
AIS Data Driven Ship Behavior Modeling in Fairways: A Random Forest Based Approach


Abstract
:1. Introduction
2. Related Work
2.1. Ship Behavior Learning Method
2.2. Ship Trajectory Prediction
3. Methodology
3.1. Problem Definition
- Extraction of Waterway Data: Since the research is concentrated on vessel behavior within the channel, it is crucial to confine the range of AIS data to the boundaries of the channel;
- Preprocessing of Historical AIS Data: This involves filtering out anomalous AIS data to ensure that the training process is not adversely affected;
- Organization of Training Data: This step includes reformatting AIS data to create labeled training datasets suitable for analysis;
- Learning Vessel Behavior Patterns: The study employs Decision Tree, Random Forest, and Gradient Boosting Regression methods to analyze and model vessel behavior patterns within the Waterway.
3.2. AIS Data Pre-Processing
| Algorithm 1: Ray-Casting Algorithm |
 |
3.3. Model Training
4. Results Analysis and Discussion
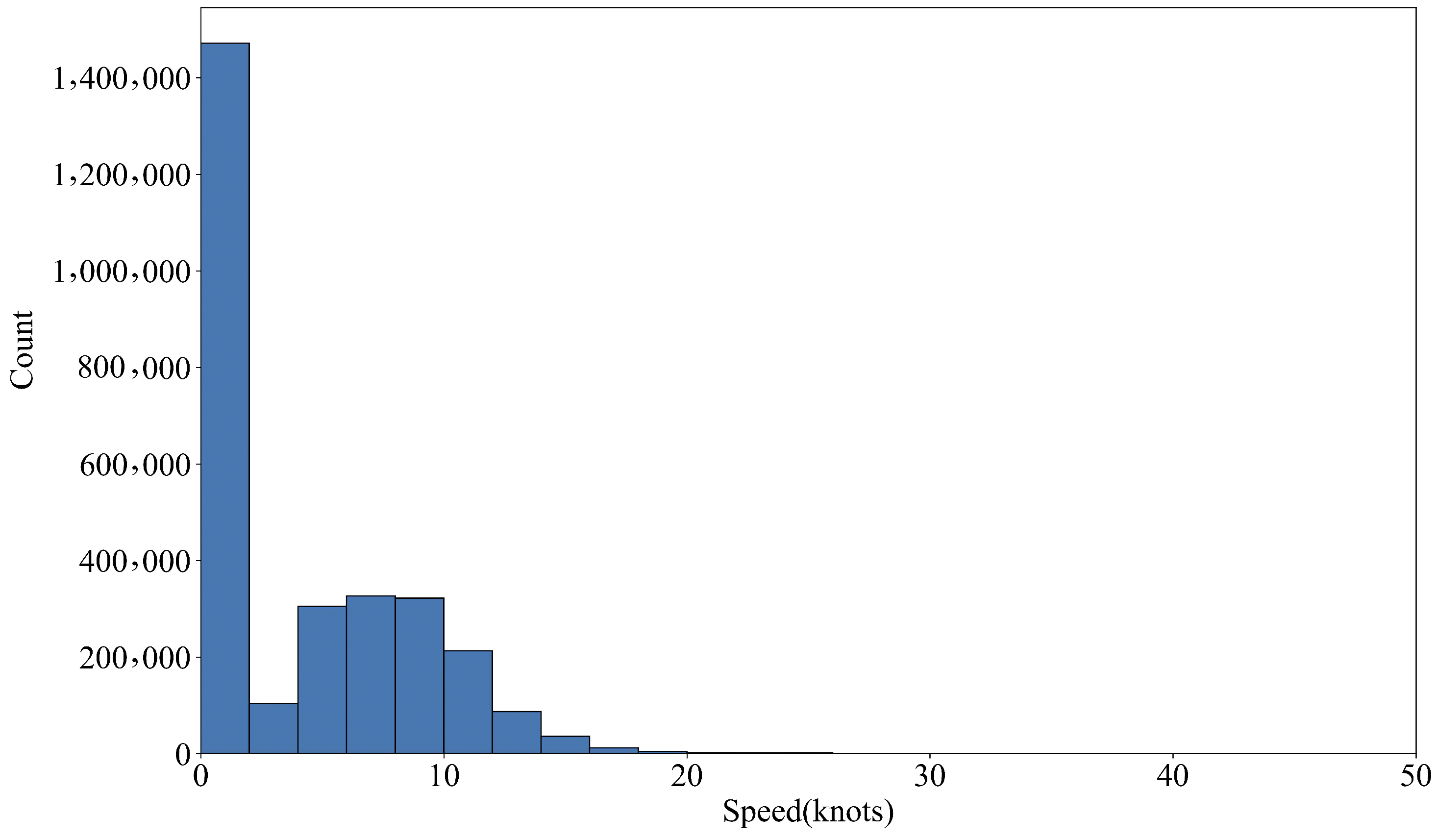
4.1. Experimental Data
4.2. Performance Metrics
4.3. Model Parameter Settings
4.4. Learning Curves
4.5. Feature Importance Comparison
4.6. Prediction Error Analysis
4.7. Complete Trajectory Prediction
5. Conclusions
- The Random Forest method outperforms both Gradient Boosting Regression and Decision Tree models in predicting vessel behavior within navigational channels. After hyperparameter tuning, the model achieves optimal performance with n_estimators set to 300, max_depth to 35, min_samples_split to 2, and min_samples_leaf to 1.
