1. Introduction
Drought is a gradual and pernicious natural catastrophic event with global socioeconomic and environmental consequences. This is a highly perilous climate-related catastrophe that has a substantial effect on both the environment and human existence [
1]. Droughts have a profound effect on municipal water supplies, which is one of their most important effects. These supplies refer to the purified water distributed to households and businesses, which is crucial for human consumption, cleanliness, and numerous critical services on a global scale [
2]. Municipal water sources are given priority during drought and water constraint due to their significant sociological and economic relevance. This prioritization entails reallocating available water resources, frequently diverting them away from other sectors, especially agriculture, to ensure the uninterrupted supply of water to urban areas and their residents [
3]. During extremely severe drought circumstances, the water sources that urban water systems depend on can be exhausted, leading to a scarcity of municipal water for consumers.
In 2018, Cape Town and other parts of the country faced acute water shortages as a result of drought. These occurrences and growing concerns about water scarcity in urban areas are the result of several factors, including rising demand for water due to population growth, unpredictable weather patterns, the effects of climate change, and, in some cases, insufficient planning and management of water infrastructure [
4,
5]. In addition, the exploitation of surface water and groundwater resources, which have historically supplied water for human sustenance and agriculture, has reached unsustainable levels in several countries, resulting in negative environmental consequences [
6]. The excessive use of these natural water resources has led to the contamination of certain water bodies, such as the salinization of over-exploited aquifers or the inability to dilute and assimilate wastewater discharges, rendering the water supplies unsuitable for human consumption [
7]. To maintain a secure and stable water supply in the present and the future, it is essential to recognize that the development of resilient water systems is an imperative necessity [
8]. In disaster management, the application of time series forecasting methodologies can serve as an early warning system.
The main aim of drought risk analysis is to improve drought management and forecasting techniques. It focuses on various aspects of droughts, such as their size, duration, intensity, and spatial extent [
9]. Droughts develop slowly, and their consequences become apparent over a long period of time. To monitor and predict droughts, various drought indices are used to measure the deviation of meteorological variables, such as precipitation, from their long-term averages [
10]. In general, drought monitoring relies on several indices, including the Palmer Drought Severity Index (PDSI) [
11], Effective Drought Index (EDI) [
12], Reconnaissance Drought Index (RDI) [
13], Standardized Precipitation Evapotranspiration Index (SPEI) [
14], Weighted Anomaly Standardized Precipitation Index (WASP) [
15], and Standardized Drought Indices (SDIs) [
16]. A comprehensive list of these indices and their descriptions can be found in Zargar et al. [
17]. However, the most widely used method for drought monitoring using drought indices is the Standardized Precipitation Index (SPI) [
18], primarily because it only uses one parameter (precipitation).
The SPI, developed by McKee et al. [
18], is widely used as a global drought monitoring tool following the Lincoln Drought Declaration of the World Meteorological Organization [
19,
20]. What sets the SPI apart from other indices is its simplicity, as it relies solely on precipitation data. As a result, it is invaluable for conducting drought risk analysis and estimations in areas where data are limited and other parameters such as stream flow, evapotranspiration, and soil moisture information may be unavailable [
21]. The SPI is applicable across different time periods and geographical areas, and it can be computed for various temporal scales [
22]. As a result, it facilitates the assessment of drought duration, magnitude, and severity, while also categorizing droughts into hydrological, agricultural, or environmental types. The SPI’s utilization of a probabilistic approach has solidified its significance in drought analysis, making it a widely adopted tool in many global regions. Hence, accurate estimation of the SPI is crucial for comprehensive drought analysis.
To date, a multitude of research papers have been published on the estimation of drought indices using data-driven techniques [
23,
24,
25,
26,
27,
28]. The significance of addressing drought-related issues has increased as time series analysis continues to advance. Prediction of drought requires the management of complex, often nonstationary, nonlinear precipitation data, and SPI time series. Rarely do we encounter simple and stable time series in practice. Consequently, it is of the utmost importance to identify an efficient method for addressing the complexities of nonlinear and nonstationary time series and for making accurate forecasts. In the realm of developing data-based drought forecasting models, linear approaches, such as the utilization of autoregressive integrated moving average (ARIMA) models, have been superseded by nonlinear approaches rooted in Artificial Intelligence models in recent years. Nonetheless, due to the complexities of evaluating time series precision, devising suitable forecasting models remains a formidable challenge [
29].
In recent years, numerous models, such as the Autoregressive Integrated Moving Average (ARIMA) model, have been utilized for drought forecasting due to its their adaptability and greater information on time-related changes [
30]. However, the ARIMA model has certain limitations that make it unsuitable for forecasting hydrometeorological time series, especially when dealing with nonstationarity and nonlinearities [
31]. According to Achite et al. [
32], machine learning techniques have limited ability to anticipate nonstationary drought time series. As machine learning has evolved, the long short-term memory (LSTM) network has emerged as a solution to resolve long-term dependencies, especially in sequences with extended intervals and delays [
33]. The LSTM model has shown promising results when applied to the prediction of drought time series and related domains [
34,
35,
36]. Nonetheless, the inherent complexity of time series frequently results in suboptimal local predictions, thereby diminishing the overall performance of forecasting [
37].
