
Identifying Key Factors for Securing a Champions League Position in French Ligue 1 Using Explainable Machine Learning Techniques

 ,
, 
 ,
,  and
and
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Problem Definition
2.3. K-Means Cluster Analysis
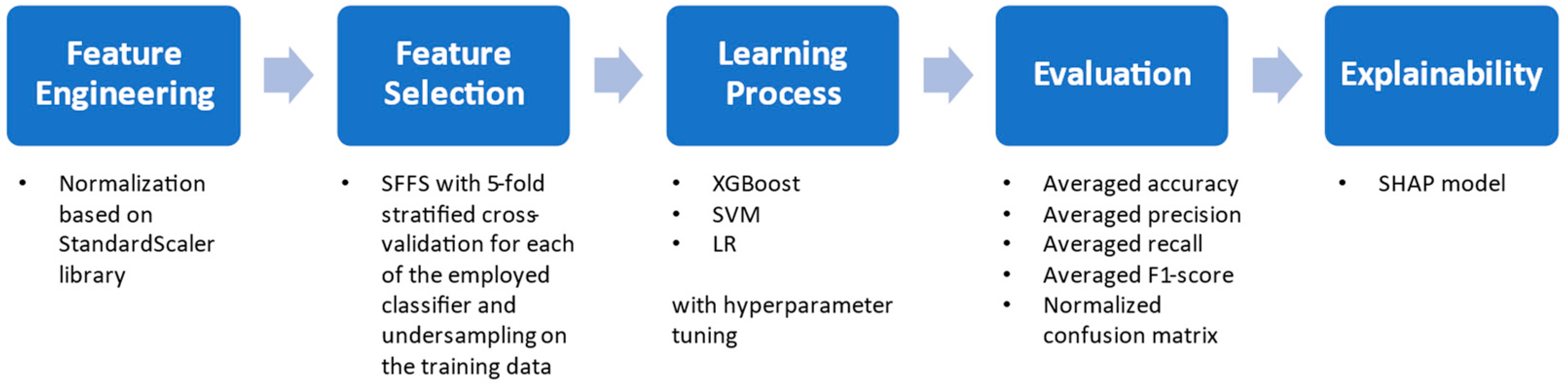
2.4. Machine Learning Workflow
3. Results
3.1. K-Means Cluster’s Results
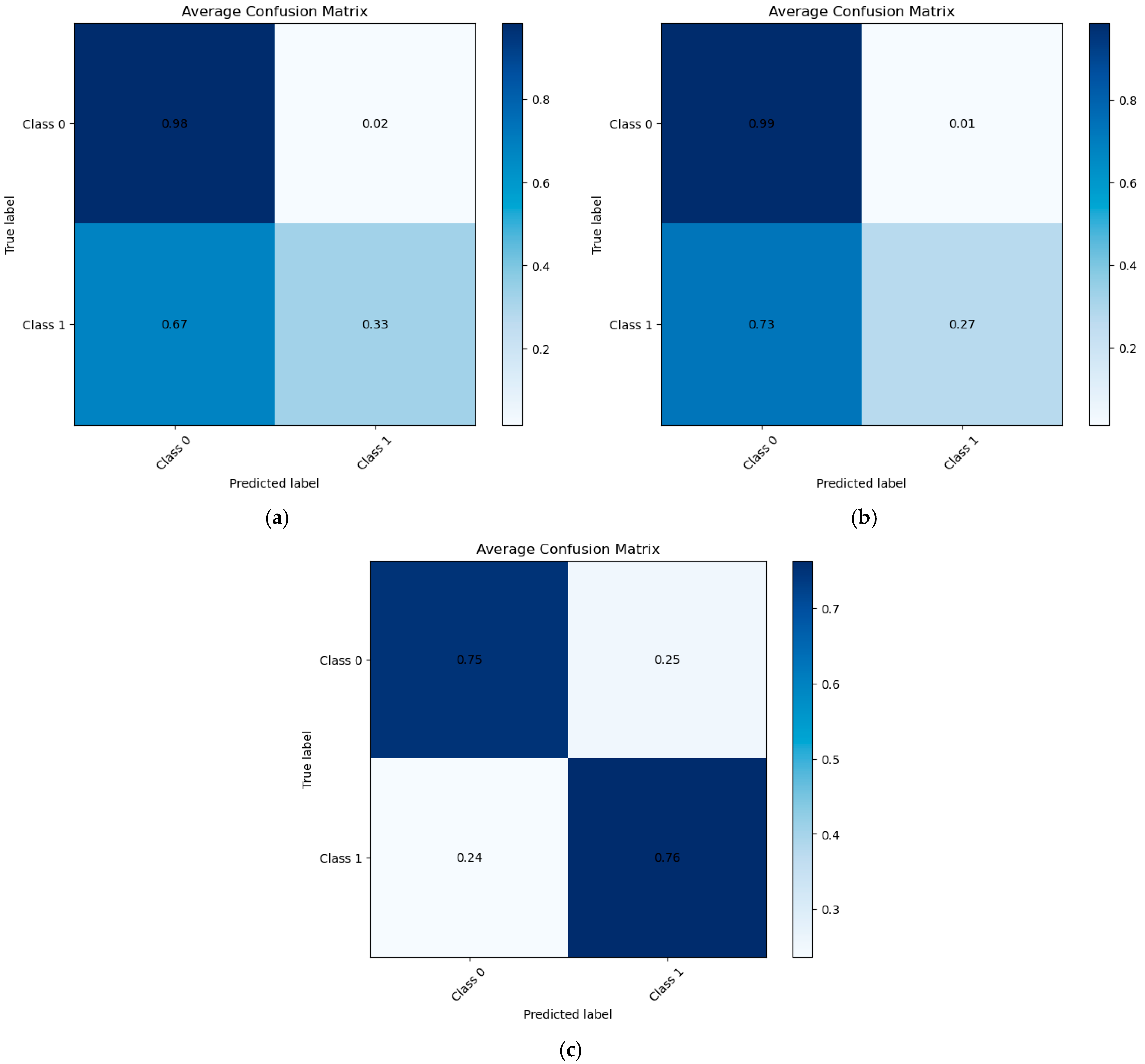
3.2. Testing Performance Metrics
3.3. Feature Selection
3.4. Explainability
4. Discussion
4.1. Passes
4.2. Defensive Actions
4.3. Other Factors
4.4. Strengths of This Study
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Plakias, S.; Moustakidis, S.; Kokkotis, C.; Papalexi, M.; Tsatalas, T.; Giakas, G.; Tsaopoulos, D. Identifying Soccer Players’ Playing Styles: A Systematic Review. J. Funct. Morphol. Kinesiol. 2023, 8, 104. [Google Scholar] [CrossRef]
- Plakias, S.; Moustakidis, S.; Kokkotis, C.; Tsatalas, T.; Papalexi, M.; Plakias, D.; Giakas, G.; Tsaopoulos, D. Identifying soccer teams’ styles of play: A scoping and critical review. J. Funct. Morphol. Kinesiol. 2023, 8, 39. [Google Scholar] [CrossRef]
- Martin, D.; Donoghue, P.G.O.; Bradley, J.; McGrath, D. Developing a framework for professional practice in applied performance analysis. Int. J. Perform. Anal. Sport 2021, 21, 845–888. [Google Scholar] [CrossRef]
- Memmert, D.; Rein, R. Match analysis, big data and tactics: Current trends in elite soccer. Ger. J. Sports Med./Deutsch. Z. Fur Sportmed. 2018, 69, 65–72. [Google Scholar] [CrossRef]
- Rein, R.; Memmert, D. Big data and tactical analysis in elite soccer: Future challenges and opportunities for sports science. SpringerPlus 2016, 5, 1–13. [Google Scholar] [CrossRef]
- Xu, D.; Zhou, H.; Quan, W.; Jiang, X.; Liang, M.; Li, S.; Ugbolue, U.C.; Baker, J.S.; Gusztav, F.; Ma, X. A new method proposed for realizing human gait pattern recognition: Inspirations for the application of sports and clinical gait analysis. Gait Posture 2024, 107, 293–305. [Google Scholar] [CrossRef]
- Xu, D.; Zhou, H.; Quan, W.; Gusztav, F.; Wang, M.; Baker, J.S.; Gu, Y. Accurately and effectively predict the ACL force: Utilizing biomechanical landing pattern before and after-fatigue. Comput. Methods Programs Biomed. 2023, 241, 107761. [Google Scholar] [CrossRef]
- Bullough, S. UEFA champions league revenues, performance and participation 2003–2004 to 2016–2017. Manag. Sport Leis. 2018, 23, 139–156. [Google Scholar] [CrossRef]
