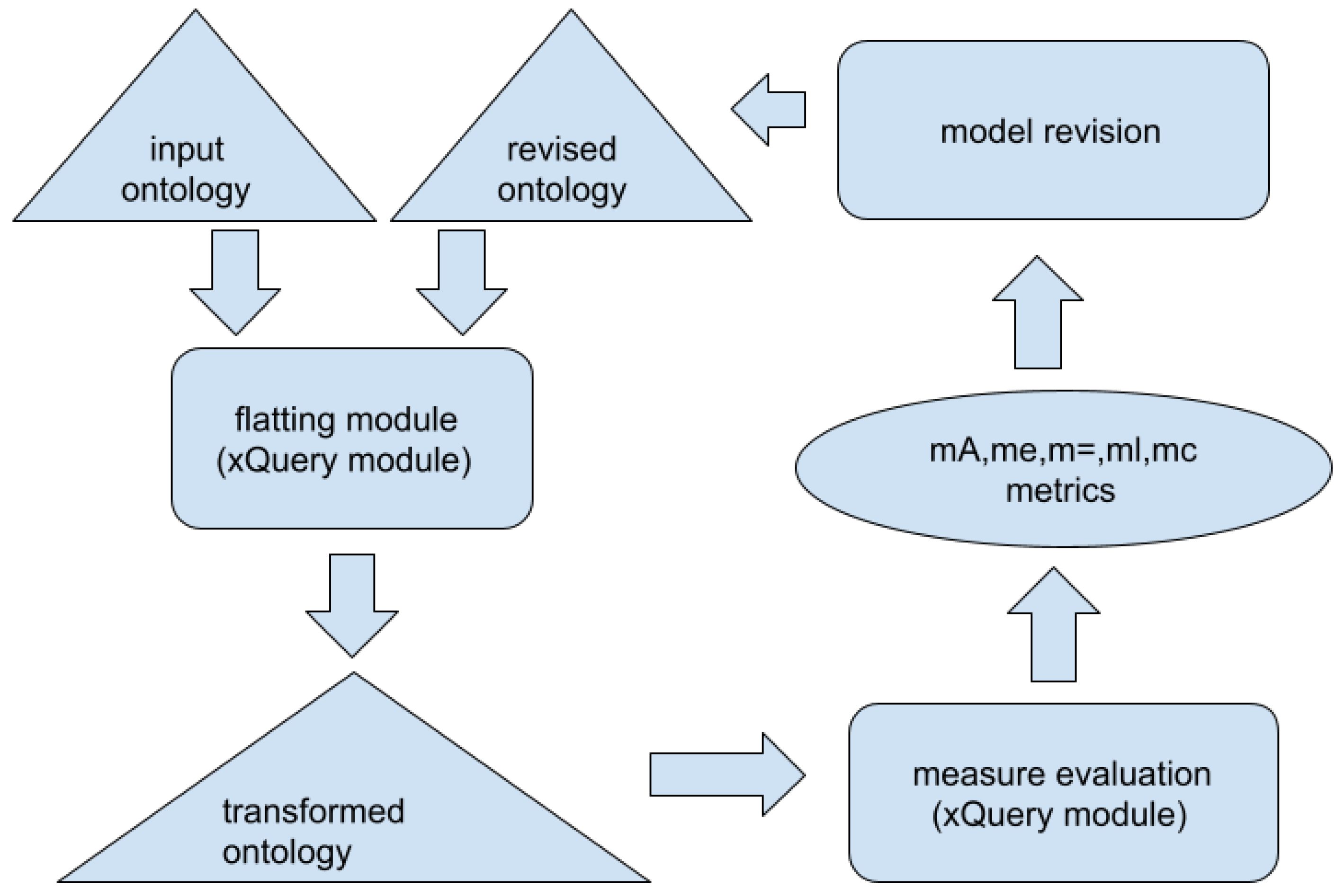
4.1. Formal Model
In this section, we introduce a property-based ontology description approach for OWL ontologies. The input ontology model is provided by
where
: the set of concepts;
: the set of individuals;
: the concept taxonomy relationship (acyclic);
: the set of properties, where denotes the value set of property p; The properties can be used as follows:
- -
in individual assertion triplets , in which case the value of p is equal to v and ;
- -
in class axioms of the following forms:
- ∗
p domain c ( or )
- ∗
- ∗
where the symbol v denotes the value of property p;
: type assignment to the individuals.
