1. Introduction
Cloud and haze are two common atmospheric phenomena that often contaminate optical remote sensing images. The existence of these contaminations degrades image quality and can significantly affect remote sensing applications, such as land cover classification [
1], change detection [
2] and quantitative analysis [
3]. For this reason, cloud and haze removal have become two essential pre-processing steps. Cloud and haze have different optical properties, and thus must be treated differently. Cloud normally blocks nearly all reflected radiation along the viewing path; hence, substitution with clear-sky pixels recorded at different time is usually suggested for recovering the lost surface information [
4]. Haze generally refers to spatially varying, semi-transparent thin cloud and aerosol layers in the atmosphere [
5,
6]. The semi-transparent property of haze is twofold. On the one hand, it increases the difficulty of discriminating hazy pixels from clear-sky pixels, since the remotely measured signal of a hazy pixel is the mixture of the spectral responses from both haze and the land surface [
7]. On the other hand, it leaves an opportunity for restoring true image information underneath hazy areas [
8]. Except for desert haze, most haze types have much smaller impacts to near infrared (NIR) and shortwave infrared (SWIR) bands than to visible bands. For this reason, the emphasis of this study is on detecting and removing haze from visible bands. For high-altitude thin cirrus clouds, since they are very hard to detect with visible bands, a specific channel (e.g., the band around 1.38 μm implemented on MODIS, Landsat-8 and Sentinel-2) and method are needed [
7,
9,
10]. An effective haze removal algorithm can be beneficial for many remote sensing applications, because more real surface reflectance can be exposed. This is particularly true when the satellite images to be used cannot be collected frequently (e.g., the revisit time of Landsat series satellites is 16 days). For large area or temporal applications demanding massive optical images, a fully automated haze removal method is highly desired [
11].
A haze removal procedure generally consists of two consecutive stages: haze detection and haze correction. Haze detection is the process of obtaining a spatially detailed haze intensity map for an image, while haze correction is the algorithm for removing haze effects from an image based on the haze intensity map. It has been commonly recognized that the performance of a haze removal method is largely dependent on the accuracy of haze detection [
6,
8,
12,
13]. Since the distributions of atmospheric haze vary dramatically in both spatial and temporal dimensions, it is extremely difficult in practical applications to collect spatially detailed in-situ measurements of atmospheric haze conditions during the time of an image acquisition [
14]. As such, a common practice to obtain a haze intensity map is estimation based on the contaminated image itself. Over the past decades, a large number of scene-based haze removal approaches have been proposed in the literature [
6,
8,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]. These existing methods fall into three general categories: dark object subtraction (DOS) [
8,
12,
13,
15,
16,
17], frequency filtering [
18,
19] and transformation based-approaches [
6,
14,
20,
21,
22,
23].
DOS-based methods were developed according to the physical principle of atmospheric effects on the image signals of dark targets. The radiative effects of atmospheric haze include scattering and absorption of sunlight in the sun–surface–sensor path. For dark surfaces, scattering effects (often known as path radiance) is a dominant and mainly additive component upon the total radiance measured by an optical sensor [
12,
15]. This indicates that it is appropriate to employ dark pixels in a scene to estimate path radiance, which is proportional to the haze optical thickness. Basically, the path radiance of a dark pixel can be estimated by subtracting a small predicted radiance from its measured at-sensor radiance. DOS-based methods have a long history and have evolved from the stage of only being suitable for homogeneous haze conditions [
13] to the stage of being able to compensate spatially varying haze contaminations [
8,
12,
15,
16]. To make use of more dark objects present in a scene, Kaufman et al. [
15] proposed a dense dark vegetation (DDV) technique, which is based on the empirical correlation between the reflectance of visible bands (usually blue and/or red bands) and that of a haze-transparent band (e.g., band 7 in the case of Landsat data) for DDV pixels. A DDV-based method does not work well if a scene does not include sufficient and evenly distributed vegetated pixels (e.g., the scenes acquired over desert areas or in the leaf-off season), or the reflectance correlations of the DDV pixels in a scene are significantly different from the standard empirical formulas [
16,
21]. Attempting to apply DDV-based method to remote sensing data without any SWIR bands, Richter et al. [
17] proposed an algorithm by introducing another empirical reflectance correlation between red and NIR bands. To utilize various land-cover types, instead of just dark and DDV pixels, in the process of characterizing the haze effects in Landsat imagery, Liang et al. [
16] presented a cluster-matching technique based on the following two assumptions: (1) the spectral responses of the same land cover type in hazy and clear-sky image areas should be statistically similar; and (2) image clusters in the visible spectrum can be derived through a clustering process with only haze-transparent bands. Recently, Makarau et al. [
8] reported a haze removal algorithm via searching for local dark targets (shaded targets or vegetated surfaces) within a scene, instead of just a few global dark objects over an entire scene. This method is feasible for the images with high spatial resolutions, because it requires more relatively pure dark pixels without mixing with bright targets. However, this method cannot be applied for scenes containing large areas of relatively bright surfaces.
As indicated by name, frequency filtering-based haze removals operate in the spatial frequency domain, rather than in spatial domain. The methods in this category assume that haze contamination is in relatively low-frequency compared to the ground reflectance pattern, and therefore can be removed by applying a filtering process [
18,
19]. Wavelet decomposition [
18] and homomorphic filter [
19] are two representative approaches in this category. The major obstacle in applying frequency filtering-based methods is to determine a cut-off frequency or choice wavelet basis. Du et al. [
18] used a haze-free reference image acquired over the same site of a hazy scene to separate the frequency components of haze from those of ground surfaces. Obviously, the prerequisite of haze-free reference images largely limits the application of the wavelet-based haze removal. Shen et al. [
19] suggested using the clear-sky areas in an image to determine the cut-off frequency. Neither of these two strategies for determining a cut-off frequency can properly address the issue of the confusion between the spatial frequencies of haze and some low-frequency land surfaces, such as desert, water bodies, homogeneous forestry and farming regions.