- Güner, İ.; Hamidi Sahneh, M. Dancing with the stars: Does playing in elite tournaments affect performance? Oxf. Bull. Econ. Stat. 2023, 85, 1–34. [Google Scholar] [CrossRef]
- Soana, M.G.; Lippi, A.; Rossi, S. Do financial markets price UEFA Champions League competition events? EuroMed J. Bus. 2024, 19, 208–228. [Google Scholar] [CrossRef]
- Lepschy, H.; Wäsche, H.; Woll, A. How to be successful in football: A systematic review. Open Sports Sci. J. 2018, 11, 3–13. [Google Scholar] [CrossRef]
- Bekris, E.; Mylonis, E.; Sarakinos, A.; Gissis, I.; Gioldasis, A.; Sotiropoulos, A. Offense and defense statistical indicators that determine the Greek Superleague teams placement on the Table 2011-12. J. Phys. Educ. Sport 2013, 13, 338–347. [Google Scholar] [CrossRef]
- Fernández-Cortés, J.; García-Ceberino, J.M.; García-Rubio, J.; Ibáñez, S.J. Influence of game indicators on the ranking of teams in the Spanish soccer league. Appl. Sci. 2023, 13, 8097. [Google Scholar] [CrossRef]
- Yang, G.; Leicht, A.S.; Lago, C.; Gómez, M.-Á. Key team physical and technical performance indicators indicative of team quality in the soccer Chinese super league. Res. Sports Med. 2018, 26, 158–167. [Google Scholar] [CrossRef]
- Chmura, P.; Oliva-Lozano, J.M.; Muyor, J.M.; Andrzejewski, M.; Chmura, J.; Czarniecki, S.; Kowalczuk, E.; Rokita, A.; Konefał, M. Physical Performance Indicators and Team Success in the German Soccer League. J. Hum. Kinet. 2022, 83, 257–265. [Google Scholar] [CrossRef]
- Andrzejewski, M.; Oliva-Lozano, J.M.; Chmura, P.; Chmura, J.; Czarniecki, S.; Kowalczuk, E.; Rokita, A.; Muyor, J.M.; Konefał, M. Analysis of team success based on match technical and running performance in a professional soccer league. BMC Sports Sci. Med. Rehabil. 2022, 14, 82. [Google Scholar] [CrossRef]
- Longo, U.G.; Sofi, F.; Candela, V.; Risi Ambrogioni, L.; Pagliai, G.; Massaroni, C.; Schena, E.; Cimmino, M.; D’Ancona, F.; Denaro, V. The influence of athletic performance on the highest positions of the final ranking during 2017/2018 Serie A season. BMC Sports Sci. Med. Rehabil. 2021, 13, 32. [Google Scholar] [CrossRef]
- Coso, J.D.; Brito, D.d.S.; Moreno-Perez, V.; Buldú, J.M.; Nevado, F.; Resta, R.; López-Del Campo, R. Influence of players’ maximum running speed on the team’s ranking position at the end of the Spanish LaLiga. Int. J. Environ. Res. Public Health 2020, 17, 8815. [Google Scholar] [CrossRef]
- Pappalardo, L.; Cintia, P. Quantifying the relation between performance and success in soccer. Adv. Complex Syst. 2018, 21, 1750014. [Google Scholar] [CrossRef]