- Through feature importance analysis, it is determined that vessel width, draft, and vessel type have low importance in the model. A comparison between models with and without these features shows minimal changes in mean squared error (MSE) and adjusted , indicating that these features can be omitted to reduce model complexity and training costs without significantly affecting performance.
- Analyzing the prediction errors for longitude, latitude, heading, and speed on the test set, the Random Forest model consistently shows the lowest MSE, with values of 2293.859, 6790.852, 6.071, and 33.242, respectively. Compared to Gradient Boosting Regression and Decision Tree models, the MSE is reduced by 65.1%, 50.6%, 60.5%, and 54.4%, respectively, and by 69.1%, 40.1%, 43.5%, and 64.2%, respectively.
- The study validates the models using complete trajectories of two vessels of different sizes, types, and berthing locations, along with predictions of speed and heading at each trajectory point. The Random Forest model demonstrates superior performance in accurately predicting vessel behavior within the navigational channel.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AIS | Automatic Identification System |
| COG | Course over ground |
| SOG | Speed over ground |
| SOLAS | International Convention for Safety of Life at Sea |
References
- Jiang, Q.; Ji, M.; Wang, J.; Sun, P. Remote Sensing Methods for Striped Marine Oil Spill Detection in Narrow Ship Channels. Ocean Eng. 2023, 289, 116162. [Google Scholar] [CrossRef]
- Xiao, Z.; Fu, X.; Zhang, L.; Goh, R.S.M. Traffic Pattern Mining and Forecasting Technologies in Maritime Traffic Service Networks: A Comprehensive Survey. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1796–1825. [Google Scholar] [CrossRef]
- Xu, L.; Di, Z.; Chen, J.; Shi, J.; Yang, C. Evolutionary Game Analysis on Behavior Strategies of Multiple Stakeholders in Maritime Shore Power System. Ocean Coast. Manag. 2021, 202, 105508. [Google Scholar] [CrossRef]
- Park, S.; Kang, W.-S.; Park, Y.-S. Analysis of Minimum Speed Control Effect Using Queue Model Focusing on Busan Port. J. Mar. Sci. Technol.-Taiwan 2020, 28, 564–571. [Google Scholar]
- Wolsing, K.; Roepert, L.; Bauer, J.; Wehrle, K. Anomaly Detection in Maritime AIS Tracks: A Review of Recent Approaches. J. Mar. Sci. Eng. 2022, 10, 112. [Google Scholar] [CrossRef]
- Rindone, C. AIS Data for Building a Transport Maritime Network: A Pilot Study in the Strait of Messina (Italy). In Proceedings of the International Conference on Computational Science and Its Applications, Braga, Portugal, 1–4 July 2024; Springer Nature Switzerland: Cham, Switzerland, 2024; Volume 11, pp. 213–226. [Google Scholar]
- Russo, F.; Musolino, G. State of the Art of Factors Affecting Times of Ships in Container Ports: Characteristics Identification of Port Generations. In Proceedings of the International Conference on Computational Science and Its Applications, Braga, Portugal, 1–4 July 2024; Springer Nature Switzerland: Cham, Switzerland, 2024; Volume 3, pp. 283–295. [Google Scholar]
- Guo, Z.; Qiang, H.; Xie, S.; Peng, X. Unsupervised Knowledge Discovery Framework: From AIS Data Processing to Maritime Traffic Networks Generating. Appl. Ocean Res. 2024, 146, 103924. [Google Scholar] [CrossRef]
- Zhang, S.; Shi, G.; Liu, Z.; Zhao, Z.; Wu, Z. Data-Driven Based Automatic Maritime Routing from Massive AIS Trajectories in the Face of Disparity. Ocean Eng. 2018, 155, 240–250. [Google Scholar] [CrossRef]
