1. Introduction
Techniques for monitoring plant physiological and healthy status and their spatiotemporal variation will benefit more precise and target-oriented crop management. Cereal leaf diseases such as powdery mildew and leaf rust frequently infect barley plants and affect the economic value of malting barley. Chlorophyll plays a crucial role for the photosynthetic processes including light harvesting and energy conversion, and thus the content of chlorophyll is a potential indicator of a range of stresses [
1]. Early detection of crop diseases and accurate assessment of chlorophyll variations are important to help crop managers to efficiently make applications of agrochemicals and fertilizers [
2,
3].
Active fluorescence techniques allow the sensing of plant physiological changes and are less affected by weather conditions than the passive ones [
4,
5]. The intensity of chlorophyll fluorescence emitted by plants is governed by both the photosynthetic activity and chlorophyll concentration [
6]. Red and far-red chlorophyll fluorescence and blue-green fluorescence (BGF) signals can be used for the detection of plant stresses as they often change before visible symptoms are detectable, for example water deficiency and heat stresses often lead to an increase in BGF and chlorophyll fluorescence, respectively [
7–
9].
Spectrally resolved fluorescence signals are typically expressed in the form of fluorescence ratios in order to be less dependent on instruments, on the intensity of exciting light and the distance of fluorescence detection [
10,
11]. The red/far-red chlorophyll fluorescence ratio (RF/FRF) is determined primarily by the
in vivo chlorophyll content, of which the high amount has more reabsorption of RF while little effect on the FRF [
12–
14]. Hence, the decline in chlorophyll content caused by biotic or abiotic stresses often result in an increase of RF/FRF [
12,
15]. In contrast, Gitelson
et al. [
16] suggested that the inverse form as far-red/red fluorescence ratio (FRF/RF) might be more precise for quantifying the chlorophyll in a wide range. Although fluorescence indices allow the non-invasive estimation of chlorophyll content, it is often unavoidable that they are nonlinearly related to chlorophyll content and lose the sensitivity when chlorophyll reaches a certain level [
16–
18]. Therefore, comprehensive algorithms might be useful to improve the use of fluorescence signals in such situations. Partial least squares (PLS) [
19] and support vector machines (SVM) [
20] have been widely used in hyperspectral remote sensing studies [
21,
22]. The partial least squares (PLS) method has the desirable property that solves not only the problem of strong co-linearity but also the problem of regression singularity due to small sample size and high dimension of predictive variables [
19]. PLS is particularly relevant in the situation where modeling data consist of many predictors relative to the number of observations [
23]. Atzberger
et al. [
23] highlighted the advantage of PLS in dealing with multi-collinearity over stepwise multiple linear and principal component regressions, even when the number of observations was smaller than the number of predictive variables. The support vector machines (SVM) method has been widely used for classification problems [
21,
24–
26] and for retrieving biophysical parameters [
27,
28]. For non-linear problems in particular, the SVM transforms the nonlinearity into a linear regression via mapping the original input space to a high dimensional feature space [
29].
Blue/red (BF/RF) and blue/far-red (BF/FRF) fluorescence ratios and combined fluorescence indices also allow to detect various stresses [
8,
30] such as water [
9] and nitrogen (N) deficiencies [
11,
31,
32] and to monitor changes in chlorophyll and polyphenols [
11,
33]. However, studies on detecting cereal diseases or estimating chlorophyll content of barley plants are scarce. Buschmann and Lichtenthaler [
34] reported that maize plants grown without nitrogen yield higher blue-green fluorescence and also the higher values of the fluorescence ratios BF/FRF and BF/RF. Langsdorf
et al. [
35] also found that BF/RF and BF/FRF ratios are the most sensitive indicators to distinguish different N treatments. As aforementioned, fluorescence indices for chlorophyll are of potential for detecting diseases, as well as for estimating leaf N content since leaf chlorophyll is related to leaf N content [
4,
36]. However, how early fluorescence indices can sense cereal diseases is not well known as diseases may precede significant losses in chlorophyll or N [
37]. Furthermore, under natural conditions the changes in fluorescence signals/indices in response to foliar diseases are usually caused by cross infections.
Recent studies have made progress on detecting diseases and nutrient stresses by hyperspectral remote sensing [
32,
38–
40]. Reflectance indices have been suggested for detecting diseases such as apple leaf scab disease under well controlled conditions [
38,
39]. However, the discriminatory performances are often affected by plant phenological development [
39]. Therefore, comparisons between different hyperspectral indices are still needed to determine which method is most appropriate and which index is most reliable across phenological stages for the early detection of plant diseases, as well as between different fluorescence indices.
The objective of this study was (i) to investigate the performance of fluorescence and reflectance indices for detecting diseases in seven varieties of field grown barley and (ii) to estimate leaf chlorophyll concentration (LCC) using these indices, and PLS and SVM methods.