- Hoppe, M.; Slomka, M.; Baumgart, C.; Weber, H.; Freiwald, J. Match running performance and success across a season in German Bundesliga soccer teams. Int. J. Sports Med. 2015, 36, 563–566. [Google Scholar] [CrossRef]
- González-Rodenas, J.; Ferrandis, J.; Moreno-Pérez, V.; López-Del Campo, R.; Resta, R.; Del Coso, J. Differences in playing style and technical performance according to the team ranking in the Spanish football LaLiga. A thirteen seasons study. PLoS ONE 2023, 18, e0293095. [Google Scholar] [CrossRef]
- Lopez-Valenciano, A.; Garcia-Gómez, J.A.; López-Del Campo, R.; Resta, R.; Moreno-Perez, V.; Blanco-Pita, H.; Valés-Vázquez, Á.; Del Coso, J. Association between offensive and defensive playing style variables and ranking position in a national football league. J. Sports Sci. 2022, 40, 50–58. [Google Scholar] [CrossRef]
- Rico-González, M.; Pino-Ortega, J.; Méndez, A.; Clemente, F.; Baca, A. Machine learning application in soccer: A systematic review. Biol. Sport 2023, 40, 249–263. [Google Scholar] [CrossRef]
- Nassis, G.; Stylianides, G.; Verhagen, E.; Brito, J.; Figueiredo, P.; Krustrup, P. A review of machine learning applications in soccer with an emphasis on injury risk. Biol. Sport 2023, 40, 233–239. [Google Scholar] [CrossRef]
- Rossi, A.; Pappalardo, L.; Cintia, P. A narrative review for a machine learning application in sports: An example based on injury forecasting in soccer. Sports 2021, 10, 5. [Google Scholar] [CrossRef]
- Xu, D.; Quan, W.; Zhou, H.; Sun, D.; Baker, J.S.; Gu, Y. Explaining the differences of gait patterns between high and low-mileage runners with machine learning. Sci. Rep. 2022, 12, 2981. [Google Scholar] [CrossRef]
- Settembre, M.; Buchheit, M.; Hader, K.; Hamill, R.; Tarascon, A.; Verheijen, R.; McHugh, D. Factors associated with match outcomes in elite European football–insights from machine learning models. J. Sports Anal. 2024, 10, 1–16. [Google Scholar] [CrossRef]
- Moustakidis, S.; Plakias, S.; Kokkotis, C.; Tsatalas, T.; Tsaopoulos, D. Predicting Football Team Performance with Explainable AI: Leveraging SHAP to Identify Key Team-Level Performance Metrics. Future Internet 2023, 15, 174. [Google Scholar] [CrossRef]
- Geurkink, Y.; Boone, J.; Verstockt, S.; Bourgois, J.G. Machine learning-based identification of the strongest predictive variables of winning and losing in Belgian professional soccer. Appl. Sci. 2021, 11, 2378. [Google Scholar] [CrossRef]