Transformation-based haze removals were initially developed based on the tasseled cap transformation (TCT) [
24], since it was noted that haze seems to be the major contributor to the fourth TCT component [
6]. Richter [
20] developed a haze detection methodology based on a two-band version (blue and red bands) of TCT. To avoid the complexity of Richter’s transformation, Zhang et al. [
6] proposed an improved version of the two-band transformation and named it the haze optimized transformation (HOT). Compared to other haze removal approaches, the HOT-based method has two notable advantages: (1) it is a single scene-based method, so no haze-free reference image is required; and (2) the algorithm relies on only two visible bands, meaning that no haze-transparent band is needed, and therefore can be applied to a broad range of remote sensing images, e.g., Landsat, MODIS, Sentinel-2, QuikBird and IKONOS. HOT-based haze removal has gained a wide attention thanks to its simplicity and is considered to be an operational tool [
6,
7,
8,
9,
10,
11,
14,
21,
25]. Nevertheless, there are three major issues associated with the conventional HOT-based method (hereinafter denoted as Manual HOT) and thus limit its extensive application. First, HOT-based haze removal is only applicable to the visible bands [
6,
22]. Second, some surface types, such as bare rock/soil, snow/ice, water bodies and bright man-made targets, could cause spurious HOT responses [
6]. Third, a manual operation is needed to identify a set of representative clear-sky pixels in a scene to define a clear line. Even though there is so far no direct solution to the first limitation, the haze correction algorithm proposed in [
8] has the potential to be extended for handling the problem. Recently, some efforts have been made to address the second issues [
14,
21,
22,
23]. To reduce the impact of spurious HOT responses on haze removal, Moro and Halounova [
14] proposed a process that excludes water bodies and urban features from HOT and then estimates HOT values for the excluded pixels through spatial interpolation. Another suggested strategy for addressing this issue is to fill the sinks and flatten the peaks in a HOT image [
21,
22]. Jiang et al. [
23] reported a semi-automatic HOT process through searching for the clearest image windows that simultaneously meet two conditions: (1) lower radiances in visible bands; and (2) high correlation between blue and red bands. Obviously, this method could fail to detect the clear-sky pixels with relative higher visible radiances. To our knowledge, there has been no reported research dedicatedly focused on fully automating HOT, which is valuable for maximizing the utility of the method, particularly for the projects requiring haze compensations for a large volume of optical satellite images.
In this study, a methodology named AutoHOT was developed to fully automate HOT and improve the accuracy of HOT-based haze removal. The remainder of this paper is structured as follows.
Section 2 provides some information related to the Landsat scenes to be used in experiments. In
Section 3, the new method is described in detail after a brief review and analysis of the key concepts and issues of HOT. The evaluations and analysis to the HOT images and dehazed results created with AutoHOT are provided in
Section 4.
Section 5 presents the conclusions drawn from the study.
3. Methods
AutoHOT is composed of three consecutive steps. The first step is for fully automating HOT process; the last two steps, HOT image post-processing and class-based HOT radiometric adjustment (HRA), are included for reducing the influences of spurious HOT responses to haze removal. The algorithms used in the steps are newly developed in this study. To facilitate the description of the procedures of AuotHOT, this section starts with
Section 3.1 to provide a brief review and analysis of some key concepts and issues in Manual HOT. The three steps of AutoHOT are described individually in
Section 3.2,
Section 3.3 and
Section 3.4.
3.1. Key Concepts and Issues in HOT-Based Haze Removal
3.1.1. HOT Space and Clear Line
HOT is applied within a two-dimensional spectral space (often referred to as HOT space) typically defined using blue and red bands. The transformation was developed based on the assumption that the spectral responses of most land surfaces in blue and red bands are highly correlated under clear-sky conditions. One of the key components in HOT is a clear line (CL), which traditionally must be defined with a number of manually identified clear-sky pixels exhibit in an image. For a scene containing some clear-sky image regions, a large number of clear-sky pixel subsets theoretically can be created, and any of these subsets can be used to define a CL. This raises a question as to which clear-sky pixel subset is best for defining a CL that can accurately identify and characterize the hazy pixels in an image. From an optimization point of view, this is an NP-complete problem, because it cannot be solved in polynomial time [
28]. In practical applications, a maximum set of the clear-sky pixels in a scene should be employed to define an optimized CL. In the case of manual identification of clear-sky pixels, this could be time consuming and difficult because of the complexity of the spatial distributions of haze and clouds, as well as the ambiguous transition zones between hazy and haze-free regions. For efficiency, users in most cases just manually select a small number, instead of a maximum number, of representative clear-sky pixels from an image. Obviously, this method of identifying clear-sky pixels is a subjective process.
3.1.2. Migrations of Hazy Pixels in HOT Space
The pixels contaminated by haze scattering migrate away from a CL in HOT space. The migrations take place toward only one side of a CL, rather than both sides. The direction of the migrations depends on the axes configuration of a HOT space. The HOT space used in this study is always defined with blue and red bands as vertical and horizontal axes, which is different from that used by Zhang et al. [
6]. As a result, hazy pixels by default migrate toward the upper side of a CL. Such a migration is because atmospheric haze contributes stronger scattering effects to blue band than to red band [
5,
6].
3.1.3. HOT Value and HOT Image
A CL divides a HOT space into two subspaces. With the axes definition used in this study, the pixels above and below a CL can be treated as hazy and haze-free pixels, respectively. In HOT, the perpendicular distance between a hazy pixel and a CL is referred to as HOT value. It has been noted that the HOT values of hazy pixels are approximately proportional to the increase of haze intensities [
6]. For this reason, HOT values have been adopted in HOT for quantifying the haze intensities of hazy pixels. For describing the spatial distributions of the haze intensities, the HOT values of all the pixels in a scene are usually recorded in a so-called HOT image, which has identical spatial dimensions as the original image. To discriminate the clear-sky pixels from the hazy pixels in a HOT image, the HOT values corresponding to the clear-sky pixels are always set to zero in this study, no matter how far the pixels are below a CL. The HOT image is equivalent to the haze intensity/thickness map used in other haze removal methods and is the basis of successfully removing haze effects from a visible band image. An optimized clear-sky pixel subset can be used to derive an optimized CL and then produce an optimized HOT image, so these three terms are considered to be equivalent.