Starting with the input ontology, the first step is to generate the related set of base properties, where every property–value pair found in the ontology corresponds to a base attribute:
We can extend the attribute set with generalization of the property values:
For an arbitrary and , the symbol is true if individual i meets property a. The attribute notation is true only if, for some value v, that property is met. In this case, the value of the property is not important.
In the next step, we introduce a new attribute property mapping:
where
The set
corresponds to the intent set of the formal concepts in FCA. In order to determine the
sets, we perform a sequence of specialization and generalization steps. In the case of specialization, the properties of parent concepts are inferred to the lower levels, that is, to the descendant concepts. The explicit specialization process is based on property-oriented class axioms in the ontology. Having an axiom
or
, we can conclude that
If
, then
is met as well. The specialization process terminates when all of the individuals are processed. Thus, an updated
set is obtained for every individual. The result is a context in which the objects correspond to the individuals. A row related to individual
i contains the elements of
.
As an example, let us take the following ontology fragment:
<DataPropertyAssertion>
<DataProperty IRI=‘‘#color’’/>
<NamedIndividual IRI=‘‘#chair1’’/>
<Literal datatypeIRI=‘‘PlainLiteral’’>brown</Literal>
</DataPropertyAssertion>
<DataPropertyAssertion>
<DataProperty IRI=‘‘#age’’/>
<NamedIndividual IRI=‘‘#peter1’’/>
<Literal datatypeIRI=‘‘integer’’>12</Literal>
</DataPropertyAssertion>
<DataPropertyAssertion>
<DataProperty IRI=‘‘#name’’/>
<NamedIndividual IRI=‘‘#peter1’’/>
<Literal datatypeIRI=‘‘PlainLiteral’’>Peter</Literal>
</DataPropertyAssertion>
<DataPropertyAssertion>
<DataProperty IRI=‘‘#age’’/>
<NamedIndividual IRI=‘‘#employee1’’/>
<Literal datatypeIRI=‘‘PlainLiteral’’>old</Literal>
</DataPropertyAssertion>
<DataPropertyAssertion>
<DataProperty IRI=‘‘#name’’/>
<NamedIndividual IRI=‘‘#employee1’’/>
<Literal datatypeIRI=‘‘PlainLiteral’’>Tom</Literal>
</DataPropertyAssertion>
<DataPropertyAssertion>
<DataProperty IRI=‘‘#age’’/>
<NamedIndividual IRI=‘‘#dog1’’/>
<Literal datatypeIRI=‘‘PlainLiteral’’>old</Literal>
</DataPropertyAssertion>
The related property set contains the following elements:
= (#color, braun)
= (#age, 12)
= (#name, Peter)
= (#age, old)
= (#name, Tom).
The generated context table is shown in
Table 1:
During the generalization process, we apply the following rule borrowed from the closed world assumption: if an attribute
a is valid for every child concept of
c, then the attribute is valid for
c. This approach is used in FCA modeling as well, among others. In the generalization step, the attribute sets of the concepts are updated, starting with the individuals. For a concept
c, the set of related attributes is calculated in the following way:
In the intersection operation, we use the following value level generalization step. If we have two attributes related to the same property (p) that have different values, we construct an attribute . This attribute means that the item has a property p with any value.
We distinguish two domain sets for any attribute a:
A concept
c is an element of the inferred domain of attribute
a if
We assume that both domain sets contain the ⊤ concept as well, i.e.,
and
. The domain set is equal to the union of the declared and inferred domains
After constructing the attribute sets for every concept and individual, the following consistency check can be performed:
For every concept, the attribute set cannot be empty, i.e.,
Different concepts must have different attribute sets, i.e.,
Domain axioms of the form ’’ are assigned only to those concepts c which meet the condition that every individual or concept having the given attribute are subconcepts of c : .
If the generated ontology would hurt these rules, then the ontology design expert must update and improve the initial ontology. These rules ensure that the every concept has a corresponding and unique attribute set similar to the FCA approach.
