

Detection of Thymoma Disease Using mRMR Feature Selection and Transformer Models

Abstract
:
1. Introduction
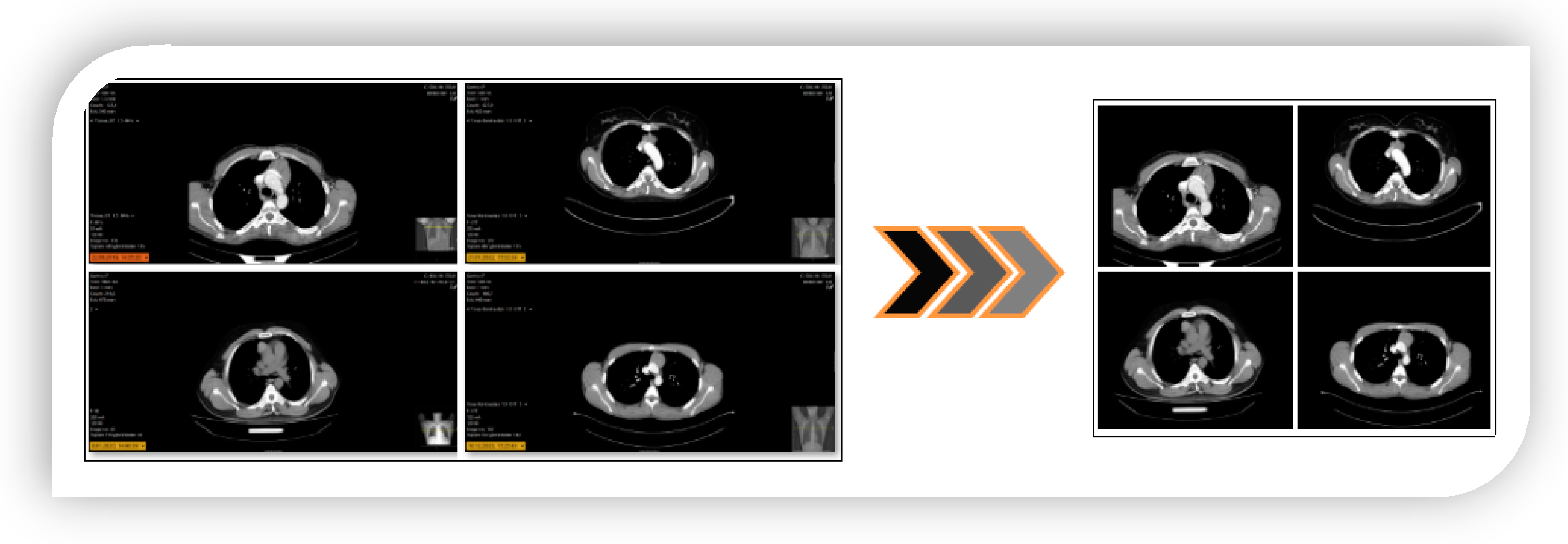
- Since the images were taken from the hospital environment, a region of interest (ROI) analysis was performed to eliminate unnecessary regions in the image. Thus, the approach aims to be more efficient when transferring images from real-time hospital environments to transformer models.
- The models were trained using transformers, a new-generation technology that has recently gained a reputation for producing more effective results than traditional deep learning models.
- Feature fusion between transformer models created feature sets with more efficient features, contributing to performance.
- The mRMR method was used to improve performance with fewer features but more efficient features by determining the most efficient combined feature set. This saves time and reduces hardware costs.
- An approach was proposed that can make objective decisions by avoiding possible disagreements between physicians and radiologists in the diagnosis of thymoma disease.
- A system was provided that provides feedback to many patients simultaneously in a short time using the proposed approach.
