1. Introduction
The amount of data available in nature has become larger, demanding new statistical distributions to modify the description of each phenomenon or experiment under study. Most lifetime data are continuous, while they are discrete in observation, which leads to a need for appropriate methods to discretize the continuous distribution to better fit these data. Almost always, the observed values are in fact discrete because they are restrained to only a finite number of decimal places and cannot really create all points in a continuum. In some other cases, because of the accuracy of the measuring apparatus or the need to save space, continuous variables are measured by the frequencies of separate class intervals, whose union creates the whole range of random variables, and multinomial law is used to model this situation. Therefore, considering them as discrete values is more appropriate. Even for a continuous life experiment, records in an interval of time result in a discrete model, which seems more suitable than a continuous model.
Recently, many discrete distributions have been identified, particularly in reliability and survival analyses. For a special description and the role of discrete distributions, one may refer to [
1,
2,
3,
4,
5,
6,
7,
8], among others. Hence, many authors have conducted much work to originate and develop discrete reliability theory from various points of view.
The characterization of continuous random variables can be performed either by their probability density function (pdf), cumulative distribution function (CDF), moments, hazard rate functions, or others. Usually, creating a discrete analogue from a continuous distribution is based on the principle of preserving one or more characteristic properties of the continuous one. Consequently, different ways to discretize a continuous distribution appear in the literature, depending on the property the researcher aims to preserve (see, for example, [
9,
10]). In [
11], the author provided an extensive survey of different discretization methods that preserve different functions.
There are many useful tips for creating discrete random variables from continuous ones: through discretization, data can actually be summarized and simplified; in addition, they can also become easier to understand, use, and explain for researchers (see [
12]). Other tests appearing in the literature are suitable for both discrete and continuous distributions (see, for example, [
13,
14]).
Therefore, it is desirable to study a suitable discrete distribution created from the underlying continuous models.
In the present paper, we discretize the continuous generalized Pareto distribution (GPD) using three different discretization methods. Almost all authors have used one discretization method, which depends on the survival function. In [
6,
7], discrete normal and discrete Rayleigh distributions were introduced, respectively, and the author used the survival discretization approach. Using the same approach, discrete Burr type II was studied in [
15]. Additionally, [
16] introduced the discrete additive Weibull distribution (see also [
17,
18,
19,
20,
21,
22,
23]). However, there remains a need to improve discrete models and generate new ones for the sake of describing and fitting the huge amount of data that appear and spread evenly throughout humans’ daily lives. Further, [
24] discussed the discrete odd Perks-G class of distributions. Reference [
25] introduced a new novel discrete distribution with an application to COVID-19, and [
26] obtained a discrete Weibull Marshall–Olkin family of distributions.
We aim to discretize the GPD since it has extensive applications and can model many real-life distributions. Recently, many authors have studied the continuous GPD; for example, one may refer to [
27], in which the authors discussed baseline methods for parameter estimation. The authors of [
28] performed statistical inference of the dynamic conditional GPD with weather and air quality factors, and [
29] discussed outlier-robust truncated maximum likelihood parameter estimators of the GPD. Reference [
30] introduced risk analysis using the GPD.
The originality of this work stems from the fact that no earlier research has been conducted in this area using the suggested discretization method and compared it with other methods from a Bayesian point of view. Symmetric and asymmetric loss functions are performed in the Bayesian estimation method using different parameter values. Therefore, the main objective of this paper is to illustrate the efficiency and performance of discrete generalized Pareto distributions (DGPDs) for modeling different COVID-19 daily death cases.
The rest of this paper is organized as follows:
Section 2 contains the model description and the discretization methods.
Section 3 presents Bayesian inference for unknown parameters, and both point and interval estimations are performed for the three DGPDs. In
Section 4, the simulation study is described. Real data examples are provided in
Section 5. Finally, conclusions are provided in
Section 6.
2. Model Description and Discretization Methods
The generalized Pareto distribution is a continuous distribution with two parameters. However, its continuous distributional form is limited in characterizing data of discrete forms. Discretizing the GPD, therefore, produces a consequent distribution that accommodates count data while preserving the vital tail-modeling feature of the GPD. In this paper, we perform three discrete versions of the two-parameter GPD and use these counterparts to model real-life data.
The probability density function (pdf) of the continuous GPD is given as
and the cumulative distribution function (CDF) is given by
where
> 0 is the scale parameter, and
is the shape parameter,
. The domain of the random variable
depends on the value of
, particularly whether it is positive or negative; hence, we have two cases: first, when
> 0,
, and when
< 0, the support of x will be bounded, i.e.,
. For
> 0, the GPD is the well-known Pareto distribution. When
, the GPD reduces to the exponential distribution, as shown in Equation (1).
The GPD has a mean of (
/(1 −
)) and a variance
, provided
< 0.5. The survival function
and the hazard rate function HR are given, respectively, as follows:
and
The three discretization methods are presented in the next subsections. The first method aims to preserve the survival function, while the second method preserves the pdf, and the third method preserves the hazard rate.
2.1. Survival Discretization Method
The probability mass function (
pmf) of a discrete distribution is defined by [
6,
7] as follows:
where
is the survival function given by Equation (3). Hence, the
pmf of the first discrete generalized Pareto distribution (DGPD1) is
The CDF of the DGPD1 distribution in the survival discretization method can be written as:
2.2. Methodology II
In this method, the
pmf of the discrete random variable is derived as an analogue of the continuous random variable with pdf
as
For more details and examples of this method, one can refer to [
11]. When applying this method to the continuous GPD, we perceive a second discrete distribution, namely, DGPD2. Accordingly, the
pmf can be written as:
The corresponding CDF is derived as
where
represents the Hurwitz zeta function.
2.3. Methodology III (Hazard Rate)
This methodology preserves the hazard rate function. It is performed as a two-stage method. In the first stage, the continuous random variable X with CDF F(x) defined on [0, +∞) is used to construct a new continuous random variable
with the hazard rate function
, (x ≥ 0). For more details about this methodology, a good reference is [
11]. The survival function of the discrete analogue
is given by
The corresponding
pmf is then given by
Note that the range of is the value of m (m need not be finite) and is determined so that it satisfies the condition 0 ≤ h (y) ≤ 1.
