
Vehicle Target Detection Network in SAR Images Based on Rectangle-Invariant Rotatable Convolution


Abstract
:
1. Introduction
2. Proposed Method
2.1. Network Architecture
- (1)
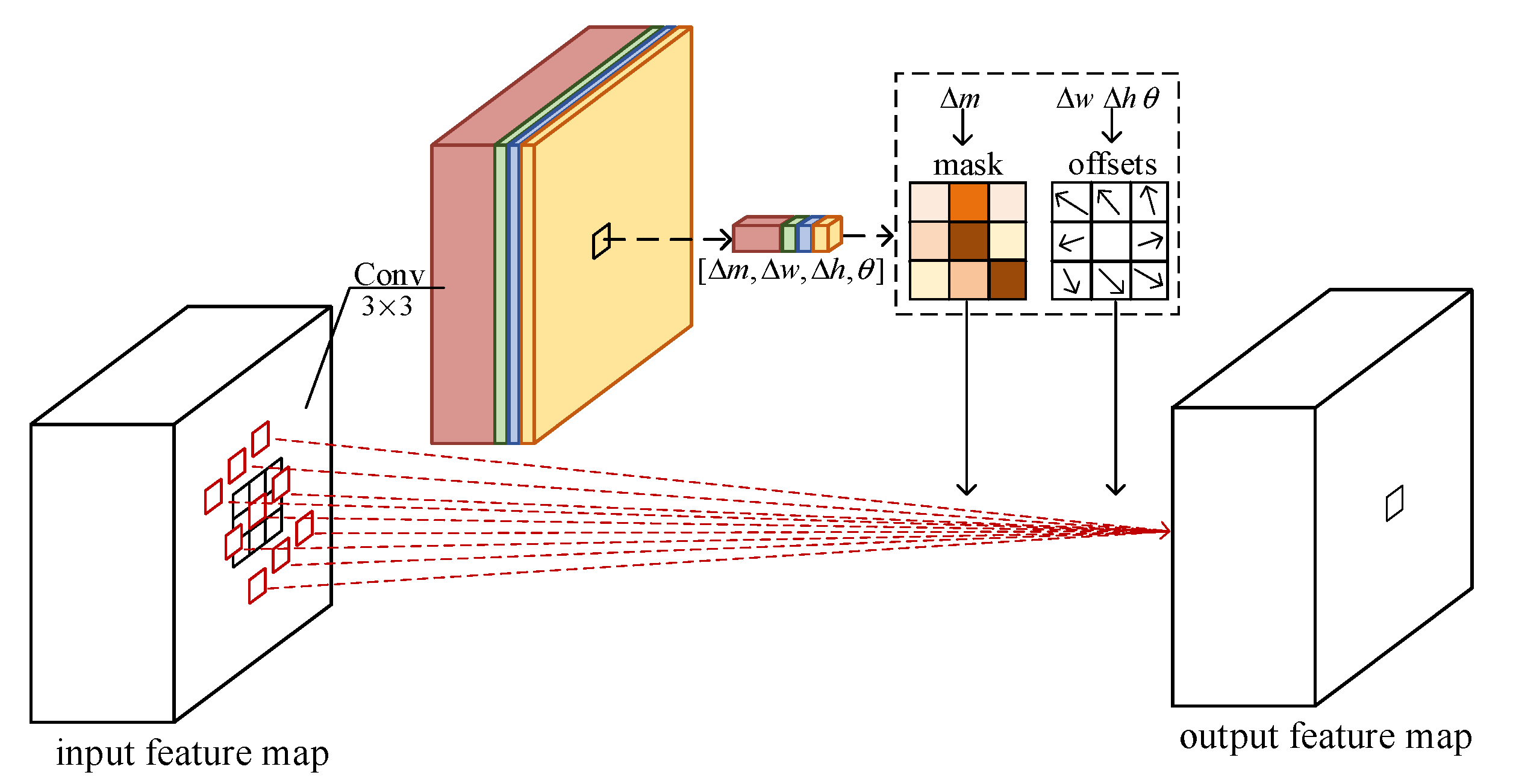
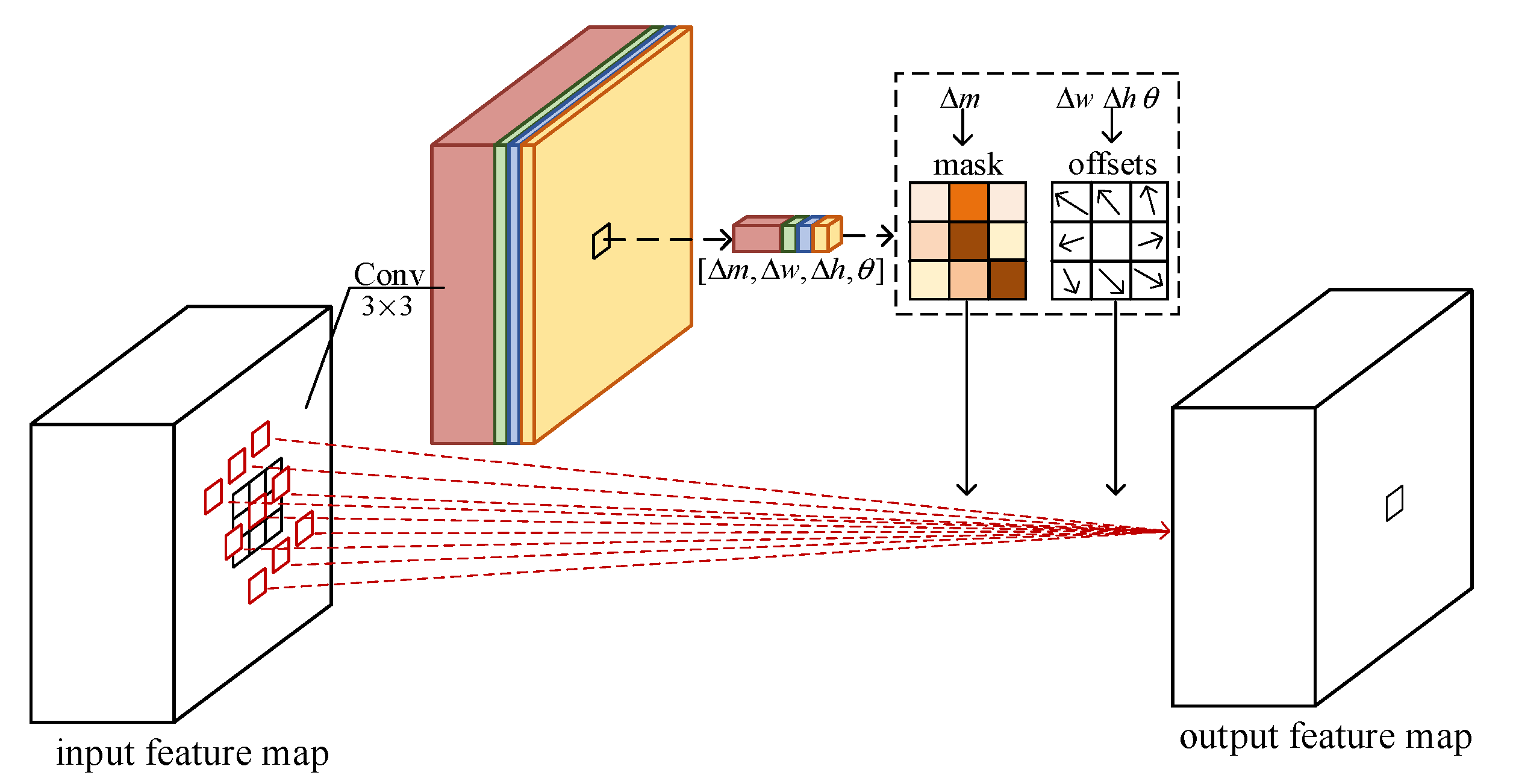
- Feature extraction module with RIRConv. This module is used to extract deep features of input SAR images. Its backbone is the truncated VGG16 network [11], which consists of 10 convolutional layers with convolutional kernels and three pooling layers. In the feature extraction module with RIRConv, the proposed RIRConv replaces the first two convolutional layers of the truncated VGG16.
- (2)
- Detection module. The detection module is added following the feature extraction module with RIRConv. It first extracts feature maps of five scales, the sizes of which are , , , , and , respectively. Then, these feature maps are fed into the convolutional predictors to output the detected boxes and the confidence score of each box.
- (3)
- Post-process module. After the detection module outputs the detected boxes, we use the non-maximum suppression (NMS) algorithm [12] to reduce the repeated detected boxes positioned to the same vehicle targets. Thus, we are able to obtain the detection results, which are the predicted specific locations of the vehicle targets.