2. Materials and Methods
2.1. Experimental Design
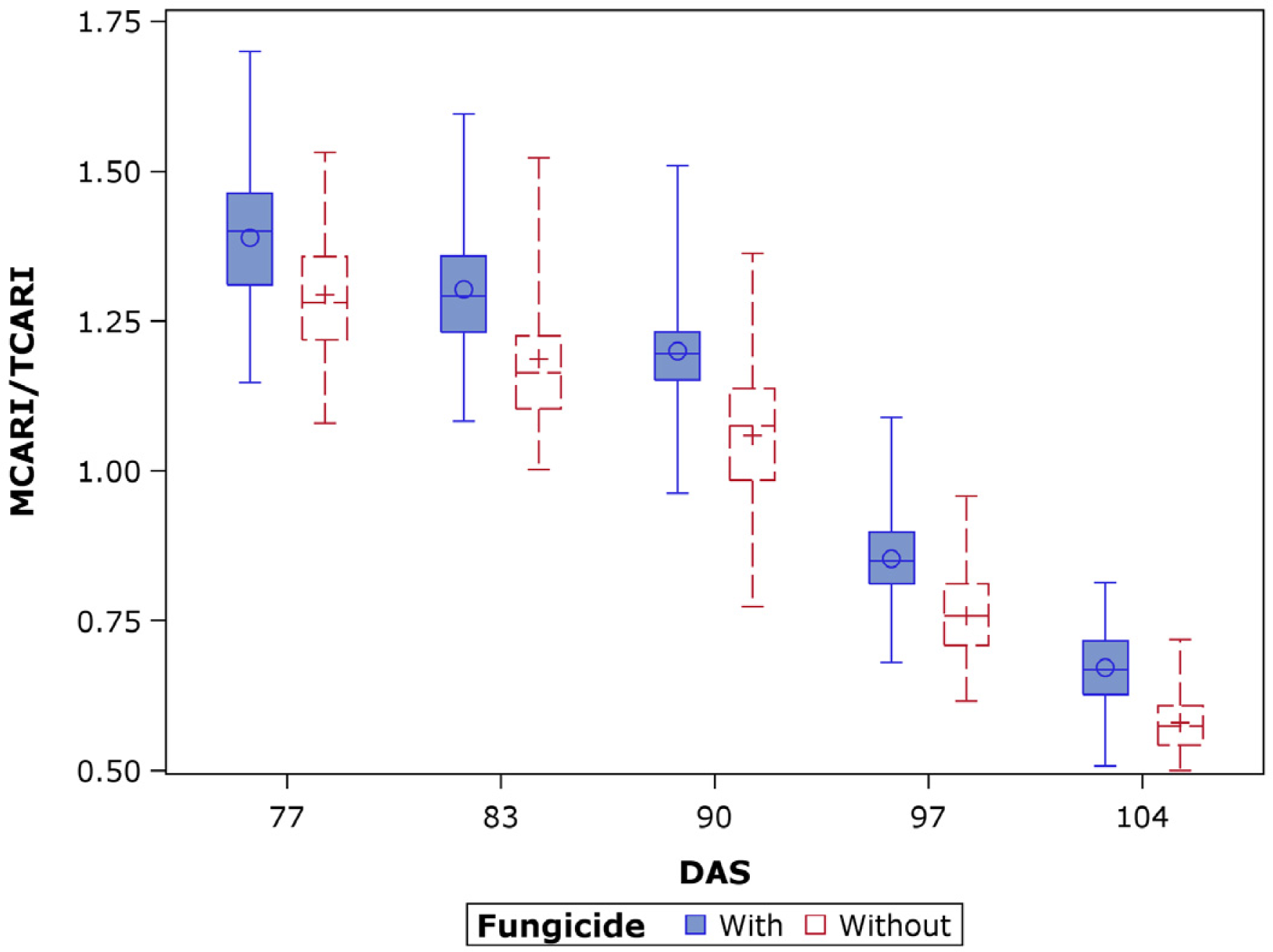
The field experiment of barley (Hordeum vulgare) was conducted at the Institute of Crop Science and Resource Conservation (INRES-Horticultural Science, 50.7299°N, 7.0754°E; 70 m.a.s.l.), University of Bonn, Germany. The soil is sandy loam with the Nmin value of 20 kg·N·ha−1. The annual average precipitation and temperature are 669 mm and 10.3 °C, respectively. The experiment was organized as a completely randomized block with three replications and a plot size of 6 m2 (4 × 1.5 m) for each variety and fungicide treatment. Ten rows of barley plants sown with a density of 320 seeds per square meter were grown in each plot. The experimental design included seven barley varieties (Belana, Marthe, Scarlett, Iron, Sunshine, Barke and Bambina) and two fungicide variants (with fungicide and without fungicide).
