
Decision-Tree-Based Classification of Lifetime Maximum Intensity of Tropical Cyclones in the Tropical Western North Pacific



Abstract
:1. Introduction
2. Data and Methodology
2.1. Data
2.2. Methodology
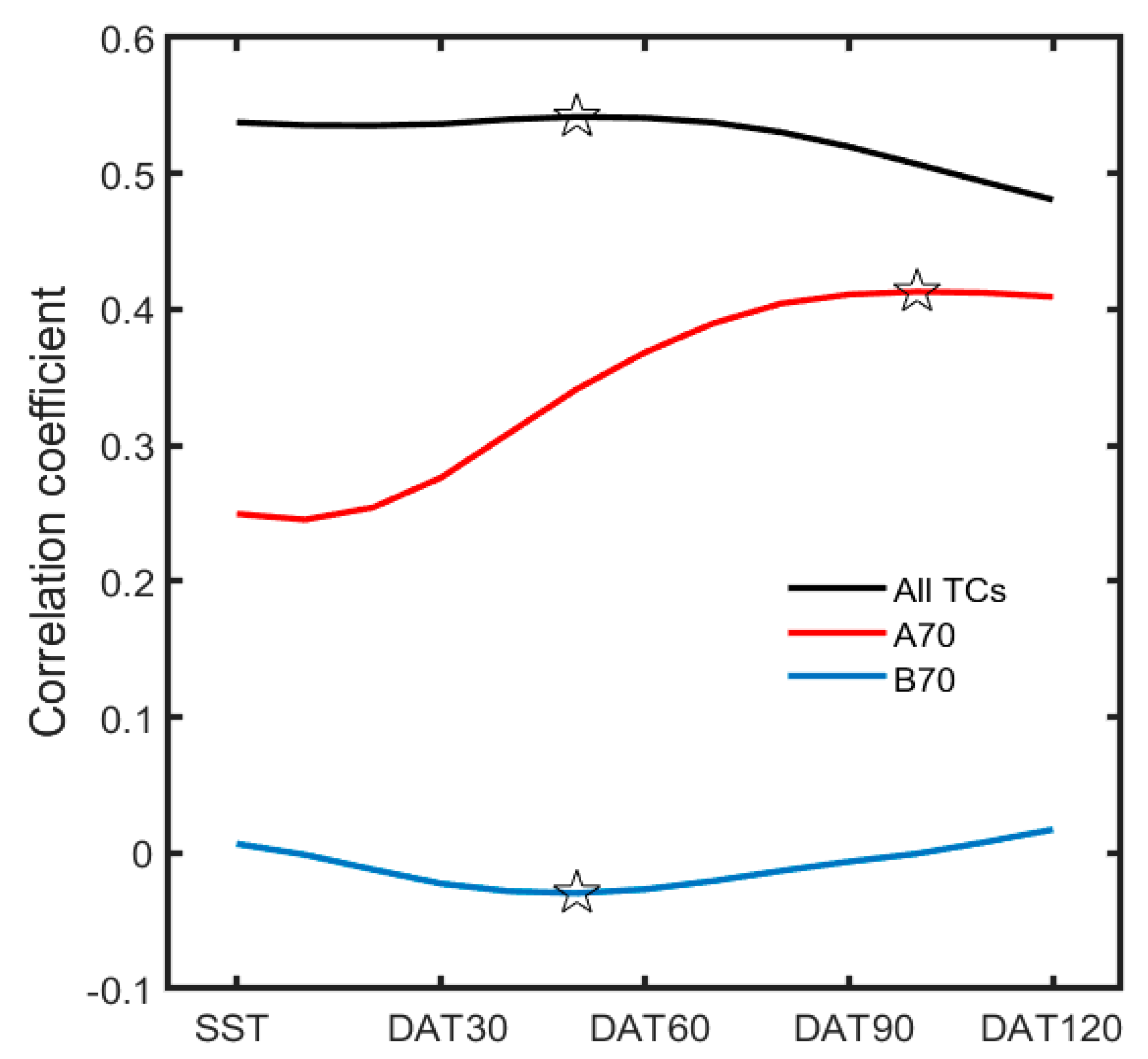
2.2.1. Static and Synoptic Potential Predictors
2.2.2. Classification and Regression Tree
2.2.3. The k-Fold Cross-Validation
2.2.4. Synthetic Minority Oversampling Technique
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeMaria, M.; Sampson, C.R.; Knaff, J.A.; Musgrave, K.D. Is tropical cyclone intensity guidance improving? Bull. Am. Meteorol. Soc. 2014, 95, 387–398. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.-H.; Moon, I.-J.; Chu, P.-S. Statistical-dynamic typhoon intensity predictions in the western North Pacific using Track Pattern Clustering and Ocean Coupling Predictors. Weather Forecast. 2018, 33, 347–365. [Google Scholar] [CrossRef]
- Emanuel, K.A. A statistical analysis of tropical cyclone intensity. Mon. Weather Rev. 2000, 128, 1139–1152. [Google Scholar] [CrossRef]
- Park, D.-S.R.; Ho, C.-H.; Kim, J.-H. Growing threat of intense tropical cyclones to East Asia over the period 1977–2010. Environ. Res. Lett. 2014, 9, 014008. [Google Scholar] [CrossRef] [Green Version]
- Moon, I.-J.; Kim, S.-H.; Klotzbach, P.; Chan, J.C.L. Roles of interbasin frequency changes in the poleward shifts of the maximum intensity location of tropical cyclones. Environ. Res. Lett. 2015, 10, 104004. [Google Scholar] [CrossRef] [Green Version]
