
DOUNet: Dynamic Optimization and Update Network for Oriented Object Detection



Abstract
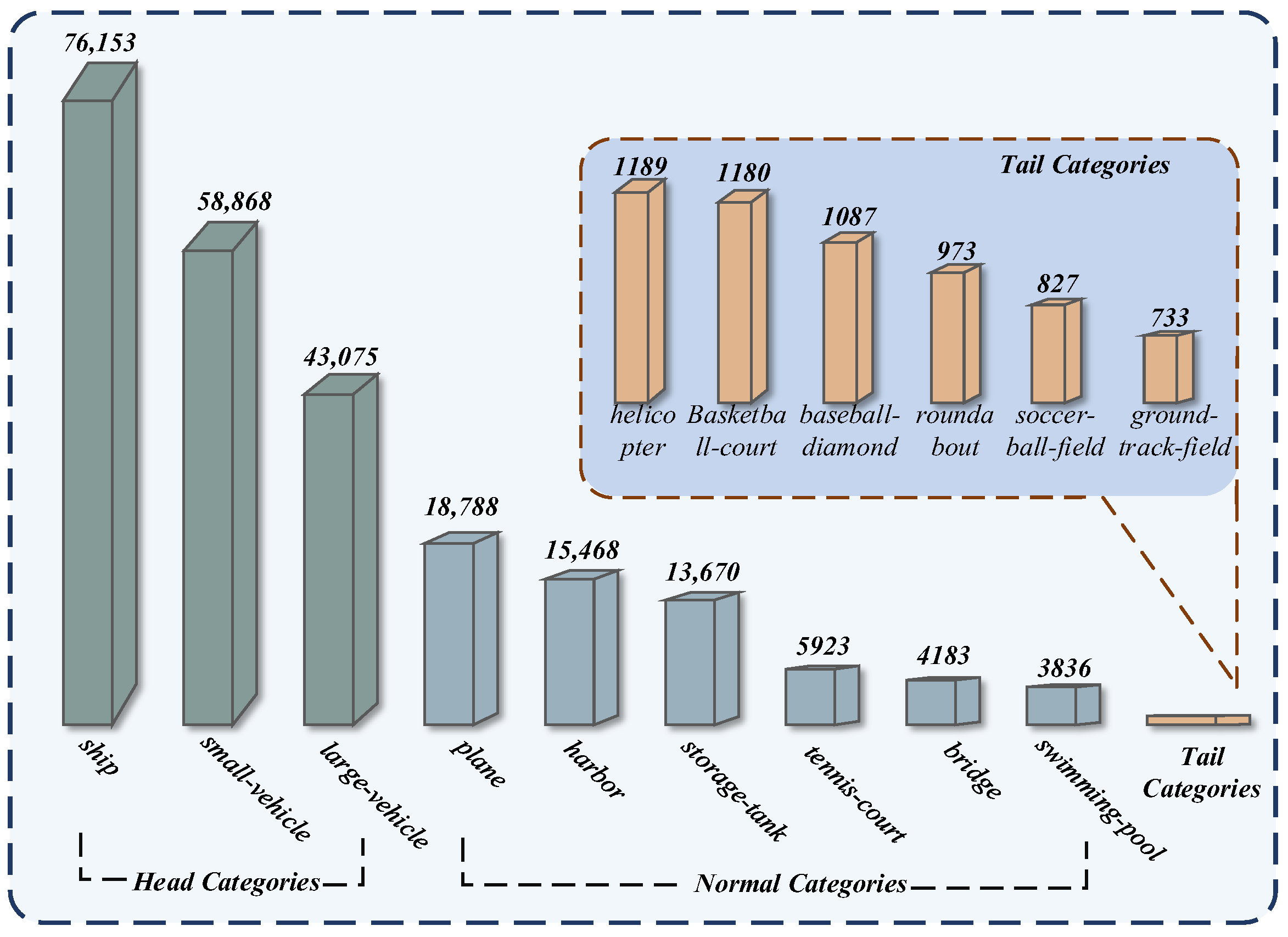
:1. Introduction
- (1)
- Previous research on feature extraction and fusion of rotating targets was not sufficiently comprehensive. In response to this issue, we combined previous research results and added both large kernel convolution and rotation convolution to the network, modified the backbone network and feature fusion network, and designed an effective feature extraction method.
