
A Local Density-Based Abnormal Case Removal Method for Industrial Operational Optimization under the CBR Framework


Abstract
:1. Introduction
- (1)
- The reason why historical cases in low-density areas should not be included in the case reuse step is analyzed from the perspective of safety and reliability requirements in industrial operational optimization problems.
- (2)
- A novel abnormal case removal method, which could effectively remove the abnormal cases before case reuse, is proposed on the basis of the Local Outlier Factor (LOF), and properly integrated into the case retrieval step.
- (3)
- The effectiveness and superiority of the newly proposed local density-based abnormal case removal method is verified by a numerical optimization case study and an industrial operational optimization case study.
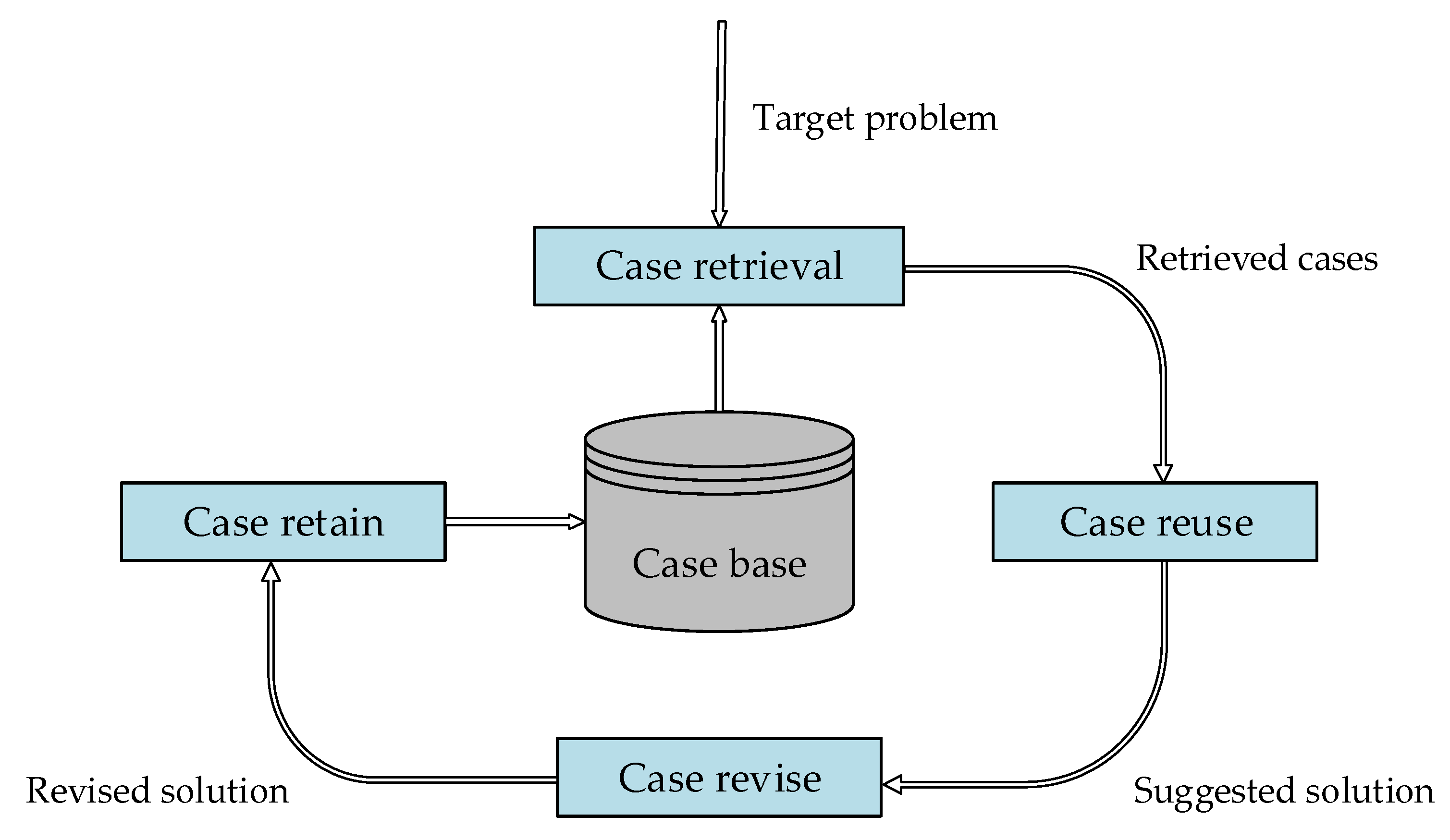
2. Preliminaries
3. Methods
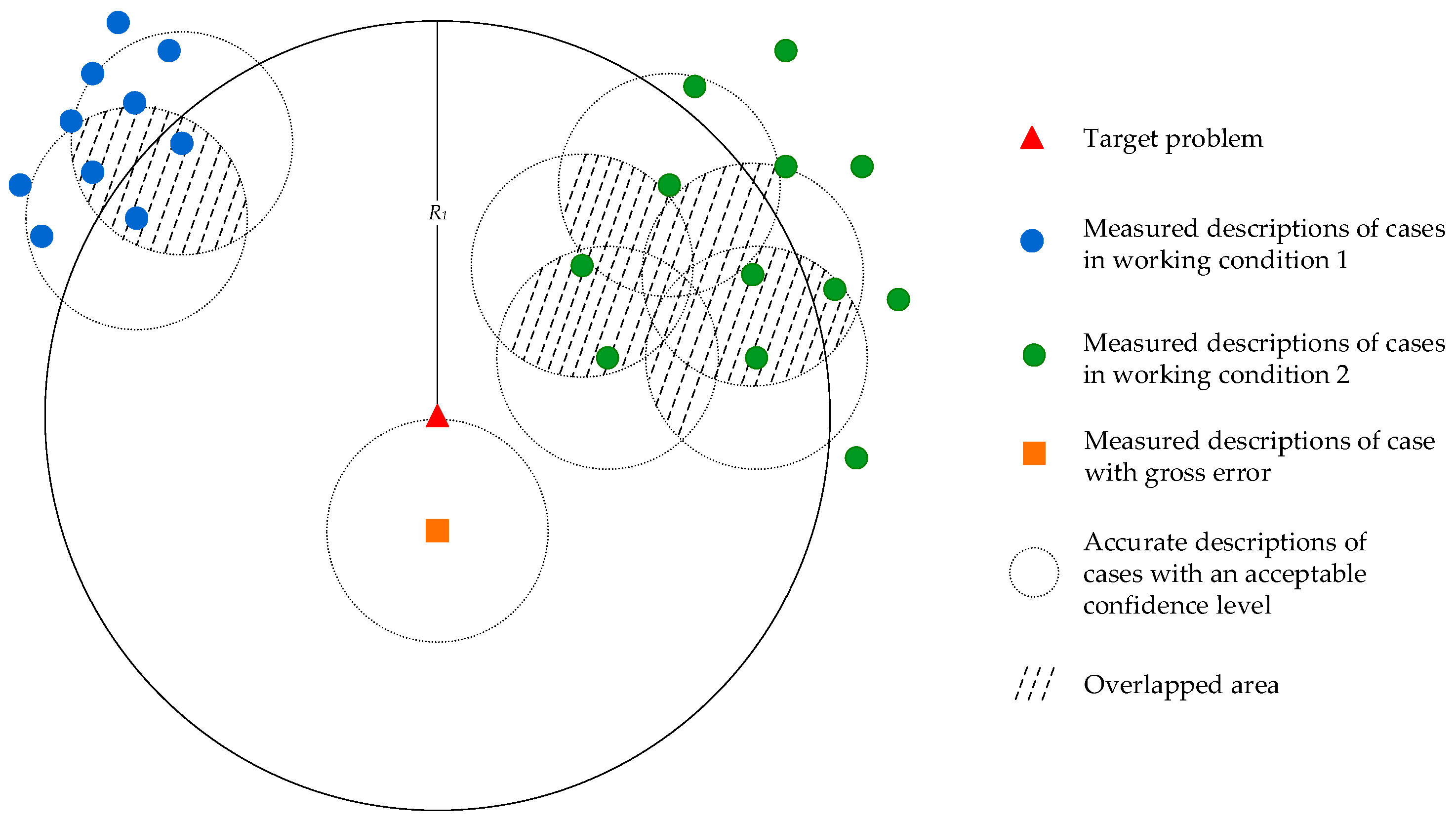
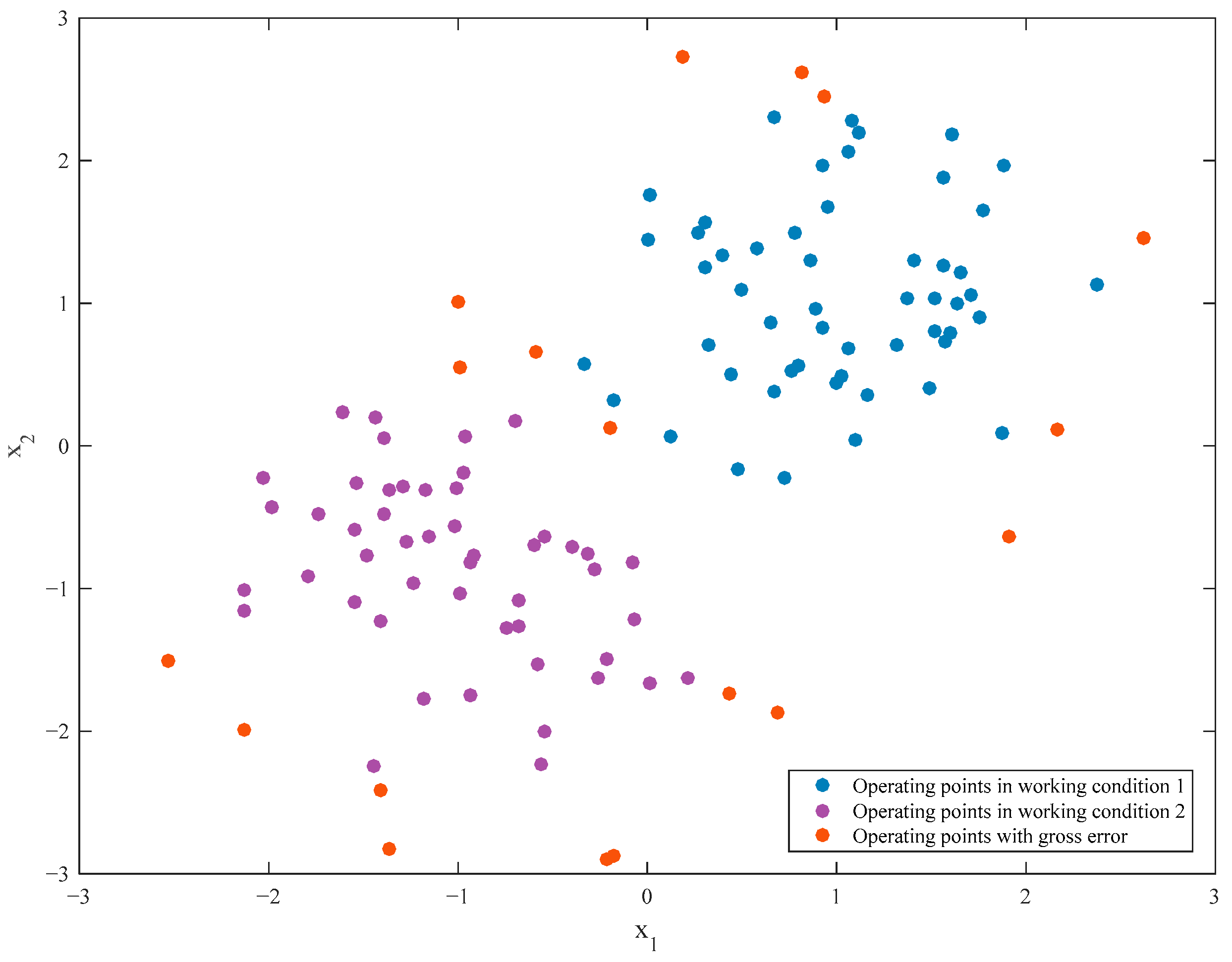
3.1. Analysis of Case Retrieval in Industrial Operational Optimization
- (a)
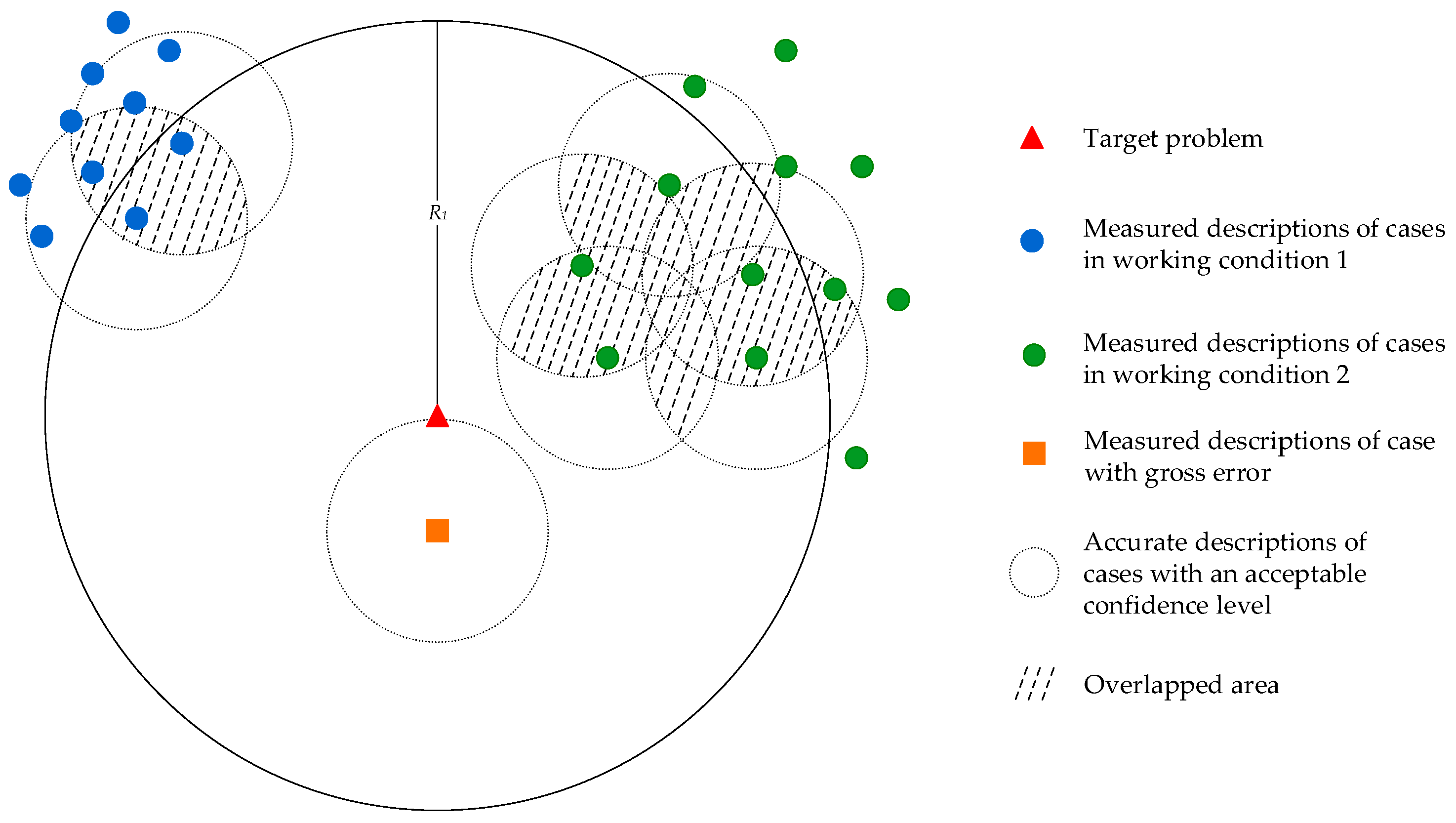
- Accuracy of case retrieval would be influenced by the measuring error
- (b)
- Accuracy of case retrieval would be influenced by the multiple working conditions
3.2. Local Density-Based Abnormal Case Removal
| Algorithm 1: Local density-based abnormal case removal |
| Input: retrieved cases; optimal parameter , |
| Output: The retrieved cases without abnormal cases |
| 1 Calculate the local density of every retrieved case according to Equation (6) |
