1. Introduction
Crop disease is one of the major agricultural disasters, and the harmful effect of a wide spread of crop disease usually manifests itself in a significant reduction in crop yield and quality. Previously, farmers and agricultural experts identified crop diseases based on personal experience, suffering limited scope and deteriorating disease identification accuracy. Since there are numerous disease categories and crop types that are influenced by outdoor environments such as light, occlusion, and jitter, different types of crop diseases show significant intra-class differences. However, different subcategories of the same disease have similar disease appearances and can only be discriminated by capturing distinguishing features in subtle regions, which poses a great challenge to high-precision crop disease classification tasks. Therefore, it is critical to design a high-performance crop disease identification model and adopt timely and effective control measures for improving crop yield and quality.
Crop disease is characterized by significant intra-class differences and subtle inter-class differences. Consequently, the crop disease classification problem belongs to the fine-grained classification problem. In the early stage, manual identification methods mainly relied on expert experience to identify crop diseases, which was time-consuming and laborious, and the misdiagnosis rate was high for diseases with a similar appearance. With the development and improvement of computer vision technology, machine learning-based methods and deep learning-based methods have promoted accurate crop disease identification. Machine learning-based methods firstly preprocess the acquired leaf images [
1,
2,
3,
4,
5], such as denoising, image conversion, and image enhancement. Secondly, the region of interest is segmented from the background. In [
6,
7,
8,
9,
10,
11,
12], researchers segmented the crop disease area and background through canny edge detection, Grabcut segmentation, Otsu segmentation, and K-means segmentation methods. Then, features of the region of interest are extracted, which are usually color, texture, and shape features [
13,
14,
15]. Studies have shown that texture features work best for disease identification. In [
13], the gray level co-occurrence matrix was used to extract corn disease texture features. In [
14], disease texture features are extracted by a spatial grayscale dependency matrix. Pires et al. [
15] compared scale-invariant feature transform (SIFT), dense scale-invariant feature transform (DSIFT), pyramid histograms of visual words (PHOW), speeded-up robust features (SURF), histogram of oriented gradients (HOG), and other feature extraction methods, the results showed that the best model performance was achieved by using PHOW to extract soybean disease characteristics. Finally, the extracted features are sent to the classifier for training [
16,
17,
18,
19,
20]. In [
16], three different methods of Patternnet neural network, support vector machine, and k-nearest neighbor (KNN) are used to train the extracted features, and KNN achieves the best results through experiments. [
17] utilized SVM and grid search-based SVM to train on the PlantVillage dataset. The SVM classifier model achieved 80% accuracy, and the grid search-based SVM classifier model achieved 84% accuracy. Hlaing et al. [
18] used SIFT to extract the texture features of tomato diseases and then sent them to the SVM classifier for training, and achieved an accuracy of 84%. Based on the analysis of the above studies, it could be seen that machine learning-based disease identification methods have major limitations, such as the hyperparameters’ selection in segmentation methods, which can have a large impact on model performance; segmentation is particularly difficult in the complex backgrounds; hand-crafted feature extraction method is less optimized, etc.
In contrast, deep learning-based methods can automatically extract image features, reduce the workload of image segmentation and feature extraction in machine learning methods, and enable end-to-end training. This has led to the widespread application of deep learning-based methods in the field of crop disease classification and has become a research hotspot. Convolutional neural networks (CNN) [
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32], a representative algorithm of deep learning, perform the best in crop disease classification. Mohanty et al. [
21] trained the PlantVillage dataset using AlexNet [
31] and GoogleNet [
32] and achieved an accuracy of 99.35%, which validated the feasibility of this method. Ferentinos et al. [
22] explored several convolutional neural networks using 25 different types of plants and found that VGG achieved the best performance with an accuracy of 99.53%. Sladojevic et al. [
23] proposed a deep convolutional network-based plant disease recognition model that was able to distinguish between healthy leaves and 13 types of diseases with an overall accuracy of 96.3%. Grinblat et al. [
24] utilized deep convolution neural networks to classify three bean species and experimentally demonstrated that the accuracy monotonically improved with increasing model depth. Ma et al. [
25] proposed a deep convolution neural network to identify cucumber diseases and compared it with traditional classifiers using random forests and support vector machines as well as AlexNet and proved its effectiveness in identifying cucumber diseases in real scenarios. This method achieved 93.4% and 92.2% accuracy on the balanced and unbalanced datasets, respectively. However, a large amount of training data are required for deep convolutional neural networks to achieve excellent performance, for which researchers have used the idea of transfer learning [
33,
34,
35,
36] to further improve model classification accuracy using CNN models pre-trained on ImageNet datasets. For example, Kaya et al. [
33] studied four different transfer learning methods on four public datasets and experimentally showed that transfer learning models based on fine-tuning are more beneficial in improving model classification performance. Too et al. [
34] fine-tuned several state-of-the-art deep CNN models on the PlantVillage dataset and obtained a model with an accuracy of 99.75%. Cruz et al. [
35] recognized grape diseases with ResNet50 [
37] backbone, obtaining balanced training time and accuracy. Numerous experiments have demonstrated that transfer learning can effectively improve the classification performance of deep convolution networks.