For the GPD model, the hazard rate function of
will be
; hence, the above condition holds. The survival function in Equation (11) for the third version of the discrete GP distribution (DGPD3) is
The corresponding
pmf is then given by
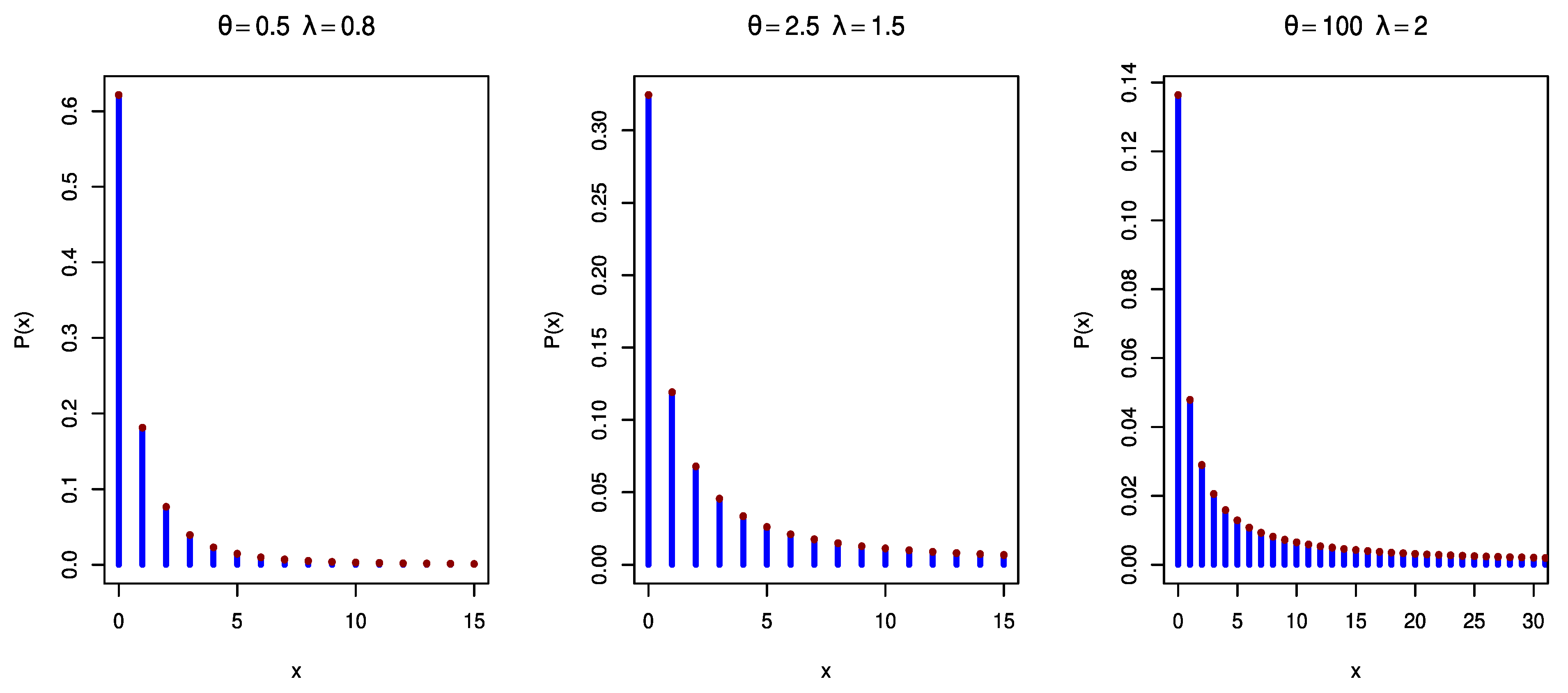
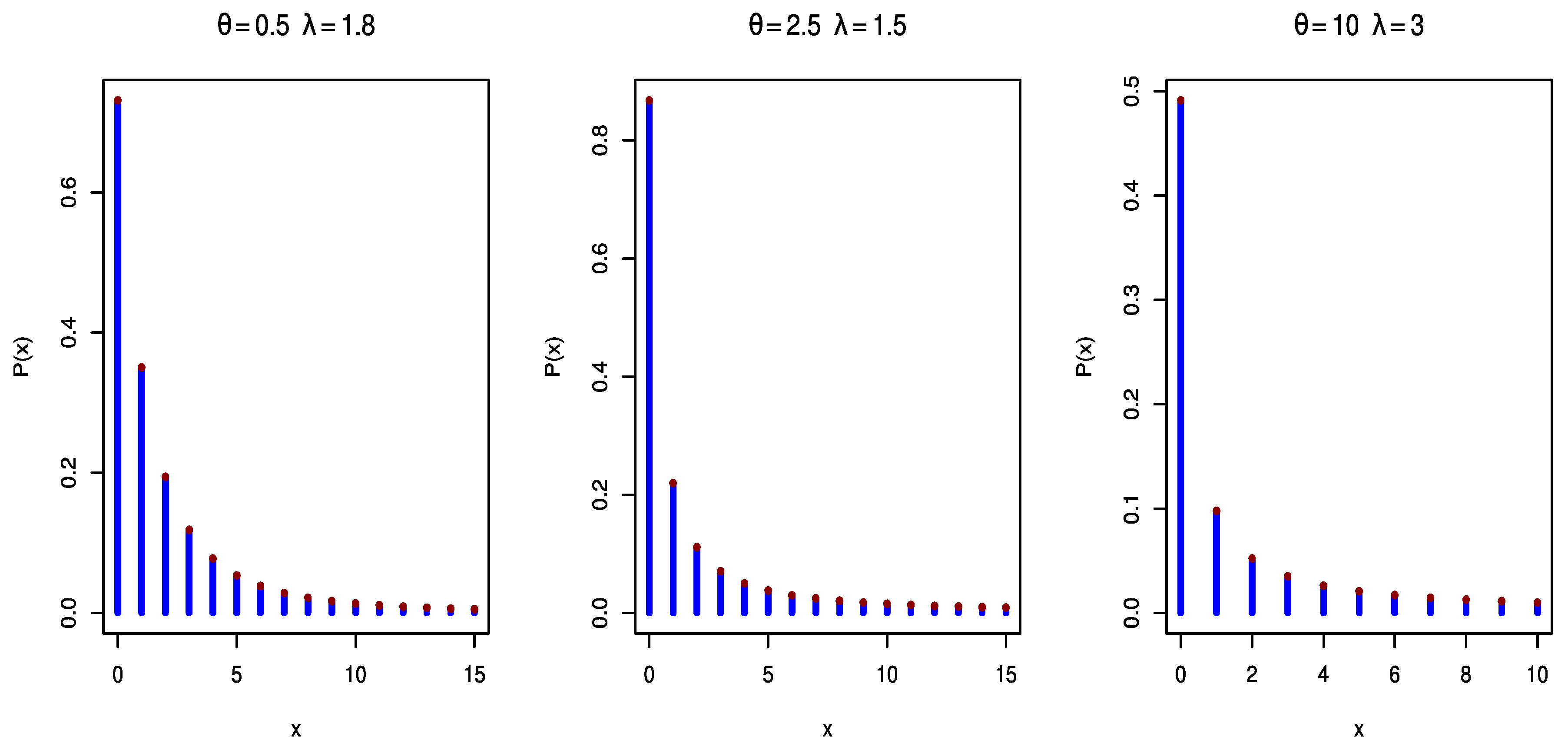
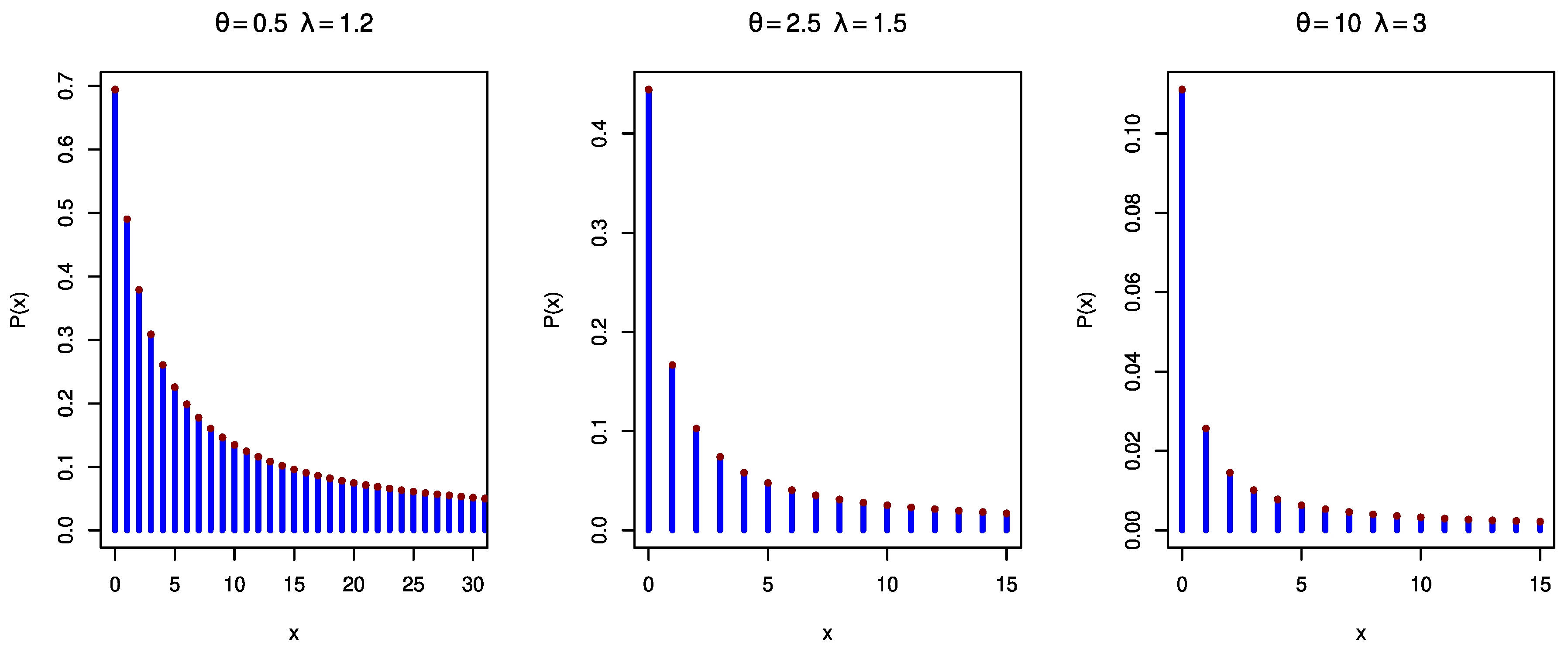
In
Figure 1,
Figure 2 and
Figure 3, the
pmfs of DGPD1, DGPD2, and DGPD3 are plotted, respectively, for different parameter values. They possess a decreasing trend with different selected parameter values.
3. Parameter Estimation
In this section, we estimate the unknown parameters of the three versions of the DGPD distribution using the Bayesian estimation method. Numerical techniques are utilized for Bayesian calculations, such as the Monte Carlo Markov Chain (MCMC) technique.
In the Bayesian method, the parameters of the model are assumed to be random variables with a certain distribution called the prior distribution. Usually, the prior information is not available; hence, we need to specify a suitable choice of the prior. In this work, we decided to use a natural joint conjugate prior distribution for the parameters
, which is known as the modified Lwin Prior; it is defined by assuming a gamma distribution for
and the Pareto (I) distribution for
. Hence,
and
where
are nonnegative hyperparameters of the assumed distributions. The authors of [
31] mentioned that it is more meaningful to express
conditional on
rather than vice versa. Moreover, they strongly believed that it is more appropriate to consider that the prior distributions for
and
are independent of each other.
Therefore, the prior distributions for
and
can be written as
Hence, the joint prior for
and
is
The joint posterior of
and
given the data is defined as
where
is the likelihood function of the DGPD,
is the joint prior given by Equation (14), and
.
The estimation for the parameters of the DGPD can be performed using different loss functions, such as (i) squared error (SE), (ii) LINEX, and (iii) general entropy (GE) loss functions. The performance of the estimators using the said loss functions was investigated using a simulation study. The bias, the mean square error (MSE), and the length of the credible interval were used as criteria for determining the superiority of the respective estimates.
3.1. Loss Functions
The following loss functions are used for posterior estimation.