- Manganello, J.V.; Hodges, K.I.; Kinter, J.L., III; Cash, B.A.; Marx, L.; Jung, T.; Achuthavarier, D.; Adams, J.D.; Altshuler, E.L.; Huang, B.; et al. Tropical cyclone climatology in a 10-km global atmospheric GCM: Toward weather-resolving climate modeling. J. Clim. 2012, 25, 3867–3893. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Held, I.M.; Lin, S.-J.; Vecchi, G.A. Simulations of global hurricane climatology, interannual variability, and response to global warming using a 50-km resolution GCM. J. Clim. 2009, 22, 6653–6678. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Tippett, M.K.; Sobel, A.H.; Camargo, S.J. Rapid intensification and the bimodal distribution of tropical cyclone intensity. Nat. Commun. 2016, 7, 10625. [Google Scholar] [CrossRef] [PubMed]
- Torn, R.D.; Snyder, C. Uncertainty of tropical cyclone best-track information. Weather Forecast. 2012, 27, 715–729. [Google Scholar] [CrossRef]
- Soloviev, A.V.; Lukas, R.; Donelan, M.A.; Haus, B.K.; Ginis, I. The air-sea interface and surface stress under tropical cyclones. Sci. Rep. 2014, 4, 5306. [Google Scholar] [CrossRef]
- Bengtsson, L.; Botzet, M.; Esch, M. Will greenhouse-induced warming over the next 50 years lead to higher frequency and greater intensity of hurricanes? Tellus 1996, 48A, 57–73. [Google Scholar] [CrossRef] [Green Version]
- Emanuel, K.A. Increasing destructiveness of tropical cyclones over the past 30 years. Nature 2005, 436, 686–688. [Google Scholar] [CrossRef] [PubMed]
- Webster, P.J.; Holland, G.; Curry, J.A.; Chang, H.-R. Changes in tropical cyclone number, duration, and intensity in a warming environment. Science 2005, 309, 1844–1846. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, W.; Gao, S.; Chen, B.; Cao, K. The application of decision tree to intensity change classification of tropical cyclones in western North Pacific. Geophys. Res. Lett. 2013, 40, 1883–1887. [Google Scholar] [CrossRef]