2. Background
2.1. Dataset
2.2. Preprocessing Step
2.3. SVM Classifier
2.4. Feature Selection Method: mRMR
2.5. Transformer Models
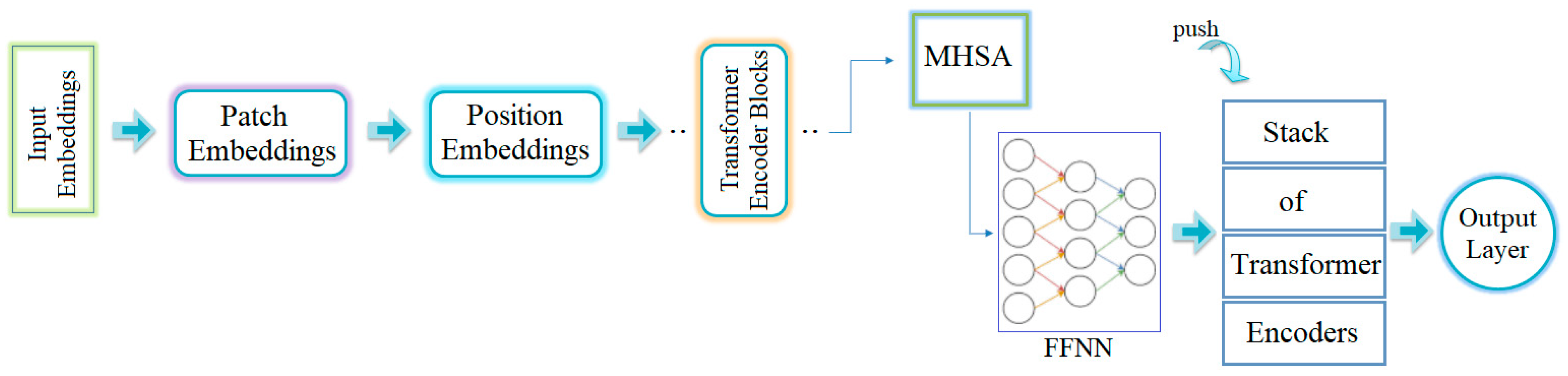
- The first stage is input embedding: This stage deals with the reception of image data. The images are divided into patches for processing. First, each image is segmented into a sequence of two-dimensional patches. These patches can have specific resolutions, such as 16 × 16 or 24 × 24 pixels.
- The next stage is patch embedding. During this stage, each patch is processed through an embedding layer. At the end of this stage, each patch is transformed into a vector representation.
- The third stage is position embedding. At this point, the order of the patches is determined and position embeddings are incorporated accordingly. This allows the model to easily determine the position of each patch.
- The fourth stage contains the transformer encoder blocks. The ViT architecture includes several transformer encoder blocks, each of which consists of two main components. The first component is Multi-head Self-Attention (MHSA), which is responsible for querying and modeling correlations between image patches. The second component is a feed-forward neural network (FFNN), which extracts and processes features from each patch and then applies the necessary transformations for the next stage.
- The fifth stage is the transformer encoder stack. During this phase, multiple encoder blocks are stacked, allowing for deeper feature extraction and learning of more complex correlations.
- The final stage is the output layer, which is common to all models. This layer aggregates the data processed by the transformer encoder stack. It is typically used for classification tasks and serves as the final layer in CNN models. For classification purposes in ViT models, activation functions such as softmax are commonly used.
- Deit3 base patch16-224: DeiT (Data-efficient Image Transformer) was developed to improve the efficiency of transform models in image processing. It is a type of DeiT3 series, known as the third generation version of a ViT-based model. The model receives input images with a resolution of 224 × 224 pixels. The images are divided into small patches of 16 × 16 pixels. These patches allow the model to learn local and distant features on the image. The model generally contains fewer transformer encoder blocks and has fewer parameters than the DeiT model types. Because it is a smaller model, it uses less memory and can compute faster. This makes it easier to use, especially in computing environments with limited hardware resources. Another advantage of this model is that it can capture important details in complex images. The DeiT3 series aims to achieve high accuracy with less data [30,31].
- MaxViT base-tf-224: MaxViT (Maximum Vision Transformer) is a ViT-based model designed for image classification and other computer vision tasks. There are several types of MaxViT, the simplest and most basic model is ‘maxvit base-tf-224’. This model takes input images with a resolution of 224 × 224 pixels. The images are not processed as a whole but are divided into parts of certain scales according to the internal structure of the model. MaxViT is generally optimized for computation and memory. The model is often preferred for image classification, object recognition, and segmentation. For the model to perform well, the dataset must be large and diverse [32,33].