3.1.1. Squared Error (SE) Loss Function
Assuming the SE loss function, Bayesian estimation for the parameters
and
is defined as the mean or expected value with respect to the joint posterior:
and
3.1.2. LINEX Loss Function
With the LINEX loss function, Bayesian estimation for the parameters
and
are formulated as
3.1.3. General Entropy (GE) Loss Functions
Using the GE loss function, Bayesian estimation for the parameters
and
is given by
3.2. Bayesian Estimation
For evaluating the above-expected values and double integration, numerical methods are essential. We opted to use the Markov Chain Monte Carlo (MCMC) technique by using the Gibbs sampling method and by formulating the suitable R code. For more details, one may refer to [
32]. Many authors have used Bayesian estimation for different lifetime models with many real data applications (see, for example, [
33,
34,
35]).
Since we implement three different discretization methods on the GP distribution, we have to deal with three cases of Bayesian inference based on the different pmfs of DGPDs that are written in Equations (6), (9), and (13).
3.2.1. Case 1
When applying the survival discretization method, we obtain DGPD1 with the
pmf given by Equation 6. The joint posterior density is
where
, and
(.,.) represents the gamma distribution.
Bayesian estimation for the parameters
and
using the
SE loss function is performed using Equations (15) and (16) with the posterior density Equation (19), respectively:
For the LINEX loss function, Bayesian estimation is obtained by using Equation (17) and the posterior density Equation (18):
Bayesian estimation for the parameters
and
using the GE loss function is obtained using Equations (18) and (19) and is given by
3.2.2. Case 2
For the second form of discrete GPD, namely, DGPD2, with the
pmf given by Equation (9), the joint posterior density is given by
where
=
.
Bayesian estimation for the parameters
and
using the SE loss function is given as
For the LINEX loss function, Bayesian estimation is found by the following integrations:
For the GE loss function, Bayesian estimation for parameters
and
is given by
3.2.3. Case 3
The third discretization method of GP yields DGPD3 with the
pmf described by Equation (13), and the joint posterior density is
where
.
Bayesian estimation for the parameters
and
using the SE loss function is given as
For the LINEX loss function, Bayesian estimation is found by the following integrations:
For the GE loss function, Bayesian estimation for parameters
and
is given by
4. Simulation Analysis
To evaluate the performance of the three discrete versions of the continuous GPD, we aim to compare the point estimation of the unknown parameters with respect to bias and MSE. Additionally, a comparison is conducted using the different loss functions described in
Section 3. Some interesting conclusions and results are reported at the end of this section.
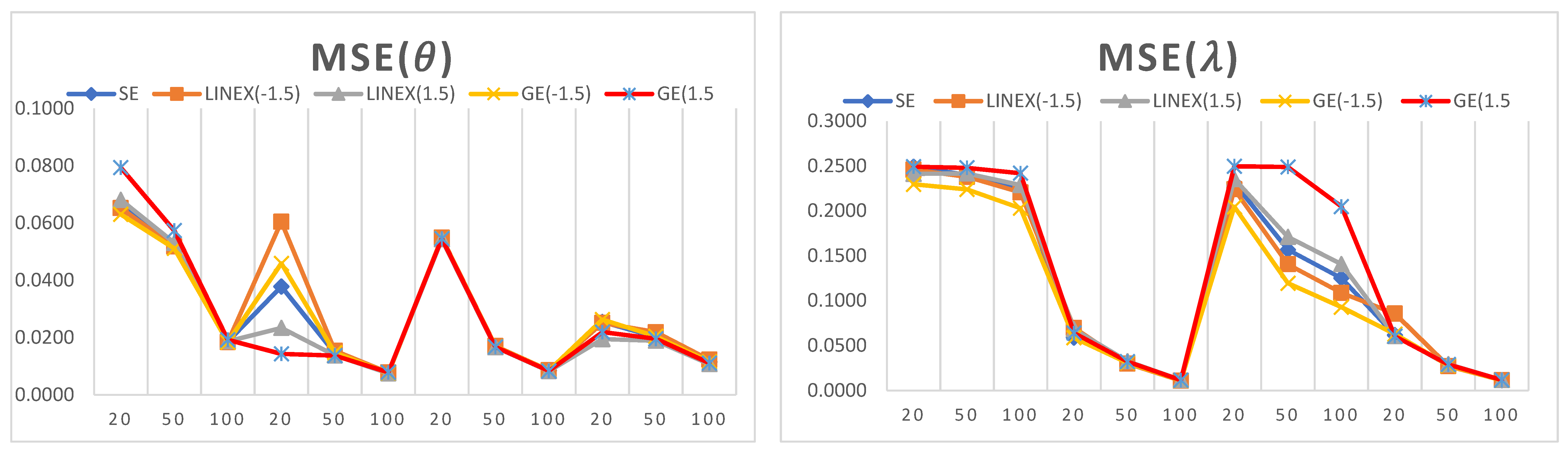
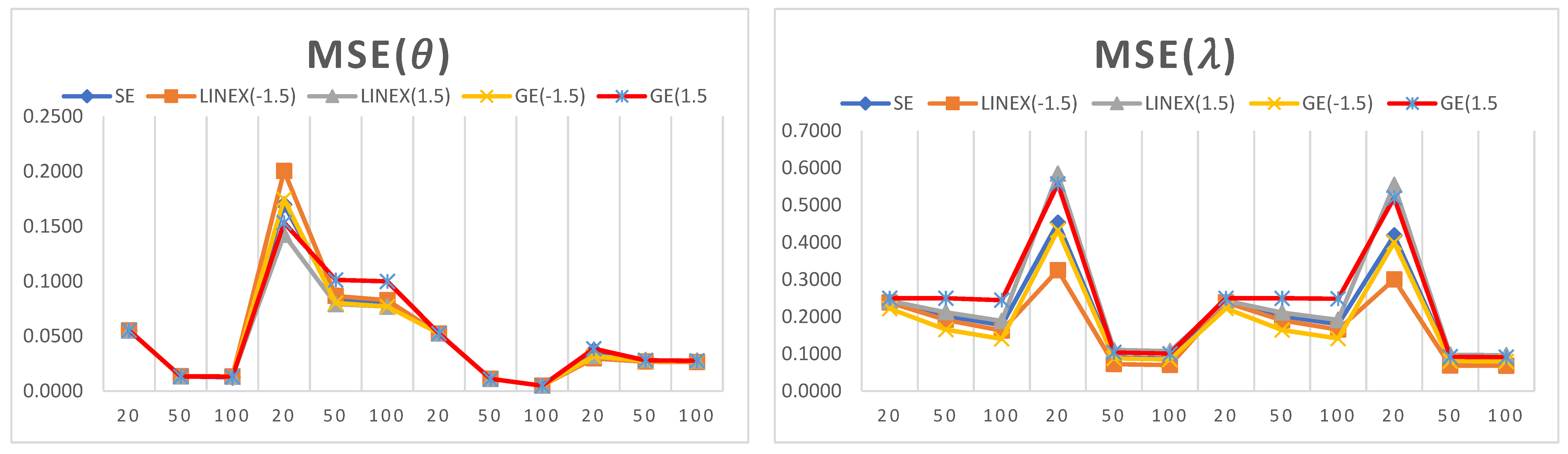
Random samples were generated with 10,000 iterations using the suitable R code; the different selected values of the parameters and were {0.5, 3}, and different sample sizes n = {20,50,100} were considered.
