



Knowledge Graph Recommendation Model Based on Feature Space Fusion


Abstract
:1. Introduction
- ●
- This paper presents a recommendation model named the knowledge graph recommendation model based on feature space fusion (KGRFSF), which can combine the content feature in KG with the behavior feature in UIG.
- ●
- This paper applies the presented model to public datasets in the fields of music and film. The experimental results show that KGRFSF can effectively improve the recommendation performance compared with the existing models.
2. Related Works
3. Our Model
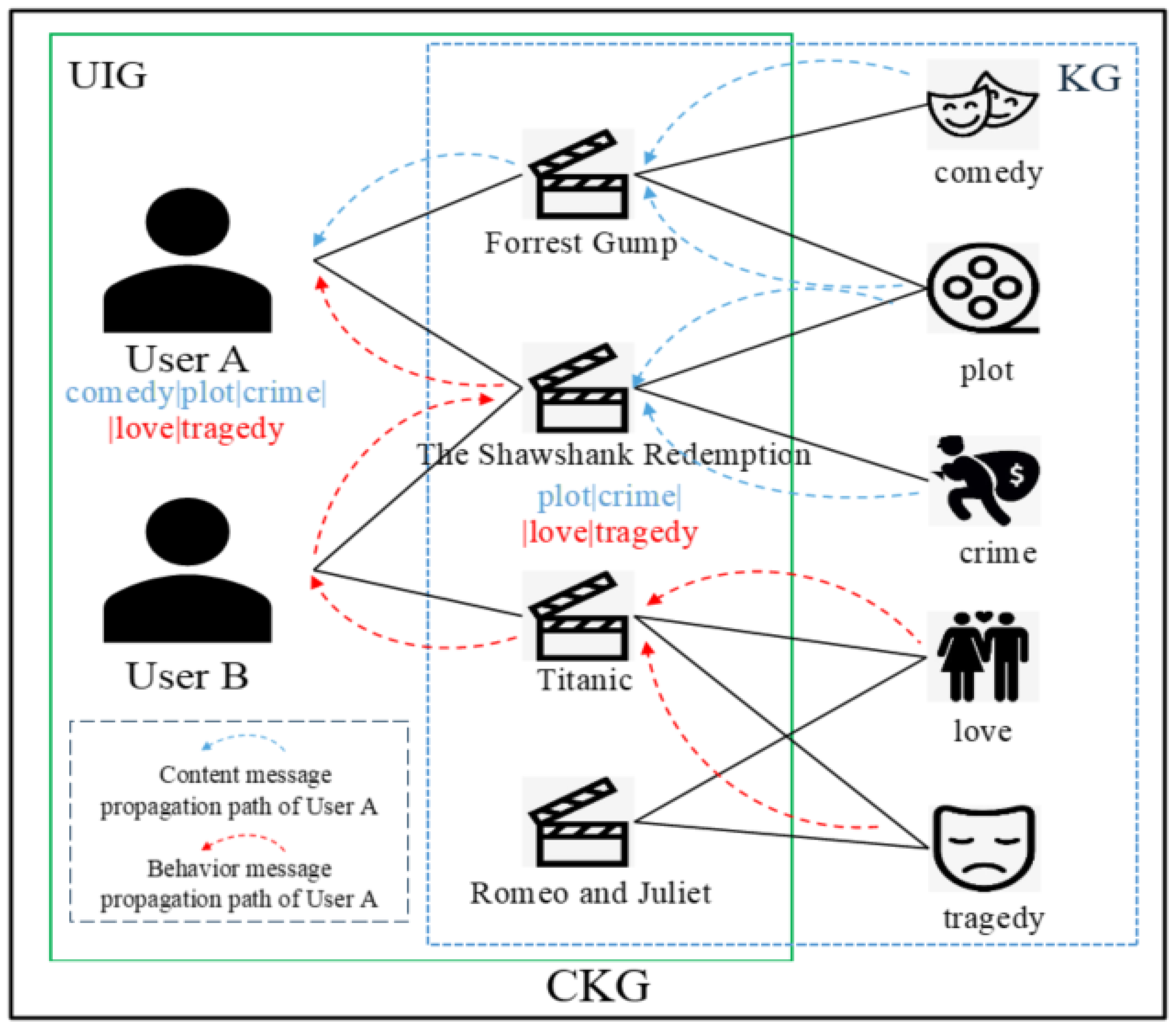
3.1. Problem Analysis and Solution
3.2. Model Introduction
| Algorithm 1: Knowledge graph recommendation model based on feature space fusion |
| Input: user u, item v, user–item bipartite graph G1 = {U, I}, knowledge graph G2 = {V, E}, embedding dimension d, learning rate ƞ, user entity set size Su, item entity set size Sv. Output: score of the user on the item (u, v). Step 1: for n = 0 to epoch do. Step 