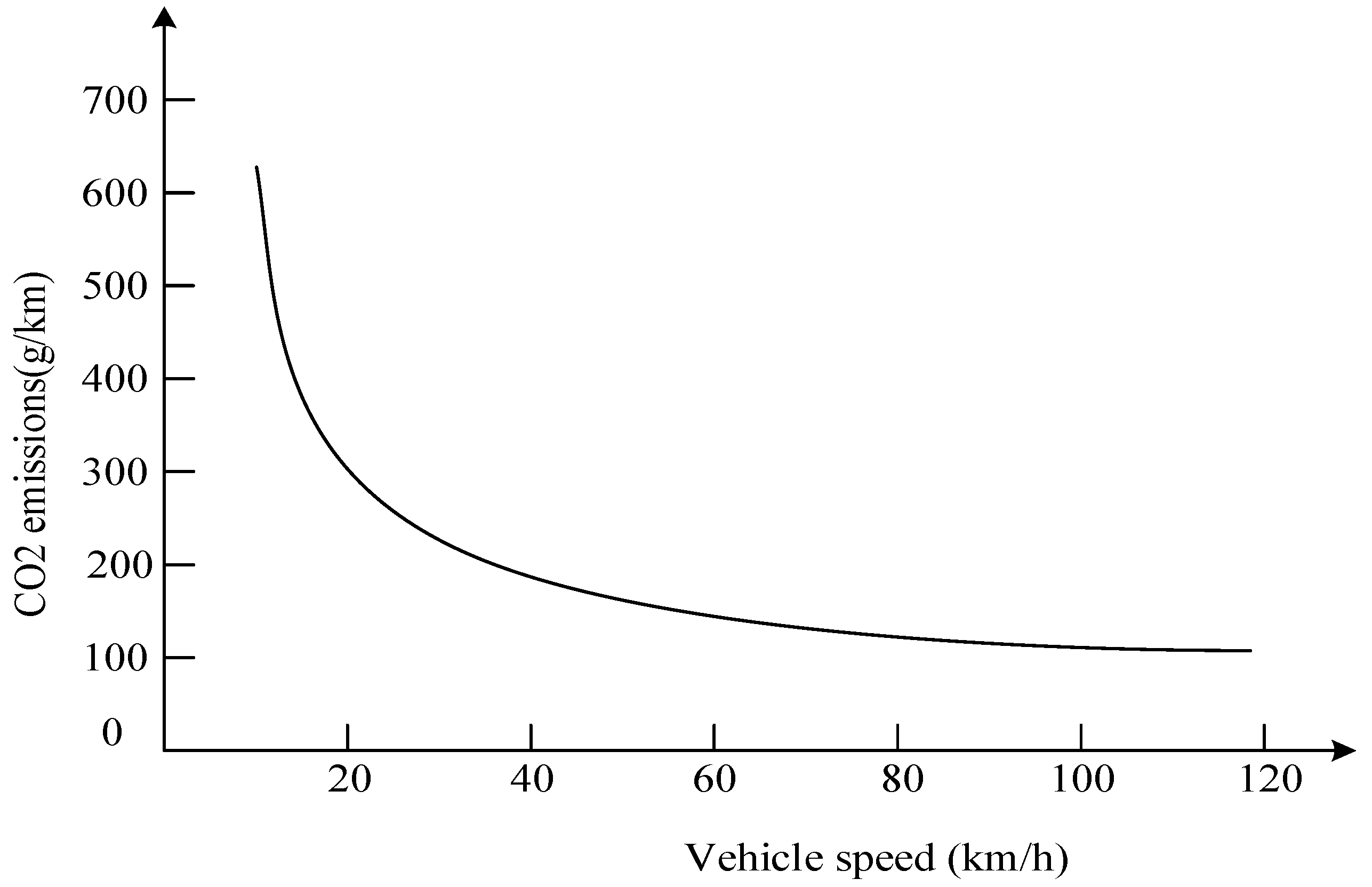
Figure 2. The traffic congestion pricing of each link generates randomly within the scope of a floating point number.
Figure 2.
Example of coding.
Figure 2.
Example of coding.
3.2.3. The Process of Algorithm
The general structure of SFLA can be described as follows:
Step 0: Input population size, the maximum number of iterations . Define the chromosome segment and the code rule of chromosome.
Step 1: Initial population. Randomly generate an initial population with F individuals (F = m × n), according to the maximal congestion pricing and population size. For the D dimension optimization problem, the individuals of the population are D dimension variables and it represents the frog’s current position. Calculate using Algorithm 1; then calculate current minimal transportation system costs using Equation (23), which represented by ; let ;
Step 2: For , calculate their fitness function , which is used to determine if the performance of the position is good. Then note individuals in descending order according to the fitness of each frog.
Step 3: Divide the population into m subpoplations: Y1, Y2, ..., Ym. Each sub population contains n frogs.
Step 4: In each subgroup, with its evolution, the positions of individuals have been improved. The following steps are the process of the subgroup local search.
Step 4.0: In each sub population, compute Fb and Fw, respectively. Set im = 0. im represents the number of the sub population, which is from 0 to M. Set in= 0. in represents the number of evolution which is from o to N (the maximum evolution iteration in each sub population).
Step 4.1: im = im + 1
Step 4.2: in = in + 1
Step 4.3: Try to adjust the position of the worst frog using Equation (25) and Equation (26). If a better solution is attained, it will replace the worst individual. Otherwise, Fg will instead of Fb. Then, recalculate Equation (25). If it still cannot get a better solution, new individual generated randomly will replace the worst individual.
Step 4.4: If in < N, then do Step 4.2
Step 4.5: If im < M, then do Step 4.1
Step 5: Implementation mix operations. After each subgroup carrying out a certain number of meme evolution, merge each subgroup Y1, Y2, ..., Ym. to X, descend X again and updates the best frog Fg in the populations.
Step 6: Stop check. If the iterative termination conditions meet, then stop, calculate using Algorithm 1; then calculate current minimal transportation system costs using Equation (23). Otherwise, do Step 3 again.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