The simulation results of point and interval estimations for the three discrete versions of the GPD are reported in
Table 1,
Table 2 and
Table 3.
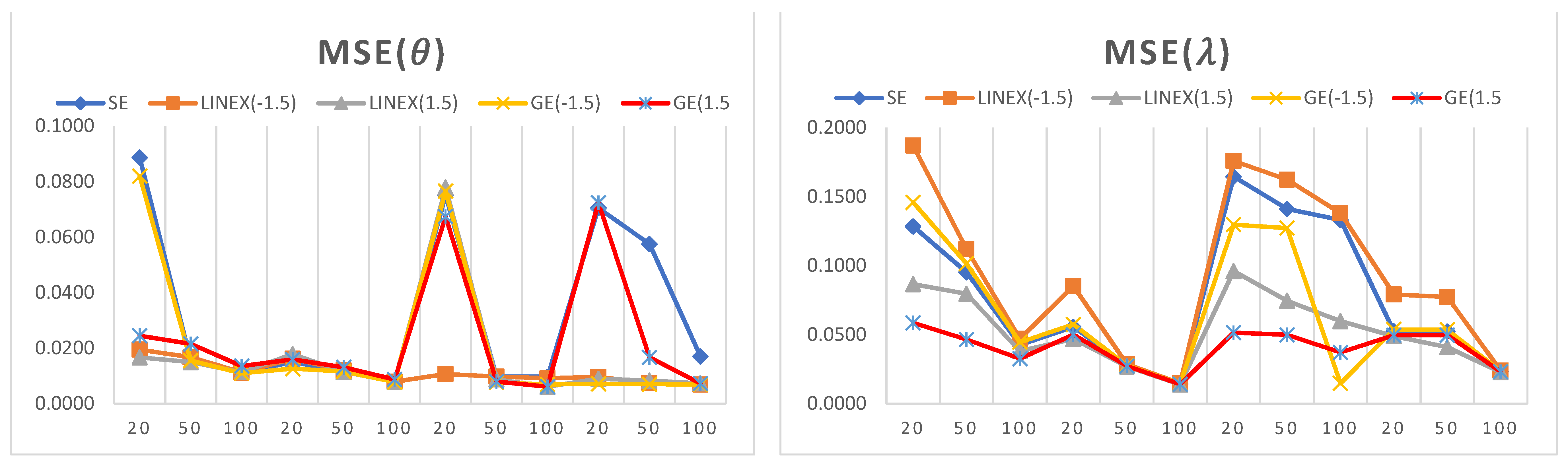
Figure 4,
Figure 5 and
Figure 6 illustrate the MSE for the simulation results in
Table 1,
Table 2 and
Table 3. The
x-axis represents sample sizes, which take values of {20,50,100}. For a fixed sample size, six different parameter values are presented. Therefore, lambda increases from 0.5 to 3 (the first six points) when theta is 0.5, and lambda increases from 0.5 to 3 (the last six points) when theta is 3.
The main simulation analysis points are as follows:
It can be observed that the estimated values of the model parameters converge to their true values when increasing the sample size. This can be observed since the MSE and biases decrease as the sample size increases, which shows that the proposed estimators are consistent in nature.
For a small sample size, the LINEX loss function provides the lowest values of MSE and bias when estimating , while the GE loss function provides the lowest values of MSE and bias when estimating .
For a large sample size, the LINEX loss function provides the lowest values of MSE and bias when estimating both parameters and .
In almost all cases, the LINEX and GE loss functions produce minimum bias and MSE values, and this is true for different sample sizes. Hence, LINEX and GE are recommended over SE in this study.
For the credible CI, it is noted that the shortest interval length is obtained when using the LINEX loss function.
The SE loss function has some advantages over other loss functions under some conditions; for example, when = = 3 and for a small sample size (n = 20), the bias and MSE attain their minimum values when estimating .
For a fixed value of , the bias decreases when the shape parameter increases. Similarly, for a fixed value of , the bias decreases when increases.
The length of the credible interval decreases when the sample size increases, and this is true for all loss functions under study.
When comparing the performance of the three DGPD analogues, we observe the following:
For almost all small-size cases, the first discrete analogue DGPD1 has the least bias and lowest MSE for different parameter values.
For a large sample size, it is observed that the MSE attains its minimum values when using the second analogue, DGPD2.
The advantage of using the third analogue, DGPD3, appears when finding the credible interval for the parameter using the GE loss function, where the interval length reaches its minimum value.
5. Real Data Examples
In this section, some real data are utilized for the purpose of proving the efficiency of the discrete analogues of the GP distribution.
Some goodness-of-fit measures are used, such as the chi-square test, Kolmogorov–Smirnov (KS), Akaike information criterion (AIC), Bayesian information criterion (BIC), corrected Akaike information criterion (CAIC), and Hannan–Quinn information criterion (HQIC). As a model selection criterion, the researcher should choose the model with the minimum value from the above-mentioned measures of fit.
Data set 1: The first set of data represents a 42-day COVID-19 data set from the United States Virgin Islands, recorded between 19 April 2021 and 30 May 2021. These data comprise daily new deaths. The data are as follows: 11, 2, 3, 10, 10, 4, 12, 0, 10, 3, 5, 12, 6, 9, 13, 4, 10, 26, 0, 32, 0, 0, 13, 10, 3, 20, 5, 6, 0, 3, 18, 2, 18, 14, 24, 7, 0, 30, 16, 26, 17, 23. The data are available on the Worldometer website at [
36].
