1. Introduction
A challenging problem in neuroimaging is to estimate directed connectivity between brain regions reconstructed from scalp EEG recordings but important to unveil their joint dynamics. Due to volume conduction, a given EEG electrode can pick up signals from several sources simultaneously, distorted along the way due to the presence of tissues with different electrical properties. Resolving these sources is called the “inverse problem”, and it consists of estimating the source parameters given the scalp EEG recordings. The number of sources is higher than the number of electrodes, rendering an ill-posed problem. Valid brain connectivity estimation critically depends on the correct localization and time series reconstruction in this stage. Several localization methods have been proposed, often yielding differing outcomes. In a comprehensive set of simulations, [
1] studied the influence of several inverse solutions, the depth of the sources, their reciprocal distance, and the Signal-to-Noise Ratio (SNR) of the recordings. They found that all these factors had a significant impact on the resulting connectivity pattern and that the number of spurious connectivity estimations depends heavily on the combinations of these factors.
In addition to the said factors, the choice of the connectivity estimator also has a significant impact. Our interest lies in directed connectivity estimation, of which partial directed coherence [
2], dynamic causal modeling [
3], structural equation modeling [
4] and (conditional) Granger causality (GC) [
5] are well-known methods. However, they rely on statistical assumptions that usually do not hold for EEG data, such as linearity [
6], stationarity and prior assumptions on connectivity being expressible as a relation between time series. However, even though some of these assumptions are violated, these methods still are best practice cases of directed connectivity estimation. In what follows, we focused on variations in traditional Granger Causality, given that it does not rely on an a priori assumed connectivity pattern. Granger Causality is a statistical hypothesis used to determine temporal causal effects between two time series. If the past of a second time series (Z) together with the past of a first time series (Y) (i.e., the “full” model) results in an improved prediction of the future value of the first time series, then the past of the first time series alone (the “reduced” model), it is said that time series Z “Granger-causes” Y.
Two main problems with this bivariate model can be discerned. Firstly, bivariate GC does not account for other time series that may be causing both Y and Z, resulting in spurious connectivity patterns. Secondly, even when bivariate GC is extended towards multiple time series by conditioning on these other variables, it is still possible that the found influence is actually caused by a linear mixture of non-interacting sources. This is because the signal measured from one electrode usually contains contributions of several sources [
7]. Important to note is the proposal of Time-Reversed Granger Causality (TRGC) by [
8], further validated by [
7], to reduce the impact of additive correlational noise due to source mixing. The idea is that when connectivity is based on temporal delay, directed connectivity should be reversed when the temporal order is reversed. Concretely, it is checked whether the obtained GC scores for non-reversed and reversed data have opposing directions and are both significant [
1]. This is clearly different from a classical way to determine significance (i.e., a likelihood ratio test). Hence, the main difference between TRGC and traditional GC is the proposed significance procedure. Still, even with TRGC, errors in connectivity estimation are here to stay. The question remains whether a totally different approach could cope with the above-mentioned problems and could perform better, or at least equally well, in comparison with the standard approaches. Artificial Neural Networks (ANNs) were considered as particularly interesting candidates given their flexible way of approximating highly non-linear relationships between variables [
9] and the fact that no a priori assumptions need to be made about signal stationarity nor the connectivity pattern (for a clear overview, see [
10]). Temporal convolutional networks (TCNs), as well as recurrent neural networks (RNNs), are usually well-suited architectures for time series [
11,
12,
13,
14,
15]. While RNNs are often seen as the gold standard for sequence modeling, TCNs have also proven their suitability, for instance, in financial forecasting [
14], electric power forecasting [
16] and language modeling [
17]. However, it remains unclear whether ANNs can signal the presence or absence of connections and their strength. Although some authors already used ANNs to derive directed brain connectivity with multilayer perceptrons and recurrent networks [
15,
18], these approaches did not include source-reconstructed EEG data. As stated before, unlike EEG source reconstruction, analyses based on EEG electrode levels do not allow for trustworthy inferences about interacting regions [
19]. Hence, the suitability of ANNs in deriving directed connectivity between reconstructed EEG sources remains unknown.
Our motivation to assess ANNs for directed connectivity estimation between reconstructed EEG sources was two-fold. First, although many connectivity estimators exist, it is not yet known which current ANNs architectures can cope better with source-reconstructed EEG activity and under various circumstances. The authors of [
1] were the first to conduct a comprehensive simulation study on the influence of dipole location, noise level, inverse solution and connectivity estimation, as well as the interactions between these factors. It was shown that different circumstances call for different analysis pipelines and that under advanced noise levels and for particular dipole configurations, even well-established methods such as TRGC can return aberrant connectivity estimates. Second, ANNs boast several appealing modeling properties that are potentially relevant to EEG modelers, such as the ability to deal with non-stationarity, non-linearity and, depending on the ANN architecture, to dispense with the prior specification of model order.
In order to assess the ability of ANNs to correctly signal the presence or absence of directed connectivity as well as connectivity strength, we compared several ANN models, including Conv2D, a novel ANN model we propose, with TRGC. We compared their performance for different dipole locations (i.e., Far–Deep/Far–Superficial) as this can inform us whether there is a future for ANN models in brain connectivity estimation. In addition, we evaluated the ANN models relevant for directed connectivity estimation. We investigated these issues by means of a simulation study, thereby making use of a slightly adapted version of the simulation framework developed by [
1] in which we manipulated the location of the dipoles and their connectivity while keeping noise level and the choice of the inverse solution constant.
2. Materials and Methods
2.1. Simulation Procedure
The simulation framework developed by [
1] was used to generate simulated EEG data originating from three dipoles. This data generating process, as well as the forward and inverse problems, were implemented in MATLAB (2020).
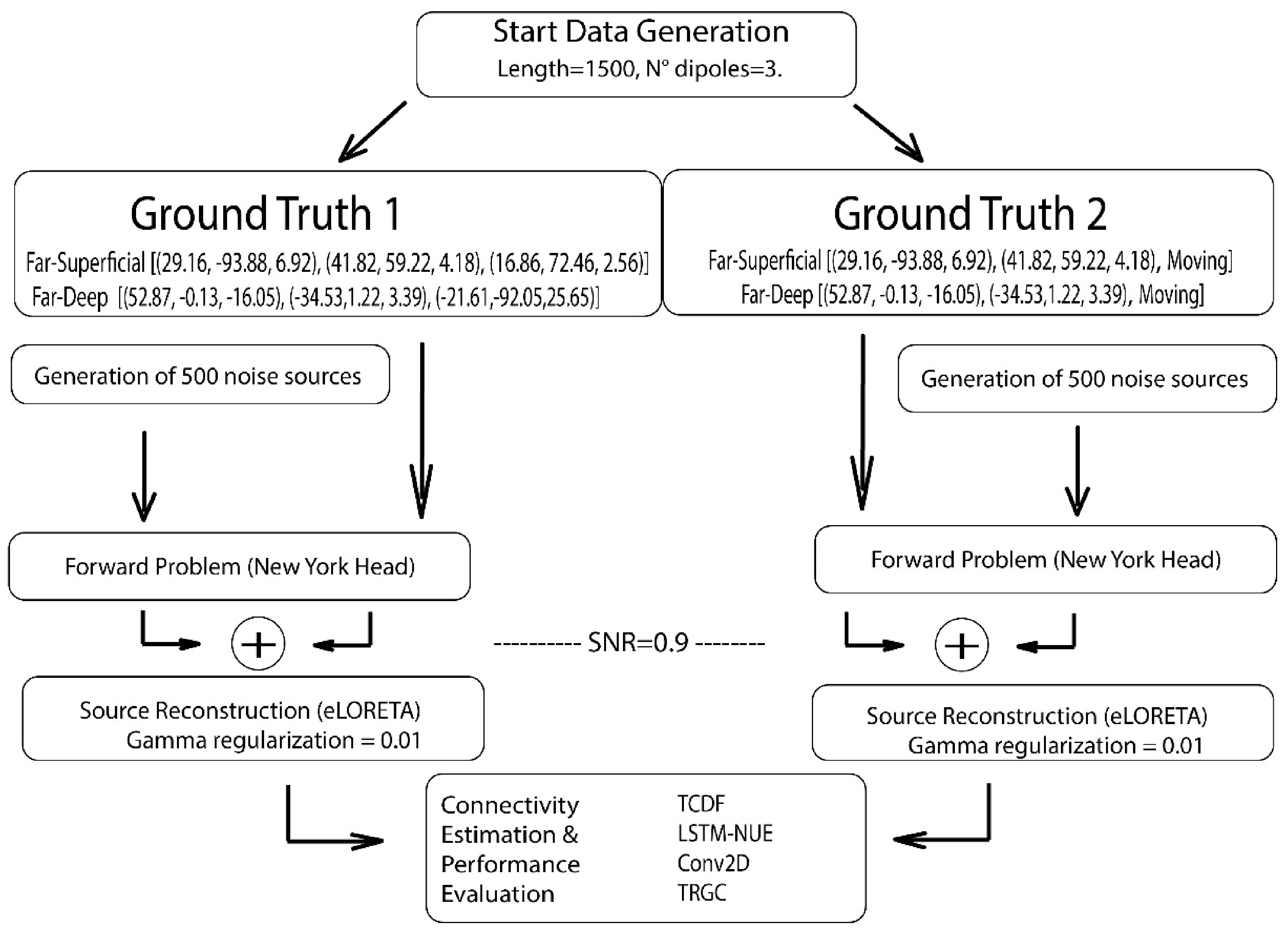
Figure 1 shows the data generation procedure. The standard length of each generated series was 1500 time steps for Ground Truth 1 and 2.