| 2 Calculate the LOF of every retrieved case according to Equation (5) |
| 3 Calculate the threshold of the retrieved cases according to Equations (7) and (8) |
| 4 Remove the cases whose LOF are higher than the threshold |
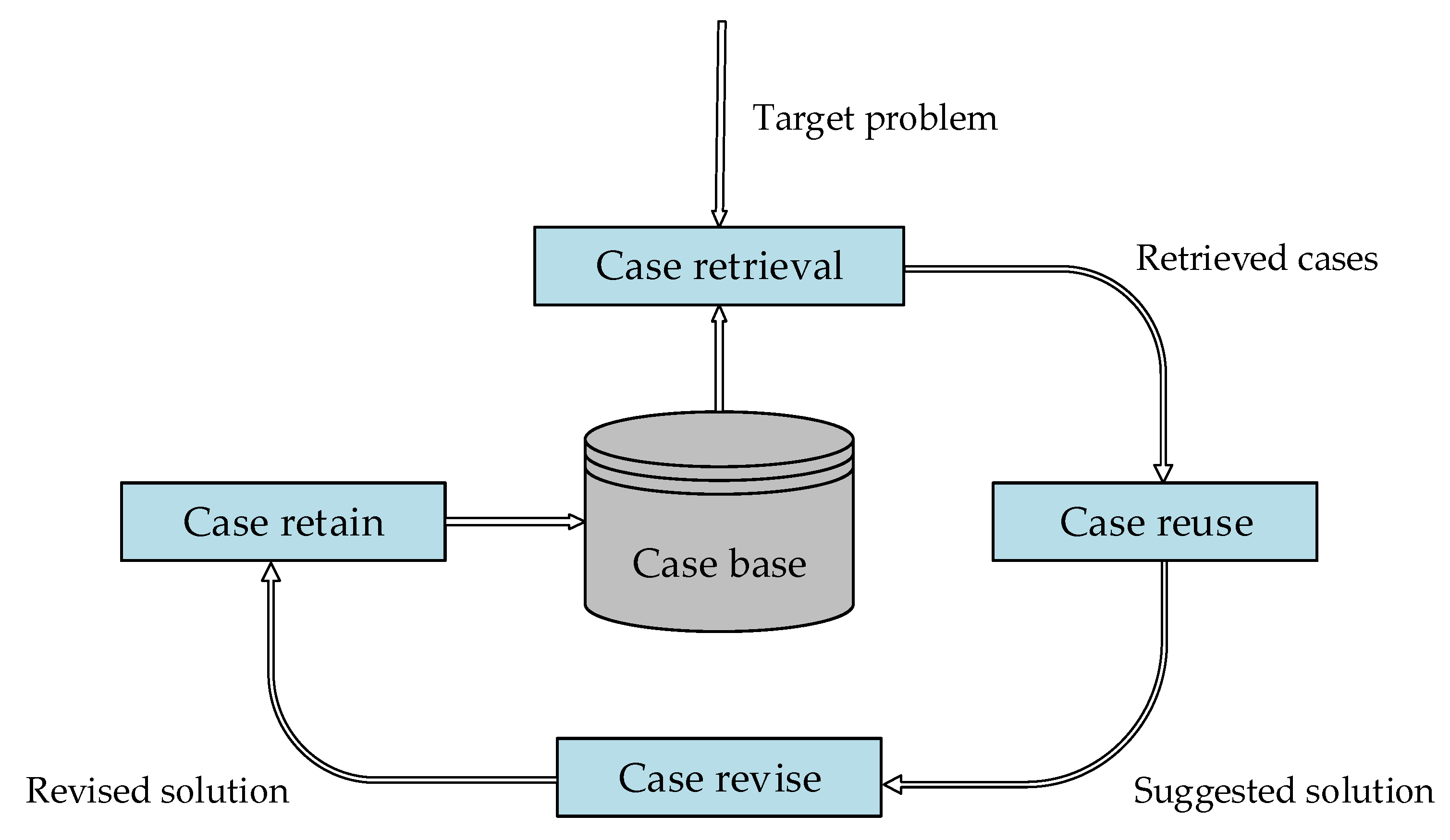
- Step 1:
- construct the case base with history data;
- Step 2:
- for a target problem, select most similar cases from the case base and construct the original retrieved cases ;
- Step 3:
- employ the local density-based abnormal case removal algorithm to remove wrongly retrieved cases;
- Step 4:
- acquire the suggested solution for the target problem according to Equation (1);
- Step 5:
- revise the suggested solution, if necessary;
- Step 6:
- store it in the case base after the target problem is solved.
