A Fast Sparse Coding Method for Image Classification


Abstract
:1. Introduction
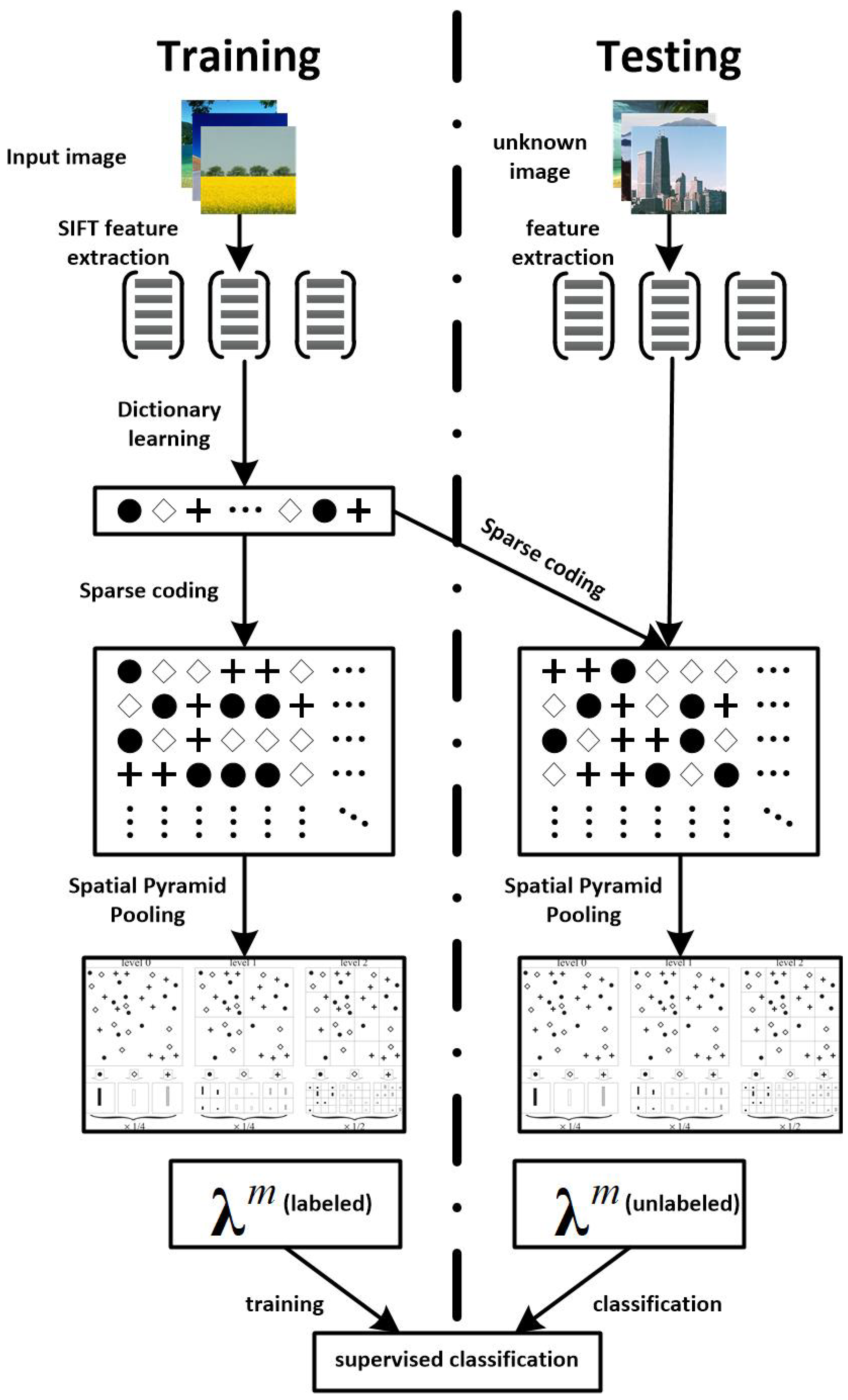
2. Methods
2.1. SIFT Feature Extraction
2.2. k-Medoids Dictionary Learning
2.3. Sparse Coding
2.4. ScSPM Feature Building and Classification
3. Results
3.1. Caltech-101 Dataset
3.2. UIUC-Sports Dataset
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 1458–1465. [Google Scholar]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local features and kernels for classification of texture and object categories: A comprehensive study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef]
- Wu, J.; Rehg, J.M. Beyond the euclidean distance: Creating effective visual codebooks using the histogram intersection kernel. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 9 September–2 October 2009; pp. 630–637. [Google Scholar]
- Liu, T.; Si, Y.; Wen, D.; Zang, M.; Lang, L. Dictionary learning for VQ feature extraction in ECG beats classification. Expert Syst. Appl. 2016, 53, 129–137. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. Comput. Vis. Image Underst. 2007, 106, 59–70. [Google Scholar] [CrossRef]
- Chong, W.; Blei, D.; Li, F.F. Simultaneous image classification and annotation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1903–1910. [Google Scholar]
- Zang, M.; Wen, D.; Wang, K.; Liu, T.; Song, W. A novel topic feature for image scene classification. Neurocomputing 2015, 148, 467–476. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Niu, Z.; Hua, G.; Gao, X.; Tian, Q. Context aware topic model for scene recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2743–2750. [Google Scholar]
- Wang, X.; Grimson, E. Spatial latent dirichlet allocation. In Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1577–1584. [Google Scholar]
- Zang, M.; Wen, D.; Liu, T.; Zou, H.; Liu, C. A pooled Object Bank descriptor for image scene classification. Expert Syst. Appl. 2018, 94, 250–264. [Google Scholar] [CrossRef]
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1794–1801. [Google Scholar]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained linear coding for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Yu, K.; Zhang, T.; Gong, Y. Nonlinear learning using local coordinate coding. In Proceedings of the Twenty-Third Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 2223–2231. [Google Scholar]
- Gao, S.; Tsang, I.W.H.; Chia, L.T.; Zhao, P. Local features are not lonely—Laplacian sparse coding for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3555–3561. [Google Scholar]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 801–808. [Google Scholar]
- Bottou, L.; Bousquet, O. The tradeoffs of large scale learning. In Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 161–168. [Google Scholar]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 689–696. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Quelhas, P.; Monay, F.; Odobez, J.M.; Gatica-Perez, D.; Tuytelaars, T.; Van Gool, L. Modeling scenes with local descriptors and latent aspects. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 1, pp. 883–890. [Google Scholar]