- Kim, H.-S.; Kim, H.S. Development of scheme for tropical cyclone genesis using machine learning. In Proceedings of the Autumn Meeting, Busan, Korea, 31 October–2 November 2016; KMS: Seoul, Korea, 2016; pp. 847–848. [Google Scholar]
- Quinlan, J. C4.5: Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993; 302p. [Google Scholar]
- Li, W.; Yang, C.; Sun, D. Mining geophysical parameters through decision-tree analysis to determine correlation with tropical cy-clone development. Comput. Geosci. 2009, 35, 309–316. [Google Scholar] [CrossRef]
- Zhang, W.; Fu, B.; Peng, M.S.; Li, T. Discriminating developing versus non-developing tropical disturbances in the western North Pacific through decision tree analysis. Weather Forecast. 2015, 30, 446–454. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, W.; Liu, J.; Lin, I.-I.; Chiu, L.S.; Cao, K. Improvements in typhoon intensity change classification by incorporating an ocean coupling potential intensity index into decision trees. Weather Forecast. 2016, 31, 95–106. [Google Scholar] [CrossRef]
- Park, M.S.; Kim, M.; Lee, M.I.; Im, J.; Park, S. Detection of tropical cyclone genesis via quantitative satellite ocean surface wind pattern and intensity analyses using decision trees. Remote Sens. Environ. 2016, 183, 205–214. [Google Scholar] [CrossRef]
- Lee, H.-M.; Won, S.-H.; Cha, E.-J.; Jung, J.-U. Development of technique for tropical cyclone formation using machine learning. In Proceedings of the Autumn Meeting, Gyeongju, Korea, 30 October–1 November 2019; KMS: Seoul, Korea, 2019; pp. 544–545. [Google Scholar]
