
An Intrinsically Explainable Method to Decode P300 Waveforms from EEG Signal Plots Based on Convolutional Neural Networks


Abstract
:1. Introduction
2. Materials and Methods
2.1. P300 Experiment
2.2. BCI Simulation
2.3. Signal Preprocessing and Plot Generation
2.4. Neural Network Architectures
2.4.1. VGG16
2.4.2. SV16
2.4.3. MSV16
2.5. Dataset Balancing
2.6. Software and Hardware
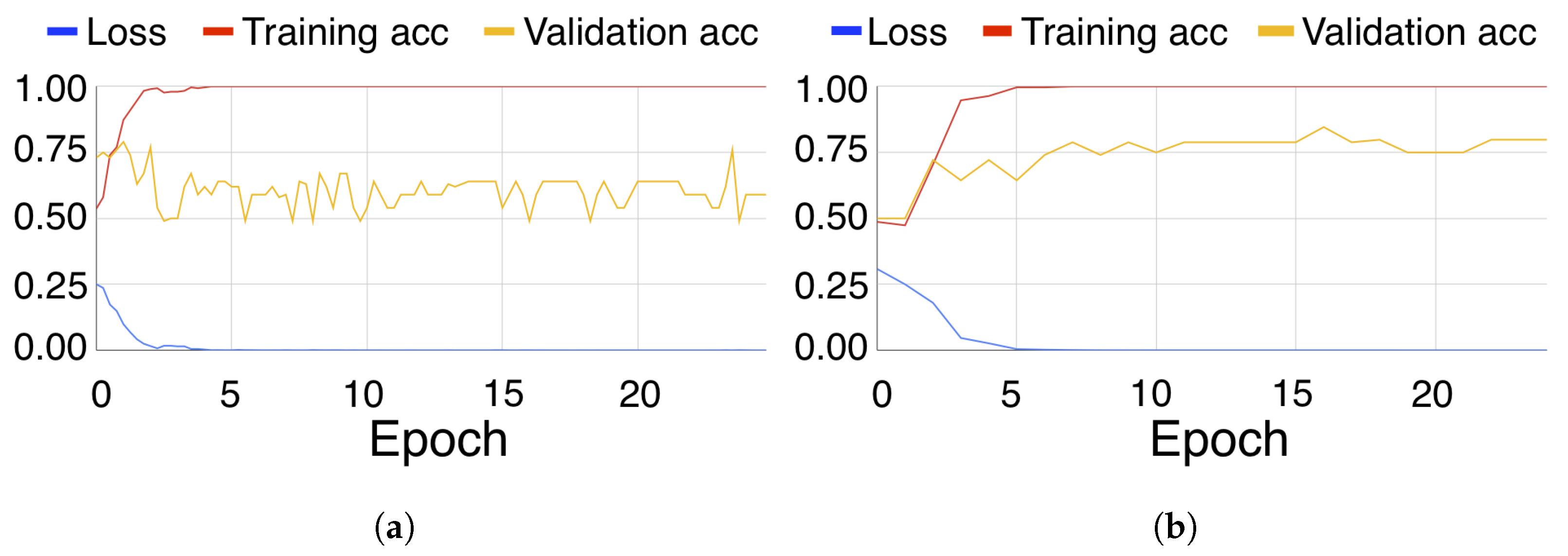
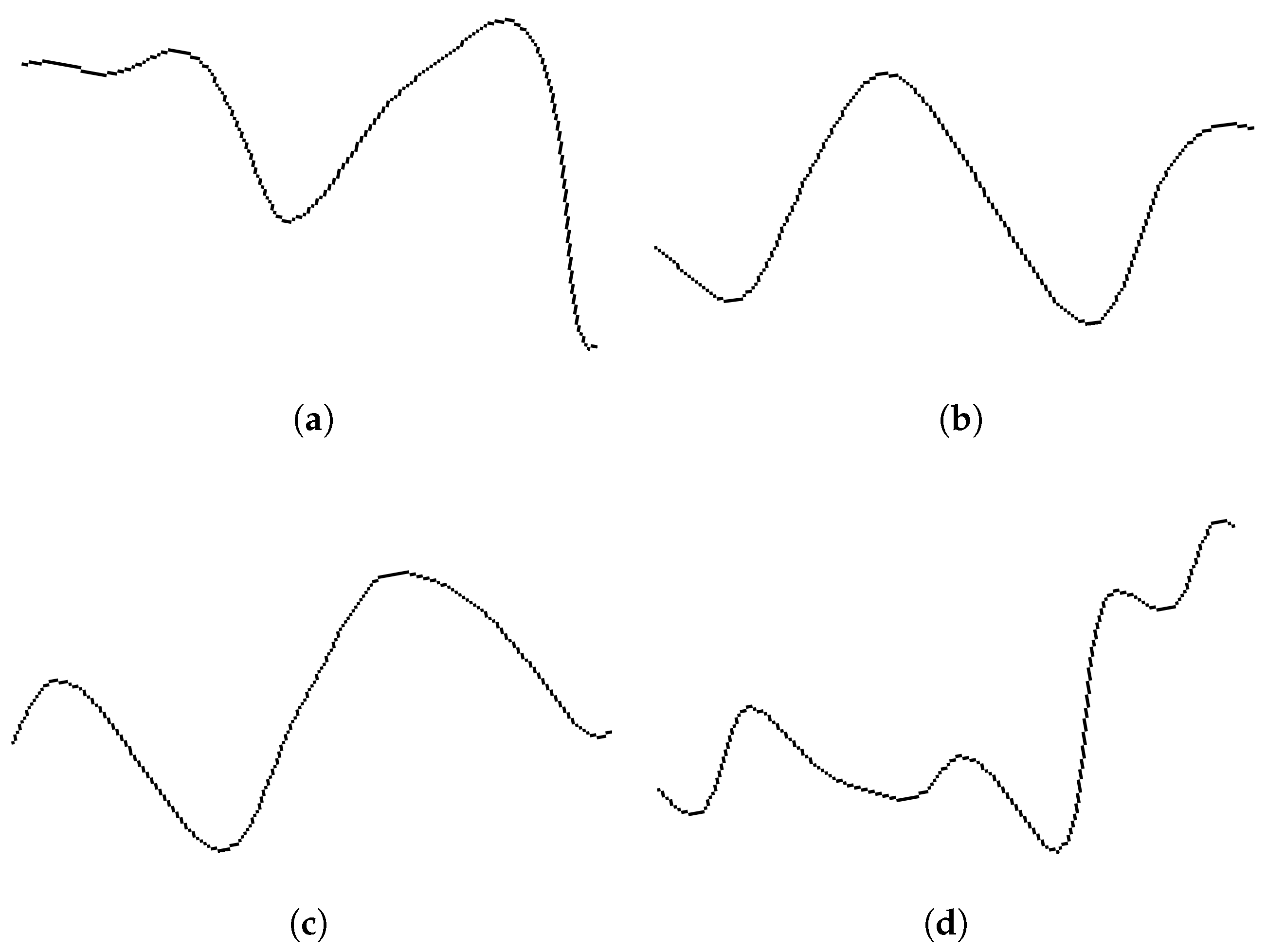
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nicolelis, M.A.L. Brain-machine-brain interfaces as the foundation for the next generation of neuroprostheses. Natl. Sci. Rev. 2021, 9, nwab206. [Google Scholar] [CrossRef] [PubMed]
- Ajiboye, A.B.; Willett, F.R.; Young, D.R.; Memberg, W.D.; Murphy, B.A.; Miller, J.P.; Walter, B.L.; Sweet, J.A.; Hoyen, H.A.; Keith, M.W.; et al. Restoration of reaching and grasping movements through brain-controlled muscle stimulation in a person with tetraplegia: A proof-of-concept demonstration. Lancet 2017, 389, 1821–1830. [Google Scholar] [CrossRef] [PubMed]
- Metzger, S.L.; Liu, J.R.; Moses, D.A.; Dougherty, M.E.; Seaton, M.P.; Littlejohn, K.T.; Chartier, J.; Anumanchipalli, G.K.; Tu-Chan, A.; Ganguly, K.; et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 2022, 13, 6510. [Google Scholar] [CrossRef] [PubMed]
- Willett, F.; Kunz, E.; Fan, C.; Avansino, D.; Wilson, G.; Choi, E.Y.; Kamdar, F.; Hochberg, L.R.; Druckmann, S.; Shenoy, K.V.; et al. A high-performance speech neuroprosthesis. bioRxiv 2023. [Google Scholar] [CrossRef] [PubMed]
- Huggins, J.E.; Krusienski, D.; Vansteensel, M.J.; Valeriani, D.; Thelen, A.; Stavisky, S.; Norton, J.J.; Nijholt, A.; Müller-Putz, G.; Kosmyna, N.; et al. Workshops of the eighth international brain-computer interface meeting: BCIs: The next frontier. Brain-Comput. Interfaces 2022, 9, 69–101. [Google Scholar] [CrossRef]
- Antonietti, A.; Balachandran, P.; Hossaini, A.; Hu, Y.; Valeriani, D. The BCI Glossary: A first proposal for a community review. Brain-Comput. Interfaces 2021, 8, 42–53. [Google Scholar] [CrossRef]
- Orhanbulucu, F.; Latifoğlu, F. Detection of amyotrophic lateral sclerosis disease from event-related potentials using variational mode decomposition method. Comput. Methods Biomech. Biomed. Eng. 2022, 25, 840–851. [Google Scholar] [CrossRef] [PubMed]
- Pugliese, R.; Sala, R.; Regondi, S.; Beltrami, B.; Lunetta, C. Emerging technologies for management of patients with amyotrophic lateral sclerosis: From telehealth to assistive robotics and neural interfaces. J. Neurol. 2022, 269, 2910–2921. [Google Scholar] [CrossRef]
- Masiello, P. Technology to support autonomy in patients with Amyotrophic Lateral Sclerosis. J. Adv. Health Care 2022, 4, 47–52. [Google Scholar] [CrossRef]