4.2. Property-Based Metrics
The property-oriented ontology model provides an opportunity to introduce specific property-based quality metrics for ontologies. The main principle is that the property distribution in the taxonomy must be well balanced and consistent. To measure this quality, we propose the following measures:
: the relative number of the properties. If the value is lower (near or below 1), there are too few properties. If the number is too high, most of the properties are not used in the taxonomy construction.
: the ratio of concepts with empty local (not inherited) property sets. From the viewpoint of FCA, if this value is greater than 0, then the ontology is invalid.
: the ratio of concepts having non-unique properties set. From the viewpoint of FCA, if this value is greater than 0, then the ontology is invalid.
. This measures shows the average length of the local (not empty) property sets. A high value means that many attributes are not relevant in the taxonomy construction.
: This value shows the total distance between the declared and inferred domain concepts. The distance function is defined as the length of the shortest path in taxonomy graph between the elements. In the best case, is equal to 0.
As an example, we compare two schema descriptions; the first is an ontology oriented model, while the second is example of the UML-OOP model.
In this example, we first take a sample ontology found on the internet [
41]. For the sake of simplicity, we use only the following concept taxonomy fragment:
Person
Employee
Professor
AssistantProfessor
AssociateProfessor
Lecturer
Assistant
Student
UndergraduateStudent
GraduateStudent
Organization
EducationOrganization
Department
Program
Course
Seminar
The list of related properties in the ontology, where the first argument denotes the declared domain and the second argument, is the range parameter.
advisor(Student, Professor)
affiliateOf(Organization, Person)
affiliatedOrganization(Organization, Organization)
alumnus(Organization, Person)
emailAddress(Person, .STRING)
head(Organization, Person)
listedCourse(Program, Course)
name(Person, .STRING)
takesCourse(Student, Course)
teacherOf(Department, Course)