To enhance time series prediction accuracy in the face of these complexities, scholars have introduced signal decomposition techniques [
38,
39,
40,
41]. Utilizing data pre-processing techniques, such as wavelet transform and decomposition methods, proves to be a highly effective approach in addressing this limitation [
42]. A study by Belayneh et al. [
43] emphasized the utility of wavelet transform as a valuable tool for data preprocessing, effectively decomposing the original dataset. This is particularly advantageous in predicting nonlinear and nonstationary time series. The wavelet transform enables the extraction of vital information at varying levels of detail, subsequently enhancing the performance of machine learning models. Rezaiy and Shabri [
44] utilized a hybrid modelling technique known as wavelet transform and ARIMA (W-ARIMA) in their drought forecasting study conducted in Kabul, Afghanistan. In their study, they utilized the Daubechies function of order 2 with a decomposition level of 3 for the wavelet transform. The integrated W-ARIMA method demonstrated superior performance in comparison to classic ARIMA techniques for SPI-based series in the short, medium, and long-term.
For the processing of nonstationary and nonlinear data with frequency components, the use of decomposition techniques serves as an additional preprocessing method in conjunction with the wavelet transform. In the context of predicting drought, decomposition emerges as a valuable tool when compared to wavelet transformation. Wavelet transform may have limitations due to a lack of sufficient mother wavelet functions or restricted decomposition levels. Signal decomposition efficiently removes certain characteristics from sequences, making them more stable and easier to handle. These methods streamline the initial simplified time series and enhance their predictability. Some of the methods include empirical mode decomposition (
EMD), ensemble empirical mode decomposition (EEMD), complementary ensemble empirical mode decomposition (CEEMD), and complementary ensemble empirical mode decomposition with adaptive noise (CEEMDAN). CEEMD addresses both the problem of blending modes in
EMD and the issue of residual white noise in EEMD. Furthermore, CEEMDAN is an enhanced iteration of CEEMD that provides enhanced adaptability in handling intricate signals with varying attributes and levels of noise. CEEMDAN is specifically intended to adaptively assess and remove noise from the signal throughout the decomposition process. This is especially advantageous when the input signal is contaminated by noise, as it enhances the integrity of the recovered components. The combination of decomposing techniques and prediction models has demonstrated potential in improving the prediction of drought in time series data [
45]. In the study conducted by Libanda and Nkolola [
46], it is demonstrated that the hybrid model exhibits greater proficiency in managing the intricacies of drought forecasting through the integration of
EMD. This integration effectively addresses the limitations of ARIMA’s exclusively linear and stationary approach. Xu et al. [
47] utilized the CEEMD-ARIMA combined model to forecast drought in the Xinjiang Uygur Autonomous Region of China. The model outperformed the standalone ARIMA in terms of prediction accuracy across many timescales. Ding et al. [
37] utilized a hybrid model combining CEEMD-LSTM to predict drought in the Xinjiang Uygur Autonomous Region of China using the standardized precipitation index. The hybrid model demonstrated superior performance compared to LSTM.
Drought forecasting, particularly for different lead times, remains a challenging task [
48]. In the literature of drought prediction, several methods using the hybrid approach for accurately predicting the SPI have been extensively discussed in recent years [
49,
50]. These hybrid methods have shown remarkable efficacy in SPI prediction, producing outstanding performance results. Despite these advancements, there is still a need for models that can accurately predict drought indices such as the SPI across diverse climatic conditions and temporal scales. The importance of accurate SPI drought prediction lies in its ability to provide and plays a pivotal role in efficient water resource management, decision-makers, policymakers and climate adaptation. Conventional models like ARIMA frequently encounter challenges in capturing the intricate, nonlinear characteristics of climatic data. While LSTM can address nonstationarity and nonlinearity through functions, optimizing its performance often entails preprocessing the data to unveil inherent patterns. Recent advancements, such as the CEEMDAN technique, hold promise for enhancing predictive accuracy by decomposing time series data into IMFs.