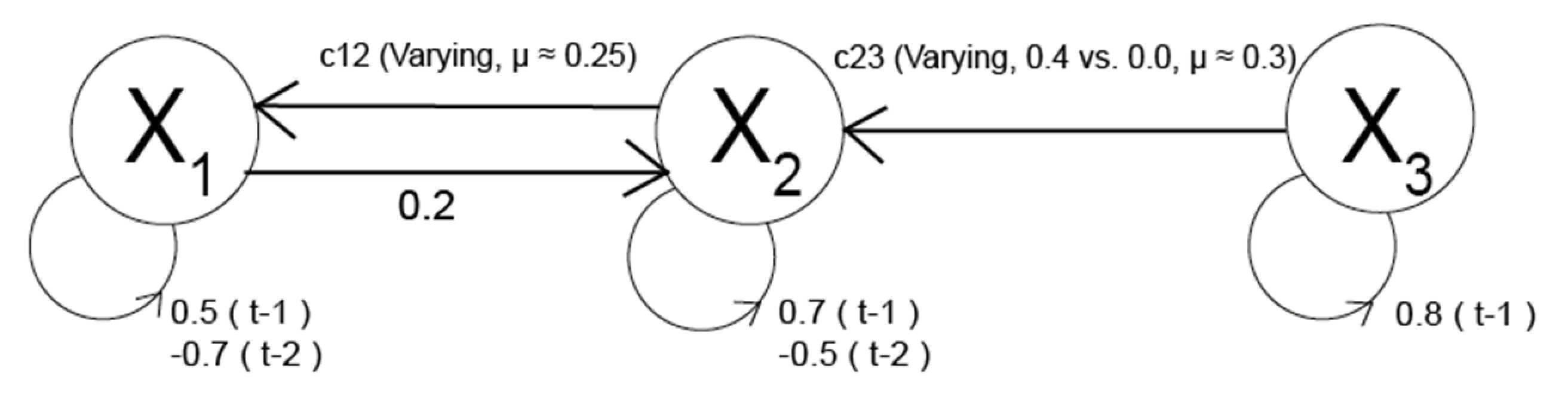
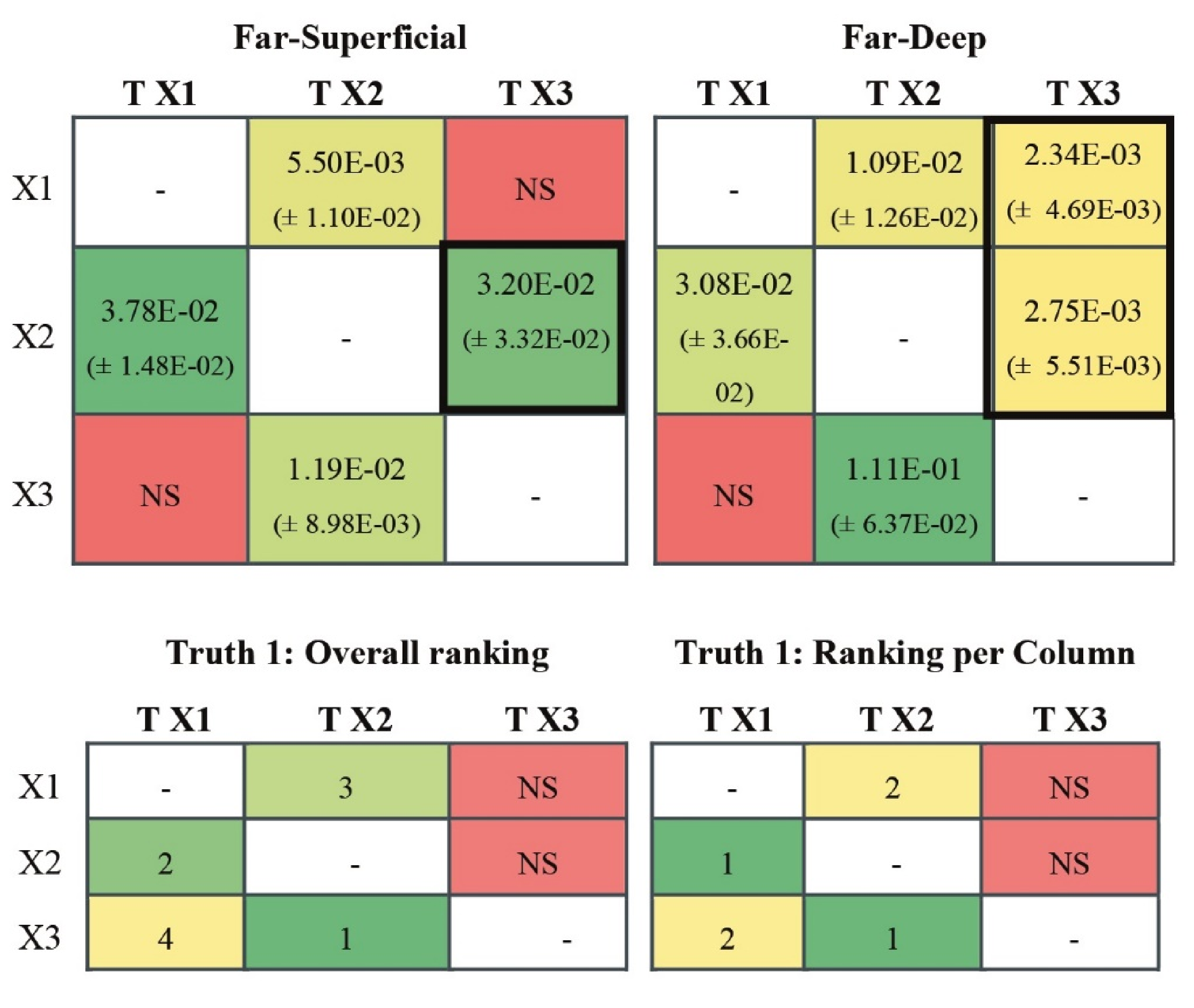
In Ground Truth 1, three fixed dipoles were used with the directionality of the connections as well as their strength being imposed (
Figure 2), a strategy used before [
20,
21,
22]:
with
X1,
X2 and
X3, three electrical sources contributing to the simulated scalp-EEG signals and with:
L = length of the generated time series (L = 1500), t = the current time step and ɛ = uncorrelated white noise, varying with time. We further assume an EEG cap with 108 electrodes.
Figure 2.
Ground Truth 1 with three fixed dipoles.
Figure 2.
Ground Truth 1 with three fixed dipoles.
