1. Introduction
The use of remote sensing methods for the monitoring of forests represents a very widespread and traditional discipline. Remote sensing (RS) is used for a number of reasons, including the acquisition of compatible data on large territorial units and the possibility of using multispectral information to determine the health status of vegetation and its development [
1,
2]. RS also allows for the mapping of forested and deforested areas, biomass estimation, forest stand classification, fire damage detection or damaged and dry forest identification [
3,
4]. Monitoring forest stands by remote sensing enables one to record data even from hard-to-reach places unsuitable for field research. Measurements can also be repeated periodically, ensuring not only the timeliness of the data but also the ability to evaluate changes that have occurred in the area [
5]. Currently, a wide range of different types of satellite data is available, which differ in spatial, temporal and spectral resolution (e.g., Landsat, Sentinel, MODIS). This offers numerous opportunities for testing the individual types of satellite data for monitoring forest vegetation [
6].
Evaluations of the state of and the changes in forest vegetation using RS have been presented by many studies in various regions of Europe, e.g., Slovakia, such as [
7], or in the High Tatras National Park and its surroundings (e.g., [
8]). Complex evaluations of the changes in forest areas and their consequences in the Carpathian region have been presented by, e.g., [
9,
10,
11]. Landsat data were used in the above-mentioned studies. Landsat images are freely accessible and useful in the analysis of large-scale forest ecosystems. On the other hand, high spatial resolution data, e.g., WorldView-2 (WV2), make it possible to detect more details in the forest landscape such as forest density and forest roads. Immitzer and Atzberger [
12] used WV2 and the Random Forest algorithm for forest classification in the Austrian province of Burgenland. Carle et al. [
13] evaluated the benefit of WV-2 spectral bands for mapping vegetation in a small river delta in coastal Louisiana, USA.
The dramatic die-off of spruce stands (Norway spruce,
Picea abies (L.) Karst.) resulting from bark beetle
Ips typhograpus outbreaks is a phenomenon experienced in many mountainous regions of Europe [
14]. Both airborne [
15] and satellite images (e.g., [
16]) are used to evaluate forest stands after an insect attack. An example of the use of WV2 is a work on the early detection of a bark beetle invasion in central Austria [
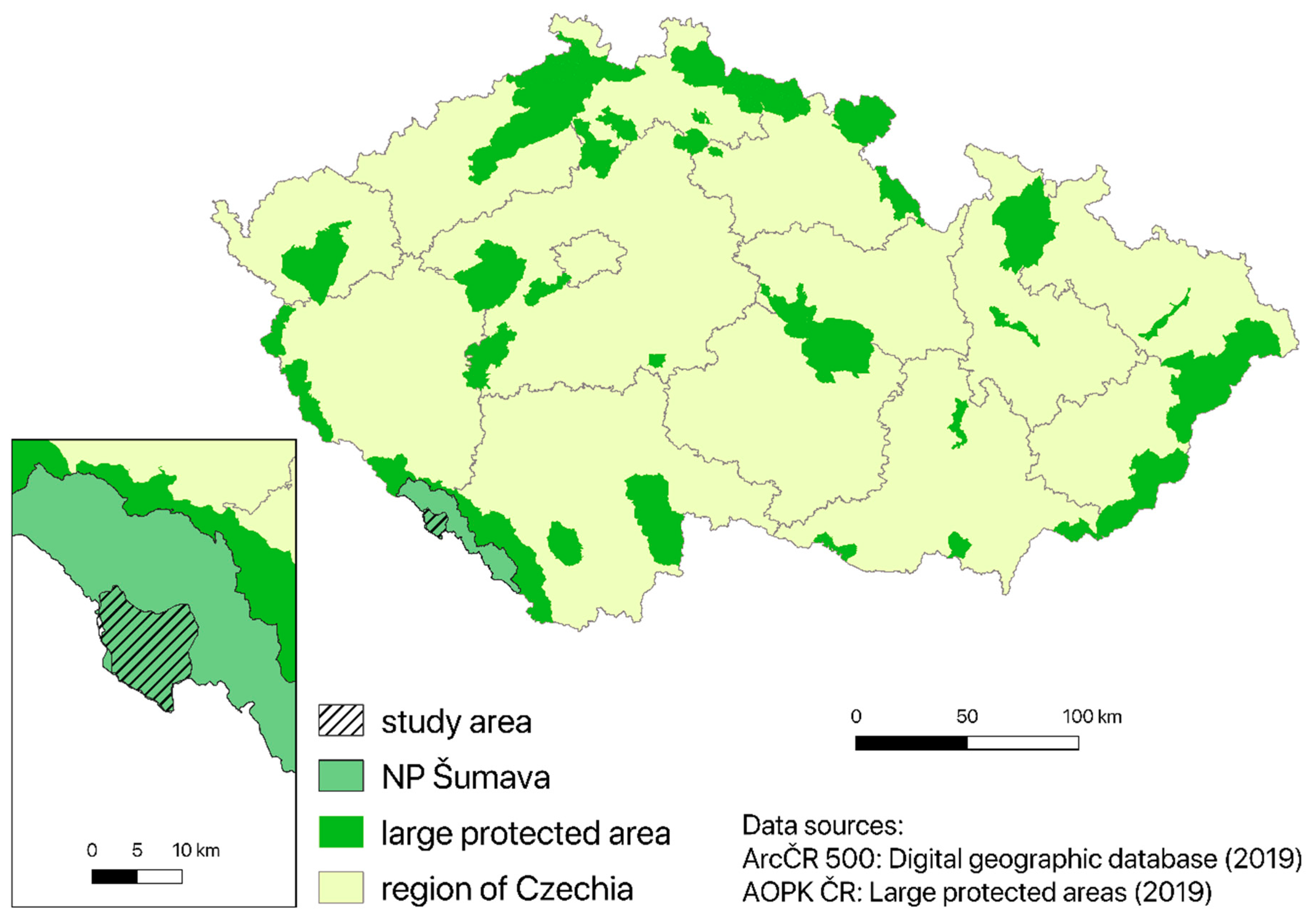
12]. The researchers conducted a Random Forest classification determining the areas of forests that were healthy, under attack or dead. The Sumava National Park in Czechia has been struggling with long-term problems with disturbances, whether they be wind calamities or subsequent bark beetle invasions in Czechia. This national park, thanks to its overlap into the German Bavarian Forest, is very often examined by Czech authors [
17,
18,
19,
20] as well as foreign authors (e.g., [
21]).