- Vucic, S. P300 jitter latency, brain-computer interface and amyotrophic lateral sclerosis. Clin. Neurophysiol. 2021, 132, 614–615. [Google Scholar] [CrossRef] [PubMed]
- Guy, V.; Soriani, M.H.; Bruno, M.; Papadopoulo, T.; Desnuelle, C.; Clerc, M. Brain computer interface with the P300 speller: Usability for disabled people with amyotrophic lateral sclerosis. Ann. Phys. Rehabil. Med. 2018, 61, 5–11. [Google Scholar] [CrossRef] [PubMed]
- Panigutti, C.; Hamon, R.; Hupont, I.; Fernandez Llorca, D.; Fano Yela, D.; Junklewitz, H.; Scalzo, S.; Mazzini, G.; Sanchez, I.; Soler Garrido, J.; et al. The role of explainable AI in the context of the AI Act. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 1139–1150. [Google Scholar]
- McCane, L.M.; Heckman, S.M.; McFarland, D.J.; Townsend, G.; Mak, J.N.; Sellers, E.W.; Zeitlin, D.; Tenteromano, L.M.; Wolpaw, J.R.; Vaughan, T.M. P300-based brain-computer interface (BCI) event-related potentials (ERPs): People with amyotrophic lateral sclerosis (ALS) vs. age-matched controls. Clin. Neurophysiol. 2015, 126, 2124–2131. [Google Scholar] [CrossRef] [PubMed]
- Kellmeyer, P.; Grosse-Wentrup, M.; Schulze-Bonhage, A.; Ziemann, U.; Ball, T. Electrophysiological correlates of neurodegeneration in motor and non-motor brain regions in amyotrophic lateral sclerosis—Implications for brain-computer interfacing. J. Neural Eng. 2018, 15. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Marini, M.R.; Pannone, D. Analyzing EEG Data with Machine and Deep Learning: A Benchmark. In Proceedings of the Image Analysis and Processing—ICIAP 2022, Lecce, Italy, 23–27 May 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer: Cham, Switzerland, 2022; pp. 335–345. [Google Scholar]
- Guo, J.; Huang, Z. A calibration-free P300 BCI system using an on-line updating classifier based on reinforcement learning. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 23–25 October 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Cluster Computing 2022, 26, 3985–3995. [Google Scholar] [CrossRef]
- Ramele, R.; Villar, A.J.; Santos, J.M. EEG Waveform Analysis of P300 ERP with Applications to Brain Computer Interfaces. Brain Sci. 2018, 8, 199. [Google Scholar] [CrossRef] [PubMed]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Gao, Z.; Yin, M.; Wu, J.; Ma, K.; Grebogi, C. Multiattention Adaptation Network for Motor Imagery Recognition. IEEE Trans. Syst. Man. Cybern. Syst. 2022, 52, 5127–5139. [Google Scholar] [CrossRef]