- (2)
- Previous studies did not take the impact of dataset imbalance on detection accuracy into account. To this end, we have designed a detection framework for long-tailed datasets to address data imbalance.
- We use large kernel convolution to expand the receptive field of the network, thereby obtaining a wide range of contextual information. In the Region Proposal Network (RPN), rotational convolution is used to extract rotating targets with different angles.
- We propose a long-tail data detection module that measures categories with different levels of imbalance, fine-tuning the trained model through loss weighting and frozen training. In addition, we have added a feature generator to generate robust features for network training.
- We propose a new network called the Dynamic Optimization and Update network (DOUNet) and demonstrate the effectiveness of our proposed method through ablation experiments and comparative experiments. The experimental results show that our proposed model performs better than the baseline model and has significantly higher accuracy in tail categories than other networks.
2. Related Work
2.1. Target Detection in Remote Sensing Images
2.2. Detection of Long-Tail Imbalanced Datasets
3. The Proposed Method
3.1. The Proposed Detector
3.2. LSK Module for Multi-Scale Feature Extraction
3.3. Rotation Convolution for Oriented Feature Extraction
3.4. Long-Tail Data Detection Module
3.4.1. Feature Generation Module
3.4.2. Foreground Category Loss Calculation Module
4. Experiments
4.1. Dataset Introduction and Evaluation Indicators
4.2. Implementation Details
4.2.1. Dataset Processing and Data Augmentation Operations
4.2.2. Environment and Experimental Setup
4.3. Ablation Study
4.4. Comparison with Other Methods
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly kernel inception network for remote sensing detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 27706–27716. [Google Scholar]
- Pu, Y.; Wang, Y.; Xia, Z.; Han, Y.; Wang, Y.; Gan, W.; Wang, Z.; Song, S.; Huang, G. Adaptive rotated convolution for rotated object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6589–6600. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 677–694. [Google Scholar]
- Yu, Y.; Da, F. Phase-shifting coder: Predicting accurate orientation in oriented object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13354–13363. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU loss for rotated object detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- Tan, J.; Lu, X.; Zhang, G.; Yin, C.; Li, Q. Equalization loss v2: A new gradient balance approach for long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1685–1694. [Google Scholar]
- Tan, J.; Wang, C.; Li, B.; Li, Q.; Ouyang, W.; Yin, C.; Yan, J. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11662–11671. [Google Scholar]
- Wang, T.; Zhu, Y.; Zhao, C.; Zeng, W.; Wang, J.; Tang, M. Adaptive class suppression loss for long-tail object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 3103–3112. [Google Scholar]
- Li, B.; Yao, Y.; Tan, J.; Zhang, G.; Yu, F.; Lu, J.; Luo, Y. Equalized focal loss for dense long-tailed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6990–6999. [Google Scholar]