3.1.4. Spurious HOT Responses
Spurious HOT responses can be caused by the following two reasons: (1) blue and red bands are not always highly correlated under clear-sky conditions [
22]; and (2) the slopes of the haze effected trajectories monotonically increase for surface classes of increasing absolute reflectance in the visible bands [
6] (in the HOT space used in this paper). For satellite images with dominantly vegetated surfaces, spurious HOT responses normally are triggered by some land-cover types, such as bare rock/soil, water bodies, snow/ice and bright man-made targets [
6]. By investigating the HOT images created from a variety of Landsat scenes, spurious HOT responses can be generally classified into four categories: clear-high-HOT (clear-sky pixels have positive HOT values), haze-high-HOT (hazy pixels have positive HOT values bigger than should be), haze-low-HOT (hazy pixels have positive HOT values smaller than should be) and haze-zero-HOT (hazy pixels have zero HOT values). The purpose of categorizing spurious HOT responses is to develop different strategies for addressing the issue.
3.1.5. HOT Radiometric Adjustment
In addition to proposing HOT for identifying and characterizing hazy pixels, Zhang et al. [
6] also provided a technique called HOT radiometric adjustment for compensating the haze effects based on a HOT image. The general idea of HRA is to apply the DOS method for each distinct HOT level. In HRA, the radiometric adjustment applicable to a subset of hazy pixels is estimated using the difference between the mean values of the darkest pixels (histogram lower bounds) in the hazy pixel subset and the set of the clear-sky pixels in a scene. HRA method was developed based on two assumptions: (1) HOT is insensitive to surface reflectance; and (2) similar dark targets are present under all haze conditions. Owing to the existence of spurious HOT responses, the first assumption obviously is invalid. The second assumption also does not hold in some situations. For example, if the histogram lower bound of the haze-free areas of an image is dominated by cloud shadow pixels (shadow pixels are darker than most land surfaces in visible bands), then the radiometric adjustment for a HOT level will be estimated with the difference between the mean values of the shadow pixels and the darkest hazy pixels (may not be shadow pixels) in the HOT level. Consequently, haze overcompensation could occur since a radiometric adjustment has been overestimated.
3.2. Fully Automated HOT
Knowing that there is normally no clear-cut boundary between hazy and haze-free zones in a scene, the goal of automating HOT is to automatically define an optimized CL that minimizes both omission and commission errors in terms of haze detection. The development of AutoHOT was started with analyzing the relation of a CL with the regression line of an entire scene.
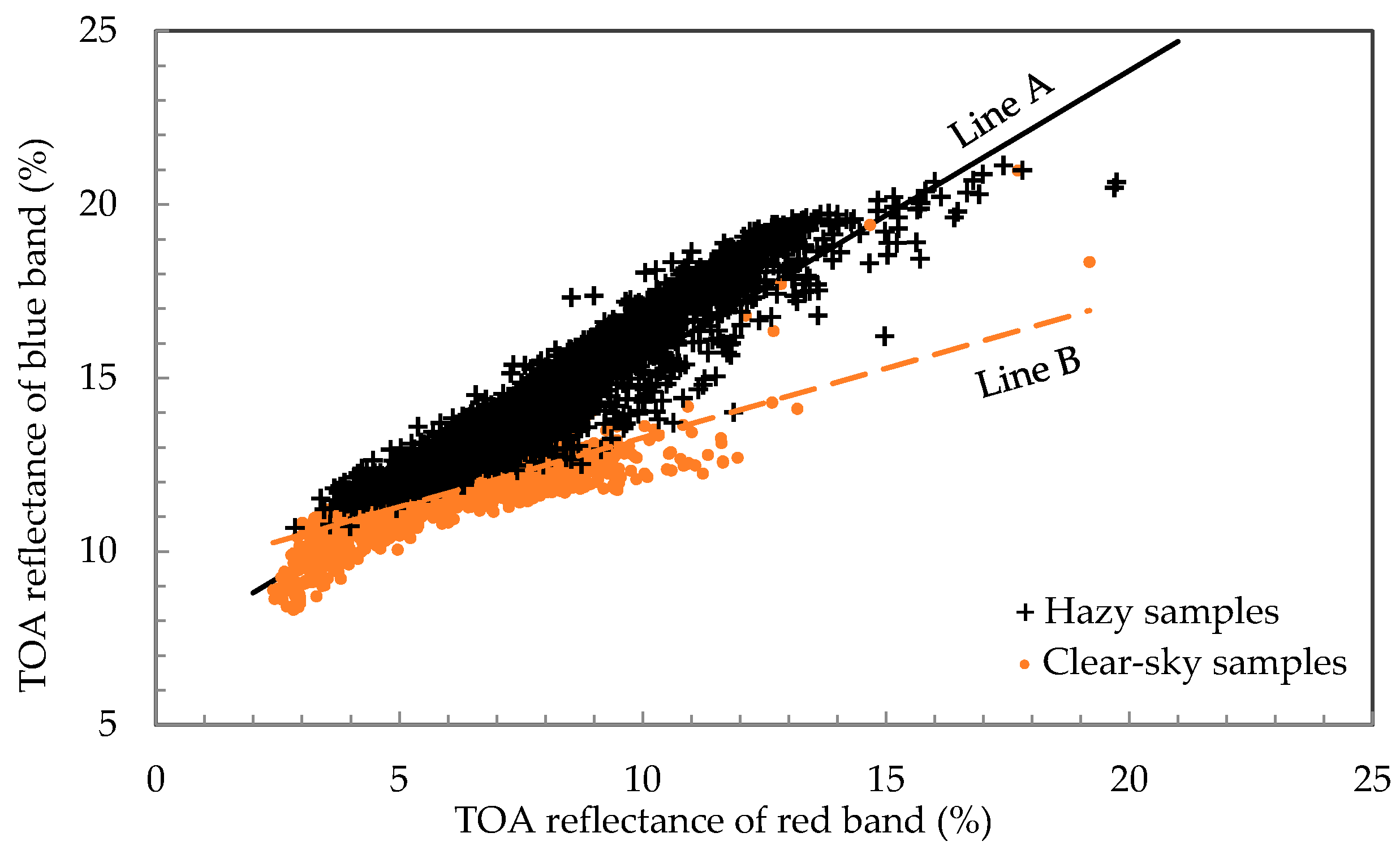
Figure 1 shows a HOT space and two scatter plots composed by samples taken separately from the hazy and haze-free regions in a Landsat-8 OLI image (Path 52/Row 16) acquired on 17 August 2014. Overall, the hazy samples are located above the clear-sky samples. The straight lines A and B in
Figure 1 are the trend lines regressed from all the samples (including both hazy and haze-free samples) and the clear-sky samples only, respectively. Because of the existence of the hazy samples, the line A has been dragged away from the line B (a CL) upward at the brighter end. The line A can easily be obtained from a given scene, while the line B cannot be defined without having a number of pre-selected representative clear-sky pixels.