Choosing the appropriate classification method and defining a suitable definition of categories is an important aspect in assessing the condition and extent of the damaged forest. Many studies primarily focus on the pixel method used by Meddens et al. [
15] or White et al. [
22], who used it to detect a bark beetle red-attack. DeRose et al. [
23] evaluated the affected forest with vegetation indexes from Landsat images, and the subsequent pixel classification achieved a total accuracy of 80–82%. Hicke and Logan [
24] focused on the classification of 3 categories using the maximum probability classifier: healthy trees, damaged trees and grasslands. The study successfully separated the red attack trees from the healthy trees and the grasslands, thanks to the RGI (Red Green Index) index and the use of reflectivity in the green zone. The overall classification accuracy was 86%. In recent years, the area of state-of-the-art classifiers, such as Support Vector Machines (SVMs), Neural Networks (NNs) or Object-Based Classification (OBIA), has been intensively developed in connection with the development and availability of data with better spatial and spectral resolutions. Latifi et al. [
25] used OBIA to classify Landsat images for an 11-year period in the Bavarian National Park to map the related forest mortality classes. The SVM method was successfully used by Hart and Veblen [
26], who classified a bark beetle forest from satellite and aerial photographs.
The objective of our study was to evaluate the usefulness of very high spatial resolution images (1.84-m WV2) and high spatial resolution images (30-m Landsat 8) to identify bark beetle outbreaks from satellite data using advanced per-pixel methods based on machine learning methods. The main aims are based on the current topics discussed in the literature, which focus on testing the individual types of data and classification methods [
27,
28,
29]. This study fills a gap that earlier studies have not handled: using WV2 in such a forest affected by bark beetle outbreaks. The long-term impact of the forest attack by the spruce bark beetle in the Sumava National Park offers an ideal opportunity to test different classification approaches and to assess the forest stand damage using remote sensing data of various spatial and spectral resolutions. The reason for comparing Landsat 8 (L8) and WV2 data was the unique timing of the acquisition of both types of data. Both images were acquired within one month in the autumn of 2015. The classification methods used are SVM and NN, which have been tested for input parameters, training areas, and other important parameters (e.g., number of iterations and background layers). The monitored categories are determined on the basis of field research, the suitability of the data inputs, a search for relevant studies and also the requirements of potential end users, such