- Swin base patch4 window7-224: Swin (Shifted Window) Transformer is an extended version of the ViT models. Swin Transformer uses window-based attention mechanisms to learn both local and global contexts, enabling the processing of multi-scale features. This model can process input images with a resolution of 224 × 224 pixels. The term Patch4 indicates that the model divides each image into 4 × 4 pixel patches. The term Windows7 refers to the window size that the model uses for attention computations, which covers an area of 7 × 7 pixels during each attention operation, making it possible to learn both local and large-scale contexts. This model is preferred for image classification, segmentation, and object recognition [34].
- ViT base patch16-224: The model accepts images with an input resolution of 224 × 224 pixels and processes them by dividing each image into 16 × 16 pixel patches. This version is a simplified version of the ViT-large model. It has fewer transform encoder blocks and a generally smaller number of parameters. It also uses less memory [28,35,36].
2.6. Proposed Hybrid Approach
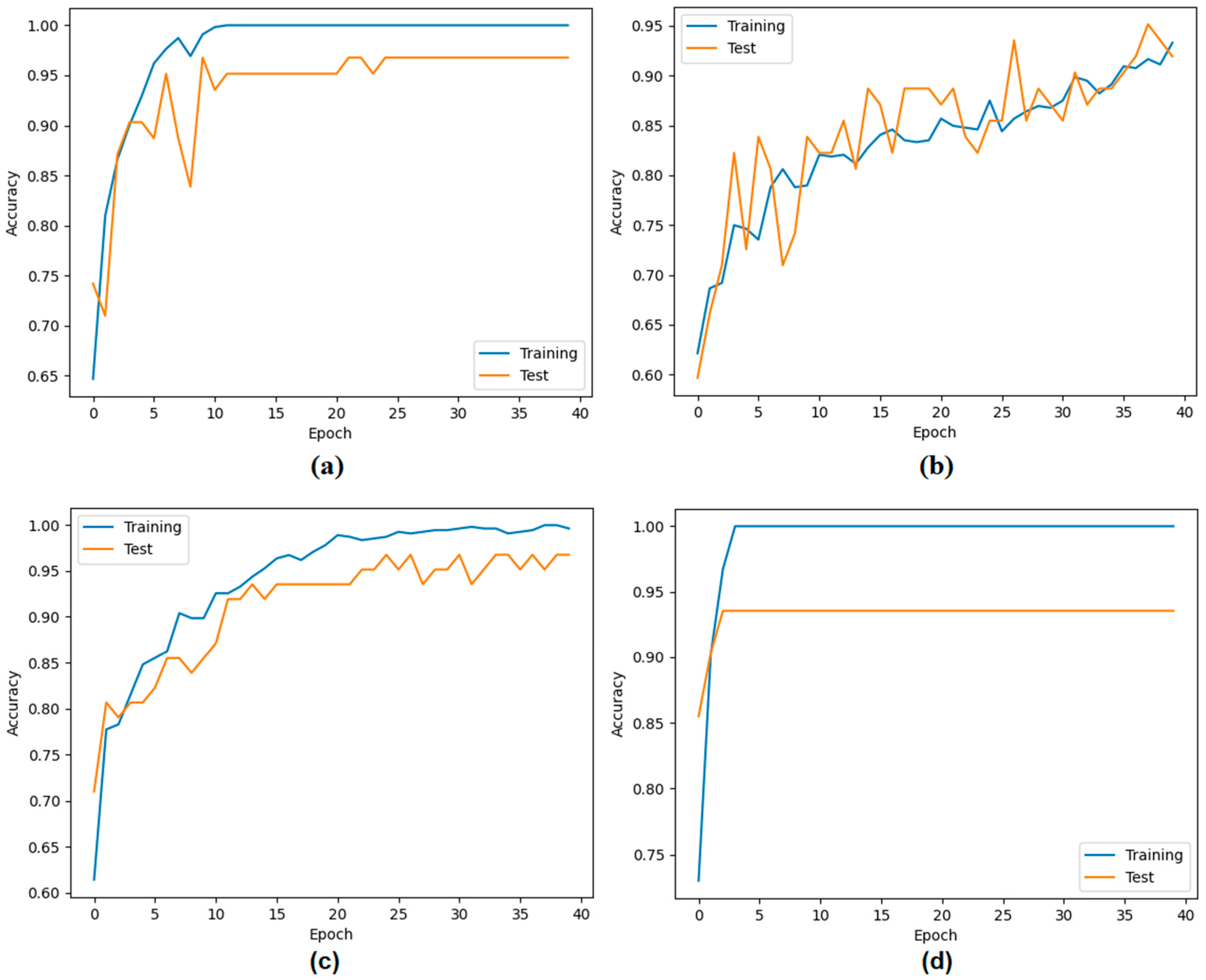
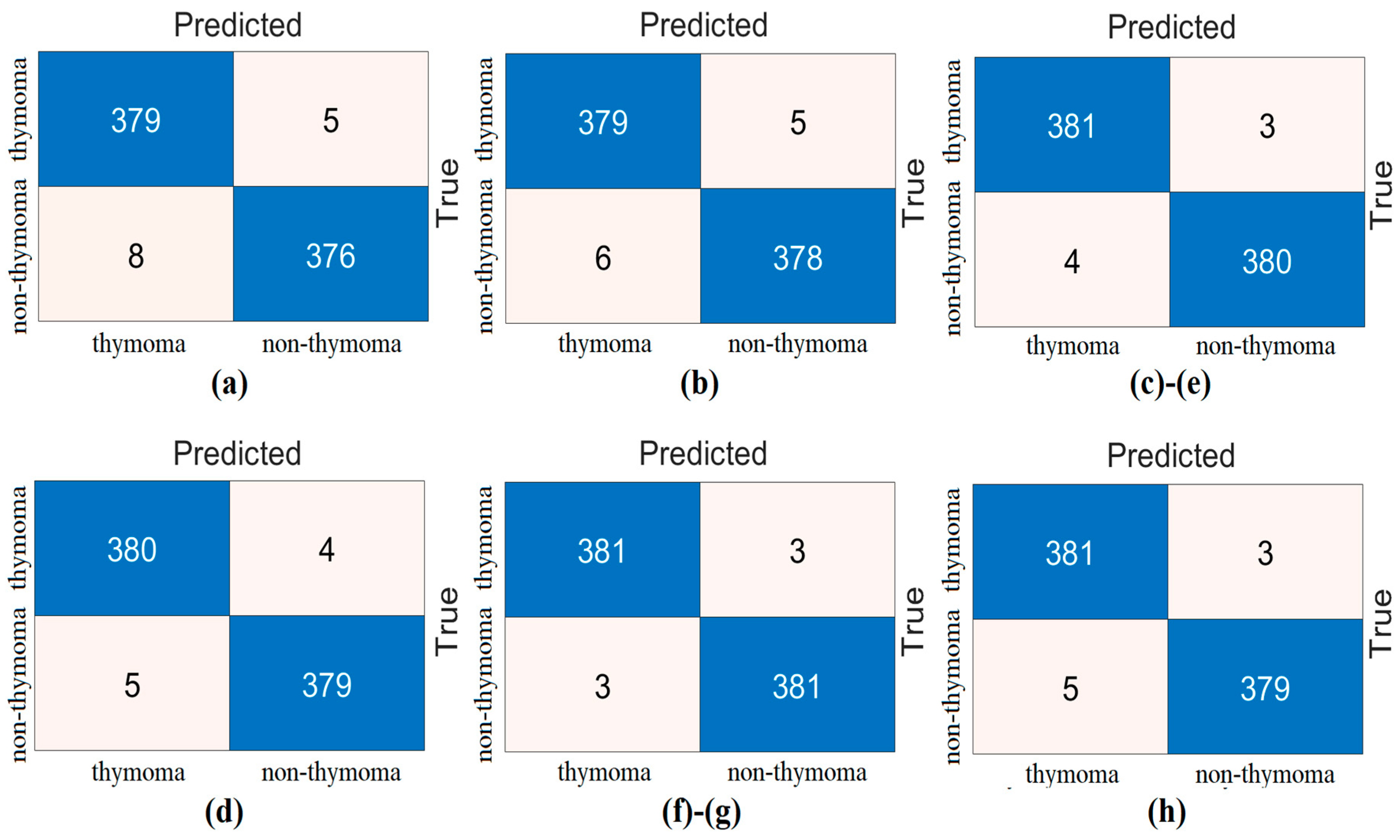
3. Experimental Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Juanpere, S.; Cañete, N.; Ortuño, P.; Martínez, S.; Sanchez, G.; Bernado, L. A Diagnostic Approach to the Mediastinal Masses. Insights Imaging 2013, 4, 29–52. [Google Scholar] [CrossRef] [PubMed]
- Duwe, B.V.; Sterman, D.H.; Musani, A.I. Tumors of the Mediastinum. Chest 2005, 128, 2893–2909. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-H.; Chan, J.K.; Yin, C.-H.; Lee, C.-C.; Chern, C.-U.; Liao, C.-I. Trends in the Incidence of Thymoma, Thymic Carcinoma, and Thymic Neuroendocrine Tumor in the United States. PLoS ONE 2019, 14, e0227197. [Google Scholar] [CrossRef]
- Su, M.; Luo, Q.; Wu, Z.; Feng, H.; Zhou, H. Thymoma-associated Autoimmune Encephalitis with Myasthenia Gravis: Case Series and Literature Review. CNS Neurosci. Ther. 2024, 30, e14568. [Google Scholar] [CrossRef]
- Pina-Oviedo, S.; Pavlisko, E.; Glass, C.; DiBernardo, L.; Sporn, T.; Roggli, V. Diagnostic Approach to Prevascular (Anterior) Mediastinal Lymphomas: When Thoracic Pathology Meets Hematopathology. Mediastinum 2023, 7, 35. [Google Scholar] [CrossRef]
- Sperling, B.; Marschall, J.; Kennedy, R.; Pahwa, P.; Chibbar, R. Thymoma: A Review of the Clinical and Pathological Findings in 65 Cases. Can. J. Surg. 2003, 46, 37–42. [Google Scholar]