- Kurczak, J.; Białas, K.; Chalupnik, R.; Kedziora, M. Using Brain-Computer Interface (BCI) and Artificial Intelligence for EEG Signal Analysis. In Proceedings of the Recent Challenges in Intelligent Information and Database Systems, Ho Chi Minh City, Vietnam, 28–30 November 2022; Szczerbicki, E., Wojtkiewicz, K., Nguyen, S.V., Pietranik, M., Krótkiewicz, M., Eds.; Springer: Singapore, 2022; pp. 214–226. [Google Scholar]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2016, 14, 016003. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yao, L.; Wang, X.; Monaghan, J.; Mcalpine, D.; Zhang, Y. A survey on deep learning based brain computer interface: Recent advances and new frontiers. arXiv 2019, arXiv:1905.04149. [Google Scholar]
- Paul, A. Prediction of missing EEG channel waveform using LSTM. In Proceedings of the 2020 4th International Conference on Computational Intelligence and Networks (CINE), Kolkata, India, 27–29 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Cai, Q.; Gao, Z.; An, J.; Gao, S.; Grebogi, C. A Graph-Temporal Fused Dual-Input Convolutional Neural Network for Detecting Sleep Stages from EEG Signals. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 777–781. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.R.; Zhang, B.; Lei, M.Y.; Cui, W.G.; Guo, Y.Z. A Channel-Projection Mixed-Scale Convolutional Neural Network for Motor Imagery EEG Decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1170–1180. [Google Scholar] [CrossRef]
- Liu, M.; Wu, W.; Gu, Z.; Yu, Z.; Qi, F.; Li, Y. Deep learning based on Batch Normalization for P300 signal detection. Neurocomputing 2018, 275, 288–297. [Google Scholar] [CrossRef]
- Havaei, P.; Zekri, M.; Mahmoudzadeh, E.; Rabbani, H. An efficient deep learning framework for P300 evoked related potential detection in EEG signal. Comput. Methods Programs Biomed. 2023, 229, 107324. [Google Scholar] [CrossRef] [PubMed]
- Kundu, S.; Ari, S. P300 based character recognition using convolutional neural network and support vector machine. Biomed. Signal Process. Control 2020, 55, 101645. [Google Scholar] [CrossRef]
- Abibullaev, B.; Zollanvari, A. A Systematic Deep Learning Model Selection for P300-Based Brain-Computer Interfaces. IEEE Trans. Syst. Man, Cybern. Syst. 2022, 52, 2744–2756. [Google Scholar] [CrossRef]
- Singh, S.A.; Meitei, T.G.; Devi, N.D.; Majumder, S. A deep neural network approach for P300 detection-based BCI using single-channel EEG scalogram images. Phys. Eng. Sci. Med. 2021, 44, 1221–1230. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.K.; Tao, X. BCINet: An Optimized Convolutional Neural Network for EEG-Based Brain-Computer Interface Applications. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 582–587. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Zhu, H.; Forenzo, D.; He, B. On The Deep Learning Models for EEG-based Brain-Computer Interface Using Motor Imagery. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 2283–2291. [Google Scholar] [CrossRef]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain-computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef]