as hydrologists, foresters or management employees of the Sumava National Park. The next goal is to calculate the total area of the classified categories and to evaluate a spatial distribution of the categories in the case study. To recapitulate, the study deals with these goals:
to evaluate and compare the applicability of the commercial, very high spatial resolution images (1.84-m WV2) with the freely downloaded, high spatial resolution images (30-m L8) for the identification of forest damage (affected by the bark beetle outbreaks);
to compare the results of the classification of forest vegetation using the advanced classification algorithms of SVM and NN based on machine learning methods;
to define the most relevant parameters of SVM and NN (e.g., number of iterations, background layers, kernel function, penalty parameter) for the highest accuracy to be achieved in the classification of land cover;
to propose a classification system with definitions of categories to distinguish between the individual stages of decay and forest regeneration after a spruce bark beetle attack;
to interpret the results of the classification and define the positives and weaknesses of the used data and classification methods.
5. Discussion
The main aim of the study was to evaluate the possibilities for the classification of forest stands affected by disturbances in the Sumava National Park. For this purpose, WV2 and L8 satellite images taken at a very similar time in 2015 were selected and compared. The next goal was to evaluate and compare the results of SVM and NN classifications based on the input satellite data.
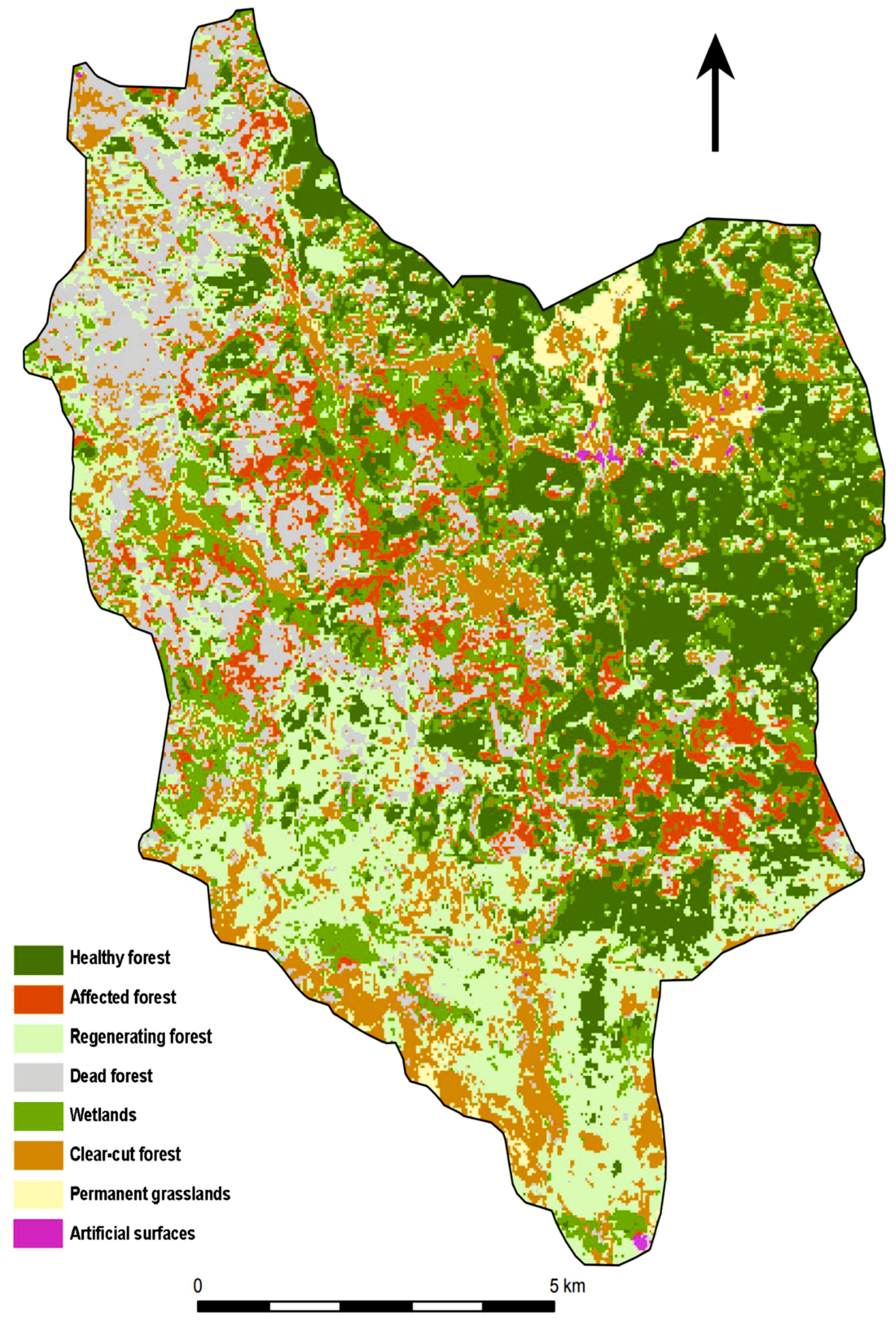
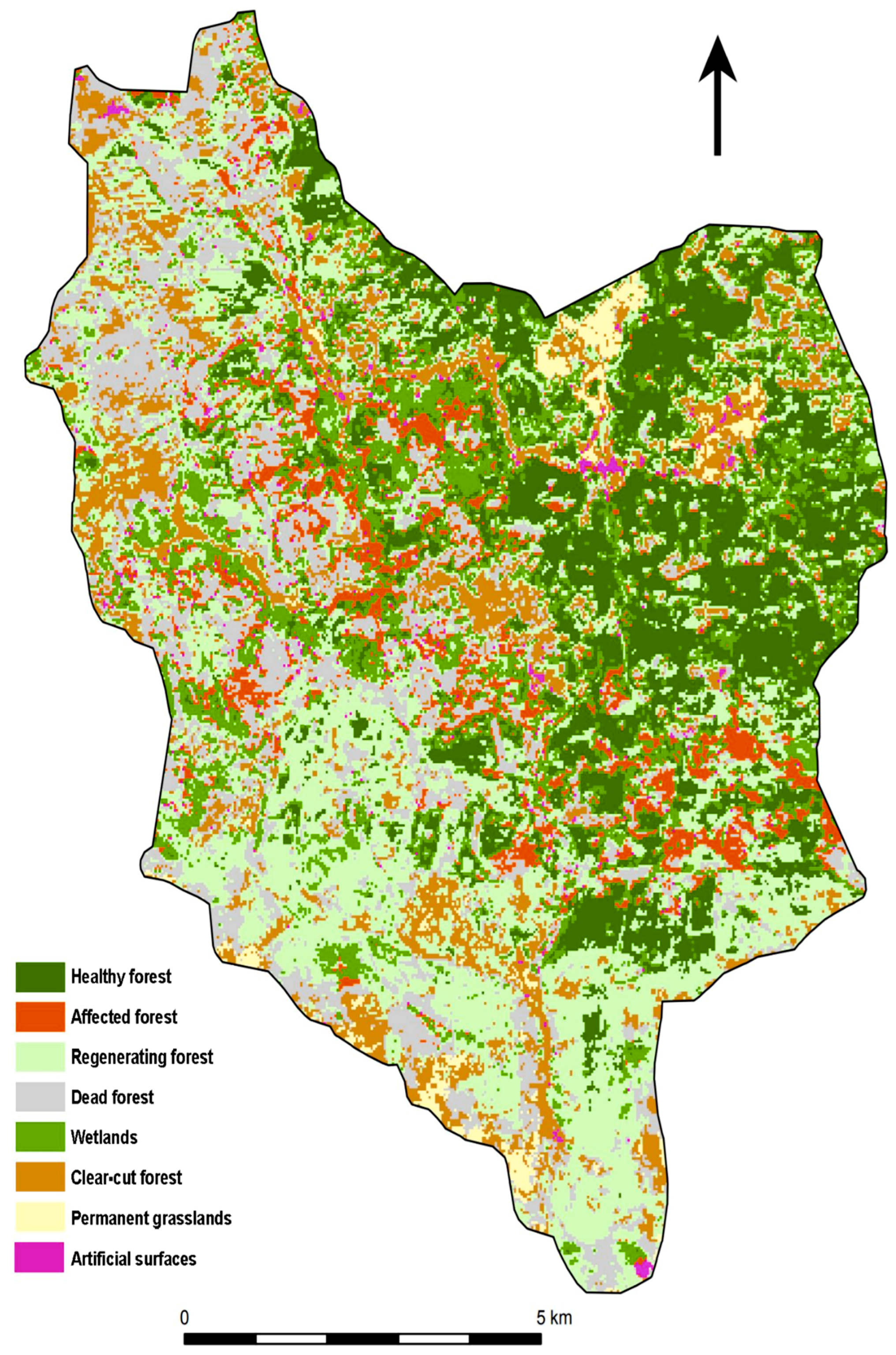
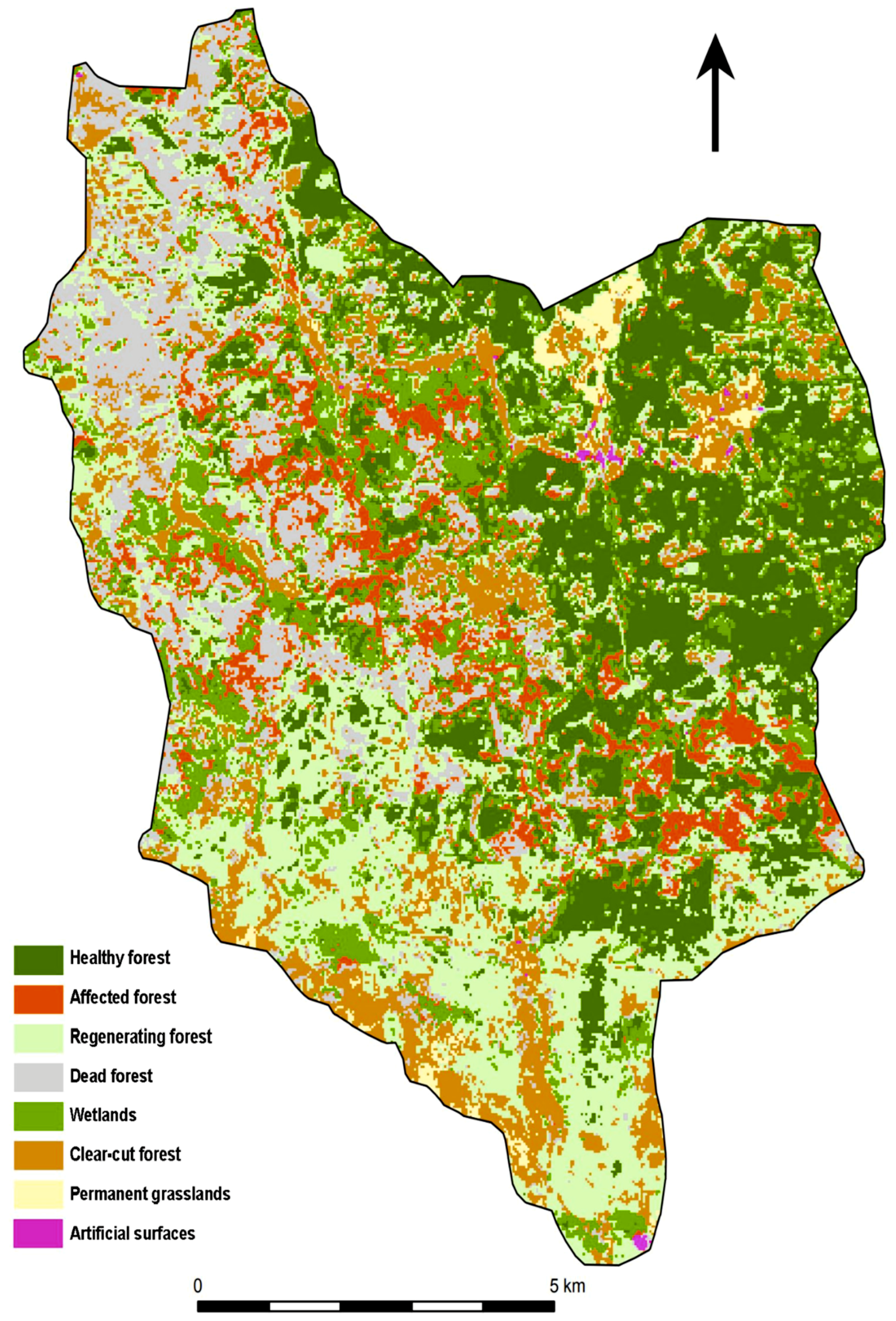
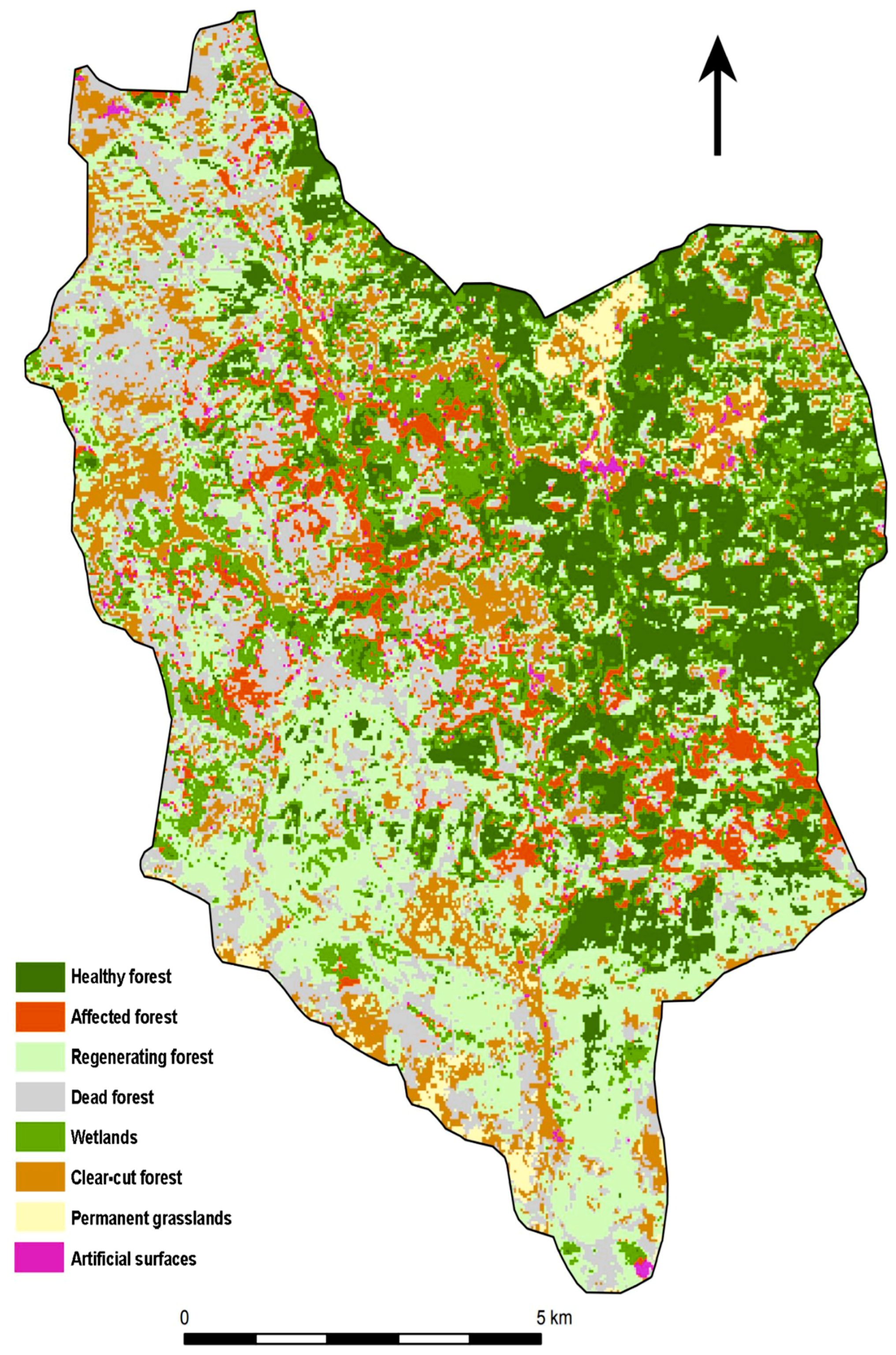
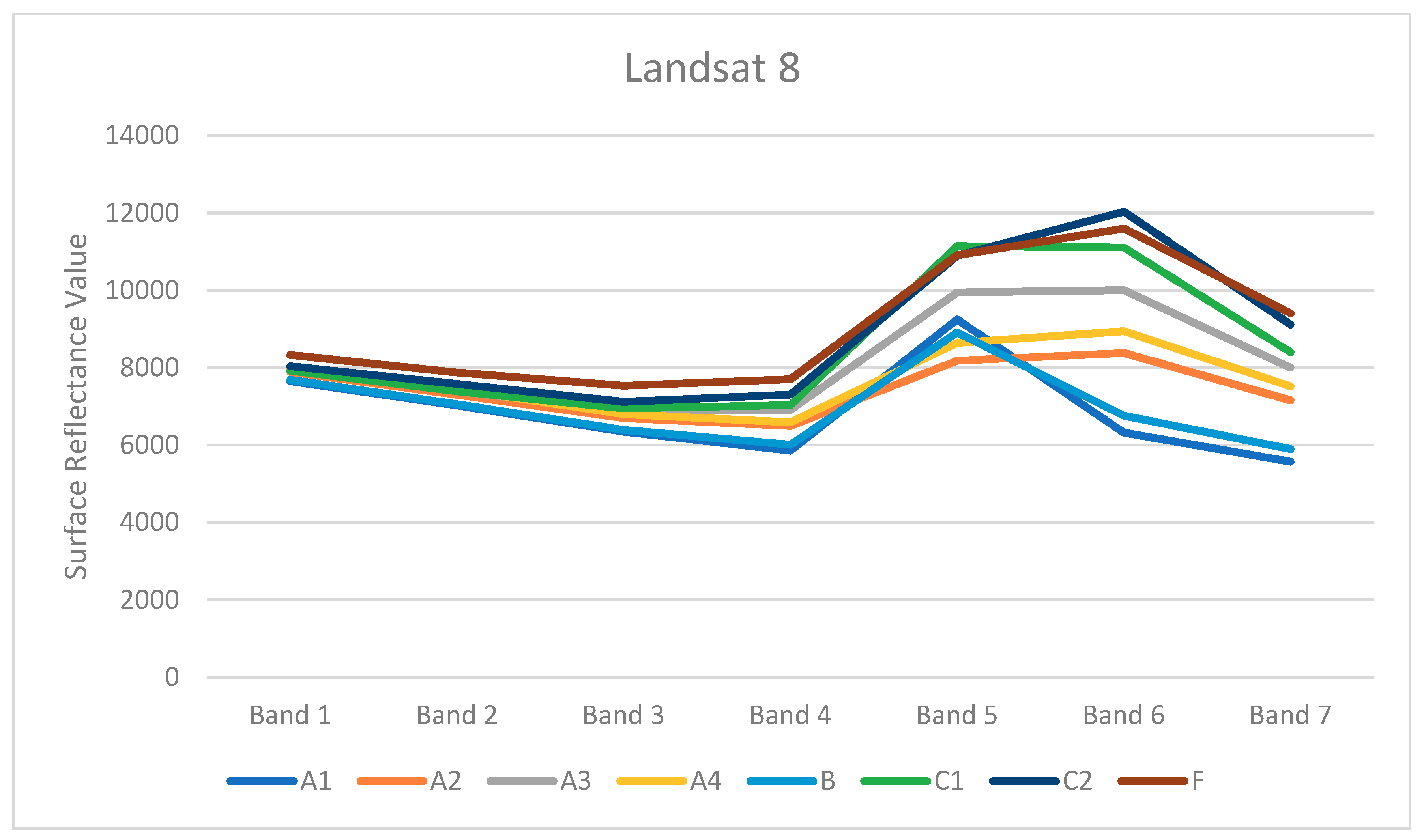
The resulting classification is based on a definition of categories that was primarily designed to distinguish between the observed stages of decay and forest regeneration after the spruce bark beetle attack. The classification classes, thus, reflect the state of vegetation in the Sumava National Park in 2015, and their definition is based on findings from a field survey, results of similar studies and experts from the Sumava National Park. The forest stands were divided into the following categories: A healthy forest, an affected forest, a dead forest, a regenerating forest and a clear-cut forest. This distinction is important from an environmental point of view, from the perspective of decision-making processes in forestry, and in nature and landscape protection. The most important aspect in determining the classes was the purpose of using the classification outputs. In the case of this study, the requirements of foresters and conservationists for forest stand monitoring and the requirements of physical geographers and hydrologists were accepted.