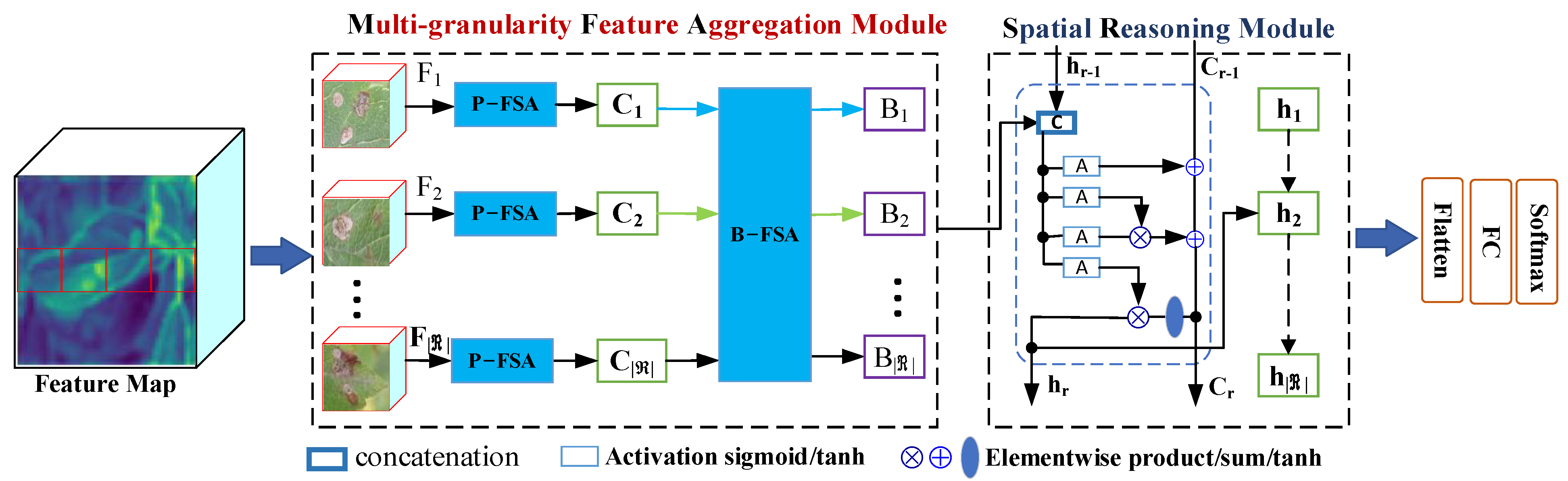
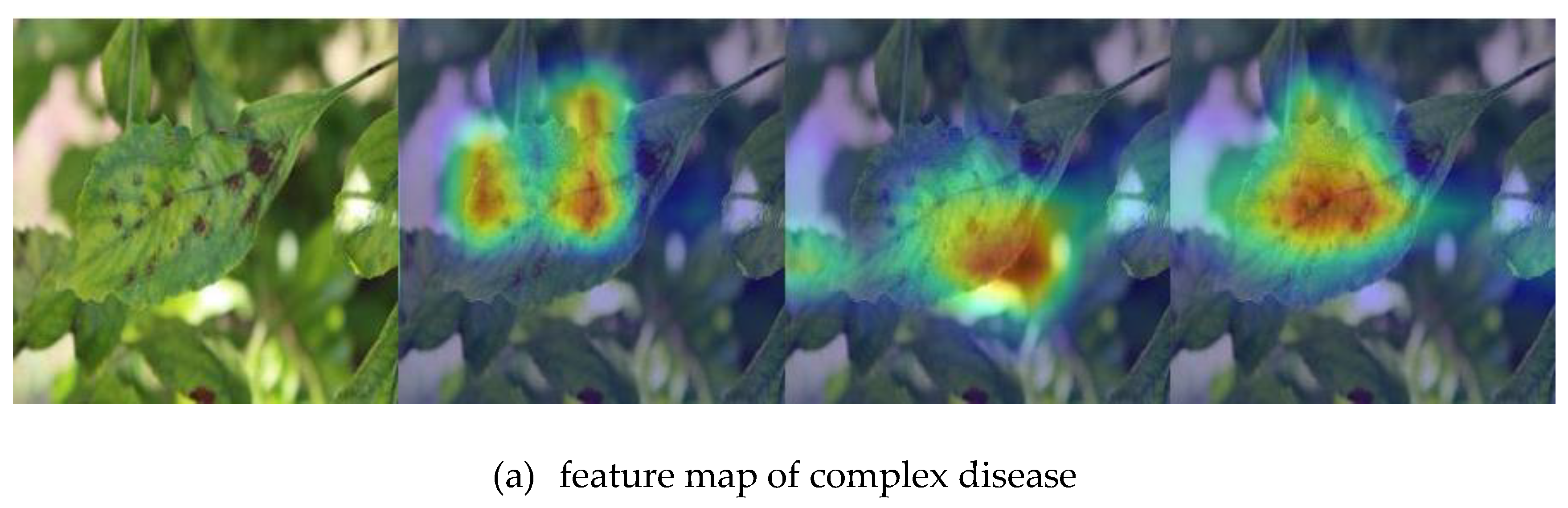
In the above studies, the models can achieve good classification results when the intra-class differences are large. However, the model performance is not satisfactory when the inter-class differences are small. To this end, a multi-granularity feature aggregation method was proposed to better capture discriminative features of subtle regions to differentiate crop diseases with similar appearances. Firstly, we utilized a pre-trained CNN to extract the feature of the input images, which were divided into several non-overlapping patches. Secondly, we explored the pixel-level spatial self-attention module to capture fine-grained discriminative cues for each disease category. Subsequently, we further investigated the block-level coarse-grained channel self-attention module for improving the discrimination of different crop species features. In addition, taking into account that the diseases are randomly distributed over distinct locations of the leaves, we exploited the spatial reasoning module to model the spatial geometric relationships between image blocks sequentially to further enhance the feature representation of the diseases for improving the discriminatory ability of disease and species characteristics. The main contributions of this paper are as follows:
- (1)
