1. Introduction
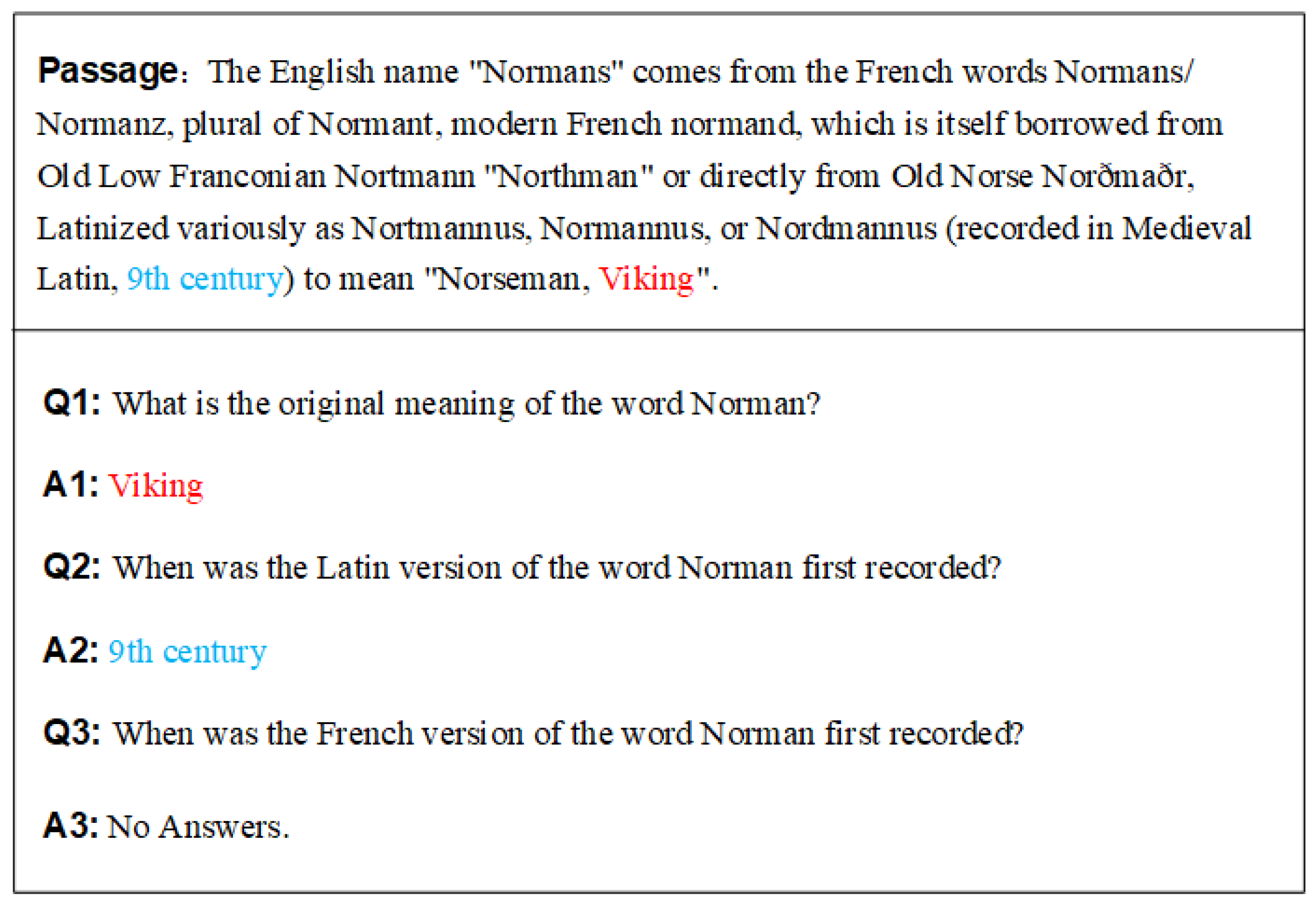
Machine reading comprehension (MRC) has long been a vital task in natural language processing (NLP). It refers to the ability of machines to read and understand a given text and answer questions based on it (as shown in
Figure 1). Better analysis and understanding of the meaning of a sentence has always been a challenge for researchers in natural language understanding (NLU). It is relevant in several ways, for example, in intelligent customer service and speech assistants [
1]. MRC has flourished, driven by the growing interest of researchers, as well as the public release of numerous datasets (for example, the Stanford Question Answering Dataset (SQuAD) [
2,
3]). Current MRC models are expected to perform the tough tasks of not only finding relevant answers to questions based on a certain text but also determining the questions that cannot be answered. For such models to be more adaptable to the real world, a deeper understanding of the text in conjunction with semantics and other information is required.