- Alothaimeen, H.S.; Memon, M.A. Treatment Outcome and Prognostic Factors of Malignant Thymoma—A Single Institution Experience. Asian Pac. J. Cancer Prev. 2020, 21, 653–661. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.-F.J.; Hurd, J.; Shah, S.A.; Liou, D.; Wang, H.; Backhus, L.M.; Lui, N.S.; D’Amico, T.A.; Shrager, J.B.; Berry, M.F. A National Analysis of Open versus Minimally Invasive Thymectomy for Stage I to III Thymoma. J. Thorac. Cardiovasc. Surg. 2020, 160, 555–567.e15. [Google Scholar] [CrossRef]
- Yang, L.; Cai, W.; Yang, X.; Zhu, H.; Liu, Z.; Wu, X.; Lei, Y.; Zou, J.; Zeng, B.; Tian, X.; et al. Development of a Deep Learning Model for Classifying Thymoma as Masaoka-Koga Stage I or II via Preoperative CT Images. Ann. Transl. Med. 2020, 8, 287. [Google Scholar] [CrossRef]
- Liu, W.; Wang, W.; Guo, R.; Zhang, H.; Guo, M. Deep Learning for Risk Stratification of Thymoma Pathological Subtypes Based on Preoperative CT Images. BMC Cancer 2024, 24, 651. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, Y.; Yuan, Y.; Yang, L.; Wang, K.; Wang, M.; Yang, X.; Wu, X.; Tian, X.; Zhang, R.; et al. 3D DenseNet Deep Learning Based Preoperative Computed Tomography for Detecting Myasthenia Gravis in Patients with Thymoma. Front. Oncol. 2021, 11, 631964. [Google Scholar] [CrossRef] [PubMed]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Classification of Flower Species by Using Features Extracted from the Intersection of Feature Selection Methods in Convolutional Neural Network Models. Measurement 2020, 158, 107703. [Google Scholar] [CrossRef]
- Bi, D.; Liu, Y.; Youssefi, N.; Chen, D.; Ma, Y. Breast Cancer Diagnosis Based on Guided Water Strider Algorithm. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2022, 236, 30–42. [Google Scholar] [CrossRef] [PubMed]
- Amaya-Tejera, N.; Gamarra, M.; Vélez, J.I.; Zurek, E. A Distance-Based Kernel for Classification via Support Vector Machines. Front. Artif. Intell. 2024, 7, 1287875. [Google Scholar] [CrossRef]
- Başaran, E. A New Brain Tumor Diagnostic Model: Selection of Textural Feature Extraction Algorithms and Convolution Neural Network Features with Optimization Algorithms. Comput. Biol. Med. 2022, 148, 105857. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting Critical Features for Data Classification Based on Machine Learning Methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Hermo, J.; Bolón-Canedo, V.; Ladra, S. Fed-MRMR: A Lossless Federated Feature Selection Method. Inf. Sci. 2024, 669, 120609. [Google Scholar] [CrossRef]