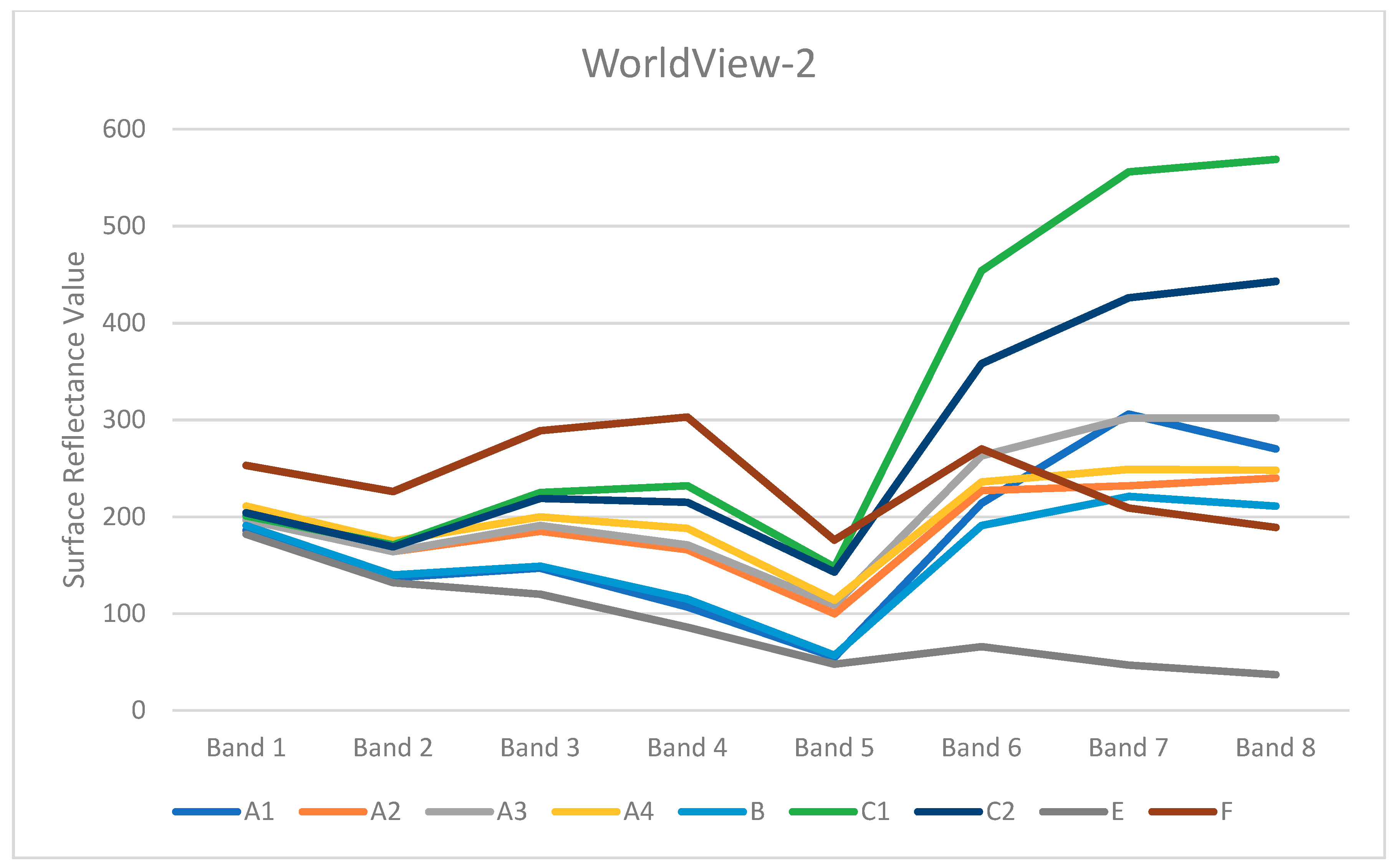
This study proved a high potential of the multispectral satellite data for research on forest vegetation affected by bark beetle outbreaks. Near infrared (NIR) and short-wave infrared (SWIR) bands are crucial for distinguishing the individual forest categories and for the evaluation of the health of forest vegetation [
1,
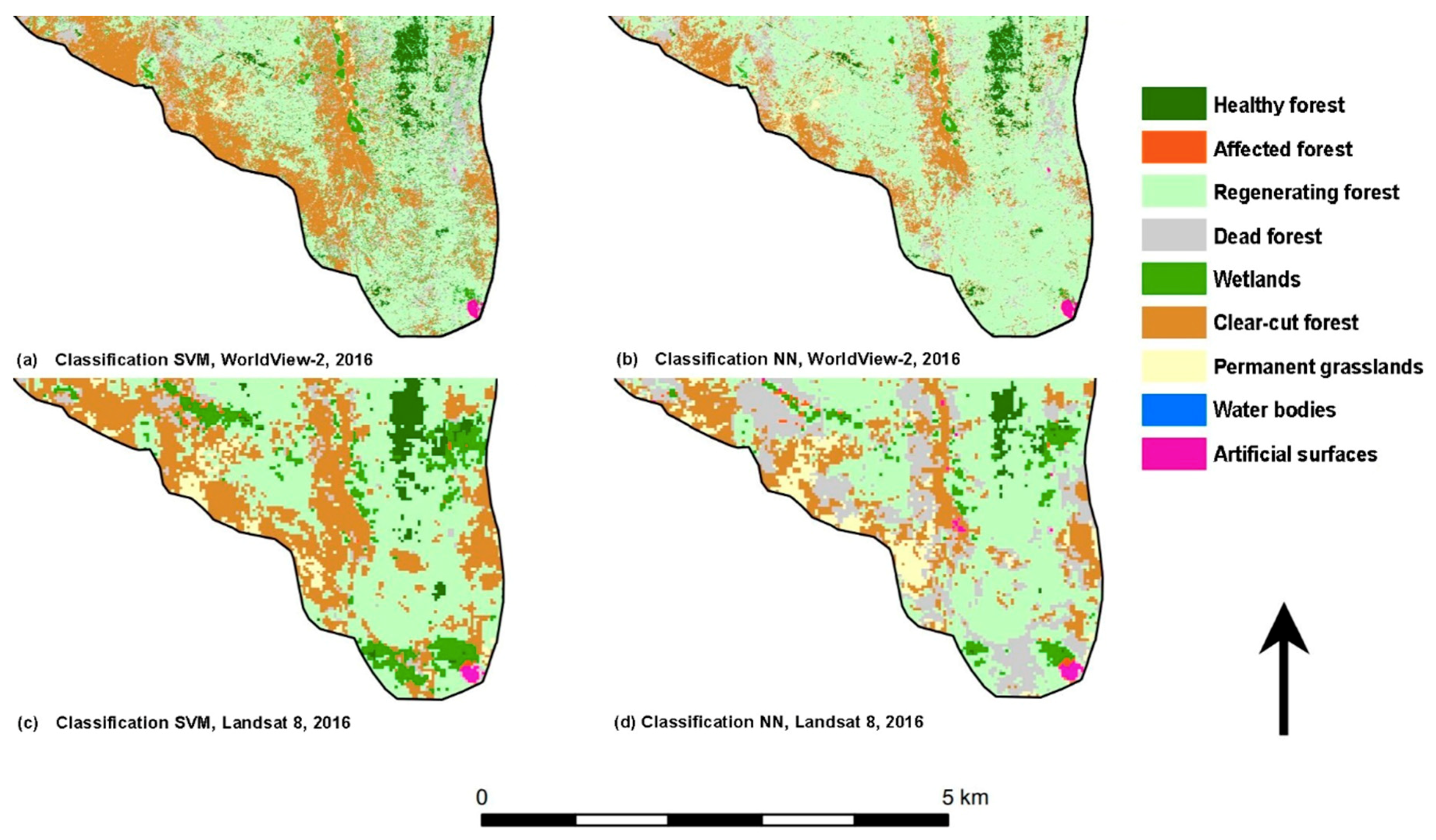
17]. From the point of view of evaluating the accuracy of the classification of individual classes, a problematic classification was assumed for the classes of the affected (A2), dead (A4) and regenerating forest (A3). In these classes, the spectral characteristics may be similar, making it more likely to be confused among themselves or, for example, with the category of clear-cut forest (C1). This assumption was confirmed; however, the classification of WV2, which has a higher spatial resolution, brought better results than L8. Most precisely, these categories were distinguished by the SMV classification based on WV2, see the error matrix tables in
Appendix B. Besides, due to the small area/size of local water bodies, it was not possible to classify these areas with respect to the Landsat 30 × 30 m spatial resolution. When classifying a Landsat image with a lower spatial resolution, the water bodies class could not be classified. From the point of view of the classification, negatives of higher resolution data are shadows, which are more visible in the WV2 image.
For the classification methods, the SVM and NN methods were selected for classification based on previous studies that dealt with forest classification, e.g., [
9,
15,
37]. These methods were applied to the WV2 and L8 satellite imageries (commercially × freely downloaded date). After evaluating all the available results, the SVM can be considered a better method than NN. This classifier achieved the highest overall accuracy and Kappa index for both classified images. In the case