- Robles-Palazón, F.J.; Puerta-Callejón, J.M.; Gámez, J.A.; Croix, M.D.S.; Cejudo, A.; Santonja, F.; de Baranda, P.S.; Ayala, F. Predicting injury risk using machine learning in male youth soccer players. Chaos Solitons Fractals 2023, 167, 113079. [Google Scholar] [CrossRef]
- Majumdar, A.; Bakirov, R.; Hodges, D.; McCullagh, S.; Rees, T. A multi-season machine learning approach to examine the training load and injury relationship in professional soccer. J. Sports Anal. 2024, 10, 47–65. [Google Scholar] [CrossRef]
- Majumdar, A.; Bakirov, R.; Hodges, D.; Scott, S.; Rees, T. Machine learning for understanding and predicting injuries in soccer. Sports Med.-Open 2022, 8, 49. [Google Scholar] [CrossRef]
- Forcher, L.; Beckmann, T.; Wohak, O.; Romeike, C.; Graf, F.; Altmann, S. Prediction of defensive success in elite soccer using machine learning-Tactical analysis of defensive play using tracking data and explainable AI. Sci. Med. Footb. 2023, in press. [CrossRef]
- Stival, L.; Pinto, A.; Andrade, F.d.S.P.d.; Santiago, P.R.P.; Biermann, H.; Torres, R.d.S.; Dias, U. Using machine learning pipeline to predict entry into the attack zone in football. PLoS ONE 2023, 18, e0265372. [Google Scholar] [CrossRef]
- Tümer, A.E.; Akyıldız, Z.; Güler, A.H.; Saka, E.K.; Ievoli, R.; Palazzo, L.; Clemente, F.M. Prediction of soccer clubs’ league rankings by machine learning methods: The case of Turkish Super League. Proc. Inst. Mech. Eng. Part P J. Sports Eng. Technol. 2022; in press. [Google Scholar] [CrossRef]
- Li, C.; Zhao, Y. Comparison of goal scoring patterns in “The Big Five” European football leagues. Front. Psychol. 2021, 11, 619304. [Google Scholar] [CrossRef]
- Whoscored. Statistics. Available online: https://www.whoscored.com/Statistics (accessed on 20 July 2023).
- Liu, H.; Hopkins, W.; Gómez, A.M.; Molinuevo, S.J. Inter-operator reliability of live football match statistics from OPTA Sportsdata. Int. J. Perform. Anal. Sport 2013, 13, 803–821. [Google Scholar] [CrossRef]
- Kessouri, O. Match performance difference between African and Top Five teams in the group stage of the 2022 World Cup. Trends Sport Sci. 2023, 30, 5–11. [Google Scholar] [CrossRef]
- Yi, Q.; Groom, R.; Dai, C.; Liu, H.; Gómez Ruano, M.Á. Differences in technical performance of players from ‘the big five’European football leagues in the UEFA Champions League. Front. Psychol. 2019, 10, 2738. [Google Scholar] [CrossRef]
- Whoscored. Glossary. Available online: https://www.whoscored.com/Glossary?fbclid=IwY2xjawEhuvZleHRuA2FlbQIxMAABHY0BGSX-n2SvqNFQAXM8fe1YrepDyQLyggXI6N5Gcwuyitw-OMQlRP45DQ_aem_RkdOv8VmWvsHjpUArenZLg (accessed on 30 July 2024).