In
Figure 1, it can be conceived that, if another linear regression is conducted over the remaining samples after eliminating the samples above the line A and with perpendicular distances bigger than a specified distance threshold (hereinafter the specified distance threshold is referred to as trimming distance and denoted by TD), then the new trend line will be closer to the line B, compared to the relation of the line A to the line B. Based on this idea, an iterative upper trimming linear regression (IUTLR) process was developed. For a given TD, an IUTLR process starts with a linear regression over all the pixels of a scene. During the next iteration, a pixel subset is first produced by excluding the pixels above the regression line obtained from the preceding iteration and with perpendicular distances bigger than the TD. Subsequently, a new linear regression is performed over the remaining pixels in the subset. This iterative process is repeated until no significant changes were observed with respect to the coefficients (slopes and intercepts) of the regression lines from two consecutive iterations. Our experiments indicated that a small number of iterations (rarely exceeding 50) usually were sufficient for an IUTLR process to converge to a steady state. In this paper, the pixel subset and its corresponding regression line created by the last iteration of a converged IUTLR process are named IUTLR pixel subset and IUTLR line, respectively.
To figure out the relationship between TD changes and their resulting IUTLR pixel subsets, IUTLR processes associated with different TDs have been applying to a number of Landsat images. Generally, the sizes of the IUTLR pixel subsets of an image are proportional to the values of the specified TDs. A close inspection to the variations of the IUTLR pixel subsets of a scene reveals that, with the increasing of the TD values, the pixel subsets normally undergo a growing process from initially including dark clear-sky pixels to the status containing most clear-sky pixels, and then incorporating some thin hazy pixels besides the clear-sky pixels. From these observations, it can be inferred that with an appropriate TD specified, it is possible to obtain an optimized IUTLR pixel subset containing a maximum number of clear-sky pixels and a minimum number of hazy pixels in a scene. Obviously, if IUTLR processes are involved in the automation of HOT, then the core of the algorithm is how to determine such an optimized TD. With an optimized IUTLR pixel subset available, an optimized CL and an optimized HOT image can be derived.
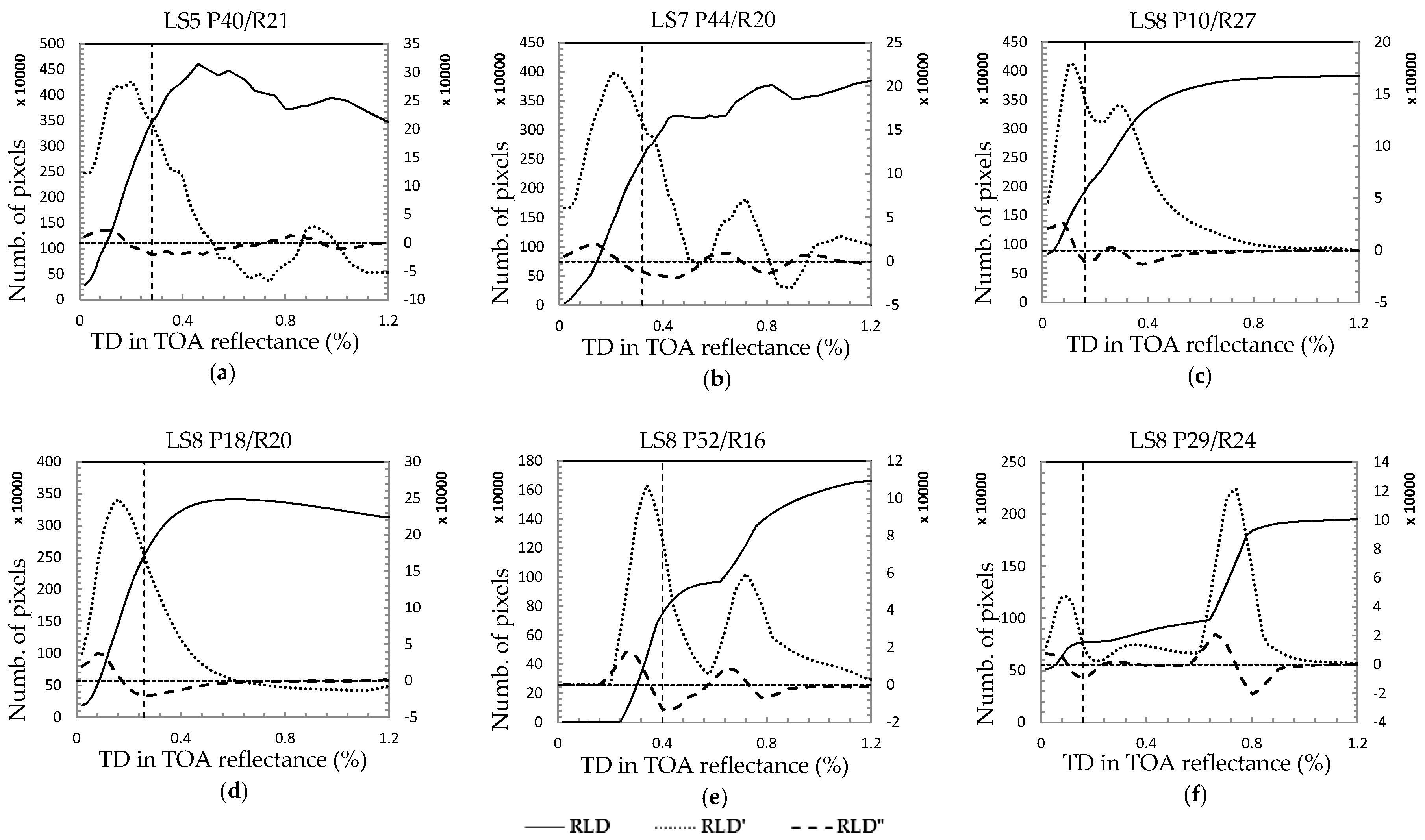
To search for an optimized TD for a scene, a double-loop scheme was introduced by nesting an IUTLR process inside the body of a loop controlled by N evenly increased TDs (the step size of the TD increment used in this study was 0.02 in the case of TOA reflectance). With this double-loop mechanism, N IUTLR lines along with N IUTLR pixel subsets can be derived for an image scene. Our strategy was to identify an optimal TD through evaluating the N IUTLR lines or N IUTLR pixel subsets. Either way, a statistical metric is needed for the evaluations. If the scatter plots of hazy and haze-free pixels in a HOT space are regarded as two classes, then the evaluations can be accomplished by measuring the separabilities of the two pixel groups separated by an IUTLR line. Unfortunately, our experiments indicated that some commonly used separability metrics, such as Jeffries–Matusita distance, Bhattacharyya distance and the transformed divergence, did not work well in this circumstance. This forced us to look for an alternative evaluation metric. According to the principle of HOT, we know that in the scatter plot of an image in HOT space, there must be a dense area composed by highly correlated clear-sky pixels. The IUTLR lines that pass through the dense scatter area should be the candidates of an optimal IUTLR line. From this analysis, regression line density (RLD) was adopted as the statistical metric for evaluating the N IUTLR lines of an image. The RLD value of an IUTLR line can be obtained by counting the number of pixels confined within a thin HOT space stripe area centered by the IUTLR line. Note that the widths of the stripe areas defined for all the IUTLR lines of a scene must be a constant small value (e.g., 0.2 in the case of TOA reflectance). By plotting the RLD values of N IUTLR lines as a function of N evenly increasing TDs, a RLD curve can be constructed for a scene. The six RLD curves (the solid curves) displayed in