The prevalent methods based on traditional deep learning, such as BiDAF [
4], AoA-attention [
5], R-Net [
6], and QANet [
7], use the static word vectors GloVe [
8] or word2vec [
9] as word representations and multilayer neural networks to enhance the model’s understanding of the text and questions through continuous iteration and combine various attention mechanisms to enhance question-text relevance. However, the traditional word vector cannot address the problem of multiple meanings of a word. In addition, the attention module has a complex network structure, which makes it challenging for it to handle longer texts and causes several other problems, resulting in unsatisfactory MRC results.
Owing to the development of language models, the significant advances achieved in common language models can be used for various tasks [
10,
11,
12,
13], and surprising results have been achieved in MRC tasks. Yu et al. [
14] used convolution kernels of different sizes to convolute and pool the encoding of BERT, and used global information and local information to fuse to improve the accuracy of reading comprehension of Chinese datasets. Pre-training language models (PrLMs) use the concept of transfer learning to train models effectively on a large corpus of relevant tasks. In addition, the parameters are fine-tuned in terms of a specific task to further optimize the models. However, based on the structural limitation of a model, the text needs to be truncated based on the maximum text length acceptable by it, leading to the loss of semantics. Further, such models are also unable to learn long-distance semantic relationships between sentences, which leads to their inability to understand text and related questions accurately.