- Wang, G.; Lauri, F.; El Hassani, A.H. Feature Selection by MRMR Method for Heart Disease Diagnosis. IEEE Access 2022, 10, 100786–100796. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, Y.; Lv, D.; Chen, X.; Lu, J.; Liu, J. A New Improved Maximal Relevance and Minimal Redundancy Method Based on Feature Subset. J. Supercomput. 2023, 79, 3157–3180. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for Object Segmentation and Fine-Grained Localization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar] [CrossRef]
- Cıbuk, M.; Budak, U.; Guo, Y.; Ince, M.C.; Sengur, A. Efficient Deep Features Selections and Classification for Flower Species Recognition. Measurement 2019, 137, 7–13. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Detection of Lung Cancer on Chest CT Images Using Minimum Redundancy Maximum Relevance Feature Selection Method with Convolutional Neural Networks. Biocybern. Biomed. Eng. 2020, 40, 23–39. [Google Scholar] [CrossRef]
- Parvaiz, A.; Khalid, M.A.; Zafar, R.; Ameer, H.; Ali, M.; Fraz, M.M. Vision Transformers in Medical Computer Vision—A Contemplative Retrospection. Eng. Appl. Artif. Intell. 2023, 122, 106126. [Google Scholar] [CrossRef]
- Chen, Z.; Xie, Y.; Wu, Y.; Lin, Y.; Tomiya, S.; Lin, J. An Interpretable and Transferrable Vision Transformer Model for Rapid Materials Spectra Classification. Digit. Discov. 2024, 3, 369–380. [Google Scholar] [CrossRef]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Wang, H.; Li, W. DDosTC: A Transformer-Based Network Attack Detection Hybrid Mechanism in SDN. Sensors 2021, 21, 5047. [Google Scholar] [CrossRef]
- Katar, O.; Yildirim, O. An Explainable Vision Transformer Model Based White Blood Cells Classification and Localization. Diagnostics 2023, 13, 2459. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tuncel, İ.; Albayrak, A.; Akın, M. Öz Dikkat Mekanizması Tabanlı Görü Dönüştürücü Kullanılarak Sıtma Parazit Tespiti. DÜMF Mühendislik Derg. 2022, 13, 271–277. [Google Scholar] [CrossRef]
- Mehrani, P.; Tsotsos, J.K. Self-Attention in Vision Transformers Performs Perceptual Grouping, Not Attention. Front. Comput. Sci. 2023, 5, 1178450. [Google Scholar] [CrossRef]