- Kim, K.-I.; Jeong, J.S.; Park, G.-K. Development of a Gridded Maritime Traffic DB for E-Navigation. Int. J. E-Navig. Marit. Econ. 2014, 1, 39–47. [Google Scholar] [CrossRef]
- Ristic, B. Detecting Anomalies from a Multitarget Tracking Output. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 798–803. [Google Scholar] [CrossRef]
- Xiao, Z.; Ponnambalam, L.; Fu, X.; Zhang, W. Maritime Traffic Probabilistic Forecasting Based on Vessels’ Waterway Patterns and Motion Behaviors. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3122–3134. [Google Scholar] [CrossRef]
- Pallotta, G.; Vespe, M.; Bryan, K. Vessel Pattern Knowledge Discovery from AIS Data: A Framework for Anomaly Detection and Route Prediction. Entropy 2013, 15, 2218–2245. [Google Scholar] [CrossRef]
- Vespe, M.; Visentini, I.; Bryan, K.; Braca, P. Unsupervised learning of maritime traffic patterns for anomaly detection. In Proceedings of the 9th IET Data Fusion & Target Tracking Conference (DF&TT 2012): Algorithms & Applications, London, UK, 16–17 May; 2012; Volume 10, pp. 1–5. [Google Scholar]
- Ristic, B.; Scala, B.; Morelande, M.; Gordon, N. Statistical analysis of motion patterns in AIS Data: Anomaly detection and motion prediction. In Proceedings of the 2008 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; Volume 10, pp. 1–7. [Google Scholar]
- Xiao, F.; Ligteringen, H.; van Gulijk, C.; Ale, B.J.M. AIS data analysis for realistic ship traffic simulation model. In Proceedings of the International Workshop on Next Generation of Nautical Traffic Model, Shanghai, China, 21–24 September 2012; pp. 44–49. [Google Scholar]
- Wu, X.; Rahman, A.; Zaloom, V. Study of Vessel Travel Behavior at Hot Spots in Sabine-Neches Waterway. Ocean Eng. 2018, 147, 399–413. [Google Scholar] [CrossRef]
- Ma, J.; Hu, Q.; Liu, T.; Zhu, Z.; Zhou, Y. Research on Ship Collision Risk Calculation in Port Navigation Waters Based on Ising Model and AIS Data. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A: Civ. Eng. 2024, 10, 04024003. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, Z.; Zhou, Z.; Chen, X.; Wu, B.; Wang, S. A Ship Trajectory Prediction Method Based on GAT and LSTM. Ocean Eng. 2023, 289, 116159. [Google Scholar] [CrossRef]
- Wu, Y.; Yv, W.; Zeng, G.; Shang, Y.; Liao, W. GL-STGCNN: Enhancing Multi-Ship Trajectory Prediction with MPC Correction. J. Mar. Sci. Eng. 2024, 12, 882. [Google Scholar] [CrossRef]
- Li, W.; Lian, Y.; Liu, Y.; Shi, G. Ship Trajectory Prediction Model Based on Improved Bi-LSTM. ASCE-ASME J. Risk. Uncertain. Eng. Syst. Part A.-Civ. Eng. 2024, 10, 04024033. [Google Scholar] [CrossRef]
- Chen, X.; Wei, C.; Zhou, G.; Wu, H.; Wang, Z.; Biancardo, S.A. Automatic Identification System (AIS) Data Supported Ship Trajectory Prediction and Analysis via a Deep Learning Model. J. Mar. Sci. Eng. 2022, 10, 1314. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, Y.; Su, J.; Lu, W.; Li, J.; Yao, Y. A Hybrid Prediction Model Based on KNN-LSTM for Vessel Trajectory. Mathematics 2022, 10, 4493. [Google Scholar] [CrossRef]
- Tian, X.; Suo, Y. Research on Ship Trajectory Prediction Method Based on Difference Long Short-Term Memory. J. Mar. Sci. Eng. 2023, 11, 1731. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, H.; Cui, F.; Liu, Y.; Liu, Z.; Dong, J. Research into Ship Trajectory Prediction Based on An Improved LSTM Network. J. Mar. Sci. Eng. 2023, 11, 1268. [Google Scholar] [CrossRef]
- Zhang, D.; Chu, X.; Wu, W.; He, Z.; Wang, Z.; Liu, C. Model Identification of Ship Turning Maneuver and Extreme Short-Term Trajectory Prediction under the Influence of Sea Currents. Ocean Eng. 2023, 278, 114367. [Google Scholar] [CrossRef]