To accurately represent the text, several researchers have focused on semantics and syntax [
15,
16,
17,
18]. SG-Net [
19] explicitly considers syntactically significant words in each input sentence and selectively picks out such words to reduce the impact of noise caused by lengthy sentences. Parsing-All [
16] benefits from each other with syntax and semantics as joint optimization goals. Zhang et al. [
20] propose an approach based on semantic parsing to answer simple and complex questions and resolves ambiguity in natural language problems. Thus, a significant improvement has been achieved in syntactic parsing. Meanwhile, graph neural networks are beginning to be used for natural language task processing owing to their ability to model non-Euclidean spatial data. Fan et al. [
21] used a combination of dependent syntax and graph convolution neural networks to perform a sentiment analysis based on comments from Internet users. Yin et al. [
22] constructed parallel GCNNs and fused them with LSTM to extract graph domain features from feature cubes. Zheng et al. [
23] modeled text hierarchically at multiple-granularity levels and used graph attention networks to obtain various granularity representations to model the dependencies between the different granularities. Wu et al. [
24] propose a novel Hierarchical-Cumulative Graph Convolutional Network (HC-GCN) to generating Social Relationship Graphs for Multiple Characters in Videos
To make up for the inability of the MRC model to deal with the two shortcomings of long texts and intersentence semantics, such that the model can understand long texts and accurately discriminate the semantics just like humans, we propose a graph neural network to feature textual sentences and in-sentence entities. Based on the feature that the different levels of granularity contain different levels of semantic information, a vast variety of semantic information is integrated to make the model’s understanding of the various semantics accurate. Thus, whether a question is answerable or not can be effectively distinguished based on the granularity of the sentence. The start and end positions, which are immensely difficult to identify, can be obtained following multigranularity fusion. Experiments conducted on the SQuAD indicate that multigranularity syntax guidance (MgSG) outperforms traditional models in terms of both exact match (EM) and F score(F1).
The main contributions of this study are as follows:
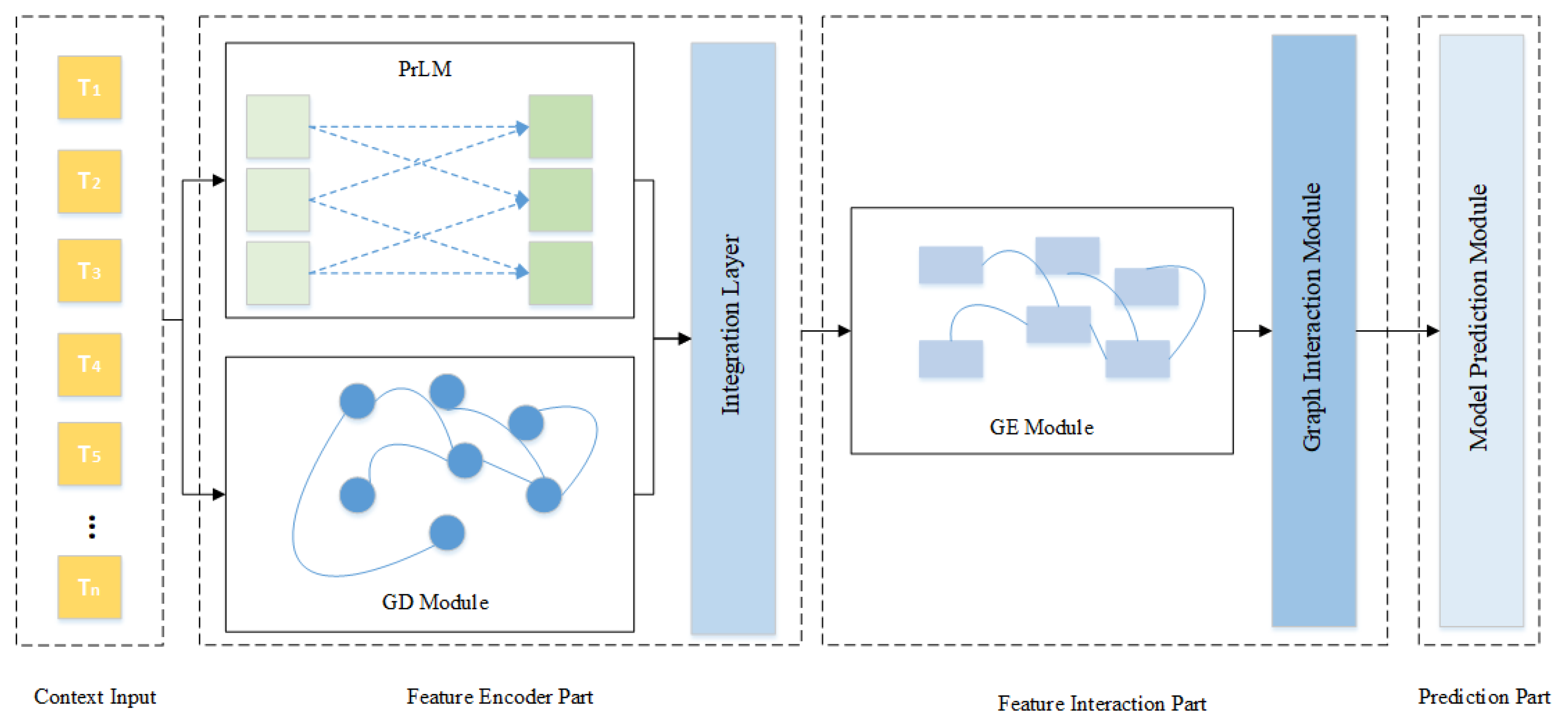
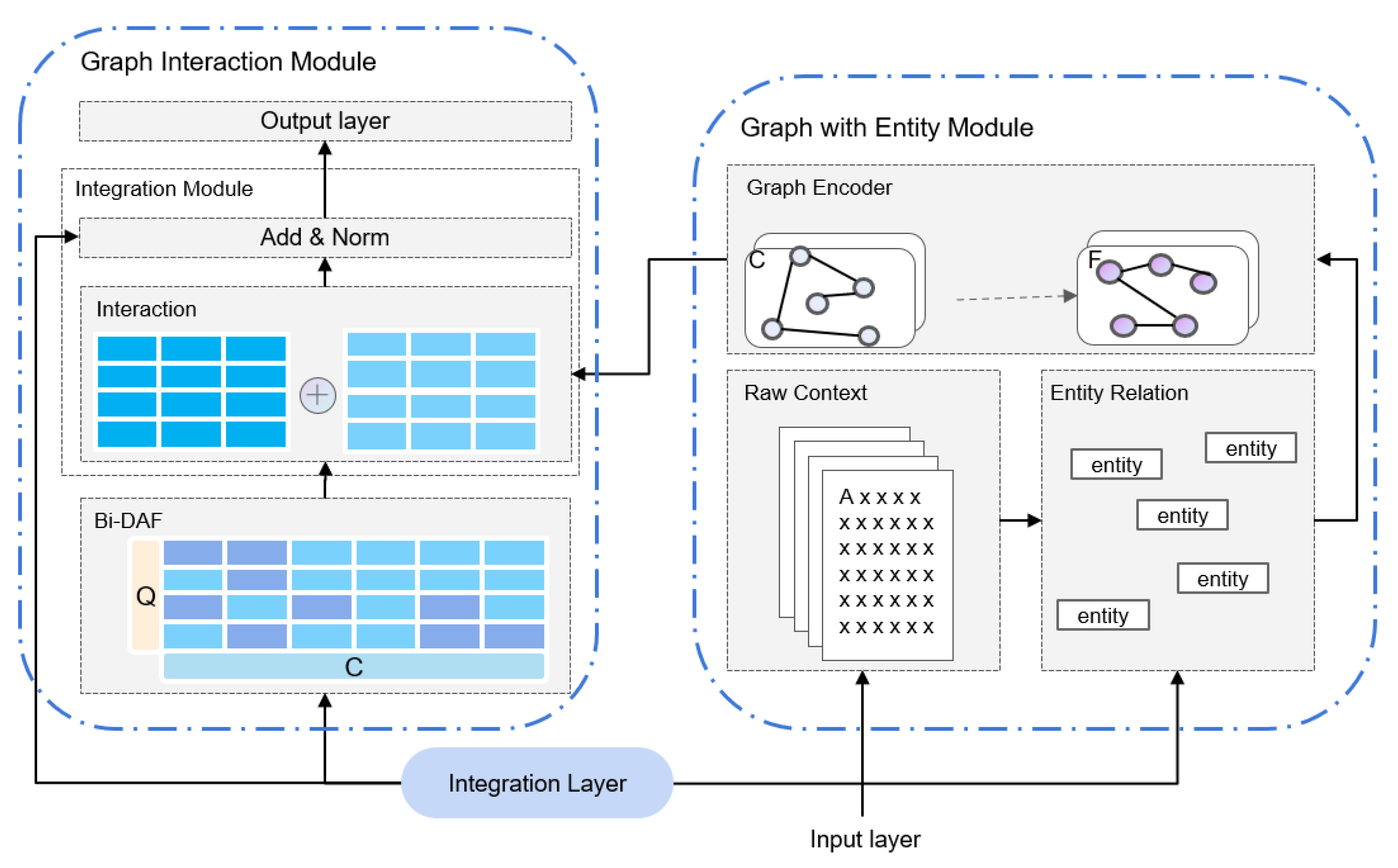
A new network structure, MgSG, is proposed. Based on the use of PrLMs to represent the text, combined with the graph structure, word and sentence granularities are used to obtain a text representation with richer semantics.
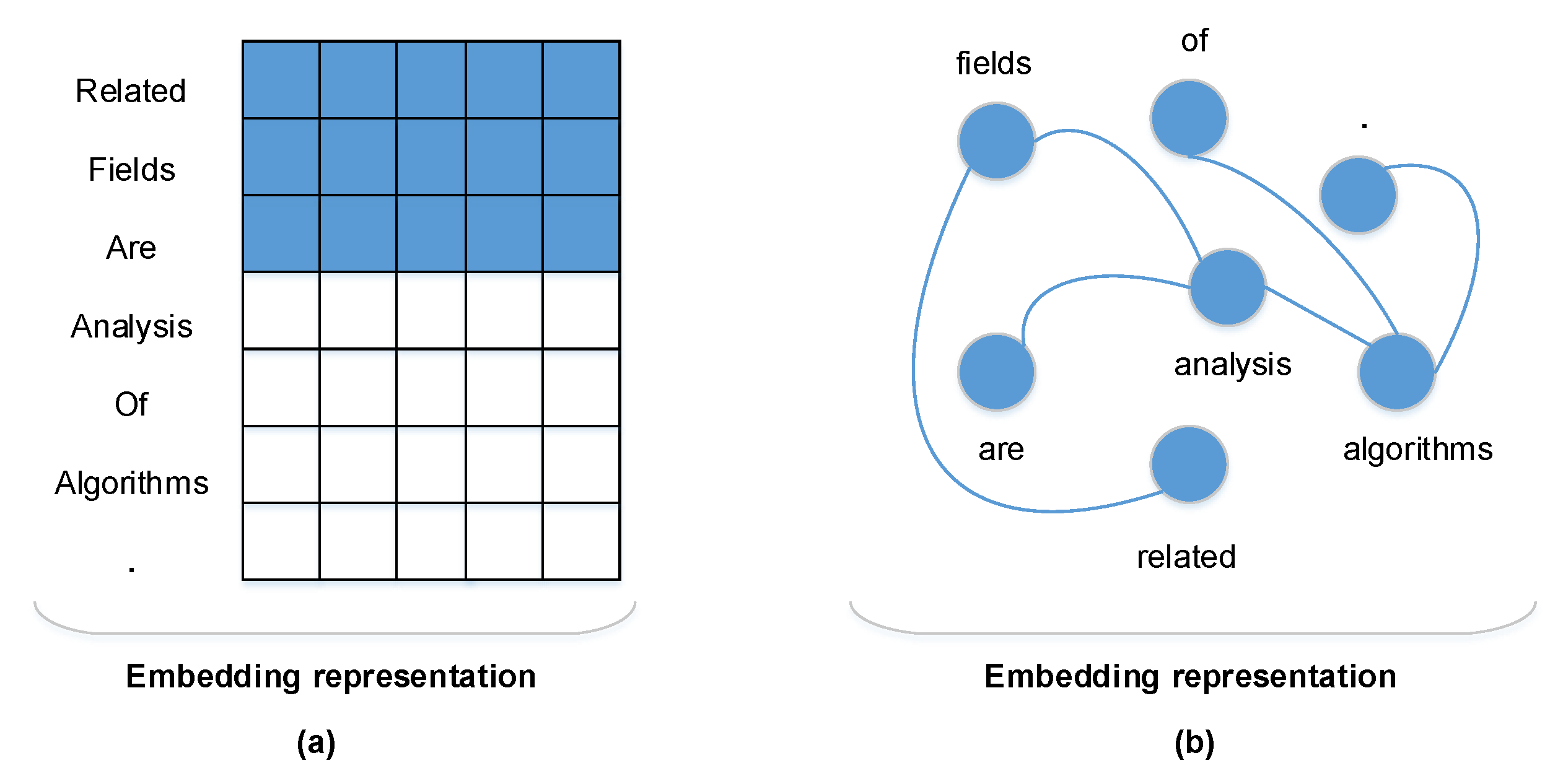
Two graph structure construction methods are designed using dependencies and named entities, and a filtering mechanism is proposed to integrate them to improve the accuracy of the overall text representation.