Table 4 summarizes the values of goodness-of-fit measures when comparing the DGPD with nine different discrete models, including those with one, two, and three parameters. The competitive models are discrete Marshal Olkin inverted Topp–Leone (DMOITL), which is introduced in [
37], Discrete Burr (DB), which is introduced in [
38], discrete Weibull (DW), which is introduced in [
39], discrete inverse Weibull (DIW), which is obtained in [
40], negative binomial NB in [
41], Poisson, discrete generalized exponential (DGE), which is introduced in [
42], discrete alpha power inverse Lomax (DAPIL) in [
19], and discrete Lindley (DL) in [
43].
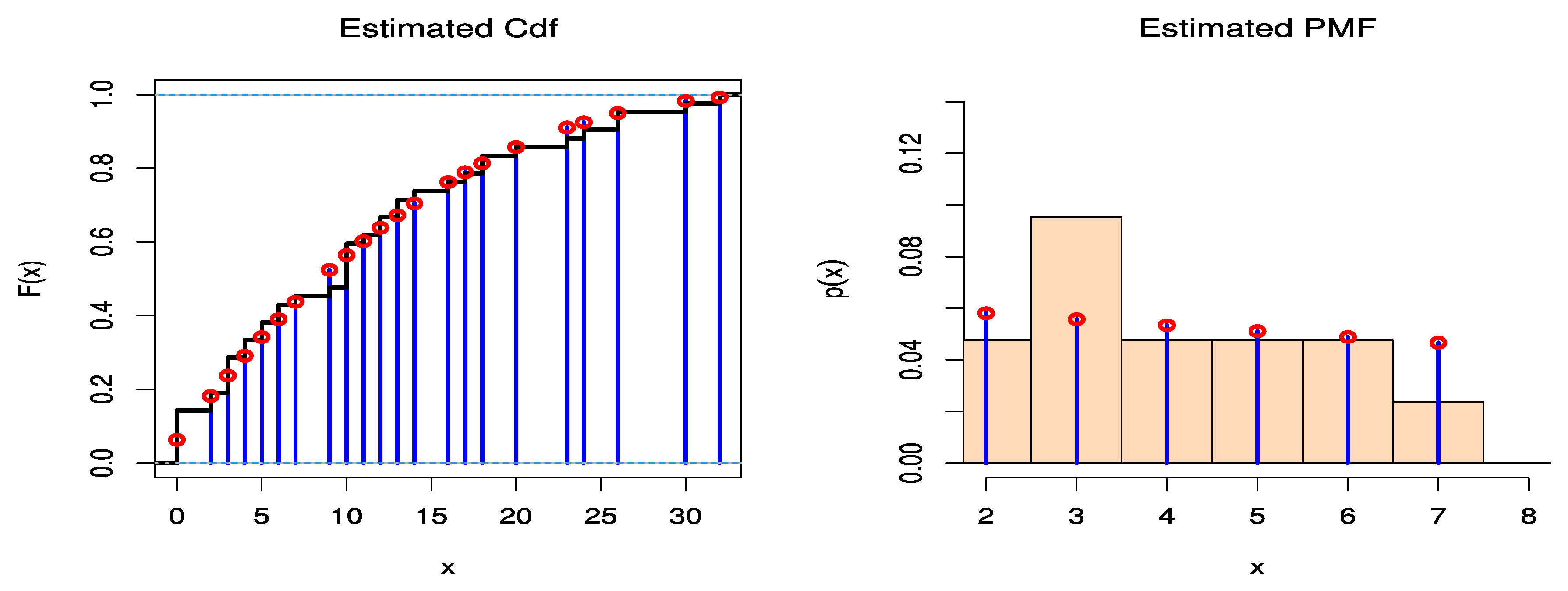
Table 4 reveals the efficiency and suitability of DGPD1 for modeling COVID-19 cases with respect to other discrete candidate models, while
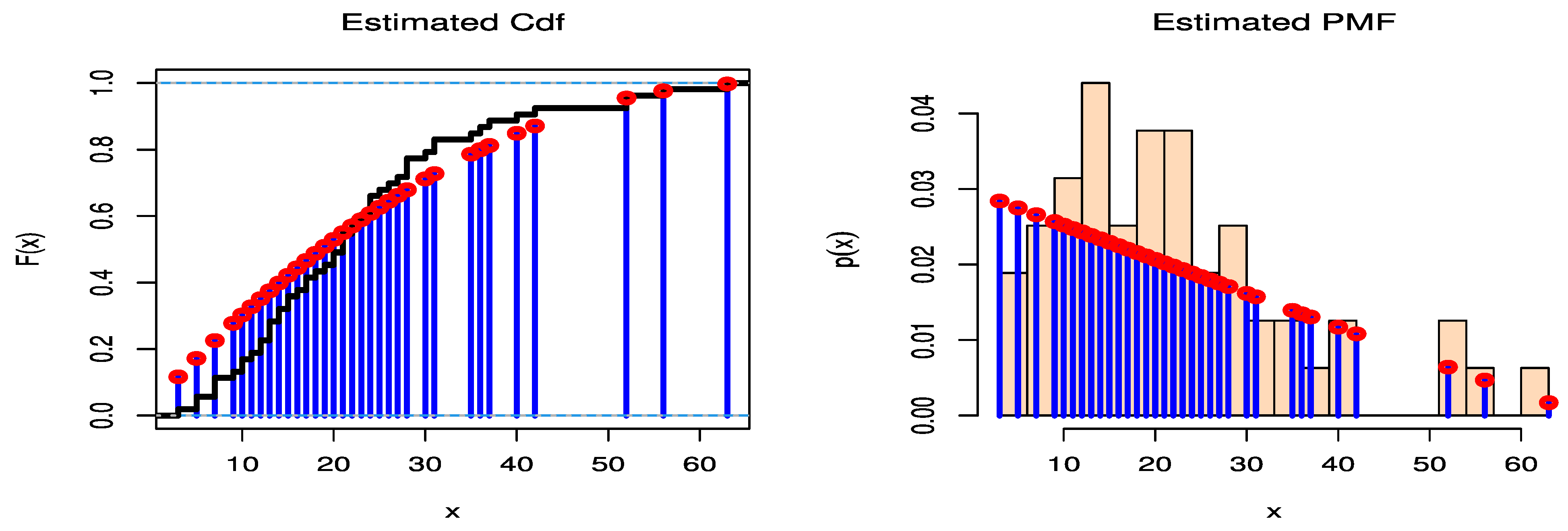
Figure 7 shows PMF and CDF for the fitted DGPD1 of data set 1. The distribution that has smaller values of key statistics, such as AIC, BIC, CAIC, HQIC, KS-test statistics, and Chi2-test statistics, is generally the one that fits the data the best. These statistics show that among all fitted models, the DGPD1 has the lowest KS-statistical, Chi2-statistical, AIC, BIC, CAIC, and HQIC values. The P-value of KS-test statistics and Chi2-test statistics are compared at the 5% level of significance. For data set 1,
Table 5 elucidates the performance of Bayesian estimation, which is marginally better than the well-known classical maximum likelihood estimation (MLE) with respect to minimizing SE.