4. Case Studies
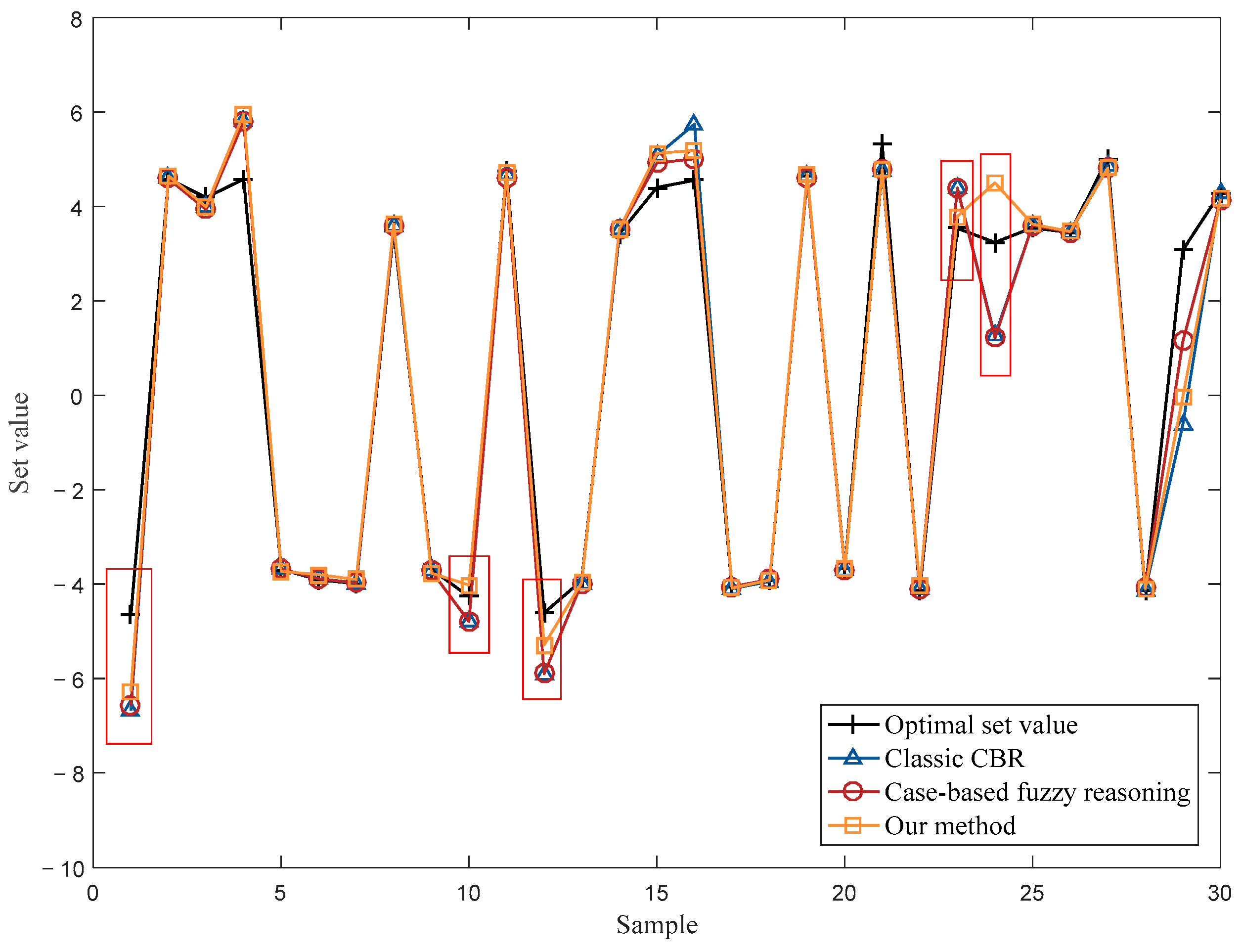
4.1. Numerical Simulation
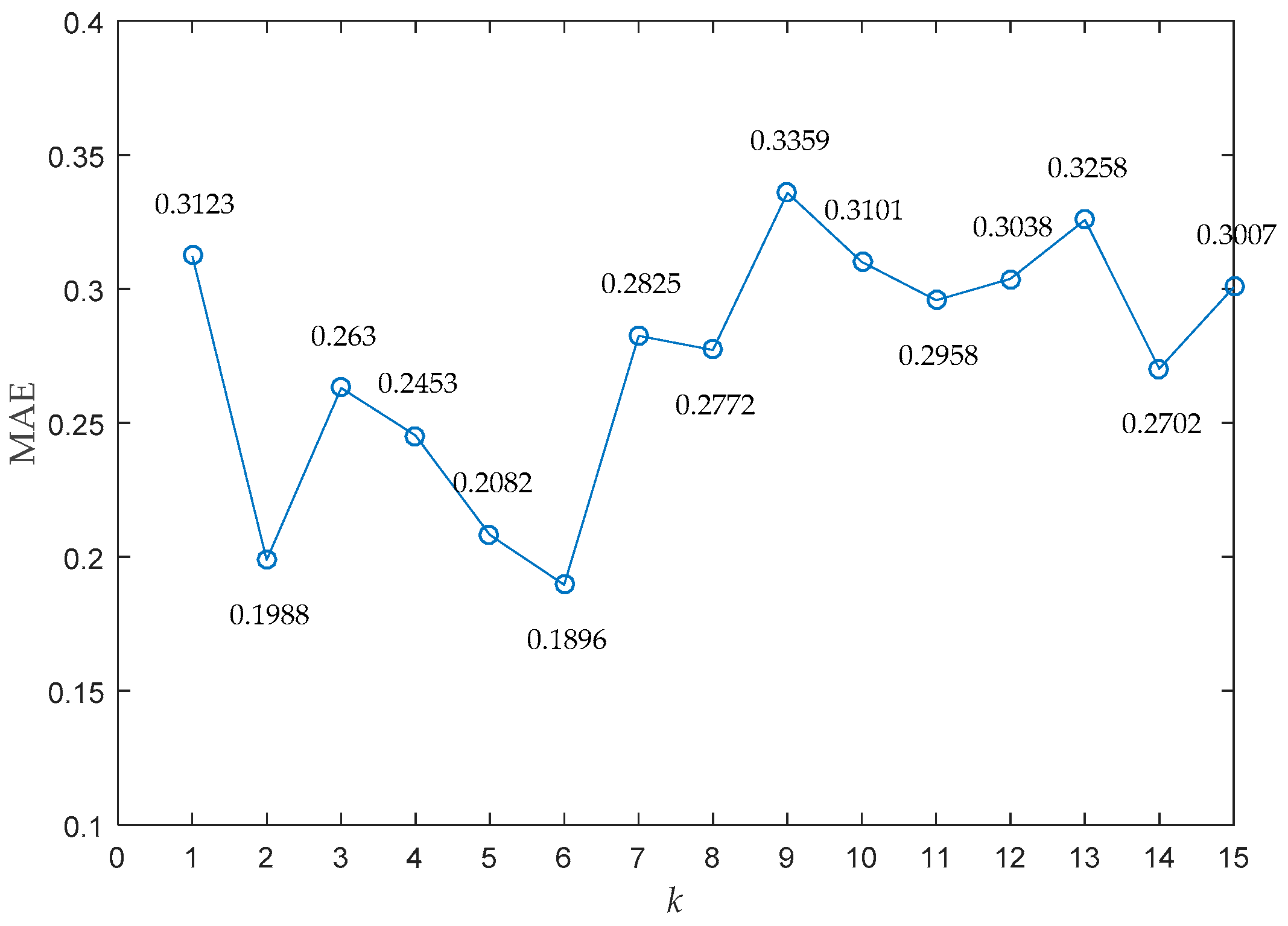
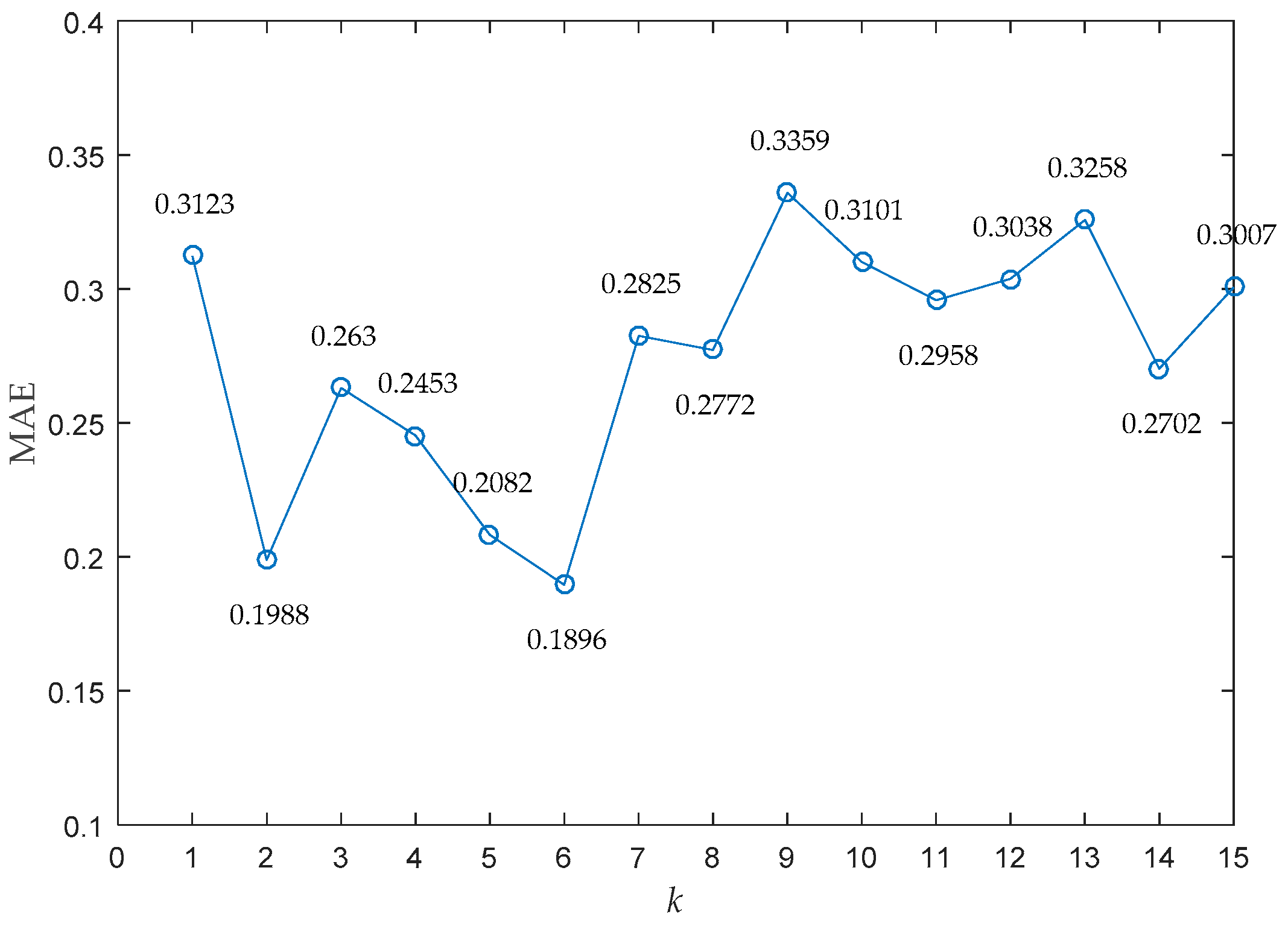
- (1)
- Supposing the parameter was fixed as a constant, if the selected parameter was too small, it would result in a lower threshold and more normal cases would be removed by mistake in the retrieved cases. This would increase the MAE.
- (2)
- Supposing the parameter was fixed as a constant, if the selected parameter was too big, it would result in a larger threshold and more abnormal cases would be preserved in the retrieved cases. This would increase the MAE.
- (3)
- Supposing the parameter was fixed as a constant, if the selected parameter was too small, fewer nearest neighbors would be included in the calculation of LOF. This would make the LOF more vulnerable to uncertainty so as to increase the MAE.
- (4)
- Supposing the parameter was fixed as a constant, if the selected parameter was too big, more nearest neighbors would be included in the calculation of LOF. This would reduce the distinguish ability of LOF so as to increase the MAE.