The role of the dependencies and named entities in reading comprehension tasks is analyzed, and it is demonstrated through experiments that both word and sentence granularities affect model performance. In addition, the two granularity representations are modularized to make them compatible with more models.
The proposed method is used for evaluation on the SQuAD and superior results are achieved in terms of both EM and F1 values when compared with the BERT-based reading comprehension model, demonstrating the effectiveness of the method.
The rest of the paper is organized as follows. Related work is summarized in
Section 2. The various components of the model proposed in the text are described in detail in
Section 3. The experimental results and analyses are presented in
Section 4. The analysis and discussion of the effectiveness of the proposed method based on experiments are presented in
Section 5. The conclusions are presented in
Section 6.
4. Experiment
In this section, we introduce our experiments in detail, including the experimental settings, datasets, evaluation metrics.
4.1. Setup
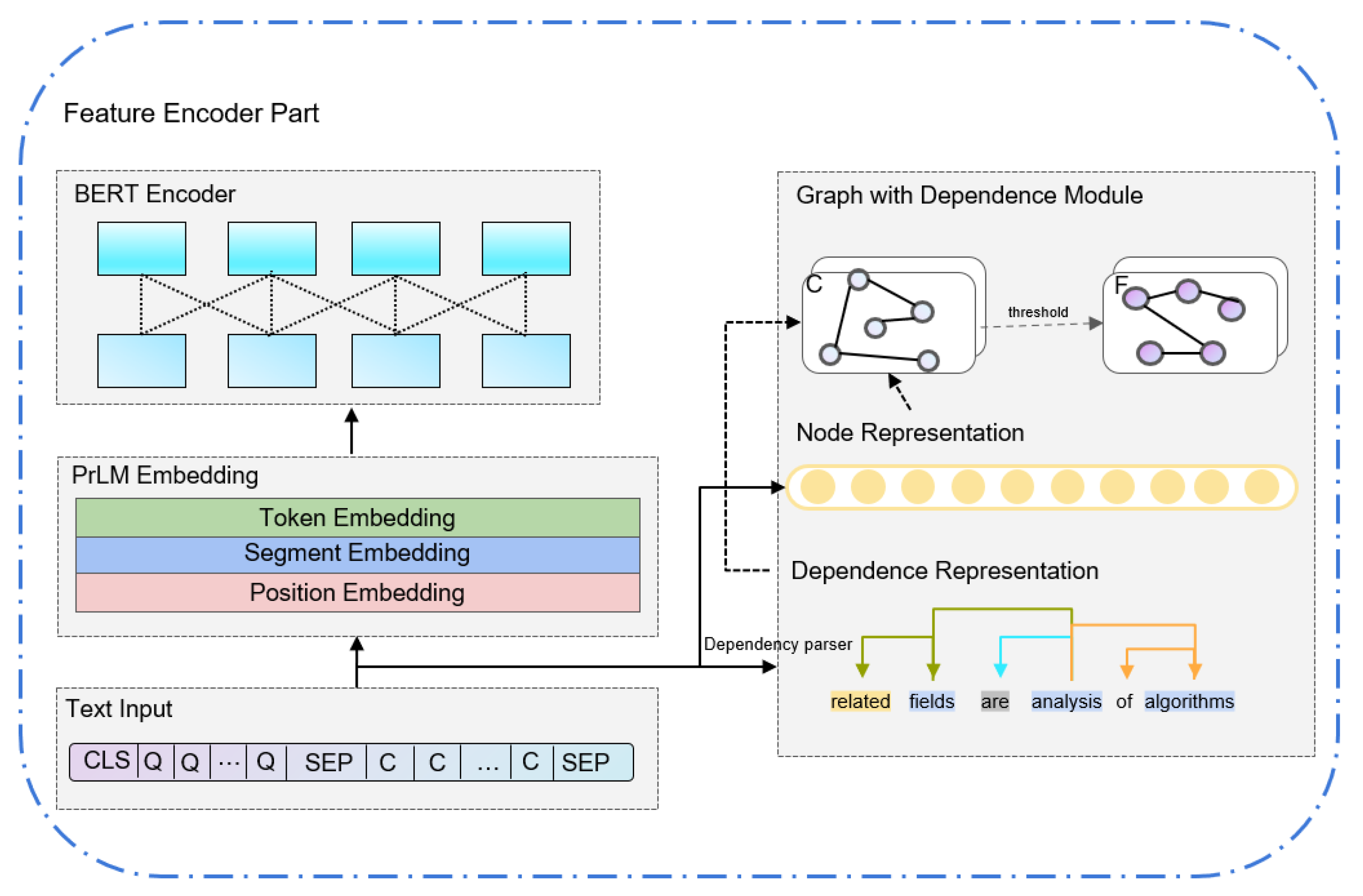
For the syntactic parser, we adopt the dependency parser from dependency parser (HPSG) [
48] through joint learning of the constituent parsing using the BERT model as the sole input, which achieves very high accuracy: 97.00% UAS and 95.43% LAS on the English dataset Penn Treebank (PTB) test set.