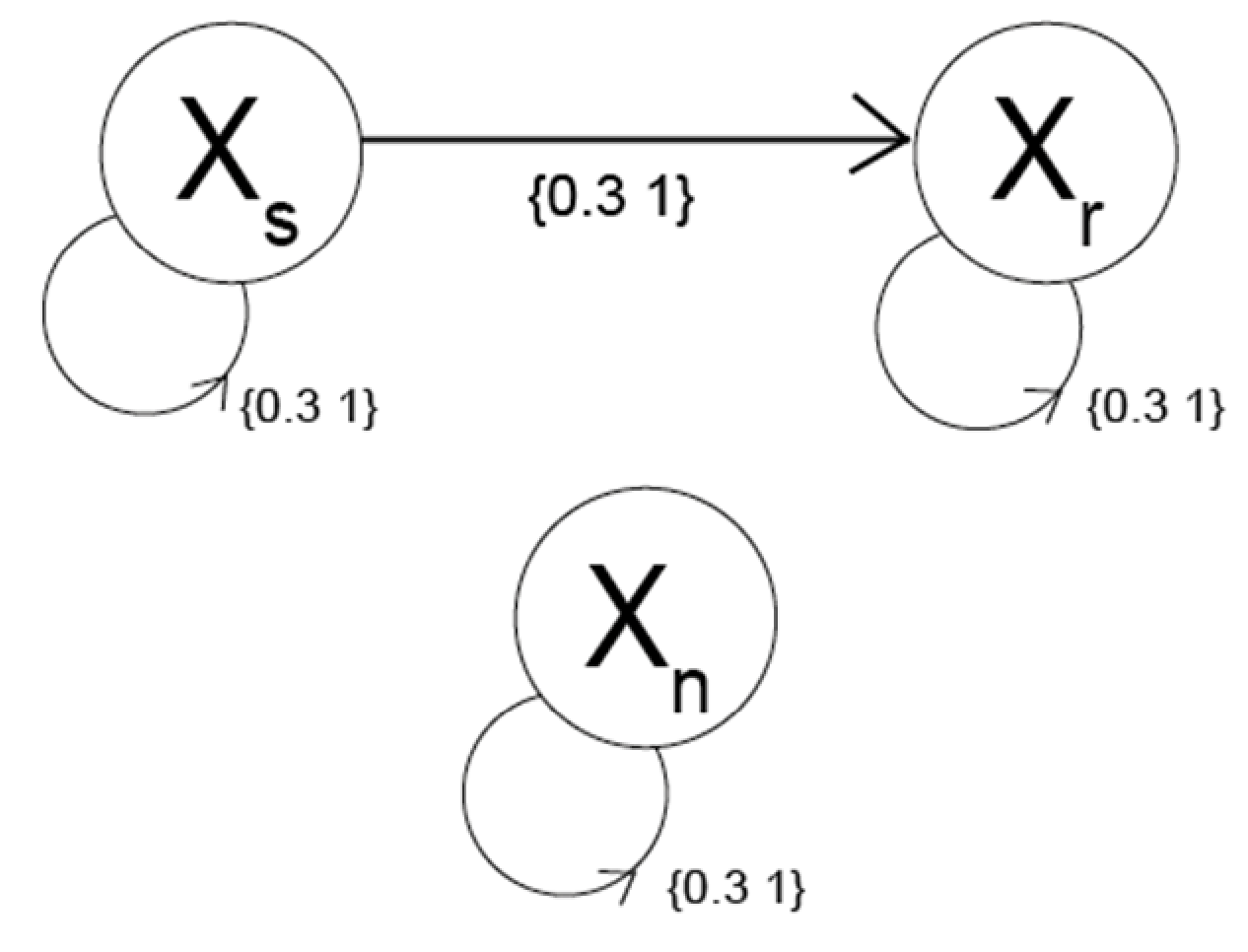
For Ground Truth 2, we considered two fixed, one moving dipole and only one true connection (
Figure 3) and focused on the presence or absence of this connectivity as well as its directionality:
with
Xs, the moving dipole, as a sender, and two fixed dipoles, with
Xr the receiver and
Xn the fixed non-interactive dipole, and
aij (
p), i, j ϵ {1, 2, 3} and
p ϵ {1, …, P} the coefficients with
a21 the coupling strength between sender and receiver. All
aij are randomly picked from the interval [0.3, 1]. Finally, ϵ is uncorrelated, biological, white noise.
The moving dipole (the sender) changes location (far, deep, close, superficial) at every iteration, with a total of 1004 iterations. The maximum time lag t is two. The reason for this ground truth is that the sender can be located at really challenging locations (too close to one of the other dipoles or very deep in the brain).
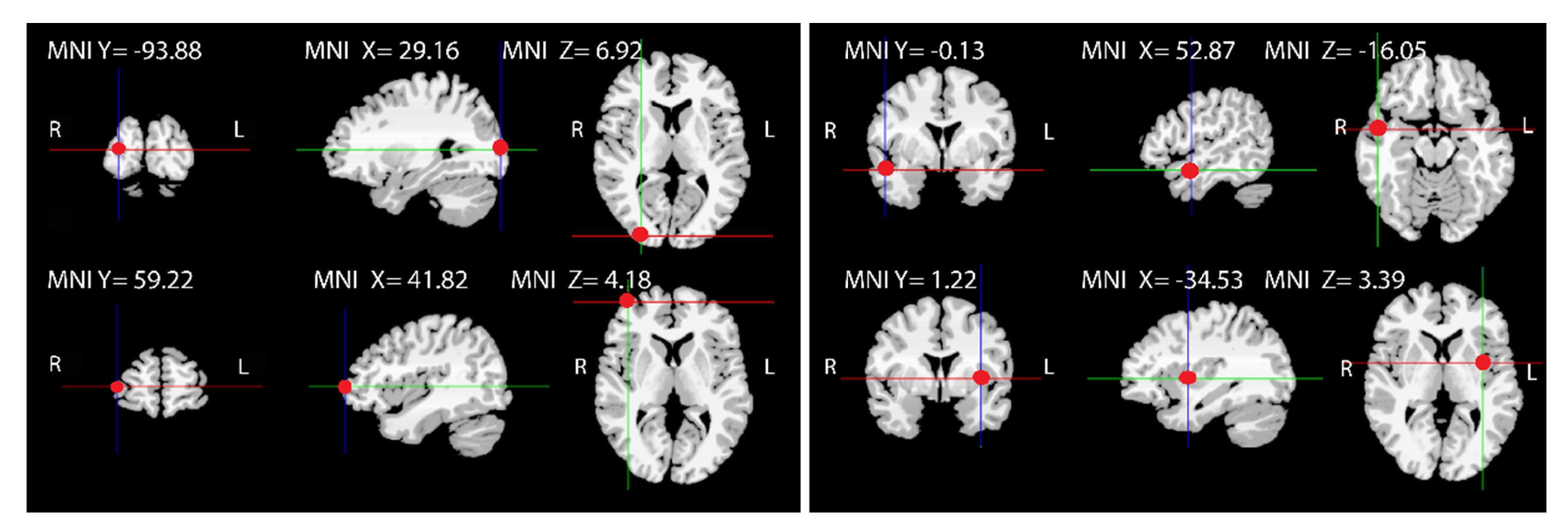
Two conditions were created for both ground truths: one condition consisted of three superficial dipoles far away from each other, while the other consisted of three dipoles located “deep” in the brain, but each dipole was still positioned far away from the other dipoles. The corresponding MNI-coordinates of the two fixed dipoles that Ground Truth 1 and 2 have in common are depicted in
Figure 4. The full set of coordinates of Ground Truth 1 (including the coordinates of the third fixed dipole) is denoted in
Figure 1.
In Ground Truth 2, the first two coordinates are the same as in Ground Truth 1, for each dipole condition, while the third dipole moves throughout the brain as described above. The Far–Superficial versus Far–Deep configurations indicate (relative) distances: “deep” denotes a distance from the origin (located at the anterior commissure) <6 cm and “superficial” >6.5 cm. The distance between dipoles is evaluated as “far” if the relative distance to the other dipoles exceeds 8 cm.
As an additional check for robustness of source localization, noise sources were added as a background activity. These were modeled using pink noise, also called 1/f noise, and created by scaling the amplitude spectrum of random white Gaussian noise with the factor1/f using the Fourier transform and its inverse.
After generating these noise sources, the forward problem is construed:
where
Y denotes the scalp-recorded potentials,
X represents the electrical sources in the brain (the dipoles), “
e” is measurement noise (electrode noise) and
L is the head volume conductor model (also called the leadfield matrix). The leadfield matrix determines how the activity flows from dipoles to electrodes. In this work, the New York Head model [
23] was used.
The pink noise and the source activity are then projected onto the scalp, after which they are summed:
Yactive and Ynoise refer to the scalp-projected source signals and pink noise activity, respectively; both are scaled by dividing them by their Frobenius norm (||Yactive (t)||FRO, ||Yactive (t)||FRO). The Signal-to-Noise Ratio (SNR) is computed for all dipoles simultaneously and set to 0.9 (γ = 0.9).
Next, white noise (spatially and temporally uncorrelated activity) is added to
Ybrain to simulate electrode noise, resulting in Equation (6) where
Ymeasurement represents the simulated EEG signal. Again γ = 0.9 is imposed as Signal-to-Noise Ratio:
Afterwards, the simulated scalp-EEG data are source-reconstructed using exact low-resolution brain electromagnetic tomography (eLORETA) [
24]. There have also been improvements to eLORETA, such as Sparse eLORETA, which uses a masking approach to improve the source localization density [
25]. The eLORETA method is a discrete, three-dimensional (3D), linear, weighted minimum norm inverse solution [
24]. In the absence of noise, an exact zero-error localization accuracy can be obtained with eLORETA, but this does not hold for noisy data, as was shown in a study comparing both scenarios [
26]. The MATLAB implementation of the eLORETA algorithm (mkfilt_eloreta2.m) from which spatial filters are obtained was developed by G. Nolte and is available in the MEG/EEG Toolbox of Hamburg (METH;
https://www.uke.de/english/departments-institutes/institutes/neurophysiology-and-pathophysiology/research/research-groups/index.html, accessed on 22 December 2021). As the input, it takes the leadfield tensor (i.e., the head model file N*M*P containing N channels, M voxels, and P dipole directions) as well as a regularization parameter gamma (set to 0.01); as the output, an N*M*P tensor A of spatial filters is returned.