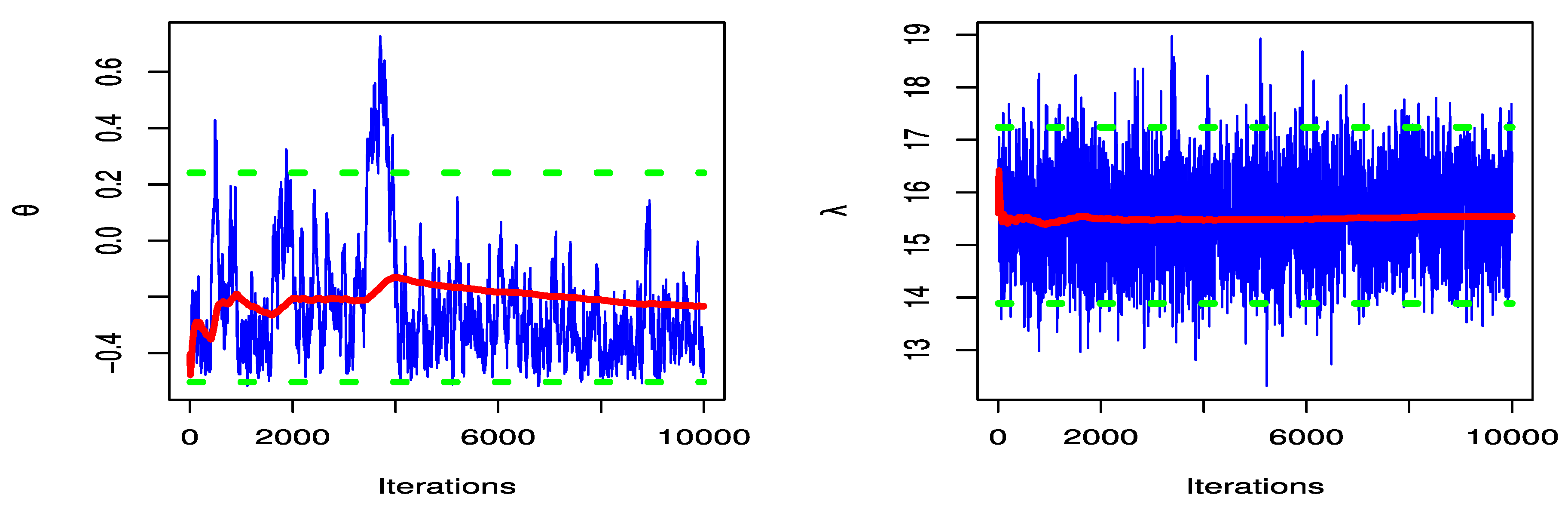
To confirm this conclusion, we should check the convergence of the MCMC results.
Figure 7 shows the trace and convergence plots of MCMC for parameter estimates of DGPD1.
Figure 8 depicts the MCMC convergence of
and
. We confirm the results of MCMC that the parameters of DGPD1 have convergence by the MH algorithm.
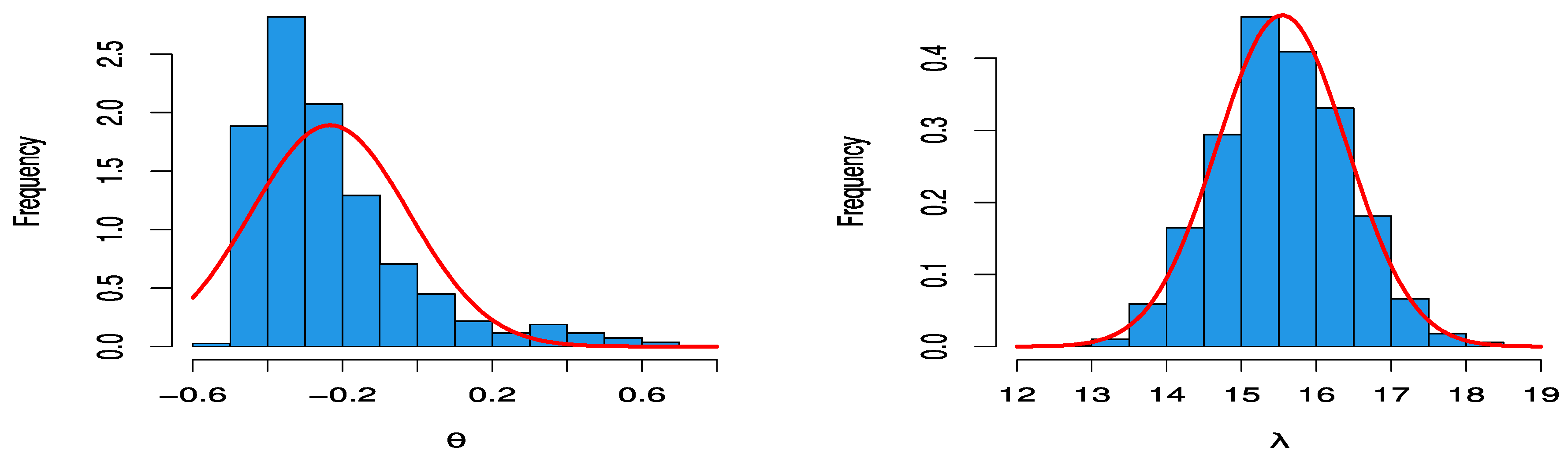
Figure 9 shows the posterior density plots of MCMC for parameter estimates of DGPD1 for data set 1, which has a normal curve, as per the proposed distribution of the MH algorithm.