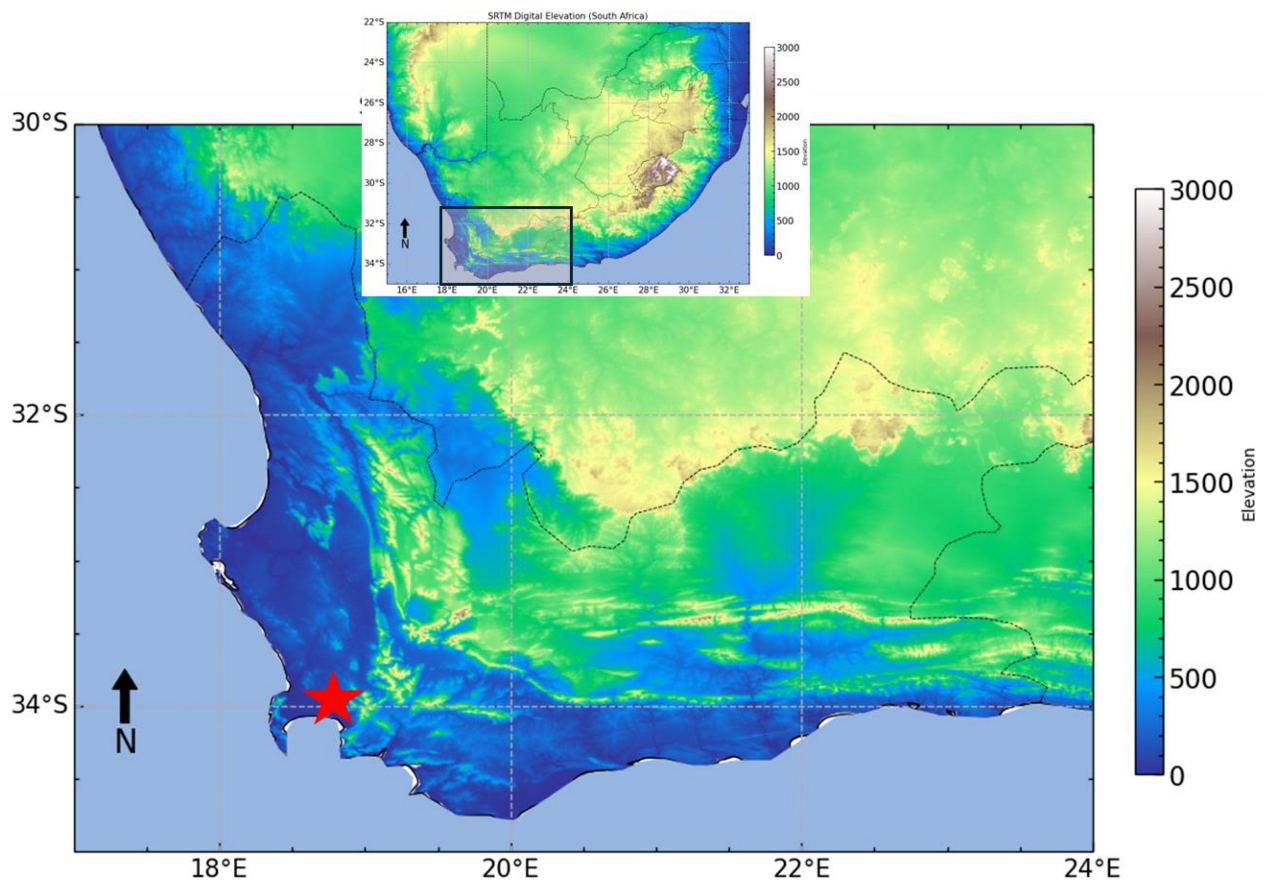
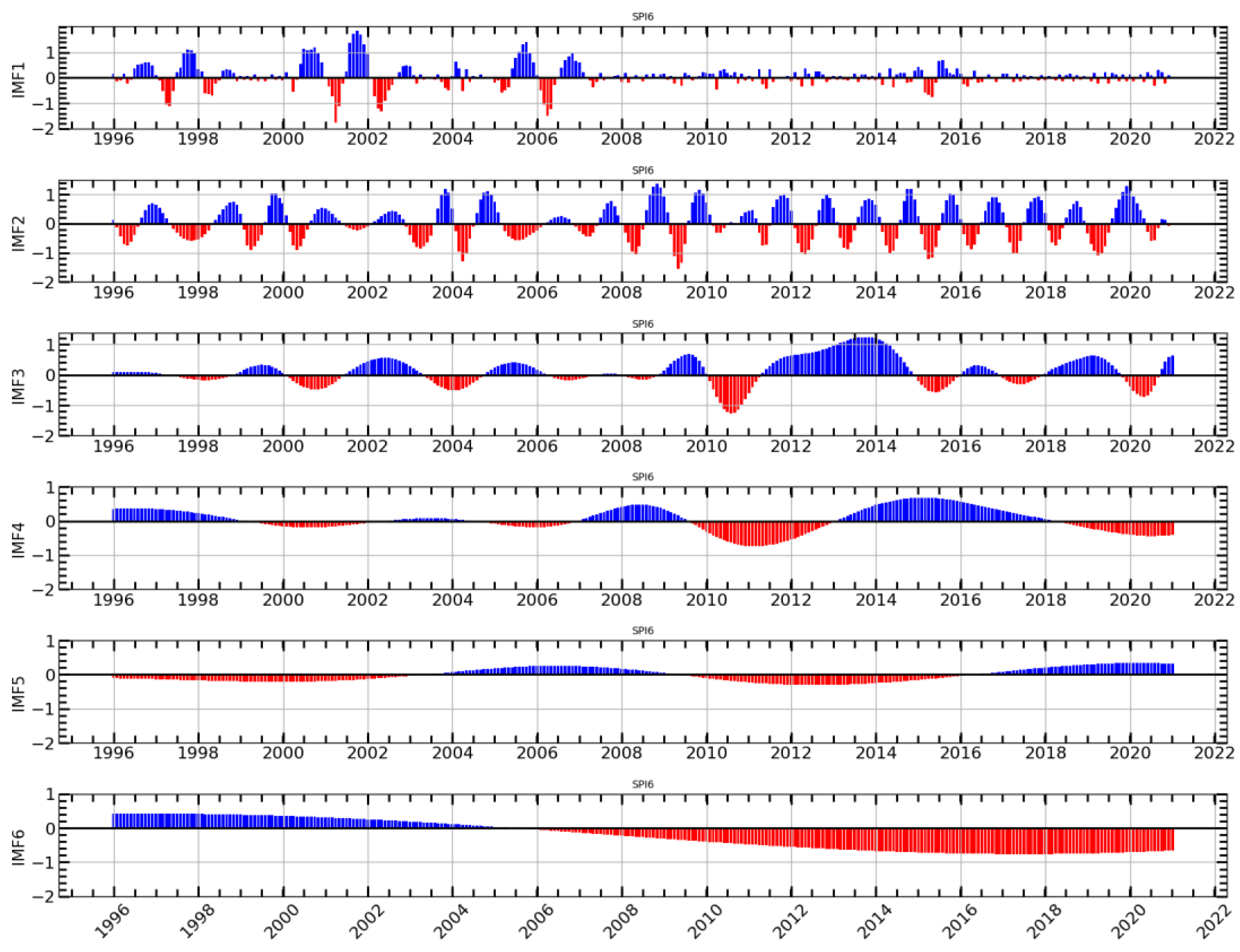
Due to the complexities associated with the nonlinear and nonstationary nature of precipitation data, our objective is to investigate more efficient methods for time series prediction. However, there is a lack of extensive research on the integration of CEEMDAN with ARIMA-LSTM for drought prediction in South Africa. The objective of the study is to enhance the precision of drought prediction by capitalizing on the strengths of these methods in managing intricate time series. Specifically, the study aims to (i) decompose precipitation data using CEEMDAN into five IMFs and one residual component; (ii) predict each IMF and the residual using ARIMA, LSTM, and ARIMA-LSTM; (iii) combine the forecasts of each IMF and residual to obtain the final drought