For the treatment group with fungicide, plants were regularly sprayed with protective or curative fungicides over the entire experimental period, while for the treatment group without fungicide no fungicides were sprayed. The seven commercial varieties of malting barley were sown on 24 March 2010. All plots were fertilized immediately after sowing with ammonium nitrate (NH4+-N) at the rate of 100 kg·N·ha−1.
For the plants of without fungicide plots, the infections were generally mild and showed only a few punctiform symptoms due to the unfavorable climatic conditions to pathogens at the study site in 2010.
2.2. Fluorescence Measurements
Random plants were preselected and marked prior to the implementation of treatment design of fungicide. From these plants, six uppermost fully expanded flag leaves were randomly sampled, stored in a cold box and immediately transported into the lab for the fluorescence measurements. The fluorescence recordings were carried out at the beginning of June up to July at weekly intervals on five dates; 9 June (77 DAS, days after sowing), 15 June (83 DAS), 22 June (90 DAS), 29 June (97 DAS) and 6 July (104 DAS). A multi-parametric fluorescence sensor, Multiplex® 3 [
41], was used in this study for the recording of fluorescence signals. Barley leaves were placed on a black anodized plate for measuring the fluorescence indices at room temperature in the lab. The mean readings of the six leaves of each plot served as the representative of each plot.
Table 1 presents the ten fluorescence indices that were investigated in this study.
2.3. Hyperspectral Reflectance Measurements
Prior to leaf sampling, canopy reflectance was measured within two hours of solar noon using QualitySpec® Pro (9 June, and 15 June) and FieldSpec® 3 (22 June, 29 June and 6 July) spectrometers from a distance of 1 m above the canopy. The same white reference panel (Spectralon) was used for calibrations for both spectrometers before spectral measurement in the field. In addition, our unpublished results of cross calibration showed that the reflectance difference is negligible, especially for the wavelengths shorter than 1,000 nm because both spectrometers were configured with the same type of detectors (ASD Inc.). The detailed configurations of the spectrometers were described elsewhere [
42]. For each of the experiment plots, six reflectance spectra were measured at six random locations within the plot. Finally, reflectance data with 1 nm steps was output for further analysis.
Table 2 shows the ten reflectance indices [
43–
49] used in this study.
2.4. Leaf Sampling and Chlorophyll Determination
After the fluorescence recordings, the six leaf samples of each plot were immediately frozen, free-dried, grounded and stored in the dark at room temperature for the determination of their chlorophyll content. The total chlorophyll content of each sample was extracted from 50 mg lyophilized material by 5 ml methanol, which was then filled up to 25 ml. After extraction, the absorbance of the extracts was measured with a UV-VIS spectrophotometer (Perkin-Elmer, Lambda 5, Waltham, MA, USA) and the leaf chlorophyll concentration (LCC) was finally determined.
2.5. Data Analysis
2.5.1. Binary Logistic Regression
To detect diseases in the without-fungicide treatment group, binary classification with logistic regression was performed. This method was successfully used in previous studies for detecting scab disease in apple leaves [
2,
38]. Logistical regression was implemented to examine the ability of each of the fluorescence and reflectance indices (
Tables 1 and
2) for detecting the event of interest (disease). Accordingly, the with- and without-fungicide treatment groups correspond respectively to 0 (healthy) and 1 (diseased) in the response variable that represents health status.