- Bao, K.; Bi, J.; Gao, M.; Sun, Y.; Zhang, X.; Zhang, W. An Improved Ship Trajectory Prediction Based on AIS Data Using MHA-BiGRU. J. Mar. Sci. Eng. 2022, 10, 804. [Google Scholar] [CrossRef]
- Wu, W.; Chen, P.; Chen, L.; Mou, J. Ship Trajectory Prediction: An Integrated Approach Using ConvLSTM-Based Sequence-to-Sequence Model. J. Mar. Sci. Eng. 2023, 11, 1484. [Google Scholar] [CrossRef]
- Liu, J.; Shi, G.; Zhu, K. Vessel Trajectory Prediction Model Based on AIS Sensor Data and Adaptive Chaos Differential Evolution Support Vector Regression (ACDE-SVR). Appl. Sci. 2019, 9, 2983. [Google Scholar] [CrossRef]
- Qian, L.; Zheng, Y.; Li, L.; Ma, Y.; Zhou, C.; Zhang, D. A New Method of Inland Water Ship Trajectory Prediction Based on Long Short-Term Memory Network Optimized by Genetic Algorithm. Appl. Sci. 2022, 12, 4073. [Google Scholar] [CrossRef]
- Jia, H.; Yang, Y.; An, J.; Fu, R. A Ship Trajectory Prediction Model Based on Attention-BILSTM Optimized by the Whale Optimization Algorithm. Appl. Sci. 2023, 13, 4907. [Google Scholar] [CrossRef]
- Roth, S. Ray Casting for Modeling Solids. Comput. Graph. Image Process. 1982, 18, 109–144. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter Name | Parameter Range | Best Parameter |
|---|---|---|---|
| max_depth | 1, 5, 10, 20, 50, 100 | 20 | |
| Decision Tree | min_samples_split | 2, 3, 5, 10, 20, 30 | 2 |
| min_samples_leaf | 1, 2, 4, 10, 20, 30 | 1 | |
| learning_rate | 0.01, 0.1, 0.2, 0.3, 0.5, 1.0 | 0.1 | |
| n_estimators | 10, 25, 50, 100, 200, 300 | 300 | |
| Gradient Boosting Regression | max_depth | 1,3, 5, 9,10,30 | 9 |
| min_samples_split | 2, 5, 7, 9, 15, 20 | 7 | |
| min_samples_leaf | 1, 2, 5, 8, 10, 15 | 2 | |
| n_estimators | 10, 20, 50, 100, 300, 500 | 300 | |
| max_depth | 1, 5, 10, 35, 50, 100 | 35 | |
| Random Forest | min_samples_split | 2, 3, 5, 10, 20, 30 | 2 |
| min_samples_leaf | 1, 3, 5, 10, 15, 20 | 1 |
| Model | Parameter | MSE | Adjusted |
|---|---|---|---|
| Random Forest | LON | 2293.8592 | 0.9999 |
| LAT | 6790.8516 | 0.9999 | |
| SOG | 6.0709 | 0.9957 | |
| COG | 33.2415 | 0.9727 | |
| Random Forest | LON | 18,823.2767 | 0.9998 |
| LAT | 27,791.3605 | 0.9996 | |
| SOG | 38.9861 | 0.9923 | |
| COG | 160.2386 | 0.9812 | |
| Decision Tree | LON | 23,957.7198 | 0.9979 |
| LAT | 18,916.4763 | 0.9978 | |
| SOG | 19.0222 | 0.9871 | |
| COG | 259.5119 | 0.9359 |
| Model | Position | COG | SOG |
|---|---|---|---|
| Random Forest | 743.8657 | 0.5998 | 0.0199 |
| Gradient Boosting Regression | 8899.3125 | 15.169 | 0.0178 |
| Decision Tree | 193,224.89 | 5405.0668 | 1.5231 |
| Model | Position | COG | SOG |
|---|---|---|---|
| Random Forest | 422.5002 | 1.2202 | 0.0023 |
| Gradient Boosting Regression | 8571.1916 | 132.4752 | 0.0401 |
| Decision Tree | 1,010,341.8 | 11,931.0257 | 3.2384 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Guo, Z.; Shi, G. AIS Data Driven Ship Behavior Modeling in Fairways: A Random Forest Based Approach. Appl. Sci. 2024, 14, 8484. https://doi.org/10.3390/app14188484
Ma L, Guo Z, Shi G. AIS Data Driven Ship Behavior Modeling in Fairways: A Random Forest Based Approach. Applied Sciences. 2024; 14(18):8484. https://doi.org/10.3390/app14188484
Chicago/Turabian StyleMa, Lin, Zhuang Guo, and Guoyou Shi. 2024. "AIS Data Driven Ship Behavior Modeling in Fairways: A Random Forest Based Approach" Applied Sciences 14, no. 18: 8484. https://doi.org/10.3390/app14188484