2: According to Formulas (5) and (6), user behavioral feature embedding ucf and item behavioral feature embedding vcf are calculated. Step 3: User content feature embedding ukg and item content feature embedding vkg are counted according to Formulas (9)–(18). Step 4: According to Formula (19)–(25), calculate the score (u, v) of users. Step 5: Calculation Formula (26). Step 6: Calculate gradient and send back to update model parameters. Step 7: end for Step 8: return (u, v) |
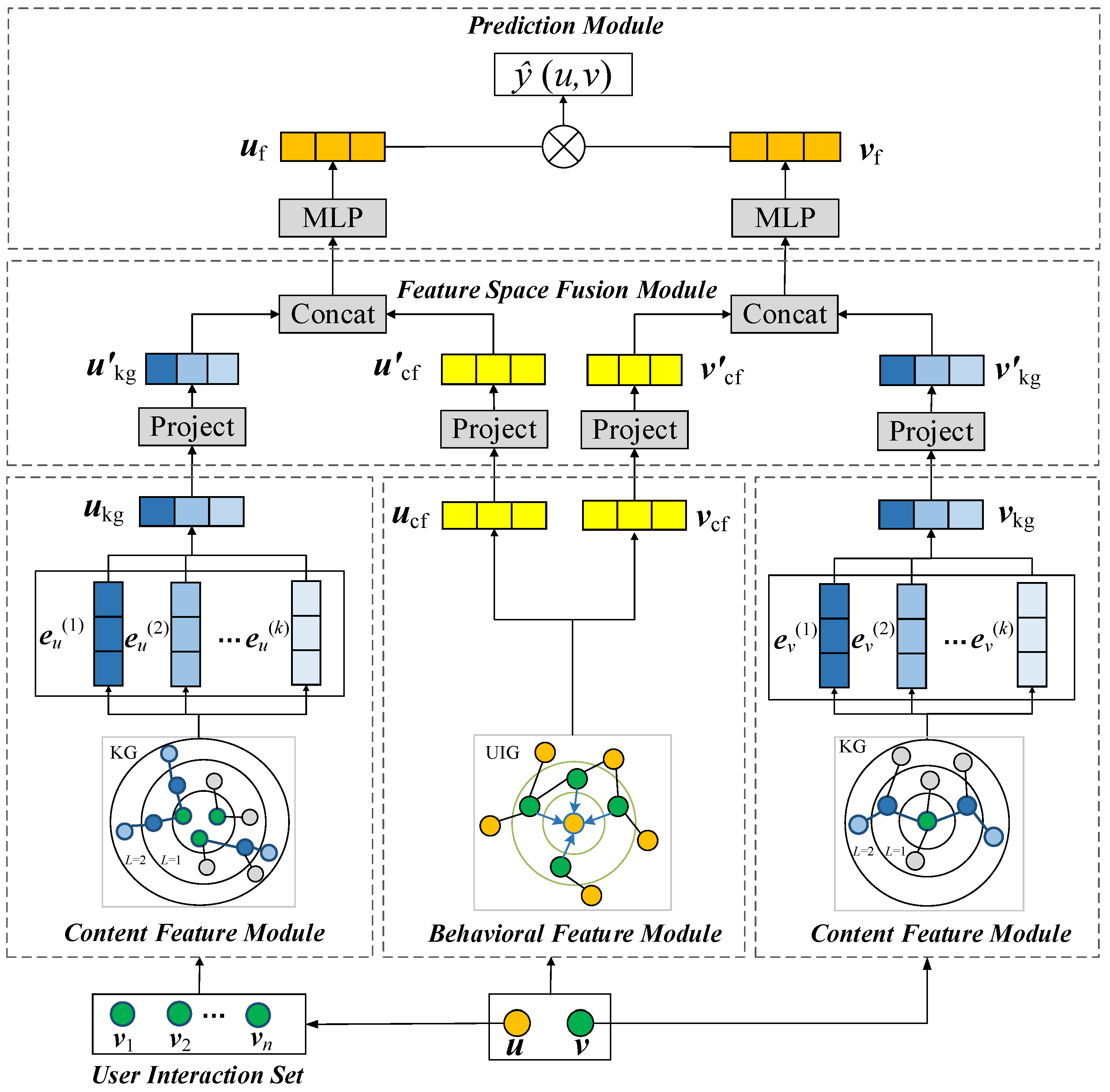
3.2.1. Behavioral Feature Module
3.2.2. Content Feature Module
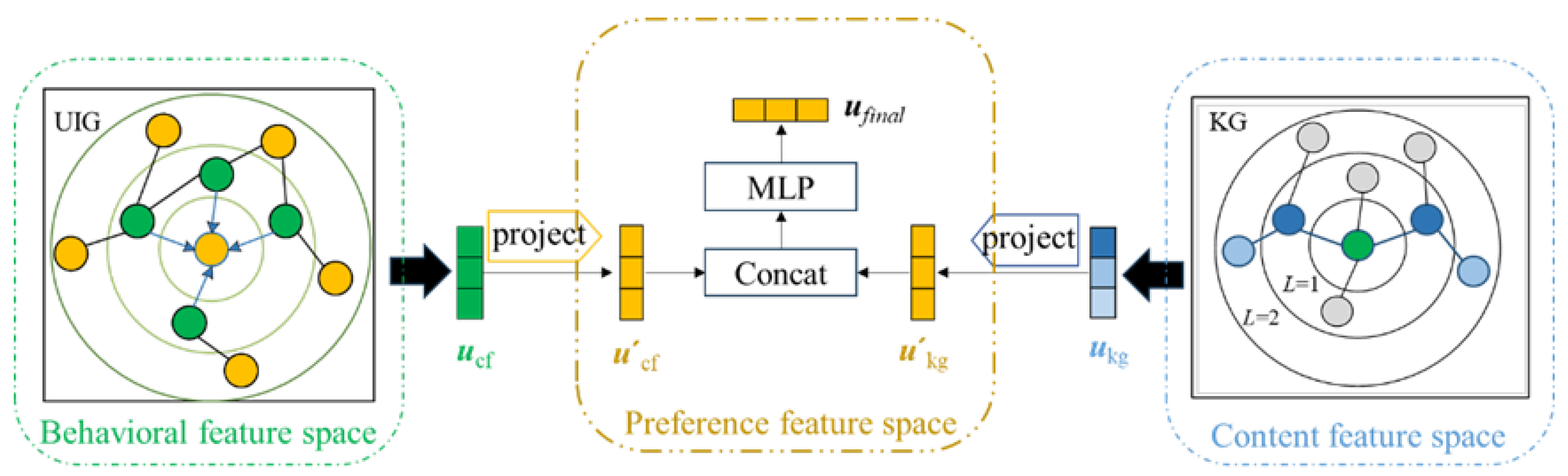
3.2.3. Feature Space Fusion Module
3.2.4. Prediction Module
4. Experiments
4.1. Datasets
4.2. Parameter Settings
4.2.1. Experimental Environment and Hyperparameter Setting
4.2.2. Experimental Metrics
4.3. Baselines
- ●
- CKE [24] is a knowledge graph recommendation model based on embedding. CKE introduces auxiliary information, such as knowledge graphs and text, into a collaborative filtering algorithm for recommendation. The model is based on the TransR [25] algorithm to calculate the embedding vector of nodes in the knowledge graph, which serves to enrich the feature expressions of users and items.
- ●
- KGCN [7] extends graph convolutional networks to the field of KG recommendation. By combining the neighborhood information of the nodes of the knowledge graph, the higher-order association information between entities in the KG is mined to obtain richer representations of users and items.
- ●
- KGAT [8] integrates UIG and KG into CKG and makes an attention mechanism to obtain the neighbor information of users and items to obtain vector representations of users and items.
- ●
- CKAN [9] models the content feature of a knowledge graph based on an attention mechanism. The model constructs a set of content entities related to users and items through collaborative filtering propagation and combines the content feature contained in the set into the feature vector representations of users and items.