- Opta. Opta Event Definitions. Available online: https://www.statsperform.com/opta-event-definitions/?fbclid=IwY2xjawEhuvpleHRuA2FlbQIxMAABHTT4_KxCgegjiu1-EetYNDfx94A--zoxUjiH8k5GoGGOj4JOddAI0ywFQg_aem_ULv1_JcQQUkT30bFLaoOlA (accessed on 30 July 2024).
- Reis, M.A.M.D.; Vasconcellos, F.V.D.A.; Almeida, M.B.D. Analysis of the effectiveness of long distance passes in 2014 Brazil FIFA World Cup. Rev. Bras. Cineantropometria Desempenho Hum. 2017, 19, 676–685. [Google Scholar] [CrossRef]
- Kapsalis, M.; Plakias, S.; Kyranoudis, A.; Zarkadoula, A.; Lathoura, A.; Tsatalas, T. Exploring the impact of possession-based performance indicators on goal scoring in elite football leagues. J. Phys. Educ. Sport 2023, 23, 2004–2015. [Google Scholar] [CrossRef]
- Rahimian, P.; Van Haaren, J.; Toka, L. Towards maximizing expected possession outcome in soccer. Int. J. Sports Sci. Coach. 2024, 19, 230–244. [Google Scholar] [CrossRef]
- Adams, D.; Morgans, R.; Sacramento, J.; Morgan, S.; Williams, M.D. Successful short passing frequency of defenders differentiates between top and bottom four English Premier League teams. Int. J. Perform. Anal. Sport 2013, 13, 653–668. [Google Scholar] [CrossRef]
- Plakias, S.; Mandroukas, A.; Kokkotis, C.; Michailidis, Y.; Mavromatis, G.; Metaxas, T. The correlation of the penetrative pass on offensive third with the possession of the ball in high level soccer. Gazzetta Med. Ital.-Arch. Sci. Med. 2022, 181, 633–638. [Google Scholar] [CrossRef]
- Gonzalez-Rodenas, J.; Lopez-Bondia, I.; Calabuig, F.; Pérez-Turpin, J.A.; Aranda, R. Creation of goal scoring opportunities by means of different types of offensive actions in US major league soccer. Hum. Mov. Spec. Issues 2017, 2017, 106–116. [Google Scholar] [CrossRef]
- Freitas, R.; Volossovitch, A.; Almeida, C.H.; Vleck, V. Elite-level defensive performance in football: A systematic review. Ger. J. Exerc. Sport Res. 2023, 53, 458–470. [Google Scholar] [CrossRef]
- Hassan, A.; Akl, A.-R.; Hassan, I.; Sunderland, C. Predicting wins, losses and attributes’ sensitivities in the soccer world cup 2018 using neural network analysis. Sensors 2020, 20, 3213. [Google Scholar] [CrossRef]
- Li, Y.; Ma, R.; Gonçalves, B.; Gong, B.; Cui, Y.; Shen, Y. Data-driven team ranking and match performance analysis in Chinese Football Super League. Chaos Solitons Fractals 2020, 141, 110330. [Google Scholar] [CrossRef]
- Castellano, J.; Casamichana, D.; Lago, C. The use of match statistics that discriminate between successful and unsuccessful soccer teams. J. Hum. Kinet. 2012, 31, 139. [Google Scholar] [CrossRef]
- Lago-Ballesteros, J.; Lago-Peñas, C. Performance in team sports: Identifying the keys to success in soccer. J. Hum. Kinet. 2010, 25, 85–91. [Google Scholar] [CrossRef]
- Engler, F.; Hohmann, A.; Siener, M. Validation of a New Soccer Shooting Test Based on Speed Radar Measurement and Shooting Accuracy. Children 2023, 10, 199. [Google Scholar] [CrossRef] [PubMed]
- Yue, Z.; Broich, H.; Mester, J. Statistical analysis for the soccer matches of the first Bundesliga. Int. J. Sports Sci. Coach. 2014, 9, 553–560. [Google Scholar] [CrossRef]
- Swathi, Y.; Challa, M. A Comparative Analysis of Explainable AI Techniques for Enhanced Model Interpretability. In Proceedings of the 2023 3rd International Conference on Pervasive Computing and Social Networking (ICPCSN), Salem, India, 19–20 June 2023; pp. 229–234. [Google Scholar]