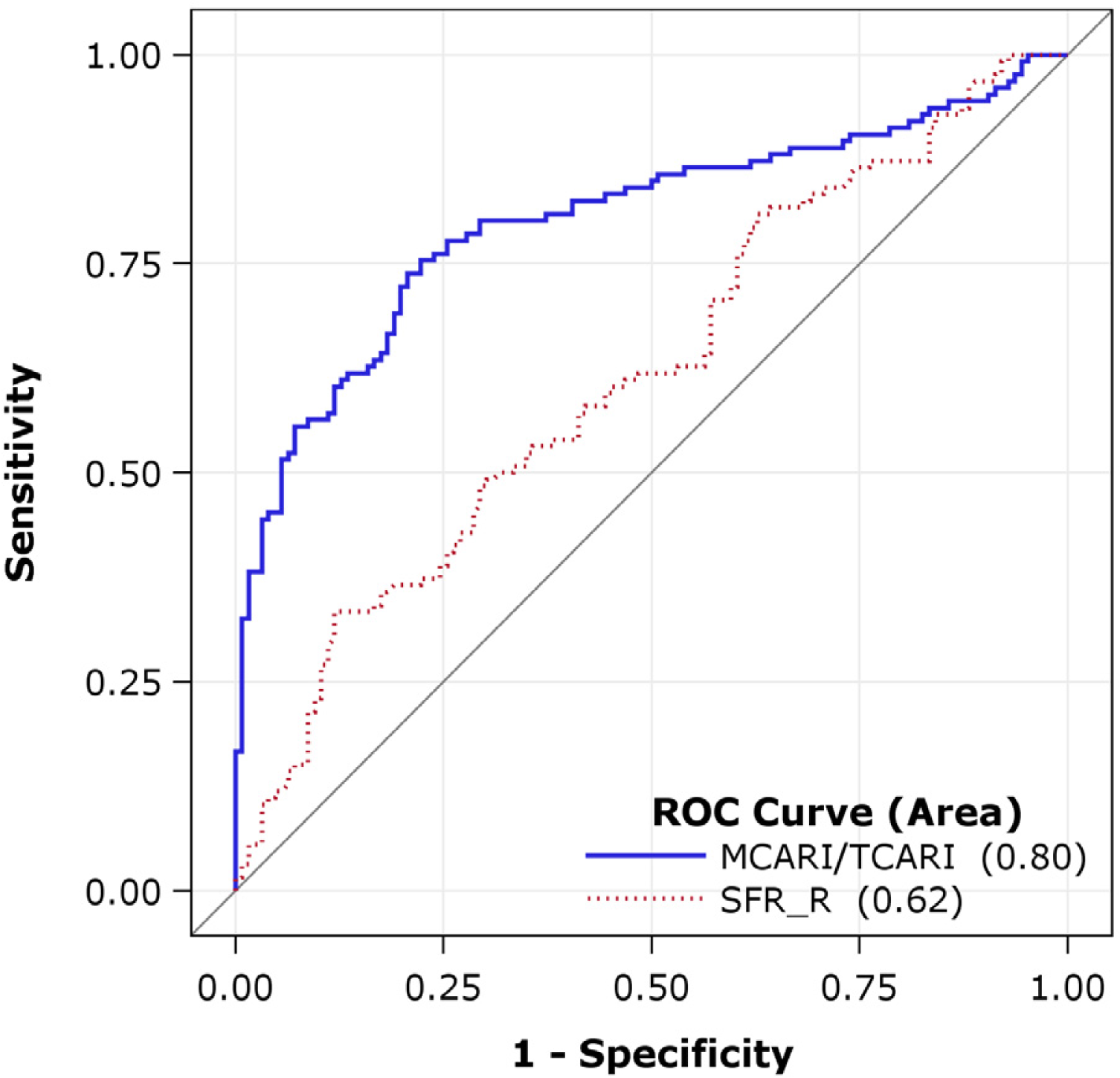
The
c-statistic was used to evaluate the discriminatory performance of different indices. The
c-value is equivalent to the area under the receiver-operating-characteristic (ROC) curve, and it ranges from 0.5 to 1. The minimum (0.5) and maximum (1) correspond to randomly guessing and perfectly discriminating the response, respectively. The general rule that considers: 0.7 ≤
c < 0.8 as acceptable discrimination; 0.8 ≤
c < 0.9 as excellent discrimination; and
c ≥ 0.9 as outstanding discrimination [
50] was used to evaluate the discriminatory performance.
2.5.2. Partial Least Squares Regression
The partial least squares (PLS) method was originally developed by the econometrician Herman Wold [
51], for use in econometrics for modeling of multivariate time series [
52]. The widely used PLS regression (PLSR), which is the simplest PLS approach for linear multivariate modeling, has the advantage that the precision of the model improves with the increasing number of variables and observations [
19].
The predictive and response variables are considered as two blocks of variables in the PLSR method [
19,
53]. The key technique implemented in PLSR is to extract the latent variables (also called factors or components), which serve as new predictors and regress the response variables on these new predictors [
54]. These new predictors (hereafter referred to as factors) are expected to explain the variation not only of the response variables but also the predictive variables. How much variation can be explained depends on how many factors are extracted. The more factors that are extracted the more variation can be explained. However, extracting too many factors increases the risk of model overfitting problem (
i.e. tailoring the model too much to the training data, leading to the detriment of predicting future observations) [
55]. Cross validation is a powerful approach to determine the number of extracted factors through minimizing the prediction error (predicted residual sum of squares, PRESS). However, using the number of factors that yield the minimum in PRESS might also lead to some degree of overfitting [
56]. Although various cross validation methods are available, one goal is always preferred that not only a minimum number of factors be selected, but also the risk of overfitting is minimized. To achieve this goal, the statistical model comparison method proposed by van der Voet [
57] is implemented. The PLSR model implemented in this study was carried out using the SAS 9.2 software package (SAS Institute Inc.).