- Baroni, G.L.; Rasotto, L.; Roitero, K.; Tulisso, A.; Di Loreto, C.; Della Mea, V. Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification. J. Imaging 2024, 10, 108. [Google Scholar] [CrossRef]
- Kunduracioglu, I.; Pacal, I. Advancements in Deep Learning for Accurate Classification of Grape Leaves and Diagnosis of Grape Diseases. J. Plant Dis. Prot. 2024, 131, 1061–1080. [Google Scholar] [CrossRef]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MaxViT: Multi-axis Vision Transformer. In ECCV 2022, Proceedings of the European Conference on Computer Vision 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; Volume 13684, pp. 459–479. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sowmya, T.S.; Narasimhulu, T.; Sunitha, G.; Manikanta, T.; Venkatesh, T. Vision Transformer Based ResNet Model for Pneumonia Prediction. In Proceedings of the 2023 4th International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 6–8 July 2023; pp. 316–321. [Google Scholar]
- Halder, A.; Gharami, S.; Sadhu, P.; Singh, P.K.; Woźniak, M.; Ijaz, M.F. Implementing Vision Transformer for Classifying 2D Biomedical Images. Sci. Rep. 2024, 14, 12567. [Google Scholar] [CrossRef] [PubMed]
- Sayyad, S.; Shaikh, M.; Pandit, A.; Sonawane, D.; Anpat, S. Confusion Matrix-Based Supervised Classification Using Microwave SIR-C SAR Satellite Dataset BT. In Recent Trends in Image Processing and Pattern Recognition, Proceedings of the Recent Trends in Image Processing and Pattern Recognition, Aurangabad, India, 3–4 January 2020; Santosh, K.C., Gawali, B., Eds.; Springer: Singapore, 2021; pp. 176–187. [Google Scholar]
- Božić, D.; Runje, B.; Lisjak, D.; Kolar, D. Metrics Related to Confusion Matrix as Tools for Conformity Assessment Decisions. Appl. Sci. 2023, 13, 8187. [Google Scholar] [CrossRef]
- Başaran, E. Classification of White Blood Cells with SVM by Selecting SqueezeNet and LIME Properties by MRMR Method. Signal Image Video Process. 2022, 16, 1821–1829. [Google Scholar] [CrossRef]
- Çalışkan, A. Diagnosis of Malaria Disease by Integrating Chi-Square Feature Selection Algorithm with Convolutional Neural Networks and Autoencoder Network. Trans. Inst. Meas. Control 2023, 45, 975–985. [Google Scholar] [CrossRef]