- Alzahab, N.A.; Apollonio, L.; Di Iorio, A.; Alshalak, M.; Iarlori, S.; Ferracuti, F.; Monteriù, A.; Porcaro, C. Hybrid Deep Learning (hDL)-Based Brain-Computer Interface (BCI) Systems: A Systematic Review. Brain Sci. 2021, 11, 75. [Google Scholar] [CrossRef] [PubMed]
- Vavoulis, A.; Figueiredo, P.; Vourvopoulos, A. A Review of Online Classification Performance in Motor Imagery-Based Brain-Computer Interfaces for Stroke Neurorehabilitation. Signals 2023, 4, 73–86. [Google Scholar] [CrossRef]
- Hossain, K.M.; Islam, M.A.; Hossain, S.; Nijholt, A.; Ahad, M.A.R. Status of deep learning for EEG-based brain-computer interface applications. Front. Comput. Neurosci. 2023, 16, 1006763. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Liu, L.; Liu, M.; Wang, W.; Wang, X.; Song, Y. Representation learning with deconvolution for multivariate time series classification and visualization. In Proceedings of the International Conference of Pioneering Computer Scientists, Engineers and Educators, Taiyuan, China, 18–21 September 2020; Springer: Singapore, 2020; pp. 310–326. [Google Scholar]
- Colyer, A. The way we think about data: Human inspection of black-box ML models; reclaiming ownership of data. Queue 2019, 17, 26–27. [Google Scholar] [CrossRef]
- Wong, F.; Zheng, E.J.; Valeri, J.A.; Donghia, N.M.; Anahtar, M.N.; Omori, S.; Li, A.; Cubillos-Ruiz, A.; Krishnan, A.; Jin, W.; et al. Discovery of a structural class of antibiotics with explainable deep learning. Nature 2023, 626, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Savage, N. Breaking into the black box of artificial intelligence. Nature, 29 March 2022. [Google Scholar]
- Ail, B.E. EEG Waveform Identification Based on Deep Learning Techniques. Master’s Thesis, Instituto TecnolÓGico de Buenos Aires, Buenos Aires, Argentina, 2022. [Google Scholar]
- Ramele, R.; Villar, A.J.; Santos, J.M. Histogram of Gradient Orientations of Signal Plots Applied to P300 Detection. Front. Comput. Neurosci. 2019, 13, 43. [Google Scholar] [CrossRef]
- Ramele, R. Histogram of Gradient Orientations of EEG Signal Plots for Brain Computer Interfaces. Ph.D. Thesis, Instituto TecnolÓGico de Buenos Aires, Buenos Aires, Argentina, 2018. [Google Scholar]
- Papastylianou, T.; Dall’ Armellina, E.; Grau, V. Orientation-Sensitive Overlap Measures for the Validation of Medical Image Segmentations. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Athens, Greece, 17–21 October 2016; Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W., Eds.; Springer: Cham, Switzerland, 2016; pp. 361–369. [Google Scholar]