2.5.3. Support Vector Regression
The support vector machines (SVM) method is a universal theory of machine learning developed by Vapnik [
20]. The main advantage of SVM is its ability to construct a linear function (e.g., classification/regression model) in a high dimensional feature space, where problems of non-linear relations of the training data in the original low dimensional space can be represented, transformed and solved. The support vector regression (SVR) is the implementation of SVM method for regression and function approximation [
58] and its standard concept and formulation are briefly described as follows:
Given a training set {(
xi,
yi), ..., (
xl,
yl)}, where
xi ∈ ℝ
n is a feature vector and
y ∈ ℝ is the target output (response variable). Assume that there is a linear function:
where
ŷ is the prediction of
yi,
ω is the weight vector and
b is the bias. We suppose in
Equation (1) the difference between
ŷ and
y is always extremely small in term of each
xi,
i.e., the function
f(
x) is powerful to predict y. Hence, in order to solve this linear problem of
Equation (1) SVR requires the solution of the following optimization problem:
Note that the tacit assumption in
Equation (2) was that such a function
f(
x) does actually exist and that
f(
x) approximates all pairs (
xi,
yi,) of the training set with the
ε precision [
58]. This optimization method using ε-insensitive loss function is the widely known
ε-SVR [
29], which is shown with a schematic in
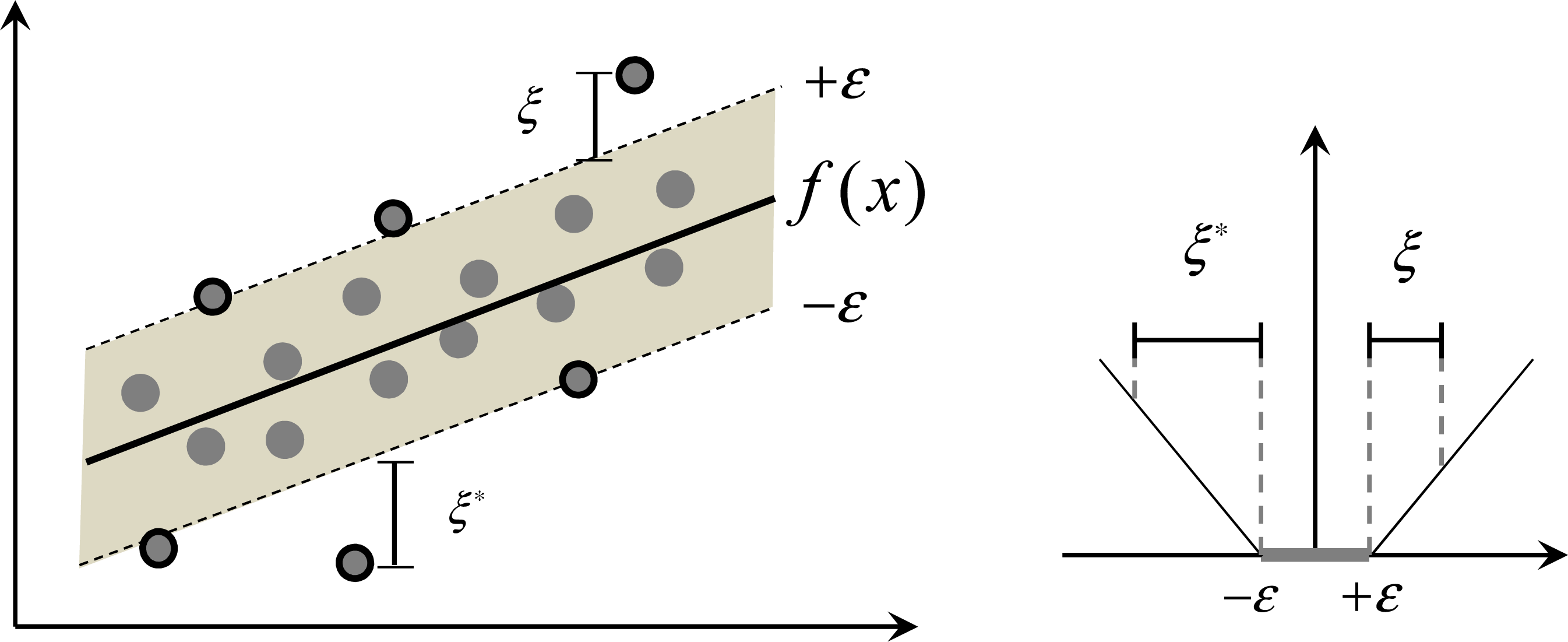
Figure 1. Only the points outside the shaded
ε-insensitive tube are called support vectors, which are penalized, and will contribute to the optimization solution [
58].