4.4. Performance Comparison
4.5. Study of KGRFSF
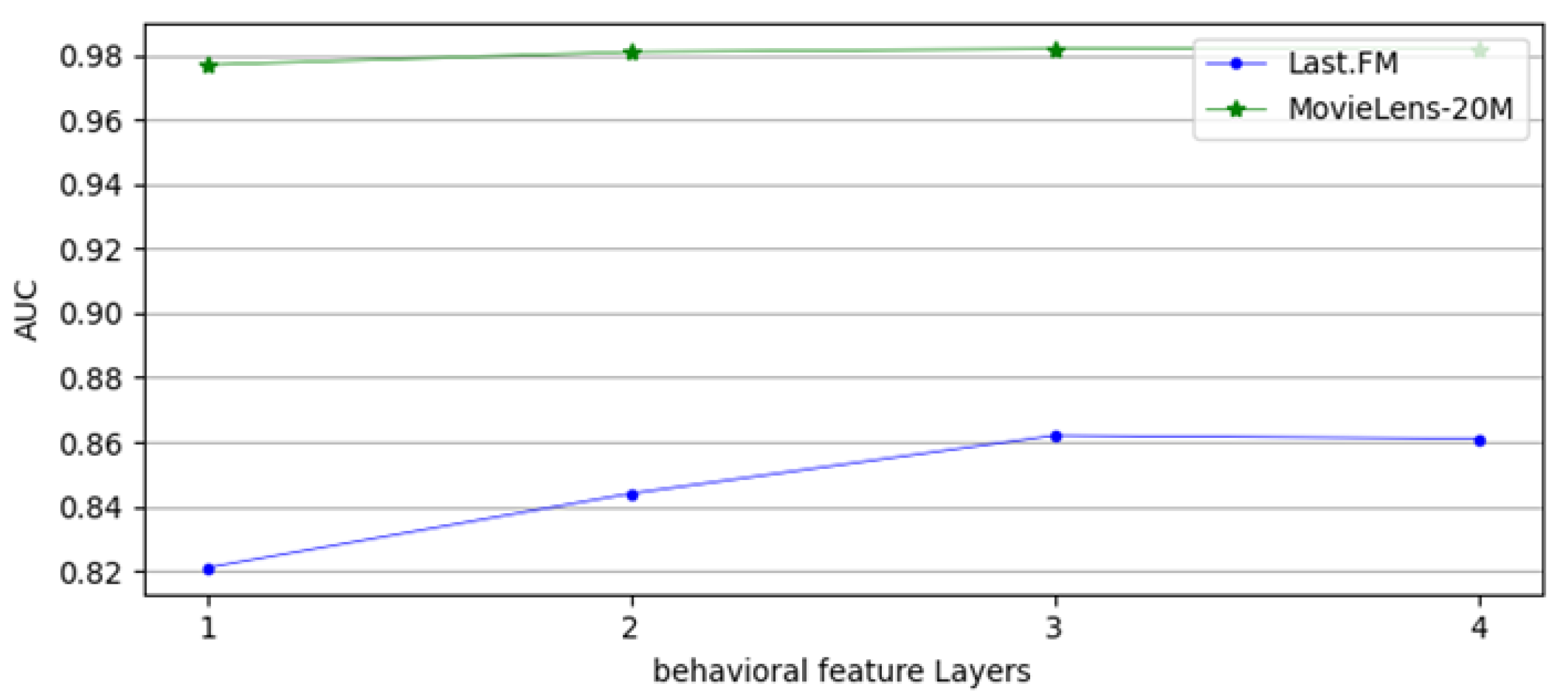
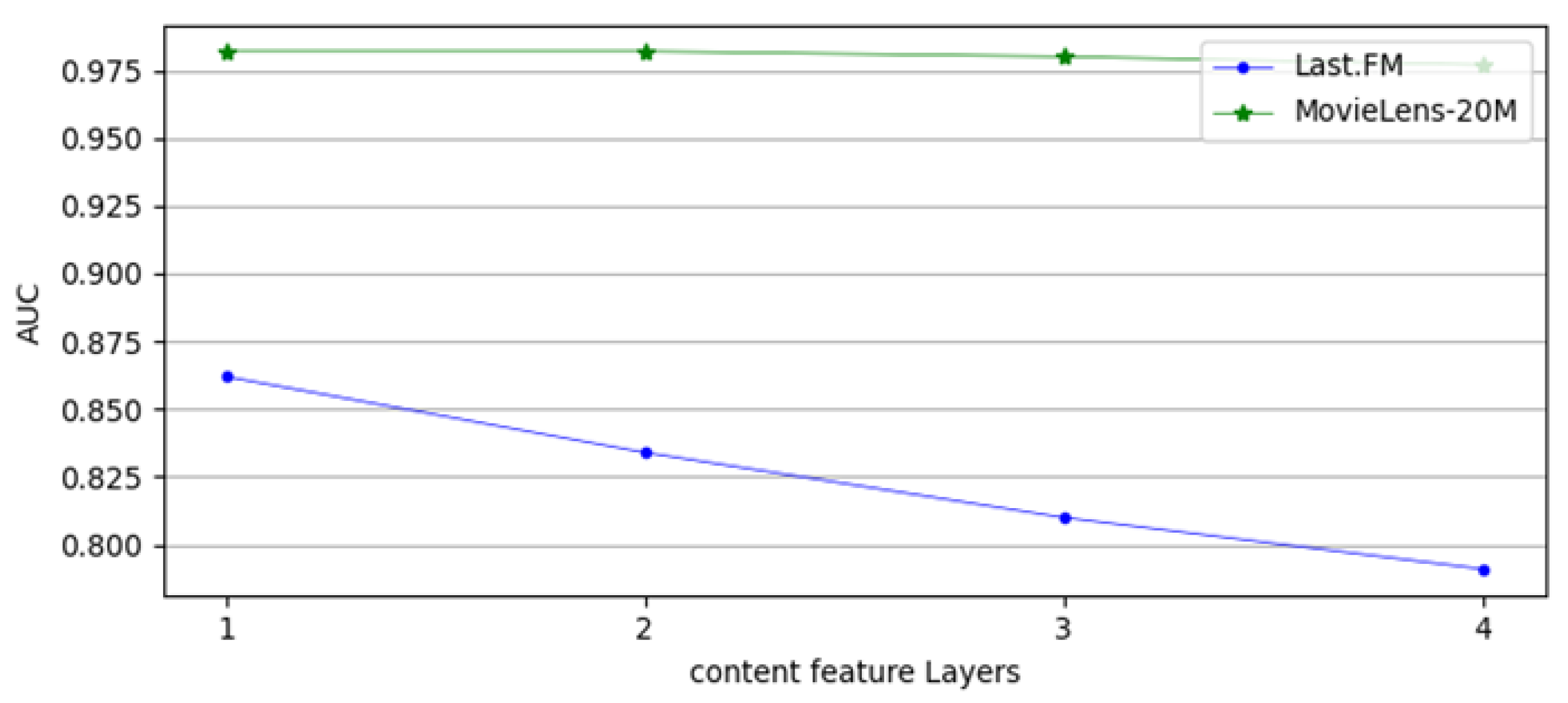
4.5.1. Influence of Network Layers
4.5.2. Influence of the Fusion Method
- ●
- Sum aggregator: The behavioral feature and content feature are directly added and then fused by a multilayer perceptron.where and are parameters to be learned. and represent behavioral features and content, respectively.
- ●
- Concat aggregator: The behavioral feature and content feature are spliced and then fused by a multilayer perceptron.where and are parameters to be learned.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, L.W.; Jiang, B.T.; Lv, S.Y.; Liu, Y.; Li, D. Survey on deep learning-based recommender systems. Chin. J. Computer. 2018, 41, 1619–1647. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web Conference, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Aboagye, E.O.; James, G.C.; Jianbin, G.; Kumar, R.; Khan, R.U. Probabilistic time context framework for big data collaborative recommendation. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence, Chengdu, China, 12–14 March 2018; pp. 118–121. [Google Scholar]
- Chen, C.; Meng, X.; Xu, Z.; Lukasiewicz, T. Location-Aware Personalized News Recommendation with Deep Semantic Analysis. IEEE Access 2017, 5, 1624–1638. [Google Scholar] [CrossRef]
- He, X.; Zhang, H.; Kan, M.Y.; Chua, T.S. Fast matrix factorization for online recommendation with implicit feedback. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 549–558. [Google Scholar]
- Liu, C.Y.; Zhou, C.; Wu, J.; Hu, Y.; Guo, L. Social recommendation with an essential preference space. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; pp. 346–353. [Google Scholar]
- Sedhain, S.; Menon, A.; Sanner, S.; Xie, L.; Braziunas, D. Low-rank linear cold-start recommendation from social data. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 236–243. [Google Scholar]
