1. Introduction
Remote sensing technology refers to technology that collects electromagnetic radiation information on Earth objects via aviation, aerospace, or artificial satellites and recognizes the Earth’s environment and resources. Due to the increasing maturity of the aviation industry, the count and quality of remote sensing images (RSIs) have improved significantly, and it is important to explore how to obtain and utilize the information in RSIs [
1]. Remote sensing object detection (RSOD) is a popular study interest in RSI processing, with the aim of identifying the categories of objects of interest in RSIs and detecting the locations of objects [
2]. Compared to natural scene images, RSIs have higher resolution, wider coverage, and contain more information. Based on the above advantages, RSOD is widely utilized in the following fields:
In military reconnaissance, RSOD techniques can detect aircraft, missiles, and other military equipment and facilities, which is convenient for the rapid acquisition of military intelligence and is an important part of the modern military system.
In urban planning, the relevant departments use RSOD techniques to quickly obtain urban topography, traffic conditions, and other data, which is conducive to the coordination of urban spatial layouts and the rational use of urban land.
In agricultural monitoring, RSOD techniques are used to monitor crop growth, pests, and other information to take preventive measures to reduce economic losses.
Due to the increasing maturity of deep learning, the performance of RSOD has significantly improved. However, there are still some challenges in RSOD, as described below:
The proportion of small objects is large. Small objects are easily missed due to a lack of feature information, which affects the detection effect. For example, there are more small targets in
Figure 1a, which creates challenges in RSOD.
The scales of objects greatly vary. Objects of the same category or different categories in RSIs are quite different in scale, and the scales presented by the same object may vary at different resolutions. As shown in
Figure 1b, the scale of the playground is large, while that of the car is small, which requires the detection algorithm to have strong scale adaptability.
The background is complex. As shown in
Figure 1c, remote sensing imaging is influenced by light, weather, and terrain, which increases the background noise of RSIs and makes the objects hard to detect.
As traditional detection methods, the VJ Detector [
3], the histogram of oriented gradients (HOG) [
4], and the deformable parts model (DPM) [
5] are mainly based on the manual extraction of features, and have high computational complexity. Deep learning-based methods can automatically extract features and have better performance. As two-stage methods, R-CNN [
6], SPPNet [
7], Fast R-CNN [
8], and Faster R-CNN [
9] have relatively high accuracy and low detection speed. One-stage algorithms, such as YOLO [
10,
11,
12,
13], improve the detection speed but are less accurate than two-stage algorithms. In recent years, one-stage algorithms have been migrated to the field of satellite observation and have obtained good detection performance. However, these methods are devised based on natural scene images. Compared to natural images, RSIs are obtained from remote distances, covering a wider range, and are influenced by factors such as lighting, weather, and terrain. Therefore, RSIs have more small objects, more multiscale objects, and more complex backgrounds. In this regard, some detection methods for RSIs have been proposed.
To enrich object features, Chen et al. [
14] combined the shallowest features with semantic info and then enhanced and fused them with deep features. However, background noise was introduced. To reduce noise interference, Fu et al. [
15] applied a balancing factor to balance the weight of feature fusion. However, this method is less robust to different tasks. Schilling et al. [
16] used deconvolution to enlarge the scale of deep features and combined them with shallow features. Hou et al. [
17] suggested a fusion tactic of cascade features, which fuses spatial features and semantic features to fuse the features of each layer and strengthen the cascade impression. Qu et al. [
18] devised an efficient feature fusion network using extended convolution to enhance the effective perception field of deep features. Although the above methods ameliorate the problem of small targets in RSIs, they reduce the inference speed.
FPNs [
19] fuse underlying visual characteristics with high-level semantic features and can predict on various scales. Yang et al. and Zou et al. [
20,
21,
22] employed a dense feature pyramid based upon the FPN to additionally enhance the connection among characteristics of diverse scales. Fu et al. [
23] increased an additional bottom-up connection after the top-down FPN to fuse the bottom features with the high-level visual features, which further enhanced feature expression ability. FMSSD [
24] used the FPN and multiple sampling rates to form a spatial feature pyramid that fuses context information into multiscale features. These methods improve the performance of multiscale object detection. Nevertheless, the equilibrium between accuracy and velocity cannot be achieved well.