- Kim, M.; Park, M.-S.; Im, J.; Park, S.; Lee, M.-I. Machine learning approaches for detecting tropical cyclone formation using satellite data. Remote Sens. 2019, 11, 1195. [Google Scholar] [CrossRef] [Green Version]
- Nam, C.C.; Park, D.-S.R.; Ho, C.-H.; Chen, D. Dependency of tropical cyclone risk on track in South Korea. Nat. Hazards Earth Syst. Sci. 2018, 18, 3225–3234. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Tang, J.; Kafatos, M. Improved associated conditions in rapid intensifications of tropical cyclones. Geophys. Res. Lett. 2007, 34, L20807. [Google Scholar] [CrossRef] [Green Version]
- Yang, R. A Systematic Classification Investigation of Rapid Intensification of Atlantic Tropical Cyclones with the SHIPS Database. Weather Forecast. 2016, 31, 495–513. [Google Scholar] [CrossRef]
- Su, H.; Wu, L.; Jiang, J.H.; Pai, R.; Liu, A.; Zhai, A.J.; Tavallali, P.; DeMaria, M. Applying satellite observations of tropical cyclone internal structures to rapid intensification forecast with machine learning. Geophys. Res. Lett. 2020, 47, e2020GL089102. [Google Scholar] [CrossRef]
- Wei, Y.; Yang, R. An Advanced Artificial Intelligence System for Investigating Tropical Cyclone Rapid Intensification with the SHIPS Database. Atmosphere 2021, 12, 484. [Google Scholar] [CrossRef]
- Kaplan, J.; De Maria, M. Large-Scale Characteristics of Rapidly Intensifying Tropical Cyclones in the North Atlantic Basin. Weather Forecast. 2003, 18, 1093–1108. [Google Scholar] [CrossRef] [Green Version]