Figure 2 (the descriptions about the six Landsat scenes are provided in
Section 2.1) are considered representative according to the smoothness of the curves and the number of local maximums.
The original purpose of creating a RLD curve for a scene was to expect there is a local maximum on the curve that corresponds to an optimized TD. This expectation apparently was found to be invalid from the inspection of
Figure 2, as not every RLD curve had a local maximum (e.g.,
Figure 2c,e,f). Our experiments further revealed that even if a RLD curve had a maximum point; the point normally was not associated with an optimized TD. To find out a way to determine an optimized TD based on a RLD curve, a three-step experiment was undertaken over a large number of Landsat scenes (none of the scenes was included in the testing data set of this paper). First, an optimal HOT image and N IUTLR pixel subsets corresponding to N evenly increasing TDs were created separately for each of the Landsat scenes. The optimal HOT image of a scene was generated with Manual HOT using the procedure described in
Section 4.1 and served as a reference case against which the N IUTLR pixel subsets were evaluated. Next, the spatial agreements between the N IUTLR pixel subsets and the clear-sky areas in the optimal HOT image of a scene were measured using overall accuracy formula, in which the hazy pixels and clear-sky pixels are treated as two classes. Finally, the IUTLR pixel subset with the best spatial agreement with the optimal HOT image of a scene was identified as an optimized IUTLR pixel subset and its corresponding TD was marked on the RLD curve of the scene. In addition to the RLD curves, the first- (RLD’) and second-order derivatives (RLD”) (e.g., the dotted and dashed curves in
Figure 2, respectively) of the curves were also created and involved in the experimental analysis. Through this experiment, a general trend has been found that the locations of most identified optimized TDs were correlated with the minimum points within the first negative segment of the RLD” curves.
According to the definition of RLD, it can be understood that a peak point of a RLD’ curve must correspond to an IUTLR line in HOT space that passes through (not necessarily the center) a dense scatter plot area. For a given image, there could be one or more dense scatter plot areas in HOT space (e.g., one is formed by clear-sky pixels and another one is constituted by the hazy pixels affected by homogenous haze). According to the optical property of haze scattering (most haze types have greater impacts to blue band than to red band), it can be said that the darkest dense scatter plot area in HOT space must be clear-sky pixel scatter plot (CSPSP). Thus, the first peak point of a RLD’ curve can be used to roughly locate CSPSP. However, we must realize that the IUTLR line associated with the first peak cannot be utilized to separate the clear-sky pixels from the hazy pixels of a scene, as it passes through the CSPSP. Recalling that IURLR pixel subsets undergo an expanding process with the increasing of TD values, it can be imagined that, after the first peak of a RLD’ curve, the expanding process must have a notable slow down when it hits the boundaries between clear and haze zones of an image. Based on derivative analysis, the minimum point of the first negative segment of RLD” curve represents a significant drop on RLD’ curve, therefore can be used to estimate an optimized TD that results in an optimized IUTLR pixel subset. With the understanding and considering some special cases, the following two rules have been developed for automatically determining an optimized TD for a scene: (1) within the first negative segment of a RLD” curve, if the distance between the minimum point and the start point of the segment (equivalent to the first peak of RLD”) is smaller than a threshold (e.g., 0.2), then the TD corresponding to the minimum point can be used as the optimized TD; otherwise, (2) the optimized TD is equal to the TD value associated with the start point plus half of the threshold. The optimized TDs in
Figure 2a,c–f were determined using the first rule, while the optimized TD in
Figure 2b was detected based on the second rule.