prediction; and (iv) evaluate the accuracy of the proposed method against traditional ARIMA and LSTM models, as well as advanced methodologies used in previous studies. The focus of the study is on Cape Town International Airport in the Western Cape province of South Africa, an area with unique drought dynamics that have not been explored using hybrid methodologies before. By combining CEEMDAN and ARIMA-LSTM, our innovative model not only fills this research gap but also provides a pioneering solution that can significantly improve accuracy in drought forecasting. Through rigorous evaluation against established benchmarks such as ARIMA and LSTM, we aim to demonstrate the superior performance of our hybrid approach, thereby solidifying its significance in advancing the field of drought prediction.
4. Discussion
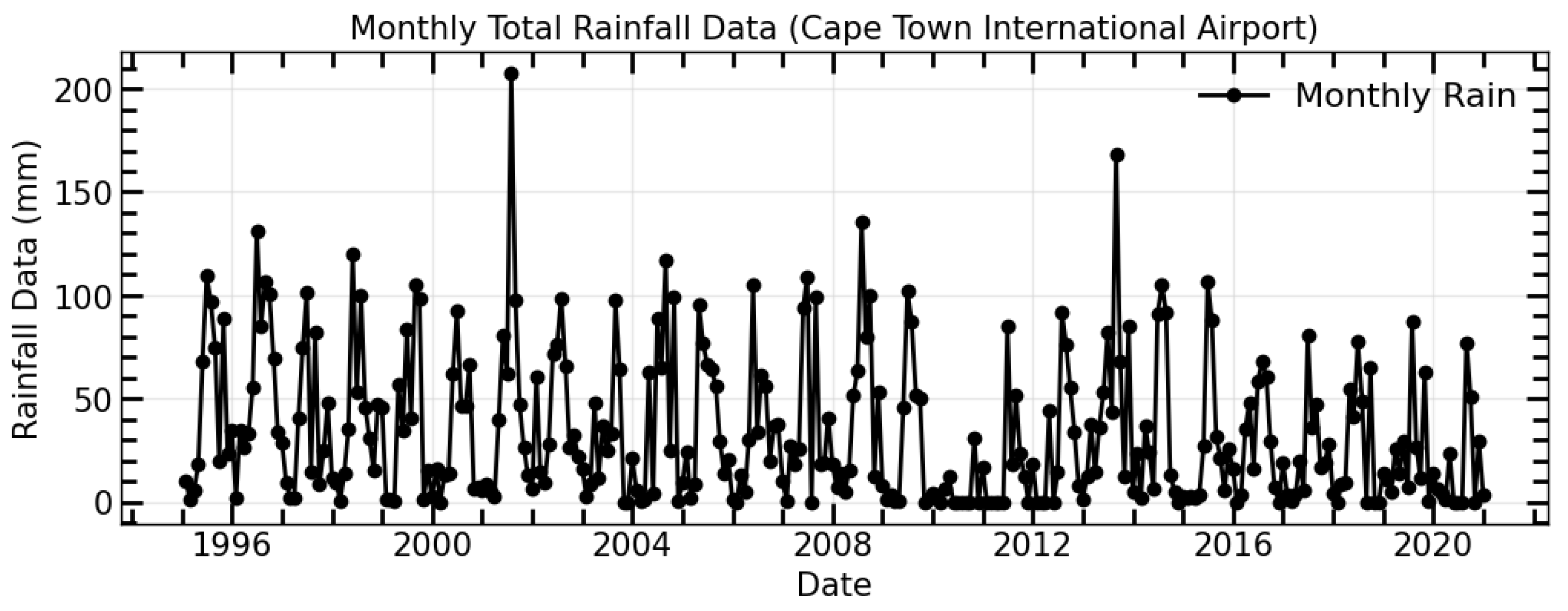