We use the available PrLMs as encoders to build the baseline MRC models: BERT and ALBERT. Our implementations of the BERT and ALBERT models are based on the public Pytorch implementation from Transformers. We use the PrLM weights in the encoder module and all the official hyperparameters. For the fine-tuning, we set the initial learning rate within {2 × , 3 × } with a warm-up rate of 0.1 and L2 weight decay of 0.01. The batch size is selected from within {8, 16, 32}. The maximum number of epochs is set to 4 for all the experiments. The hyperparameters are selected using the dev set.
4.2. Datasets
Our proposed model is evaluated on two MRC datasets: SQuAD2.0 and CMRC 2018 [
49].
SQuAD2.0 is an MRC dataset on Wikipedia articles with more than 150K questions. As a widely used MRC benchmark dataset, SQuAD2.0 is an upgrade of SQuAD1.1 with over 50,000 new and unanswerable questions that are written adversarially by crowdworkers to look similar to answerable ones. The training dataset contains 87 K answerable and 43 K unanswerable questions.
CMRC is a span-extraction dataset for Chinese MRC. This dataset consists of nearly 20,000 real questions annotated in Wikipedia passages by human experts. Before annotation, a document is divided into several articles, and each article is no more than 500 words in length.
4.3. Evaluation
The EM and F1 are used to evaluate the performance of the model at the token level. EM denotes the percentage of answers predicted by the model in the dataset that are the same as the ground truth. F1 denotes the average word coverage between the model-predicted answers and ground truths in the dataset.
5. Results and Discussion
In this section, we demonstrate the experiment results and analyze the reasons for the results.
5.1. Experiment Results
We present a comparison between the proposed model and the baseline models on the SQuAD 2.0 and CMRC 2018 dev sets, including three traditional methods and several fine-tuned methods based on PrLMs. The main results are presented in
Table 1 and
Table 2.
The results indicate that the proposed model combined with the various pre-trained models mentioned indicate varying degrees of improvement, some of which are significant. For the SQuAD dataset, comparing the same pre-trained models but with different sizes. Although the improvement of the large model is not as large as that of the small model, there is still a relatively obvious improvement. For example, the EM of BERT-large has increased by 0.5%. Compared with the large improvement of the small model, because the learning ability of the large model is strong enough, some grammatical relations have been learned, which leads to the fact that the additional feature information we have may have been learned, so compared with the small model, the improvement is not very obvious. Then, the improvement for albert-base+MgSG is better than that of BERT-large, and the amount of parameters is much smaller than that of BERT-large. This proves that the improvement of our module is more obvious for small models, which provides a new idea for model Lightweighting.
For the CMRC dataset, it can be seen from
Table 2 that the fusion of multigranularity features with the baseline model also effects a performance improvement of approximately 1% over the baseline model. However, CMRC is a Chinese dataset. Different languages bring different grammatical rules and semantics. Compared with Chinese grammar rules, English grammar rules are obviously clearer, and the semantic information contained in the dependencies of words is also clearer, which can greatly help the understanding of sentences. Therefore, the improvement of the model for English data is greater. Due to the grammatical structure of Chinese is more random and irregular, which makes it difficult for us to use the information contained in Chinese grammar accurately and correctly. On the other hand, it proves that our model can make good use of the hidden information contained in explicit grammatical structures and the use of weak grammatical structures is less stable.