of WV2 and L8, total overall accuracies of 86% and 71% and Kappa indices of 0.84 and 0.66 were achieved with SVM, respectively. The NN algorithm using WV2 also produced very promising results, with over 80% overall accuracy and a Kappa index of 0.79. Due to the very heterogenic character of the forest in the case study, the achieved accuracy could be considered as acceptable, although some previous studies e.g., [
24] achieved a higher accuracy. However, these studies did not focus on such damaged and heterogenic forests.
The testing of the appropriate parameters for the classification of both algorithms became an important step. The choice of the parameters for the SVM and NN classifiers was based primarily on our own testing and the studies already carried out to address a similar topic in the given area. Some of the results reported [
37] were confirmed in this study based on different data, especially, the fact that accelerating the process of training the NN network does not lead to better results. The highest accuracy of NN brought the adjustment of the Training Threshold Contribution to 0.1 and 1000 Iterations. In the SVM algorithm, the choice of values for the parameters offered was mainly influenced by the selected Kernel function. RBF and polynomial functions were selected for testing. The polynomial function provided a better accuracy than RBF. After evaluating all the available results, SVM can be considered as a better method than NN. This classifier achieved the highest overall accuracy and Kappa index for both classified images. Similarly, in the case of the most important classes from the perspective of forest growth (forest management) A1–4, using SVM, the best results were achieved for both the user and the processing accuracy. The NN algorithm of WV2 also produced very good results, with over 80% overall accuracy. In the L8 image, the effect of the lower spatial resolution in class B and F classifications is evident.