- Thölke, P.; Mantilla-Ramos, Y.-J.; Abdelhedi, H.; Maschke, C.; Dehgan, A.; Harel, Y.; Kemtur, A.; Mekki Berrada, L.; Sahraoui, M.; Young, T.; et al. Class Imbalance Should Not Throw You off Balance: Choosing the Right Classifiers and Performance Metrics for Brain Decoding with Imbalanced Data. Neuroimage 2023, 277, 120253. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B. Processing 2D Barcode Data with Metaheuristic Based CNN Models and Detection of Malicious PDF Files. Appl. Soft Comput. 2024, 161, 111722. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gender | |
| Male | 91 (%71.1) |
| Female | 37 (%28.9) |
| Age (year, mean ± SD) | 54.6 ± 16.8 |
| CT size (year, mean ± SD) | 4.8 ± 1.9 |
| Masaoka Staging System | |
| Stage 1 | 21 (%16.4) |
| Stage 2a | 58 (%45.4) |
| Stage 2b | 38 (%29.7) |
| Stage 3 | 11 (%8.5) |
| WHO histologic classification | |
| A | 23 (%17.9) |
| AB | 21 (%16.4) |
| B1 | 19 (%14.9) |
| B2 | 34 (%26.6) |
| B3 | 31 (%24.2) |
| Symptoms | |
| Cough | |
| Yes | 27 (%21.1) |
| No | 101 (%78.9) |
| Chest pain | |
| Yes | 40 (%31.2) |
| No | 88 (%68.8) |
| Chest Distress | |
| Yes | 37 (%28.9) |
| No | 91 (%71.1) |
| Myasthenia Gravis | |
| Yes | 39 (%30.5) |
| No | 89 (%69.5) |
| Gender | |
| Male | 108 (%63.5) |
| Female | 62 (%36.5) |
| Age (year, mean ± SD) | 56.5 ± 15.6 |
| Diseases of the non-thymoma group | |
| Thymic hyperplasia | 51 (%30) |
| Lymphoma | 45 (%26.5) |
| Thymic cyst | 39 (%22.9) |
| Thymic carcinoma | 18 (%10.6) |
| Germ cell tumour | 11 (%6.5) |
| Ectopic parathyroid-thyroid | 6 (%3.5) |
| SVM Parameter | Parameter Value/Choice |
|---|---|
| Kernel function | Cubic |
| Kernel scale | Auto |
| Box constraint level | 1 |
| Multiclass method | One-vs-One |
| Model | Parameter | Preference/Value |
|---|---|---|
| DeiT3 | Loss function | Cross Entropy |
| Learning rate | 1 × 10−4 | |
| MaxViT | Optimization | SGD |
| Classifier | Linear | |
| Swin | Epoch | 40 |
| Mini-batch | 2 | |
| ViT | Training rate: testing rate | 0.8:0.2 |
| Transformer Model | Features | Class | Se | Sp | Pre | F-Scr | Acc | TOP #N |
|---|---|---|---|---|---|---|---|---|
| Deit3/base patch16 | 768 | thymoma | 93.75 | 89.18 | 90.36 | 92.02 | 91.55 | #3 |
| non-thymoma | 89.18 | 93.75 | 92.95 | 91.03 | ||||
| MaxViT/base-tf | 768 | thymoma | 85.0 | 91.89 | 91.89 | 88.31 | 88.31 | #4 |
| non-thymoma | 91.89 | 85.0 | 85.0 | 88.31 | ||||
| Swin/base patch4 | 1024 | thymoma | 97.50 | 94.59 | 95.12 | 96.29 | 96.10 | #1 |
| non-thymoma | 94.59 | 97.50 | 97.22 | 95.89 | ||||
| ViT/base patch16 | 768 | thymoma | 97.50 | 93.24 | 93.97 | 95.70 | 95.45 | #2 |