2.2. Connectivity Models
The ANNs evaluated in this study were selected based on their suitability for time series analysis (
Table 1). While TCDF outputs attention scores, for which higher scores are used to represent stronger connectivities, LSTM-NUE makes use of Granger Causality scores equaling NNGC = errreduced−errfull, which are then binarized [
18]. Conv2D uses the R
2-score between the real and predicted values of the current target (i.e., the time steps to be predicted). While using TRGC as implemented by [
1], only binary GC scores are outputted. The configuration (i.e., the used parameters) of each ANN was determined using a data-driven approach, such that for each ANN, the parameters returning the best results were chosen. This parameters pre-testing was performed with different simulated data sets (i.e., differing from the data sets that were used to report the final results).
2.2.1. Temporal Causal Discovery Framework
The Temporal Causal Discovery Framework (TCDF) developed by [
14] is based on the concept of a one-dimensional Temporal Convolutional Network (TCN) and is available on Github [
27]. Input to the framework consists of an NxL data set consisting of N time series of equal Length L. Within the framework, one depthwise-separable TCN is used to obtain a prediction for a single source (target). The input of the network consists of the history of all time series, including the target time series. The output is the history of the target time series. An attention mechanism is added: each TCNj has its own trainable attention vector Vj = [vX1j, vX2j, …, vij, … vNj], that learns which of the input time series is correlated with the target by multiplying attention score vij with input time series Xi in TCNj. When the training of the network starts, all attention scores are initialized as 1 and are, as such, adapted during training. The direction of connectivity and significance is determined using a shuffling procedure. For significance determination, one of the time series is shuffled while keeping the other one(s) intact when predicting the target. The runs with shuffled time series did not involve any model retraining. Instead, in the prediction step, the losses obtained when using the “shuffled” time series as predictors were compared with the losses obtained when using the non-shuffled time series. Only if the loss of a network increases significantly when a time series is shuffled that time series is considered a cause of the target time series. A time series X1 is only considered to be a significant contributor to another time series X2 if, in the first stage, its attention score is larger than one. Only if, after shuffling the potentially contributing time series X1, the difference between losses obtained by predicting future time steps with the unshuffled time series and losses obtained by predicting using shuffled time series is large enough, using an a priori determined threshold significance value, time series X1 is considered a significant contributor to time series X2. TCDF was run with PyTorch (version 1.4.0,
www.pytorch.org, accessed on 17 December 2021).
Configuration. For TCDF, the chosen parameters were the number of hidden layers = 1, kernel size = dilation coefficient = 4 (a time-dimensional kernel), learning rate = 0.01, optimizer = Adam, number of epochs = 1000, significance threshold= 0.9998, seed = 1000. Kernel weights are initialized following a distribution with µ = 0, variance = 0.1.
2.2.2. LSTM-NUE—Long Short-Term Memory with Non-Uniform Embedding
Another connectivity measure is based on the RNN, in which directed cycling connections are present, i.e., there are feedback connections from output to input, and these connections create possibilities for memorization. A subtype of RNNs is the Long Short-Term Memory network (LSTM). This type of network provides a resolution for vanishing and exploding gradient problems in recurrent networks. It performs this by introducing gates and memory cells which also makes it very flexible towards gap length. The implementation in this study is an LSTM with Non-Uniform Embedding (NUE, a feature selection procedure) by [
15], which is also publicly available [
28]. NUE is an iterative selection procedure adopted from [
18] to detect the most informative time steps of the predicting time series (phase one). In phase one, a vector
V containing the most informative past time steps to explain the present state of a target time series X1 is obtained by iteratively adding time steps (of the time series’ own past, but also of the past of the other time series) to the training set and obtaining a new model error as a time step is added. For instance, let
V = [
VX1n, VX2n, VX3n] represent the vector with the most relevant past time steps to explain the present of the target time series. This selection of time steps goes on until the prediction error becomes larger than or equal to a threshold or until the maximum amount of time steps is reached. If for a certain time series X2, no time steps have been added in
V, the time series is not further considered as a potential contributor to target time series X1, and it is not considered in the next phase (phase two). Phase one results in an estimation of the error variance of the full model (i.e., the model containing all relevant past time steps from different time series). In phase two, the model is fit only with this smaller set of time steps. The error of the reduced model is finally obtained by not using the values of the time series (e.g., X3) that is a potential contributor to the target time series X1. If the error (Loss
Reduced) of this reduced model is larger than the error of the full model (Loss
Full), time series X3 is considered a significant contributor to time series X1 (“X3 Granger-predicts X1”).
In LSTM-NUE, no shuffling is used to determine connectivity. Instead, the significance procedure consists of two phases. Determining significance is based on (1) the selection of relevant time samples from all time series rendering a full model, after which the time series whose time samples were not selected are already as potential causes of the target time series. (2) The remaining candidates are then, as a test, subsequently excluded from the model to obtain the reduced model (i.e., the model with only the target time series as its own predictor). Hence, this exclusion phase is, to some extent, comparable with the shuffling procedure used in TCDF, given that this procedure is in this way testing the relevance of a certain time series in the prediction of another (by excluding it OR by shuffling the values).
Configuration: for LSTM-NUE, the parameters are the number of hidden layers = 1, the number of units in each layer = 30, batch size = 30, num_shift = 1, sequence_length = 20, number of epochs = 100, theta = 0.09, learning rate = 0.001, weight decay = 1 × 10−7, min_error = 1 × 10−7 (=a priori determined error to determine whether a certain time step should be included in the final model), and train/validation split = 0.85/0.15. Default kernel initializer = “glorot_uniform”, which draws samples from a uniform distribution, is used to initialize the weights of the LSTM-layer.
2.2.3. Conv2D—Two-Dimensional Convolutional Network
Finally, we propose a two-dimensional Convolutional Network (Conv2D) as a way to test whether a 2D kernel variation in TCDF has merit. The input consists of an NxL data set, which is transformed into a four-dimensional tensor (time samples of training set, window size, amount of predicting time series, 1). The source code is accessible via Github (kul-EEG-sourceconnectivity,
https://github.com/irisv440/kul-EEG-sourceconnectivity, accessed on 21 September 2021).
Some important differences with TCDF are the fact that a two-dimensional kernel is used and that a cross-validation procedure, adapted for time series, is embedded in the framework. While in TCDF, a one-dimensional kernel (with height = 1) slides over the data along the time dimension (=width of the kernel, i.e., the amount of time steps considered together), in Conv2D, a two-dimensional kernel is used in which the second dimension represents the amount of time series that will be convolved together. The second dimension has an upper bound, which is the total amount of time series within the input data. We hypothesized that by adding a second dimension (feature dimension) to TCN, we could capture the most important aspects of the other time series, leading to more correct connectivity estimates. However, it was suggested (e.g., [
29]) that convolving data from several time series can also cause less accurate results (in our case, this means lower Sensitivity and lower Precision) because too many time series are convolved together, possibly erasing the impact of changes in individual time series. Similar to TCDF, the input to the network consists of all time series, including the target time series. The output is a single target time series.