The ontology schema does not contain any individual declarations; thus, the set contains only the ⊤ concept for every attribute a. The proposed metrics have the following values for this sample ontology:
.
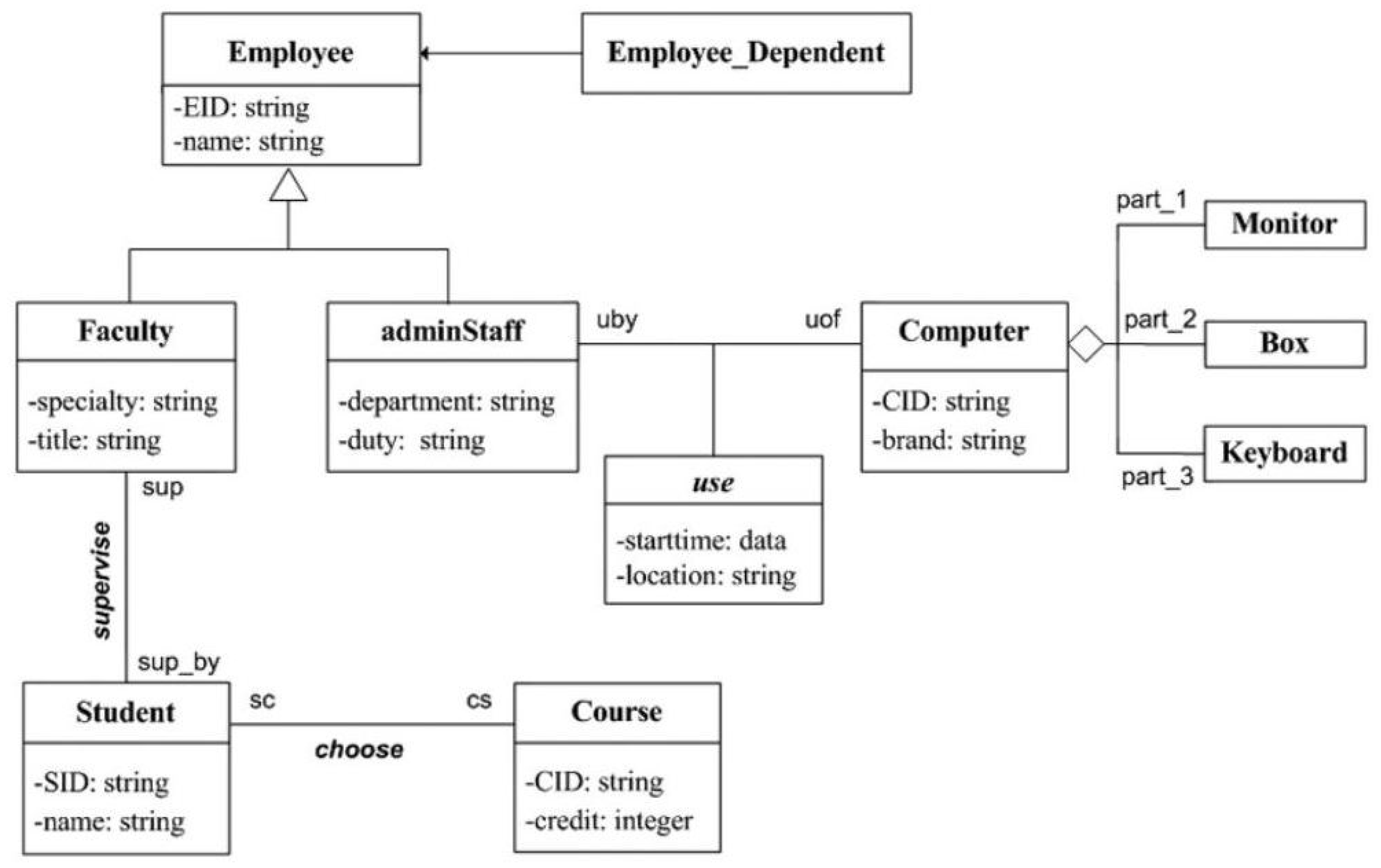
The second example schema is the UML class diagram presented in
Figure 2. If we consider this UML diagram as an ontology model, we have the following metric values:
.
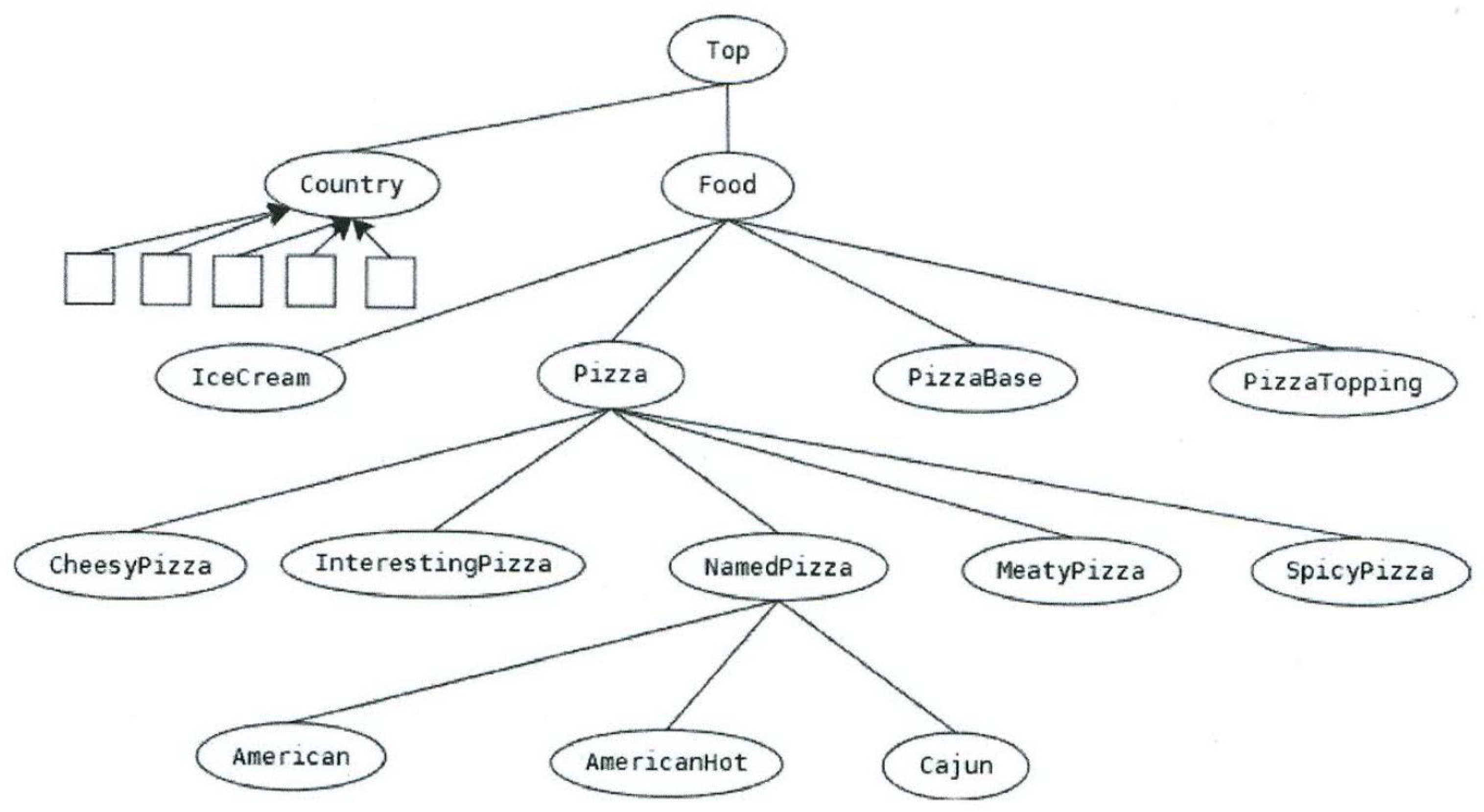
The third example is the standard pizza ontology [
43] presented in
Figure 3. The presented reduced ontology contains only fourteen concepts, while the depth of the taxonomy hierarchy is 4. The ontology contains three properties. The first step of ontology processing is to generate the corresponding properties. In this reduced ontology, fifteen attributes were generated from the properties. In the specialization process, eight concepts were extended with inherited attributes (the most widely used derived attribute is ’hasBase some PizzaBase’). In the subsequent generalization phase, the ’NamedPizza’ concept is extended with three new attributes. The resulted ontology can be characterized by the following measures:
The fourth example is a large-scale Java project, the source code of the Apache Jena framework (
http://jena.apache.org/, (accessed on 26 October 2022). The framework contains 5881 Java source files. We have implemented a class analyzer application using the Reflection API to extract the class definitions. We identified 6264 classes for further analysis. The class/data member/method structure is considered here as a concept/attribute structure. In the processing method, the following simplifications were implemented:
The data types and signatures in attributes and methods are ignored;
All attributes and methods are assumed to be public;
The embedded classes are ignored.
From all source files, we extracted the following data:
name: fully qualified name of the Java class
attributes: attribute names
methods: method names
parent: name and package of the parent class
implements: list of interfaces which has implemented in the given class.
The names of the classes are not necessary unique; therefore, it is necessary to consider the fully qualified names of the classes. The main characteristic parameters of the Jena Apache framework source code is summarized in
Table 2.