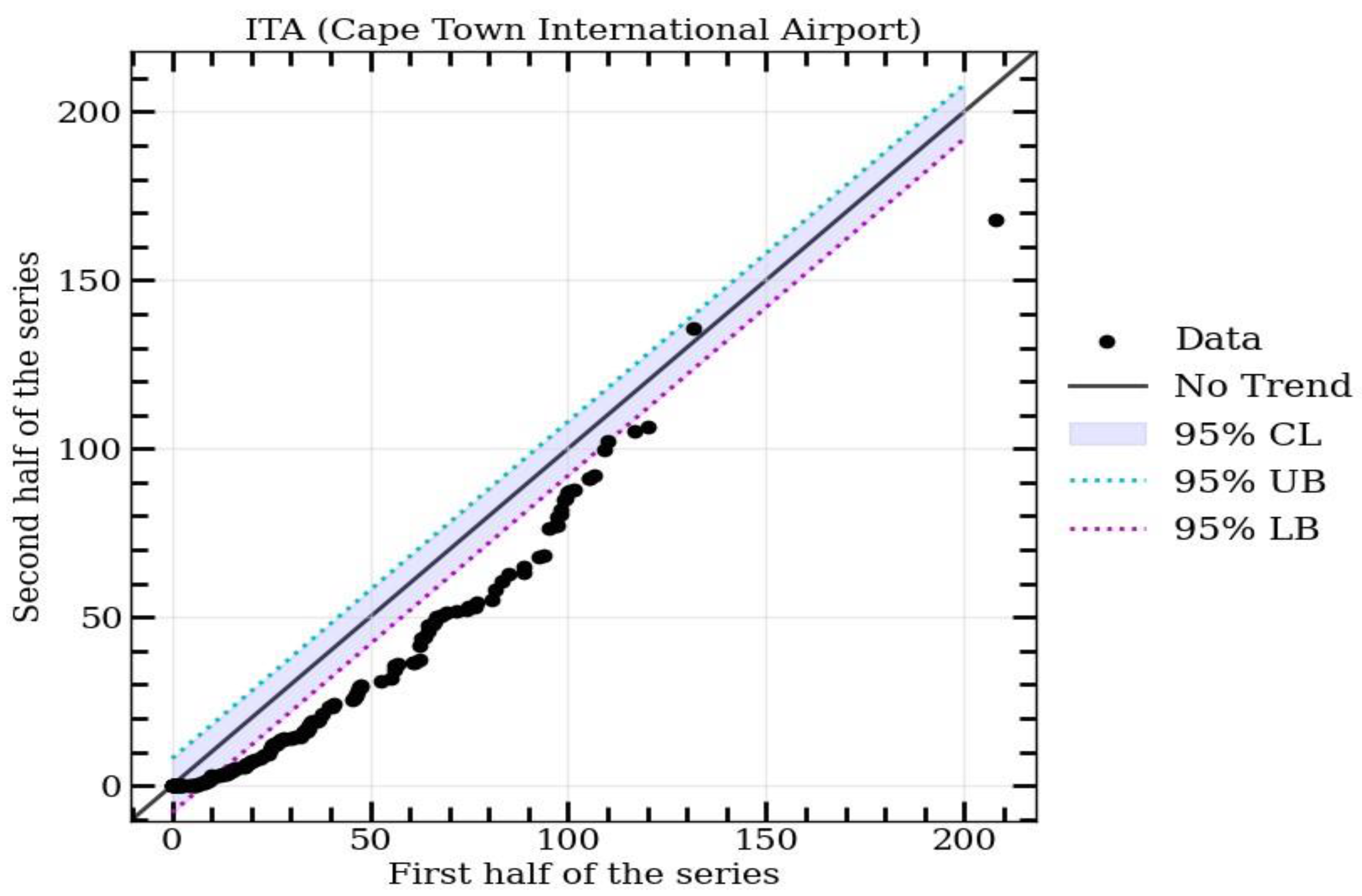
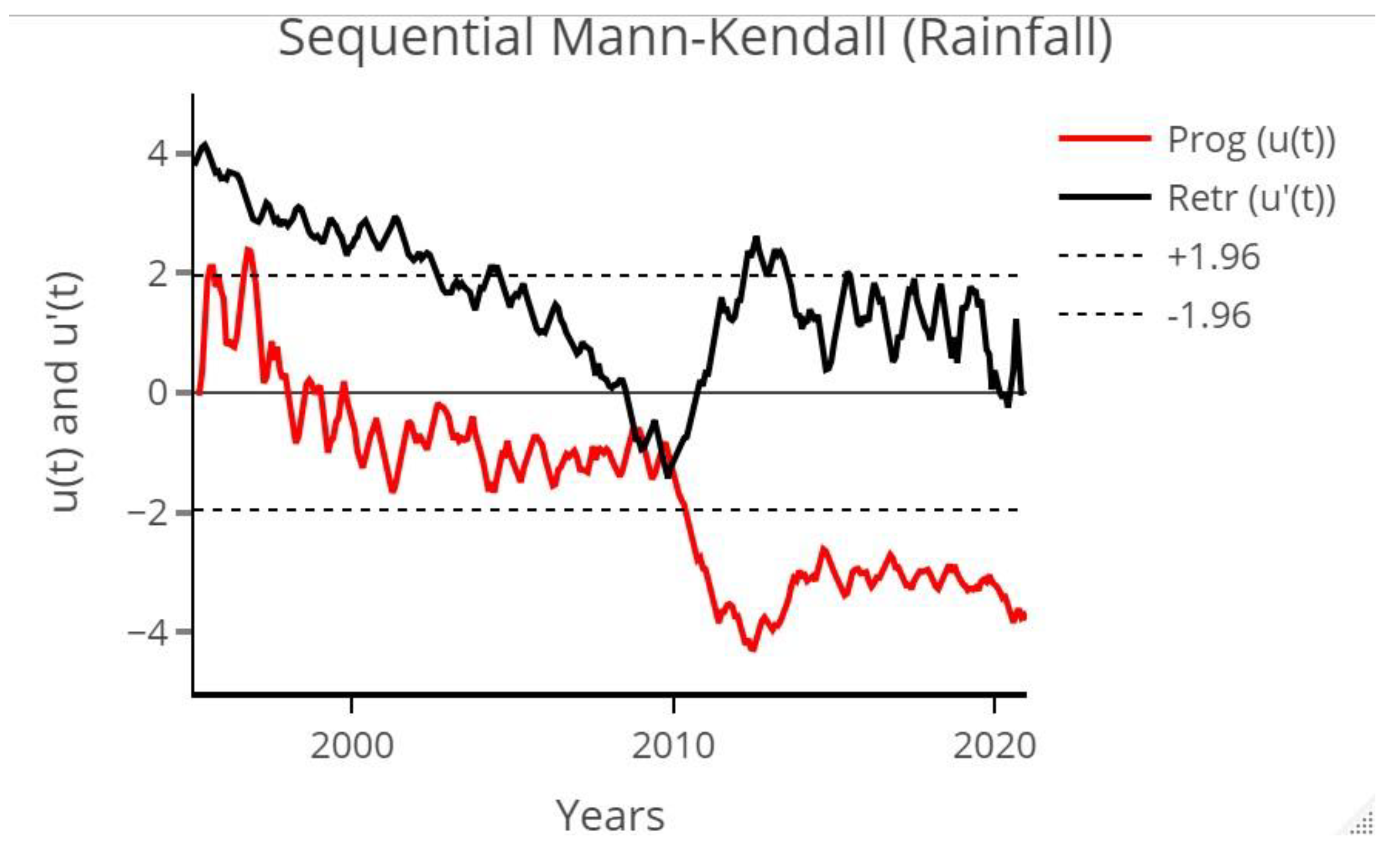
In this study, we utilized innovative trend analysis methods, including the Mann–Kendall test and Sequential Mann–Kendall test, to determine the drought trends in meteorological variables within the basin. The precipitation drought indicator was evaluated in relation to the precipitation data obtained from the weather station at Cape Town International Airport. The ITA, Mann–Kendall test, and SQ-MK trend methods indicated a significant downward trend in rainfall in Cape Town. These findings align with the research conducted by Ndebele et al. [
82] and Jury [
83]. A study conducted by Ndebele [
82] also reported a significant negative trend in rainfall measurements for Cape Town. Additionally, Jury [
82] found evidence of a consistent drying trend, faster warming, and declining rainfall, particularly during the winter wet seasons. The SQ-MK findings presented in this research further support the notion of a steady dry trend, which coincided with the El Niño Period of 2015–2017. These results are consistent with the findings of a study conducted by Wolski et al. [
84]. We also employed ITA, which complements the MK and SQ-MK tests in terms of trends, and the results reveal the importance of knowing drought conditions. The findings of our study support previous research conducted by Nxumalo et al. [
85], Muse et al. [
86], and Tladi et al. [
87], which emphasize the importance of employing trend analysis in African countries to investigate the impacts of climate change. Trends and predictive models play a crucial role in informing proactive decision making.