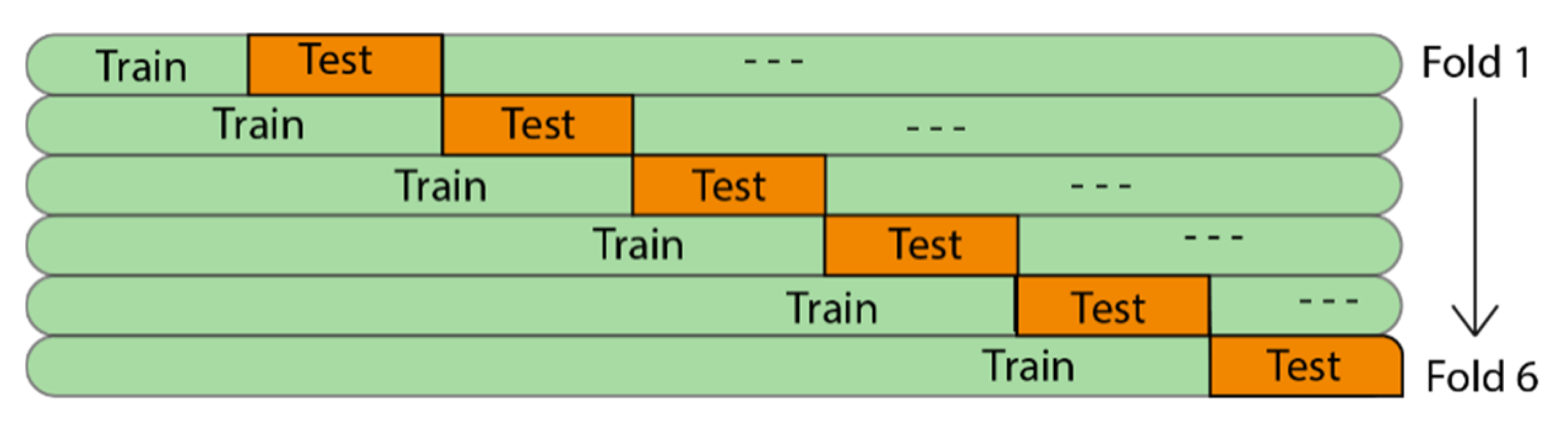
A second difference is cross-validation (CV) for time series. Cross-validation is a powerful method for detecting overfitting, but its implementation in time series models is not trivial, given that no leakage from future to past may exist. This issue was solved by using 6-fold cross-validation on a rolling basis based upon “TimeSeriesSplit” from the model selection module of the sklearn-library version 0.24.1 (Scikit-learn, original version released by [
30]). With TimeSeriesSplit, we obtained the following train-test regime for the folds where “---“represents the unused part of the data in the corresponding fold (
Figure 5).
In addition, given that connectivity may vary over longer time spans (as is also the case in Ground Truth 1), working with only one division in the train/validation/test-set (respecting past versus future) can cause false positives or false negatives since one may be training on a portion of the time series where connectivity is very strong between, for instance, X3 and X2 while validating and/or testing on a part where the same connectivity is weak (or the other way around).
As a metric for connectivity strength, the R2-score between the real values and the predicted values of the current target is used. The better a time series pair is successful in predicting a target, the larger the similarity between the true values and the predicted values will be, hence the stronger the connectivity between the time series and target. When, for instance, two different pairs of time series X1 and X2, versus X1 and X3 are used as predictors for X1, R2 again represents the similarity between predicted and true values of the target X1. When the prediction of X1 becomes better when predicted by time series X1 and X2 together, instead of with X1 and X3, one could conclude that connectivity is stronger between X1 and X2 than between X1 and X3. The R2 scores themselves are obtained from the cross-validation folds, after which the average R2 score is taken over the folds and over the number of used runs for one data set. The corresponding output is a scoring matrix representing all combinations of time series used as predictors and possible target time series. If the R2 score is >0 and the predicting time series are considered significant (see “Connectivity Analysis using ANNs”), the obtained R2 score can be interpreted. However, when including more than two predictors, this relationship is not so easily established anymore, given that the R2-score still represents the connection between the target and all predicting time series together. Similar to TCDF, the direction of connectivity and significance is determined using a shuffling procedure. Significance weights are obtained by comparing training and test loss differences, after which a data-driven cutoff (here 0.70) is used to differentiate between contributing and non-contributing time series. More concretely, training difference = (first training loss)–(final training loss), where the latter is expected to be much lower than the first term, and Test difference = (first training loss)–(loss of test-indices using shuffled train data) where the latter is expected to be high because of the shuffled data; hence, one expects the test difference to be very small. Next, if the average test difference was larger than the average_training_difference * significance (=0.9998), the potential connection is considered not significant in the first place. Significance weights are obtained by (test difference/training difference). If the weight is larger than the cutoff (=0.70), the connection is considered not significant. The used significance level, as well as the cutoff for significance weights, were experimentally determined, and the final choice was based upon a data-driven approach (by experimenting with significance levels in the range of {0.70, 1} and with cutoff-scores in the range of [0.40, 0.70]). For the current kind of simulated data, these values worked well.