| non-thymoma | 93.24 | 97.50 | 97.18 | 95.17 |
| Representing Letter Symbol | Models with Combined Features | Feature Counts |
|---|---|---|
| W | DeiT3 and Swin | 1792 |
| V | DeiT3 and ViT | 1536 |
| Y | Swin and ViT | 1792 |
| Z | DeiT3 and Swin and ViT | 2560 |
| Feature Merging between Models | Dataset | Class | Se | Pre | F-Scr | Acc |
|---|---|---|---|---|---|---|
| W, V, Y, Z | train/test rate 0.8:0.2 | thymoma | 100 | 100 | 100 | 100 |
| non-thymoma | 100 | 100 | 100 | |||
| W, V, Z | Cross-validation (k = 10) | thymoma | 99.21 | 98.96 | 99.09 | 99.08 |
| non-thymoma | 98.95 | 99.21 | 99.09 | |||
| Y | thymoma | 99.21 | 98.70 | 98.96 | 98.95 | |
| non-thymoma | 98.69 | 99.21 | 98.95 |
| No | Column Number | Score |
|---|---|---|
| 1 | 124 | 0.6145 |
| 2 | 785 | 0.6118 |
| 3 | 1308 | 0.2060 |
| 4 | 68 | 0.1921 |
| 5 | 262 | 0.1714 |
| 6 | 1009 | 0.0821 |
| ⋮ | ||
| 1535 | 1400 | 0.0001 |
| 1536 | 606 | 0.0000 |
| Combined Feature Set | Machine Learning | Top Features | Acc (%) (Test: 0.2) | Acc (%) (Cross val./k = 10) |
|---|---|---|---|---|
| ‘V’ 1536 features | SVM | 50 | 98.69 | 98.31 |
| 100 | 100 | 98.57 | ||
| 200 | 100 | 99.09 | ||
| 300 | 100 | 98.83 | ||
| 400 | 100 | 99.09 | ||
| 500 | 100 | 99.22 | ||
| 750 | 98.69 | 99.22 | ||
| 1000 | 99.35 | 98.96 |
| Article | Year | Model/Method | Result |
|---|---|---|---|
| Lei Yang et al. [9] | 2020 | DenseNet and ROI | AUC: 0.730 |
| Wei Liu et al. [10] | 2024 | ResNet50 and ROI and Lasso and MLP | AUC: 0.998 |
| Zhenguo Liu et al. [11] | 2021 | 3D-DenseNet and Machine learning | Acc: 0.724 |
| This study | 2024 | ROI and Transformer models and Feature set merging and mRMR and SVM | Acc: 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agar, M.; Aydin, S.; Cakmak, M.; Koc, M.; Togacar, M. Detection of Thymoma Disease Using mRMR Feature Selection and Transformer Models. Diagnostics 2024, 14, 2169. https://doi.org/10.3390/diagnostics14192169
Agar M, Aydin S, Cakmak M, Koc M, Togacar M. Detection of Thymoma Disease Using mRMR Feature Selection and Transformer Models. Diagnostics. 2024; 14(19):2169. https://doi.org/10.3390/diagnostics14192169
Chicago/Turabian StyleAgar, Mehmet, Siyami Aydin, Muharrem Cakmak, Mustafa Koc, and Mesut Togacar. 2024. "Detection of Thymoma Disease Using mRMR Feature Selection and Transformer Models" Diagnostics 14, no. 19: 2169. https://doi.org/10.3390/diagnostics14192169