- Price, J.F. Metrics of hurricane-ocean interaction: Vertically-integrated or vertically-averaged ocean temperature? Ocean Sci. 2009, 5, 351–368. [Google Scholar] [CrossRef] [Green Version]
- Park, J.H.; Yae, D.E.; Lee, K.J.; Lee, H.J.; Lee, S.W.; Noh, S.; Kim, S.J.; Shin, J.Y.; Nam, S.H. Rapid decay of slowly moving typhoon Soulik (2018) due to interactions with the strongly stratified Northern East China Sea. Geophys. Res. Lett. 2019, 46, 14595–14603. [Google Scholar] [CrossRef] [Green Version]
- Lin, I.-I.; Black, P.; Price, J.F.; Yang, C.Y.; Chen, S.S.; Lien, C.C.; Harr, P.; Chi, N.H.; Wu, C.C.; D’Asaro, E.A. An ocean coupling potential intensity index for tropical cyclones. Geophys. Res. Lett. 2013, 40, 1878–1882. [Google Scholar] [CrossRef]
- Balaguru, K.; Foltz, G.R.; Leung, L.R.; D’Asaro, E.; Emanuel, K.A.; Liu, H.; Zedler, S.E. Dynamic Potential Intensity: An improved representation of the ocean’s impact on tropical cyclones. Geophys. Res. Lett. 2015, 42, 6739–6746. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.; Kim, S.H.; Chu, P.S.; Moon, I.J.; Soloviev, A.V. An index to better estimate tropical cyclone intensity change in the western North Pacific. Geophys. Res. Lett. 2019, 46, 8960–8968. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks/Cole Advanced Books & Software: Monterey, CA, USA, 1984; ISBN 978-0-412-04841-8. [Google Scholar]
- McLachlan, G.J.; Do, K.-A.; Ambroise, C. Analyzing Microarray Gene Expression Data; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Chawla, N.V. C4.5 and imbalanced data sets: Investigating the effect of sampling method, probabilistic estimate, and decision tree structure. In Proceedings of the International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; International Machine Learning Society: Princeton, NJ, USA, 2003; Volume 3, pp. 66–73. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and f-measure to roc, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Knaff, J.A.; Sampson, C.R.; DeMaria, M. An operational Statistical Typhoon Intensity Prediction Scheme for the western North Pacific. Weather Forecast. 2005, 20, 688–699. [Google Scholar] [CrossRef] [Green Version]
- Kaplan, J.; DeMaria, M.; Knaff, J.A. A revised tropical cyclone rapid intensification index for the Atlantic and eastern North Pacific basins. Weather Forecast. 2010, 25, 220–241. [Google Scholar] [CrossRef]
- Gao, S.; Chiu, L.S. Development of statistical typhoon intensity prediction: Application to satellite observed surface evaporation and rain rate (STIPER). Weather Forecast. 2012, 27, 240–250. [Google Scholar] [CrossRef]
- Kaplan, J.; Rozoff, C.M.; DeMaria, M.; Sampson, C.R.; Kossin, J.P.; Velden, C.S.; Cione, J.J.; Dunion, J.P.; Knaff, J.A.; Zhang, J.A.; et al. Evaluating environmental impacts on tropical cyclone rapid intensification predictability utilizing statistical models. Weather Forecast. 2015, 30, 1374–1396. [Google Scholar] [CrossRef]
- Knaff, J.A.; Sampson, C.R.; Musgrave, K.D. An Operational Rapid Intensification Prediction Aid for the Western North Pacific. Weather Forecast. 2018, 33, 799–811. [Google Scholar] [CrossRef]
- Wada, A. Reexamination of tropical cyclone heat potential in the western north pacific. J. Geophys. Res. Atmos. 2016, 121, 6723–6744. [Google Scholar] [CrossRef] [Green Version]
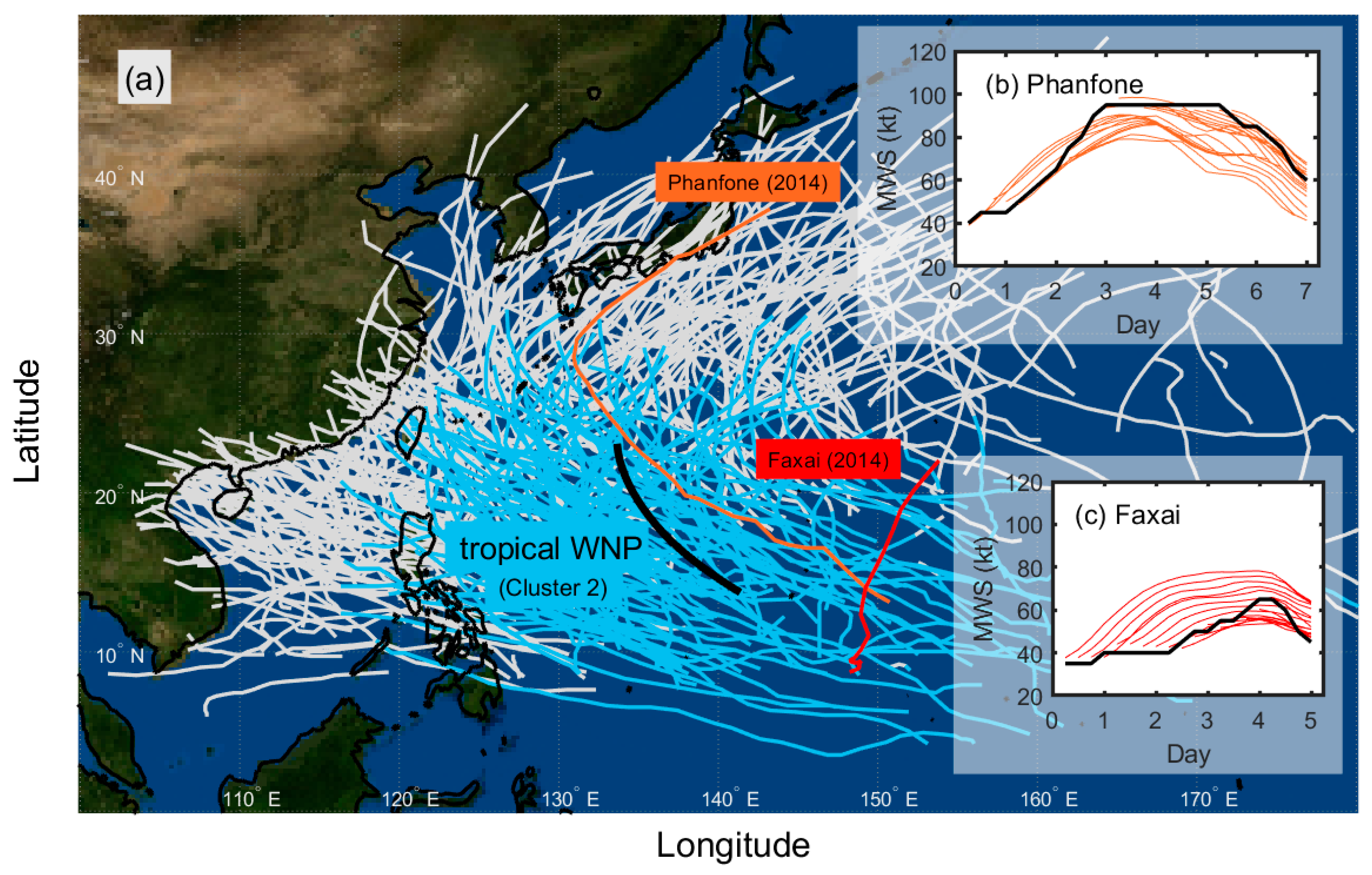