Configuration: for Conv2D, the parameters were as follows: number of hidden layers = 1, number of filters = 24, kernel size = {4*2, 4*3} (width*height), dilation coefficient = 1, number of epochs = 12, window size = 5, learning rate = 0.005, optimizer = “Adam”, significance = 0.9998, cut-off scores for significance weights = 0.70 and number of train/test splits for CV = 6. Default kernel initializer = “glorot_uniform”, was used to initialize the weights of Keras’ Conv2D-layer.
2.2.4. TRGC—Time-Reversed Granger Causality
As our baseline method, Time-Reversed Granger Causality (TRGC), as implemented (by means of the Matlab function “tr_gc_test”, embedded in “simulation_source_connectivity”), and evaluated by [
1], was used. As stated before, the difference with “traditional” GC is the type of significance procedure. Instead of the classical way to determine significance (a likelihood ratio test), which cannot distinguish between actual versus spurious correlations due to source mixing, it determines whether the “standard” GC scores for non-reversed and reversed data have opposing directions and are both significant. In other words, direction-flipping must occur when data are time-reversed. This is referred to as conjunction-based TRGC [
7]. A drawback of GC (and hence, TRGC) is that one needs to define the model order, which is feasible when the ground truth is known, such as in simulations, but in “real” EEG data, this quickly becomes a tricky problem. An advantage, on the other hand, is the fact that with TRGC, one model for all sources is constructed, after which one threshold is applied to all obtained GC scores.
Configuration. Function tr_gc_test takes as input an NxL matrix H’, the model order, the number of time steps in the time series, alpha, the type of significance test (“conservative”, requiring significant GC scores with original as well as reversed data; versus a significance test based on difference scores between GC scores in normal and reversed order) and finally, the type of VAR model estimation regression mode to calculate pairwise-conditional time-domain Granger Causality scores. In this work, the model order of TRGC was set to two, we opted for “conservative” significance testing, and ordinary least squares (OLS) was used as Vector-Autoregression (VAR) estimator. We used an alpha level of 0.05, FDR corrected [
31]. The corresponding p-value was taken as a threshold to binarize connectivity scores.
2.3. Performance Evaluation
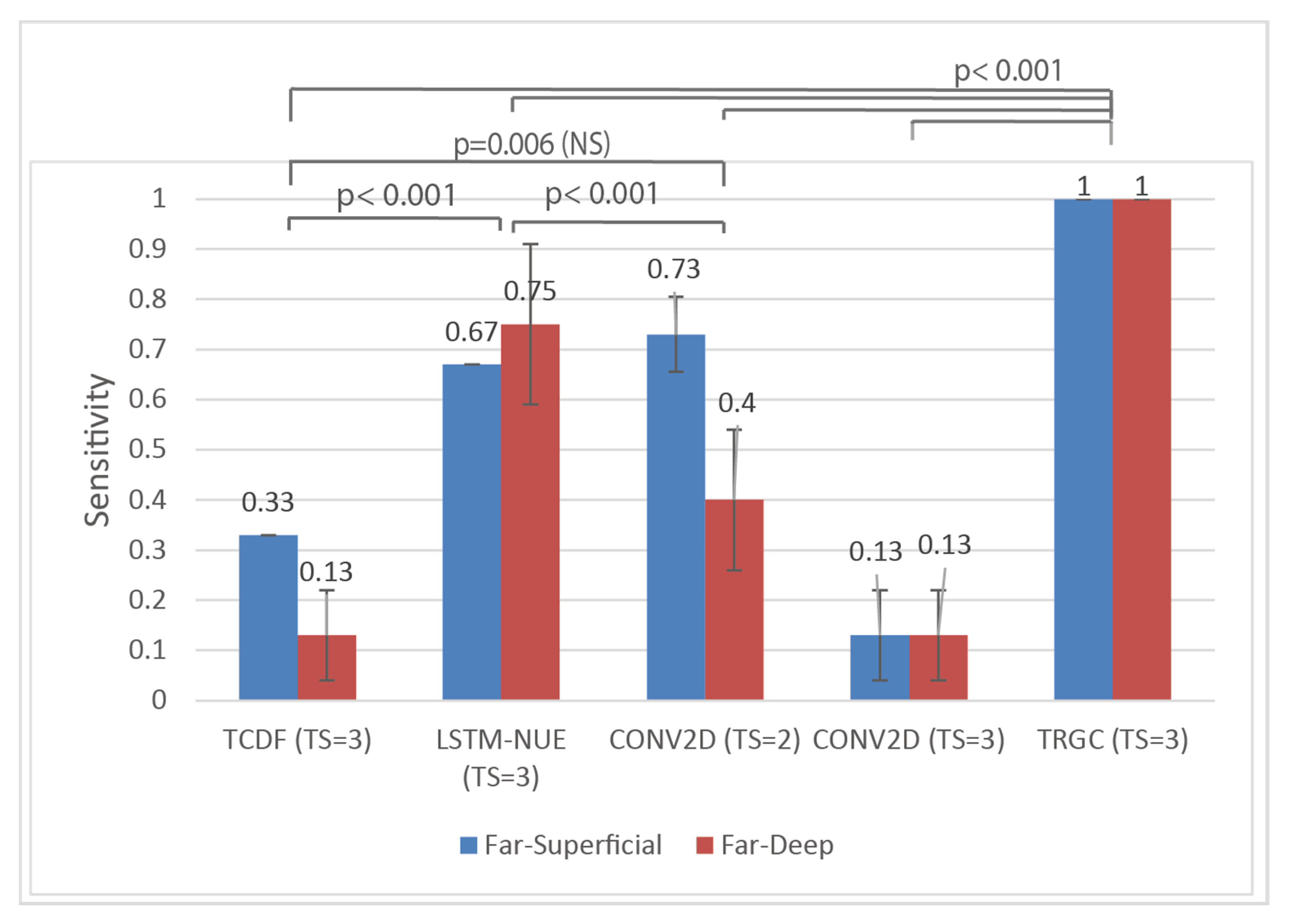
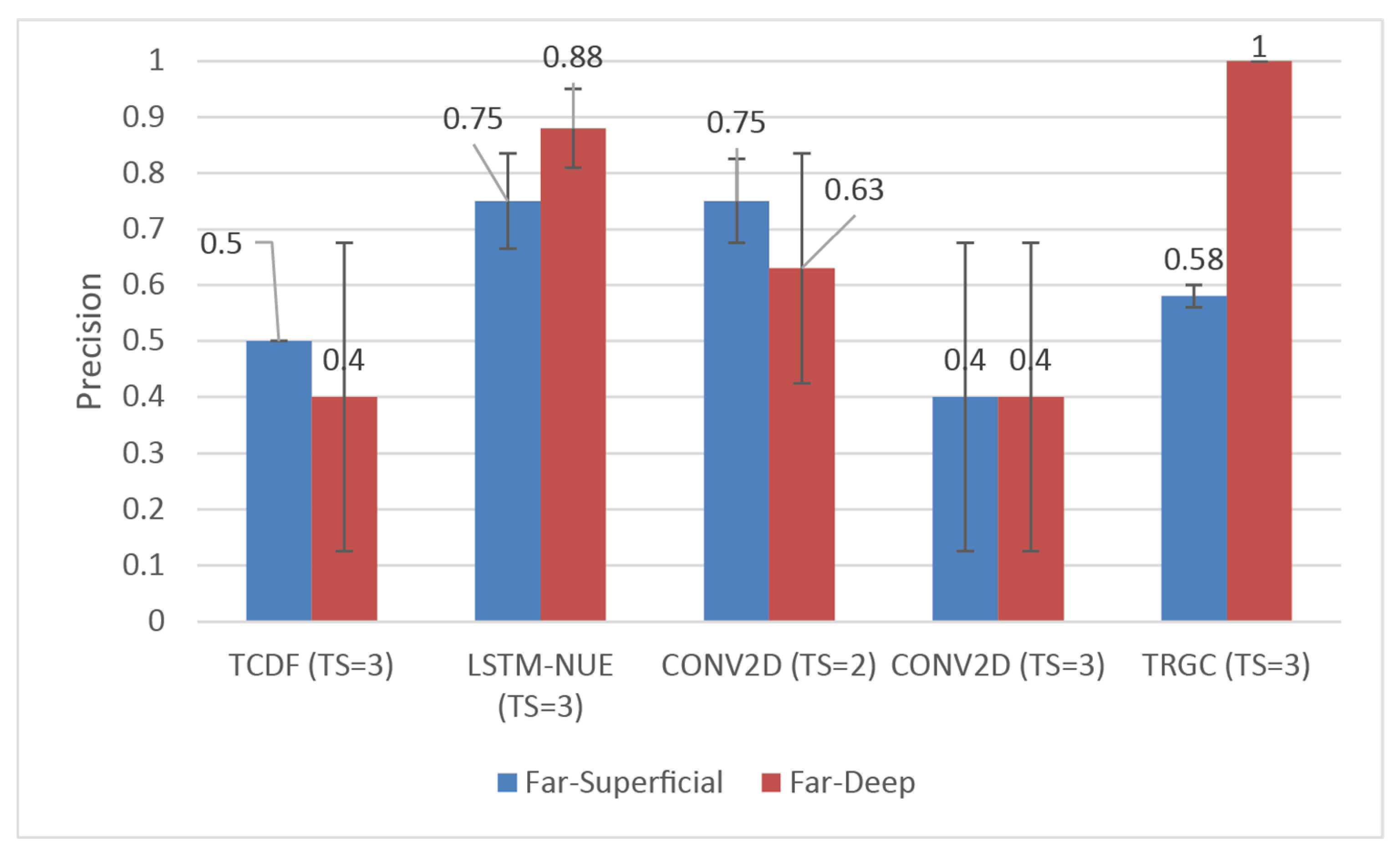
The main question is whether the connections in the ground truths could be detected by the evaluated networks and by TRGC (“True Positives”, TP) without detecting too many false connections (“False Positives”, FP), thus connections that are not present in the ground truths. Measures based upon these are Precision, Sensitivity/Recall, and F1-score (
Figure 6), which we used for comparing TCDF, LSTM-NUE, Conv2D and TRGC.
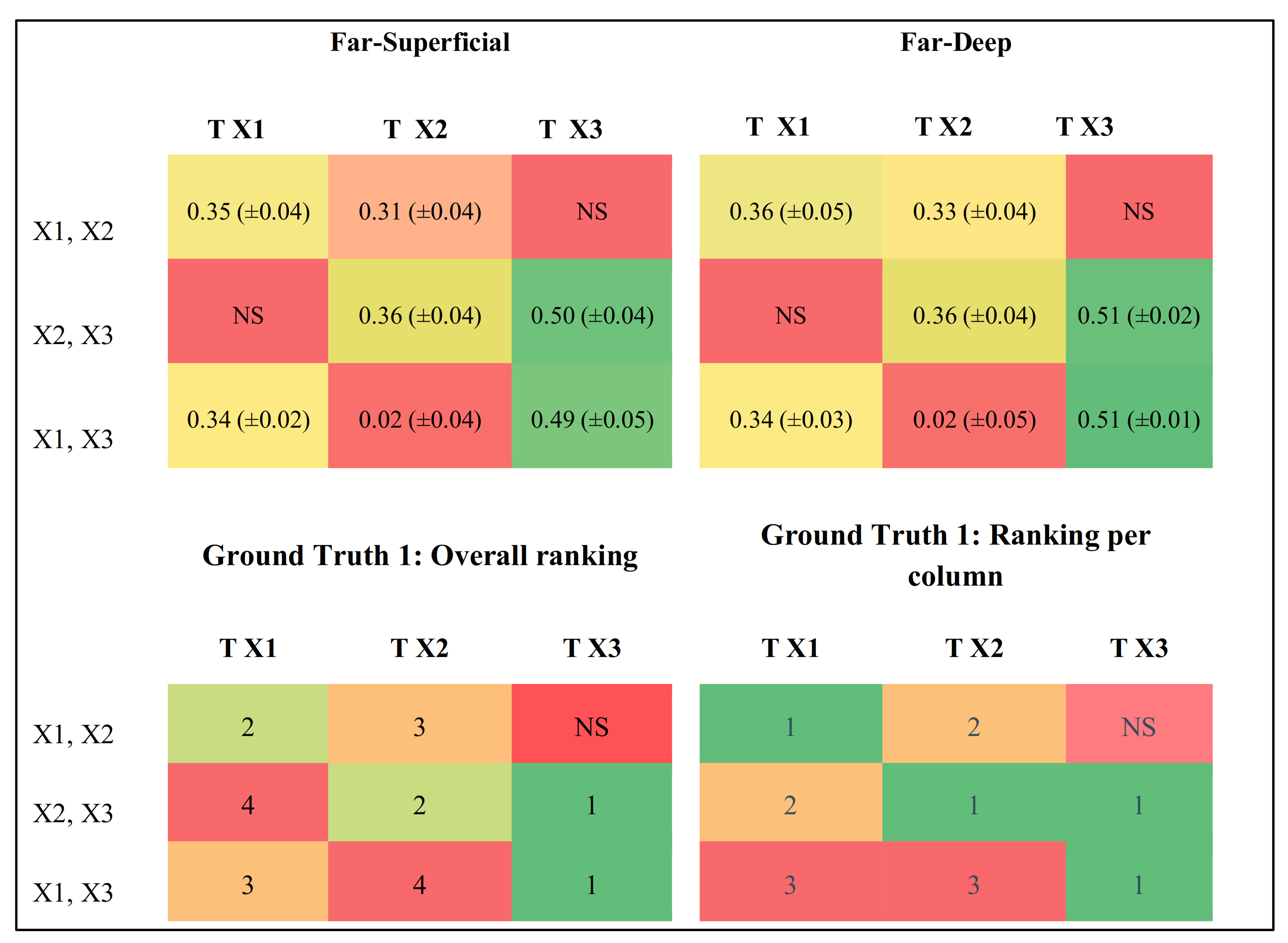
The results on connectivity strength are not directly compared between models as they differ substantially. These strength estimates, based on the mean over five runs on the same data set, are calculated and ranked. It must be emphasized that these strength estimates are relative per model and target training as, for each target time series, the network is trained differently. The latter implies that connection strengths obtained in the prediction of a particular Target time series X1 cannot be readily compared with connection strengths obtained in the prediction of another target time series X2. If F1 < 50%, only rankings are presented. Self-connectivity is not taken into account to avoid an overly positive perception of the results.