- Volkovs, M.; Yu, G.; Poutanen, T. Dropoutnet: Addressing cold start in recommender systems. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4957–4966. [Google Scholar]
- Gu, Y.; Zhao, B.; Hardtke, D.; Sun, Y. Learning global term weights for content-based recommender systems. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 391–400. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripple net: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. KGAT: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Wang, Z.; Lin, G.; Tan, H.; Chen, Q.; Liu, X. CKAN: Collaborative Knowledge-aware attentive network for recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 219–228. [Google Scholar]
- Cao, Y.; Wang, X.; He, X.; Hu, Z.; Chua, T.S. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1151–1161. [Google Scholar]
- Wu, L.; Yang, Y.; Zhang, K.; Hong, R.; Fu, Y.; Wang, M. Joint item recommendation and attribute inference: An adaptive graph convolutional network approach. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 679–688. [Google Scholar]
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K.; Zhang, F.; Wang, Z.; Zheng, K. Multi-modal knowledge graphs for recommender systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 1405–1414. [Google Scholar]
- Xia, L.; Huang, C.; Xu, Y.; Dai, P.; Zhang, X.; Yang, H.; Pei, J.; Bo, L. Knowledge-enhanced hierarchical graph transformer network for multi-behavior recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 4486–4493. [Google Scholar]
- Wang, X.; Huang, T.; Wang, D.; Yuan, Y.; Liu, Z.; He, X.; Chua, T.S. Learning intents behind interactions with knowledge graph for recommendation. In Proceedings of the Web Conference 2021, Virtual Event, Slovenia, 19–23 April 2021; pp. 878–887. [Google Scholar]
- Hahnloser, R.H.; Sarpeshkar, R.; Mahowald, M.A.; Douglas, R.J.; Seung, H.S. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 2020, 6789, 947. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In International Workshop on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–29 January 2015; pp. 2181–2187. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Users | Items | Interactions | Entities | Relations | Triples |