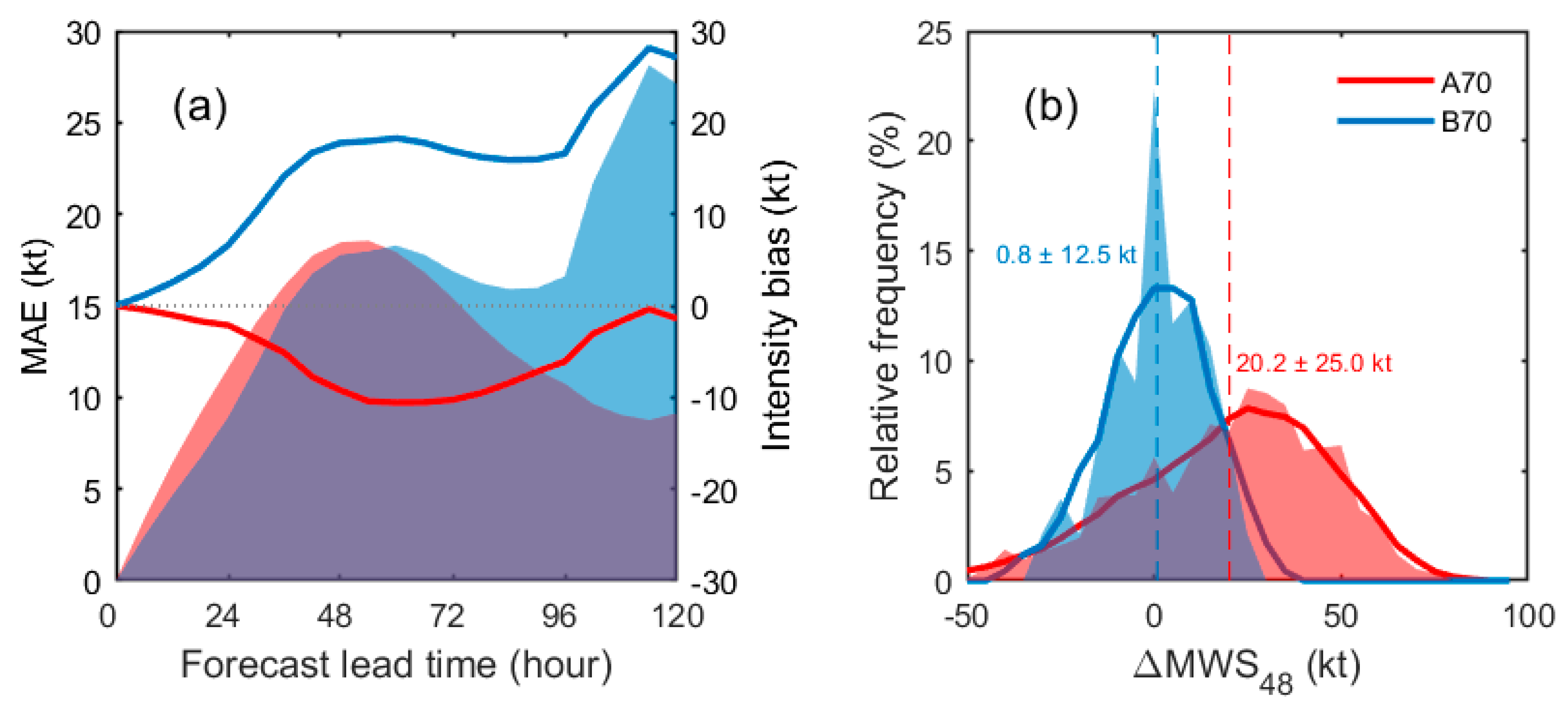
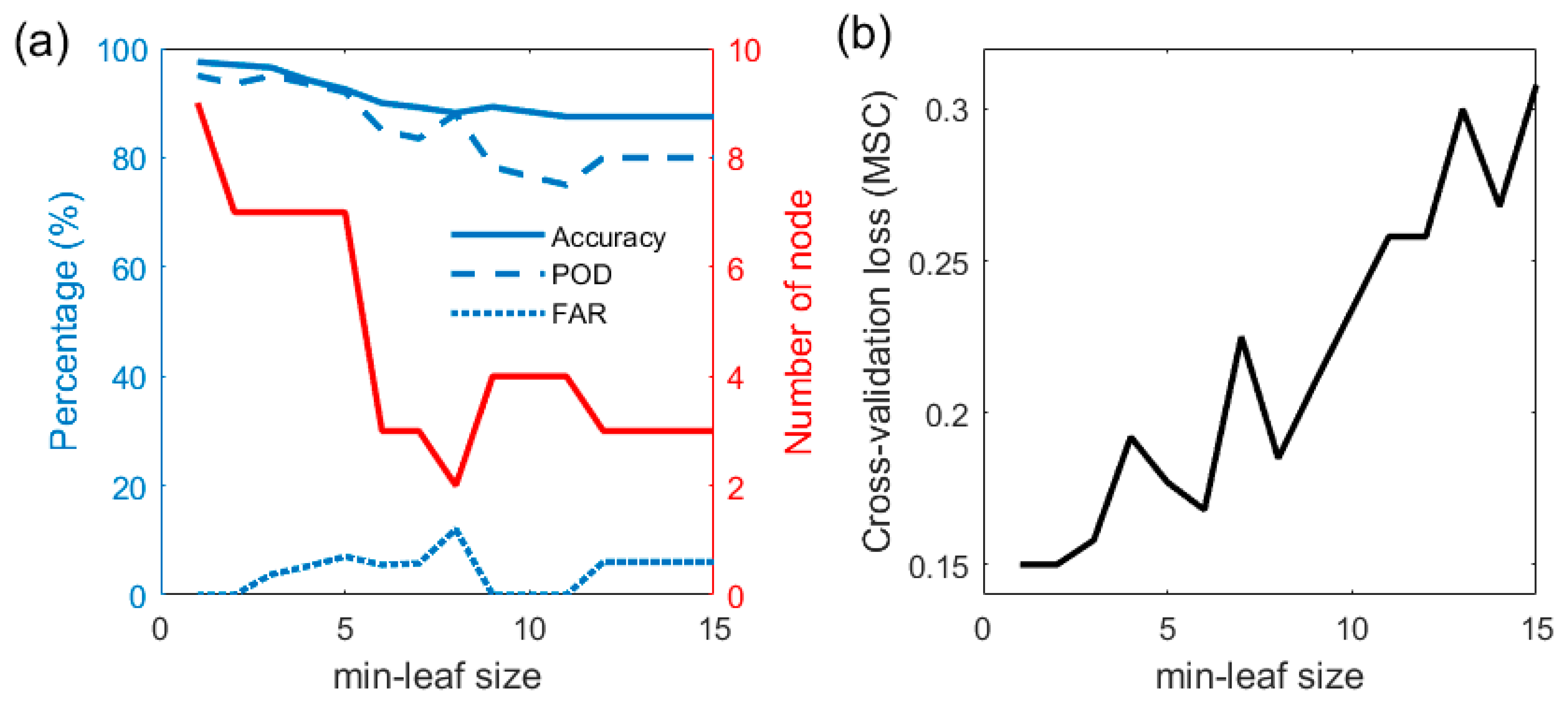
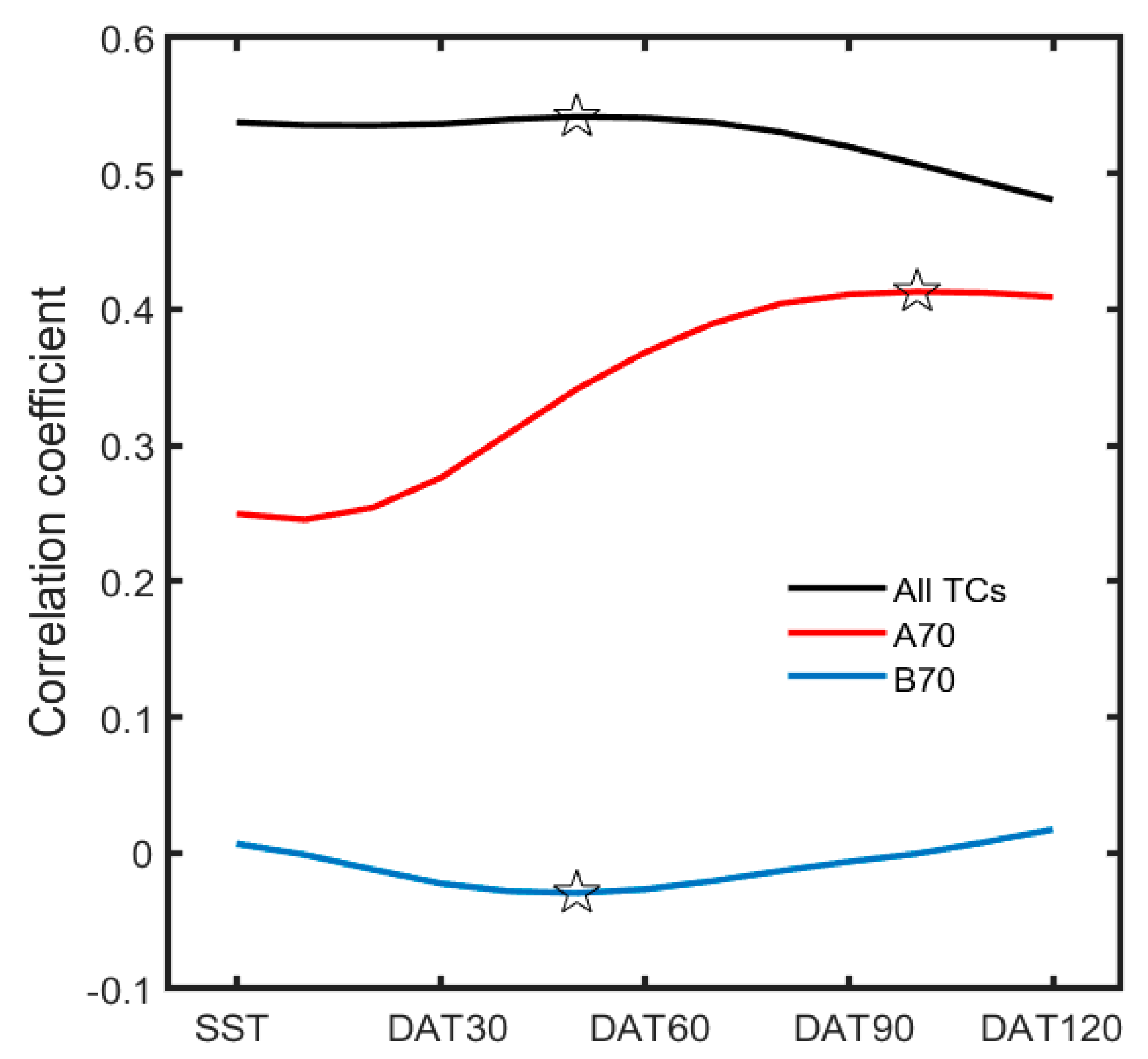

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | r |
|---|---|---|
| JDAY | The absolute value of Julian day—248 | −0.27 |
| LAT | Latitude of typhoon location | −0.33 |
| LON | Longitude of typhoon location | 0.07 |
| SPD | Storm moving speed | −0.23 |
| D200 | Area-averaged (0 km to 1000 km) divergence at 200 hPa | 0.05 |
| RV500 | Area-averaged (0 km to 1000 km) relative vorticity at 500 hPa | 0.16 |
| RV850 | Area-averaged (0 km to 1000 km) relative vorticity at 850 hPa | 0.04 |
| U200 | Area-averaged (200 km to 800 km) zonal wind at 200 hPa | −0.28 |
| T200 | Area-averaged (200 km to 800 km) air temperature at 200 hPa | −0.39 |
| RHHI | Area-averaged (200 km to 800 km) relative humidity 500–300 hPa | 0.32 |
| RHLO | Area-averaged (200 km to 800 km) relative humidity 850–700 hPa | 0.29 |
| SH200 | Area-averaged (200 km to 800 km) 200 hPa to 850 hPa vertical wind shear | −0.17 |
| SH500 | Area-averaged (200 km to 800 km) 500 hPa to 850 hPa vertical wind shear | −0.32 |
| OHC | Area-averaged (0 km to 200 km) ocean heat contents | 0.52 |
| DAT10—DAT120 | Ocean temperatures averaged from the near-surface down to the various depth (10 to 120 m, 10-m interval) | 0.48–0.54 |
| DMPI10—DMPI120 | Maximum potential intensity using DAT10—DAT120 | 0.47–0.56 |
| Period | A70 | B70 | Total |
|---|---|---|---|
| 2004–2013 | 60 | 17 | 77 |
| 2014–2016 | 26 | 10 | 36 |
| 2004–2016 | 86 | 27 | 113 |
| Rule NO. | Decision Rules | The Confidence of the Rule |
|---|---|---|