5.2. Ablation Study
In this section, we describe certain ablation experiments that were conducted to demonstrate the validity of the proposed model. All the experimental baselines refer to the BERT base model except for the comparison of changes in variable.
To verify the effectiveness of our module, we separately added two modules to the baseline model. From the experimental results presented in
Table 3, we can see that when we add the GD module and the graph with entity (GE) module to the baseline, the performance of the model is significantly improved. Further, combined with the results presented in
Table 1, we understand that these two modules can improve performance when used alone, and they are compatible and improve each other’s performance when used together.
We also demonstrate the effectiveness of our proposed method with an example. As shown in
Figure 7, in the first example, the question is
What chemical did Priestley use in his experiments on oxygen? and the answer is obviously in the vicinity of the person named entity in the question in the paragraph, and then the BERT model. The answer was not predicted, and the answer suggested by our model was mercuric oxide. This shows that by constructing part-of-speech edges, the model can have a more specific goal in finding answers. The problem of the second example in
Figure 7 is
Which is one of the park features located in North Fresno?, the difficulty of this question is that it does not provide a very direct keyword,
North Fresno, feature can only provide the approximate location of the answer in the text and there are multiple misleading answers around. Our method can give the correct answer because it follows the grammatical structure and reinforces the hidden information contained in
Woodward Park as the subject of
which features the Shinzen Japanese Gardens, while BERT cannot.
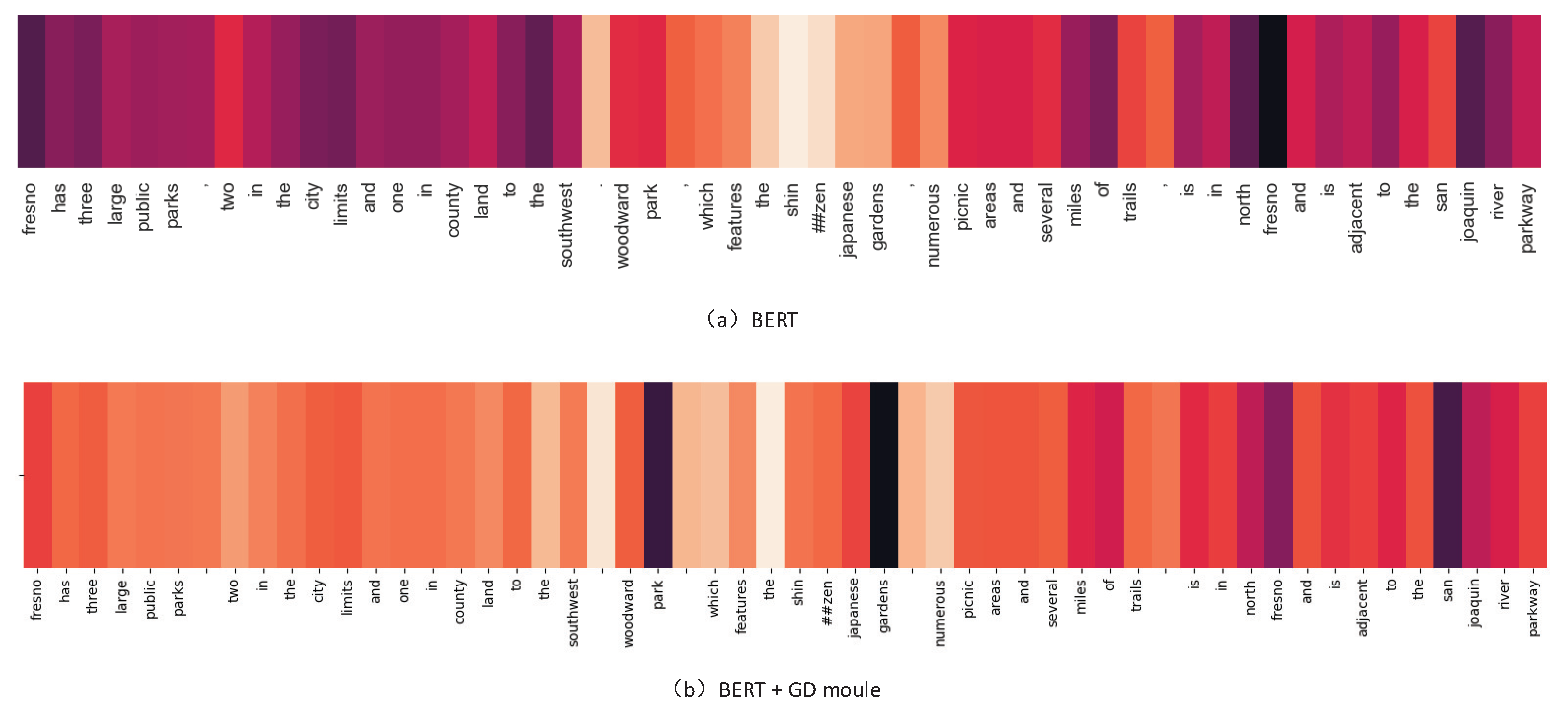
We also verify the effectiveness of the dependency syntax through experiments. We will first average the hidden state representations of the last layer of BERT and generate the corresponding heatmap (
Figure 8). We find that BERT is significantly more interested in regular subject position, but this is not where the answer comes from. We then summed and averaged the output of our module with the representation of the hidden state. The darker the color, the higher the impact. Due to the addition of dependency syntax, the attention of the model significantly weakens the position of the beginning, and is biased towards the parenthesis in the sentence, which is the source of the correct answer.