Generally, when
ε is under a reasonable range, the optimization problem is considered to be feasible. However, in practical application, it may not be feasible due to different kinds of noises and uncertainty. In this context, the slack variables
ξi and
were introduced to permit an otherwise that some instances
xi being out of the ε precision, and then the optimization problem of
Equation (2) can be represented as the formulation of the standard form of SVR by Vapnik [
20] as follow:
where (
xi,
yi) has its corresponding
ξi and
, respectively, which denotes the deviation of predicted value above +
ε and below −
ε (
Figure 1). The parameter
C is a constant to determine the tradeoff between the model complexity and the training errors [
59]. In addition to the
ε-SVR,
ν-SVR and some other kinds of SVRs, they vary in the optimization of the corresponding parameters.
Furthermore, based on kernel functions the training data will be mapped into feature space to apply the regression algorithm. Commonly used kernels include linear, polynomial, radial basis function (RBF) and sigmoid. In this study, the
ε-SVR model was implemented in MATLAB R2010a (The MathWorks, Inc.) with the LIBSVM tool [
60].
2.5.4. Model Validation
The performance of regression models for the estimation of LCC was evaluated by comparing the differences in the coefficients of determination (R
2) and root mean square error (RMSE) in predictions. The higher the R
2 and the lower the RMSE the higher the precision and accuracy of the model to predict LCC. The RMSE values were calculated according to
Equation (4),
where
yi and
ŷ are the measured and the predicated values of LCC, respectively, and
n is the number of samples.
5. Conclusions
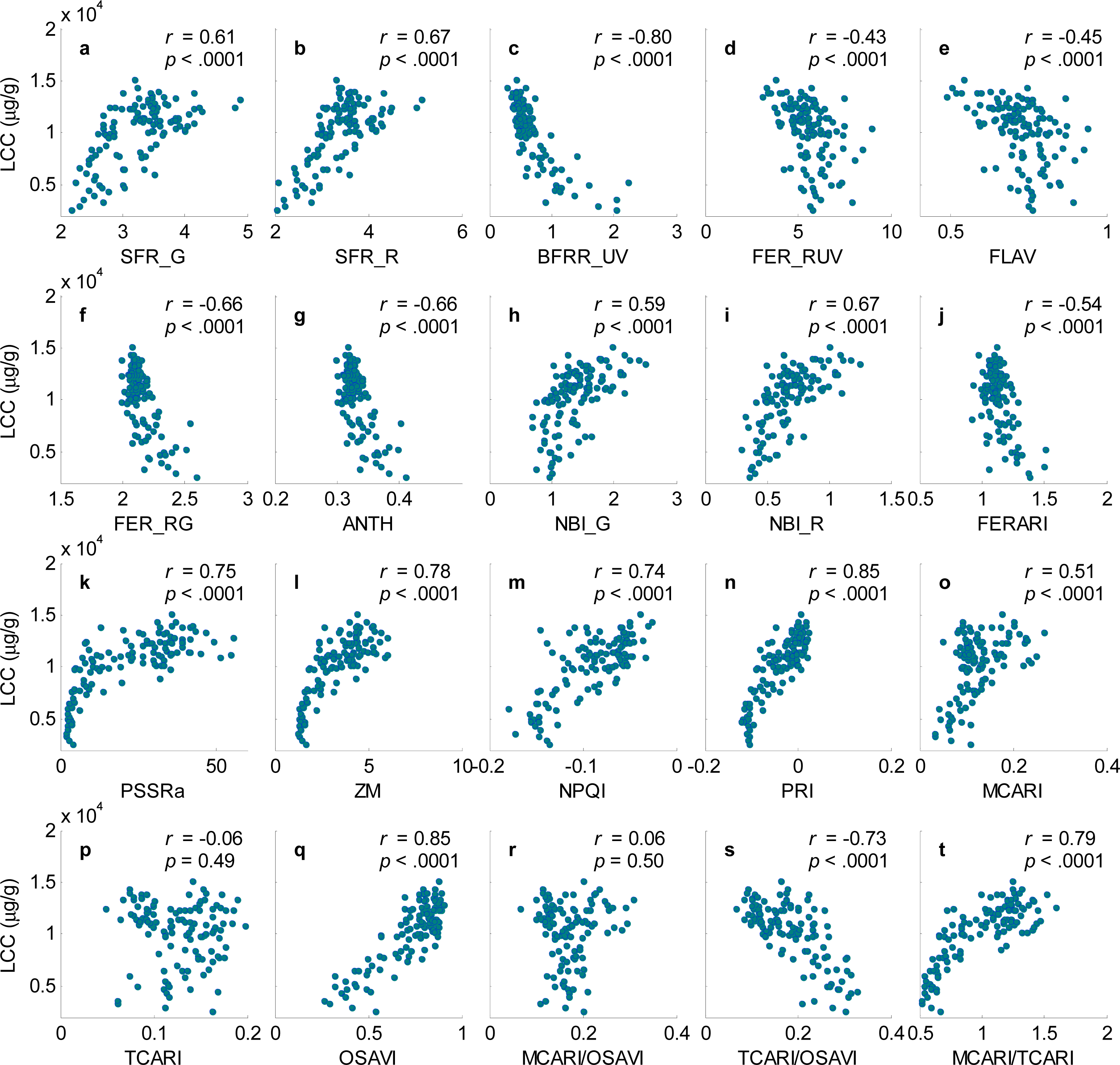
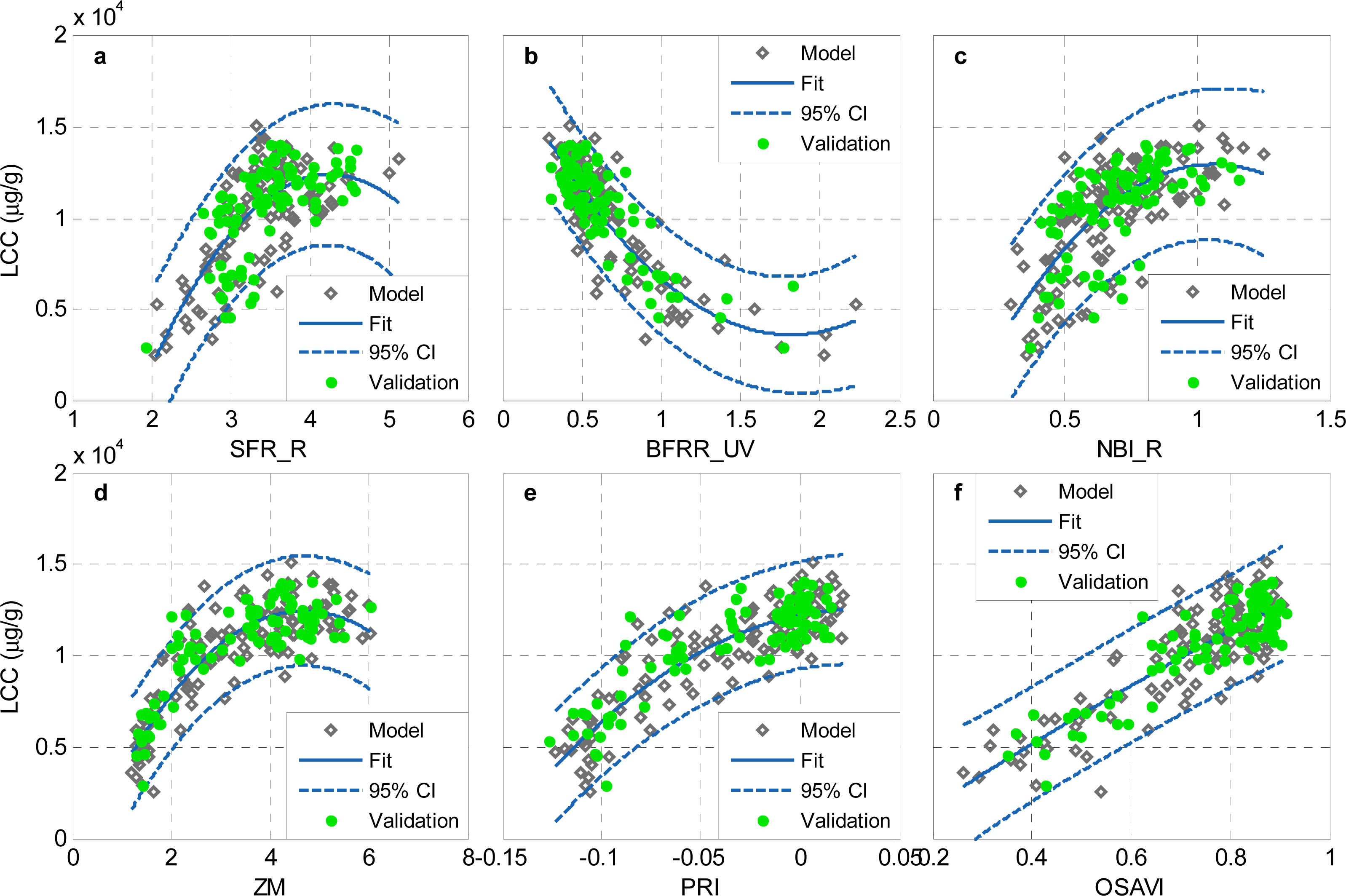
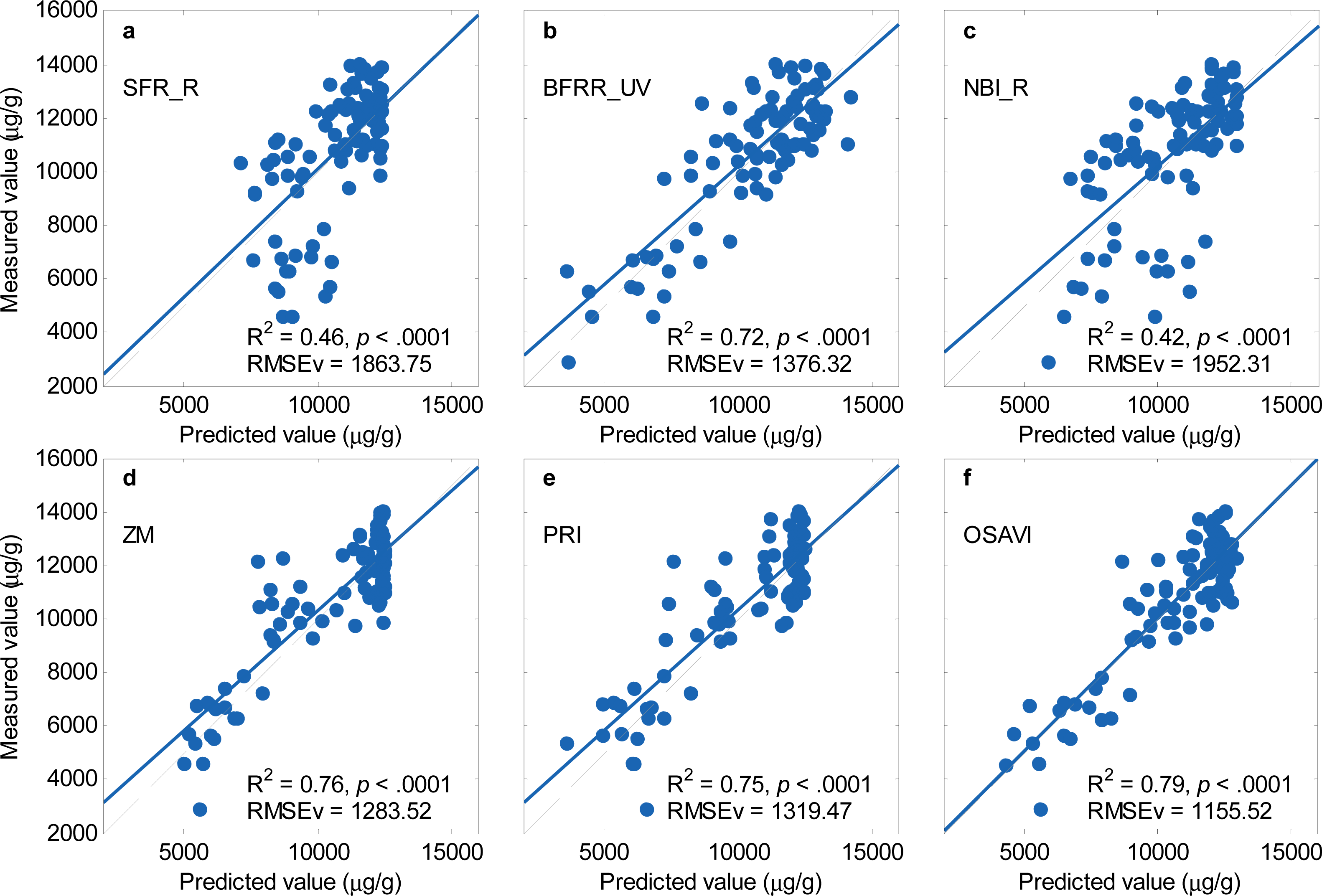
There is a time lag between the occurrence of barley diseases and significant losses of leaf chlorophyll concentration (LCC). Hyperspectral reflectance indices showed good discrimination between healthy and slightly-diseased barley plants that precede significant losses in LCC. A combination of MCARI and TCARI (MCARI/TCARI) showed a promising performance on early detecting diseases across seven barley varieties. Reflectance indices generally showed good performance on predicting LCC (R2 = 0.75 − 0.79). The blue to far-red fluorescence ratio, BFRR_UV, also performed well for predicting LCC (R2 = 0.72) compared to other fluorescence indices. However, the BFRR_UV vs. LCC relationship was nonlinear, which still constrained the accuracy for LCC estimation. PLSR and SVR models overcome the nonlinear problem, significantly increased the accuracy in estimating LCC (R2 > 0.81).
The possible shortage of this study is that fluorescence signals were measured on individual leaves while hyperspectral reflectance were measured on canopy level, thus a meaningful comparison between the fluorescence and reflectance indices is not possible. Future studies should consider performing canopy level fluorescence and hyperspectral measurements for cross comparisons, for example mounting the fluorescence sensor on a wheeled platform [
11].
Further studies on different species under different environmental conditions remain to be undertaken to explore the full potential of fluorescence and hyperspectral remote sensing for detecting and identifying crop diseases, which would facilitate the fungicide-specific management in precision agriculture.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}