Data set 2: The second set of data represents a 53-day COVID-19 data set from Italy, recorded between 13 June 2021 and 4 August 2021. These data comprise daily new deaths. The data are as follows: 52, 26, 36, 63, 52, 37, 35, 28, 17, 21, 31, 30, 10, 56, 40, 14, 28, 42, 24, 21, 28, 22, 12, 31, 24, 14, 13, 25, 12, 7, 13, 20, 23, 9, 11, 13, 3, 7, 10, 21, 15, 17, 5, 7, 22, 24, 15, 19, 18, 16,5, 20, 27. The data are available on the Worldometer website at [
36].
Figure 10 shows PMF and CDF for the fitted DGP of data set 2. The SE values of the parameters of DGP are shown in
Table 6 to compare between MLE and Bayesian estimation methods for data set 2. From the results of SE in
Table 6, we note that Bayesian estimation is a superior estimation method for data set 2 compared to MLE.
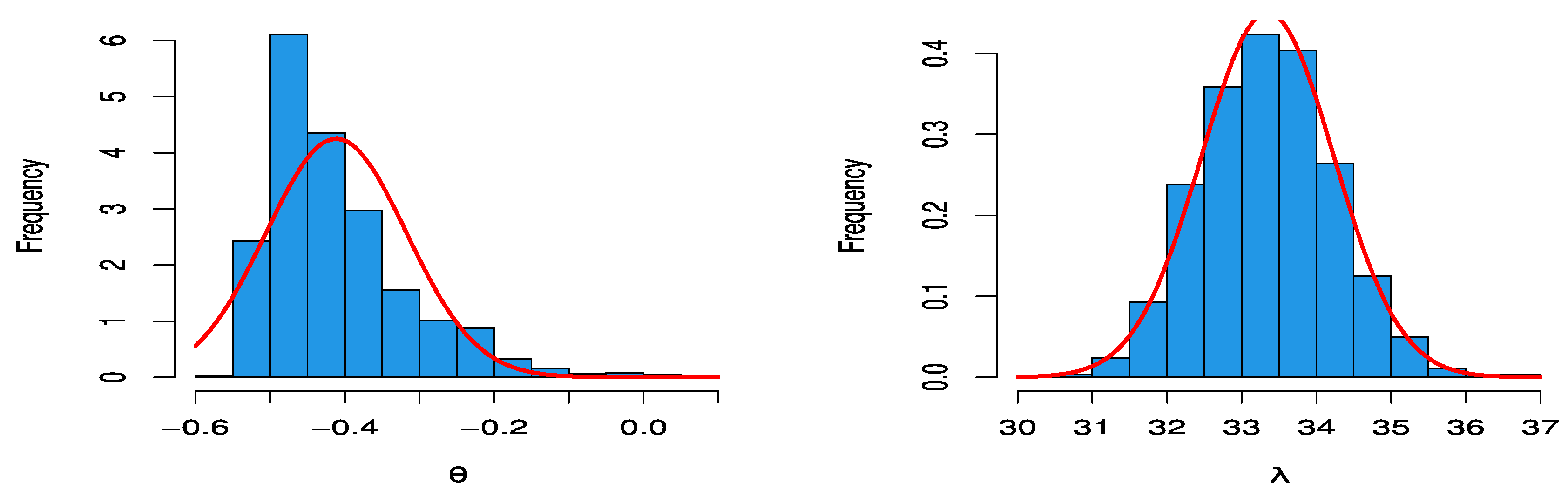
Figure 11 shows that the posterior density plots of MCMC for parameter estimates of DGPD1 for data set 2 have a normal curve, as per the proposed distribution of the MH algorithm. To confirm this conclusion, we should check the convergence of the MCMC results.
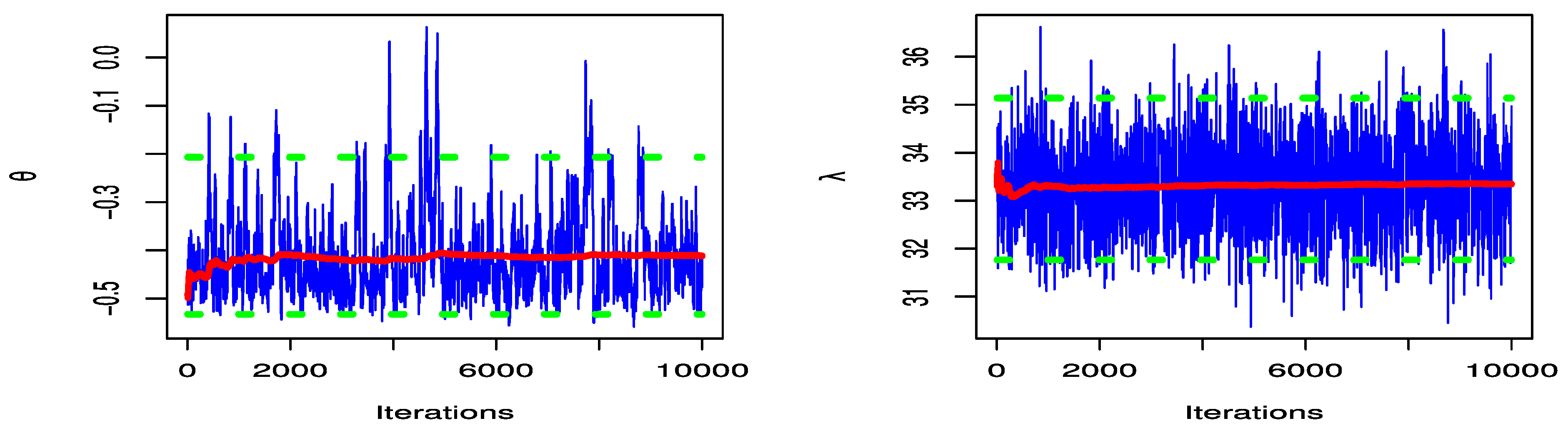
Figure 12 shows the trace and convergence plots of MCMC for parameter estimates of DGPD1 for data set 2. In
Figure 12, we confirm that the results of MCMC for the parameters of DGPD1 have convergence by the MH algorithm.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}