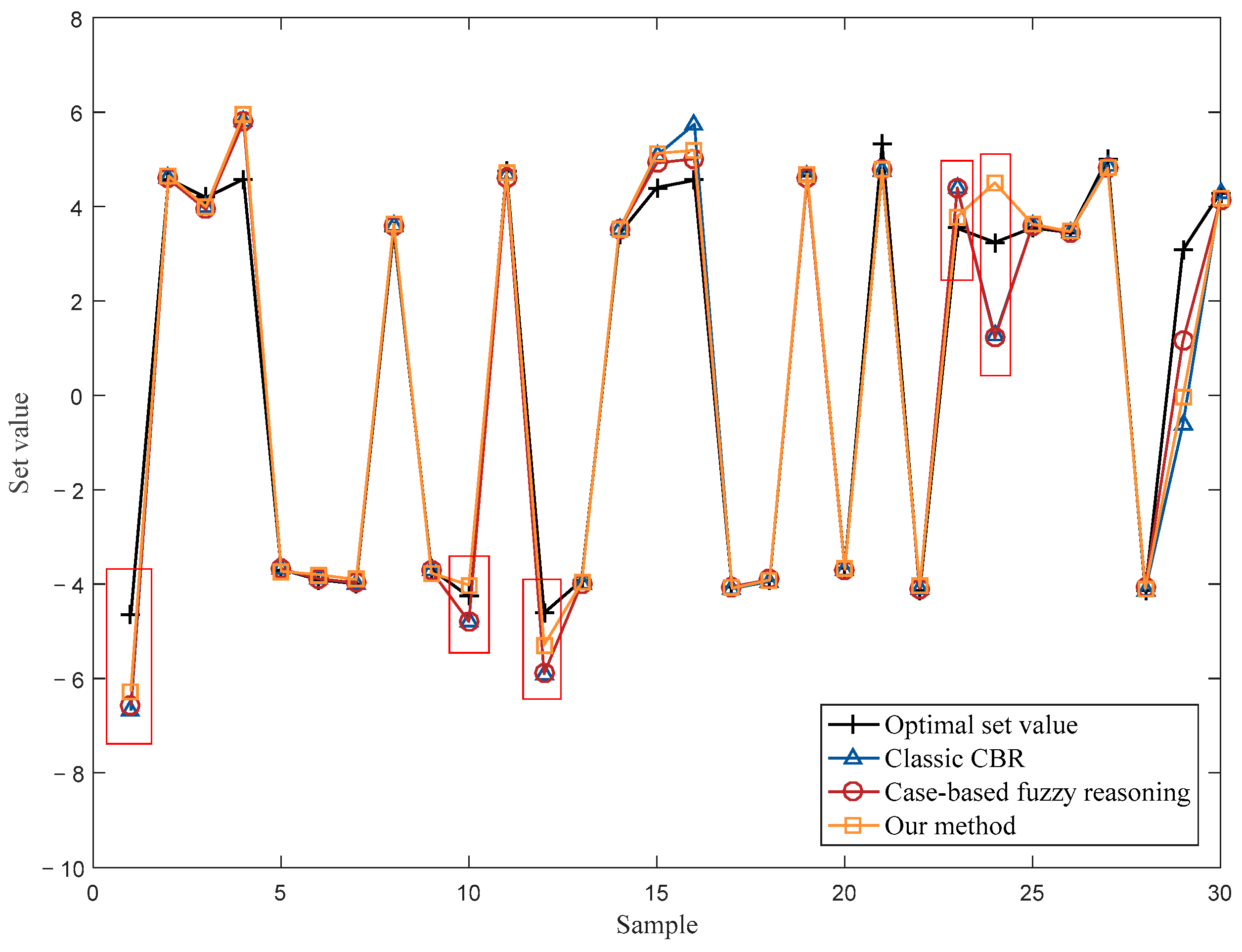
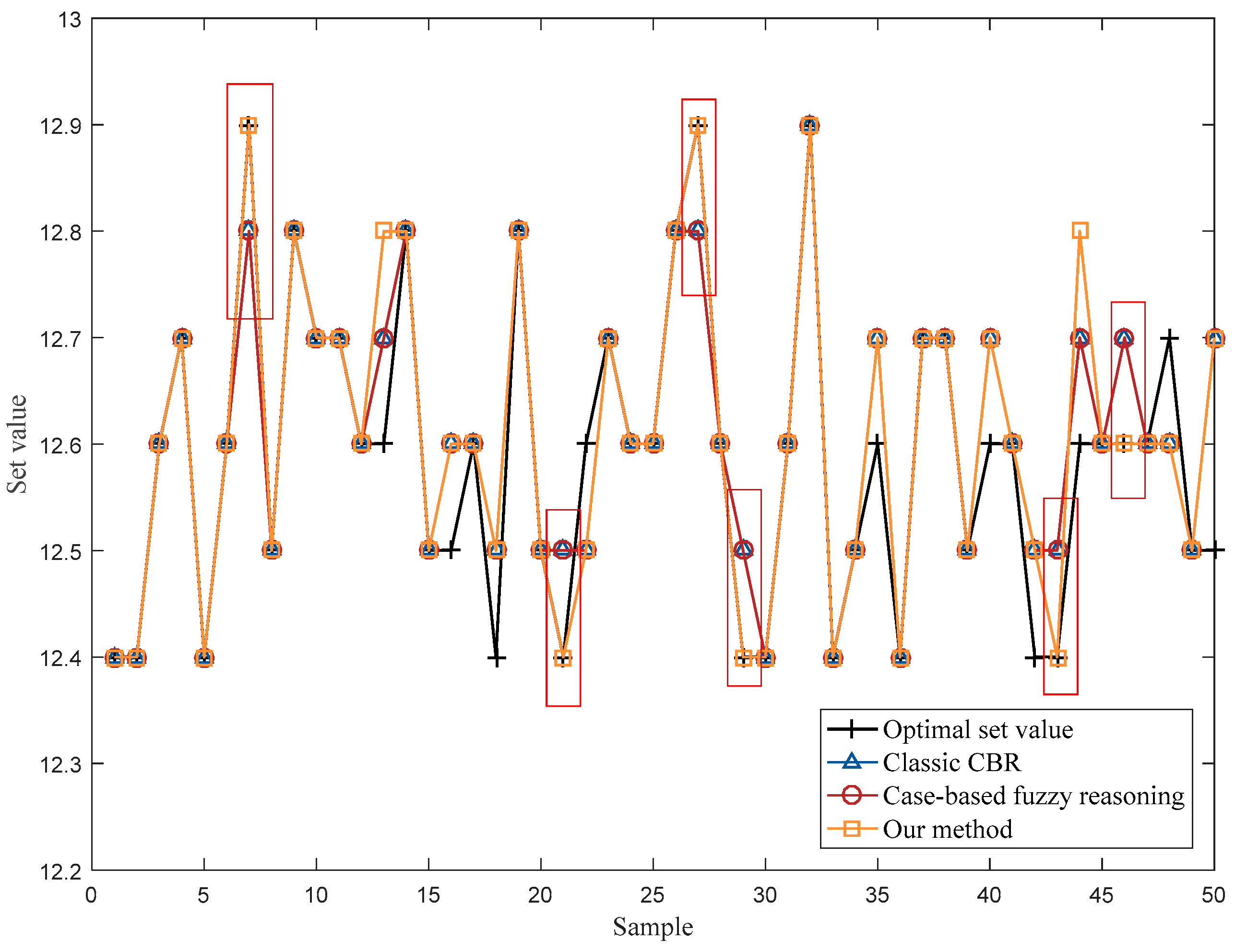
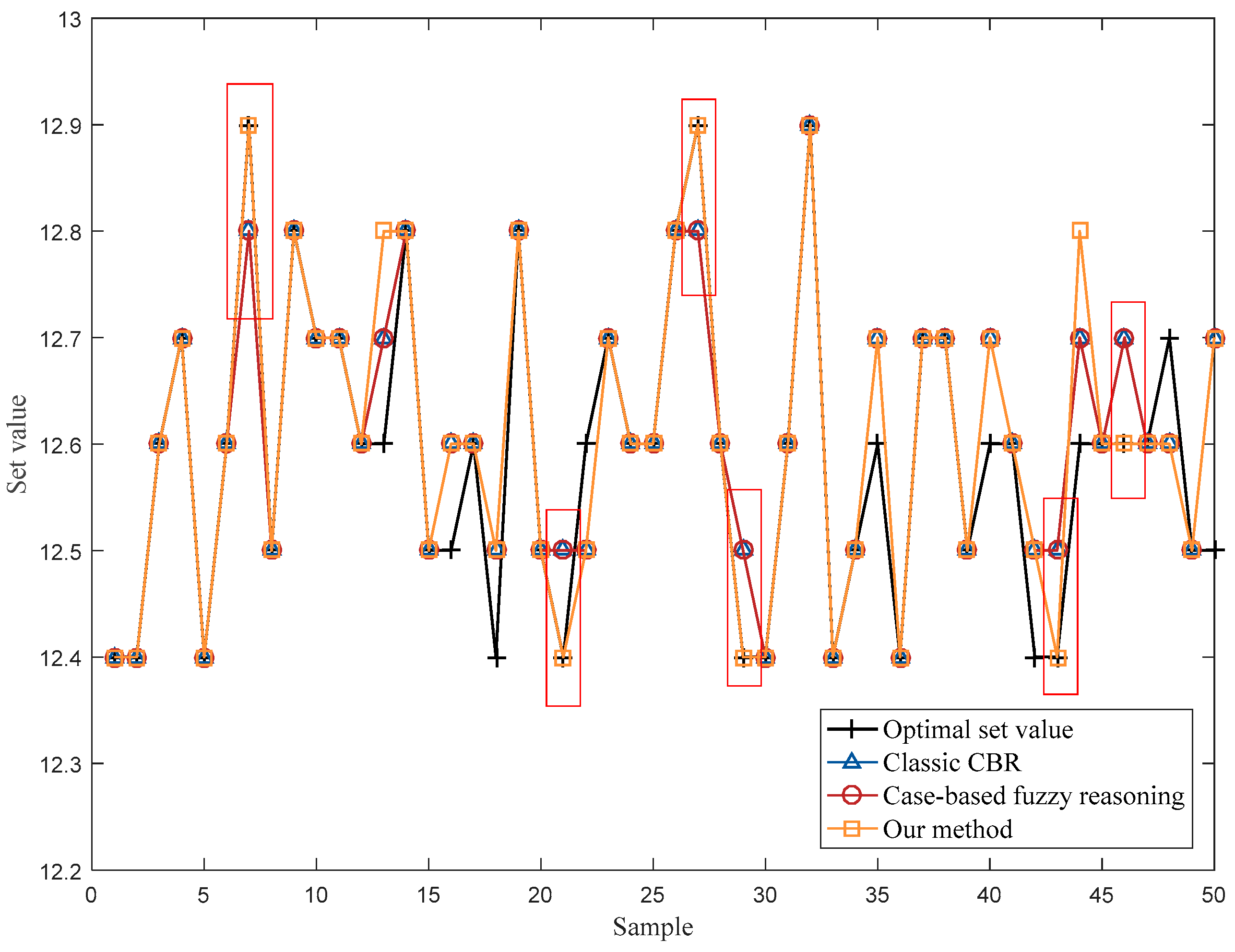
4.2. Operational Optimization of an Industrial Cut-Made Process of Cigarette Production
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, H.T.; Chai, Z.; Dogru, O.; Jiang, B.; Huang, B. Data-Driven Fault Detection for Dynamic Systems with Performance Degradation: A Unified Transfer Learning Framework. IEEE Trans. Instrum. Meas. 2020, 70, 3504712. [Google Scholar] [CrossRef]
- Sun, B.; Yang, C.H.; Zhu, H.Q.; Li, Y.G.; Gui, W.H. Modeling, Optimization, and Control of Solution Purification Process in Zinc Hydrometallurgy. IEEE/CAA J. Autom. Sin. 2018, 5, 564–576. [Google Scholar] [CrossRef]
- Xue, Y.F.; Wang, Y.L.; Sun, B.; Peng, X.Y. An Efficient Computational Cost Reduction Strategy for the Population-Based Intelligent Optimization of Nonlinear Dynamical Systems. IEEE Trans. Ind. Inf. 2021, 17, 6624–6633. [Google Scholar] [CrossRef]
- Xie, R.; Liu, W.H.; Chen, M.Y.; Shi, Y.J. A Robust Operation Method with Advanced Adiabatic Compressed Air Energy Storage for Integrated Energy System under Failure Conditions. Machines 2022, 10, 51. [Google Scholar] [CrossRef]
- Chen, Q.D.; Ding, J.L.; Chai, T.Y.; Pan, Q.K. Evolutionary Optimization Under Uncertainty: The Strategies to Handle Varied Constraints for Fluid Catalytic Cracking Operation. IEEE Trans. Cybern. 2022, 52, 2249–2262. [Google Scholar] [CrossRef]
- Yang, C.E.; Ding, J.L.; Jin, Y.C.; Wang, C.Z.; Chai, T.Y. Multitasking Multiobjective Evolutionary Operational Indices Optimization of Beneficiation Processes. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1046–1057. [Google Scholar] [CrossRef]
- Boggs, P.T.; Tolle, J.W. Sequential Quadratic Programming for Large-Scale Nonlinear Optimization. J. Comput. Appl. Math. 2000, 124, 123–137. [Google Scholar] [CrossRef]
- Liu, Q.Y.; Zha, Y.W.; Liu, T.; Lu, C. Research on Adaptive Control of Air-Borne Bolting Rigs Based on Genetic Algorithm Optimization. Machines 2021, 9, 240. [Google Scholar] [CrossRef]
- Zheng, X.Y.; Su, X.Y. Sliding Mode Control of Electro-Hydraulic Servo System Based on Optimization of Quantum Particle Swarm Algorithm. Machines 2021, 9, 283. [Google Scholar] [CrossRef]
- Chen, H.T.; Chai, Z.; Dogru, O.; Jiang, B.; Huang, B. Data-Driven Designs of Fault Detection Systems via Neural Network-Aided Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Chai, T.Y.; Ding, J.L.; Wang, H. Multi-Objective Hybrid Intelligent Optimization of Operational Indices for Industrial Processes and Application. IFAC Proc. Vol. 2011, 44, 10517–10522. [Google Scholar] [CrossRef] [Green Version]
- Ran, G.T.; Liu, J.; Li, C.J.; Lam, H.-K.; Li, D.Y.; Chen, H.T. Fuzzy-Model-Based Asynchronous Fault Detection for Markov Jump Systems with Partially Unknown Transition Probabilities: An Adaptive Event-Triggered Approach. IEEE Trans. Fuzzy Syst. 2022. [Google Scholar] [CrossRef]
- Pan, Z.F.; Chen, H.T.; Wang, Y.L.; Huang, B.; Gui, W.H. A New Perspective on AE- and VAE-Based Process Monitoring. TechRxiv 2022. [Google Scholar] [CrossRef]
- Wang, Y.J.; Li, H.G. A Novel Intelligent Modeling Framework Integrating Convolutional Neural Network with An Adaptive Time-Series Window and Its Application to Industrial Process Operational Optimization. Chemom. Intell. Lab. Syst. 2018, 179, 64–72. [Google Scholar] [CrossRef]