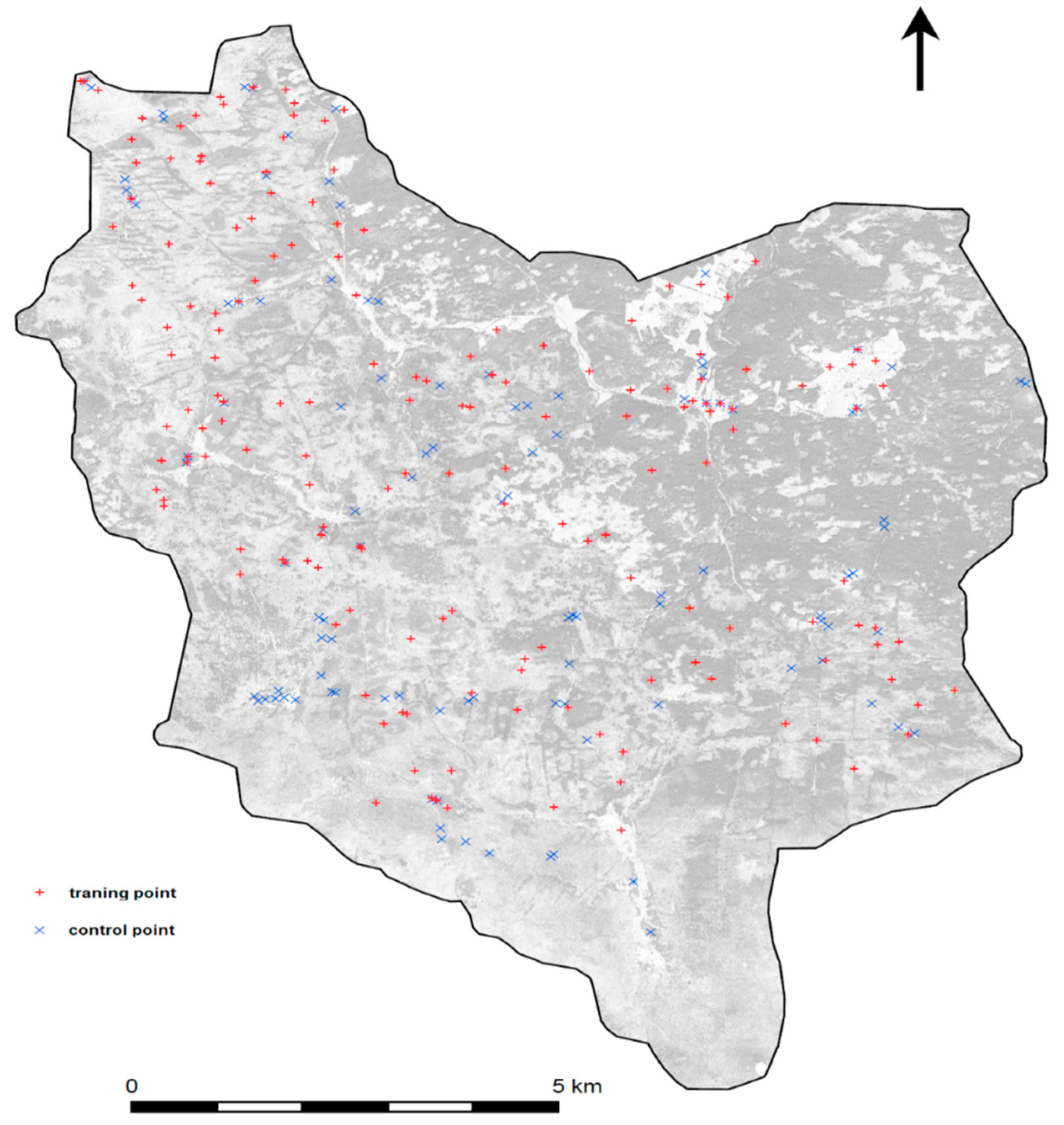
An important part of the classification is certainly the creation of a training set and control points. It is essential that the training points for each class are evenly spatially distributed. At the same time, it is also necessary that the control points of the classification are measured at the similar time as the acquisition [
32]. In the case of this work, the control points of the forest categories were collected several days after the acquisition of the WV2 data. The calculation of the accuracy of the classifications was based on the control points that were measured using a GPS device (80 points were measured in the forest vegetation). These points were supplemented by the points derived from the orthophoto and WV2 multispectral data, e.g., water bodies, artificial areas. The final number of checkpoints was 109 points for WV2 and 102 for Landsat 8. In order to verify the results of this study, it would be useful to consider collecting more control points in the future, especially for forest stands.
The disadvantage of pixel classification is the so-called salt and pepper effect. For some suppression of this effect, a median filter with a 5 × 5 grid was used. However, this method did not remove all the small areas (single pixels), and its implications could influence the resulting scores in the accuracy assessment and the comparison of L8 and WV2 images. This is one of the great advantages of the OBIA object classification, where it is not necessary to solve the problem of single pixels thanks to the initial segmentation.
Comparing the results of the classification and accuracy assessment of the WW2 and L8 images, the effect of the better spatial resolution is evident for the WV2 image. The SVM classification of this image achieved better accuracy for the forest classes (A1–4) as well as the other classes than the classification based on L8. In particular, the forest categories (healthy, affected, regenerating and dead forests) are very relevant from the ecological and forest management point of view, so the ability of WV2 to separate these categories is very significant. A combination of the very high spatial resolution and the suitable spectral resolution, with 8 visible and near infrared bands in the WV2 image, seems to be crucial for the classification of the forest categories affected by disturbances. On the other hand, the archive of Landsat data is free and provides a long-time series of data (since the 1970s). So, it is possible to analyze L8 data using time series methods and to investigate changes in forests based on the multitemporal data of L8.
Based on the results of our case study, it was confirmed that WV2 data had better abilities in the classification of disturbed forest than L8 data. WV2 is useful in small-scale case studies due to the better spatial resolution with a suitable spectral resolution (visible, red edge and NIR bands) see [
12,
13]. According to the results of many studies [
9,
11,
17], Landsat data are suitable for large-scale case studies/regions. Landsat data also enable the evaluation of changes in the forest vegetation over a long-term period. In general, the most important factors for an evaluation of the data used in a classification are the purposes and objectives of the study (classification system, scale, requirements of the end-users etc.). Obviously, WV2 data were more significant and useful than L8 for the purposes of this study.
With regard to the application of the classification methods to the Sumava National Park, it is not possible to say with certainty whether similar results would be achieved in other territories. In order to generalize the presented conclusions, it would be necessary to test the whole procedure on more than one area of interest. The best transferable method could be the SVM algorithm, which requires an appropriate training set, and within which it is relatively easy to define input parameters. NN methods, meanwhile, require more experience of the processor especially in terms of detailed knowledge of data and territory. Anyway, it would be useful to test other combinations of parameters with the classification methods in different case studies. An evaluation of vegetation indices as input data in classification could be another way of investigating this thematic in depth.
As for testing other types of data, it would undoubtedly be useful to include Sentinel-2 or Planet.com data (PlanetScope, SkySat) in the testing. The availability of new types of data since 2015, when the data used for this study were collected, has increased dramatically. So, this study can be taken as an inspiration for future studies that will use more modern data types or different classification algorithms such as the Random Forest Classifier.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}