The attribute-level quality of the Apache Jena framework can be provided by the following parameters:
4.3. Property Relevance
The investigation of attribute relevance is a standard method in data mining, especially in the classification domain, where the correlation between the attribute and the target variable determines the importance of the attribute [
44]. The relevance ordering of the attributes can be used, among others, in data reduction or data representation. If we consider the FCA approach, we can see that in FCA every attribute has the same importance, and all possible formal concepts are contained in the generated concept sets. In practical applications, only a small subset of concepts is used and recognized. The selected concepts have a larger practical importance, however. This simplified concept model is represented in the semantic models constructed for the application programs; thus, the generated schema should express the relevance value of the involved concepts. Applying this idea to the constructed ontologies, we can introduce an importance measure for the attributes and properties.
In FSA, for every attribute
a there exists a concept
c, where
This concept meets the condition
This concept is the unique suprenum of attribute a. In ontology or other schema modeling, this concept c may be missing. In this case, attribute a may be less important than the attributes with a unique suprenum in the ontology.
Based on this consideration, for a property
p in the ontology we can define the relevance factor
as
Symbol means that the property part of a is equal to p. This measure shows how far the suprenum concepts of a are from the optimal position. In the best case, the suprenum of every attributes related to p is the child node of the top element. In this model, a lower value means a higher importance.
Here, we take the properties defined in the reduced pizza ontology (
Section 4.2). Based on the generated property-oriented ontology representation, we obtain the following relevance values:
Based on calculations, the property hasBase has the largest importance in the presented example ontology. The property hasTopping has a relatively high importance as well, while hasCountryOfOrigin is a property with low importance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}