- Zhang, S.; Li, Z.; Yan, S.; He, X.; Sun, J. Distribution alignment: A unified framework for long-tail visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2361–2370. [Google Scholar]
- Qi, T.; Xie, H.; Li, P.; Ge, J.; Zhang, Y. Balanced Classification: A Unified Framework for Long-Tailed Object Detection. IEEE Trans. Multimed. 2023, 26, 3088–3101. [Google Scholar] [CrossRef]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-adaptive selection and measurement for oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 923–932. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8792–8801. [Google Scholar]
- Yu, Y.; Yang, X.; Li, Q.; Zhou, Y.; Zhang, G.; Yan, J.; Da, F. H2rbox-v2: Boosting hbox-supervised oriented object detection via symmetric learning. arXiv 2023, arXiv:2304.04403. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AP50 | AP75 | mAP.5:.95 | APT | APTN | APH |
|---|---|---|---|---|---|---|
| LSKNet | 75.86 | 47.65 | 45.46 | 72.33 | 74.25 | 82.32 |
| LSK-CLS | 76.43 | 48.77 | 46.18 | 73.59 | 75.04 | 82.02 |
| LSK-ARC | 75.91 | 47.41 | 45.53 | 72.20 | 74.28 | 82.44 |
| DOUNet(ours) | 76.54 | 49.01 | 46.22 | 73.48 | 75.18 | 81.98 |
| Model | AP50 | AP75 | mAP.5:.95 | FPS(s) | Parameter(M) | GFLOPs |
|---|---|---|---|---|---|---|
| LSKNet | 75.86 | 47.65 | 45.46 | 22.6 | 21.0 | 124.42 |
| LSK-CLS | 76.43 | 48.77 | 46.18 | 22.7 | 21.0 | 124.42 |
| LSK-ARC | 75.91 | 47.41 | 45.53 | 6.3 | 22.77 | 73.2 |
| DOUNet(ours) | 76.54 | 49.01 | 46.22 | 6.3 | 22.77 | 73.2 |
| Method | Head Categories | Normal Categories | Tail Categories | mAP(%) | |||
|---|---|---|---|---|---|---|---|
| SV | LV | TC | BC | HA | BR | ||
| Rotated RepPoints [4] | 71.27 | 51.78 | 90.51 | 70.46 | 50.69 | 36.32 | 59.44 |
| SASM [22] | 72.08 | 72.35 | 90.90 | 75.69 | 63.75 | 45.41 | 66.43 |
| Rotated RetinaNet [2] | 77.51 | 62.63 | 90.89 | 82.31 | 56.46 | 40.88 | 68.42 |
| KFIoU [15] | 72.30 | 64.01 | 90.90 | 82.33 | 63.00 | 46.25 | 69.59 |
| CFA [23] | 79.05 | 74.14 | 90.87 | 80.35 | 64.40 | 49.19 | 69.63 |
| Oriented RepPoints [4] | 78.38 | 73.14 | 90.87 | 83.75 | 63.69 | 49.61 | 71.72 |
| PSC [12] | 78.92 | 70.08 | 90.90 | 82.82 | 61.35 | 42.48 | 71.91 |
| H2RBox-v2 [24] | 79.81 | 74.77 | 90.88 | 85.47 | 65.87 | 50.75 | 72.61 |
| PKINet-T [6] | 76.35 | 81.92 | 90.85 | 84.14 | 67.11 | 51.24 | 73.60 |
| S2A-Net [8] | 78.61 | 77.37 | 90.90 | 86.28 | 66.08 | 51.57 | 73.92 |
| RetinaNet ConvNeXt [25] | 78.91 | 74.11 | 90.90 | 87.75 | 62.62 | 46.78 | 74.47 |
| Oriented R-CNN [10] | 78.33 | 77.82 | 90.88 | 85.60 | 67.67 | 51.78 | 74.99 |
| LSKNet [5] | 75.02 | 83.77 | 90.90 | 86.30 | 68.65 | 50.87 | 75.86 |
| DOUNet(ours) | 75.11 | 82.95 | 90.90 | 87.92 | 73.27 | 51.04 | 76.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, L.; Zhao, D.; Lan, Q.; Chen, F. DOUNet: Dynamic Optimization and Update Network for Oriented Object Detection. Appl. Sci. 2024, 14, 8249. https://doi.org/10.3390/app14188249
Deng L, Zhao D, Lan Q, Chen F. DOUNet: Dynamic Optimization and Update Network for Oriented Object Detection. Applied Sciences. 2024; 14(18):8249. https://doi.org/10.3390/app14188249
Chicago/Turabian StyleDeng, Liwei, Dexu Zhao, Qi Lan, and Fei Chen. 2024. "DOUNet: Dynamic Optimization and Update Network for Oriented Object Detection" Applied Sciences 14, no. 18: 8249. https://doi.org/10.3390/app14188249