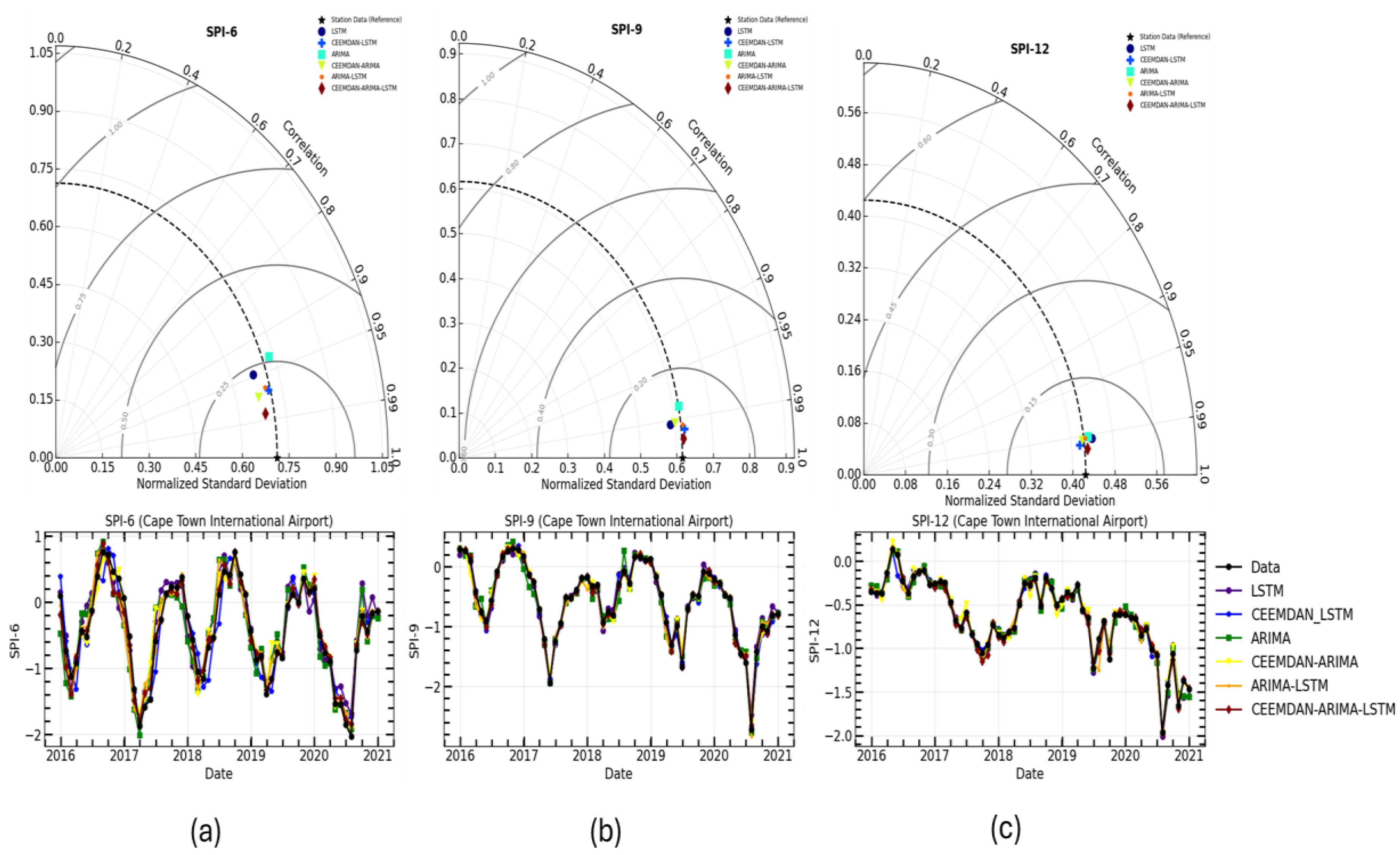
According to the statistical indices in
Table 4, the models with CEEMDAN performed considerably better than those without, leading to improved forecasting accuracy. These findings are consistent with previous studies [
37,
47,
88,
89,
90,
91], which emphasized the enhanced forecasting accuracy of employing hybrid drought forecasting models in comparison to stand-alone models. For instance, Ding et al. [
37] proposed a hybrid model based on complementary ensemble empirical mode decomposition (CEEMD) and long short-term memory (LSTM) to improve the accuracy of drought prediction in the Xinjiang Uygur Autonomous Region in China. A comparison of their results revealed that CEEMD was able to improve the forecasting accuracy of the hybrid model, as evidenced by the decreasing mean square error with increasing timescale, and the gradual improvement of the CEEMD-LSTM models. The hybrid CEEMD-LSTM model outperformed the LSTM model with
RMSE values of 0.815, 0.578, 0.378, 0.291, 0.219, and 0.152 for SPI-1, SPI-3, SPI-6, SPI-9, SPI-12, and SPI-24, respectively. Xu et al. [
47] explored the strengths of autoregressive integrated moving average (ARIMA) and complementary ensemble empirical mode decomposition (CEEMD) to predict drought using 60 years of monthly precipitation data from 1960 to 2019 for the Ningxia Hui Autonomous Region. The results revealed that the CEEMD–ARIMA model had lower
MAE and
RMSE values compared to the ARIMA model at all timescales. Additionally, the NSE, KGE, and WI values were higher for the CEEMD–ARIMA model, indicating higher prediction accuracy and suitability for predicting a multiscale SPI. Salisu and Shabriet [
89] proposed a hybrid Wavelet–ARIMA model and examined its ability to forecast drought using SPI data from January 1954 to December 2008. The comparison of their results showed that the Wavelet improved the forecasting accuracy of the hybrid model, as the mean square error decreased by an average value of 43%. Rezaiy and Shabri [
90] combined the Support Vector Machine (SVM) model with ensemble empirical mode decomposition (EEMD) to present a novel method for drought prediction using monthly precipitation data from Bamyan province in Central Afghanistan, spanning the period January 1970 to December 2019. The results demonstrated that the EEMD-SVM technique significantly improved drought forecasting accuracy, especially for mid- and long-term SPIs. For example, in the testing period, SPI 9 yielded an
RMSE of 0.1632,
MAE of 0.1208, and
R2 of 0.9357, while for SPI 12, the
RMSE was 0.1078,
MAE was 0.0745, and
was 0.9141. These results indicate that the EEMD-SVM technique outperformed conventional ARIMA and SVM models, achieving the best criteria with the lowest
RMSE and
MAE values and the highest
value.