A multi-granularity feature aggregation method is proposed to strengthen the connection between different granularity features by exploring multiple regions and hierarchically learning the discriminative disease feature from pixel level to block level.
- (2)
Considering that subtle changes in the overall region and its spatial arrangement can better refine the learning process, a spatial reasoning module is introduced to improve the model’s performance.
- (3)
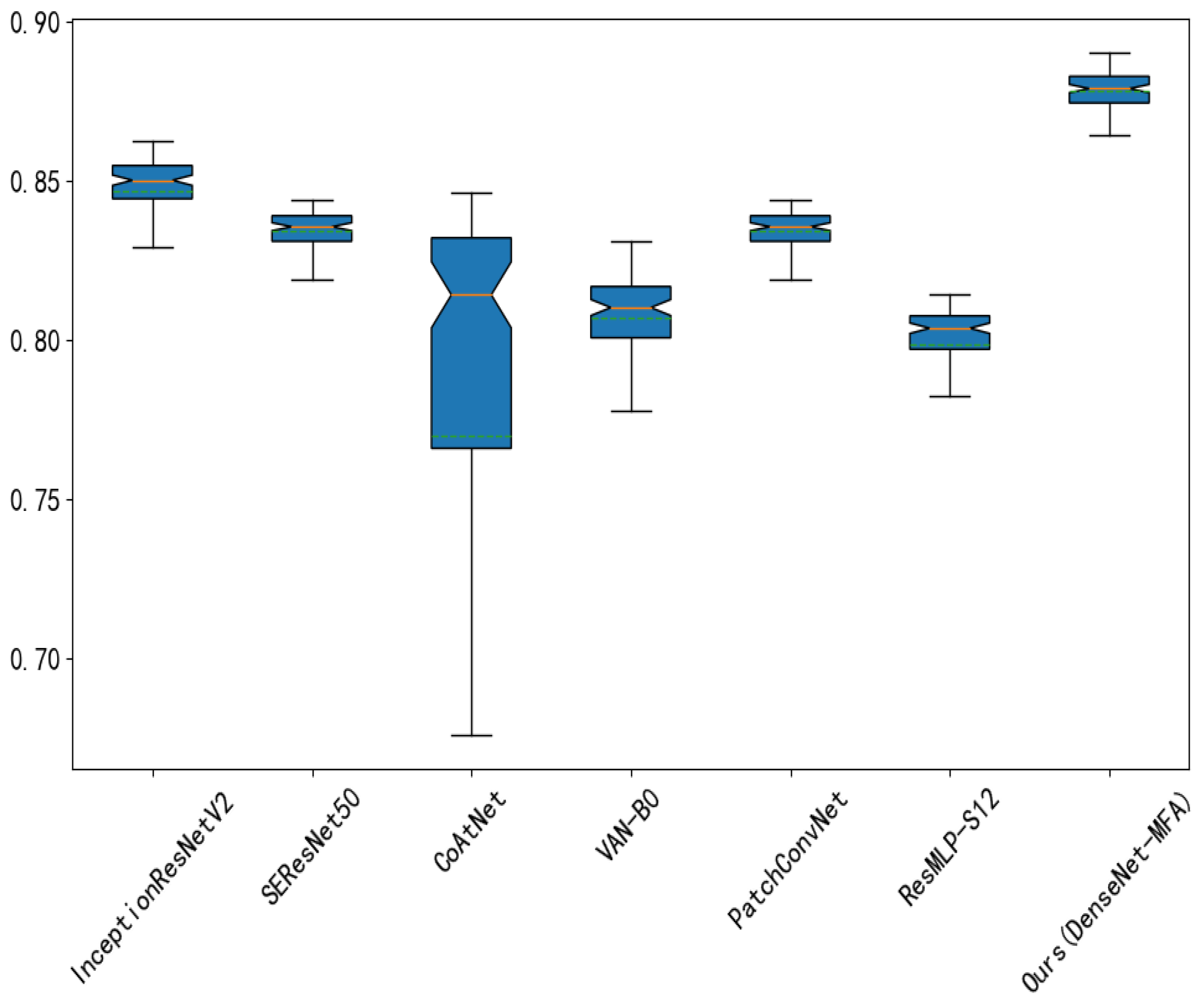
The experimental results of PDR2018, FGVC8 and non-lab PlantDoc datasets show that the method not only effectively improves the classification accuracy, but also has low complexity.
The sections of this paper are organized as follows: In
Section 2, the dataset is introduced.
Section 3 describes the method proposed in this paper. The experimental results and analysis are given in
Section 4. Discussion of the method of this paper is given in
Section 5. Conclusions are given in
Section 6.
6. Conclusions
Nowadays, crop diseases pose a major threat to the global food supply. Since crop diseases exhibit dramatic intra-class variances and subtle inter-class differences, it increases the difficulty of accurately classifying fine-grained crop diseases. In this study, we proposed a multi-granularity feature aggregation method for accurate crop disease recognition. Firstly, the fine-grained features of disease images were extracted by pixel-level spatial self-attention module and block-level channel self-attention module. Then, they were coupled with the spatial reasoning module to model the spatial relationships of different feature blocks. Thus, the localization and recognition of disease regions were strengthened and the feature representation was enhanced. Experimental results on the PDR2018, FGVC8 and PlantDoc datasets demonstrated the effectiveness of the method. In practical applications, in particular, the proposed method could not only serve farmers with timely and effective disease diagnosis, guiding them to carry out correct control activities, and minimizing the number of pesticide applications, but could also effectively protect the environment and reduce costs.
Although the proposed method could better capture the subtle features of crop diseases and enhance the descriptive capability of the disease feature, there was still much room for improvement. Firstly, our method used only a single network, and the effective features extracted were limited to disease images with complex background noise. Secondly, the classification accuracy for a few disease categories was reduced for datasets with unbalanced categories. Therefore, we will consider optimizing the network structure and extracting discriminative features by explicitly locating disease locations in our future work. In addition, we will expand the dataset by combining data augmentation methods such as GAN, so as to further improve the model classification accuracy.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}