- Ganapathy, K.; Abdul, S.S.; Nursetyo, A.A. Artificial intelligence in neurosciences: A clinician’s perspective. Neurol. India 2018, 66, 934. [Google Scholar] [CrossRef]
- Kawala-Sterniuk, A.; Browarska, N.; Al-Bakri, A.; Pelc, M.; Zygarlicki, J.; Sidikova, M.; Martinek, R.; Gorzelanczyk, E.J. Summary of over Fifty Years with Brain-Computer Interfaces—A Review. Brain Sci. 2021, 11, 43. [Google Scholar] [CrossRef] [PubMed]
- Brunner, C.; Birbaumer, N.; Blankertz, B.; Guger, C.; Kübler, A.; Mattia, D.; del R. Millán, J.; Miralles, F.; Nijholt, A.; Opisso, E.; et al. BNCI Horizon 2020: Towards a roadmap for the BCI community. Brain-Comput. Interfaces 2015, 2, 1–10. [Google Scholar] [CrossRef]
- Riccio, A.; Simione, L.; Schettini, F.; Pizzimenti, A.; Inghilleri, M.; Olivetti Belardinelli, M.; Mattia, D.; Cincotti, F. Attention and P300-based BCI performance in people with amyotrophic lateral sclerosis. Front. Hum. Neurosci. 2013, 7, 732. [Google Scholar] [CrossRef]
- Schalk, G.; Mcfarland, D.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J. BCI2000: A general-purpose Brain-Computer Interface (BCI) system. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef] [PubMed]
- Abdulaal, M.J.; Casson, A.J.; Gaydecki, P. Performance of Nested vs. Non-Nested SVM Cross-Validation Methods in Visual BCI: Validation Study. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1680–1684. [Google Scholar] [CrossRef]
- Shafer, G.; Vovk, V. A Tutorial on Conformal Prediction. J. Mach. Learn. Res. 2008, 9, 371–421. [Google Scholar]
- Delorme, A. EEG is better left alone. Sci. Rep. 2023, 13, 2372. [Google Scholar] [CrossRef] [PubMed]
- van Drongelen, W. 4-Signal Averaging. In Signal Processing for Neuroscientists; van Drongelen, W., Ed.; Academic Press: Burlington, NJ, USA, 2007; pp. 55–70. [Google Scholar] [CrossRef]
- Jackson, A.F.; Bolger, D.J. The neurophysiological bases of EEG and EEG measurement: A review for the rest of us. Psychophysiology 2014, 51, 1061–1071. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, P.; Guo, L.; Zhang, Y.; Li, P.; Yao, D. Z-score linear discriminant analysis for EEG based brain-computer interfaces. PLoS ONE 2013, 8, e74433. [Google Scholar] [CrossRef] [PubMed]
- Jestico, J.; Fitch, P.; Gilliatt, R.W.; Willison, R.G. Automatic and rapid visual analysis of sleep stages and epileptic activity. A preliminary report. Electroencephalogr. Clin. Neurophysiol. 1977, 43, 438–441. [Google Scholar] [CrossRef]