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene classification via pLSA. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 517–530. [Google Scholar]
- Li, L.J.; Fei-Fei, L. What, where and who? Classifying events by scene and object recognition. In Proceedings of the IEEE International Conference on Computer Vision, io de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Luo, W.; Li, J.; Yang, J.; Xu, W.; Zhang, J. Convolutional sparse autoencoders for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3289–3294. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Proceedings of the Twenty-eighth Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 487–495. [Google Scholar]
- Boureau, Y.L.; Le Roux, N.; Bach, F.; Ponce, J.; LeCun, Y. Ask the locals: Multi-way local pooling for image recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2651–2658. [Google Scholar]
- Feng, J.; Ni, B.; Tian, Q.; Yan, S. Geometric ℓp-norm feature pooling for image classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2609–2704. [Google Scholar]
- Yang, M.; Chang, H.; Luo, W. Discriminative analysis-synthesis dictionary learning for image classification. Neurocomputing 2017, 219, 404–411. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Shi, W.; Gong, Y.; Xia, Y.; Zhanga, Y. Normalized Non-Negative Sparse Encoder for Fast Image Representation. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Lin, G.; Fan, C.; Zhu, H.; Miu, Y.; Kang, X. Visual feature coding based on heterogeneous structure fusion for image classification. Inf. Fus. 2017, 36, 275–283. [Google Scholar] [CrossRef]
- Kabbai, L.; Abdellaoui, M.; Douik, A. Image classification by combining local and global features. Vis. Comput. 2018, 1–15. [Google Scholar] [CrossRef]
- Li, L.J.; Su, H.; Fei-Fei, L.; Xing, E.P. Object bank: A high-level image representation for scene classification & semantic feature sparsification. In Proceedings of the Twenty-fourth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1378–1386. [Google Scholar]
- Liu, Q.; Liu, C. A novel locally linear KNN method with applications to visual recognition. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2010–2021. [Google Scholar] [PubMed]
- Bai, S.; Li, Z.; Hou, J. Learning two-pathway convolutional neural networks for categorizing scene images. Multimed. Tools Appl. 2017, 76, 16145–16162. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Tao, X.; Gong, Y.; Zheng, N. Constructing deep sparse coding network for image classification. Pattern Recognit. 2017, 64, 130–140. [Google Scholar]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Chen, H.; Xie, K.; Wang, H.; Zhao, C. Scene image classification using locality-constrained linear coding based on histogram intersection. Multimed. Tools Appl. 2018, 77, 4081–4092. [Google Scholar] [CrossRef]
- Hu, J.; Tan, Y.P. Nonlinear dictionary learning with application to image classification. Pattern Recognit. 2018, 75, 282–291. [Google Scholar] [CrossRef]