2.2. Rectangle-Invariant Rotatable Convolution
3. Experimental Results and Analysis
3.1. Experimental Data Description
3.2. Experimental Settings
3.3. Evaluation Criteria
3.4. Comparison with Other SAR Target Detection Methods
3.5. Model Analyses
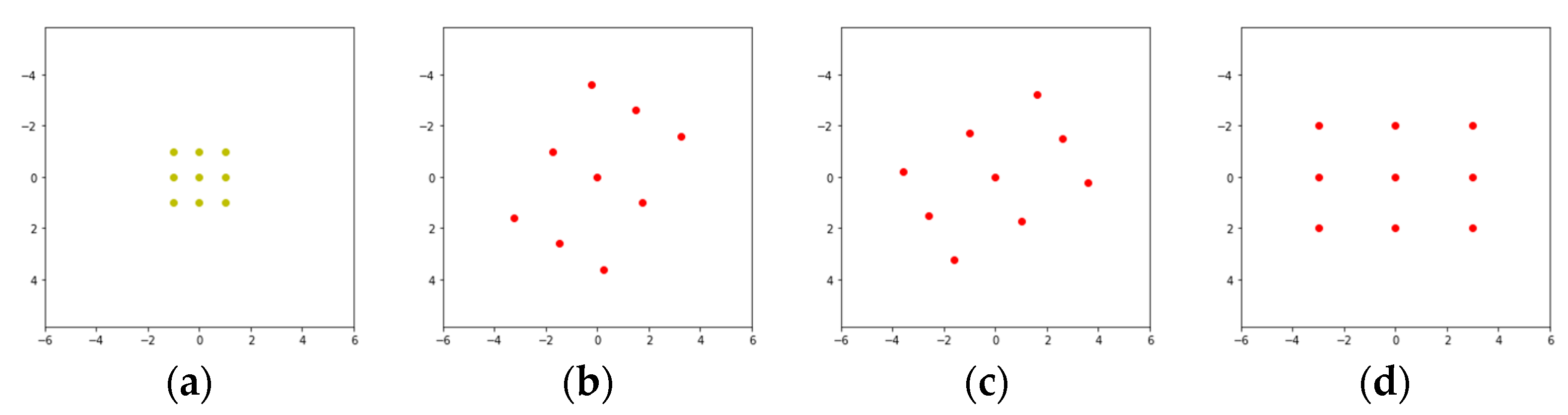
3.5.1. Sampling Locations in the RIRConv
3.5.2. Parameters, FLOPs, and Runtime Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Novak, L.M.; Burl, M.C.; Irving, W.W. Optimal polarimetric processing for enhanced target detection. IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 234–244. [Google Scholar] [CrossRef]
- Alberola-Lopez, C.; Casar-Corredera, J.; de Miguel-Vela, G. Object CFAR detection in gamma-distributed textured-background images. IEE Proc.-Vis. Image Signal Process. 1999, 146, 130–136. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards realtime object detection with region proposal networks. In Proceedings of the Neural Information Processing System, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Du, L.; Li, L.; Wei, D.; Mao, J. Saliency-Guided Single Shot Multibox Detector for Target Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3366–3376. [Google Scholar] [CrossRef]
- Wang, Z.; Du, L.; Mao, J.; Liu, B.; Yang, D. SAR target detection based on SSD with data augmentation and transfer learning. IEEE Geosci. Remote Sens. Lett. 2018, 16, 150–154. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, 20–24 August 2006; pp. 850–855. [Google Scholar]
- SANDIA Mini SAR Complex Imagery. Available online: http://www.sandia.gov/radar/complex-data/index.html (accessed on 10 January 2018).
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Two-parameter CFAR | 0.3789 | 0.7966 | 0.5135 |
| Gamma CFAR | 0.3931 | 0.8136 | 0.5301 |
| Faster R-CNN | 0.8115 | 0.8051 | 0.8083 |
| Original SSD | 0.8468 | 0.8814 | 0.8638 |
| DA-TL SSD | 0.8843 | 0.8983 | 0.8912 |
| RefineDet | 0.8828 | 0.9237 | 0.9027 |
| Proposed method | 0.9134 | 0.9431 | 0.9280 |
| Parameters | FLOPs | Runtime (Seconds/Per Test Sub-Image) | |
|---|---|---|---|
| Faster R-CNN | 0.102 | ||
| SSD | 0.015 | ||
| RefineDet | 0.054 | ||
| Proposed method | 0.021 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Du, Y.; Du, L. Vehicle Target Detection Network in SAR Images Based on Rectangle-Invariant Rotatable Convolution. Remote Sens. 2022, 14, 3086. https://doi.org/10.3390/rs14133086
Li L, Du Y, Du L. Vehicle Target Detection Network in SAR Images Based on Rectangle-Invariant Rotatable Convolution. Remote Sensing. 2022; 14(13):3086. https://doi.org/10.3390/rs14133086
Chicago/Turabian StyleLi, Lu, Yuang Du, and Lan Du. 2022. "Vehicle Target Detection Network in SAR Images Based on Rectangle-Invariant Rotatable Convolution" Remote Sensing 14, no. 13: 3086. https://doi.org/10.3390/rs14133086
APA StyleLi, L., Du, Y., & Du, L. (2022). Vehicle Target Detection Network in SAR Images Based on Rectangle-Invariant Rotatable Convolution. Remote Sensing, 14(13), 3086. https://doi.org/10.3390/rs14133086