| 1 | If DMPI20 < 114 kt, then TC will not develop above 70 kt. | 45/51 = 88.2% |
| 2 | If DMPI20 ≥ 114 kt and LAT ≥ 22.1° N, then TC will not develop above 70 kt. | 8/9 = 88.9% |
| 3 | If DMPI20 ≥ 114 kt, LAT < 22.1° N and DAT100 < 26.3 °C, TC will not develop above 70 kt. | 4/6 = 66.7% |
| 4 | If DMPI20 ≥ 114 kt, LAT < 22.1° N and DAT100 ≥ 26.3 °C, TC will develop above 70 kt. | 51/54 = 94.4% |
| Model | |||
|---|---|---|---|
| A70 | B70 | ||
| Observed | A70 | 51 | 9 |
| B70 | 3 | 57 | |
| Model | |||
|---|---|---|---|
| A70 | B70 | ||
| Observed | A70 | 24 | 2 |
| B70 | 5 | 5 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-H.; Moon, I.-J.; Won, S.-H.; Kang, H.-W.; Kang, S.K. Decision-Tree-Based Classification of Lifetime Maximum Intensity of Tropical Cyclones in the Tropical Western North Pacific. Atmosphere 2021, 12, 802. https://doi.org/10.3390/atmos12070802
Kim S-H, Moon I-J, Won S-H, Kang H-W, Kang SK. Decision-Tree-Based Classification of Lifetime Maximum Intensity of Tropical Cyclones in the Tropical Western North Pacific. Atmosphere. 2021; 12(7):802. https://doi.org/10.3390/atmos12070802
Chicago/Turabian StyleKim, Sung-Hun, Il-Ju Moon, Seong-Hee Won, Hyoun-Woo Kang, and Sok Kuh Kang. 2021. "Decision-Tree-Based Classification of Lifetime Maximum Intensity of Tropical Cyclones in the Tropical Western North Pacific" Atmosphere 12, no. 7: 802. https://doi.org/10.3390/atmos12070802
APA StyleKim, S. -H., Moon, I. -J., Won, S. -H., Kang, H. -W., & Kang, S. K. (2021). Decision-Tree-Based Classification of Lifetime Maximum Intensity of Tropical Cyclones in the Tropical Western North Pacific. Atmosphere, 12(7), 802. https://doi.org/10.3390/atmos12070802