- Liu, L.; Wang, L.; Liu, X. In defense of soft-assignment coding. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2486–2493. [Google Scholar]
- Li, L.J.; Zhu, J.; Su, H.; Xing, E.P.; Fei-Fei, L. Multi-level structured image coding on high-dimensional image representation. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 147–161. [Google Scholar]
- Li, L.J.; Su, H.; Lim, Y.; Fei-Fei, L. Object bank: An object-level image representation for high-level visual recognition. Int. J. Comput. Vis. 2014, 107, 20–39. [Google Scholar] [CrossRef]


{kind=link}
| // Initialization |
| // Input all samples as |
| // Randomly select a sample to join the medoids set as the first medoid |
| do |
| // Iteratively search for other medoids |
| for |
| // Allocation cluster numbers of candidate samples |
| for |
| do |
| end |
| // Calculating the selecting probability of the candidate samples |
| for |
| do |
| end |
| // Extracting a candidate sample as a medoid by probability |
| do |
| end |
| // Learning dictionary |
| // Allocation cluster number |
| for |
| do |
| end |
| // Update dictionary |
| for |
| do |
| end |
| // To determine whether convergence |
| if |
| do “Output as medoids” |
| else Go to the step “// Allocation cluster number” |
| end |
| Algorithms | 15 Training | 30 Training |
|---|---|---|
| SPM [1] | 56.4% | 66.4% |
| ScSPM [13] | 67.0% | 73.2% |
| LLC [14] | 65.4% | 73.4% |
| Local Pooling [26] | - | 77.3% |
| GLP [27] | 70.3% | 82.7% |
| DASDL [28] | - | 75.5% |
| encoder [29] | 67.5% | 73.9% |
| FScSPM (Our Approach) | 76.3% | 84.8% |
| Algorithms | 15 Training | 30 Training |
|---|---|---|
| HVFC-HSF [30] | 70.7% | 78.7% |
| CLGC(RGB-RGB) [31] | - | 72.6% |
| CSAE [24] | 64.0% | 71.4% |
| Hybrid-CNN [25] | - | 84.8% |
| FScSPM (Our Approach) | 76.3% | 84.8% |
| Algorithms | Avg. Accuracy |
|---|---|
| LScSPM [16] | 85.3% |
| MR-BoF [36] | 85.1% |
| HILLC+SPM [37] | 85.0% |
| SNDL [38] | 85.2% |
| FScSPM (Our Approach) | 86.7% |
| Algorithms | Avg. Accuracy |
|---|---|
| Local Soft Assignment [39] | 82.3% |
| LLKc [33] | 86.4% |
| encoder [29] | 85.5% |
| CLGC(RGB-RGB) [31] | 86.4% |
| MUSIC [40] | 81.8% |
| OB2014 [41] | 82.3% |
| Hybrid-CNN [25] | 94.2% |
| TPN-FS [34] | 95.2% |
| DeepSCNet [35] | 87.1% |
| FScSPM (Our Approach) | 86.7% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, M.; Wen, D.; Liu, T.; Zou, H.; Liu, C. A Fast Sparse Coding Method for Image Classification. Appl. Sci. 2019, 9, 505. https://doi.org/10.3390/app9030505
Zang M, Wen D, Liu T, Zou H, Liu C. A Fast Sparse Coding Method for Image Classification. Applied Sciences. 2019; 9(3):505. https://doi.org/10.3390/app9030505
Chicago/Turabian StyleZang, Mujun, Dunwei Wen, Tong Liu, Hailin Zou, and Chanjuan Liu. 2019. "A Fast Sparse Coding Method for Image Classification" Applied Sciences 9, no. 3: 505. https://doi.org/10.3390/app9030505
APA StyleZang, M., Wen, D., Liu, T., Zou, H., & Liu, C. (2019). A Fast Sparse Coding Method for Image Classification. Applied Sciences, 9(3), 505. https://doi.org/10.3390/app9030505