3.3. HOT Image Post-Processing
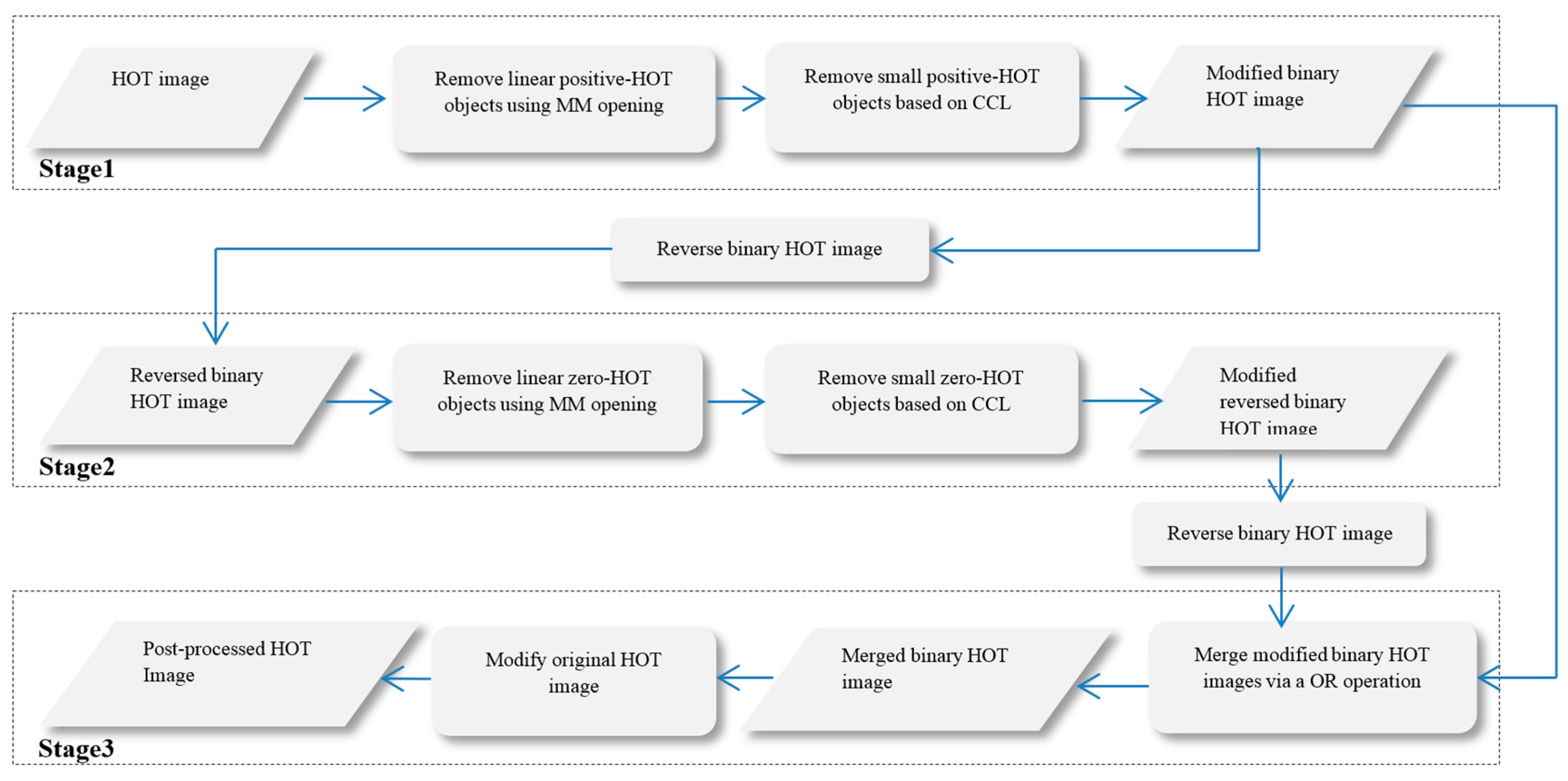
Since the HOT values of the pixels below a CL are set to zero, a HOT image consists of a set of connected positive-HOT and zero-HOT image regions. Due to spurious HOT responses, the HOT values of some pixels do not reflect their haze conditions (e.g., clear-high-HOT and haze-zero-HOT situations). To reduce the influences of spurious HOT responses to haze removal, AutoHOT includes two additional steps, HOT image post-processing and class-based HRA. HOT image post-processing was developed based on an assumption that haze regions normally occur over large spatial scales. Thereby, fine-scale (either with small areas or with thin linear shapes) positive-HOT and zero-HOT objects most likely result from spurious HOT responses and should be removed from a HOT image.
Figure 3 depicts the flowchart of HOT image post-processing. The procedure can be generally divided into three stages. The first two stages are designed to identify fine-scale clear-high-HOT and haze-zero-HOT objects in HOT images, respectively. The algorithms used in these two stages are implemented with the help of the opening operation of mathematical morphology [
29] and connected component labeling [
30]. The results of the first two stages are stored separately in two binary images. In the third stage, the two binary image are first merged via a logical OR operation. In the merged binary image, the pixels with 0 or 1 represent clear-sky or hazy pixels, respectively. The second step of the third stage is to modify the original HOT image according to the following two rules: (1) change a positive HOT value in the HOT image to zero if its corresponding pixel in the merged image is zero; and (2) estimate a HOT value for a zero-value pixel in the HOT image if its corresponding pixel in the merged image is one. The HOT value estimation currently is done using spatial interpolation with inverse distance weighting.