4. Discussion
While considering Sensitivity and Precision, it was shown that, among the ANNs, LSTM-NUE yielded superior results in terms of Sensitivity, resulting in statistically significant differences with the other ANNs except for Conv2D with TS = 2. In terms of Precision, however, no significant differences among the ANNs were found while using Ground Truth 1. TRGC outperformed all ANNs in terms of Sensitivity but, statistically, no differences in Precision were found given that the main effect of the connectivity method was only marginally significant. The lack of a statistically significant effect of connectivity method on Precision, as well as the lack of an effect of dipole condition, and the lack of an interaction effect on both Sensitivity as well as Precision are quite counterintuitive. Indeed, given (1) the patterns observed across both Ground Truths and (2) the results from [
1], which convincingly showed effects of different dipole conditions on connectivity patterns as well as interaction effects of connectivity method and dipole condition, one could at least expect an effect of dipole condition. For instance, in [
1], it was shown that with an SNR of 0.9 and in a Far–Superficial dipole condition, false positives (as related to Precision) were rather rare, while for other dipole conditions, the percentage of false positives increases (hence decreasing Precision). A related (solely qualitative) observation is the variability in the results of the ANNs (as became obvious through the standard deviations from the mean as depicted in
Figure 7 and
Figure 8) versus the stability of results produced by TRGC. In particular, ANNS seems to exhibit an increased variability in performance in the Far–Deep Condition (in contrast to the Far–Superficial condition), while almost no such variability is observed for TRGC. A possible culprit could be the initial randomization of the weights in ANNs, but how this instability could differ between architectures or between dipole conditions is unclear and deserves attention in future studies. One of the most important observations of Ground Truth 1 is the relatively poor Precision score of TRGC in the Far–Superficial condition, albeit that a difference with the Far–Deep dipole condition could not be statistically confirmed. More data may be needed to confirm the observed trends. The above-mentioned contrasting results are further discussed below, together with possible explanations with regard to the used connectivity methods.
Using Ground Truth 2, no differences in Sensitivity between TRGC and LSTM-NUE were found given that both methods returned almost always a Sensitivity of one, while Precision was significantly higher for TRGC than for LSTM-NUE. The other ANNs did not detect any connection. The good performance of TRGC regarding Precision is not surprising. In [
1], it was already shown that TRGC outperformed Multivariate Granger Causality (MVGC), especially when it comes to false positives (as reflected in a lower False Positive Rate), which is logical given that the introduction of time-reversal could indeed allow for a better distinction between correlated time series (due to linear mixtures of EEG signals) and true temporal precedence of one time series with regard to another. Although the idea of TRGC is relatively new (as it was first proposed in 2013, by [
8]) in comparison to, for instance, bivariate GC and MVGC, due to its appealing theoretical properties as well as its further validation by [
7], it was quickly picked up in the field, given its relevance for, among others, EEG source connectivity. Recent developments include, for instance, variations in TRGC that allow for other than normal distributions [
32].
In summary, it became clear that, among the ANNs, LSTM-NUE obtained better Sensitivity scores and (although only statistically confirmed using Ground Truth 2) better Precision scores. TRGC outperformed the ANNs in terms of Sensitivity, but in the case of Ground Truth 1, questions arose surrounding its Precision in the Far–Superficial dipole condition (although its Precision was significantly better in Ground Truth 2, without any indication of possible differences between dipole conditions). While all connections were discovered, two false positives were detected relatively consistently, indicating that even with time-reversal there is, in certain circumstances, an over-detection of connections. The lack of performance of TCDF and Conv2D in Ground Truth 2 cannot be due to the location of the two fixed dipoles since they were located at the exact same location as in Ground Truth 1. Hence, we suspect that the moving nature of the sending dipole explains (at least partly) the lack of Sensitivity in TCDF and Conv2D. Taking the results from both Ground Truths together, both LSTM-NUE and TRGC are clearly more sensitive, but they both still tend towards over-detection.
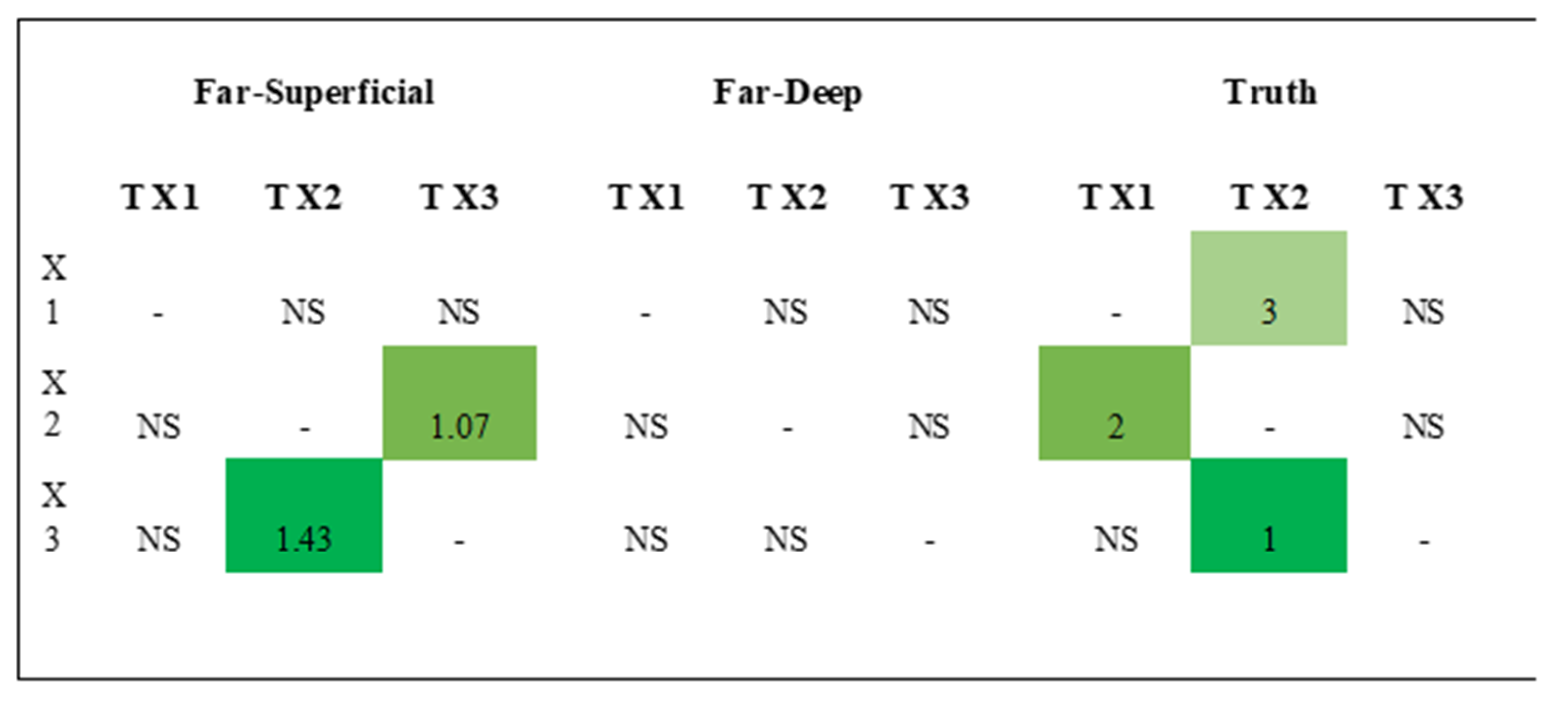
With regard to the score strength rankings, not much can be said about TCDF given that the mean attention scores were significant only for two time series in the Far–Superficial dipole condition, from which one was a falsely detected connectivity (i.e., a false positive). In contrast to TCDF, with LSTM-NUE, for two out of three targets, correct column-wise rankings were obtained for Ground Truth 1. For Conv2D (with TS = 2), correct rankings for predictor pair were found in terms of R
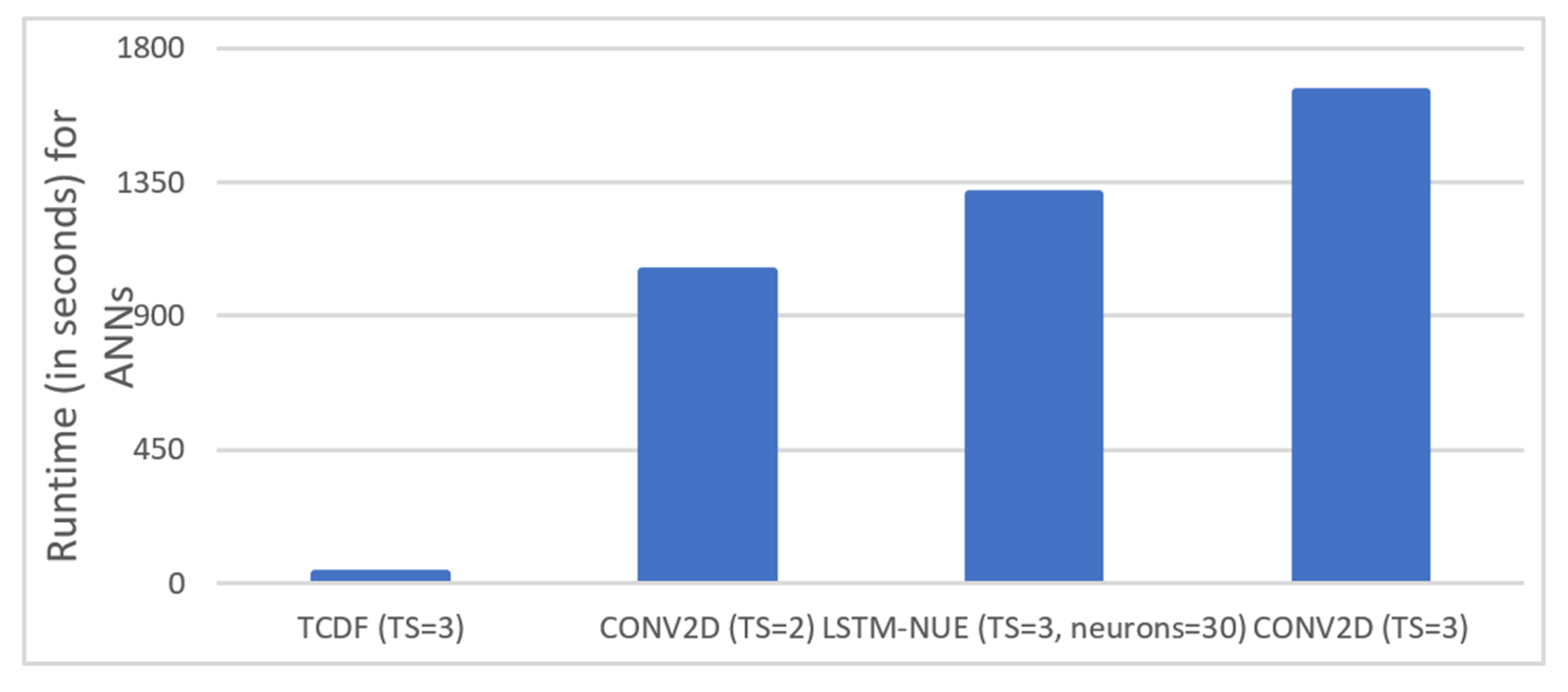