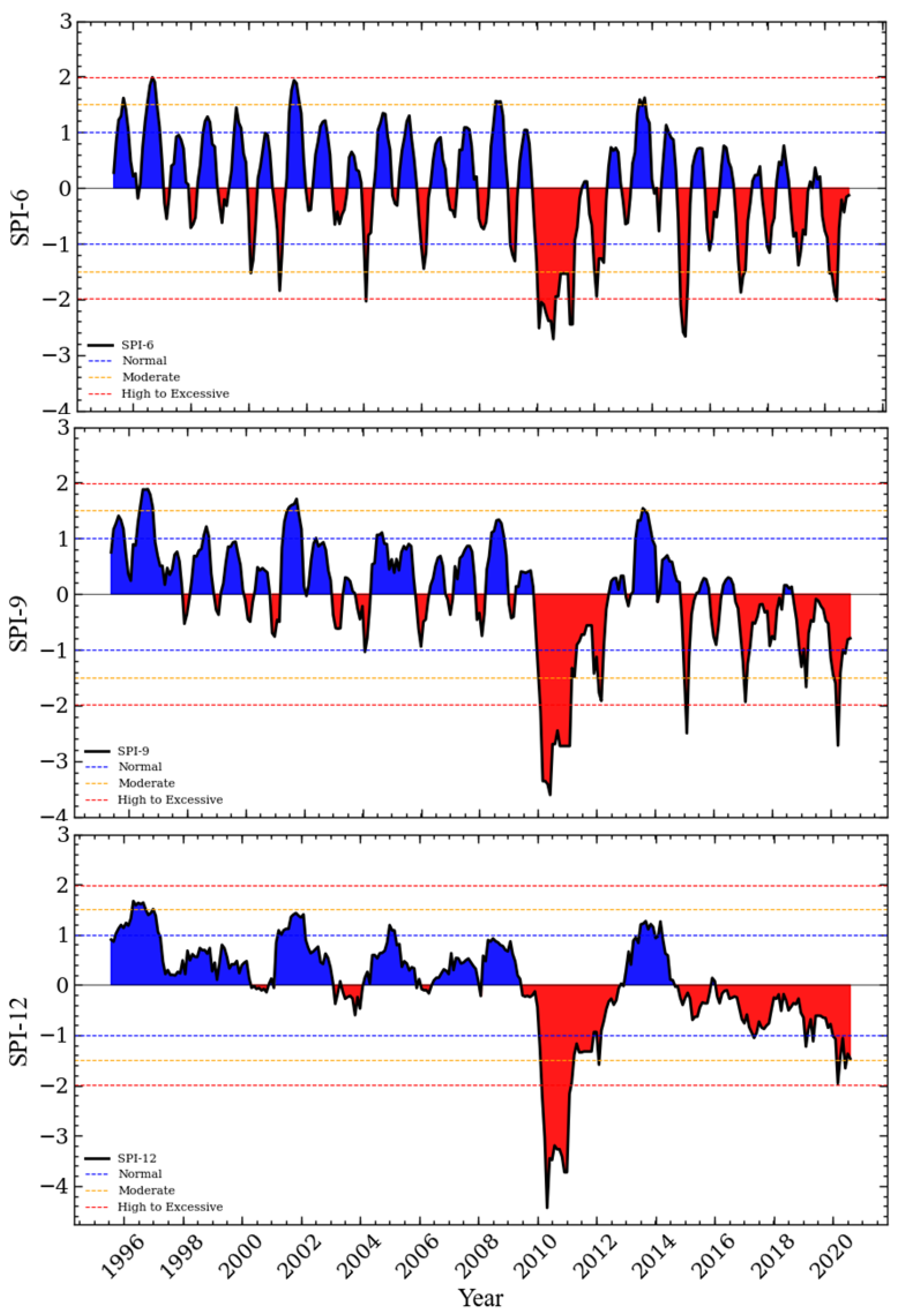
Based on a comparative analysis of this study’s findings with previous research, it is evident that the SPI forecasting results indicate that the hybrid model (CEEMDAN-ARIMA-LSTM) consistently outperformed all other models across all SPI timescales in terms of prediction accuracy. The RMSE of the CEEMDAN-ARIMA-LSTM hybrid model is 0.121, 0.044, and 0.042 for SPI-6, SPI-9, and SPI-12, respectively. The for this hybrid model is 0.972, 0.991, and 0.955, for SPI-6, SPI-9, and SPI-12, respectively. This indicates that this is the most suitable model for forecasting long-term drought conditions in Cape Town. Based on the aforementioned discussion and the findings of this study, our work provides valuable insights into the use of the hybrid CEEMDAN-ARIMA-LSTM model for forecasting meteorological drought.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}