3.4. Class-Based HOT Radiometric Adjustment
HOT image post-processing only reduces the number of two types of spurious HOT responses, clear-high-HOT and haze-zero-HOT. To minimize the haze compensation errors due to haze-high-HOT, haze-low-HOT and inconsistent dark targets are present under different haze conditions (violation of the assumptions of HRA, see
Section 3.1.5), an improved version of HRA was developed for AutoHOT by applying HRA to each classified pixel group (hereinafter the improved HRA is referred to as class-based HRA).
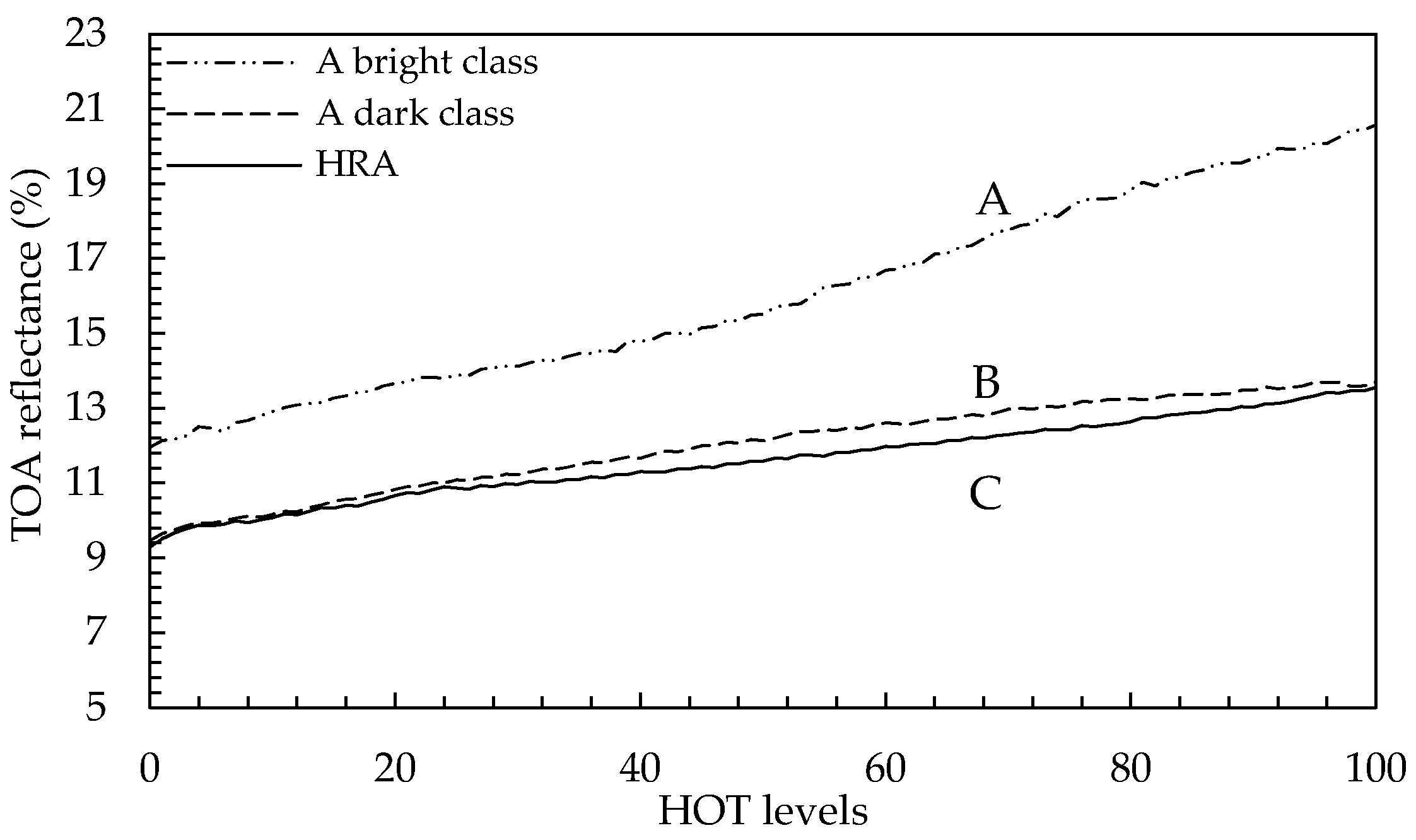
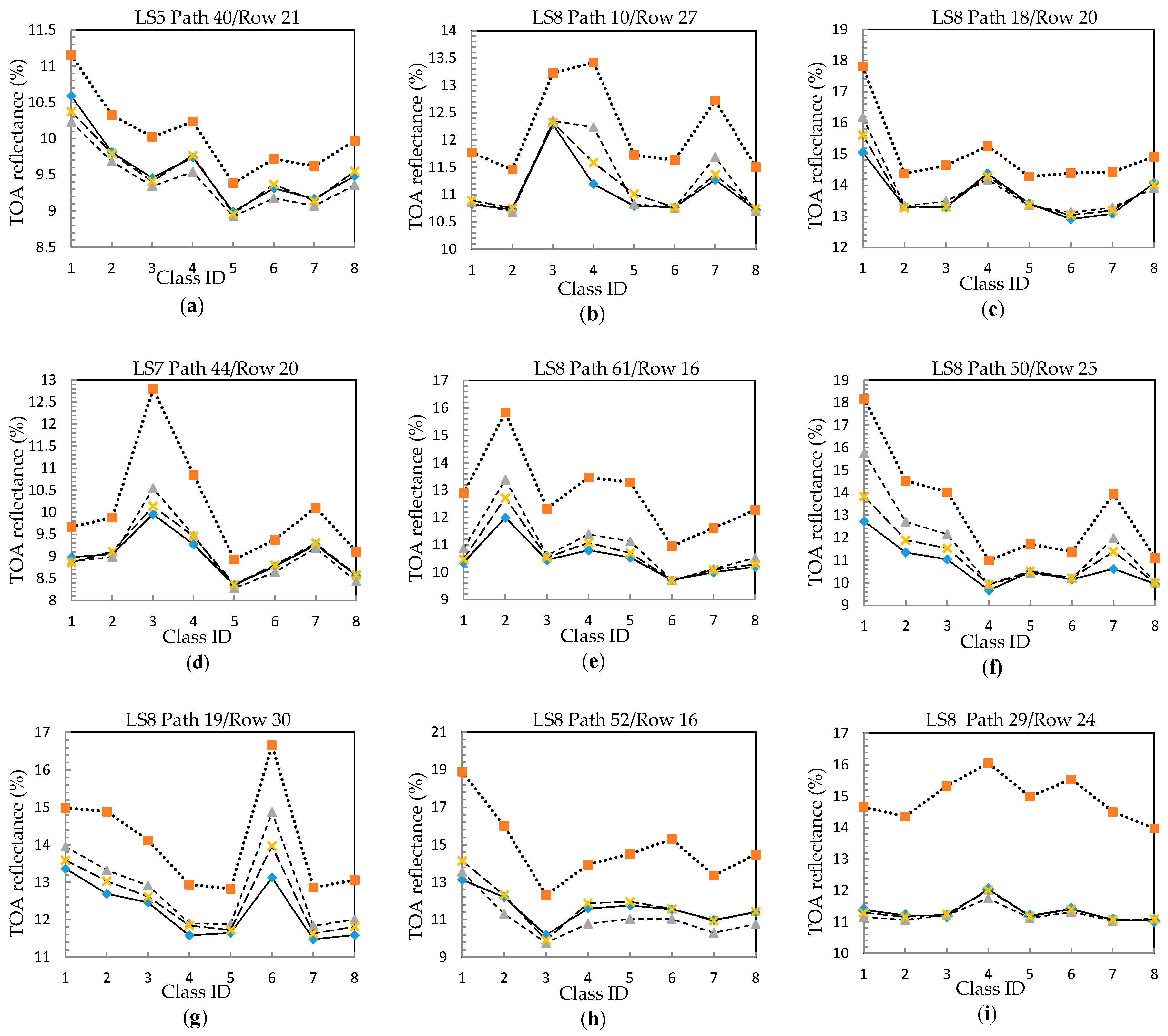
For illustrating the necessity of applying class-based HRA, three dark-bound mean curves of 100 HOT levels (HOT value ranged from 0.0 to 5.0 with a step size equal to 0.05), shown in
Figure 4, were generated using the first (coastal/aerosol) band of a Landsat-8 OLI scene (Path 50/Row 25, mainly water and mountainous areas) acquired on 19 August 2014. Lines A and B in
Figure 4 are generated with dark-bound means of a bright class (mainly deforestation areas) and a dark class (dominated by shadow and shade pixels of mountains), respectively. Line C (in
Figure 4) was created in the same way as in conventional HRA with the dark-bound means of different HOT levels regardless land-cover types. It can be understood that, for the hazy pixels of the dark class, two HOT-based haze removal methods will produce similar results. Because the overall slopes of line B (the base line for correcting the dark class in class-based HRA) and line C (the base line for correcting all hazy pixels in conventional HRA) are very close, conventional HRA will undercompensate the hazy pixels of the bright class, since the slope of line A is much bigger than that of line C. It must be pointed out that the notable slope difference between line A and C is not fortuitous, the difference is consistent with the results obtained from the MODTRAN-based haze effect simulation conducted by Zhang et al. [
6]. This means that class-based HRA conforms more accurately to the outputs of atmospheric radiative transfer model.