2-scores, also for two out of three targets. When looking closer to the contributions of individual time series, it was found that predicting, for instance, X1, with itself and another time series works better than predicting it without the past of X1, which is logical. The fact that adding more predictors (i.e., Conv2D with TS = 3) did not work out is obviously the most problematic aspect of Conv2D. Once a third predictor was added, performance dropped substantially, and it was hypothesized that this could be due to the fact that it was convolving rather uncorrelated or only slightly correlated time series together confuses the two-dimensional network to the extent that no proper prediction can be made. The fact that channels are not kept separate such as in a depthwise-separable architecture, may play an important role in this aspect. Finally, with regard to runtimes (time needed to train a model), LSTM-NUE was together with Conv2D, TS = 3 the most time-consuming method, which calls for a trade-off between accuracy and Time Complexity. It is especially the non-uniform embedding strategy (NUE) that is responsible for the high Time Complexity. However, in [
15], it was shown that the current LSTM-model could also produce reasonable results without implementation of the NUE strategy, thereby lowering its Time Complexity drastically.
Moreover, in [
15], it was shown that LSTM-NUE could cope with different types of ground truths (linear, non-linear and non-linear with varying length lags), as confirmed in our work. Contrary to [
15], we, in addition, had Ground Truth 2 with a moving dipole (i.e., the “Sender”) which worked relatively well for LSTM-NUE. Hence, the latter can cope not only with time-varying parameters but also, to some extent, with changing dipole locations. Both TCDF and Conv2D cope far less well with a moving sender, probably (or at least partly) because of the occurrence of both closeness and deepness in the same setting, which has an impact on how signals are transformed by source reconstruction. TCDF and Conv2D are, in contrast to LSTM-NUE, not a part of the family of Recurrent Neural Networks and therefore do not contain feedback loops. The LSTM is particularly known for its excellent memory properties by virtue of its gates that help to remember versus forget certain time samples. In general, the better memory properties of an LSTM in combination with the NUE approach probably play an important role in dealing with variations over time. An LSTM may also be better in looking through (uncorrelated) noise components because it remembers formerly seen time samples better and, subsequently, should be better in detecting (even weak) patterns over time, also when occluded by noise. This, in turn, may make it easier to deal with more challenging dipole locations or with heavier data transformations. However, this same property could also make an LSTM more sensitive to correlated noise from source mixing. TCDF, on the other hand, has the advantage of a very low Time Complexity, at least partly due to its sparsity in interconnection weights (given its depthwise-separable architecture), but it seems less able to distinguish correlation from causation. This may be due to the lack of feedback loops, an “active” memory feature that makes it difficult to distinguish true patterns from noise over longer time intervals. In this study, TCDF was tuned as such that not too many false positives were detected (given its problem of distinguishing correlation from causation), and this more “conservative” configuration may have led to its low Sensitivity. Overall, we can conclude that, among the ANN models, LSTM-NUE performed best in terms of Sensitivity and Precision regardless of which ground truth was used even though no shuffling or time-reversal was used for connectivity assessment. The contrasting results of TRGC in terms of Precision between dipole conditions in Ground Truths 1 and 2 are puzzling and clearly show an “oversensitivity” of TRGC under certain circumstances. Still, TRGC and LSTM-NUE yielded acceptable-to-good results, albeit both suffer from over-detection. An interesting new finding is the fact that an LSTM is, to some extent, able to provide an answer to the question of whether connectivity between sources is present or absent, at least for source-reconstructed, simulated EEG data. The fact that too many faulty connections were detected (especially in Ground Truth 2) calls for improvements. One possibility is to use LSTM-NUE as part of a masking approach, on top of which another learner is stacked. This masking approach has already led to many advantages in source localization [
25], and it may also facilitate connectivity detection with ANNs, especially when overly sensitive to it. In this sense, other ANNs, even with a lower Time Complexity than that of LSTM-NUE, could possibly also be considered as potentially directed connectivity estimators.
An obvious future step is testing whether ANNs can also be applied to real EEG data, albeit that several possible caveats should be taken into account. First and foremost, as shown by [
1], under low noise conditions, dipole conditions may matter less, but differences between dipole conditions could become more obvious (i.e., more disturbing) under higher noise levels. Even long-established connectivity methods suffer from this. Since controlling noise levels is hard, reasonably one could opt for EEG-data for which (1) the contributing brain areas are rather superficially located, (2) the connectivity patterns are relatively well known and preferably supported by both high-density EEG and fMRI-data so that a performance evaluation becomes feasible since no ground truth is available for real EEG-data. Testing ANNs and contrasting them with TRGC/other established methods using vision-related or motor-related EEG-datasets makes thus more sense than testing them with data with relatively unknown connectivity patterns. Regions of Interest (ROIs) can be defined based upon previous knowledge about involved brain areas. As for source localization, a reasonable choice is eLORETA. Data-driven approaches (as opposed to ROI-selection), e.g., data-driven clustering [
33], seem only reasonable in a later stage when the value of the used ANN is proven on real EEG data.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