|---|---|---|---|---|---|---|
| Last.FM | 1872 | 3846 | 92,346 | 9366 | 60 | 15,518 |
| MovieLens-20 M | 138,159 | 16,954 | 13,501,622 | 102,569 | 32 | 499,474 |
| Dataset | d | Su | Sv | λ | Lr | Batch-Size |
|---|---|---|---|---|---|---|
| Last.FM | 64 | 8 | 16 | 1 × 10−5 | 1 × 10−5 | 1024 |
| MovieLens-20 M | 64 | 16 | 24 | 1 × 10−5 | 1 × 10−5 | 1024 |
| Model | Last.FM | MovieLens-20 M | ||
|---|---|---|---|---|
| AUC | F1 | AUC | F1 | |
| CKE | 0.747 | 0.674 | 0.927 | 0.874 |
| KGCN | 0.802 | 0.708 | 0.977 | 0.930 |
| KGAT | 0.829 | 0.742 | 0.975 | 0.929 |
| CKAN | 0.842 | 0.769 | 0.976 | 0.929 |
| KGRFSF | 0.862 | 0.799 | 0.982 | 0.931 |
| Improve/% | 2% | 3% | 0.6% | 0.2% |
| Fusion Method | Last.FM | MovieLens-20 M | |||
|---|---|---|---|---|---|
| AUC | F1 | AUC | F1 | ||
| Other fusion methods | KGRFSF-aggsum | 0.844 | 0.779 | 0.974 | 0.924 |
| KGRFSF-aggconcat | 0.842 | 0.783 | 0.979 | 0.925 | |
| Feature space fusion method | KGRFSF-aggproject | 0.862 | 0.799 | 0.982 | 0.931 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Wang, X.; Wang, R.; Gu, J.; Li, J. Knowledge Graph Recommendation Model Based on Feature Space Fusion. Appl. Sci. 2022, 12, 8764. https://doi.org/10.3390/app12178764
Zhang S, Wang X, Wang R, Gu J, Li J. Knowledge Graph Recommendation Model Based on Feature Space Fusion. Applied Sciences. 2022; 12(17):8764. https://doi.org/10.3390/app12178764
Chicago/Turabian StyleZhang, Suqi, Xinxin Wang, Rui Wang, Junhua Gu, and Jianxin Li. 2022. "Knowledge Graph Recommendation Model Based on Feature Space Fusion" Applied Sciences 12, no. 17: 8764. https://doi.org/10.3390/app12178764
APA StyleZhang, S., Wang, X., Wang, R., Gu, J., & Li, J. (2022). Knowledge Graph Recommendation Model Based on Feature Space Fusion. Applied Sciences, 12(17), 8764. https://doi.org/10.3390/app12178764