- Bresenham, J.E. Algorithm for computer control of a digital plotter. IBM Syst. J. 1965, 4, 25–30. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet Large Scale Visual Recognition Challenge 2014 (ILSVRC2014). 2014. Available online: https://www.image-net.org/challenges/LSVRC/2014/ (accessed on 3 September 2022).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tibon, R.; Levy, D.A. Striking a balance: Analyzing unbalanced event-related potential data. Front. Psychol. 2015, 6, 555. [Google Scholar] [CrossRef]
- Gramfort, A.; Luessi, M.; Larson, E.; Engemann, D.A.; Strohmeier, D.; Brodbeck, C.; Parkkonen, L.; Hämäläinen, M.S. MNE software for processing MEG and EEG data. NeuroImage 2014, 86, 446–460. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Friedman, B. Creating a TensorFlow CNN in C++. 2014. Available online: https://towardsdatascience.com/creating-a-tensorflow-cnn-in-c-part-2-eea0de9dcada (accessed on 4 April 2024).
- Pavlov, Y.G.; Adamian, N.; Appelhoff, S.; Arvaneh, M.; Benwell, C.S.; Beste, C.; Bland, A.R.; Bradford, D.E.; Bublatzky, F.; Busch, N.A.; et al. #EEGManyLabs: Investigating the replicability of influential EEG experiments. Cortex 2021, 144, 213–229. [Google Scholar] [CrossRef] [PubMed]
- Lowe, G. SIFT-the scale invariant feature transform. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Theodorsson-Norheim, E. Friedman and Quade tests: BASIC computer program to perform nonparametric two-way analysis of variance and multiple comparisons on ranks of several related samples. Comput. Biol. Med. 1987, 17, 85–99. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Carneiro de Albuquerque, I.M.; Gramfort, A.; Falk, T.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain-computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef] [PubMed]
- Wolpaw, J.; Wolpaw, E.W. (Eds.) Brain-Computer Interfaces: Principles and Practice; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Rao, R.P.N. Brain-Computer Interfacing: An Introduction; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar] [CrossRef]
- Valeriani, D.; Santoro, F.; Ienca, M. The present and future of neural interfaces. Front. Neurorobotics 2022, 16. [Google Scholar] [CrossRef]
- Perry, J.C.; Rosen, J.; Burns, S. Upper-Limb Powered Exoskeleton Design. IEEE/ASME Trans. Mechatron. 2007, 12, 408–417. [Google Scholar] [CrossRef]
- Lobo-Prat, J.; Keemink, A.Q.L.; Stienen, A.H.A.; Schouten, A.C.; Veltink, P.H.; Koopman, B.F.J.M. Evaluation of EMG, force and joystick as control interfaces for active arm supports. J. NeuroEng. Rehabil. 2014, 11, 68. [Google Scholar] [CrossRef]
- Coupé, C.; Oh, Y.M.; Dediu, D.; Pellegrino, F. Different languages, similar encoding efficiency: Comparable information rates across the human communicative niche. Sci. Adv. 2019, 5, eaaw2594. [Google Scholar] [CrossRef] [PubMed]