To reduce the background interference, Zhang et al. [
25] extracted the feature mask of the objects and the background and introduced the pixel attention mechanism to weight the classes. However, this approach relies on prior knowledge and lacks universality. After extracting multiscale features, Li et al. [
26] utilized the attention mechanism to enhance the features of each feature map. SCRDet [
27] proposed a supervised attention network to decrease background noise. Li et al. [
28] designed a salience pyramid fusion strategy to suppress background noise and introduced global attention mechanisms to enhance semantic information. Although attentional mechanisms can effectively weaken background information, they introduce additional mask calculations. Lightweight convolution is often used to reduce computational costs. Li et al. [
29] proposed a lightweight convolutional called GSConv. Although this method requires more training data and increases tuning difficulty, the sparse connectivity and group convolution adopted lighten the model and maintain accuracy. Luo et al. [
30] improved inference speed by improving the neck layer of YOLOv5 with GSConv.
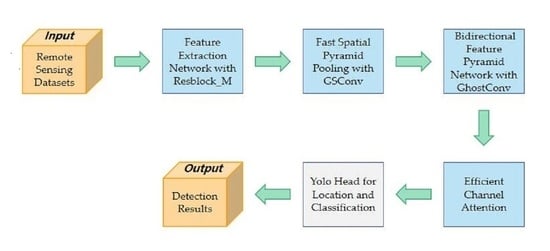
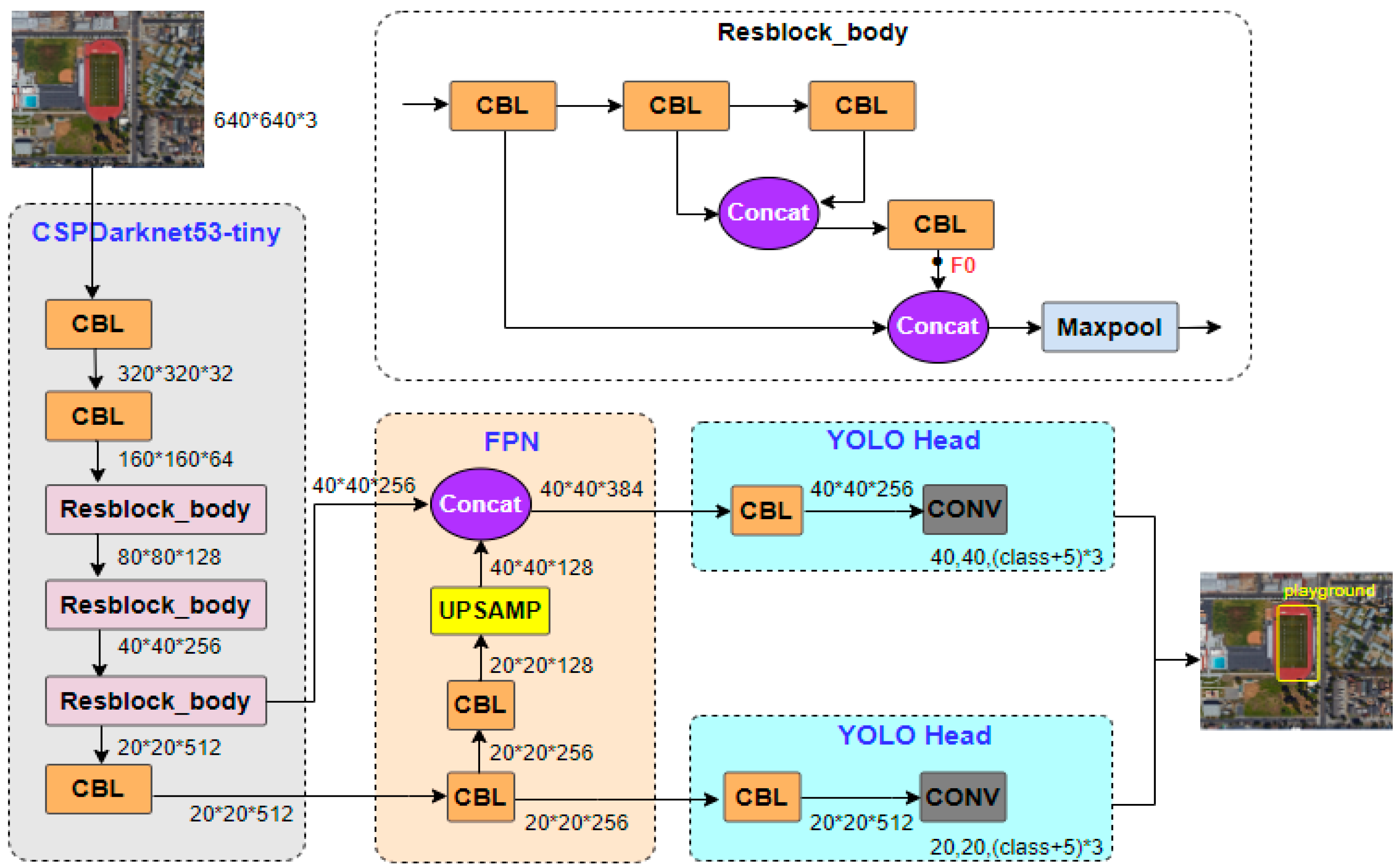
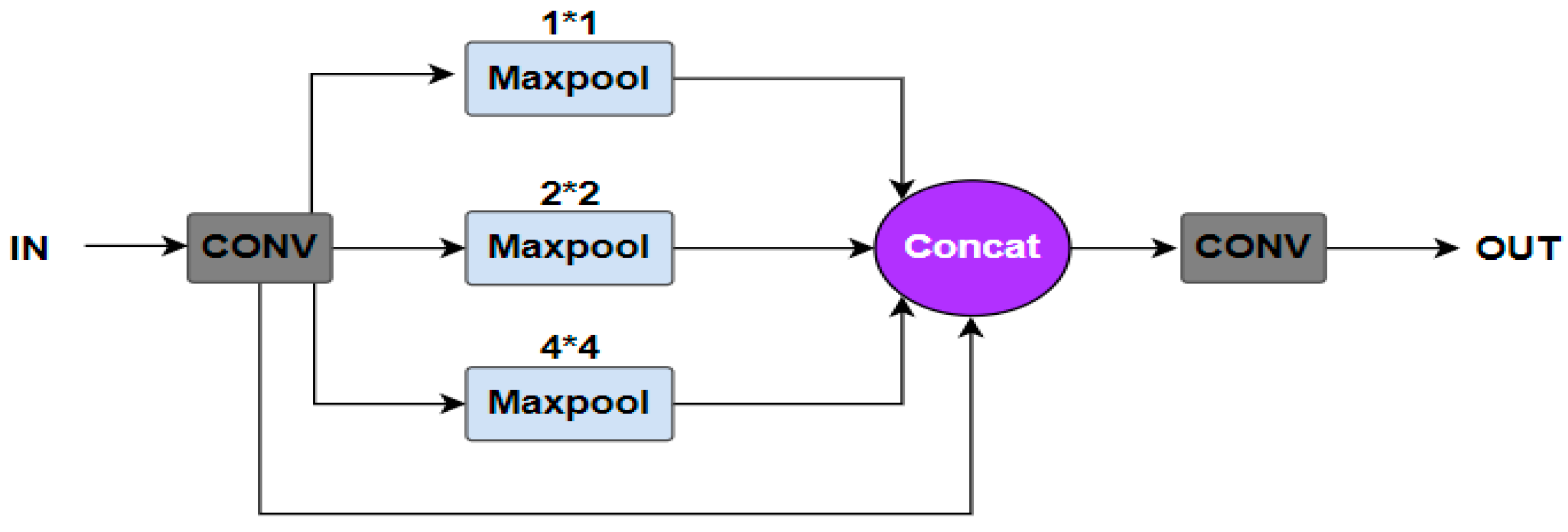
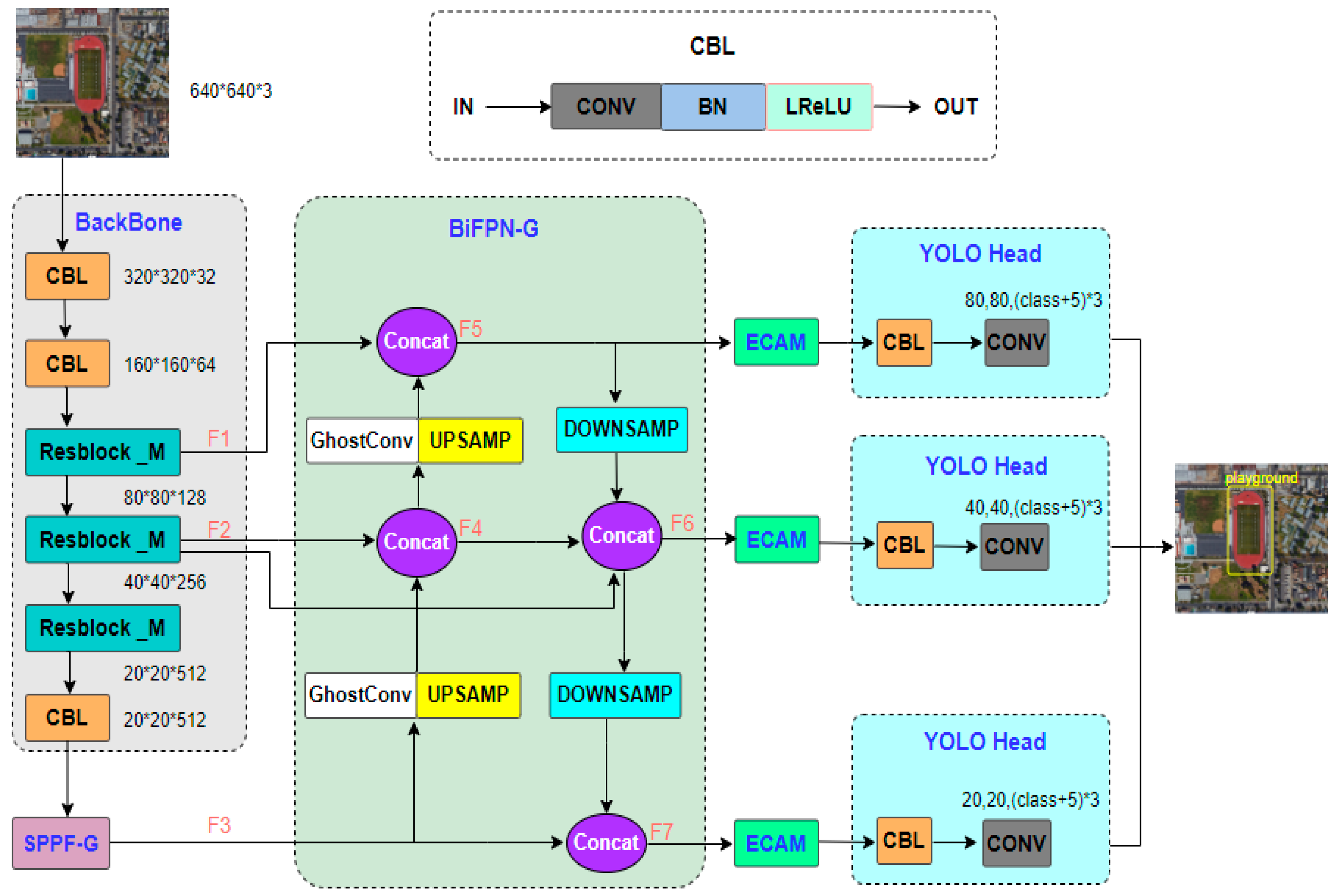
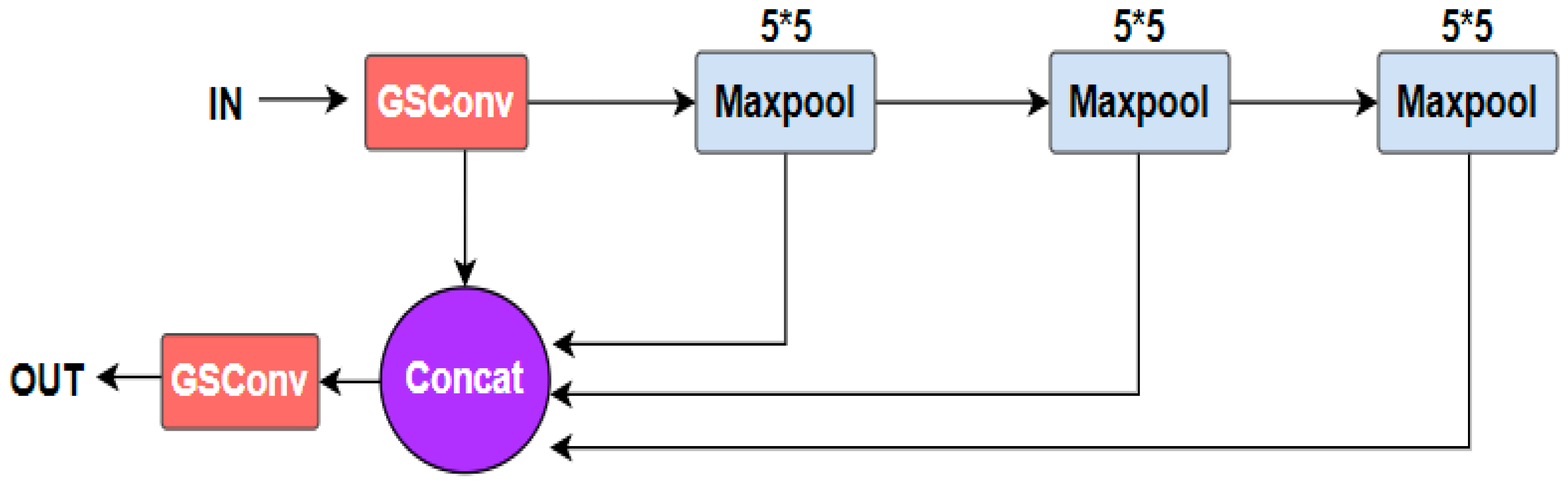
Inspired by the above methods, we propose a lightweight model that combines channel attention with multiscale feature fusion. First, we designed a fast spatial pyramid pooling incorporating GSConv (SPPF-G) for feature fusion [
7], which fleshes out the spatial features of small targets. Second, the three-layer bidirectional feature pyramid network (BiFPN-G) [
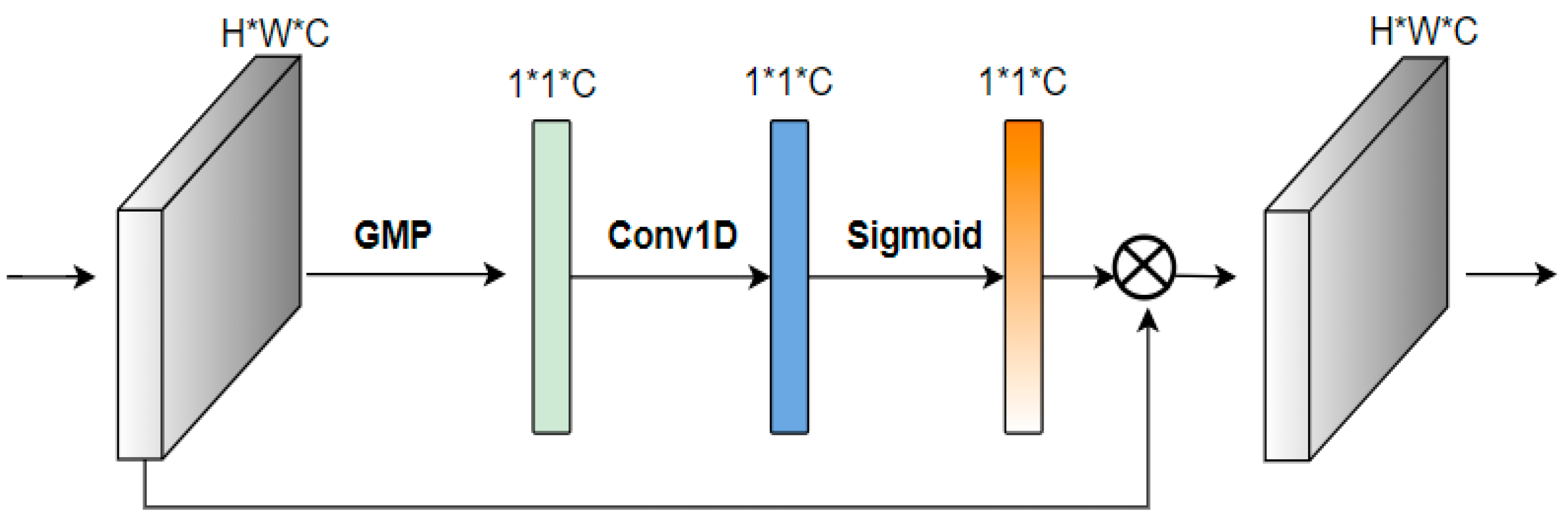
31] is suggested to integrate the deep semantic information with the shallow spatial information and to output the feature maps of different scales, which improves the scale adaptation ability of the model. Last, a novel efficient channel attention (ECAM) [
32] is suggested to reduce background interference. The above methods reduce the inference speed; we constructed a new residual block (Resblock_M) [
33] in the backbone to balance accuracy and speed.