- Klimo, M.; Kopčan, J.; Králik, L.u. Explainability as a Method for Learning From Computers. IEEE Access 2023, 11, 35853–35865. [Google Scholar] [CrossRef]
- Plakias, S.; Tsatalas, T.; Armatas, V.; Tsaopoulos, D.; Giakas, G. Tactical Situations and Playing Styles as Key Performance Indicators in Soccer. J. Funct. Morphol. Kinesiol. 2024, 9, 88. [Google Scholar] [CrossRef] [PubMed]
- Prieto, J.; Gómez, M.-Á.; Sampaio, J. From a static to a dynamic perspective in handball match analysis: A systematic review. Open Sports Sci. J. 2015, 8, 25–34. [Google Scholar] [CrossRef]
- Pratas, J.M.; Volossovitch, A.; Carita, A.I. Goal scoring in elite male football: A systematic review. J. Hum. Sport Exerc. 2018, 13, 218–230. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Position | Team | Points | Cluster |
|---|---|---|---|
| 1 | PSG | 85 | 1 |
| 2 | Lens | 84 | 1 |
| 3 | Marseille | 73 | 1 |
| 4 | Rennes | 68 | 2 |
| 5 | Lille | 67 | 2 |
| 6 | Monaco | 65 | 2 |
| 7 | Lyon | 62 | 2 |
| 8 | Clermont | 59 | 2 |
| 9 | Nice | 58 | 2 |
| 10 | Lorient | 55 | 2 |
| 11 | Reims | 51 | 3 |
| 12 | Montpellier | 50 | 3 |
| 13 | Toulouse | 48 | 3 |
| 14 | Brest | 44 | 3 |
| 15 | Strasbourg | 40 | 3 |
| 16 | Nantes | 36 | 3 |
| 17 | Auxerre | 35 | 3 |
| 18 | Ajaccio | 26 | 3 |
| 19 | Troyes | 24 | 3 |
| 20 | Angers | 18 | 3 |
| ML Models | Accuracy | Recall | F1-Score | Precision | Num of Features |
|---|---|---|---|---|---|
| XGBoost | 88.42% | 32.53% | 45.43% | 77.51% | 18 |
| SVM | 87.89% | 27.19% | 39.54% | 78.79% | 10 |
| LR | 75.13% | 76.32% | 48.03% | 35.15% | 6 |
| Features | Relative Importance | Description | Variable’s Type |
|---|---|---|---|
| SHORT PASSES | 0.71 | Passes shorter than 15 yards | Numeric |
| THROUGH BALLS | 0.48 | An attempted/accurate pass between opposition players in their defensive line to find an onrushing teammate | Numeric |
| LONG BALLS | −0.58 | Passes longer than 25 yards | Numeric |
| TACKLES ATTEMPTED | −0.46 | Dispossessing an opponent, whether the tackling player comes away with the ball or not | Numeric |
| SHOTS TOTAL COUNT | 0.12 | All attempts to score a goal made with any (legal) part of the body, either on or off target | Numeric |
| ATTEMPTS SET PIECES | −0.06 | The percentage of attempts that have been made via a set piece situation (in relation to the total attempts from set pieces and open play). | Numeric |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plakias, S.; Kokkotis, C.; Mitrotasios, M.; Armatas, V.; Tsatalas, T.; Giakas, G. Identifying Key Factors for Securing a Champions League Position in French Ligue 1 Using Explainable Machine Learning Techniques. Appl. Sci. 2024, 14, 8375. https://doi.org/10.3390/app14188375
Plakias S, Kokkotis C, Mitrotasios M, Armatas V, Tsatalas T, Giakas G. Identifying Key Factors for Securing a Champions League Position in French Ligue 1 Using Explainable Machine Learning Techniques. Applied Sciences. 2024; 14(18):8375. https://doi.org/10.3390/app14188375
Chicago/Turabian StylePlakias, Spyridon, Christos Kokkotis, Michalis Mitrotasios, Vasileios Armatas, Themistoklis Tsatalas, and Giannis Giakas. 2024. "Identifying Key Factors for Securing a Champions League Position in French Ligue 1 Using Explainable Machine Learning Techniques" Applied Sciences 14, no. 18: 8375. https://doi.org/10.3390/app14188375