- Ding, J.; Modares, H.; Chai, T.; Lewis, F.L. Data-Based Multiobjective Plant-Wide Performance Optimization of Industrial Processes Under Dynamic Environments. IEEE Trans. Ind. Inf. 2016, 12, 454–465. [Google Scholar] [CrossRef]
- Li, Y.N.; Wang, X.L.; Liu, Z.J.; Bai, X.W.; Tan, J. A Data-Based Optimal Setting Method for the Coking Flue Gas Denitration Process. Can. J. Chem. Eng. 2018, 97, 876–887. [Google Scholar] [CrossRef]
- Ding, J.L.; Chai, T.Y.; Wang, H.F.; Wang, J.W.; Zheng, X.P. An Intelligent Factory-Wide Optimal Operation System for Continuous Production Process. Enterp. Inf. Syst. 2016, 10, 286–302. [Google Scholar] [CrossRef]
- Zhang, Z.P.; Chen, D.J.; Feng, Y.Z.; Yuan, Z.H.; Chen, B.Z.; Qin, W.Z.; Zou, S.W.; Qin, S.; Han, J.F. A Strategy for Enhancing the Operational Agility of Petroleum Refinery Plant using Case Based Fuzzy Reasoning Method. Comput. Chem. Eng. 2018, 111, 27–36. [Google Scholar] [CrossRef]
- Aamodt, A. Case-Based Reasoning: Foundational Issues, Methodological Variations, and System Approaches Aicom—Artificial Intelligence Communications. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Zhai, Z.; Ortega, J.; Castillejo, P.; Beltran, V. A Triangular Similarity Measure for Case Retrieval in CBR and Its Application to an Agricultural Decision Support System. Sensors 2019, 19, 4605. [Google Scholar] [CrossRef] [Green Version]
- Fei, L.G.; Feng, Y.Q. A Novel Retrieval Strategy for Case-Based Reasoning Based on Attitudinal Choquet Integral. Eng. Appl. Artif. Intell. 2020, 94, 103791. [Google Scholar] [CrossRef]
- Zhu, G.N.; Hu, J.; Qi, J.; Ma, J.; Peng, Y.H. An Integrated Feature Selection and Cluster Analysis Techniques for Case-Based Reasoning. Eng. Appl. Artif. Intell. 2015, 39, 14–22. [Google Scholar] [CrossRef]
- López, B. Case-Based Reasoning: A Concise Introduction. In Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan Claypool Publishers: San Rafael, CA, USA, 2013; Volume 7, pp. 1–103. [Google Scholar]
- Ahn, J.; Park, M.; Lee, H.S.; Ahn, S.J.; Ji, S.H.; Song, K.; Son, B.S. Covariance Effect Analysis of Similarity Measurement Methods for Early Construction Cost Estimation using Case-Based Reasoning. Autom. Constr. 2017, 81, 254–266. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Tsai, H.C.; Chiu, Y.H. Fuzzy Case-Based Reasoning for Coping with Construction Disputes. Expert Syst. Appl. 2009, 36, 4106–4113. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. Gaussian Case-Based Reasoning for Business Failure Prediction with Empirical Data in China. Inf. Sci. 2009, 179, 89–108. [Google Scholar] [CrossRef]
- Pan, D.; Jiang, Z.H.; Chen, Z.P.; Gui, W.H.; Xie, Y.F.; Yang, C.H. Temperature Measurement and Compensation Method of Blast Furnace Molten Iron Based on Infrared Computer Vision. IEEE Trans. Instrum. Meas. 2019, 68, 3576–3588. [Google Scholar] [CrossRef]
- Liang, S.; Zeng, J. Fault Detection for Complex System under Multi-Operation Conditions Based on Correlation Analysis and Improved Similarity. Symmetry 2020, 12, 1836. [Google Scholar] [CrossRef]
- Chergui, O.; Begdouri, A.; Groux-Leclet, D. Integrating a Bayesian Semantic Similarity Approach into CBR for Knowledge Reuse in Community Question Answering. Knowl. Based Syst. 2019, 185, 104919. [Google Scholar] [CrossRef]