- Kursa, M.B.; Jankowski, A.; Rudnicki, W.R. Boruta–a system for feature selection. Fundam. Informaticae 2010, 101, 271–285. [Google Scholar] [CrossRef]
- Liang, Y.; Li, S.; Yan, C.; Li, M.; Jiang, C. Explaining the black-box model: A survey of local interpretation methods for deep neural networks. Neurocomputing 2021, 419, 168–182. [Google Scholar] [CrossRef]
- Azam, S.; Montaha, S.; Fahim, K.U.; Rafid, A.K.H.; Mukta, M.S.H.; Jonkman, M. Using feature maps to unpack the CNN Black box theory with two medical datasets of different modality. Intell. Syst. Appl. 2023, 18, 200233. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Linse, K.; Aust, E.; Joos, M.; Hermann, A. Communication matters-pitfalls and promise of hightech communication devices in palliative care of severely physically disabled patients with amyotrophic lateral sclerosis. Front. Neurol. 2018, 9, 603. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Ehsan, U.; Wintersberger, P.; Liao, Q.V.; Mara, M.; Streit, M.; Wachter, S.; Riener, A.; Riedl, M.O. Operationalizing Human-Centered Perspectives in Explainable AI. In Proceedings of the Conference on Human Factors in Computing Systems-Proceedings, Online, 8–13 May 2021. [Google Scholar] [CrossRef]
- Raissi, M. Open Problems in Applied Deep Learning. arXiv 2023, arXiv:2301.11316. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | SWLDA | SVM | EEGNET | BCINET | SIFT | VGG16 | SV16 | MSV16 |
|---|---|---|---|---|---|---|---|---|
| 1 | 45 | 40 | 50 | 45 | 35 | 15 | 10 | 0 |
| 2 | 30 | 50 | 30 | 55 | 85 | 70 | 50 | 75 |
| 3 | 65 | 55 | 70 | 65 | 25 | 30 | 30 | 40 |
| 4 | 40 | 50 | 60 | 55 | 55 | 30 | 40 | 30 |
| 5 | 35 | 45 | 40 | 45 | 40 | 35 | 50 | 50 |
| 6 | 35 | 70 | 60 | 75 | 60 | 45 | 40 | 50 |
| 7 | 60 | 35 | 90 | 80 | 80 | 70 | 65 | 80 |
| 8 | 90 | 95 | 100 | 95 | 95 | 90 | 95 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ail, B.E.; Ramele, R.; Gambini, J.; Santos, J.M. An Intrinsically Explainable Method to Decode P300 Waveforms from EEG Signal Plots Based on Convolutional Neural Networks. Brain Sci. 2024, 14, 836. https://doi.org/10.3390/brainsci14080836
Ail BE, Ramele R, Gambini J, Santos JM. An Intrinsically Explainable Method to Decode P300 Waveforms from EEG Signal Plots Based on Convolutional Neural Networks. Brain Sciences. 2024; 14(8):836. https://doi.org/10.3390/brainsci14080836
Chicago/Turabian StyleAil, Brian Ezequiel, Rodrigo Ramele, Juliana Gambini, and Juan Miguel Santos. 2024. "An Intrinsically Explainable Method to Decode P300 Waveforms from EEG Signal Plots Based on Convolutional Neural Networks" Brain Sciences 14, no. 8: 836. https://doi.org/10.3390/brainsci14080836