The following are the contributions of this thesis:
We designed SPPF-G for feature fusion, which fleshes out the spatial features of small targets and improves the detection accuracy of small objects.
We modified the two-layer feature pyramid network (FPN) [
19] to a three-layer BiFPN-G to integrate the deep semantic information with the shallow spatial information, thus improving the detection ability of the model for multiscale objects.
We proposed the ECAM to enhance object information and suppress background noise and proposed a less computational residual block named Resblock_M to balance accuracy with speed.
The remainder of the paper is arranged as follows:
Section 2 presents the relevant existing methods and our proposed method.
Section 3 presents the experimental results obtained on different datasets.
Section 4 is a discussion of the experimental results and future work.
Section 5 is the summarization and future prospects of our work.
4. Discussion
In this paper, we demonstrate that BSFCDet can maintain a better balance between detection accuracy and detection speed. The results may be attributed to the following facts. SPPF-G is used to achieve feature fusion, in which the serial pooling method reduces feature redundancy, and the size of maximum pooling is unified to 5 × 5, which increases the receptive field of the images and enriches the spatial information of small objects. GSConv improves the diversity of features and robustness of the network to small objects and complex backgrounds. The three-layer BiFPN-G integrates the semantic information of deep features and spatial information of shallow features, improving the detection ability of the model for multiscale objects. Adding an output layer in the shallow layer preserves more features of small objects, improving the recognition rate of small objects. ECAM reduces background interference and enhances object features. A residual block with smaller computational complexity balances the detection accuracy and speed of the model.
However, some limitations of this study still exist. Firstly, SPPF-G, BiFPN-G, and ECAM ignore the increase in parameter quantity, which reduces the detection speed, especially when the model introduces BiFPN-G with high computational complexity, resulting in a significant decrease in detection speed. Secondly, to balance accuracy and speed, Resblock_M loses some accuracy, but does not increase the speed too much. Finally, our method only considers small objects, multiscale objects, and complex backgrounds, without considering other issues such as object occlusion in RSIs.
In summary, in the future work, we will focus on accelerating the model by designing more lightweight networks to improve both the accuracy and inference speed of the model [
52]. We will study the mixed use of non-maximum suppression (NMS) and Soft-NMS [
53] in image post-processing, integrating the advantages of both, removing redundant bounding boxes, and improving the model’s robustness to object occlusion. Specifically, two thresholds, N1 and N2, are set. When IOU is higher than N1, traditional NMS is directly executed for filtering. When IOU is between N1 and N2, Soft-NMS is executed to reduce the confidence of overlapping anchor boxes. When IOU is lower than N2, no operation is performed.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}