- Smyth, B.; Mckenna, E. Competence Guided Incremental Footprint-Based Retrieval. Knowl. Based Syst. 2001, 14, 155–161. [Google Scholar] [CrossRef]
- Zhang, Q.; Shi, C.Y.; Niu, Z.D.; Cao, L.B. HCBC: A Hierarchical Case-Based Classifier Integrated with Conceptual Clustering. IEEE Trans. Knowl. Data Eng. 2019, 31, 152–165. [Google Scholar] [CrossRef]
- Zhong, S.S.; Xie, X.L.; Lin, L. Two-Layer Random Forests Model For Case Reuse In Case-Based Reasoning. Expert Syst. Appl. 2015, 42, 9412–9425. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Formula |
|---|---|
| Euclidean Distance | |
| Mahalanobis Distance | |
| Cosine angle Distance | |
| Manhattan Distance | |
| Chebyshev Distance |
| MAE | |||||
|---|---|---|---|---|---|
| 0.1858 | 0.2378 | 0.1937 | 0.1984 | 0.2070 | |
| 0.1872 | 0.2380 | 0.1622 | 0.2001 | 0.1948 | |
| 0.1870 | 0.2078 | 0.1651 | 0.1675 | 0.1526 | |
| 0.1742 | 0.1967 | 0.1671 | 0.1475 | 0.1521 | |
| 0.1741 | 0.1930 | 0.1956 | 0.1457 | 0.1470 | |
| 0.1647 | 0.2032 | 0.1950 | 0.1458 | 0.1478 | |
| 0.1935 | 0.2016 | 0.1882 | 0.1541 | 0.1478 | |
| 0.1930 | 0.2018 | 0.1873 | 0.1893 | 0.1602 | |
| 0.1859 | 0.1840 | 0.1840 | 0.1877 | 0.1877 | |
| 0.1797 | 0.1896 | 0.1896 | 0.1896 | 0.1896 | |
| 0.1896 | 0.1896 | 0.1896 | 0.1896 | 0.1896 |
| Case Description | Case Solution |
|---|---|
| Average ambient temperature at the drying machine | The optimal set value of leaf-silk drying machine in production line A |
| Average ambient moisture at the drying machine | |
| Average leaf-silk moisture content of production line B | |
| Average leaf-silk moisture content of production line C | |
| Tobacco stems moisture content | |
| Expanded leaf-silk moisture content | |
| Blending time | |
| Average ambient temperature at spicing | |
| Average ambient moisture at spicing |
| Case Description | Optimized Parameters |
|---|---|
| Average ambient temperature at the drying machine | 0.4317 |
| Average ambient moisture at the drying machine | 0.3811 |
| Average leaf-silk moisture content of production line B | 0.5302 |
| Average leaf-silk moisture content of production line C | 0.3529 |
| Tobacco stems moisture content | 0.4173 |
| Expanded leaf-silk moisture content | 0.5513 |
| Blending time | 0.5556 |
| Average ambient temperature at spicing | 0.4098 |
| Average ambient moisture at spicing | 0.4885 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, X.; Wang, Y.; Guan, L.; Xue, Y. A Local Density-Based Abnormal Case Removal Method for Industrial Operational Optimization under the CBR Framework. Machines 2022, 10, 471. https://doi.org/10.3390/machines10060471
Peng X, Wang Y, Guan L, Xue Y. A Local Density-Based Abnormal Case Removal Method for Industrial Operational Optimization under the CBR Framework. Machines. 2022; 10(6):471. https://doi.org/10.3390/machines10060471
Chicago/Turabian StylePeng, Xiangyu, Yalin Wang, Lin Guan, and Yongfei Xue. 2022. "A Local Density-Based Abnormal Case Removal Method for Industrial Operational Optimization under the CBR Framework" Machines 10, no. 6: 471. https://doi.org/10.3390/machines10060471
APA StylePeng, X., Wang, Y., Guan, L., & Xue, Y. (2022). A Local Density-Based Abnormal Case Removal Method for Industrial Operational Optimization under the CBR Framework. Machines, 10(6), 471. https://doi.org/10.3390/machines10060471