Further, as illustrated in
Figure 9 and
Figure 10, we present two different examples using the SQuAD dataset to demonstrate the effectiveness of the proposed method. For the example presented in
Figure 9, the answer is a name. In addition, not too many other named entities are present in this sentence. Therefore, the named entity granularity effectively reinforces the role of the answer in this sentence. When only named entity granularity is added to the model, the probability of predicting an answer improves by almost 2%. However, when the only dependency granularity is added, model is 1.6% less likely to predict an answer. The reason for such results is that the syntactic complexity of the sentence is too high because it contains multiple clauses, causing the model to focus too much on the relationship between the sentences and not pay attention to the answer. When we add both granularities to the model, it still has a positive effect on the prediction of the answer. This is consistent with the data presented in
Table 1.
Figure 10 presents another form of the answer, which itself increases the difficulty of the model predicting the answer when the answer is a sentence. When there are a few named entities in the sentence, there is a high probability that they will occur in the answer. In this example,
solutions and
resources are reinforced. The dependency relationship plays a more significant role in this example, and this specific dependency relationship analysis is illustrated in
Figure 7. The results obtained from these two examples demonstrate the effectiveness of the proposed method.
5.3. Discussion
In this section, we present a deep analysis of the effect of extensions to named entities for the various parts of speech and multiple parameters with dependencies on the performance of the model.
First, we experimented with and analyzed the relationship between the number of layers and the performance of the graph neural network in which the dependencies were located. Further, to verify the effect of graph sparsity, we analyzed the values of the dependency threshold and the categories of the named entity. The experimental results are presented in
Table 4,
Table 5 and
Table 6.
Table 4 indicates that as the number of dependent layers increased, the F1 value of the model steadily increased from layer 1 to 4. This result suggests that more interword relationships can be obtained by interfusing pairs of nodes at further layers, forming a better understanding of the sentences. However, as the number of layers increases to 5, the evaluation index decreases. Thus, the experimental results suggest that when the number of layers of dependencies increases to a certain number, it is counterproductive to learn interword relationships after the model has already learned them.
Further, as presented in
Table 5, we analyze the effect of dependency thresholds on the performance of the model. We argue that when there are only a very few words in a sentence as a collection of subwords, the words in this collection should not represent the meaning of the sentence; a higher number of subwords are more representative of the meaning of the sentence. The experimental results also verify our conjecture that such a fusion will instead affect the performance of the model when the dependency threshold is 0, that is, when all the words have dependencies. When we increased the threshold to a certain value, we obtained the best balance.
This experiment proves the correctness of our extended entity range. By adding different entity types, we found that although the expanded entity types do not account for a high proportion of the overall dataset, the numbers usually contain extremely high information in a piece of text, and even some answers are numbers. In addition, we also thought that some pronouns actually sometimes refer to some entities, and in some sentences, entities are omitted and pronouns are used. However, when we added the upper pronoun, the results were lower. The main reason is that the number of words that pronouns can refer to is too large, and the referential relationship is very difficult to handle. This leads to the reason for the performance degradation caused by adding pronouns.
6. Conclusions
This paper proposes a MRC model that combines graph neural networks with multiple-granularity semantic fusion. The model takes advantage of the graph network structure that can link long-distance nodes using sentence dependencies and entities as two important features to help PrLM with a smaller number of parameters to obtain more accurate text and question representations by adding fewer parameters and computational cost. Using the BERT as the baseline model, MgSG achieves significantly better results than the baseline model on the SQuAD2.0, demonstrating that MgSG has a significant impact on MRC. At the same time, we also found that our method can better learn explicit grammatical structures or clear grammatical structures (such as English). This provides new ideas for future research on model lightweighting and analysis of syntactic semantics.
In the future, we will try to use other graph structures(i.e., graph-to-sequence models) to learn more features and delve into how to make the model better understand data with unclear grammatical structures, such as Chinese, to achieve a better understanding of the text.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}