In class-based HRA, the class-dependent HOT values are employed in the haze compensation of similar surface type. This ensures that the HOT values involved in the calculation mainly reflect atmospheric haze intensities, rather than the variations of surface reflectance; therefore, the first HRA assumption is automatically satisfied. A requirement of applying class-based HRA is the existence of a set of clear-sky pixels for every class. In this study, the minimum number of clear-sky pixels for each class was set to 1000 for statistical representation. If a class does not have a sufficient number of clear-sky pixels (rarely happen in our study), then some dark clear-sky pixels of a class most similar to the targeted class are employed as supplements. The worst scenario of class-based HRA is that none of the classes has an adequate number of clear-sky pixels. In this case, conventional HRA can be applied. It is worth mentioning that HOT image post-processing is a helpful step for class-based HRA, because it can remove fine-scale clear-high-HOT objects from a HOT image. This could be critical for applying class-based HRA to some land-cover types such as man-made targets and bare rock/soil. Because these surface types might not have a sufficient number of clear-sky pixels without HOT image post-processing. On the other hand, class-based HRA ensures that the darkest pixels used for estimating the radiometric adjustments for different HOT levels of a class more likely belong to the same (or similar) land-cover type, meaning that the second assumption of HRA can be met to some degree as well.
Obviously, a classification map must be available to apply class-based HRA. With the intention of fully automating AutoHOT, we adopted the idea suggested by Liang et al. [
16] for unsupervised classification with haze-transparent bands (bands 4, 5 and 7 in the case of Landsat sensors 5 and 7; bands 5–7 in the case of Landsat 8). To increase the computational efficiency, a K-mean clustering analysis was applied to a number (normally a few hundreds and thousands) of the samplers created by a spectral screening process [
31], rather than to an entire scene. To ensure that the histogram of each land-cover class is formed with large pixel populations, a small number (5 to 10) of classes had been specified in the classification. Note that the number of the classes used for class-based HRA does not necessarily match the actual number of the land-cover classes exhibit in a scene, because the purpose of the classification here is to roughly divide the scene pixels into a few groups, particularly to separate brighter classes from darker classes, rather than the classification in traditional sense.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}